Il Linguaggio di Programmazione Rust
di Steve Klabnik, Carol Nichols, and Chris Krycho, con contributi della Community Rust
Questa versione del testo presuppone l’utilizzo di Rust 1.90.0 (rilasciato il
2025-09-18) o successivo con edition = "2024" nel file Cargo.toml di tutti i
progetti per configurarli in modo da utilizzare gli idiomi dell’edizione 2024 di
Rust. Consulta la sezione “Installazione” del Capitolo 1 per installare o aggiornare Rust, e vedi l’Appendice E per informazioni sulle varie edizioni.
Il libro originale in inglese in formato HTML si trova su
https://doc.rust-lang.org/stable/book/
oppure offline su installazioni di Rust fatte tramite rustup; esegui rustup doc --book per visualizzarlo.
Sono disponibili alcune traduzioni fatte dalla community.
Questo testo, in inglese, è disponibile anche come libro cartaceo o ebook da No Starch Press.
🚨 Vuoi provare un’esperienza di apprendimento più interattiva? Prova una versione modificata del Libro (in inglese), con aggiunta di quiz, sottolineature, visualizzazioni e molto altro: https://rust-book.cs.brown.edu
Prefazione
Il linguaggio di programmazione Rust ha fatto molta strada in pochi anni, dalla sua creazione e incubazione da parte di una piccola e giovane comunità di appassionati, fino a diventare uno dei linguaggi di programmazione più amati e richiesti al mondo. Ripensando a tutto ciò, era inevitabile che la potenza e le promesse di Rust attirassero l’attenzione e trovassero spazio nella programmazione di sistemi. Quello che non era scontato era la crescita globale dell’interesse e dell’innovazione che ha permeato le comunità open source, catalizzando un’adozione su larga scala in vari settori.
Oggi è facile indicare le meravigliose caratteristiche che Rust offre per spiegare questa esplosione di interesse e adozione. Chi non vorrebbe sicurezza nella gestione della memoria, e prestazioni elevate, e un compilatore amichevole, e ottimi strumenti, insieme a tante altre fantastiche funzionalità? Il linguaggio Rust che vedi oggi combina anni di ricerca nella programmazione di sistemi con la saggezza pratica di una comunità vivace e appassionata. Questo linguaggio è stato progettato con uno scopo e realizzato con cura, offrendo agli sviluppatori uno strumento che rende più facile scrivere codice sicuro, veloce e affidabile.
Ma ciò che rende Rust davvero speciale sono le sue radici nel dare potere a te, l’utente, per raggiungere i tuoi obiettivi. Questo è un linguaggio che vuole che tu abbia successo, e il principio di empowerment attraversa il cuore della comunità che costruisce, mantiene e promuove questo linguaggio. Dall’edizione precedente di questo testo definitivo, Rust si è ulteriormente sviluppato in un linguaggio davvero globale e affidabile. Il Rust Project è ora robustamente supportato dalla Rust Foundation, che investe anche in iniziative chiave per garantire che Rust sia sicuro, stabile e sostenibile.
Questa edizione di The Rust Programming Language è un aggiornamento completo, che riflette l’evoluzione del linguaggio nel corso degli anni e fornisce nuove informazioni preziose. Ma non è solo una guida alla sintassi e alle librerie: è un invito a unirti a una comunità che valorizza qualità, prestazioni e design riflessivo. Che tu sia uno sviluppatore esperto che vuole esplorare Rust per la prima volta o un Rustacean esperto che cerca di affinare le proprie abilità, questa edizione offre qualcosa per tutti.
Il viaggio di Rust è stato caratterizzato da collaborazione, apprendimento e iterazione. La crescita del linguaggio e del suo ecosistema è un riflesso diretto della comunità vibrante e diversificata che lo sostiene. I contributi di migliaia di sviluppatori, dai progettisti del linguaggio ai collaboratori occasionali, sono ciò che rende Rust uno strumento così unico e potente. Prendendo in mano questo libro, non stai solo imparando un nuovo linguaggio di programmazione: stai entrando a far parte di un movimento per rendere il software migliore, più sicuro e più piacevole da usare.
Benvenuto nella comunità di Rust!
- Bec Rumbul, Direttore Esecutivo della Rust Foundation
Introduzione
Nota: questa edizione del libro in inglese è identica a The Rust Programming Language, disponibile in formato cartaceo ed ebook presso No Starch Press.
Benvenuti a Il Linguaggio di Programmazione Rust, un libro introduttivo su Rust. Il linguaggio di programmazione Rust ti aiuta a scrivere software più veloce e affidabile. L’ergonomia di alto livello e il controllo di basso livello sono spesso in contrasto nella progettazione dei linguaggi di programmazione; Rust sfida questo conflitto. Grazie al bilanciamento tra potenti capacità tecniche e un’ottima esperienza di sviluppo, Rust ti offre la possibilità di controllare i dettagli di basso livello (come l’utilizzo della memoria) senza tutte le difficoltà tradizionalmente associate a tale controllo.
A Chi È Rivolto Rust
Rust è ideale per molte persone per una serie di motivi. Diamo un’occhiata ad alcuni dei gruppi più importanti.
Team di Sviluppatori
Rust si sta dimostrando uno strumento produttivo per la collaborazione tra grandi team di sviluppatori con diversi livelli di conoscenza della programmazione di sistemi. Il codice di basso livello è soggetto a vari bug subdoli, che nella maggior parte degli altri linguaggi possono essere individuati solo attraverso test approfonditi e un’attenta revisione del codice da parte di sviluppatori esperti. In Rust, il compilatore svolge un ruolo di gatekeeper rifiutando di compilare il codice con questi bug subdoli, compresi i bug di concorrenza. Lavorando a fianco del compilatore, il team può dedicare il proprio tempo a concentrarsi sulla logica del programma piuttosto che a cercare i bug.
Rust porta anche strumenti di sviluppo contemporanei nel mondo della programmazione di sistemi:
- Cargo, il gestore di dipendenze e strumento di compilazione integrato, rende l’aggiunta, la compilazione e la gestione delle dipendenze semplice e coerente in tutto l’ecosistema Rust.
- Lo strumento di formattazione
rustfmtgarantisce uno stile di programmazione coerente tra gli sviluppatori. - Il Server LSP del Linguaggio Rust potenzia l’integrazione dell’ambiente di sviluppo integrato (IDE) per il completamento del codice e i messaggi di errore in linea.
Utilizzando questi e altri strumenti dell’ecosistema Rust, gli sviluppatori possono essere produttivi mentre scrivono codice a livello di sistema.
Studenti
Rust è rivolto agli studenti e a coloro che sono interessati a conoscere i concetti di sistema. Utilizzando Rust, molte persone hanno imparato a conoscere argomenti come lo sviluppo di sistemi operativi. La comunità è molto accogliente e felice di rispondere alle domande degli studenti. Attraverso iniziative come questo libro, i team di Rust vogliono rendere i concetti di sistema più accessibili a un maggior numero di persone, soprattutto a chi è alle prime armi con la programmazione.
Aziende
Centinaia di aziende, grandi e piccole, utilizzano Rust in produzione per una serie di compiti, come strumenti a riga di comando, servizi web, strumenti DevOps, dispositivi embedded, analisi e transcodifica di audio e video, cripto-valute, bioinformatica, motori di ricerca, applicazioni per l’Internet delle cose, machine learning e persino parti importanti del browser web Firefox.
Sviluppatori Open Source
Rust è per le persone che vogliono costruire il linguaggio di programmazione Rust, la comunità, gli strumenti per gli sviluppatori e le librerie. Ci piacerebbe che tu contribuissi al linguaggio Rust.
Persone che Apprezzano la Velocità e la Stabilità
Rust è per le persone che desiderano velocità e stabilità in un linguaggio. Per velocità intendiamo sia la velocità con cui il codice Rust può essere eseguito, sia la velocità con cui Rust ti permette di scrivere programmi. I controlli del compilatore di Rust assicurano la stabilità quando si aggiungono funzionalità e riscrive il codice, in contrasto con la fragilità del codice legacy dei linguaggi senza questi controlli, che spesso gli sviluppatori hanno paura di modificare. Puntando ad astrazioni a costo zero, ovvero funzionalità di livello superiore che vengono compilate in codice di livello inferiore con la stessa velocità del codice scritto manualmente, Rust cerca di rendere il codice sia sicuro che veloce.
Il linguaggio Rust spera di supportare anche molti altri utenti; quelli citati qui sono solo alcuni dei maggiori interessati. Nel complesso, la più grande ambizione di Rust è quella di eliminare i compromessi che i programmatori hanno accettato per decenni, offrendo sicurezza e produttività, velocità e ergonomia. Prova Rust e vedi se le sue scelte funzionano per te.
Per Chi È Questo Libro
Questo libro presuppone che tu abbia scritto codice in un altro linguaggio di programmazione, ma non fa alcuna ipotesi su quale sia. Abbiamo cercato di rendere il materiale ampiamente accessibile a coloro che provengono da un’ampia varietà di background di programmazione. Non dedichiamo molto tempo a parlare di cosa sia la programmazione o di come pensarla. Se sei completamente nuovo alla programmazione, è meglio che tu legga un libro che fornisca un’introduzione specifica alla programmazione.
Come Utilizzare Questo Libro
In generale, questo libro presuppone che tu lo legga in sequenza, dall’inizio alla fine. I capitoli più avanzati si basano sui concetti dei capitoli precedenti, e i capitoli iniziali potrebbero non approfondire un determinato argomento, che invece viene sviluppato più approfonditamente in un capitolo successivo.
In questo libro troverai due tipi di capitoli: i capitoli concettuali e i capitoli di progetto. Nei capitoli concettuali, imparerai a conoscere un aspetto di Rust. Nei capitoli di progetto, costruiremo insieme dei piccoli programmi, applicando ciò che hai imparato finora. I capitoli 2, 12 e 21 sono capitoli di progetto; il resto sono capitoli concettuali.
Il Capitolo 1 spiega come installare Rust, come scrivere un programma “Hello, world!” e come utilizzare Cargo, il gestore di pacchetti e lo strumento di compilazione di Rust. Il Capitolo 2 è un’introduzione pratica alla scrittura di un programma in Rust, con la creazione di un gioco di indovinelli con i numeri. Qui trattiamo i concetti ad un livello più superficiale e i capitoli successivi forniranno ulteriori dettagli. Se vuoi sporcarti subito le mani, il Capitolo 2 è dove puoi iniziare. Se invece sei uno studente particolarmente meticoloso, che preferisce imparare ogni dettaglio prima di passare al successivo, potresti voler saltare il Capitolo 2 e passare direttamente al Capitolo 3 che tratta le caratteristiche di Rust simili a quelle di altri linguaggi di programmazione; dopo, potrai ritornare al Capitolo 2 se vorrai applicare in un progetto quanto appreso.
Nel Capitolo 4 imparerai a conoscere il sistema di proprietà (ownership
d’ora in poi) di Rust. Il Capitolo 5 parla di strutture e metodi, mentre il
Capitolo 6 tratta le enumerazioni, le espressioni match e il costrutto
della struttura di controllo if let. Utilizzerai le strutture e le
enumerazioni per creare type personalizzati in Rust.
Nel Capitolo 7 imparerai a conoscere il sistema dei moduli di Rust, le regole di visibilità per l’organizzazione del codice e la sua Application Programming Interface (API) pubblica. Il Capitolo 8 tratta alcune strutture di dati comuni che la libreria standard mette a disposizione, come vettori, stringhe e mappe hash. Il Capitolo 9 esplora la filosofia e le tecniche di gestione degli errori di Rust.
Il Capitolo 10 approfondisce i generici, i tratti e la longevità (trait e
lifetime), che ti danno la possibilità di definire codice applicabile a più
tipologie di dato. Il Capitolo 11 è dedicato ai test, che anche con le
garanzie di sicurezza di Rust sono necessari per garantire la correttezza della
logica del tuo programma. Nel Capitolo 12, costruiremo la nostra
implementazione di un sottoinsieme di funzionalità dello strumento da riga di
comando grep, che cerca il testo all’interno dei file. Per questo,
utilizzeremo molti dei concetti discussi nei capitoli precedenti.
Il Capitolo 13 esplora le chiusure e gli iteratori: caratteristiche di Rust che derivano dai linguaggi di programmazione funzionale. Nel Capitolo 14 esamineremo Cargo in modo più approfondito e parleremo delle migliori pratiche per condividere le tue librerie con altri. Il Capitolo 15 parla dei puntatori intelligenti che la libreria standard mette a disposizione e dei traits che ne consentono la funzionalità.
Nel Capitolo 16, esamineremo diversi modelli di programmazione concorrente e parleremo di come Rust ti aiuti a programmare con più sotto-processi (thread d’ora in poi) senza paura. Nel Capitolo 17, esploreremo la sintassi async e await di Rust, insieme a task, futures e stream, e il modello di concomitanza leggera che consentono.
Il Capitolo 18 analizza come gli idiomi di Rust si confrontano con i principi della programmazione orientata agli oggetti che potresti conoscere. Il Capitolo 19 è un riferimento ai pattern e al loro riconoscimento (pattern matching), che sono modi potenti di esprimere idee nei programmi Rust. Il Capitolo 20 contiene una varietà di argomenti di interesse, tra cui Rust non sicuro (unsafe Rust d’ora in poi), macro e altre informazioni su longevità, trait, tipologie (type), funzioni e chiusure.
Nel Capitolo 21, completeremo un progetto in cui implementeremo un server web multi-thread di basso livello!
Infine, alcune appendici contengono informazioni utili sul linguaggio in un formato meno strutturato. L’Appendice A tratta delle parole chiave di Rust, l’Appendice B degli operatori e dei simboli di Rust, l’Appendice C dei trait derivabili forniti dalla libreria standard, l’Appendice D di alcuni utili strumenti di sviluppo e l’Appendice E delle varie edizioni di Rust. Nell’Appendice F puoi trovare un elenco delle traduzioni del libro, mentre nell’Appendice G si parlerà di come viene realizzato Rust e di cosa sia la nightly Rust.
Non c’è un modo sbagliato di leggere questo libro: se vuoi andare avanti, fallo pure! Potresti dover tornare indietro ai capitoli precedenti se ti senti confuso, ma fai quello che va bene per te.
Una parte importante del processo di apprendimento di Rust consiste nell’imparare a leggere i messaggi di errore visualizzati dal compilatore: questi ti guideranno verso un codice funzionante. Per questo motivo, ti forniremo molti esempi che non si compilano insieme al messaggio di errore che il compilatore ti mostrerà in ogni situazione. Sappi che se inserisci ed esegui un esempio a caso, potrebbe non compilarsi! Assicurati di leggere il testo circostante per capire se l’esempio che stai cercando di eseguire è destinato a dare un errore. Nella maggior parte delle situazioni, ti guideremo alla correzione di questi errori che comportano la mancata compilazione. Ferris ti aiuterà anche a distinguere il codice che non è destinato a funzionare:
| Ferris | Significato |
|---|---|
 | Questo codice non si compila! |
 | Questo codice genera panic! |
 | Questo codice non funziona come dovrebbe. |
Nella maggior parte dei casi, ti guideremo alla versione corretta di qualsiasi codice che non si compila.
Codice Sorgente
I file sorgente da cui è stato generato questo libro si trovano su GitHub per la versione italiana.
La versione originale in inglese si trova anch’essa su GitHub.
Primi Passi
Iniziamo il tuo viaggio in Rust! C’è molto da imparare, ma ogni viaggio inizia da qualche parte. In questo capitolo parleremo di come:
- Installare Rust su Linux, macOS e Windows
- Scrivere un programma che stampi
Hello, world! - Utilizzare
cargo, il gestore di pacchetti e il sistema di compilazione di Rust
Installazione
Il primo passo è quello di installare Rust. Scaricheremo Rust attraverso
rustup, uno strumento a riga di comando per gestire le versioni di Rust e gli
strumenti associati. Per il download è necessaria una connessione a internet.
Nota: Se per qualche motivo preferisci non utilizzare
rustup, consulta la pagina Altri metodi di installazione di Rust per ulteriori opzioni.
I passaggi seguenti installano l’ultima versione stabile del compilatore Rust. Le garanzie di stabilità di Rust assicurano che tutti gli esempi del libro che vengono compilati continueranno a essere compilati anche con le versioni più recenti di Rust. L’output potrebbe differire leggermente da una versione all’altra perché Rust spesso migliora i messaggi di errore e gli avvertimenti. In altre parole, qualsiasi versione più recente e stabile di Rust che installerai utilizzando questi passaggi dovrebbe funzionare come previsto con il contenuto di questo libro.
Annotazioni per la Riga di Comando
In questo capitolo e in tutto il libro, mostreremo alcuni comandi utilizzati
nel terminale. Le linee che dovresti inserire in un terminale iniziano tutte
con $. Non è necessario digitare il carattere $; è il prompt della riga di
comando mostrato per indicare l’inizio di ogni comando. Le linee che non
iniziano con $ mostrano solitamente l’output del comando precedente.
Inoltre, gli esempi specifici per PowerShell useranno > anziché $.
Installare rustup su Linux o macOS
Se stai usando Linux o macOS, apri un terminale e inserisci il seguente comando:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Il comando scarica uno script e avvia l’installazione dello strumento rustup,
che installa l’ultima versione stabile di Rust. Potrebbe esserti richiesta la
tua password. Se l’installazione ha successo, apparirà la seguente riga:
Rust is installed now. Great!
Avrai anche bisogno di un linker, che è un programma che Rust utilizza per unire i suoi output compilati in un unico file. È probabile che tu ne abbia già uno. Se ottieni errori di linker, dovresti installare un compilatore C, che di solito include un linker. Un compilatore C è utile anche perché alcuni pacchetti comuni di Rust dipendono dal codice C e avranno bisogno di un compilatore C.
Su macOS, puoi ottenere un compilatore C eseguendo:
$ xcode-select --install
Gli utenti Linux dovrebbero generalmente installare GCC o Clang, in base alla
documentazione della loro distribuzione. Ad esempio, se utilizzi Ubuntu, puoi
installare il pacchetto build-essential.
Installare rustup su Windows
Su Windows, vai su https://www.rust-lang.org/tools/install e segui le istruzioni per installare Rust. A un certo punto dell’installazione, ti verrà richiesto di installare Visual Studio, che fornisce un linker e le librerie native necessarie per compilare i programmi. Se hai bisogno di aiuto per questo passaggio, consulta https://rust-lang.github.io/rustup/installation/windows-msvc.html.
Il resto di questo libro utilizza comandi che funzionano sia in cmd.exe che in PowerShell. Se ci sono differenze specifiche, ti spiegheremo quale utilizzare.
Risolvere i Problemi
Per verificare se Rust è stato installato correttamente, apri il terminale e inserisci questo comando:
$ rustc --version
Dovresti vedere il numero di versione, l’hash del commit e la data del commit dell’ultima versione stabile rilasciata, nel seguente formato:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Se vedi queste informazioni, hai installato Rust con successo! Se non vedi
queste informazioni, controlla che Rust sia nella tua variabile di sistema
%PATH% come segue.
Su Windows con CMD, usa:
> echo %PATH%
In PowerShell, usa:
> echo $env:Path
In Linux e macOS, usa:
$ echo $PATH
Se sembra essere tutto in ordine ma Rust non funziona ancora, ci sono diversi posti in cui puoi trovare aiuto. Scopri come metterti in contatto con altri Rustaceani (Rustacean d’ora in poi) (uno stupido soprannome con cui ci chiamiamo) sulla pagina della comunità.
Aggiornare e Disinstallare
Una volta che Rust è stato installato tramite rustup, l’aggiornamento a una
nuova versione è semplice. Dalla tua shell, esegui il seguente script di
aggiornamento:
$ rustup update
Per disinstallare Rust e rustup, esegui il seguente script di disinstallazione
dalla tua shell:
$ rustup self uninstall
Leggere la Documentazione in Locale
L’installazione di Rust include anche una copia locale della documentazione per
poterla leggere offline. Esegui rustup doc per aprire la documentazione locale
nel tuo browser.
Ogni qual volta hai un dubbio su un type o una funzione fornita dalla libreria standard e non sei sicuro di cosa faccia o di come usarla, usa la documentazione delle API per scoprirlo!
Usare Editor di Testo e IDE
Questo libro non fa alcuna ipotesi sugli strumenti che utilizzi per scrivere il codice Rust. Qualsiasi editor di testo è in grado di fare il suo lavoro! Tuttavia, molti editor di testo e IDE (ambienti di sviluppo integrati) hanno un supporto integrato per Rust. Puoi sempre trovare un elenco abbastanza aggiornato di molti editor e IDE nella pagina degli strumenti sul sito web di Rust.
Lavorare Offline con Questo Libro
In diversi esempi, utilizzeremo pacchetti Rust oltre alla libreria standard. Per
lavorare a questi esempi, dovrai disporre di una connessione a internet o aver
scaricato le dipendenze in anticipo. Per scaricare le dipendenze in anticipo,
puoi eseguire i seguenti comandi. (Spiegheremo cos’è cargo e cosa fa ciascuno
di questi comandi in dettaglio più avanti)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
In questo modo i download di questi pacchetti verranno memorizzati nella cache e
non sarà necessario scaricarli in seguito. Una volta eseguito questo comando,
non dovrai conservare la cartella get-dependencies. Se hai eseguito questo
comando, puoi aggiungere il flag --offline quando userai il comando cargo
nel resto del libro per utilizzare queste versioni memorizzate nella cache
invece di scaricarle da internet in quel momento.
Hello, World!
Ora che hai installato Rust, è il momento di scrivere il tuo primo programma
Rust. Quando si impara un nuovo linguaggio, è consuetudine scrivere un piccolo
programma che stampi sullo schermo il testo Hello, world!
Nota: questo libro presuppone una certa familiarità di base con la riga di comando. Rust non ha particolari esigenze per quanto riguarda l’editing o gli strumenti o dove risiede il tuo codice, quindi se preferisci usare IDE invece della riga di comando, sentiti libero di usare il tuo IDE preferito. Molti IDE ora hanno un certo grado di supporto per Rust; controlla la documentazione dell’IDE per maggiori dettagli. Il team di Rust si è concentrato sull’integrazione ottima con gli IDE tramite
rust-analyzer. Vedi Appendice D per maggiori dettagli.
Impostare una Directory dei Progetti
Inizierai creando una directory per memorizzare il tuo codice Rust. Per Rust non è importante dove si trovi il tuo codice, ma per gli esercizi e i progetti di questo libro ti consigliamo di creare una cartella progetti nella tua home directory e di tenere tutti i tuoi progetti lì.
Apri un terminale e inserisci i seguenti comandi per creare una cartella progetti e una cartella per il progetto “Hello, world!” all’interno della directory progetti.
Per Linux, macOS, e PowerShell su Windows, digita questo:
$ mkdir ~/progetti
$ cd ~/progetti
$ mkdir hello_world
$ cd hello_world
Per Windows con CMD, digita questo:
> mkdir "%USERPROFILE%\progetti"
> cd /d "%USERPROFILE%\progetti"
> mkdir hello_world
> cd hello_world
Programma Rust Basilare
Adesso crea un nuovo file sorgente e chiamalo main.rs. I file di Rust terminano sempre con l’estensione .rs. Se usi più di una parola nel nome del file, la convenzione è di usare un trattino basso per separarle. Ad esempio, usa hello_world.rs piuttosto che helloworld.rs.
Ora apri il file main.rs che hai appena creato e inserisci il codice del Listato 1-1.
fn main() { println!("Hello, world!"); }
Hello, world!Salva il file e torna alla finestra del terminale alla cartella ~/progetti/hello_world . Su Linux o macOS, inserisci i seguenti comandi per compilare ed eseguire il file:
$ rustc main.rs
$ ./main
Hello, world!
Su Windows, inserisci il comando .\main invece di ./main:
> rustc main.rs
> .\main
Hello, world!
Indipendentemente dal sistema operativo, la stringa Hello, world! dovrebbe
essere stampata sul terminale. Se non vedi questo output, consulta la sezione
“Risolvere i Problemi” nel capitolo
Installazione per trovare aiuto.
Se Hello, world! è stato stampato, congratulazioni! Hai ufficialmente scritto
un programma Rust. Questo ti rende un programmatore Rust, benvenuto!
Anatomia di un Programma Rust
Esaminiamo in dettaglio questo programma “Hello, world!”. Ecco il primo pezzo del puzzle:
fn main() { }
Queste righe definiscono una funzione chiamata main. La funzione main è
speciale: è sempre il primo codice che viene eseguito in ogni eseguibile Rust.
Qui, la prima riga dichiara una funzione chiamata main che non ha parametri e
non restituisce nulla. Se ci fossero dei parametri, andrebbero dentro le
parentesi (()).
Il corpo della funzione è racchiuso da {}. Rust richiede parentesi graffe
intorno a tutti i corpi delle funzioni. È buona norma posizionare la parentesi
graffa di apertura sulla stessa riga della dichiarazione della funzione,
aggiungendo uno spazio in mezzo.
Nota: se vuoi attenerti a uno stile standard in tutti i progetti Rust, puoi usare uno strumento di formattazione automatica chiamato
rustfmtper formattare il tuo codice in un particolare stile (maggiori informazioni surustfmtin Appendice D). Il team di Rust ha incluso questo strumento nella distribuzione standard di Rust, comerustc, quindi dovrebbe essere già installato sul tuo computer!
Il corpo della funzione main contiene il seguente codice:
#![allow(unused)] fn main() { println!("Hello, world!"); }
Questa riga fa tutto il lavoro di questo piccolo programma: stampa il testo sullo schermo. Ci sono tre dettagli importanti da notare.
Innanzitutto, println! chiama una macro di Rust. Se invece avesse chiamato
una funzione, sarebbe stata inserita come println (senza il !). Le macro di
Rust sono un modo per scrivere codice che genera codice per estendere la
sintassi di Rust e ne parleremo in modo più dettagliato nel Capitolo
20. Per ora, ti basterà sapere che usare una !
significa che stai chiamando una macro invece di una normale funzione e che le
macro non seguono sempre le stesse regole delle funzioni.
In secondo luogo, vedi la stringa "Hello, world!" che viene passata come
argomento a println! e la stringa viene stampata sullo schermo.
In terzo luogo, terminiamo la riga con un punto e virgola (;), che indica che
questa espressione è terminata e che la prossima è pronta per iniziare. La
maggior parte delle righe di codice Rust terminano con un punto e virgola
Compilare ed Eseguire
Hai appena eseguito un programma appena creato, quindi esaminiamo ogni fase del processo.
Prima di eseguire un programma Rust, devi compilarlo con il compilatore Rust
inserendo il comando rustc e passandogli il nome del tuo file sorgente, in
questo modo:
$ rustc main.rs
Se hai un background in C o C++, noterai che è simile a gcc o clang. Dopo
aver compilato con successo, Rust produce un eseguibile binario.
Su Linux, macOS e PowerShell su Windows, puoi vedere l’eseguibile usando il
comando ls nella tua shell:
$ ls
main main.rs
Su Linux e macOS, vedrai due file. Con PowerShell su Windows, vedrai gli stessi tre file che vedresti usando CMD. Con CMD su Windows, inserisci il seguente comando:
> dir /B %= the /B option says to only show the file names =%
main.exe
main.pdb
main.rs
Questo mostra il file del codice sorgente con estensione .rs, il file eseguibile (main.exe su Windows, solo main su tutte le altre piattaforme) e, se usi Windows, un file contenente informazioni di debug con estensione .pdb. Ora puoi eseguire il file main o main.exe, in questo modo:
$ ./main # or .\main su Windows
Se il tuo main.rs è il tuo programma “Hello, world!”, questa riga stampa
Hello, world! sul tuo terminale.
Se hai più familiarità con un linguaggio dinamico, come Ruby, Python o JavaScript, potresti non essere abituato alla compilazione e all’esecuzione di un programma come fasi separate. Rust è un linguaggio compilato in anticipo, il che significa che puoi compilare un programma e dare l’eseguibile a qualcun altro, che potrà eseguirlo anche senza avere Rust installato. Se dai a qualcuno un file .rb, .py o .js, deve avere un’implementazione di Ruby, Python o JavaScript installata (rispettivamente). Ma in questi linguaggi, hai bisogno di un solo comando per compilare ed eseguire il tuo programma. Sono compromessi diversi per ogni linguaggio di programmazione.
La semplice compilazione con rustc va bene per i programmi semplici, ma quando
il tuo progetto cresce, vorrai gestire tutte le opzioni e rendere facile la
condivisione del tuo codice. A seguire, ti presenteremo lo strumento Cargo, che
ti aiuterà a scrivere programmi Rust veri e propri.
Hello, Cargo!
Cargo è il sistema di compilazione e il gestore di pacchetti di Rust. La maggior parte dei Rustacean utilizza questo strumento per gestire i propri progetti Rust perché Cargo gestisce molte attività al posto tuo, come la compilazione del codice, il download delle librerie da cui dipende il tuo codice e la compilazione di tali librerie (chiamiamo le librerie di cui il tuo codice ha bisogno dipendenze)
I programmi Rust più semplici, come quello che abbiamo scritto finora, non hanno dipendenze. Se avessimo costruito il progetto “Hello, world!” con Cargo, questo avrebbe utilizzato solo la parte di Cargo che si occupa della costruzione del codice. Man mano che scriverai programmi Rust più complessi, aggiungerai delle dipendenze e se inizierai un progetto utilizzando Cargo, sarà molto più facile aggiungere dipendenze.
Poiché la stragrande maggioranza dei progetti Rust utilizza Cargo, il resto di questo libro presuppone che anche tu stia utilizzando Cargo. Cargo viene installato insieme a Rust se hai utilizzato l’installazione di cui si parla nella sezione “Installazione”. Se hai installato Rust in altro modo, controlla se Cargo è installato inserendo quanto segue nel tuo terminale:
$ cargo --version
Se viene visualizzato un numero di versione, allora è fatta! Se viene
visualizzato un errore, come ad esempio comando non trovato, consulta la
documentazione relativa al tuo metodo di installazione per determinare come
installare Cargo separatamente.
Creare un Progetto con Cargo
Creiamo un nuovo progetto utilizzando Cargo e vediamo come si differenzia dal nostro progetto originale “Hello, world!“. Torna alla tua cartella progetti (o dove hai deciso di memorizzare il tuo codice). Poi, su qualsiasi sistema operativo, esegui il seguente comando:
$ cargo new hello_cargo
$ cd hello_cargo
Il primo comando crea una nuova cartella e un nuovo progetto chiamato hello_cargo. Abbiamo chiamato il nostro progetto hello_cargo e Cargo crea i suoi file in una cartella con lo stesso nome.
Vai nella cartella hello_cargo ed elenca i file. Vedrai che Cargo ha generato due file e una cartella per noi: un file Cargo.toml e una cartella src con un file main.rs al suo interno.
Ha anche inizializzato un nuovo repository Git insieme a un file .gitignore. I
file Git non verranno generati se esegui cargo new all’interno di un
repository Git esistente; puoi annullare questo comportamento utilizzando cargo new --vcs=git.
Nota: Git è un diffuso software di controllo di versione distribuito. Puoi modificare
cargo newper utilizzare un altro sistema di controllo di versione o nessun sistema di controllo di versioni utilizzando il flag--vcs. Eseguicargo new --helpper vedere le opzioni disponibili.
Apri Cargo.toml nell’editor di testo che preferisci. Dovrebbe assomigliare al codice del Listato 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
cargo newQuesto file è nel formato TOML (Tom’s Obvious, Minimal Language), che è il formato di configurazione di Cargo.
La prima riga, [package], è un’intestazione di sezione che indica che le
dichiarazioni seguenti stanno configurando un pacchetto. Man mano che
aggiungeremo altre informazioni a questo file, aggiungeremo altre sezioni.
Le tre righe successive definiscono le informazioni di configurazione di cui
Cargo ha bisogno per compilare il tuo programma: il nome, la versione e
l’edizione di Rust da utilizzare. Parleremo della chiave edition in Appendice
E.
L’ultima riga, [dependencies], è l’inizio di una sezione in cui puoi elencare
tutte le dipendenze del tuo progetto. In Rust, i pacchetti di codice sono
chiamati crates (inteso come cassetta, contenitore…). Non avremo bisogno di
altri crates per questo progetto, ma lo faremo nel primo progetto del Capitolo
2, quindi useremo questa sezione di dipendenze.
Ora apri src/main.rs e dai un’occhiata:
File: src/main.rs
fn main() { println!("Hello, world!"); }
Cargo ha generato per te un programma “Hello, world!”, proprio come quello che abbiamo scritto nel Listato 1-1! Finora, le differenze tra il nostro progetto e quello generato da Cargo sono che Cargo ha inserito il codice nella cartella src, e che c’è un file di configurazione Cargo.toml nella directory principale.
Cargo si aspetta che i tuoi file sorgente si trovino all’interno della cartella src. La directory principale del progetto è solo per i file README, le informazioni sulla licenza, i file di configurazione e tutto ciò che non riguarda il tuo codice. L’utilizzo di Cargo ti aiuta a organizzare i tuoi progetti: c’è un posto per ogni cosa e ogni cosa è al suo posto.
Se hai iniziato un progetto che non utilizza Cargo, come abbiamo fatto con il
progetto “Hello, world!”, puoi convertirlo in un progetto che utilizza Cargo.
Sposta il codice del progetto nella cartella src e crea un file Cargo.toml
appropriato. Un modo semplice per ottenere il file Cargo.toml è eseguire
cargo init, che lo creerà automaticamente.
Costruire e Eseguire un Progetto Cargo
Ora vediamo cosa cambia quando costruiamo ed eseguiamo il programma “Hello, world!” con Cargo! Dalla cartella hello_cargo, costruisci il tuo progetto inserendo il seguente comando:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///progetti/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Questo comando crea un file eseguibile in target/debug/hello_cargo (o target\debug\hello_cargo.exe_ su Windows) anziché nella tua cartella corrente. Poiché la compilazione predefinita è una compilazione di debug, Cargo mette il binario in una cartella chiamata debug. Puoi eseguire l’eseguibile con questo comando:
$ ./target/debug/hello_cargo # o .\target\debug\hello_cargo.exe su Windows
Hello, world!
Se tutto è andato bene, Hello, world! dovrebbe essere stampato sul terminale.
L’esecuzione di cargo build per la prima volta fa sì che Cargo crei anche un
nuovo file nella directory principale: Cargo.lock. Questo file tiene traccia
delle versioni esatte delle dipendenze nel tuo progetto. Questo progetto non ha
dipendenze, quindi il file è un po’ scarno. Non dovrai mai modificare questo
file manualmente; Cargo gestisce il suo contenuto per te.
Abbiamo appena costruito un progetto con cargo build e lo abbiamo eseguito con
./target/debug/hello_cargo, ma possiamo anche usare cargo run per compilare
il codice e poi eseguire l’eseguibile risultante con un solo comando:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Utilizzare cargo run è più comodo che doversi ricordare di eseguire cargo build e poi utilizzare l’intero percorso del binario, quindi la maggior parte
degli sviluppatori utilizza cargo run.
Nota che questa volta non abbiamo visto l’output che indicava che Cargo stava
compilando hello_cargo. Cargo ha capito che i file non erano cambiati, quindi
non ha ricostruito ma ha semplicemente eseguito il binario. Se avessi modificato
il codice sorgente, Cargo avrebbe ricostruito il progetto prima di eseguirlo e
avresti visto questo output:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///progetti/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo offre anche un comando chiamato cargo check, che controlla rapidamente
il tuo codice per assicurarsi che venga compilato ma che non produce un
eseguibile:
$ cargo check
Checking hello_cargo v0.1.0 (file:///progetti/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
E perché non dovresti volere un eseguibile? Spesso, cargo check è molto più
veloce di cargo build perché salta il passaggio della produzione di un
eseguibile. Se controlli continuamente il tuo lavoro mentre scrivi il codice,
l’uso di cargo check accelererà il processo di sapere se il tuo progetto è
privo di errori e compilabile! Per questo motivo, molti Rustacean eseguono
cargo check periodicamente mentre scrivono il loro programma per assicurarsi
che si compili. Poi eseguono cargo build quando sono pronti a creare
l’eseguibile.
Ricapitoliamo quello che abbiamo imparato finora su Cargo:
- Possiamo creare un progetto utilizzando
cargo new. - Possiamo costruire un progetto utilizzando
cargo build. - Possiamo costruire ed eseguire un progetto in un unico passaggio utilizzando
cargo run. - Possiamo costruire un progetto senza produrre un binario per controllare gli
errori utilizzando
cargo check. - Invece di salvare il risultato della compilazione nella stessa directory del nostro codice, Cargo lo salva nella directory target/debug.
Un ulteriore vantaggio dell’utilizzo di Cargo è che i comandi sono gli stessi indipendentemente dal sistema operativo su cui stai lavorando. Quindi, a questo punto, non forniremo più istruzioni specifiche per Linux e macOS rispetto a Windows.
Costruire per il Rilascio
Quando il tuo progetto è finalmente pronto per essere rilasciato, puoi usare
cargo build --release per compilarlo con le ottimizzazioni. Questo comando
creerà un eseguibile in target/release invece che in target/debug. Le
ottimizzazioni rendono il tuo codice Rust più veloce, ma attivarle allunga i
tempi di compilazione del tuo programma. Per questo motivo esistono due profili
diversi: uno per lo sviluppo, quando vuoi ricostruire rapidamente e spesso, e un
altro per la creazione del programma finale che darai a un utente e che non sarà
ricostruito più volte e che funzionerà il più velocemente possibile. Se vuoi
fare un benchmark del tempo di esecuzione del tuo codice, assicurati di eseguire
cargo build --release e di fare il benchmark con l’eseguibile in
target/release.
Sfruttare Le Convenzioni di Cargo
Con i progetti semplici, Cargo non offre molti vantaggi rispetto all’uso di
rustc, ma si dimostrerà utile quando i tuoi programmi diventeranno più
complessi. Quando i programmi diventano più file o hanno bisogno di una
dipendenza, è molto più facile lasciare che Cargo coordini la compilazione.
Anche se il progetto hello_cargo è semplice, ora utilizza gran parte degli
strumenti che userai nel resto della tua carriera in Rust. Infatti, per lavorare
su qualsiasi progetto esistente, puoi usare i seguenti comandi per verificare il
codice usando Git, passare alla directory del progetto e compilare:
$ git clone example.org/un_progetto_nuovo
$ cd un_progetto_nuovo
$ cargo build
Per maggiori informazioni su Cargo, consulta la documentazione.
Riepilogo
Sei già partito alla grande nel tuo viaggio assieme a Rust! In questo capitolo hai imparato a..:
- Installare l’ultima versione stabile di Rust usando
rustup. - Aggiornare a una versione più recente di Rust.
- Aprire la documentazione installata localmente.
- Scrivere ed eseguire un programma “Hello, world!” usando direttamente
rustc. - Creare ed eseguire un nuovo progetto usando le convenzioni di Cargo.
Questo è un ottimo momento per costruire un programma più sostanzioso per abituarsi a leggere e scrivere codice in Rust. Quindi, nel Capitolo 2, costruiremo un programma di gioco di indovinelli. Se invece preferisci iniziare imparando come funzionano in Rust alcuni concetti base della programmazione, consulta il Capitolo 3 e poi ritorna al Capitolo 2.
Programmare un Gioco di Indovinelli
Cominciamo a programmare in Rust lavorando insieme a un progetto pratico! Questo
capitolo ti introduce ad alcuni concetti comuni di Rust mostrandoti come
utilizzarli in un programma reale. Imparerai a conoscere let, match, metodi,
funzioni associate, crates esterni e molto altro ancora! Nei capitoli
successivi esploreremo queste idee in modo più dettagliato, mentre in questo
capitolo ti limiterai a mettere in pratica le nozioni fondamentali.
Implementeremo un classico problema di programmazione per principianti: un gioco di indovinelli. Ecco come funziona: il programma genererà un numero intero casuale compreso tra 1 e 100. Poi chiederà al giocatore di inserire un’ipotesi. Dopo aver inserito un’ipotesi, il programma indicherà se l’ipotesi è troppo bassa o troppo alta. Se l’ipotesi è corretta, il gioco stamperà un messaggio di congratulazioni e terminerà.
Impostare un Nuovo Progetto
Per creare un nuovo progetto, vai nella cartella progetti che hai creato nel Capitolo 1 e crea un nuovo progetto con Cargo, in questo modo:
$ cargo new gioco_indovinello
$ cd gioco_indovinello
Il primo comando, cargo new, prende il nome del progetto (gioco_indovinello)
come primo argomento. Il secondo comando entra nella directory del nuovo
progetto.
Diamo un’occhiata al file Cargo.toml appena generato:
File: Cargo.toml
[package]
name = "gioco_indovinello"
version = "0.1.0"
edition = "2024"
[dependencies]
Come hai visto nel Capitolo 1, cargo new genera per te un programma “Hello,
world!”. Guarda il file src/main.rs:
File: src/main.rs
fn main() { println!("Hello, world!"); }
Ora compiliamo questo programma “Hello, world!” ed eseguiamolo nello stesso
passaggio utilizzando il comando cargo run:
$ cargo run
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.33s
Running `target/debug/gioco_indovinello`
Hello, world!
Il comando run è utile quando hai bisogno di iterare rapidamente su un
progetto, come faremo in questo gioco, testando velocemente ogni modifica prima
di passare alla successiva.
Riapri il file src/main.rs. In questo file scriverai tutto il codice.
Elaborare un’Ipotesi
La prima parte del programma del gioco di indovinelli richiederà l’input dell’utente, lo elaborerà e verificherà che l’input sia nella forma prevista. Per iniziare, permetteremo al giocatore di inserire un’ipotesi. Inserisci il codice del Listato 2-1 in src/main.rs.
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Questo codice contiene molte informazioni, quindi analizziamolo riga per riga.
Per ottenere l’input dell’utente e poi stampare il risultato come output,
dobbiamo utilizzare il modulo di input/output io. Il modulo io proviene
dalla libreria standard, nota come std:
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Come impostazione predefinita, Rust ha un insieme di risorse definite nella libreria standard che vengono inserite in ogni programma. Questo insieme è chiamato preludio (prelude d’ora in poi) e puoi vedere tutto ciò che contiene nella documentazione della libreria standard.
Se una risorsa che vuoi utilizzare non è presente nel prelude, devi renderla
disponibile esplicitamente con un’istruzione use. L’utilizzo del modulo
std::io ti offre una serie di utili funzioni, tra cui la possibilità di
ricevere input dall’utente.
Come hai visto nel Capitolo 1, la funzione main è il punto di ingresso del
programma:
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}La sintassi fn dichiara una nuova funzione; le parentesi, (), indicano che
non ci sono parametri; e la parentesi graffa, {, inizia il corpo della
funzione.
Come hai imparato nel Capitolo 1, println! è una macro che stampa una
stringa sullo schermo:
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Questo codice stampa un messaggio che introduce il gioco e richiede un input da parte dell’utente.
Memorizzare i Valori con le Variabili
Successivamente, creeremo una variabile per memorizzare l’input dell’utente, in questo modo:
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Ora il programma si fa interessante! In questa piccola riga succedono molte
cose. Usiamo l’istruzione let per creare la variabile. Ecco un altro esempio:
let mele = 5;Questa riga crea una nuova variabile di nome mele e la lega al valore 5. In
Rust, le variabili sono immutabili (immutable) come impostazione predefinita,
il che significa che una volta assegnato un valore alla variabile, il valore non
cambierà. Parleremo di questo concetto in dettaglio nella sezione “Variabili e
mutabilità” del Capitolo 3. Per
rendere mutabile (mutable) una variabile, aggiungiamo mut prima del nome
della variabile:
let mele = 5; // immutabile
let mut banane = 5; // mutabileNota: la sintassi
//inizia un commento che continua fino alla fine della riga. Rust ignora tutto ciò che è contenuto nei commenti. Parleremo dei commenti in modo più dettagliato nel Capitolo 3.
Torniamo al nostro gioco di indovinelli. Ora sai che let mut ipotesi
introdurrà una variabile mutabile di nome ipotesi. Il segno di uguale (=)
indica a Rust che vogliamo legare qualcosa alla variabile in quel momento. A
destra del segno di uguale c’è il valore a cui ipotesi è legata, che è il
risultato della chiamata a String::new, una funzione che restituisce una nuova
istanza di una String. String è un type di
stringa fornito dalla libreria standard che è un pezzo di testo codificato UTF-8
modificabile in lunghezza.
La sintassi :: nella riga ::new indica che new è una funzione associata al
type String. Una funzione associata è una funzione implementata su un
type, in questo caso String. Questa funzione new crea una nuova stringa
vuota. Troverai una funzione new in molti type perché è un nome comune per
una funzione che crea un nuovo valore di qualche tipo.
In pratica, la linea let mut ipotesi = String::new(); ha creato una variabile
mutable che è attualmente legata a una nuova istanza vuota di String. Wow!
Ricevere l’Input dell’Utente
Ricordiamo che abbiamo incluso le funzionalità di input/output della libreria
standard con use std::io; nella prima riga del programma. Ora chiameremo la
funzione stdin dal modulo io, che ci permetterà di gestire l’input
dell’utente:
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Se non avessimo importato il modulo io con use std::io; all’inizio del
programma, potremmo comunque utilizzare la funzione scrivendo questa chiamata di
funzione come std::io::stdin. La funzione stdin restituisce un’istanza di
std::io::Stdin, che è un type che rappresenta un
handle all’input standard del tuo terminale.
Successivamente, la riga .read_line(&mut ipotesi) chiama il metodo
read_line sull’handle di input standard per
ottenere un input dall’utente. Passiamo anche &mut ipotesi come argomento a
read_line per dirgli in quale stringa memorizzare l’input dell’utente. Il
compito di read_line è quello di prendere tutto ciò che l’utente digita
nell’input standard e aggiungerlo a una stringa (senza sovrascriverne il
contenuto), quindi passiamo tale stringa come argomento. L’argomento stringa
deve essere mutable in modo che il metodo possa cambiare il contenuto della
stringa.
Il simbolo & indica che questo argomento è un riferimento (reference d’ora
in poi), il che ti dà la possibilità di permettere a più parti del codice di
accedere a un dato senza doverlo copiare più volte in memoria. I reference
sono una funzionalità complessa e uno dei principali vantaggi di Rust è la
sicurezza e la facilità con cui è possibile utilizzarli. Non hai bisogno di
conoscere molti di questi dettagli per finire questo programma. Per ora, tutto
ciò che devi sapere è che, come le variabili, i reference sono immutabili come
impostazione predefinita. Di conseguenza, devi scrivere &mut ipotesi piuttosto
che solo &ipotesi per renderli mutable (il Capitolo 4 spiegherà i
reference in modo più approfondito)
Gestire i Potenziali Errori con Result
Stiamo ancora lavorando su questa riga di codice. Ora stiamo discutendo di una terza riga di testo, ma notiamo che fa ancora parte di un’unica riga logica di codice. La prossima parte è questo metodo:
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Avremmo potuto scrivere questo codice come:
io::stdin().read_line(&mut ipotesi).expect("Errore di lettura");Tuttavia, una riga lunga può essere difficile da leggere, quindi è meglio
dividerla. Spesso è consigliabile andare a capo e aggiungere degli spazi bianchi
per aiutare a spezzare le righe lunghe quando chiami un metodo con la sintassi
.nome_metodo(). Ora vediamo cosa fa questa riga.
Come accennato in precedenza, read_line inserisce qualsiasi cosa l’utente
inserisca nella stringa che gli passiamo, ma restituisce anche un valore
Result. Result è una enumerazione (enum per brevità), che è un type che può trovarsi in uno dei
molteplici stati possibili. Chiamiamo ogni stato possibile una variante.
Il Capitolo 6 tratterà le enum in modo più
dettagliato. Lo scopo di questi type Result è quello di fornire informazioni
sulla gestione degli errori.
Le varianti di Result sono Ok e Err. La variante Ok indica che
l’operazione è andata a buon fine e contiene il valore generato con successo. La
variante Err indica che l’operazione non è andata a buon fine e contiene
informazioni su come o perché l’operazione è fallita.
I valori del tipo Result, come i valori di qualsiasi type, hanno dei metodi
definiti su di essi. Un’istanza di Result ha un metodo expect che puoi chiamare. Se questa istanza di Result è un valore Err,
expect causerà l’arresto del programma e visualizzerà il messaggio che hai
passato come argomento a expect. Se il metodo read_line restituisce un
Err, è probabile che sia il risultato di un errore proveniente dal sistema
operativo sottostante. Se questa istanza di Result è un valore Ok, expect
prenderà il valore di ritorno che Ok sta tenendo e ti restituirà solo quel
valore in modo che tu possa usarlo. In questo caso, quel valore è il numero di
byte nell’input dell’utente.
Se non chiami expect, il programma verrà compilato, ma riceverai un avviso:
$ cargo build
Compiling gioco_indovinello v0.1.0 (file:///pregetti/gioco_indovinello)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut ipotesi);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut ipotesi);
| +++++++
warning: `gioco_indovinello` (bin "gioco_indovinello") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.29s
Rust avverte che non è stato utilizzato il valore Result restituito da
read_line, indicando che il programma non ha gestito un possibile errore.
Il modo corretto per sopprimere l’avvertimento è quello di scrivere del codice
che gestisca questi potenziali errori, ma nel nostro caso non è un grosso
problema mandare in crash il programma quando si verifica un problema, quindi
possiamo usare expect. Imparerai a recuperare dagli errori nel Capitolo
9.
Stampare i Valori con i Segnaposto in println!
A parte la parentesi graffa di chiusura, c’è un’ultima riga da discutere nel codice:
use std::io;
fn main() {
println!("Indovina il numero!");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Questa riga stampa la stringa che ora contiene l’input dell’utente. La serie di
parentesi graffe {} è un segnaposto: pensa a {} come a delle piccole chele
di granchio che tengono fermo un valore. Quando stampi il valore di una
variabile, il nome della variabile può essere inserito all’interno delle
parentesi graffe. Quando devi stampare il risultato della valutazione di
un’espressione, inserisci delle parentesi graffe vuote nella stringa di formato,
quindi fai seguire alla stringa di formato un elenco separato da virgole di
espressioni da stampare in ogni segnaposto vuoto, nello stesso ordine. Stampare
una variabile e il risultato di un’espressione in un’unica chiamata a println!
sarebbe così:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} e y + 2 = {}", y + 2); }
Questo codice produrrà x = 5 e y + 2 = 12.
Proviamo la Prima Parte
Proviamo la prima parte del gioco di indovinelli utilizzando cargo run:
$ cargo run
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.40s
Running `target/debug/gioco_indovinello`
Indovina il numero!
Inserisci la tua ipotesi.
6
Hai ipotizzato: 6
A questo punto, la prima parte del gioco è terminata: stiamo ricevendo input dalla tastiera e poi li stiamo stampando.
Generare un Numero Segreto
Ora dobbiamo generare un numero segreto che l’utente cercherà di indovinare. Il
numero segreto dovrebbe essere diverso ogni volta, in modo da rendere il gioco
divertente più di una volta. Utilizzeremo un numero casuale compreso tra 1 e
100, in modo che il gioco non sia troppo difficile. Rust non include ancora la
funzionalità dei numeri casuali nella sua libreria standard, ma il team di Rust
fornisce un crate rand con tale funzionalità.
Aumentare le Funzionalità con un Crate
Ricorda che un crate è una raccolta di file di codice sorgente in Rust. Il
progetto che stiamo costruendo è un crate binario, cioè un eseguibile. Il
crate rand è un crate libreria, che contiene codice destinato a essere
utilizzato in altri programmi e non può essere eseguito da solo.
Prima di poter scrivere del codice che utilizzi rand, dobbiamo modificare il
file Cargo.toml per includere il crate rand come dipendenza. Apri il file
e aggiungi la seguente riga in fondo, sotto l’intestazione della sezione delle
dipendenze [dependencies] che Cargo ha creato per te. Assicurati di
specificare rand esattamente come abbiamo fatto qui, con questo numero di
versione, altrimenti gli esempi di codice di questo tutorial potrebbero non
funzionare:
File: Cargo.toml
[dependencies]
rand = "0.8.5"
Nel file Cargo.toml, tutto ciò che segue un’intestazione fa parte di quella
sezione che continua fino all’inizio di un’altra sezione. In [dependencies],
indichi a Cargo quali sono i crate esterni da cui dipende il tuo progetto e
quali sono le versioni di tali crate richieste. In questo caso, specifichiamo
il crate rand con lo specificatore di versione semantica 0.8.5. Cargo
comprende il Versionamento Semantico (a volte chiamato
SemVer per brevità), che è uno standard per la scrittura dei numeri di
versione. Lo specificatore 0.8.5 è in realtà un’abbreviazione di ^0.8.5, che
indica qualsiasi versione che sia almeno 0.8.5 ma inferiore a 0.9.0.
Cargo considera queste versioni con API pubbliche compatibili con la versione 0.8.5 e questa specifica ti garantisce di ottenere l’ultima release della patch che si compila ancora con il codice di questo capitolo. Qualsiasi versione 0.9.0 o superiore non garantisce di avere le stesse API utilizzate negli esempi seguenti.
Ora, senza modificare alcun codice, costruiamo il progetto, come mostrato nel Listato 2-2.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
cargo build dopo l’aggiunta del crate rand come dipendenzaPotresti vedere numeri di versione diversi (ma saranno tutti compatibili con il codice, grazie a SemVer!) e righe diverse (a seconda del sistema operativo) e le righe potrebbero essere in un ordine diverso.
Quando includiamo una dipendenza esterna, Cargo recupera le ultime versioni di tutto ciò di cui la dipendenza ha bisogno dal registro, registry, che è una copia dei dati di Crates.io. Crates.io è il sito in cui le persone che fanno parte dell’ecosistema Rust pubblicano i loro progetti Rust open source che possono essere utilizzati da altri.
Dopo aver aggiornato il registro, Cargo controlla la sezione [dependencies] e
scarica tutti i crate elencati che non sono già stati scaricati. In questo
caso, anche se abbiamo elencato solo rand come dipendenza, Cargo ha preso
anche altri crate da cui rand dipende per funzionare. Dopo aver scaricato i
crate, Rust li compila e poi compila il progetto con le dipendenze
disponibili.
Se esegui immediatamente cargo build di nuovo senza apportare alcuna modifica,
non otterrai alcun risultato a parte la riga Finished. Cargo sa che ha già
scaricato e compilato le dipendenze e che non hai modificato nulla nel tuo file
Cargo.toml. Cargo sa anche che non hai modificato nulla del tuo codice, quindi
non ricompila nemmeno quello. Non avendo nulla da fare, semplicemente termina
l’esecuzione.
Se apri il file src/main.rs, apporti una modifica banale e poi salvi e ricostruisci, vedrai solo due righe di output:
$ cargo build
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Queste righe mostrano che Cargo ricompila solo le modifiche, il file src/main.rs. Le dipendenze non sono cambiate, quindi Cargo sa di poter riutilizzare ciò che ha già scaricato e compilato in precedenza.
Garantire Build Riproducibili
Cargo ha un meccanismo che ti garantisce di ricostruire lo stesso artefatto ogni
volta che tu o chiunque altro costruisce il tuo codice: Cargo utilizzerà solo le
versioni delle dipendenze che hai specificato fino a quando non indicherai il
contrario. Per esempio, supponiamo che la prossima settimana esca la versione
0.8.6 del crate rand, che contiene un’importante correzione di un bug, ma
anche una regressione incompatibile con il tuo codice. Per gestire questo
problema, Rust crea il file Cargo.lock la prima volta che esegui cargo build, che quindi ora si trova nella directory gioco_indovinello.
Quando costruisci un progetto per la prima volta, Cargo calcola tutte le versioni delle dipendenze che soddisfano i criteri e le scrive nel file Cargo.lock. Quando costruisci il tuo progetto in futuro, Cargo vedrà che il file Cargo.lock esiste e userà le versioni specificate in esso, invece di fare tutto il lavoro per trovare di nuovo le versioni. In altre parole, il tuo progetto rimarrà alla versione 0.8.5 fino a quando non effettuerai un aggiornamento esplicito, grazie al file Cargo.lock. Poiché il file Cargo.lock è importante per la creazione di build riproducibili, spesso viene inserito nel controllo sorgente insieme al resto del codice del progetto.
Aggiornare un Crate per Ottenere una Nuova Versione
Quando vuoi aggiornare un crate, Cargo mette a disposizione il comando
update, che ignorerà il file Cargo.lock e troverà tutte le ultime versioni
che corrispondono alle tue specifiche in Cargo.toml. Cargo scriverà quindi
queste versioni nel file Cargo.lock. Altrimenti, di default, Cargo cercherà
solo le versioni maggiori di 0.8.5 e minori di 0.9.0. Se il crate rand ha
rilasciato nuove versioni sia per la versione 0.8 che per la 0.9, vedrai quanto
segue se eseguirai cargo update:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.9.0)
Cargo ignora la versione 0.9.0. A questo punto, noterai anche un cambiamento nel
tuo file Cargo.lock che indica che la versione del crate rand che stai
utilizzando è la 0.8.6. Per utilizzare la versione 0.9.0 di rand o qualsiasi
altra versione della serie 0.9.x, dovrai aggiornare il file Cargo.toml in
questo modo:
[dependencies]
rand = "0.9.0"
La prossima volta che eseguirai cargo build, Cargo aggiornerà il registro dei
crate disponibili e rivaluterà i requisiti di rand in base alla nuova
versione che hai specificato.
C’è molto altro da dire su Cargo e sul suo ecosistema, di cui parleremo nel Capitolo 14, ma per ora questo è tutto ciò che devi sapere. Cargo rende molto facile il riutilizzo delle librerie, per cui i Rustacean sono in grado di scrivere progetti più piccoli che sono assemblati da una serie di pacchetti.
Generare un Numero Casuale
Iniziamo a usare rand per generare un numero da indovinare. Il passo
successivo è aggiornare src/main.rs, come mostrato nel Listato 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Per prima cosa aggiungiamo la riga use rand::Rng;. Il trait Rng definisce
i metodi che i generatori di numeri casuali implementano e questo trait deve
essere nell’ambito di utilizzo (in scope d’ora in poi), per poter utilizzare
tali metodi. Il Capitolo 10 tratterà in dettaglio i trait.
Nella prima riga, chiamiamo la funzione rand::thread_rng che ci fornisce il
particolare generatore di numeri casuali che utilizzeremo: un generatore locale
che si appoggia al sistema operativo. Poi chiamiamo il metodo gen_range sul
generatore di numeri casuali. Questo metodo è definito dal trait Rng che
abbiamo portato in scope con l’istruzione use rand::Rng;. Il metodo
gen_range prende un’espressione di intervallo come argomento e genera un
numero casuale nell’intervallo. Il tipo di espressione di intervallo che stiamo
usando qui ha la forma inizio..=fine ed è inclusivo dei limiti inferiore e
superiore, quindi dobbiamo specificare 1..=100 per richiedere un numero
compreso tra 1 e 100.
Nota: non sarai sempre a conoscenza di quali trait utilizzare e quali metodi e funzioni chiamare di un crate, quindi ogni crate ha una documentazione con le istruzioni per utilizzarlo. Un’altra caratteristica interessante di Cargo è che eseguendo il comando
cargo doc --open, la documentazione fornita da tutte le tue dipendenze viene creata localmente e aperta nel browser. Se sei interessato ad altre funzionalità del craterand, ad esempio, eseguicargo doc --opene clicca surandnella barra laterale a sinistra.
La seconda nuova riga stampa il numero segreto. Questo è utile durante lo sviluppo del programma per poterlo testare, ma lo elimineremo dalla versione finale. Non è un grande gioco se il programma stampa la risposta non appena inizia!
Prova a eseguire il programma alcune volte:
$ cargo run
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/gioco_indovinello`
Indovina il numero!
Il numero segreto è: 7
Inserisci la tua ipotesi.
4
Hai ipotizzato: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/gioco_indovinello`
Indovina il numero!
Il numero segreto è: 83
Inserisci la tua ipotesi.
5
Hai ipotizzato: 5
Dovresti ottenere diversi numeri casuali, tutti compresi tra 1 e 100. Ottimo lavoro!
Confrontare l’Ipotesi con il Numero Segreto
Ora che abbiamo l’input dell’utente e un numero casuale, possiamo confrontarli. Questo passo è mostrato nel Listato 2-4. Nota che questo codice non è compilabile per il momento, come spiegheremo.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --taglio--
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => println!("Hai indovinato!"),
}
}Per prima cosa aggiungiamo un’altra istruzione use, che porta un type
chiamato std::cmp::Ordering dalla libreria standard. Il type Ordering è
un’altra enum e ha le varianti Less, Greater e Equal. Questi sono i tre
risultati possibili quando si confrontano due valori.
Poi aggiungiamo cinque nuove righe in basso che utilizzano il type Ordering.
Il metodo cmp confronta due valori e può essere richiamato su qualsiasi cosa
possa essere confrontata. Come parametro prende un reference a qualsiasi cosa
si voglia confrontare: in questo caso sta confrontando ipotesi con
numero_segreto. Poi restituisce una variante dell’enum Ordering che
abbiamo portato nello scope con l’istruzione use. Utilizziamo un’espressione
match per decidere cosa fare successivamente in base a
quale variante di Ordering è stata restituita dalla chiamata a cmp con i
valori in ipotesi e numero_segreto.
Un’espressione match è composta da due rami. Da una parte un pattern su
cui fare il confronto, dall’altra il codice da eseguire se il valore dato a
match corrisponde al pattern. Rust prende il valore dato a match e lo
confronta con il _ pattern_ dei vari rami, eseguendo poi il codice se
corrispondono. I pattern e il costrutto match sono potenti caratteristiche
di Rust: ti permettono di esprimere una varietà di situazioni in cui il tuo
codice potrebbe imbattersi e ti assicurano di gestirle tutte. Queste
caratteristiche saranno trattate in dettaglio nel Capitolo 6 e nel Capitolo 19,
rispettivamente.
Facciamo un esempio con l’espressione match che utilizziamo qui. Supponiamo
che l’utente abbia ipotizzato 50 e che il numero segreto generato in modo
casuale questa volta sia 38.
Quando il codice confronta 50 con 38, il metodo cmp restituirà
Ordering::Greater perché 50 è maggiore di 38. L’espressione match ottiene il
valore Ordering::Greater e inizia a controllare il pattern di ciascun ramo.
Esamina il pattern del primo ramo, Ordering::Less, e vede che il valore
Ordering::Greater non corrisponde a Ordering::Less, quindi ignora il codice
in quel ramo e passa al ramo successivo. Il modello del ramo successivo è
Ordering::Greater, che corrisponde a Ordering::Greater! Il codice
associato in quel ramo verrà eseguito e stamperà Troppo grande! sullo schermo.
L’espressione match termina dopo la prima corrispondenza riuscita, quindi non
esaminerà l’ultimo ramo in questo scenario.
Tuttavia, il codice del Listato 2-4 non viene compilato. Proviamo:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&numero_segreto) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/4eb161250e340c8f48f66e2b929ef4a5bed7c181/library/core/src/cmp.rs:964:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `gioco_indovinello` (bin "gioco_indovinello") due to 1 previous error
Il messaggio di errore afferma che ci sono mismatched types (type non
corrispondenti). Rust ha un sistema di type forte e statico. Tuttavia, ha
anche l’inferenza del type. Quando abbiamo scritto let mut ipotesi = String::new(), Rust è stato in grado di dedurre che ipotesi doveva essere un
String e non ci ha fatto scrivere il type. Il numero_segreto, d’altra
parte, è un type numerico. Alcuni type numerici di Rust possono avere un
valore compreso tra 1 e 100: i32, un numero a 32 bit; u32, un numero a 32
bit senza segno; i64, un numero a 64 bit; e altri ancora. Se non diversamente
specificato, Rust imposta come predefinito un i32, che è il type di
numero_segreto a meno che non si aggiungano informazioni sul type altrove
che indurrebbero Rust a dedurre un type numerico differente. Il motivo
dell’errore è che Rust non può confrontare una type stringa e un type
numerico.
In definitiva, vogliamo convertire la String che il programma legge come input
in un type numerico in modo da poterlo confrontare numericamente con il numero
segreto. Lo facciamo aggiungendo questa riga al corpo della funzione main:
File: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
println!("Inserisci la tua ipotesi.");
// --taglio--
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: u32 = ipotesi.trim().parse().expect("Inserisci un numero!");
println!("Hai ipotizzato: {ipotesi}");
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => println!("Hai indovinato!"),
}
}La riga è:
let ipotesi: u32 = ipotesi.trim().parse().expect("Inserisci un numero!");Creiamo una variabile di nome ipotesi. Ma aspetta, il programma non ha già una
variabile di nome ipotesi? Sì, ma Rust ci permette di oscurare, il valore
precedente di ipotesi con uno nuovo. Lo Shadowing ci permette di
riutilizzare il nome della variabile ipotesi invece di costringerci a creare
due variabili uniche, come ipotesi_str e ipotesi, per esempio. Ne parleremo
in modo più dettagliato nel Capitolo 3, ma per ora,
sappi che questa funzione è spesso usata quando vuoi convertire un valore da un
type ad un altro.
Leghiamo questa nuova variabile all’espressione ipotesi.trim().parse().
L’ipotesi nell’espressione si riferisce alla variabile ipotesi originale che
contiene l’input come stringa. Il metodo trim su un’istanza di String
elimina ogni spazio bianco ad inizio e fine, cosa da fare prima di convertire la
stringa in u32, che può contenere solo dati numerici. L’utente deve premere
invio per confermare l’input da terminale e questo aggiunge un
carattere nuova_linea (newline d’ora in poi) alla stringa letta da
read_line. Per esempio, se l’utente digita 5 e poi preme
invio, ipotesi conterrà: 5\n. Il carattere \n rappresenta
newline. (Su Windows, premere invio aggiunge anche il carattere di
ritorno a capo oltre a newline, risultando in \r\n.) Il metodo trim
elimina sia \n che \r\n, restituendo quindi solo 5.
Il metodo parse sulle stringhe converte una stringa in
un altro type. In questo caso, lo usiamo per convertire una stringa in un
numero. Dobbiamo indicare a Rust il tipo esatto di numero che vogliamo usando
let ipotesi: u32. I due punti (:) dopo ipotesi dicono a Rust che
annoteremo il tipo di variabile. Rust ha alcuni type numerici incorporati;
u32 visto qui è un intero a 32 bit senza segno. È una buona scelta predefinita
per un piccolo numero positivo. Imparerai a conoscere altri type numerici
Capitolo 3.
Inoltre, l’annotazione u32 in questo programma di esempio e il confronto con
numero_segreto significa che Rust dedurrà che anche numero_segreto dovrebbe
essere un u32. Quindi ora il confronto sarà tra due valori con lo stesso
type!
Il metodo parse funziona solo su caratteri che possono essere convertiti
logicamente in numeri e quindi può facilmente causare errori. Se, ad esempio, la
stringa contenesse A👍%, non ci sarebbe modo di convertirla in un numero.
Poiché potrebbe fallire, il metodo parse restituisce un type Result,
proprio come fa il metodo read_line (discusso in precedenza in “Gestire i
Potenziali Errori con Result”). Tratteremo questo Result allo stesso modo utilizzando nuovamente
il metodo expect. Se parse restituisce una variante Err perché non è
riuscito a creare un numero dalla stringa, la chiamata expect causerà il crash
del gioco e stamperà il messaggio che gli abbiamo fornito. Se parse riesce a
convertire la stringa in un numero, restituirà la variante Ok di Result e
expect restituirà il numero che vogliamo dal valore Ok.
Ora eseguiamo il programma:
$ cargo run
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/gioco_indovinello`
Indovina il numero!
Il numero segreto è: 58
Inserisci la tua ipotesi.
76
Hai ipotizzato: 76
Troppo grande!
Bene! Anche se sono stati aggiunti degli spazi prima del numero, il programma ha capito che l’utente aveva ipotizzato 76. Esegui il programma alcune volte per verificare il diverso comportamento con diversi tipi di input: ipotizzare il numero corretto, ipotizzare un numero troppo alto e ipotizzare un numero troppo basso.
Ora la maggior parte del gioco funziona, ma l’utente può fare una sola ipotesi. Cambiamo questa situazione aggiungendo un ciclo!
Consentire Più Ipotesi con la Ripetizione
La parola chiave loop (ripetizione) crea un ciclo infinito. Aggiungeremo un
ciclo per dare agli utenti più possibilità di indovinare il numero:
File: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
// --taglio--
println!("Il numero segreto è: {numero_segreto}");
loop {
println!("Inserisci la tua ipotesi.");
// --taglio--
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: u32 = ipotesi.trim().parse().expect("Inserisci un numero!");
println!("Hai ipotizzato: {ipotesi}");
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => println!("Hai indovinato!"),
}
}
}Come puoi vedere, abbiamo spostato tutto ciò che va dalla richiesta di indovinare in poi all’interno di un ciclo. Assicurati di aggiungere degli spazi ad inizio riga per indentare correttamente il codice all’interno del ciclo ed esegui di nuovo il programma. Il programma ora chiederà sempre un’altra ipotesi, il che introduce un nuovo problema: come fa l’utente a smettere di giocare?
L’utente può sempre interrompere il programma utilizzando la scorciatoia da
tastiera ctrl-C. Ma c’è un altro modo per sfuggire a
questo mostro insaziabile, come accennato nella discussione su parse in
“Confrontare l’ipotesi con il numero
segreto”: se
l’utente inserisce una risposta non numerica, il programma si blocca. Possiamo
approfittarne per consentire all’utente di uscire, come mostrato qui:
$ cargo run
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/gioco_indovinello`
Indovina il numero!
Il numero segreto è: 59
Inserisci la tua ipotesi.
45
Hai ipotizzato: 45
Troppo piccolo!
Inserisci la tua ipotesi.
60
Hai ipotizzato: 60
Troppo grande!
Inserisci la tua ipotesi.
59
Hai ipotizzato: 59
Hai indovinato!
Inserisci la tua ipotesi.
esci
thread 'main' panicked at src/main.rs:28:47:
Inserisci un numero!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Digitando esci chiude il gioco, ma come noterai, anche l’inserimento di
qualsiasi altro input che non sia un numero. Questo è a dir poco sub-ottimale:
vogliamo che il gioco si fermi anche quando viene indovinato il numero corretto.
Uscire Dopo un’Ipotesi Corretta
Programmiamo il gioco in modo che esca quando l’utente vince, aggiungendo
un’istruzione break (uscita):
File: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
loop {
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: u32 = ipotesi.trim().parse().expect("Inserisci un numero!");
println!("Hai ipotizzato: {ipotesi}");
// --taglio--
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => {
println!("Hai indovinato!");
break;
}
}
}
}L’aggiunta della riga break dopo Hai indovinato! fa sì che il programma esca
dal ciclo quando l’utente indovina correttamente il numero segreto. Uscire dal
ciclo significa anche uscire dal programma, perché il ciclo è l’ultima parte di
main.
Gestire Gli Input Non Validi
Per perfezionare ulteriormente il comportamento del gioco, invece di mandare in
crash il programma quando l’utente non inserisce un numero valido, facciamo in
modo che il gioco ignori un valore non numerico in modo che l’utente possa
continuare a indovinare. Possiamo farlo modificando la riga in cui ipotesi
viene convertito da String in u32, come mostrato nel Listato 2-5.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
loop {
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
// --taglio--
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: u32 = match ipotesi.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Hai ipotizzato: {ipotesi}");
// --taglio--
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => {
println!("Hai indovinato!");
break;
}
}
}
}Passiamo da una chiamata expect a un’espressione match per passare dal
crash su un errore alla gestione di quell’errore. Ricorda che parse
restituisce un type Result e Result è un’enum che ha le varianti Ok e
Err. Stiamo usando un’espressione match qui, come abbiamo fatto con il
risultato Ordering del metodo cmp.
Se parse riesce a trasformare la stringa in un numero, restituirà un valore
Ok che contiene il numero risultante. Questo valore Ok corrisponderà allo
schema del primo ramo e l’espressione match restituirà il valore num che
parse ha prodotto e messo all’interno del valore Ok. Quel numero finirà
proprio dove vogliamo nella nuova variabile ipotesi che stiamo creando.
Se parse non riesce a trasformare la stringa in un numero, restituirà un
valore Err che contiene ulteriori informazioni sull’errore. Il valore Err
non corrisponde allo schema Ok(num) del primo ramo match, ma corrisponde
allo schema Err(_) del secondo ramo. Il trattino basso, _, è un valore
piglia-tutto; in questo esempio, stiamo dicendo che va bene qualsiasi valore
di Err, indipendentemente dalle informazioni che contene. Quindi il programma
eseguirà il codice del secondo ramo, continue, che dice al programma di
passare alla successiva iterazione del loop e di chiedere un’altra ipotesi.
Quindi, in effetti, il programma ignora tutti gli errori che parse potrebbe
incontrare!
Ora tutto il programma dovrebbe funzionare come previsto. Proviamo:
$ cargo run
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/gioco_indovinello`
Indovina il numero!
Il numero segreto è: 61
Inserisci la tua ipotesi.
10
Hai ipotizzato: 10
Troppo piccolo!
Inserisci la tua ipotesi.
99
Hai ipotizzato: 99
Troppo grande!
Inserisci la tua ipotesi.
foo
Inserisci la tua ipotesi.
61
Hai ipotizzato: 61
Hai vinto!
Perfetto! Con un’ultima piccola modifica, finiremo il gioco di indovinelli.
Ricorda che il programma continua a stampare il numero segreto. Questo funziona
bene per testare il funzionamento, ma rovina il gioco. Eliminiamo il println!
che produce il numero segreto. Il Listato 2-6 mostra il codice finale.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
loop {
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: u32 = match ipotesi.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Hai ipotizzato: {ipotesi}");
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => {
println!("Hai indovinato!");
break;
}
}
}
}A questo punto, hai costruito con successo il gioco dell’indovinello: complimenti!
Riepilogo
Questo progetto è stato un modo pratico per introdurti a molti nuovi concetti di
Rust: let, match, le funzioni, l’uso di crate esterni e altro ancora. Nei
prossimi capitoli imparerai a conoscere questi concetti in modo più dettagliato.
Il Capitolo 3 tratta i concetti che la maggior parte dei linguaggi di
programmazione possiede, come le variabili, i tipi di dati e le funzioni, e
mostra come utilizzarli in Rust. Il Capitolo 4 esplora la ownership
(controllo esclusivo), una caratteristica che rende Rust diverso dagli altri
linguaggi. Il Capitolo 5 parla delle strutture e della sintassi dei metodi,
mentre il Capitolo 6 spiega come funzionano le enum.
Concetti Comuni di Programmazione
Questo capitolo tratta i concetti che appaiono in quasi tutti i linguaggi di programmazione e come funzionano in Rust. Molti linguaggi di programmazione hanno molti punti in comune. Nessuno dei concetti presentati in questo capitolo è esclusivo di Rust, ma li discuteremo nel contesto di Rust e spiegheremo le convenzioni per l’utilizzo di questi concetti.
In particolare, imparerai a conoscere le variabili, i type di base, le funzioni, i commenti e le strutture di controllo. Questi fondamenti saranno presenti in ogni programma di Rust e impararli presto ti darà una base solida da cui partire.
Parole Chiave
Il linguaggio Rust ha una serie di parole chiave che sono riservate all’uso esclusivo del linguaggio, proprio come in altri linguaggi. Tieni presente che non puoi usare queste parole come nomi di variabili o funzioni. La maggior parte delle parole chiave ha un significato speciale e le userai per svolgere varie attività nei tuoi programmi Rust; alcune non hanno alcuna funzionalità correntemente associata, ma sono state riservate per le funzionalità che potrebbero essere aggiunte a Rust in futuro. Puoi trovare l’elenco delle parole chiave nell’Appendice A.
Variabili e Mutabilità
Come accennato nella sezione “Memorizzare i valori con le Variabili”, come impostazione predefinita, le variabili sono immutabili. Questo è uno dei tanti stimoli che Rust ti dà per scrivere il tuo codice in modo da sfruttare la sicurezza e la facilità di concorrenza che Rust offre. Tuttavia, hai ancora la possibilità di rendere le tue variabili mutabili. Esploriamo come e perché Rust ti incoraggia a favorire l’immutabilità e perché a volte potresti voler rinunciare a questa cosa.
Quando una variabile è immutabile, una volta che un valore è legato a un nome,
non è più possibile cambiarlo. Per vederlo con mano, genera un nuovo progetto
chiamato variabili nella tua cartella progetti utilizzando cargo new variabili.
Ed ora, nella nuova cartella variabili, apri src/main.rs e sostituisci il suo codice con il seguente, che per il momento risulterà non compilabile:
File: src/main.rs
fn main() {
let x = 5;
println!("Il valore di x è: {x}");
x = 6;
println!("Il valore di x è: {x}");
}Salva ed esegui il programma utilizzando cargo run. Dovresti ricevere un
messaggio di errore relativo a un errore di immutabilità, come mostrato in
questo output:
$ cargo run
Compiling variabili v0.1.0 (file:///progetti/variabili)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("Il valore di x è: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variabili` (bin "variabili") due to 1 previous error
Questo esempio mostra come il compilatore ti aiuta a trovare gli errori nei tuoi programmi. Gli errori del compilatore possono essere frustranti, ma in realtà significano solo che il tuo programma non sta ancora facendo in modo sicuro ciò che vuoi; non significano che non sei un buon programmatore! Anche ai Rustacean più esperti appaiono errori del compilatore.
Hai ricevuto il messaggio di errore cannot assign twice to immutable variable perché hai cercato di assegnare un secondo valore alla variabile immutabile
x.
È importante che ci vengano segnalati errori in tempo di compilazione quando si tenta di modificare un valore che è stato definito immutabile, perché proprio questa situazione può portare a dei bug. Se una parte del nostro codice opera sulla base del presupposto che un valore non cambierà mai e un’altra parte del codice modifica quel valore, è possibile che la prima parte del codice non faccia ciò per cui è stata progettata. La causa di questo tipo di bug può essere difficile da rintracciare a posteriori, soprattutto quando la seconda parte del codice modifica il valore solo qualche volta. Il compilatore di Rust garantisce che quando si afferma che un valore non cambierà, non cambierà davvero, quindi non dovrai tenerne traccia tu stesso. Il tuo codice sarà quindi più facile da analizzare.
Ma la mutabilità può essere molto utile e può rendere il codice più comodo da
scrivere. Sebbene le variabili siano immutabili come impostazione predefinita,
puoi renderle mutabili aggiungendo mut davanti al nome della variabile, come
hai fatto nel Capitolo 2. L’aggiunta di mut rende anche palese quando si andrà a rileggere il
codice in futuro che altre parti del codice cambieranno il valore di questa
variabile.
Ad esempio, cambiamo src/main.rs con il seguente:
File: src/main.rs
fn main() { let mut x = 5; println!("Il valore di x è: {x}"); x = 6; println!("Il valore di x è: {x}"); }
Quando eseguiamo il programma ora, otteniamo questo:
$ cargo run
Compiling variabili v0.1.0 (file:///progetti/variabili)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.49s
Running `target/debug/variabili`
Il valore di x è: 5
Il valore di x è: 6
Siamo autorizzati a cambiare il valore legato a x da 5 a 6 quando si usa
mut. In definitiva, decidere se usare la mutabilità o meno dipende da te e da
ciò che ritieni più utile in quella particolare situazione.
Dichiarare le Costanti
Come le variabili immutabili, le costanti sono valori legati a un nome che non possono essere modificati, ma ci sono alcune differenze tra le costanti e le variabili.
Innanzitutto, non puoi usare mut con le costanti. Le costanti non solo sono
immutabili come impostazione predefinita, sono sempre immutabili. Dichiari le
costanti usando la parola chiave const invece della parola chiave let e il
type del valore deve essere annotato. Tratteremo i type e le annotazioni
dei type nella prossima sezione, “Tipi di Dato”,
quindi non preoccuparti dei dettagli in questo momento. Sappi solo che devi
sempre annotare il type.
Le costanti possono essere dichiarate in qualsiasi scope, compreso quello globale, il che le rende utili per i valori che molte parti del codice devono conoscere.
L’ultima differenza è che le costanti possono essere impostate solo su un’espressione costante, non sul risultato di un valore che può essere calcolato solo in fase di esecuzione.
Ecco un esempio di dichiarazione di una costante:
#![allow(unused)] fn main() { const TRE_ORE_IN_SECONDI: u32 = 60 * 60 * 3; }
Il nome della costante è TRE_ORE_IN_SECONDI e il suo valore è impostato come
il risultato della moltiplicazione di 60 (il numero di secondi in un minuto) per
60 (il numero di minuti in un’ora) per 3 (il numero di ore che vogliamo contare
in questo programma). La convenzione di Rust per la denominazione delle costanti
prevede l’uso di maiuscole con trattini bassi tra le parole. Il compilatore è in
grado di valutare il risultato di un’operazione in fase di compilazione, il che
ci permette di scegliere di scrivere questo valore in un modo più facile da
capire e da verificare, piuttosto che impostare questa costante al valore
10.800. Consulta la sezione Valutazione delle costanti (in
inglese) per maggiori informazioni sulle operazioni che possono
essere utilizzate quando si dichiarano le costanti.
Le costanti sono valide per tutto il tempo di esecuzione di un programma, all’interno dello scope in cui sono state dichiarate. Questa proprietà rende le costanti utili per dei valori nella tua applicazione che più parti del programma potrebbero avere bisogno di conoscere, come ad esempio il numero massimo di punti che un giocatore di un gioco può guadagnare o la velocità della luce.
Dichiarare come costanti i valori codificati usati nel tuo programma è utile per trasmettere il significato di quel valore a chi leggerà il codice in futuro. Inoltre, è utile per avere un solo punto del codice da modificare se il valore codificato deve essere aggiornato in futuro.
Shadowing
Come hai visto nel tutorial sul gioco dell’indovinello nel Capitolo
2, puoi dichiarare una nuova variabile con lo
stesso nome di una variabile precedente. I Rustacean dicono che la prima
variabile è oscurata, shadowing, dalla seconda, il che significa che la
seconda variabile è quella che il compilatore vedrà quando userai il nome della
variabile. In effetti, la seconda variabile oscura la prima, portando a sé
qualsiasi uso del nome della variabile fino a quando non sarà essa stessa
oscurata o lo scope terminerà. Possiamo fare shadowing di una variabile
usando lo stesso nome della variabile e ripetendo l’uso della parola chiave
let come segue:
File: src/main.rs
fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("Il valore di x nello scope interno è: {x}"); } println!("Il valore di x è: {x}"); }
Questo programma vincola innanzitutto x a un valore di 5. Poi crea una nuova
variabile x ripetendo let x =, prendendo il valore originale e aggiungendo
1 in modo che il valore di x sia 6. Quindi, all’interno di uno scope
interno creato con le parentesi graffe, la terza istruzione let oscura x e
crea una nuova variabile, moltiplicando il valore precedente per 2 per dare a
x un valore di 12. Quando lo scope termina, finisce pure lo shadowing e
x torna a essere 6. Quando si esegue questo programma, si ottiene il
seguente risultato:
$ cargo run
Compiling variabili v0.1.0 (file:///progetti/variabili)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.29s
Running `target/debug/variabili`
Il valore di x nello scope interno è: 12
Il valore di x è: 6
Lo shadowing è diverso dall’indicare una variabile come mut perché otterremo
un errore in fase di compilazione se cercassimo accidentalmente di riassegnare
questa variabile senza usare la parola chiave let. Usando let, possiamo
eseguire alcune trasformazioni su un valore ma far sì che la variabile sia
immutabile dopo che le trasformazioni sono completate.
L’altra differenza tra mut e lo shadowing è che, poiché stiamo
effettivamente creando una nuova variabile quando usiamo di nuovo la parola
chiave let, possiamo cambiare il type del valore ma riutilizzare lo stesso
nome. Ad esempio, supponiamo che il nostro programma chieda a un utente di
scriverci quanti spazi vuole tra un testo e l’altro inserendo dei caratteri di
spazio, e poi vogliamo memorizzare questo input come un numero:
fn main() { let spazi = " "; let spazi = spazi.len(); }
La prima variabile spazi è di type stringa e la seconda variabile spazi è
di type numerico. Lo shadowing ci evita quindi di dover inventare nomi
diversi, come spazi_str e spazi_num; possiamo invece riutilizzare il nome
più semplice spazi. Tuttavia, se proviamo a usare mut per fare questa cosa,
come mostrato qui, otterremo un errore di compilazione:
fn main() {
let mut spazi = " ";
spazi = spazi.len();
}L’errore dice che non è consentito mutare il type di una variabile:
$ cargo run
Compiling variabili v0.1.0 (file:///progetti/variabili)
error[E0308]: mismatched types
--> src/main.rs:4:13
|
3 | let mut spazi = " ";
| ----- expected due to this value
4 | spazi = spazi.len();
| ^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variabili` (bin "variabili") due to 1 previous error
Ora che abbiamo visto il funzionamento delle variabili, passiamo in rassegna le varie tipologie di dato, type, che possono essere.
Tipi di Dato
Ogni valore in Rust è di un determinato type, il che dice a Rust che tipo di
dati vengono specificati in modo che sappia come lavorare con quei dati.
Esamineremo due sottoinsiemi di tipi di dati: scalare e composto. Tieni presente
che Rust è un linguaggio tipizzato staticamente, il che significa che deve
conoscere il type di tutte le variabili in fase di compilazione. Il
compilatore di solito può dedurre quale type vogliamo utilizzare in base al
valore e al modo in cui lo utilizziamo. Nei casi in cui sono possibili
molteplici type, come quando abbiamo convertito uno String in un type
numerico usando parse nella sezione “Confrontare l’ipotesi con il numero
segreto” del Capitolo 2, dobbiamo aggiungere
un’annotazione, specificando il type in questo modo:
fn main() {
let ipotesi: u32 = "42".parse().expect("Non è un numero!");
}Se non aggiungiamo l’annotazione del type : u32 mostrata nel codice
precedente, Rust visualizzerà il seguente errore, il che significa che il
compilatore ha bisogno di ulteriori informazioni per sapere quale type
vogliamo utilizzare:
$ cargo build
Compiling annotazione_senza_type v0.1.0 (file:///progetti/annotazione_senza_type)
error[E0284]: type annotations needed
--> src/main.rs:3:9
|
3 | let ipotesi = "42".parse().expect("Non è un numero!");
| ^^^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `ipotesi` an explicit type
|
3 | let ipotesi: /* Type */ = "42".parse().expect("Non è un numero!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `annotazione_senza_type` (bin "annotazione_senza_type") due to 1 previous error; 1 warning emitted
Potrai vedere annotazioni di type diverso per altri tipi di dati.
I Type Scalari
Un type scalare rappresenta un singolo valore. Rust ha quattro type scalari primari: numeri interi, numeri in virgola mobile, booleani e caratteri. Potresti riconoscerli da altri linguaggi di programmazione. Andiamo a vedere come funzionano in Rust.
Il Type Intero
Un intero (integer) è un numero senza una componente frazionaria. Nel Capitolo
2 abbiamo utilizzato un tipo integer, il type u32. Questa dichiarazione
del type indica che il valore a cui è associato deve essere un integer senza
segno (i type integer con segno iniziano con i invece che con u) che
occupa 32 bit di spazio. La Tabella 3-1 mostra i type integer incorporati in
Rust. Possiamo usare una qualsiasi di queste varianti per dichiarare il type
di un valore intero.
Tabella 3-1: Type Integer in Rust
| Lunghezza | Con Segno | Senza Segno |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| in base all’Architettura | isize | usize |
Ogni variante può essere con segno o senza e ha una dimensione esplicita. Con segno e senza segno si riferisce alla possibilità che il numero sia negativo. In altre parole, se il numero deve avere un segno con sé (signed in inglese) o se sarà sempre e solo positivo e potrà quindi essere rappresentato senza segno (unsigned in inglese). È come scrivere numeri su carta: quando il segno conta, un numero viene indicato con il segno più o con il segno meno; tuttavia, quando è lecito ritenere che il numero sia positivo, viene visualizzato senza segno. I numeri con segno vengono memorizzati utilizzando la rappresentazione del complemento a due.
Ogni variante con segno può memorizzare numeri da -(2n - 1) a 2n
- 1 - 1 inclusi, dove n è il numero di bit che la variante utilizza.
Quindi, un
i8può memorizzare numeri da -(27) a 27 - 1, il che equivale a -128 a 127. Le varianti senza segno possono memorizzare numeri da 0 a 2n - 1, quindi unu8può memorizzare numeri da 0 a 2 8 - 1, il che equivale a 0 a 255.
Inoltre, i type isize e usize dipendono dall’architettura del computer su
cui viene eseguito il programma: 64 bit se si tratta di un’architettura a 64 bit
e 32 bit se si tratta di un’architettura a 32 bit.
Puoi scrivere i letterali integer in una qualsiasi delle forme mostrate nella
Tabella 3-2. Nota che i letterali numerici che possono essere di più type
numerici permettono, tramite un suffisso, di specificarne il type in questo
modo 57u8. I letterali numerici possono anche usare _ come separatore visivo
per rendere il numero più facile da leggere, come ad esempio 1_000, che avrà
lo stesso valore che avrebbe se avessi specificato 1000.
Tabella 3-2: letterali Integer in Rust
| Letterali numerici | Esempio |
|---|---|
| Decimale | 98_222 |
| Esadecimale | 0xff |
| Ottale | 0o77 |
| Binario | 0b1111_0000 |
Byte (solo u8) | b'A' |
Come si fa a sapere quale type numerico utilizzare? Se non sei sicuro, le
impostazioni predefinite di Rust sono in genere un buon punto di partenza: il
type integer di default è i32. La situazione principale in cui puoi usare
isize o usize è quando indicizzi qualche tipo di collezione.
Integer Overflow
Supponiamo di avere una variabile di type u8 che può contenere valori
compresi tra 0 e 255. Se provi a cambiare la variabile con un valore al di
fuori di questo intervallo, ad esempio 256, si verificherà un integer
overflow, che può portare a uno dei due comportamenti seguenti. Quando stai
compilando in modalità debug, Rust include controlli per l’integer overflow
che fanno sì che il tuo programma vada in panico (panic d’ora in poi) in
fase di esecuzione se si verifica questo comportamento. Rust usa il termine
panic quando un programma termina con un errore; parleremo in modo più
approfondito di panic nella sezione “Errori Irreversibili con
panic!” del Capitolo 9.
Quando si compila in modalità release con il flag --release, Rust non
include i controlli per l’integer overflow che causano il panic. Invece,
se si verifica l’overflow, Rust esegue l’avvolgimento del complemento a due.
In pratica, i valori maggiori del valore massimo che il type può contenere
si “avvolgono” fino al minimo dei valori che il type può contenere. Nel caso
di un u8, il valore 256 diventa 0, il valore 257 diventa 1 e così via. Il
programma non andrà in panic, ma la variabile avrà un valore che
probabilmente non è quello che ci si aspettava che avesse. Affidarsi
all’avvolgimento del complemento a due degli integer è considerato un
errore. Per gestire esplicitamente la possibilità di overflow, puoi utilizzare
queste famiglie di metodi forniti dalla libreria standard per i type
numerici primitivi:
- Racchiudere tutte le modalità con i metodi
wrapping_*, come ad esempiowrapping_add. - Restituire il valore
Nonese c’è overflow con i metodichecked_*. - Restituire il valore e un booleano che indica se c’è stato overflow con i
metodi
overflowing_*. - Saturare i valori minimi o massimi del valore con i metodi
saturating_*.
Il Type a Virgola Mobile
Rust ha anche due type primitivi per i numeri in virgola mobile, abbreviato
float in inglese, che sono numeri con punti decimali. I type in virgola
mobile di Rust sono f32 e f64, rispettivamente di 32 e 64 bit. Il tipo
predefinito è f64 perché sulle CPU moderne ha più o meno la stessa velocità di
f32 ma è in grado di garantire una maggiore precisione. Tutti i type in
virgola mobile sono con segno.
Ecco un esempio che mostra i numeri in virgola mobile in azione:
File: src/main.rs
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
I numeri in virgola mobile sono rappresentati secondo lo standard IEEE-754.
Operazioni Numeriche
Rust supporta le operazioni matematiche di base che ti aspetteresti per tutte le
tipologie di numero: addizione, sottrazione, moltiplicazione, divisione e resto.
La divisione degli interi tronca verso lo zero al numero intero più vicino. Il
codice seguente mostra come utilizzare ogni operazione numerica in una
dichiarazione let:
File: src/main.rs
fn main() { // addizione let somma = 5 + 10; // sottrazione let differenza = 95.5 - 4.3; // multiplicazione let prodotto = 4 * 30; // divisione let quoziente = 56.7 / 32.2; let troncato = -5 / 3; // Restituisce -1 // resto let resto = 43 % 5; }
Ogni espressione in queste dichiarazioni utilizza un operatore matematico e valuta un singolo valore, che viene poi legato a una variabile. Appendice B contiene un elenco di tutti gli operatori che Rust mette a disposizione.
Il Type Booleano
Come nella maggior parte degli altri linguaggi di programmazione, un type
booleano in Rust ha due valori possibili: vero o falso (true e false
rispettivamente d’ora in poi). I booleani hanno la dimensione di un byte. Il
type booleano in Rust viene specificato con bool. Ad esempio:
File: src/main.rs
fn main() { let t = true; let f: bool = false; // con specificazione del type }
Il modo principale per utilizzare i valori booleani è attraverso i condizionali,
come ad esempio un’espressione if. Tratteremo il funzionamento delle
espressioni if in Rust nella sezione “Controllare il
flusso”.
Il Type Carattere
Il type carattere (char d’ora in poi) di Rust è il tipo alfabetico più
primitivo del linguaggio. Ecco alcuni esempi di dichiarazione di valori char:
File: src/main.rs
fn main() { let c = 'z'; let z: char = 'ℤ'; // con specificazione del type let gattino_innamorato = '😻'; }
Nota che specifichiamo i letterali char con le singole virgolette, al
contrario dei letterali stringa, che utilizzano le virgolette doppie. Il type
char di Rust ha la dimensione di 4 byte e rappresenta un valore scalare
Unicode, il che significa che può rappresentare molte altre cose oltre
all’ASCII. Le lettere accentate, i caratteri cinesi, giapponesi e coreani, le
emoji e gli spazi a larghezza zero sono tutti valori char validi in Rust. I
valori scalari Unicode vanno da U+0000 a U+D7FF e da U+E000 a U+10FFFF
inclusi. Tuttavia, un “carattere” non è un concetto vero e proprio in Unicode,
quindi quello che tu potresti concettualmente pensare essere un “carattere”
potrebbe non corrispondere a cosa sia effettivamente un char in Rust.
Discuteremo questo argomento in dettaglio nella sezione “Memorizzare Testo
Codificato UTF-8 con le Stringhe” del Capitolo 8.
I Type Composti
I type composti possono raggruppare più valori in un unico type. Rust ha due type composti primitivi: le tuple e gli array.
Il Type Tupla
Una tupla è un modo generale per raggruppare una serie di valori di tipo diverso in un unico type composto. Le tuple hanno una lunghezza fissa: una volta dichiarate, non possono crescere o diminuire di dimensione. Creiamo una tupla scrivendo un elenco di valori separati da virgole all’interno di parentesi tonde. Ogni posizione nella tupla ha un type e i type dei diversi valori nella tupla non devono essere necessariamente gli stessi. In questo esempio abbiamo aggiunto annotazioni del type opzionali:
File: src/main.rs
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
La variabile tup si lega all’intera tupla perché una tupla è considerata un
singolo elemento composto. Per ottenere i singoli valori di una tupla, possiamo
fare pattern matching per destrutturare il valore di una tupla, in questo
modo:
File: src/main.rs
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("Il valore di y è: {y}"); }
Questo programma crea prima una tupla e la associa alla variabile tup. Quindi
utilizza un pattern con let per prendere tup e trasformarlo in tre
variabili separate, x, y e z. Questa operazione è chiamata
destrutturazione perché spezza la singola tupla in tre parti. Infine, il
programma stampa il valore di y, che è 6,4.
Possiamo anche accedere direttamente a un elemento della tupla utilizzando un
punto (.) seguito dall’indice del valore a cui vogliamo accedere. Ad esempio:
File: src/main.rs
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let cinque_cento = x.0; let sei_virgola_quattro = x.1; let uno = x.2; }
Questo programma crea la tupla x e poi accede a ogni elemento della tupla
utilizzando i rispettivi indici. Come nella maggior parte dei linguaggi di
programmazione, il primo indice di una tupla è 0.
La tupla senza valori ha un nome speciale, unit. Questo valore e il suo type
corrispondente sono entrambi scritti () e rappresentano un valore vuoto o un
type di ritorno vuoto. Le espressioni restituiscono implicitamente il valore
unit se non restituiscono nessun altro valore.
Il Type Array
Un altro modo per avere una collezione di valori multipli è un array. A differenza di una tupla, ogni elemento di un array deve avere lo stesso type. A differenza degli array in altri linguaggi, gli array in Rust hanno una lunghezza fissa.
Scriviamo i valori di un array come un elenco separato da virgole all’interno di parentesi quadre:
File: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; }
Gli array sono utili quando vuoi che i tuoi dati siano allocati sullo stack, come gli altri type che abbiamo visto finora, piuttosto che nell’heap (parleremo dello stack e dell’heap in modo più approfondito nel Capitolo 4) o quando vuoi assicurarti di avere sempre un numero fisso di elementi. Un array, però, non è flessibile come il type vettore (vector d’ora in poi). Un vector è un type simile, che consente la collezione di dati, fornito dalla libreria standard ma che è autorizzato a crescere o a ridursi di dimensione perché il suo contenuto risiede nell’heap. Se non sei sicuro se usare un array o un vector, è probabile che tu debba usare un vector. Il Capitolo 8 tratta i vector in modo più dettagliato.
Tuttavia, gli array sono più utili quando sai che il numero di elementi non dovrà cambiare. Ad esempio, se dovessi utilizzare i nomi dei mesi in un programma, probabilmente utilizzeresti un array piuttosto che un vector perché sai che conterrà sempre 12 elementi:
#![allow(unused)] fn main() { let mesi = ["Gennaio", "Febbraio", "Marzo", "Aprile", "Maggio", "Giugno", "Luglio", "Agosto", "Settembre", "Ottobre", "Novembre", "Dicembre"]; }
Il type array si scrive utilizzando le parentesi quadre con il type di ogni elemento, il punto e virgola e il numero di elementi dell’array, in questo modo:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
In questo caso, i32 è il type di ogni elemento. Dopo il punto e virgola, il
numero 5 indica che l’array contiene cinque elementi.
Puoi anche inizializzare un array in modo che contenga lo stesso valore per ogni elemento specificando il valore iniziale, seguito da un punto e virgola, e poi la lunghezza dell’array tra parentesi quadre, come mostrato qui:
#![allow(unused)] fn main() { let a = [3; 5]; }
L’array chiamato a conterrà 5 elementi che saranno tutti impostati
inizialmente al valore 3. Questo equivale a scrivere let a = [3, 3, 3, 3, 3]; ma in modo più conciso.
Accedere Agli Elementi dell’Array
Un array è un singolo blocco di memoria di dimensione fissa e nota che può essere allocato nello stack. Puoi accedere agli elementi di un array utilizzando l’indicizzazione, in questo modo:
File: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; let primo = a[0]; let secondo = a[1]; }
In questo esempio, la variabile denominata primo otterrà il valore 1 perché
è il valore all’indice [0] dell’array. La variabile denominata secondo
otterrà il valore 2 dall’indice [1] dell’array.
Accedere Agli Elementi Non Validi dell’Array
Vediamo cosa succede se cerchi di accedere a un elemento di un array che si trova oltre la fine dell’array stesso. Supponiamo di eseguire questo codice, simile al gioco di indovinelli del Capitolo 2, per ottenere un indice dell’array dall’utente:
File: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Digita un indice dell'array.");
let mut indice = String::new();
io::stdin()
.read_line(&mut indice)
.expect("Errore di lettura");
let indice: usize = indice
.trim()
.parse()
.expect("L'indice inserito non è un numero");
let elemento = a[indice];
println!("Il valore dell'elemento all'indice {indice} è: {elemento}");
}Se esegui questo codice utilizzando cargo run e inserisci 0, 1, 2, 3 o
4, il programma stamperà il valore corrispondente a quell’indice nell’array.
Se invece inserisci un numero oltre la fine dell’array, come ad esempio 10,
vedrai un risultato come questo:
thread 'main' panicked at src/main.rs:19:20:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Il programma ha generato un errore durante l’esecuzione (at runtime in
inglese) nel momento in cui ha utilizzato un valore non valido nell’operazione
di indicizzazione. Il programma è uscito con un messaggio di errore e non ha
eseguito l’istruzione finale println!. Quando si tenta di accedere a un
elemento utilizzando l’indicizzazione, Rust controlla che l’indice specificato
sia inferiore alla lunghezza dell’array. Se l’indice è maggiore o uguale alla
lunghezza, Rust va in panic. Questo controllo deve avvenire durante
l’esecuzione, soprattutto in questo caso, perché il compilatore non può sapere
quale valore inserirà l’utente quando eseguirà il codice in seguito.
Questo è un esempio dei principi di sicurezza della memoria di Rust in azione. In molti linguaggi di basso livello, questo tipo di controllo non viene fatto e quando si fornisce un indice errato, si può accedere a una memoria non valida. Rust ti protegge da questo tipo di errore uscendo immediatamente invece di consentire l’accesso alla memoria e continuare. Il Capitolo 9 tratta di altri aspetti della gestione degli errori di Rust e di come puoi scrivere codice leggibile e sicuro che non va in panic né consente l’accesso non valido alla memoria.
Funzioni
Le funzioni sono molto diffuse nel codice di Rust. Hai già visto una delle
funzioni più importanti del linguaggio: la funzione main, che è il punto di
ingresso di molti programmi. Hai anche visto la parola chiave fn, che ti
permette di dichiarare nuove funzioni.
Il codice Rust utilizza lo snake case come stile convenzionale per i nomi di funzioni e variabili, in cui tutte le lettere sono minuscole e i trattini bassi separano le parole. Ecco un programma che contiene un esempio di definizione di funzione:
File: src/main.rs
fn main() { println!("Hello, world!"); altra_funzione(); } fn altra_funzione() { println!("Un'altra funzione."); }
In Rust definiamo una funzione inserendo fn seguito dal nome della funzione e
da una serie di parentesi tonde. Le parentesi graffe indicano al compilatore
dove inizia e finisce il corpo della funzione.
Possiamo chiamare qualsiasi funzione che abbiamo definito inserendo il suo nome
seguito da una serie di parentesi tonde. Poiché altra_funzione è definita nel
programma, può essere chiamata dall’interno della funzione main. Nota che
abbiamo definito altra_funzione dopo la funzione main nel codice sorgente;
avremmo potuto definirla anche prima. A Rust non interessa dove definisci le tue
funzioni, ma solo che siano definite in una parte del codice che sia “visibile”,
in scope, al chiamante.
Cominciamo un nuovo progetto binario chiamato funzioni per esplorare
ulteriormente le funzioni. Inserisci l’esempio altra_funzione in src/main.rs
ed eseguilo. Dovresti vedere il seguente output:
$ cargo run
Compiling funzioni v0.1.0 (file:///progetti/funzioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.37s
Running `target/debug/funzioni`
Hello, world!
Un'altra funzione.
Le righe vengono eseguite nell’ordine in cui appaiono nella funzione main.
Prima viene stampato il messaggio “Hello, world!”, poi viene chiamata
altra_funzione e viene stampato il suo messaggio.
Parametri
Possiamo definire le funzioni in modo che abbiano dei parametri, ovvero delle variabili speciali che fanno parte della firma di una funzione. Quando una funzione ha dei parametri, puoi fornirle dei valori concreti per questi parametri. Tecnicamente, i valori concreti sono chiamati argomenti, ma in una conversazione informale si tende a usare le parole parametro e argomento in modo intercambiabile, sia per le variabili nella definizione di una funzione che per i valori concreti passati quando si chiama una funzione.
In questa versione di altra_funzione aggiungiamo un parametro:
File: src/main.rs
fn main() { altra_funzione(5); } fn altra_funzione(x: i32) { println!("Il valore di x è: {x}"); }
Prova a eseguire questo programma; dovresti ottenere il seguente risultato:
$ cargo run
Compiling funzioni v0.1.0 (file:///progetti/funzioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.36s
Running `target/debug/funzioni`
Il valore di x è: 5
La dichiarazione di altra_funzione ha un parametro chiamato x. Il type di
x è specificato come i32. Quando passiamo 5 ad altra_funzione, la macro
println! mette 5 nel punto in cui si trovava la coppia di parentesi graffe
contenente x nella stringa di formato.
Nelle firme delle funzioni è obbligatorio dichiarare il type di ogni parametro. Si tratta di una decisione deliberata nel design di Rust: richiedere le annotazioni sul type nelle definizioni delle funzioni significa che il compilatore non ha quasi mai bisogno che tu le usi in altre parti del codice per capire a quale type ti riferisci. In questo modo il compilatore potrà anche dare messaggi di errore più utili se sa quali type si aspetta la funzione.
Quando definisci più parametri, separa le dichiarazioni dei parametri con delle virgole, in questo modo:
File: src/main.rs
fn main() { stampa_unita_misura(5, 'h'); } fn stampa_unita_misura(valore: i32, unita_misura: char) { println!("La misura è : {valore}{unita_misura}"); }
Questo esempio crea una funzione chiamata stampa_unita_misura con due
parametri. Il primo parametro si chiama valore ed è un i32. Il secondo si
chiama unita_misura ed è di type char. La funzione stampa quindi un testo
contenente sia il valore che unita_misura.
Eseguiamo il codice. Sostituisci il codice attualmente presente nel file
src/main.rs_ del tuo progetto funzioni con l’esempio precedente ed eseguilo
con cargo run:
$ cargo run
Compiling funzioni v0.1.0 (file:///progetti/funzioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/funzioni`
La misura è : 5h
Poiché abbiamo chiamato la funzione con 5 come valore per valore e 'h'
come valore per unita_misura, l’output del programma contiene questi valori.
Dichiarazioni ed Espressioni
I corpi delle funzioni sono costituiti da una serie di dichiarazioni che possono eventualmente terminare con un’espressione. Finora le funzioni che abbiamo trattato non hanno incluso un’espressione finale, ma hai visto un’espressione come parte di una dichiarazione. Poiché Rust è un linguaggio basato sulle espressioni, questa è una distinzione importante da capire. Altri linguaggi non hanno le stesse distinzioni, quindi vediamo cosa sono le dichiarazioni e le espressioni e come le loro differenze influenzano il corpo delle funzioni.
- Le dichiarazioni sono istruzioni che eseguono un’azione e non restituiscono un valore.
- Le espressioni vengono valutate e restituiscono un valore risultante.
Vediamo alcuni esempi.
In realtà abbiamo già usato le dichiarazioni e le espressioni. Creare una
variabile e assegnarle un valore con la parola chiave let è una dichiarazione.
Nel Listato 3-1, let y = 6; è una dichiarazione.
fn main() { let y = 6; }
main contenente una dichiarazioneAnche la definizione di una funzione è una dichiarazione; l’intero esempio precedente è, di per sé, una dichiarazione. (Come vedremo più avanti, però, chiamare una funzione non è una dichiarazione.)
Le dichiarazioni non restituiscono valori. Pertanto, non puoi assegnare una
dichiarazione let a un’altra variabile, come cerca di fare il codice seguente;
otterrai un errore:
File: src/main.rs
fn main() {
let x = (let y = 6);
}Quando esegui questo programma, l’errore che otterrai è simile a questo:
$ cargo run
Compiling funzioni v0.1.0 (file:///progetti/funzioni)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `funzioni` (bin "funzioni") generated 1 warning
error: could not compile `funzioni` (bin "funzioni") due to 1 previous error; 1 warning emitted
La dichiarazione let y = 6 non restituisce un valore, quindi non c’è nulla a
cui x possa legarsi. Questo è diverso da ciò che accade in altri linguaggi,
come C e Ruby, dove l’assegnazione restituisce il valore dell’assegnazione. In
questi linguaggi, puoi scrivere x = y = 6 e far sì che sia x che y abbiano
il valore 6; questo non è il caso di Rust.
Le espressioni che valutate restituiscono un valore costituiscono la maggior
parte del resto del codice che scriverai in Rust. Considera un’operazione
matematica, come 5 + 6, che è un’espressione che restituisce il valore 11.
Le espressioni possono far parte di dichiarazioni: nel Listato 3-1, il 6 nella
dichiarazione let y = 6; è un’espressione che valuta il valore 6. Chiamare
una funzione è un’espressione. Chiamare una macro è un’espressione. Pure
definire tramite parentesi graffe un nuovo scope ad esempio:
File: src/main.rs
fn main() { let y = { let x = 3; x + 1 }; println!("Il valore di y è: {y}"); }
Questa espressione:
{
let x = 3;
x + 1
}è un blocco che, in questo caso, valuta 4. Questo valore viene legato a y
come parte dell’istruzione let. Nota che la riga x + 1 non ha un punto e
virgola alla fine, il che è diverso dalla maggior parte delle righe che hai
visto finora. Le espressioni non includono il punto e virgola finale. Se
aggiungi un punto e virgola alla fine di un’espressione, la trasformi in una
dichiarazione e quindi non restituirà un valore. Tienilo a mente mentre leggi il
prossimo paragrafo sui valori di ritorno delle funzioni e le espressioni.
Funzioni con Valori di Ritorno
Le funzioni possono restituire dei valori al codice che le chiama. Non
assegniamo un nome ai valori di ritorno, ma dobbiamo esplicitarne il type dopo
una freccia (->). In Rust, il valore di ritorno della funzione è sinonimo del
valore dell’espressione finale nel blocco del corpo della funzione. Puoi far
ritornare un valore anche in anticipo alla funzione usando la parola chiave
return e specificando un valore, ma la maggior parte delle funzioni
restituisce l’ultima espressione in modo implicito. Ecco un esempio di funzione
che restituisce un valore:
File: src/main.rs
fn cinque() -> i32 { 5 } fn main() { let x = cinque(); println!("Il valore di x è: {x}"); }
Non ci sono chiamate di funzione, macro o dichiarazioni let nella funzione
cinque, ma solo il numero 5 da solo. Si tratta di una funzione perfettamente
valida in Rust. Nota che anche il type di ritorno della funzione è specificato
come -> i32. Prova a eseguire questo codice; l’output dovrebbe essere simile a
questo:
$ cargo run
Compiling funzioni v0.1.0 (file:///progetti/funzioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.34s
Running `target/debug/funzioni`
Il valore di x è: 5
Il 5 in cinque è il valore di ritorno della funzione, motivo per cui il
type di ritorno è i32. Esaminiamo il tutto più in dettaglio. Ci sono due
elementi importanti: innanzitutto, la riga let x = cinque(); mostra che stiamo
utilizzando il valore di ritorno di una funzione per inizializzare una
variabile. Poiché la funzione cinque restituisce un 5, questa riga è uguale
alla seguente:
#![allow(unused)] fn main() { let x = 5; }
In secondo luogo, la funzione cinque non ha parametri e definisce il type
del valore di ritorno, ma il corpo della funzione è un solitario 5 senza punto
e virgola perché è un’espressione il cui valore vogliamo restituire.
Vediamo un altro esempio:
File: src/main.rs
fn main() { let x = più_uno(5); println!("Il valore di x è: {x}"); } fn più_uno(x: i32) -> i32 { x + 1 }
Eseguendo questo codice verrà stampato Il valore di x è: 6. Ma che succede se
inseriamo un punto e virgola alla fine della riga contenente x + 1,
trasformandola da espressione a dichiarazione?
File: src/main.rs
fn main() {
let x = più_uno(5);
println!("Il valore di x è: {x}");
}
fn più_uno(x: i32) -> i32 {
x + 1;
}La compilazione di questo codice produrrà un errore, come segue:
$ cargo run
Compiling funzioni v0.1.0 (file:///progetti/funzioni)
error[E0308]: mismatched types
--> src/main.rs:7:23
|
7 | fn più_uno(x: i32) -> i32 {
| ------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `funzioni` (bin "funzioni") due to 1 previous error
Il messaggio di errore principale, mismatched types (type incompatibili),
rivela il problema principale di questo codice. La definizione della funzione
più_uno dice che restituirà un i32, ma le dichiarazioni non risultano in un
valore, restituendo un (), il type unit. Pertanto, non viene restituito
nulla, il che contraddice la definizione della funzione e provoca un errore. In
questo output, Rust fornisce un messaggio che può aiutare a correggere questo
problema: suggerisce di rimuovere il punto e virgola, che risolverebbe l’errore.
Commenti
Tutti i programmatori si sforzano di rendere il loro codice facile da capire, ma a volte è necessario fornire ulteriori spiegazioni. In questi casi, i programmatori lasciano dei commenti nel loro codice sorgente che il compilatore ignorerà ma che chi legge il codice sorgente potrebbe trovare utili.
Ecco un semplice commento:
#![allow(unused)] fn main() { // hello, world }
In Rust, lo stile idiomatico di commento inizia un commento con due barre
oblique, slash in inglese, e il commento continua fino alla fine della riga.
Per i commenti che si estendono oltre una singola riga, dovrai includere // su
ogni riga, come in questo caso:
#![allow(unused)] fn main() { // Stiamo facendo qualcosa di complicato, tanto da aver bisogno di // più righe di commento per farlo! Speriamo che questo commento possa // spiegare cosa sta succedendo. }
I commenti possono essere inseriti anche alla fine delle righe contenenti codice:
File: src/main.rs
fn main() { let numero_fortunato = 7; // Oggi mi sento fortunato }
Ma più spesso li vedrai utilizzati in questo formato, con il commento su una riga separata sopra il codice che sta annotando:
File: src/main.rs
fn main() { // Oggi mi sento fortunato let numero_fortunato = 7; }
Rust ha anche un altro tipo di commento, i commenti alla documentazione, di cui parleremo nella sezione “Pubblicazione di un Crate su Crates.io” del Capitolo 14.
Controllare il Flusso
La possibilità di eseguire del codice a seconda che una condizione sia vera e
la possibilità di eseguire ripetutamente del codice finché una data condizione è
vera sono elementi fondamentali della maggior parte dei linguaggi di
programmazione. I costrutti più comuni che ti permettono di controllare il
flusso di esecuzione del codice in Rust sono le espressioni if e i cicli.
L’Espressione if
Un’espressione if (se in italiano) ti permette di ramificare il tuo codice a
seconda delle condizioni. Fornisci una condizione e poi dici: “Se questa
condizione è soddisfatta, esegui questo blocco di codice. Se la condizione non è
soddisfatta, non eseguire questo blocco di codice”.
Crea un nuovo progetto chiamato ramificazioni nella tua directory progetti
per sperimentare con l’espressione if. Nel file src/main.rs, inserisci
quanto segue:
File: src/main.rs
fn main() { let numero = 3; if numero < 5 { println!("condizione era vera"); } else { println!("condizione era falsa"); } }
Tutte le espressioni if iniziano con la parola chiave if, seguita da una
condizione. In questo caso, la condizione verifica se la variabile numero ha o
meno un valore inferiore a 5. Il blocco di codice da eseguire se la condizione è
true viene posizionato subito dopo la condizione, all’interno di parentesi
graffe. I blocchi di codice associati alle condizioni nelle espressioni if
possono esser viste come dei rami, proprio come i rami nelle espressioni
match di cui abbiamo parlato nella sezione “Confrontare l’ipotesi con il
numero segreto” del Capitolo 2.
Opzionalmente, possiamo anche includere un’espressione else (altrimenti in
italiano), come abbiamo scelto di fare in questo caso, per dare al programma un
blocco di codice alternativo da eseguire nel caso in cui la condizione sia
valutata false. Se non fornisci un’espressione else e la condizione è
false, il programma salterà il blocco if e passerà alla parte di codice
successiva.
Prova a eseguire questo codice; dovresti vedere il seguente risultato:
$ cargo run
Compiling ramificazioni v0.1.0 (file:///progetti/ramificazioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.06s
Running `target/debug/ramificazioni`
condizione era vera
Proviamo a cambiare il valore di numero con un valore che renda la condizione
false per vedere cosa succede:
fn main() {
let numero = 7;
if numero < 5 {
println!("condizione era vera");
} else {
println!("condizione era falsa");
}
}Esegui nuovamente il programma e guarda l’output:
$ cargo run
Compiling ramificazioni v0.1.0 (file:///progetti/ramificazioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/ramificazioni`
condizione era falsa
Vale anche la pena di notare che la condizione in questo codice deve essere un
bool. Se la condizione non è un bool, otterremo un errore. Ad esempio, prova
a eseguire il seguente codice:
File: src/main.rs
fn main() {
let numero = 3;
if numero {
println!("numero era tre");
}
}Questa volta la condizione if valuta un valore di 3 e Rust lancia un errore:
$ cargo run
Compiling ramificazioni v0.1.0 (file:///progetti/ramificazioni)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if numero {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `ramificazioni` (bin "ramificazioni") due to 1 previous error
L’errore indica che Rust si aspettava un bool ma ha ottenuto un numero intero.
A differenza di linguaggi come Ruby e JavaScript, Rust non cercherà
automaticamente di convertire i type non booleani in booleani. Devi essere
esplicito e fornire sempre ad if un’espressione booleana come condizione. Se
vogliamo che il blocco di codice if venga eseguito solo quando un numero non è
uguale a 0, ad esempio, possiamo modificare l’espressione if nel seguente
modo:
File: src/main.rs
fn main() { let numero = 3; if numero != 0 { println!("numero era qualcosa di diverso da zero"); } }
L’esecuzione di questo codice stamperà numero era qualcosa di diverso da zero.
Gestire Condizioni Multiple con else if
Puoi utilizzare condizioni multiple combinando if e else in un’espressione
else if. Ad esempio:
File: src/main.rs
fn main() { let numero = 6; if numero % 4 == 0 { println!("numero è divisibile per 4"); } else if numero % 3 == 0 { println!("numero è divisibile per 3"); } else if numero % 2 == 0 { println!("numero è divisibile per 2"); } else { println!("numero non è divisibile per by 4, 3, o 2"); } }
Questo programma ha quattro possibili rami. Dopo averlo eseguito, dovresti vedere il seguente output:
$ cargo run
Compiling ramificazioni v0.1.0 (file:///progetti/ramificazioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.36s
Running `target/debug/ramificazioni`
numero è divisibile per 3
Quando questo programma viene eseguito, controlla ogni espressione if a turno
ed esegue il primo corpo per il quale la condizione è valutata true. Nota che
anche se 6 è divisibile per 2, non vediamo l’output numero è divisibile per 2,
né vediamo il testo numero non è divisibile per 4, 3 o 2 del blocco else.
Questo perché Rust esegue il blocco solo per la prima condizione true e una
volta che ne trova una, le restanti non vengono controllate.
L’uso di troppe espressioni else if può rendere il codice un po’ confusionario
e difficile da leggere, quindi se ne hai più di una, potresti valutare di
riscrivere il codice. Il Capitolo 6 descrive un potente costrutto di
ramificazione di Rust chiamato match per gestire casi del genere.
Utilizzare if in Una Dichiarazione let
Dato che if è un’espressione, possiamo usarla a destra di una dichiarazione
let per assegnare il risultato a una variabile, come nel Listato 3-2.
fn main() { let condizione = true; let numero = if condizione { 5 } else { 6 }; println!("Il valore di numero è: {numero}"); }
if as una variabileLa variabile numero sarà legata a un valore basato sul risultato
dell’espressione if. Esegui questo codice per vedere cosa succede:
$ cargo run
Compiling ramificazioni v0.1.0 (file:///progetti/ramificazioni)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.40s
Running `target/debug/ramificazioni`
Il valore di numero è: 5
Ricorda che i blocchi di codice valutano l’ultima espressione in essi contenuta
e i numeri da soli sono anch’essi espressioni. In questo caso, il valore
dell’intera espressione if dipende da quale blocco di codice viene eseguito.
Ciò significa che i valori che possono essere i risultati di ogni ramo di if
devono essere dello stesso tipo; nel Listato 3-2, i risultati sia del ramo
if che del ramo else erano numeri interi i32. Se i type non sono
corrispondenti, come nell’esempio seguente, otterremo un errore:
File: src/main.rs
fn main() {
let condizione = true;
let numero = if condizione { 5 } else { "sei" };
println!("Il valore di numero è: {numero}");
}Quando proviamo a compilare questo codice, otterremo un errore: i rami if e
else hanno type incompatibili e Rust indica esattamente dove trovare il
problema nel programma:
$ cargo run
Compiling ramificazioni v0.1.0 (file:///progetti/ramificazioni)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:45
|
4 | let numero = if condizione { 5 } else { "sei" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `ramificazioni` (bin "ramificazioni") due to 1 previous error
L’espressione nel blocco if ritorna un integer e l’espressione nel blocco
else ritorna una stringa. Questo non funziona perché le variabili devono avere
un type univoco e Rust ha bisogno di sapere definitivamente in fase di
compilazione di che type è la variabile numero. Conoscere il type di
numero permette al compilatore di verificare che il type sia valido ovunque
si utilizzi numero. Rust non sarebbe in grado di farlo se il type di
numero fosse determinato solo in fase di esecuzione; il compilatore sarebbe
più complesso e darebbe meno garanzie sul codice se dovesse tenere traccia dei
più disparati type possibili per ogni variabile.
Ripetizione con i Cicli
Spesso è utile eseguire un blocco di codice più di una volta. Per questo compito, Rust mette a disposizione diversi cicli (loop in inglese), che eseguono il codice all’interno del corpo del ciclo fino alla fine e poi ripartono immediatamente dall’inizio. Per sperimentare con i cicli, creiamo un nuovo progetto chiamato cicli.
Rust mette a disposizione tre tipologie di ciclo: loop, while e for.
Proviamo ciascuno di essi.
Ripetere il Codice con loop
La parola chiave loop dice a Rust di eseguire un blocco di codice più e più
volte per sempre o finché non gli dici esplicitamente di fermarsi.
A titolo di esempio, modifica il file src/main.rs nella tua cartella cicli in questo modo:
File: src/main.rs
fn main() {
loop {
println!("ancora!");
}
}Quando eseguiamo questo programma, vedremo ancora! stampato in continuazione
fino a quando non interromperemo il programma manualmente. La maggior parte dei
terminali supporta la scorciatoia da tastiera ctrl-C per
interrompere un programma che è bloccato in un ciclo continuo. Provaci:
$ cargo run
Compiling cicli v0.1.0 (file:///progetti/cicli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/cicli`
ancora!
ancora!
ancora!
ancora!
^C!
Il simbolo ^C rappresenta quando hai premuto ctrl-C.
Potresti vedere o meno la parola ancora! stampata dopo la ^C, a seconda di
dove si trovava il codice nel ciclo quando ha ricevuto il segnale di
interruzione.
Fortunatamente, Rust offre anche un modo per uscire da un ciclo utilizzando del
codice. Puoi inserire la parola chiave break all’interno del ciclo per
indicare al programma quando interrompere l’esecuzione del ciclo. Ricorda che
abbiamo fatto questo nel gioco di indovinelli nella sezione “Uscire dopo
un’ipotesi corretta” del Capitolo 2 per uscire
dal programma quando l’utente indovinava il numero segreto.
Nel gioco di indovinelli abbiamo usato anche continue, che in un ciclo indica
al programma di saltare tutto il codice rimanente in questa iterazione del ciclo
e di passare all’iterazione successiva.
Restituire Valori dai Cicli
Uno degli utilizzi di un loop è quello di riprovare un’operazione che sai che
potrebbe fallire, come ad esempio controllare se un thread ha completato il
suo lavoro. Potresti anche aver bisogno di passare il risultato di questa
operazione al di fuori del ciclo al resto del tuo codice. Per farlo, puoi
aggiungere il valore che vuoi che venga restituito dopo l’espressione break
che utilizzi per interrompere il ciclo; quel valore verrà restituito al di fuori
del ciclo in modo da poterlo utilizzare, come mostrato qui:
fn main() { let mut contatore = 0; let risultato = loop { contatore += 1; if contatore == 10 { break contatore * 2; } }; println!("Il risultato è {risultato}"); }
Prima del ciclo, dichiariamo una variabile chiamata contatore e la
inizializziamo a 0. Poi dichiariamo una variabile chiamata risultato per
contenere il valore restituito dal ciclo. A ogni iterazione del ciclo,
aggiungiamo 1 alla variabile contatore e poi controlliamo se contatore è
uguale a 10. Quando lo è, usiamo la parola chiave break con il valore
contatore * 2. Dopo il ciclo, usiamo un punto e virgola per terminare
l’istruzione che assegna il valore a risultato. Infine, stampiamo il valore in
risultato, che in questo caso è 20.
Puoi anche usare return all’interno di un ciclo. Mentre break esce solo dal
ciclo corrente, return esce sempre dalla funzione corrente.
Distinguere con le Etichette di Loop
Se hai un ciclo annidato all’interno di un altro ciclo, break e continue si
applicano al loop più interno in quel momento. Puoi specificare facoltativamente
un’etichetta (loop label) su uno specifico ciclo per poi usare con break o
continue quell’etichetta per specificare a quale ciclo applicare l’istruzione.
Le loop label devono iniziare con una virgoletta singola. Ecco un esempio con
due cicli annidati:
fn main() { let mut conteggio = 0; 'aumenta_conteggio: loop { println!("conteggio = {conteggio}"); let mut rimanente = 10; loop { println!("rimanente = {rimanente}"); if rimanente == 9 { break; } if conteggio == 2 { break 'aumenta_conteggio; } rimanente -= 1; } conteggio += 1; } println!("Fine conteggio = {conteggio}"); }
Il ciclo esterno ha la label 'aumenta_conteggio e conta da 0 a 2. Il ciclo
interno senza label conta da 10 a 9. Il primo break che non specifica una
label esce solo dal ciclo interno. L’istruzione break 'aumenta_conteggio;
esce dal ciclo esterno. Questo codice stamperà:
$ cargo run
Compiling cicli v0.1.0 (file:///progetti/cicli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.35s
Running `target/debug/cicli`
conteggio = 0
rimanente = 10
rimanente = 9
conteggio = 1
rimanente = 10
rimanente = 9
conteggio = 2
rimanente = 10
Fine conteggio = 2
Semplificare Cicli Condizionali con while
Spesso un programma ha bisogno di valutare una condizione all’interno di un
ciclo. Quando la condizione è true, il ciclo viene eseguito. Quando la
condizione cessa di essere true, il programma chiama break, interrompendo il
ciclo. È possibile implementare un comportamento del genere utilizzando una
combinazione di loop, if, else e break; se vuoi, puoi provare a farlo in
un programma. Tuttavia, questo schema è così comune che Rust ha un costrutto di
linguaggio incorporato per questi casi, chiamato ciclo while (finché in
italiano). Nel Listato 3-3, usiamo while per eseguire il ciclo del programma
tre volte, contando alla rovescia ogni volta, e poi, dopo il ciclo, stampiamo un
messaggio e usciamo.
fn main() { let mut numero = 3; while numero != 0 { println!("{numero}!"); numero -= 1; } println!("PARTENZA!!!"); }
while per eseguire codice finché la condizione è trueQuesto costrutto elimina un sacco di annidamenti che sarebbero necessari se
usassi loop, if, else e break, ed è di più semplice lettura. Finché una
condizione risulta true, il codice viene eseguito; altrimenti, esce dal ciclo.
Eseguire un Ciclo su una Collezione con for
Puoi scegliere di utilizzare il costrutto while per eseguire un ciclo sugli
elementi di una collezione, come un array. Ad esempio, il ciclo nel Listato 3-4
stampa ogni elemento dell’array a.
fn main() { let a = [10, 20, 30, 40, 50]; let mut indice = 0; while indice < 5 { println!("il valore è: {}", a[indice]); indice += 1; } }
whileIn questo caso, il codice conteggia tutti gli elementi dell’array: inizia
dall’indice 0 e poi esegue un ciclo fino a raggiungere l’ultimo indice
dell’array (cioè quando indice < 5 non è più true). L’esecuzione di questo
codice stamperà ogni elemento dell’array:
$ cargo run
Compiling cicli v0.1.0 (file:///progetti/cicli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.36s
Running `target/debug/cicli`
il valore è: 10
il valore è: 20
il valore è: 30
il valore è: 40
il valore è: 50
Tutti e cinque i valori dell’array appaiono nel terminale, come previsto.
Anche se indice raggiungerà un valore di 5 a un certo punto, il ciclo viene
bloccato prima che si tenti di leggere un sesto elemento dell’array.
Tuttavia, questo approccio è incline all’errore; potremmo causare il panic del
programma se il valore dell’indice o la condizione di test non sono corretti.
Per esempio, se cambiassi la definizione dell’array a per avere quattro
elementi, ma dimenticassi di aggiornare la condizione a while indice < 4, il
codice andrebbe in panic. È anche lento, perché il compilatore aggiunge codice
di esecuzione per eseguire il controllo condizionale per verificare se l’indice
è entro i limiti dell’array a ogni iterazione del ciclo.
Come alternativa più concisa, puoi usare un ciclo for ed eseguire del codice
per ogni elemento di una collezione. Un ciclo for assomiglia al codice del
Listato 3-5.
fn main() { let a = [10, 20, 30, 40, 50]; for elemento in a { println!("il valore è: {elemento}"); } }
forQuando eseguiamo questo codice, vedremo lo stesso risultato del Listato 3-4. Ma,
cosa più importante, abbiamo aumentato la sicurezza del codice ed eliminato la
possibilità di bug che potrebbero derivare dall’andare oltre la fine dell’array
o dal non accedere ad ogni elemento dell’array. Il codice macchina generato dai
cicli for può essere anche più efficiente, perché l’indice non deve essere
confrontato con la lunghezza dell’array a ogni iterazione.
Utilizzando il ciclo for, non dovrai ricordarti di modificare altro codice se
cambierai il numero di valori nell’array, come invece faresti con il metodo
while usato nel Listato 3-4.
La sicurezza e la concisione dei cicli for li rendono il costrutto di ciclo
più usato in Rust. Anche nelle situazioni in cui vuoi eseguire un certo numero
di volte il codice, come nell’esempio del conto alla rovescia che utilizzava un
ciclo while nel Listato 3-3, la maggior parte dei Rustacean userebbe un
ciclo for. Il modo per farlo sarebbe quello di usare un Range, fornito dalla
libreria standard, che genera tutti i numeri in sequenza partendo da un numero e
finendo prima di un altro numero.
Ecco come apparirebbe il conto alla rovescia utilizzando un ciclo for e un
altro metodo di cui non abbiamo ancora parlato, rev, per invertire
l’intervallo.
File: src/main.rs
fn main() { for numero in (1..4).rev() { println!("{numero}!"); } println!("PARTENZA!!!"); }
Questo codice è un po’ più carino, vero?
Riepilogo
Ce l’hai fatta! Questo capitolo è stato molto impegnativo: hai imparato a
conoscere le variabili, i type di dati scalari e composti, le funzioni, i
commenti, le espressioni if e i cicli! Per esercitarti con i concetti discussi
in questo capitolo, prova a costruire dei programmi per eseguire le seguenti
operazioni:
- Convertire le temperature tra Fahrenheit e Celsius.
- Generare l’n-esimo numero di Fibonacci.
- Stampare il testo del canto natalizio “The Twelve Days of Christmas”, sfruttando la ripetizione della canzone.
Quando sarai pronto per andare avanti, parleremo di un concetto di Rust che non esiste in altri linguaggi di programmazione: la ownership.
Capire la Ownership
Il controllo esclusivo o proprietà (la ownership d’ora in poi) è la caratteristica più qualificante di Rust e ha profonde implicazioni per il resto del linguaggio. Permette a Rust di garantire la sicurezza dei dati in memoria senza bisogno di un garbage collector, quindi è importante capire come funziona la ownership. In questo capitolo parleremo della ownership e di diverse caratteristiche correlate: il prestito (borrowing d’ora in poi), le slice e il modo in cui Rust dispone i dati in memoria.
Cos’è la Ownership?
La ownership è un insieme di regole che disciplinano la gestione della memoria da parte di un programma Rust. Tutti i programmi devono gestire il modo in cui utilizzano la memoria del computer durante l’esecuzione. Alcuni linguaggi hanno una garbage collection che cerca regolarmente la memoria non più utilizzata durante l’esecuzione del programma; in altri linguaggi, il programmatore deve allocare e rilasciare esplicitamente la memoria. Rust utilizza un terzo approccio: la memoria viene gestita attraverso un sistema di controllo esclusivo con un insieme di regole che il compilatore controlla. Se una qualsiasi delle regole viene violata, il programma non viene compilato. Nessuna delle caratteristiche di ownership rallenterà il tuo programma mentre è in esecuzione.
Poiché la ownership è un concetto nuovo per molti programmatori, ci vuole un po’ di tempo per abituarsi. La buona notizia è che più si acquisisce esperienza con Rust e con le regole del sistema di ownership, più sarà facile sviluppare naturalmente codice sicuro ed efficiente. Non mollare!
Quando capirai la ownership, avrai una solida base per comprendere le caratteristiche che rendono Rust unico. In questo capitolo imparerai la ownership lavorando su alcuni esempi che si concentrano su una struttura di dati molto comune: le stringhe.
Lo Stack e l’Heap
Molti linguaggi di programmazione non richiedono di pensare allo stack e all’heap molto spesso. Ma in un linguaggio di programmazione di sistema come Rust, il fatto che un valore sia sullo stack o nell’heap influisce sul comportamento del linguaggio e sul motivo per cui devi prendere determinate decisioni.
Sia lo stack che l’heap sono parti di memoria disponibili per il codice da utilizzare in fase di esecuzione, ma sono strutturate in modi diversi. Lo stack memorizza i valori nell’ordine in cui li ottiene e rimuove i valori nell’ordine opposto. Questo viene definito last in, first out (LIFO). Pensa a una pila di piatti: quando aggiungi altri piatti, li metti in cima alla pila e quando ti serve un piatto, ne togli uno dalla cima. Aggiungere o rimuovere i piatti dal centro o dal fondo non funzionerebbe altrettanto bene! L’aggiunta di dati sullo stack viene definita push (immissione), mentre la rimozione dei dati viene definita pop (estrazione). Tutti i dati archiviati sullo stack devono avere una dimensione nota e fissa. I dati con una dimensione sconosciuta in fase di compilazione o una dimensione che potrebbe cambiare devono invece essere archiviati nell’heap.
L’heap è meno organizzato: quando metti i dati nell’heap, richiedi una certa quantità di spazio. L’allocatore di memoria trova un punto vuoto nell’heap che sia sufficientemente grande, lo contrassegna come in uso e restituisce un puntatore, che è l’indirizzo di quella posizione. Questo processo è chiamato allocazione nell’heap e talvolta è abbreviato semplicemente in allocazione (l’inserimento di valori sullo stack non è considerato allocazione). Poiché il puntatore all’heap ha una dimensione nota e fissa, è possibile archiviare il puntatore sullo stack, ma quando si desiderano i dati effettivi è necessario seguire il puntatore. Pensa di essere seduto in un ristorante. Quando entri, indichi il numero di persone nel tuo gruppo e il cameriere trova un tavolo vuoto adatto a tutti e ti conduce lì. Se qualcuno nel tuo gruppo arriva in ritardo, può chiedere dove sei seduto e trovarti.
Il push sullo stack è più veloce dell’allocazione nell’heap perché l’allocatore non deve mai cercare un posto dove archiviare i nuovi dati; quella posizione è sempre in cima allo stack. In confronto, l’allocazione dello spazio nell’heap richiede più lavoro perché l’allocatore deve prima trovare uno spazio sufficientemente grande per contenere i dati e quindi eseguire la contabilità per prepararsi all’allocazione successiva.
L’accesso ai dati nell’heap è più lento dell’accesso ai dati sullo stack perché è necessario leggere un puntatore sullo stack per poi “saltare” all’indirizzo di memoria nell’heap per accedere ai dati. I processori attuali sono più veloci se non “saltano” troppo in giro per la memoria. Continuando l’analogia, consideriamo un cameriere in un ristorante che prende ordini da molti tavoli. È più efficiente ricevere tutti gli ordini su un tavolo prima di passare al tavolo successivo. Prendere un ordine dal tavolo A, poi un ordine dal tavolo B, poi ancora uno da A e poi ancora uno da B sarebbe un processo molto più lento. Allo stesso modo, un processore può svolgere meglio il proprio lavoro se lavora su dati vicini ad altri dati (come sono sullo stack) piuttosto che più lontani (come possono essere nell’heap).
Quando il codice chiama una funzione, i valori passati alla funzione (inclusi, potenzialmente, puntatori ai dati nell’heap) e le variabili locali della funzione vengono inseriti sullo stack. Quando la funzione termina, tali valori vengono estratti, pop, sullo _stack.
Tenere traccia di quali parti del codice utilizzano quali dati nell’heap, ridurre al minimo la quantità di dati duplicati nell’heap e ripulire i dati inutilizzati nell’heap in modo da non esaurire la memoria sono tutti problemi che la ownership risolve. Una volta compresa la ownership, non sarà necessario pensare molto spesso allo stack e all’heap, ma comprendere che lo scopo principale della ownership è gestire i dati dell’heap può aiutare a capire perché funziona in questo modo.
Regole di Ownership
Per prima cosa, diamo un’occhiata alle regole di ownership, tenendole a mente mentre lavoriamo agli esempi che le illustrano:
- Ogni valore in Rust ha un proprietario, owner.
- Ci può essere un solo owner alla volta.
- Quando l’owner esce dallo scope, il valore viene rilasciato.
Scope delle Variabili
Ora che abbiamo visto e imparato la sintassi di base di Rust, non includeremo
tutto il codice fn main() { negli esempi, quindi se stai seguendo, assicurati
di inserire manualmente i seguenti esempi all’interno di una funzione main. Di
conseguenza, i nostri esempi saranno un po’ più concisi, permettendoci di
concentrarci sui dettagli reali piuttosto che sul codice di base.
Come primo esempio di ownership, analizzeremo lo scope di alcune variabili. Lo scope è l’ambito all’interno di un programma nel quale un elemento è valido. Prendiamo la seguente variabile:
#![allow(unused)] fn main() { let s = "ciao"; }
La variabile s si riferisce a un letterale stringa, il cui valore è codificato
nel testo del nostro programma. La variabile è valida dal momento in cui viene
dichiarata fino alla fine dello scope corrente. Il Listato 4-1 mostra un
programma con commenti che annotano i punti in cui la variabile s sarebbe
valida (in scope).
fn main() { { // `s` non è valida qui, perché non ancora dichiarata let s = "hello"; // `s` è valida da questo punto in poi // fai cose con `s` } // questo scope è finito, e `s` non è più valida }
In altre parole, ci sono due momenti importanti:
- Quando
sentra nello scope, è valida; - Rimane valida fino a quando non esce dallo scope.
A questo punto, la relazione tra scope e validità delle variabili è simile a
quella di altri linguaggi di programmazione. Ora ci baseremo su questa
comprensione introducendo il type String.
Il Type String
Per illustrare le regole di ownership, abbiamo bisogno di un tipo di dati più
complesso di quelli trattati nel Capitolo 3. I
type trattati in precedenza hanno dimensioni note, possono essere inseriti e
estratti sullo stack quando il loro scope è terminato, possono essere
rapidamente copiati per creare una nuova istanza indipendente se un’altra parte
del codice deve utilizzare lo stesso valore in uno scope diverso. Ma vogliamo
esaminare i dati archiviati nell’heap e capire come Rust sa quando ripulire la
memoria che quei dati usavano quando non serve più, e il type String è un
ottimo esempio da cui partire.
Ci concentreremo sulle parti di String che riguardano la ownership. Questi
aspetti si applicano anche ad altri type di dati complessi, siano essi forniti
dalla libreria standard o creati dall’utente. Parleremo di String oltre
l’aspetto della ownership nel Capitolo 8.
Abbiamo già visto i letterali stringa, in cui un valore stringa è codificato nel
nostro programma. I letterali stringa sono convenienti, ma non sono adatti a
tutte le situazioni in cui potremmo voler utilizzare del testo. Uno dei motivi è
che sono immutabili. Un altro è che non tutti i valori di stringa possono essere
conosciuti quando scriviamo il nostro codice: ad esempio, cosa succederebbe se
volessimo prendere l’input dell’utente e memorizzarlo? È per queste situazioni
che Rust ha un il type String. Questo type gestisce i dati allocati
nell’heap e come tale è in grado di memorizzare una quantità di testo a noi
sconosciuta in fase di compilazione. Puoi creare un type String partendo da
un letterale stringa utilizzando la funzione from, in questo modo:
#![allow(unused)] fn main() { let s = String::from("ciao"); }
L’operatore double colon (doppio - due punti) :: ci permette di integrare
questa particolare funzione from nel type String piuttosto che usare un
nome come string_from. Parleremo di questa sintassi nella sezione “Sintassi
dei metodi” del Capitolo 5 e quando parleremo di
come organizzare la nomenclatura nei moduli in “Percorsi per fare riferimento a
un elemento nell’albero dei moduli” nel
Capitolo 7.
Questo tipo di stringa può essere mutata:
fn main() { let mut s = String::from("hello"); s.push_str(", world!"); // push_str() aggiunge un letterale a una String println!("{s}"); // verrà stampato `hello, world!` }
Allora, qual è la differenza? Perché String può essere mutata ma i letterali
no? La differenza sta nel modo in cui questi due type vengono gestiti in
memoria.
Memoria e Allocazione
Nel caso di un letterale stringa, conosciamo il contenuto al momento della compilazione, quindi il testo è codificato direttamente nell’eseguibile finale. Per questo motivo i letterali stringa sono veloci ed efficienti. Ma queste proprietà derivano solo dall’immutabilità del letterale stringa. Sfortunatamente, non possiamo inserire una porzione di memoria indefinita nel binario per ogni pezzo di testo la cui dimensione è sconosciuta al momento della compilazione e la cui dimensione potrebbe cambiare durante l’esecuzione del programma.
Con il type String, per supportare una porzione di testo mutabile e
espandibile, dobbiamo allocare una quantità di memoria nell’heap, sconosciuta
in fase di compilazione, per contenere il contenuto. Questo significa che:
- La memoria deve essere richiesta all’allocatore di memoria in fase di esecuzione.
- Abbiamo bisogno di un modo per restituire questa memoria all’allocatore quando
abbiamo finito con la nostra
String.
La prima parte la facciamo noi: quando chiamiamo String::from, la sua
implementazione richiede la memoria di cui ha bisogno. Questo è praticamente
universale nei linguaggi di programmazione.
Tuttavia, la seconda parte è diversa. Nei linguaggi con un garbage collector (GC), il GC tiene traccia e ripulisce la memoria che non viene più utilizzata e non abbiamo bisogno di pensarci. Nella maggior parte dei linguaggi senza GC, è nostra responsabilità identificare quando la memoria non viene più utilizzata e chiamare il codice per de-allocarla esplicitamente, proprio come abbiamo fatto per richiederla. Farlo correttamente è stato storicamente un difficile problema di programmazione. Se ce lo dimentichiamo, sprecheremo memoria. Se lo facciamo troppo presto, avremo una variabile non valida. Se lo facciamo due volte, anche questo è un bug. Dobbiamo accoppiare esattamente un’allocazione con esattamente una de-allocazione (o rilascio, liberazione).
Rust prende una strada diversa: la memoria viene rilasciata automaticamente una
volta che la variabile che la possiede esce dallo scope. Ecco una versione del
nostro esempio sullo scope che utilizza una String invece di un letterale
stringa:
fn main() { { let s = String::from("hello"); // `s` è valida da questo punto in poi // fai cose con `s` } // questo scope è finito, e `s` non è più valida }
C’è un punto naturale in cui possiamo rilasciare la memoria di cui la nostra
String ha bisogno all’allocatore: quando s esce dallo scope. Quando una
variabile esce dallo scope, Rust chiama per noi una funzione speciale. Questa
funzione si chiama drop, ed è dove l’autore di String
può inserire il codice per rilasciare la memoria. Rust chiama drop
automaticamente alla parentesi graffa di chiusura.
Nota: in C++, questo schema di de-allocazione delle risorse alla fine del ciclo di vita di un elemento è talvolta chiamato Resource Acquisition Is Initialization (RAII). La funzione
dropdi Rust ti sarà familiare se hai usato gli schemi RAII.
Questo schema ha un profondo impatto sul modo in cui viene scritto il codice Rust. Può sembrare semplice in questo momento, ma il comportamento del codice può essere inaspettato in situazioni più complicate quando vogliamo che più variabili utilizzino i dati che abbiamo allocato nell’heap. Esploriamo ora alcune di queste situazioni.
Interazione tra Variabili e Dati con Move
In Rust, più variabili possono interagire con gli stessi dati in modi diversi. Il Listato 4-2 mostra un esempio che utilizza un integer.
fn main() { let x = 5; let y = x; }
x a yProbabilmente possiamo indovinare cosa sta facendo: “Associa il valore 5 a
x; quindi crea una copia del valore in x e associala a y.” Ora abbiamo due
variabili, x e y, ed entrambe uguali a 5. Questo è effettivamente ciò che
sta accadendo. Poiché gli integer sono valori semplici con una dimensione
fissa e nota, questi due valori 5 vengono immessi sullo stack.
Ora diamo un’occhiata alla versione con String:
fn main() { let s1 = String::from("hello"); let s2 = s1; }
Sembra molto simile, quindi potremmo pensare che il funzionamento sia lo stesso:
cioè che la seconda riga faccia una copia del valore in s1 e lo assegni a
s2. Ma non è esattamente quello che succede.
Nella Figura 4-1 diamo un’occhiata sotto le coperte per vedere com’è in realtà
una String. Una String è composta da tre parti, mostrate a sinistra: un
puntatore (ptr) alla memoria che contiene il contenuto della stringa, una
lunghezza (len) e una capienza (capacity). Questo gruppo di dati è
memorizzato sullo stack. A destra c’è la memoria nell’heap che contiene il
contenuto.

Figura 4-1: La representazione in memoria di una String
con valore "hello" assegnato a s1
La lunghezza è la quantità di memoria, in byte, utilizzata attualmente dal
contenuto della String. La capienza è la quantità totale di memoria, in byte,
che String ha ricevuto dall’allocatore. La differenza tra lunghezza e capacità
è importante, ma non in questo contesto, quindi per ora va bene ignorare la
capienza.
Quando assegniamo s1 a s2, i dati String vengono copiati, ovvero copiamo
il puntatore, la lunghezza e la capienza presenti sullo stack. Non copiamo i
dati nell’heap a cui fa riferimento il puntatore. In altre parole, la
rappresentazione dei dati in memoria è simile alla Figura 4-2.

Figura 4-2: La rappresentazione in memoria della variabile
s2 che contiene una copia del puntatore, lunghezza e capienza di s1
La rappresentazione non assomiglia alla Figura 4-3, che è l’aspetto che avrebbe
la memoria se Rust copiasse anche i dati dell’heap. Se Rust facesse così,
l’operazione s2 = s1 potrebbe diventare molto dispendiosa in termini
prestazionali e di memoria qualora i dati nell’heap fossero di grandi
dimensioni.

Figura 4-3: Un’altra possibilità di come potrebbe essere s2 = s1 se Rust copiasse anche i dati dell’heap
In precedenza, abbiamo detto che quando una variabile esce dallo scope, Rust
chiama automaticamente la funzione drop e ripulisce la memoria nell’heap di
quella variabile. Ma la Figura 4-2 mostra entrambi i puntatori di dati che
puntano alla stessa posizione. Questo è un problema: quando s2 e s1 escono
dallo scope, entrambe tenteranno di de-allocare la stessa memoria. Questo è
noto come errore da doppia de-allocazione (double free error in inglese) ed
è uno dei bug di sicurezza della memoria menzionati in precedenza. Rilasciare la
memoria due volte può portare a corruzione di memoria, che può potenzialmente
esporre il programma a vulnerabilità di sicurezza.
Per garantire la sicurezza della memoria, dopo la riga let s2 = s1;, Rust
considera s1 come non più valido. Pertanto, Rust non ha bisogno di de-allocare
nulla quando s1 esce dallo scope. Controlla cosa succede quando provi a
usare s1 dopo che s2 è stato creato: non funzionerà:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}Otterrai un errore di questo tipo perché Rust ti impedisce di utilizzare il riferimento invalidato:
$ cargo run
Compiling ownership v0.1.0 (file:///progetti/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:6:16
|
3 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
4 | let s2 = s1;
| -- value moved here
5 |
6 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
4 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Se hai sentito i termini copia superficiale e copia profonda mentre lavoravi
con altri linguaggi, il concetto di copiare il puntatore, la lunghezza e la
capacità senza copiare i dati probabilmente ti sembrerà simile a una copia
superficiale. Ma poiché Rust invalida anche la prima variabile, invece di
essere chiamata copia superficiale, questa operazione è nota come move
(spostamento). In questo esempio, diremmo che s1 è stata spostata in s2.
Quindi, ciò che accade in realtà è mostrato nella Figura 4-4.

Figura 4-4: La rappresentazione in memoria dopo che s1 è
resa non valida
Questo risolve il nostro problema! Con la sola s2 valida, quando essa uscirà
dallo scope, solo lei rilascerà la memoria e il gioco è fatto.
Inoltre, c’è una scelta progettuale implicita in questo: Rust non creerà mai automaticamente copie “profonde” dei tuoi dati. Pertanto, si può presupporre che qualsiasi copia automatica sia poco dispendiosa in termini prestazionali e di memoria.
Scope e Assegnazione
L’opposto di ciò è vero anche per la relazione tra scope, ownership e
memoria rilasciata tramite la funzione drop. Quando assegni un valore
completamente nuovo a una variabile esistente, Rust chiamerà drop e libererà
immediatamente la memoria del valore originale. Considera questo codice, ad
esempio:
fn main() { let mut s = String::from("hello"); s = String::from("ciao"); println!("{s}, world!"); }
Inizialmente dichiariamo una variabile s e la associamo a una String con il
valore "hello". Poi creiamo immediatamente una nuova String con il valore
"ciao" e la assegniamo a s. A questo punto, non c’è più nulla che faccia
riferimento al valore originale nell’heap. La Figura 4-5 mostra i dati sullo
stack e nell’heap al momento:

Figura 4-5: La rappresentazione in memoria dopo che il primo valore è completamente sostituito.
La stringa originale esce così immediatamente dallo scope. Rust eseguirà la
funzione drop su di essa e la sua memoria verrà rilasciata immediatamente.
Quando stamperemo il valore alla fine, sarà "ciao, world!".
Interazione tra Variabili e Dati con Clone
Se vogliamo effettivamente duplicare i dati nell’heap della String, e non
solo i dati sullo stack, possiamo utilizzare un metodo comune chiamato
clone. Parleremo della sintassi dei metodi nel Capitolo 5, ma dato che i
metodi sono una caratteristica comune a molti linguaggi di programmazione,
probabilmente li hai già visti.
Ecco un esempio del metodo clone in azione:
fn main() { let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {s1}, s2 = {s2}"); }
Questo funziona benissimo e produce esplicitamente il comportamento mostrato nella Figura 4-3, in cui i anche i dati dell’heap vengono duplicati.
Quando vedi una chiamata a clone, sai che viene eseguito del codice arbitrario
e che questo potrebbe essere dispendioso. È un indicatore visivo del fatto che
sta succedendo qualcosa di diverso.
Duplicare Dati Sullo Stack
C’è un’altra peculiarità di cui non abbiamo ancora parlato: questo codice che utilizza gli integer, in parte mostrato nel Listato 4-2, funziona ed è valido
fn main() { let x = 5; let y = x; println!("x = {x}, y = {y}"); }
Ma questo codice sembra contraddire ciò che abbiamo appena imparato: non abbiamo
una chiamata a clone, ma x è ancora valido e non è stato spostato in y.
Il motivo è che i type come gli integer che hanno una dimensione nota in
fase di compilazione vengono archiviati interamente sullo stack, quindi le
copie dei valori effettivi sono veloci da creare. Ciò significa che non c’è
motivo per cui vorremmo impedire che x sia valido dopo aver creato la
variabile y. In altre parole, qui non c’è differenza tra copia profonda e
superficiale, quindi chiamare clone non farebbe nulla di diverso dalla solita
copia superficiale e possiamo tralasciarlo.
Rust ha un’annotazione speciale chiamata trait Copy che possiamo appiccicare
sui type memorizzati sullo stack, come lo sono gli integer (parleremo
meglio dei trait nel Capitolo 10). Se un type
implementa il trait Copy, le variabili che lo utilizzano non si spostano,
ma vengono semplicemente copiate, rendendole ancora valide dopo l’assegnazione
ad un’altra variabile.
Rust non ci permette di annotare un type con Copy se il type, o una
qualsiasi delle sue parti, ha implementato il trait Drop. Se il type ha
bisogno che accada qualcosa di speciale quando il valore esce dallo scope e
aggiungiamo l’annotazione Copy a quel type, otterremo un errore in fase di
compilazione. Per sapere come aggiungere l’annotazione Copy al tuo type,
consulta “Trait Derivabili” nell’Appendice
C.
Quindi, quali type implementano il trait Copy? Puoi controllare la
documentazione del type in questione per esserne sicuro, ma come regola
generale, qualsiasi gruppo di valori scalari semplici può implementare Copy e
niente che richieda l’allocazione o che sia una qualche forma di risorsa può
implementare Copy:
Ecco alcuni dei type che implementano Copy:
- Tutti i type integer, come
u32. - Il type booleano,
bool, con i valoritrueefalse. - Tutti i type in virgola mobile, come
f64. - Il type carattere,
char. - Le tuple, se contengono solo type che implementano
Copy. Ad esempio,(i32, i32)implementaCopy, ma(i32, String)no.
Ownership e Funzioni
I meccanismi che regolano il passaggio di un valore a una funzione sono simili a quelli dell’assegnazione di un valore a una variabile. Passando una variabile a una funzione, questa viene spostata o copiata, proprio come fa l’assegnazione. Il Listato 4-3 contiene un esempio con alcune annotazioni che mostrano dove le variabili entrano ed escono dallo scope.
fn main() { let s = String::from("hello"); // `s` entra nello scope prende_ownership(s); // il valore di `s` viene spostato nella funzione... // ... e quindi qui smette di esser valido let x = 5; // `x` entra nello scope duplica(x); // Siccome i32 implementa il tratto Copy, // `x` NON viene spostato nella funzione, // quindi dopo può ancora essere usata. } // Qui, `x` esce dallo scope, ed anche `s`. Tuttavia, siccome il valore di `s` // era stato spostato, non succede nulla di particolare. fn prende_ownership(una_stringa: String) { // `una_stringa` entra nello scope println!("{una_stringa}"); } // Qui, `una_stringa` esce dallo scope e `drop` viene chiamato. // La memoria corrispondente viene rilasciata. fn duplica(un_integer: i32) { // `un_integer` entra nello scope println!("{un_integer}"); } // Qui, `un_integer` esce dallo scope. Non succede nulla di particolare.
Se provassimo a usare s dopo la chiamata a prende_ownership, Rust
segnalerebbe un errore in fase di compilazione. Questi controlli statici ci
proteggono dagli errori. Prova ad aggiungere del codice a main che usi s e
x per sperimentare dove puoi usarli e dove le regole di ownership te lo
impediscono.
Valori di Ritorno e Scope
I valori di ritorno possono anch’essi trasferire la ownership. Il Listato 4-4 mostra un esempio di funzione che restituisce un valore, con annotazioni simili a quelle del Listato 4-3.
fn main() { let s1 = cede_ownership(); // `cede_ownership` sposta il proprio // valore di ritorno in `s1` let s2 = String::from("hello"); // `s2` entra in scope let s3 = prende_e_restituisce(s2); // `s2` viene spostata in // `prende_e_restituisce`, che a sua // volta sposta il proprio valore // di ritorno in `s3` } // Qui, `s3` esce dallo scope e viene cancellata con `drop`. `s2` era stata spostata // e quindi non succede nulla. `s1` viene cancellata con `drop` anch'essa. fn cede_ownership() -> String { // `cede_ownership` spostera il proprio valore di // ritorno alla funzione che l'ha chiamata let una_stringa = String::from("yours"); // `una_stringa` entra in scope una_stringa // `una_stringa` viene ritornata e spostata // alla funzione chiamante } // Questa funzione prende una String e ritorna una String. fn prende_e_restituisce(altra_stringa: String) -> String { // `altra_stringa` entra in scope altra_stringa // `altra_stringa` viene ritornata // e spostata alla funzione chiamante }
La ownership di una variabile segue ogni volta lo stesso schema: assegnare un
valore a un’altra variabile la sposta. Quando una variabile che include dati
nell’heap esce dallo scope, il valore verrà cancellato da drop a meno che
la ownership dei dati non sia stata spostata ad un’altra variabile.
Anche se funziona, prendere e cedere la ownership con ogni funzione è un po’ faticoso. Cosa succede se vogliamo consentire a una funzione di utilizzare un valore ma non di prenderne la ownership? È piuttosto fastidioso che tutto ciò che passiamo debba anche essere restituito se vogliamo usarlo di nuovo, oltre a tutte le varie elaborazioni sui dati che la funzione esegue e che magari è necessario ritornare pure quelle.
Rust ci permette di ritornare più valori utilizzando una tupla, come mostrato nel Listato 4-5
fn main() { let s1 = String::from("ciao"); let (s2, lung) = calcola_lunghezza(s1); println!("La lunghezza di '{s2}' è {lung}."); } fn calcola_lunghezza(s: String) -> (String, usize) { let lunghezza = s.len(); // len() restituisce la lunghezza di una String (s, lunghezza) }
Ma questa è una procedura inutilmente complessa e richiede molto lavoro per un concetto che dovrebbe essere comune. Fortunatamente per noi, Rust ha una funzionalità che consente di utilizzare un valore senza trasferirne la ownership, chiamata riferimento (reference in inglese).
Reference e Borrowing
Il problema con il codice nel Listato 4-5 è che dobbiamo restituire la String
alla funzione chiamante in modo da poter ancora utilizzare la String dopo la
chiamata a calcola_lunghezza, perché la String è stata spostata in
calcola_lunghezza. Possiamo invece fornire un riferimento (reference) al
valore String. Un reference è come un puntatore in quanto è un indirizzo che
possiamo seguire per accedere ai dati archiviati a quell’indirizzo di memoria;
la ownership di quei dati appartiene ad un’altra variabile. A differenza di un
puntatore, è garantito che un reference punti a un valore valido di un certo
type finché il reference è ancora valido.
Ecco come definiresti e utilizzeresti una funzione calcola_lunghezza che abbia
un reference ad un oggetto come parametro invece di assumere la ownership
del valore:
fn main() { let s1 = String::from("ciao"); let lung = calcola_lunghezza(&s1); println!("La lunghezza di '{s1}' è {lung}."); } fn calcola_lunghezza(s: &String) -> usize { s.len() }
Innanzitutto, nota che tutto il codice che dichiarava e ritornava la variabile
tupla è sparito. In secondo luogo, nota che passiamo &s1 a calcola_lunghezza
e, nella sua definizione del parametro, prendiamo &String anziché String. Il
carattere & (E commerciale) rappresenta il reference e consente di fare
riferimento a un valore senza prenderne la ownership.
La Figura 4-6 illustra questo concetto.

Figura 4-6: Schema di &String s che punta a String
s1
Nota: l’opposto della referenziazione tramite l’uso di
&è la de-referenziazione, che si realizza con l’operatore di de-referenziazione*(dereference operator). Vedremo alcuni usi dell’operatore di de-referenziazione nel Capitolo 8 e discuteremo i dettagli della de-referenziazione nel Capitolo 15.
Diamo un’occhiata più da vicino alla chiamata di funzione:
fn main() { let s1 = String::from("ciao"); let lung = calcola_lunghezza(&s1); println!("La lunghezza di '{s1}' è {lung}."); } fn calcola_lunghezza(s: &String) -> usize { s.len() }
La sintassi &s1 ci permette di creare un reference che punta al valore di
s1 ma non lo possiede. Poiché il reference non lo possiede, il valore a
cui punta non verrà rilasciato dalla memoria quando il reference smette di
essere utilizzato. Allo stesso modo, la firma della funzione utilizza & per
indicare che il type del parametro s è un reference. Aggiungiamo alcune
annotazioni esplicative:
fn main() { let s1 = String::from("ciao"); let lung = calcola_lunghezza(&s1); println!("La lunghezza di '{s1}' è {lung}."); } fn calcola_lunghezza(s: &String) -> usize { // `s` è un reference a una String s.len() } // Qui, `s` esce dallo scope. Ma siccome `s` non ha ownership di quello // a cui fa riferimento, i valori di String non vengono cancellati
Lo scope in cui la variabile s è valida è lo stesso dello scope di
qualsiasi parametro di funzione, ma il valore a cui punta il reference non
viene eliminato quando s smette di essere utilizzato, perché s non ha la
ownership. Quando le funzioni hanno reference come parametri anziché valori
effettivi, non avremo bisogno di restituire i valori per restituire la
ownership, perché la ownership non ci è mai stata trasferita.
L’azione di creare un reference viene chiamata borrowing (fare un prestito in italiano). Come nella vita reale, se una persona possiede qualcosa, puoi chiedergliela in prestito. Quando hai finito, devi restituirla. Non la possiedi.
Quindi, cosa succede se proviamo a modificare qualcosa che abbiamo in prestito? Prova il codice nel Listato 4-6. Avviso spoiler: non funziona!
fn main() {
let s = String::from("hello");
cambia(&s);
}
fn cambia(una_stringa: &String) {
una_stringa.push_str(", world");
}Ecco l’errore:
$ cargo run
Compiling ownership v0.1.0 (file:///progetti/ownership)
error[E0596]: cannot borrow `*una_stringa` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | una_stringa.push_str(", world");
| ^^^^^^^^^^^ `una_stringa` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn cambia(una_stringa: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Così come le variabili sono immutabili come impostazione predefinita, lo sono anche i reference. Non possiamo modificare qualcosa a cui abbiamo solo un riferimento.
Reference Mutabili
Possiamo correggere il codice del Listato 4-6 per permetterci di modificare un valore preso in prestito con alcune piccole modifiche che utilizzano, invece, un reference mutabile:
fn main() { let mut s = String::from("hello"); cambia(&mut s); } fn cambia(una_stringa: &mut String) { una_stringa.push_str(", world"); }
Per prima cosa rendiamo s mutabile con mut. Poi creiamo un reference
mutabile con &mut s dove chiamiamo la funzione cambia e aggiorniamo la firma
della funzione in modo che accetti un reference mutabile con una_stringa: &mut String. In questo modo è molto chiaro che la funzione cambia muterà il
valore che prende in prestito. I reference mutabili hanno una grande
restrizione: se hai un reference mutabile a un valore, non puoi avere altri
reference a quel valore. Questo codice che tenta di creare due reference
mutabili a s fallirà:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}Ecco l’errore:
$ cargo run
Compiling ownership v0.1.0 (file:///progetti/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:6:14
|
5 | let r1 = &mut s;
| ------ first mutable borrow occurs here
6 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
L’errore dice che questo codice non è valido perché non possiamo avere più di un
reference mutabile alla volta ad s. Il primo reference mutabile è in r1
e deve durare fino a quando non viene utilizzato nel println!, ma tra la
creazione di quel reference mutabile e il suo utilizzo, abbiamo cercato di
creare un altro reference mutabile in r2 che prende in prestito gli stessi
dati di r1.
La restrizione che impedisce più reference mutabili agli stessi dati contemporaneamente consente la mutazione ma in modo molto controllato. È qualcosa con cui chi comincia a programmare in Rust fatica perché la maggior parte dei linguaggi ti consente di mutare quando vuoi. Il vantaggio di avere questa restrizione è che Rust può prevenire conflitti di accesso ai dati, data race, in fase di compilazione. Una data race è simile a una condizione di competizione e si verifica quando si verificano questi tre comportamenti:
- Due o più puntatori accedono contemporaneamente agli stessi dati.
- Almeno uno dei puntatori viene utilizzato per scrivere nei dati.
- Non viene utilizzato alcun meccanismo per sincronizzare l’accesso ai dati
I data race causano comportamenti non programmati e possono essere difficili da diagnosticare e risolvere quando si cerca di individuarli durante l’esecuzione; Rust previene questo problema rifiutando di compilare codice contenente data race!
Come sempre, possiamo usare le parentesi graffe per creare uno scope nuovo, consentendo di avere più reference mutabili, ma non simultanee:
fn main() { let mut s = String::from("ciao"); { let r1 = &mut s; } // qui `r1` esce dallo scope, quindi possiamo creare // un nuovo reference senza problemi let r2 = &mut s; }
Rust applica una regola simile per combinare reference mutabili e immutabili. Questo codice genera un errore:
fn main() {
let mut s = String::from("ciao");
let r1 = &s; // nessun problema
let r2 = &s; // nessun problema
let r3 = &mut s; // GROSSO PROBLEMA
println!("{r1}, {r2}, e {r3}");
}Ecco l’errore:
$ cargo run
Compiling ownership v0.1.0 (file:///progetti/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:7:14
|
5 | let r1 = &s; // nessun problema
| -- immutable borrow occurs here
6 | let r2 = &s; // nessun problema
7 | let r3 = &mut s; // GROSSO PROBLEMA
| ^^^^^^ mutable borrow occurs here
8 |
9 | println!("{r1}, {r2}, e {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Wow! Non possiamo nemmeno avere un reference mutabile mentre ne abbiamo uno immutabile allo stesso valore.
Chi userà un reference immutabile non si aspetta certo che il valore cambi improvvisamente! Tuttavia, sono consentiti reference multipli immutabili perché nessuno che stia leggendo i dati ha la possibilità di influenzare la lettura dei dati da parte di altri.
Nota che lo scope di un reference inizia dal punto in cui viene introdotto e
continua fino all’ultima volta che viene utilizzato. Ad esempio, questo codice
verrà compilato perché l’ultimo utilizzo dei reference immutabili avviene nel
println!, prima che venga introdotto il reference mutabile:
fn main() { let mut s = String::from("ciao"); let r1 = &s; // nessun problema let r2 = &s; // nessun problema println!("{r1} and {r2}"); // Le variabili `r1` e `r2` non verranno più usato dopo questo punto let r3 = &mut s; // nessun problema println!("{r3}"); }
Gli scope dei reference immutabili r1 e r2 terminano dopo il println!
in cui sono stati utilizzati per l’ultima volta, ovvero prima che venga creato
il reference mutabile r3. Questi scope non si sovrappongono, quindi questo
codice è consentito: il compilatore capisce che il reference non verrà più
utilizzato in nessun altro punto prima della fine dello scope.
Anche se a volte gli errori di borrowing possono essere frustranti, ricorda che è il compilatore di Rust a segnalare un potenziale bug in anticipo (in fase di compilazione e non in fase di esecuzione) e a mostrarti esattamente dove si trova il problema. In questo modo non dovrai cercare di capire perché i tuoi dati non sono quelli che pensavi fossero quando il programma è in esecuzione.
Reference Pendenti
Nei linguaggi con puntatori, è facile creare erroneamente un puntatore pendente, cioè un puntatore che fa riferimento a una posizione in memoria non più valido, perché quella memoria assegnata a quella variabile è stata liberata, ma non si è provveduto a cancellare anche il puntatore che per l’appunto rimane pendente puntando a qualcosa che non è più disponibile. In Rust, al contrario, il compilatore garantisce che i reference non diverranno mai pendenti: se si ha un reference ad alcuni dati, il compilatore ci impedirà di usare quel reference dopo che i dati sono usciti dallo scope.
Proviamo a creare un reference pendente per vedere come Rust li previene segnalando un errore in fase di compilazione:
fn main() {
let reference_a_nulla = pendente();
}
fn pendente() -> &String {
let s = String::from("ciao");
&s
}Ecco l’errore:
$ cargo run
Compiling ownership v0.1.0 (file:///progetti/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:18
|
5 | fn pendente() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn pendente() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn pendente() -> &String {
5 + fn pendente() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Questo messaggio di errore si riferisce a una funzionalità che non abbiamo ancora trattato: la longevità (lifetime d’ora in poi). Parleremo in dettaglio della lifetime nel Capitolo 10. Ma, se trascuriamo le parti relative alla lifetime, il messaggio contiene la chiave del motivo per cui questo codice è un problema:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
(traduzione: il type di ritorno di questa funzione contiene un valore in
prestito, ma non c’è alcun valore da cui prenderlo in prestito)
Diamo un’occhiata più da vicino a cosa succede esattamente in ogni fase della
nostra funzione pendente:
fn main() {
let reference_a_nulla = pendente();
}
fn pendente() -> &String { // pendente ritorna un reference a String
let s = String::from("ciao"); // `s` è una String nuova
&s // ritorniamo un reference alla String `s`
} // Qui `s` esce dallo scope e viene cancellata, così come la memora assegnatale.
// Pericolo!Poiché s viene creato all’interno di pendente, quando il codice di
pendente sarà terminato, s e la memoria ad essa assegnata verranno
rilasciate. Ma abbiamo cercato di restituire un reference a questa memoria.
Ciò significa che questo reference punterebbe a una String non valida.
Questo non va bene! Rust non ci permette di farlo.
La soluzione è restituire direttamente la String:
fn main() { let stringa = non_pendente(); } fn non_pendente() -> String { let s = String::from("ciao"); s }
Questo funziona senza problemi: la ownership viene spostata all’esterno e non viene rilasciato nulla.
Le Regole dei Reference
Ricapitoliamo quello che abbiamo detto sui reference:
- In un dato momento, puoi avere o un singolo reference mutabile o un numero qualsiasi di reference immutabili.
- I reference devono essere sempre validi.
Successivamente, analizzeremo un’altra tipologia di reference: le sezioni (slice in inglese).
Il Type Slice
Le slice (sezioni, fette, porzioni in italiano) ti permettono di fare riferimento (un reference) a una sequenza contigua di elementi in una collezione. Una slice è una tipologia di reference, quindi non ha ownership.
Ecco un piccolo problema di programmazione: scrivi una funzione che prenda una stringa di parole separate da spazi e restituisca la prima parola che trova in quella stringa. Se la funzione non trova uno spazio nella stringa, l’intera stringa deve essere considerata come una sola parola, quindi deve essere restituita l’intera stringa.
Nota: Ai fini dell’introduzione alle slice di stringhe, stiamo assumendo solo caratteri ASCII in questa sezione; una discussione più approfondita sulla gestione di UTF-8 si trova nella sezione “Memorizzare testo codificato UTF-8 con le stringhe” del Capitolo 8.
Lavoriamo su come scrivere la firma di questa funzione senza usare slice per ora, per comprendere il problema che le slice risolveranno:
fn prima_parola(s: &String) -> ?La funzione prima_parola ha un parametro di tipo &String. Non abbiamo
bisogno di ownership, quindi va bene. (In Rust idiomatico, le funzioni non
prendono la ownership dei loro argomenti se non strettamente necessario, e i
motivi per questo diventeranno chiari man mano che andremo avanti.) Ma cosa
dovremmo ritornare? Non abbiamo davvero un modo per descrivere una parte di
una stringa. Tuttavia, potremmo restituire l’indice della fine della parola,
indicato da uno spazio. Proviamo a farlo, come mostrato nel Listato 4-7.
fn prima_parola(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &lettera) in bytes.iter().enumerate() { if lettera == b' ' { return i; } } s.len() } fn main() {}
prima_parola che restituisce un valore di indice byte nella variabile StringPoiché dobbiamo esaminare la String elemento per elemento e controllare se un
valore è uno spazio, convertiremo la nostra String in un array di byte usando
il metodo as_bytes.
fn prima_parola(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &lettera) in bytes.iter().enumerate() {
if lettera == b' ' {
return i;
}
}
s.len()
}
fn main() {}Successivamente, creiamo un iteratore sull’array di byte usando il metodo
iter:
fn prima_parola(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &lettera) in bytes.iter().enumerate() {
if lettera == b' ' {
return i;
}
}
s.len()
}
fn main() {}Discuteremo gli iteratori in modo più dettagliato nel Capitolo 13. Per ora, sappi che iter è un metodo che restituisce ogni elemento
in una collezione e che enumerate prende il risultato di iter e restituisce
ogni elemento come parte di una tupla. Il primo elemento della tupla restituita
da enumerate è l’indice, e il secondo elemento è un riferimento all’elemento.
Questo è un po’ più conveniente rispetto a calcolarci l’indice da soli.
Poiché il metodo enumerate restituisce una tupla, possiamo usare i pattern
per destrutturare quella tupla. Discuteremo meglio i pattern nel Capitolo
6. Nel ciclo for, specifichiamo un pattern che ha i per l’indice
nella tupla e &item per il singolo byte nella tupla. Poiché da
.iter().enumerate() otteniamo un reference all’elemento, usiamo & nel
pattern.
All’interno del ciclo for, cerchiamo il byte che rappresenta lo spazio usando
la sintassi del letterale byte. Se troviamo uno spazio, restituiamo la
posizione. Altrimenti, restituiamo la lunghezza della stringa usando s.len().
fn prima_parola(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &lettera) in bytes.iter().enumerate() {
if lettera == b' ' {
return i;
}
}
s.len()
}
fn main() {}Ora abbiamo un metodo per scoprire l’indice della fine della prima parola nella
stringa, ma c’è un problema. Stiamo ritornando un usize da solo, che è un
numero significativo solo se usato in contesto con &String. In altre parole,
poiché è un valore separato dalla String, non c’è garanzia che rimarrà valido
in futuro. Considera il programma nel Listing 4-8 che utilizza la funzione
prima_parola dal Listing 4-7.
fn prima_parola(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &lettera) in bytes.iter().enumerate() { if lettera == b' ' { return i; } } s.len() } fn main() { let mut s = String::from("hello world"); let parola = prima_parola(&s); // `parola` riceverà il valore 5 s.clear(); // questo svuota la String, rendendola uguale a "" // `parola` mantiene ancora il valore di 5, ma `s` non contiene più quello a cui // quel 5 si riferisce, quindi `parola` è adesso considerabile come non valida! }
prima_parola e poi modificare il contenuto della StringQuesto programma si compila senza errori e lo farebbe anche se usassimo parola
dopo aver chiamato s.clear(). Poiché parola non è collegato allo stato di
s, parola contiene ancora il valore 5. Potremmo usare quel valore 5 con
la variabile s per cercare di estrarre la prima parola, ma questo sarebbe un
bug perché il contenuto di s è cambiato da quando abbiamo salvato 5 in
parola.
Doversi preoccupare dell’indice in parola che si disallinea con i dati in s
è noioso e soggetto a errori! Gestire questi indici è ancora più fragile se
scriviamo una funzione seconda_parola. La sua firma dovrebbe apparire così:
fn seconda_parola(s: &String) -> (usize, usize) {Ora stiamo tracciando un indice di partenza e un indice di fine, e abbiamo ancora altri valori che sono stati calcolati da dati in un determinato stato, ma che non sono per nulla legati a quello stato in qualche modo. Abbiamo tre variabili non correlate e indipendenti che noi dobbiamo mantenere in sincronia.
Fortunatamente, Rust ha una soluzione a questo problema: le slice di stringhe.
Slice di Stringa
Una slice di stringa (string slice) è un reference a una sequenza contigua
degli elementi di una String, e appare così:
fn main() { let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11]; }
Invece di un reference all’intera String, hello è un reference a una
porzione della String, specificata con l’aggiunta di [0..5]. Creiamo le
slice usando un intervallo all’interno delle parentesi quadre specificando
[indice_inizio..indice_fine], dove indice_inizio è la prima posizione
nella slice e indice_fine è l’ultima posizione nella slice più uno.
Internamente, la struttura dati della slice memorizza la posizione iniziale e
la lunghezza della slice, che corrisponde a indice_fine meno
indice_inizio. Quindi, nel caso di let world = &s[6..11];, world sarebbe
una slice che contiene un puntatore al byte all’indice 6 di w con un valore
di lunghezza di 5.
La Figura 4-7 mostra questo in un diagramma.

Figura 4-7: Slice di stringa che si riferisce a parte di
una String
Con la sintassi d’intervallo .. di Rust, se vuoi iniziare dall’indice 0, puoi
omettere il valore prima dei due punti. In altre parole, questi sono
equivalenti:
#![allow(unused)] fn main() { let s = String::from("hello"); let slice = &s[0..2]; let slice = &s[..2]; }
Allo stesso modo, se la tua slice include l’ultimo byte della String, puoi
omettere il numero finale. Ciò significa che questi sono equivalenti:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[3..len]; let slice = &s[3..]; }
Puoi anche omettere entrambi i valori per prendere una slice dell’intera stringa. Quindi questi sono equivalenti:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..]; }
Nota: Gli indici di intervallo delle slice di stringa devono trovarsi in posizioni valide tenendo conto anche dei caratteri UTF-8. Se tenti di creare una slice nel mezzo di un carattere multi-byte, il tuo programma terminerà con un errore.
Tenendo presente tutte queste informazioni, riscriviamo prima_parola per
restituire una slice. Il type che indica la slice di stringa è scritto
come &str:
fn prima_parola(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &lettera) in bytes.iter().enumerate() { if lettera == b' ' { return &s[0..i]; } } &s[..] } fn main() {}
Otteniamo l’indice per la fine della parola nello stesso modo in cui lo abbiamo fatto nel Listato 4-7, cercando la prima occorrenza di uno spazio. Quando troviamo uno spazio, restituiamo una slice di stringa usando l’inizio della stringa e l’indice dello spazio come indici di inizio e fine.
Ora, quando chiamiamo prima_parola, otteniamo un singolo valore che è legato
ai dati sottostanti. Il valore è composto da un reference al punto di partenza
della slice e dal numero di elementi nella slice.
Restituire una slice funzionerebbe anche per una funzione seconda_parola:
fn seconda_parola(s: &String) -> &str {Ora abbiamo una funzione più semplice in cui è molto più difficile succedano
cose strane perché il compilatore garantirà che i reference alla String
rimangano validi. Ricordi il bug nel programma nel Listato 4-8, quando abbiamo
ottenuto l’indice per la fine della prima parola ma poi abbiamo svuotato la
stringa, rendendo il nostro indice non valido? Quel codice era logicamente
errato ma non mostrava immediatamente errori. I problemi si sarebbero
manifestati più tardi se avessimo continuato a cercare di usare l’indice della
prima parola con una stringa svuotata. Le slice rendono questo bug impossibile
e ci fanno sapere che abbiamo un problema con il nostro codice molto prima.
Usare la versione slice di prima_parola genererà un errore di compilazione:
fn prima_parola(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &lettera) in bytes.iter().enumerate() {
if lettera == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let parola = prima_parola(&s);
s.clear(); // errore!
println!("la prima parola è: {parola}");
}Ecco l’errore del compilatore:
$ cargo run
Compiling ownership v0.1.0 (file:///progetti/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:19:5
|
17 | let parola = prima_parola(&s);
| -- immutable borrow occurs here
18 |
19 | s.clear(); // errore!
| ^^^^^^^^^ mutable borrow occurs here
20 |
21 | println!("la prima parola è: {parola}");
| ------ immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ricorda le regole di borrowing: se abbiamo un reference immutabile a
qualcosa, non possiamo anche prendere un reference mutabile. Poiché clear
deve troncare la String, ha bisogno di ottenere un reference mutabile. Il
println! dopo la chiamata a clear utilizza il reference a parola, quindi
il reference immutabile deve essere ancora attivo a quel punto. Rust vieta che
il reference mutabile in clear e il reference immutabile a parola
esistano contemporaneamente, e la compilazione fallisce. Non solo Rust ha reso
la nostra funzione più facile da usare, ma ha anche eliminato un’intera classe
di errori durante la compilazione!
Letterali Stringa come Slice
Ricordi che abbiamo parlato dei letterali stringa memorizzati all’interno del binario? Ora che abbiamo scoperto le slice, possiamo comprendere correttamente i letterali stringa:
#![allow(unused)] fn main() { let s = "Hello, world!"; }
Il type di s qui è &str: è una slice che punta a quel punto specifico
nel binario. Questo è anche il motivo per cui i letterali stringa sono
immutabili; &str è un reference immutabile.
Slice di Stringa come Parametri
Sapendo che puoi avere slice di letterali e di valori String, arriviamo a un
ulteriore miglioramento per prima_parola, e cioè la sua firma:
fn prima_parola(s: &String) -> &str {Un Rustacean più esperto scriverebbe invece la firma come mostrata nel Listato
4-9, perché ci permette di usare la stessa funzione sia su valori &String che
su valori &str.
fn prima_parola(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &lettera) in bytes.iter().enumerate() {
if lettera == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mia_stringa = String::from("hello world");
// `prima_parola` funziona con slice di `String`, parziali o intere.
let parola = prima_parola(&mia_stringa[0..6]);
let parola = prima_parola(&mia_stringa[..]);
// `prima_parola` funziona anche con reference a `String`, che corrisponde
// a una slice intera di `String`.
let parola = prima_parola(&mia_stringa);
let mia_stringa_letterale = "hello world";
// `prima_parola` funziona con slice di letterali di stringa,
// parziali o intere.
let parola = prima_parola(&mia_stringa_letterale[0..6]);
let parola = prima_parola(&mia_stringa_letterale[..]);
// E siccome i letterali di stringa *sono* già delle slice,
// funziona pure così, senza usare la sintassi delle slice!
let parola = prima_parola(mia_stringa_letterale);
}prima_parola utilizzando una slice come type del parametro sSe abbiamo una slice di stringa, possiamo passarlo direttamente. Se abbiamo
una String, possiamo passare una slice della String o un reference alla
String. Questa flessibilità sfrutta la deref coercions (de-referenziazione
forzata), una funzionalità che tratteremo nella sezione “Usare la
De-Referenziazione Forzata in Funzioni e Metodi” del Capitolo 15.
Definire una funzione che come parametro prende una slice di stringa invece di
un reference a una String rende la nostra funzione più generica e utile
senza perdere alcuna funzionalità:
fn prima_parola(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &lettera) in bytes.iter().enumerate() { if lettera == b' ' { return &s[0..i]; } } &s[..] } fn main() { let mia_stringa = String::from("hello world"); // `prima_parola` funziona con slice di `String`, parziali o intere. let parola = prima_parola(&mia_stringa[0..6]); let parola = prima_parola(&mia_stringa[..]); // `prima_parola` funziona anche con reference a `String`, che corrisponde // a una slice intera di `String`. let parola = prima_parola(&mia_stringa); let mia_stringa_letterale = "hello world"; // `prima_parola` funziona con slice di letterali di stringa, // parziali o intere. let parola = prima_parola(&mia_stringa_letterale[0..6]); let parola = prima_parola(&mia_stringa_letterale[..]); // E siccome i letterali di stringa *sono* già delle slice, // funziona pure così, senza usare la sintassi delle slice! let parola = prima_parola(mia_stringa_letterale); }
Altre Slice
Le slice di stringa, come puoi immaginare, sono specifiche per le stringhe. Ma c’è anche un tipo di slice più generale. Considera questo array:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; }
Proprio come potremmo voler fare riferimento a parte di una stringa, potremmo voler fare riferimento a parte di un array. Lo faremmo in questo modo:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
Questa slice ha il type &[i32]. Funziona allo stesso modo delle string
slice, memorizzando un reference al primo elemento e una lunghezza.
Utilizzerai questo tipo di slice per tutti i type di altre collezioni.
Discuteremo di queste collezioni in dettaglio quando parleremo dei vettori nel
Capitolo 8.
Riepilogo
I concetti di ownership, borrowing e slice garantiscono la sicurezza della memoria nei programmi Rust già in fase d compilazione. Il linguaggio Rust ti offre il controllo sul tuo utilizzo della memoria nello stesso modo in cui fanno altri linguaggi di programmazione di sistema, ma avere un proprietario (ownership) per ogni dato e che questo pulisca automaticamente i propri dati quando se ne va (non più in scope), significa non dover scrivere e debuggare codice extra per ottenere questo controllo.
L’ownership influisce su come molte altre parti di Rust funzionano, quindi
parleremo di questi concetti ulteriormente nel resto del libro. Passiamo al
Capitolo 5 e vediamo come raggruppare pezzi di dati insieme in una struct.
Utilizzare le Struct per Strutturare Dati Correlati
Una struttura (struct d’ora in poi) è un tipo di dati personalizzato che ti permette di raggruppare e denominare più valori correlati che formano un gruppo significativo. Se sei familiare con un linguaggio orientato agli oggetti, una struct è simile agli attributi di dati di un oggetto. In questo capitolo, confronteremo le tuple con le struct per costruire su ciò che già conosci e dimostrare quando le struct sono un modo migliore per raggruppare dati.
Dimostreremo come definire e istanziare le struct. Discuteremo come definire funzioni associate, in particolare il tipo di funzioni associate chiamate metodi (method), per specificare il comportamento associato a un type struct. Le struct ed enum (discussi nel Capitolo 6) sono i blocchi di costruzione per creare nuovi type nel dominio del tuo programma per sfruttare appieno il controllo dei type in fase di compilazione di Rust.
Definire e Istanziare le Struct
Le struct sono simili alle tuple, discussi nella sezione “Il Type Tupla”, in quanto entrambi possono contenere più valori correlati. Come per le tuple, i componenti di una struct possono essere di type diversi. A differenza delle tuple, in una struct puoi denominare ogni pezzo di dati in modo che sia chiaro il significato dei valori. L’aggiunta di questi nomi significa che le struct sono più flessibili delle tuple: non devi fare affidamento sull’ordine dei dati per specificare o accedere ai valori di un’istanza.
Per definire una struct, inseriamo la parola chiave struct e diamo un nome
all’intera struct. Il nome di una struct dovrebbe descrivere il significato
dei dati raggruppati insieme. Poi, all’interno di parentesi graffe, definiamo i
nomi e i type dei pezzi di dati, che chiamiamo campi (field in inglese).
Ad esempio, il Listato 5-1 mostra una struct che memorizza informazioni su un
account utente.
struct Utente { attivo: bool, nome_utente: String, email: String, numero_accessi: u64, } fn main() {}
UtentePer utilizzare una struct dopo averla definita, creiamo un’istanza di quella
struct specificando valori concreti per ciascuno dei campi. Creiamo un’istanza
indicando il nome della struct e poi aggiungendo parentesi graffe contenenti
coppie chiave: valore, dove le chiavi sono i nomi dei campi e i valori sono
i dati che vogliamo memorizzare in quei campi. Non dobbiamo specificare i campi
nello stesso ordine in cui li abbiamo dichiarati nella struct. In altre
parole, la definizione della struct è come un modello generale per il type,
e le istanze riempiono quel modello con dati particolari per creare valori del
type. Ad esempio, possiamo dichiarare un utente particolare come mostrato nel
Listato 5-2.
struct Utente { attivo: bool, nome_utente: String, email: String, numero_accessi: u64, } fn main() { let utente1 = Utente { attivo: true, nome_utente: String::from("qualcuno123"), email: String::from("qualcuno@mia_mail.com"), numero_accessi: 1, }; }
UtentePer ottenere un valore specifico da una struct, usiamo la notazione col punto.
Ad esempio, per accedere all’indirizzo email di questo utente, usiamo
utente1.email. Se l’istanza è mutabile, possiamo cambiare un valore usando la
notazione col punto assegnando un valore a un campo in particolare. Il Listato
5-3 mostra come modificare il valore del campo email di un’istanza Utente
mutabile.
struct Utente { attivo: bool, nome_utente: String, email: String, numero_accessi: u64, } fn main() { let mut utente1 = Utente { attivo: true, nome_utente: String::from("qualcuno123"), email: String::from("qualcuno@mia_mail.com"), numero_accessi: 1, }; user1.email = String::from("nuova_email@mia_mail.com"); }
email di un’istanza UtenteNota che l’intera istanza deve essere mutabile; Rust non ci permette di contrassegnare solo alcuni campi come mutabili. Come per qualsiasi espressione, possiamo costruire una nuova istanza della struct come ultima espressione nel corpo di una funzione per restituire implicitamente quella nuova istanza.
Il Listato 5-4 mostra la funzione nuovo_utente che restituisce un’istanza
Utente con l’email e il nome utente indicati. Il campo attivo assume il
valore true e numero_accessi prende il valore di 1.
struct Utente { attivo: bool, nome_utente: String, email: String, numero_accessi: u64, } fn nuovo_utente(email: String, nuome_utente: String) -> Utente { User { attivo: true, nuome_utente: nuome_utente, email: email, numero_accessi: 1, } } fn main() { let utente1 = nuovo_utente( String::from("qualcuno@mia_mail.com"), String::from("qualcuno123"), ); }
nuovo_utente che prende una email e un nome utente per ritornare un’istanza UtenteHa senso chiamare i parametri della funzione con lo stesso nome dei campi della
struct, ma dover ripetere i nomi dei campi email e nome_utente e delle
variabili è un po’ noioso. Se la struct avesse più campi, la ripetizione di
ogni nome diventerebbe ancora più fastidiosa. Per fortuna esiste una comoda
scorciatoia!
Utilizzare la Sintassi Abbreviata di Inizializzazione
Poiché i nomi dei parametri e i nomi dei campi della struct sono esattamente
gli stessi, possiamo usare la sintassi di inizializzazione abbreviata dei campi
(field init shorthand) per riscrivere la funzione nuovo_utente in modo che
si comporti esattamente allo stesso modo ma senza la ripetizione di
nome_utente e email, come mostrato nel Listato 5-5.
struct Utente { attivo: bool, nome_utente: String, email: String, numero_accessi: u64, } fn nuovo_utente(email: String, nome_utente: String) -> Utente { Utente { attivo: true, nome_utente, email, numero_accessi: 1, } } fn main() { let utente1 = nuovo_utente( String::from("qualcuno@mia_mail.com"), String::from("qualcuno123"), ); }
nuovo_utente che usa la sintassi abbreviata perché i campi e i parametri nome_utente e email hanno lo stesso nomeQui stiamo creando una nuova istanza della struct Utente, che ha un campo
chiamato email. Vogliamo impostare il valore del campo email sul valore del
parametro email della funzione nuovo_utente. Dato che il campo email e il
parametro email hanno lo stesso nome, dobbiamo solo scrivere email invece di
email: email.
Creare Istanze con la Sintassi di Aggiornamento delle Struct
Spesso è utile creare una nuova istanza di una struct che include la maggior parte dei valori da un’altra istanza dello stesso type, ma con alcune modifiche. Puoi farlo usando la sintassi di aggiornamento delle struct (struct update).
Per prima cosa, nel Listato 5-6 mostriamo come creare regolarmente una nuova
istanza Utente in utente2, senza la sintassi di aggiornamento. Impostiamo un
nuovo valore per email ma per il resto utilizziamo gli stessi valori di
utente1 creati nel Listato 5-2.
struct Utente { attivo: bool, nome_utente: String, email: String, numero_accessi: u64, } fn main() { // --taglio-- let utente1 = Utente { email: String::from("qualcuno@mia_mail.com"), nome_utente: String::from("qualcuno123"), attivo: true, numero_accessi: 1, }; let utente2 = Utente { attivo: utente1.attivo, nome_utente: utente1.nome_utente, email: String::from("altra_mail@example.com"), numero_accessi: utente1.numero_accessi, }; }
Utente con gli stessi valori tranne uno di utente1Utilizzando la sintassi di aggiornamento, possiamo ottenere lo stesso effetto
con meno codice, come mostrato nel Listato 5-7. La sintassi .. specifica che i
restanti campi non impostati esplicitamente dovrebbero avere lo stesso valore
dei campi nell’istanza data.
struct Utente { attivo: bool, nome_utente: String, email: String, numero_accessi: u64, } fn main() { // --taglio-- let utente1 = Utente { email: String::from("qualcuno@mia_mail.com"), nome_utente: String::from("qualcuno123"), attivo: true, numero_accessi: 1, }; let utente2 = Utente { email: String::from("altra_mail@example.com"), ..utente1 }; }
email per un’istanza di Utente, ma utilizzando o restanti valori da utente1Anche il codice nel Listato 5-7 crea un’istanza in utente2 che ha un valore
diverso per email ma ha gli stessi valori per i campi nome_utente, attivo
e numero_accessi di utente1. La parola chiave ..utente1 deve venire per
ultima per specificare che tutti i campi rimanenti dovrebbero ottenere i propri
valori dai campi corrispondenti in utente1, ma possiamo scegliere di
specificare i valori per tutti i campi che vogliamo in qualsiasi ordine,
indipendentemente dall’ordine dei campi nella definizione della struct.
Nota che la sintassi di aggiornamento utilizza = come un assegnazione; questo
perché sposta i dati, proprio come abbiamo visto nella sezione ”Interazione tra
Variabili e Dati con Move”. In questo esempio, non
possiamo più utilizzare utente1 dopo aver creato utente2 perché la String
nel campo nome_utente di utente1 è stata spostata in utente2. Se avessimo
fornito a utente2 nuovi valori String sia per l’email che per
nome_utente e quindi avessimo utilizzato solo i valori attivo e
numero_accessi di utente1, utente1 sarebbe ancora valido dopo aver creato
utente2. Sia attivo che numero_accessi sono type che implementano il
trait Copy, quindi si applicherebbe il comportamento discusso nella sezione
”Duplicare dati sullo Stack”. In questo esempio
possiamo ancora utilizzare utente1.email, perché il suo valore non è stato
spostato da utente1.
Creare Type Diversi con Struct Tupla
Rust supporta anche struct che assomigliano alle tuple, chiamate struct
tupla (tuple struct). Le struct tupla hanno il significato aggiuntivo che
il nome della struct fornisce, ma non hanno nomi associati ai loro campi;
piuttosto, hanno solo i type dei campi. Le struct tupla sono utili quando si
vuole dare un nome all’intera tupla e renderla un type diverso da altre tuple,
e quando denominare ogni campo come in una struct regolare sarebbe poco utile
o ridondante. Per definire una struct tupla, inizia con la parola chiave
struct e il nome della struct seguito dai type della tupla. Ad esempio,
qui definiamo e utilizziamo due struct tupla chiamate Colore e Punto:
struct Colore(i32, i32, i32); struct Punto(i32, i32, i32); fn main() { let nero = Colore(0, 0, 0); let origine = Punto(0, 0, 0); }
Tieni presente che i valori nero e origine sono di type diverso perché
sono istanze di struct tupla diverse. Ogni struct che definisci diventa un
nuovo type a sé stante, anche se i campi all’interno della struct potrebbero
avere gli stessi type. Ad esempio, una funzione che accetta un parametro di
type Colore non può accettare un Punto come argomento, anche se entrambi i
type sono costituiti da tre valori i32. Oltretutto, le istanze di una
struct tupla sono simili alle tuple in quanto puoi destrutturarle nelle loro
singole parti e puoi utilizzare un . seguito dall’indice per accedere a un
singolo valore. A differenza delle tuple però, le struct tupla richiedono di
nominare il type di struct quando le destrutturi. Ad esempio, scriveremo
let Punto(x, y, z) = origine; per destrutturare i valori del Punto origine
in variabili chiamate x, y e z.
Definire Struct Unit
Puoi anche definire struct che non hanno campi! Queste sono chiamate struct
unit (unit-like struct) perché si comportano in modo simile a (), il
type unit menzionato nella sezione “Il Type Tupla”. Le struct unit possono essere utili quando è necessario implementare un
trait su un type ma non si hanno dati che si vogliono memorizzare nel type
stesso.
Parleremo dei trait nel Capitolo 10.
Ecco un esempio di dichiarazione e istanziazione di una struct unit chiamata
SempreUguale:
struct SempreUguale; fn main() { let suggetto = SempreUguale; }
Per definire SempreUguale, utilizziamo la parola chiave struct, il nome che
vogliamo e quindi un punto e virgola. Non c’è bisogno di parentesi graffe o
tonde! Quindi possiamo ottenere un’istanza di SempreUguale nella variabile
soggetto in un modo simile: utilizzando il nome che abbiamo definito, senza
parentesi graffe o tonde. Immagina che in seguito implementeremo il
comportamento per questo type in modo tale che ogni istanza di SempreUguale
sia sempre uguale a ogni istanza di qualsiasi altro type, magari per avere un
risultato noto a scopo di test. Non avremmo bisogno di dati per implementare
quel comportamento! Vedremo nel Capitolo 10 come definire i trait e
implementarli su qualsiasi type, comprese le struct unit.
Ownership dei Dati di Struct
Nella definizione della struct Utente, abbiamo utilizzato il type
String invece del type slice di stringa &str. Questa è una scelta
deliberata perché vogliamo che ogni istanza di questa struct possieda tutti
i suoi dati e che tali dati siano validi per tutto il tempo in cui la struct
è valida.
È anche possibile che le struct memorizzino reference a dati posseduti da qualcos’altro, ma per farlo è necessario l’uso di lifetime, una funzionalità di Rust di cui parleremo nel Capitolo 10. Lifetime garantisce che i dati a cui fa riferimento una struct siano validi finché lo è la struct. Supponiamo che provi a memorizzare un reference in una struct senza specificare la lifetime, come nel seguente esempio in src/main.rs; questo non funzionerà:
struct Utente {
attivo: bool,
nome_utente: &str,
email: &str,
numero_accessi: u64,
}
fn main() {
let user1 = Utente {
attivo: true,
nome_utente: "qualcuno123",
email: "qualcuno@mia_mail.com",
numero_accessi: 1,
};
}Il compilatore si lamenterà richiedendo degli identificatori di lifetime:
$ cargo run
Compiling struct v0.1.0 (file:///progetti/structs)
error[E0106]: missing lifetime specifier
--> src/main.rs:3:18
|
3 | nome_utente: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct Utente<'a> {
2 | attivo: bool,
3 ~ nome_utente: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:4:12
|
4 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct Utente<'a> {
2 | attivo: bool,
3 | nome_utente: &str,
4 ~ email: &'a str,
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `struct` (bin "struct") due to 2 previous errors
Nel Capitolo 10, discuteremo come risolvere questi errori in modo da poter
memorizzare reference nelle struct, ma per ora risolveremo errori come
questi usando type con ownership come String invece di reference come
&str.
Un Esempio di Programma Che Usa Struct
Per capire quando potremmo voler usare le struct, scriviamo un programma che calcola l’area di un rettangolo. Partiremo usando variabili singole e poi riscriveremo il programma un pezzo per volta finché non useremo le struct.
Creiamo un nuovo progetto binario con Cargo chiamato rettangoli che prenderà la larghezza e l’altezza di un rettangolo specificate in pixel e calcolerà l’area del rettangolo. Il Listato 5-8 mostra un breve programma con un modo per farlo nel file src/main.rs del nostro progetto.
fn main() { let larghezza1 = 30; let altezza1 = 50; println!( "L'area del rettangolo è di {} pixel quadrati.", area(larghezza1, altezza1) ); } fn area(larghezza: u32, altezza: u32) -> u32 { larghezza * altezza }
Ora esegui questo programma usando cargo run:
$ cargo run
Compiling rettangoli v0.1.0 (file:///progetti/rettangoli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.15s
Running `target/debug/rettangoli`
L'area del rettangolo è di 1500 pixel quadrati.
Questo codice riesce a calcolare l’area del rettangolo chiamando la funzione
area con ogni dimensione, ma possiamo fare di più per rendere il codice chiaro
e leggibile.
Il problema con questo codice è evidente nella firma di area:
fn main() {
let larghezza1 = 30;
let altezza1 = 50;
println!(
"L'area del rettangolo è di {} pixel quadrati.",
area(larghezza1, altezza1)
);
}
fn area(larghezza: u32, altezza: u32) -> u32 {
larghezza * altezza
}La funzione area dovrebbe calcolare l’area di un rettangolo singolo, ma la
funzione che abbiamo scritto ha due parametri, e non è chiaro da nessuna parte
nel nostro programma che i parametri siano correlati. Sarebbe più leggibile e
più gestibile raggruppare larghezza e altezza insieme. Abbiamo già discusso un
modo per farlo nella sezione “Il Type Tupla”
del Capitolo 3: usando le tuple.
Riscrivere con le Tuple
Il Listato 5-9 mostra un’altra versione del nostro programma che usa le tuple.
fn main() { let rettangolo1 = (30, 50); println!( "L'area del rettangolo è di {} pixel quadrati.", area(rettangolo1) ); } fn area(dimensioni: (u32, u32)) -> u32 { dimensioni.0 * dimensioni.1 }
Da un lato, questo programma è migliore. Le tuple ci permettono di aggiungere un po’ di struttura, e ora stiamo passando un solo argomento. Ma dall’altro, questa versione è meno chiara: le tuple non nominano i loro elementi, quindi dobbiamo indicizzare le parti della tupla, rendendo il nostro calcolo meno ovvio.
Confondere larghezza e altezza non avrebbe importanza per il calcolo dell’area,
ma se volessimo disegnare il rettangolo sullo schermo, importerebbe! Dovremmo
tenere a mente che larghezza è l’indice della tupla 0 e altezza è l’indice
della tupla 1. Questo sarebbe ancora più difficile da capire e ricordare per
qualcun altro che in futuro leggesse o usasse il nostro codice. Poiché non
abbiamo reso palese il significato dei nostri dati nel codice, è più facile
introdurre errori.
Riscrivere con le Struct
Usiamo la struct per aggiungere significato etichettando i dati. Possiamo trasformare la tupla che stiamo usando in una struct con un nome per l’intero e nomi per le parti, come mostrato nel Listato 5-10.
struct Rettangolo { larghezza: u32, altezza: u32, } fn main() { let rettangolo1 = Rettangolo { larghezza: 30, altezza: 50, }; println!( "L'area del rettangolo è di {} pixel quadrati.", area(&rettangolo1) ); } fn area(rettangolo: &Rettangolo) -> u32 { rettangolo.larghezza * rettangolo.altezza }
RettangoloQui abbiamo definito una struct e l’abbiamo chiamata Rettangolo. All’interno
delle parentesi graffe, abbiamo definito i campi come larghezza e altezza,
entrambi di type u32. Poi, in main, abbiamo creato un’istanza particolare
di Rettangolo che ha larghezza 30 e altezza 50.
La nostra funzione area è ora definita con un solo parametro, che abbiamo
chiamato Rettangolo, il cui type è un reference immutabile a un’istanza
della struct Rettangolo. Come menzionato nel Capitolo 4, ci serve solo
prendere in prestito la struct piuttosto che averne la ownership. In questo
modo, main mantiene la sua ownership e può continuare a usare rettangolo1,
che è il motivo per cui usiamo & nella firma della funzione e dove chiamiamo
la funzione.
La funzione area accede ai campi larghezza e altezza dell’istanza di
Rettangolo (nota che accedere ai campi di un’istanza di struct presa in
prestito non muove i valori dei campi, motivo per cui spesso si vedono
reference di struct). La nostra firma della funzione per area ora dice
esattamente ciò che intendiamo: calcolare l’area di Rettangolo, usando i suoi
campi larghezza e altezza. Questo comunica che larghezza e altezza sono
correlate tra loro e fornisce nomi descrittivi ai valori invece di usare gli
indici della tupla 0 e 1. Questo è un vantaggio in termini di chiarezza.
Aggiungere Funzionalità con i Trait Derivati
Sarebbe utile poter stampare un’istanza di Rettangolo mentre eseguiamo il
debug del nostro programma e vedere i valori di tutti i suoi campi. Il Listato
5-11 prova a usare la macro println! come l’abbiamo
usata nei capitoli precedenti. Questo però non funzionerà.
struct Rettangolo {
larghezza: u32,
altezza: u32,
}
fn main() {
let rettangolo1 = Rettangolo {
larghezza: 30,
altezza: 50,
};
println!("rettangolo1 è {rettangolo1}");
}RettangoloQuando compiliamo questo codice, otteniamo un errore con questo messaggio principale:
error[E0277]: `Rettangolo` doesn't implement `std::fmt::Display`
La macro println! può fare molti tipi di formattazione e, come impostazione
predefinita, le parentesi graffe dicono a println! di usare una formattazione
conosciuta come Display, output pensato per il l’utente finale che utilizzerà
il programma. I type primitivi che abbiamo visto finora implementano Display
di default perché c’è un solo modo in cui vorresti mostrare un 1 o qualsiasi
altro type primitivo a un utente. Ma con le struct il modo in cui println!
dovrebbe formattare l’output è meno chiaro perché ci sono più possibilità di
visualizzazione: vuoi le virgole o no? Vuoi stampare le parentesi graffe? Devono
essere mostrati tutti i campi? A causa di questa ambiguità, Rust non cerca di
indovinare ciò che vogliamo, e le struct non hanno un’implementazione standard
di Display da usare con println! e il segnaposto {}.
Se continuiamo a leggere gli errori, troveremo questa nota utile:
= help: the trait `std::fmt::Display` is not implemented for `Rettangolo`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
Proviamolo! La chiamata alla macro println! ora assomiglierà a
println!("rettangolo1 è {rettangolo1:?}");. Inserire lo specificatore :?
all’interno delle parentesi graffe dice a println! che vogliamo usare un
formato di output chiamato Debug. Il trait Debug ci permette di stampare
la nostra struct in un modo utile per gli sviluppatori, così possiamo vedere
il suo valore mentre eseguiamo il debug del nostro codice.
Compila il codice con questa modifica. Accidenti! Otteniamo ancora un errore:
error[E0277]: `Rettangolo` doesn't implement `Debug`
Ma di nuovo, il compilatore ci dà una nota utile:
= help: the trait `Debug` is not implemented for `Rettangolo`
= note: add `#[derive(Debug)]` to `Rettangolo` or manually `impl Debug for Rettangolo`
Rust include effettivamente funzionalità per stampare informazioni di debug,
ma dobbiamo esplicitamente dichiararlo per rendere disponibile quella
funzionalità alla nostra struct. Per farlo, aggiungiamo l’attributo esterno
#[derive(Debug)] appena prima della definizione della struct, come mostrato
nel Listato 5-12.
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } fn main() { let rettangolo1 = Rettangolo { larghezza: 30, altezza: 50, }; println!("rettangolo1 è {rettangolo1:?}"); }
Debug e stampare Rettangolo usando la formattazione di debugOra quando eseguiamo il programma, non otterremo errori e vedremo il seguente output:
$ cargo run
Compiling rettangoli v0.1.0 (file:///progetti/rettangoli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/rettangoli`
rettangolo1 è Rettangolo { larghezza: 30, altezza: 50 }
Bene! Non è l’output più bello, ma mostra i valori di tutti i campi per questa
istanza, il che aiuterebbe sicuramente durante lo sviluppo e il debug del
programma. Quando abbiamo struct più grandi, è utile avere un output un po’
più facile da leggere; in quei casi, possiamo usare {:#?} invece di {:?}
nella stringa di println!. In questo esempio, usare lo stile {:#?} produrrà
il seguente output:
$ cargo run
Compiling rettangoli v0.1.0 (file:///progetti/rettangoli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/rettangoli`
rettangolo1 è Rettangolo {
larghezza: 30,
altezza: 50,
}
Un altro modo per stampare un valore usando il formato Debug è usare la macro
dbg!, che prende ownership di un’espressione (a differenza di
println!, che prende un reference), stampa file e numero di linea di dove
quella chiamata a dbg! si verifica nel codice insieme al valore risultante di
quell’espressione, e restituisce l’ownership del valore.
Nota: Chiamare la macro dbg! stampa sullo stream di errore standard (
stderr), a differenza diprintln!, che stampa sullo stream di output standard (stdout). Parleremo meglio distderrestdoutnella sezione “Scrivere i Messaggi di Errore su Standard Error invece che su Standard Output” del Capitolo 12.
Ecco un esempio in cui siamo interessati al valore che viene assegnato al campo
larghezza, così come al valore dell’intera struct in rettangolo1:
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } fn main() { let scala = 2; let rettangolo1 = Rettangolo { larghezza: dbg!(30 * scala), altezza: 50, }; dbg!(&rettangolo1); }
Possiamo mettere dbg! attorno all’espressione 30 * scala e, poiché dbg!
restituisce l’ownership del valore dell’espressione, il campo larghezza
otterrà lo stesso valore come se non avessimo la chiamata a dbg! lì. Non
vogliamo che dbg! prenda ownership di rettangolo1, quindi usiamo un
riferimento a rettangolo1 nella chiamata successiva. Ecco come appare l’output
di questo esempio:
$ cargo run
Compiling rettangoli v0.1.0 (file:///progetti/rettangoli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/rettangoli`
[src/main.rs:10:20] 30 * scala = 60
[src/main.rs:14:5] &rettangolo1 = Rettangolo {
larghezza: 60,
altezza: 50,
}
Possiamo vedere che il primo frammento di output proviene da src/main.rs riga
10 dove stiamo facendo il debug dell’espressione 30 * scala, e il suo valore
risultante è 60 (la formattazione Debug implementata per gli integer è di
stampare solo il loro valore). La chiamata a dbg! alla riga 14 di
src/main.rs stampa il valore di &rettangolo1, che è la struct
Rettangolo. Questo output usa la formattazione Debug “pretty” del type
Rettangolo. La macro dbg! può essere davvero utile quando stai cercando di
capire cosa sta facendo il tuo codice!
Oltre al trait Debug, Rust fornisce diversi trait che possiamo usare con
l’attributo derive che possono aggiungere comportamenti utili ai nostri type
personalizzati. Quei trait e i loro comportamenti sono elencati
nell’Appendice C. Tratteremo come implementare questi
trait con un comportamento personalizzato e come creare i propri trait nel
Capitolo 10. Ci sono anche molti attributi oltre a derive; per maggiori
informazioni, vedi la sezione “Attributes” del Rust Reference.
La nostra funzione area è molto specifica: calcola solo l’area dei rettangoli.
Sarebbe utile legare questo comportamento più strettamente alla nostra struct
Rettangolo perché non funzionerà con altri type. Vediamo come possiamo
continuare a riscrivere questo codice trasformando la funzione area in un
metodo (method) definito sul nostro type Rettangolo.
Metodi
I metodi (method) sono simili alle funzioni: le dichiariamo con la parola
chiave fn e un nome, possono avere parametri e un valore di ritorno, e
contengono del codice che viene eseguito quando il metodo viene chiamato da
un’altra parte. Diversamente dalle funzioni, i metodi sono definiti nel contesto
di una struct (o di un’enum o di un trait object, che tratteremo nel
Capitolo 6 e Capitolo 18, rispettivamente), e il loro primo parametro è sempre self, che
rappresenta l’istanza della struct su cui il metodo viene chiamato.
Sintassi dei Metodi
Trasformiamo la funzione area che prende un’istanza di Rettangolo come
parametro rendendola invece un metodo definito sulla struct Rettangolo, come
mostrato nel Listato 5-13.
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } impl Rettangolo { fn area(&self) -> u32 { self.larghezza * self.altezza } } fn main() { let rettangolo1 = Rettangolo { larghezza: 30, altezza: 50, }; println!( "L'area del rettangolo è di {} pixel quadrati.", rettangolo1.area() ); }
area nella struct RettangoloPer definire la funzione nel contesto di Rettangolo, iniziamo un blocco impl
(implementazione) per Rettangolo. Tutto ciò che sta dentro questo blocco
impl sarà associato al type Rettangolo. Poi spostiamo la funzione area
all’interno delle parentesi graffe dell’impl e cambiamo il primo (e in questo
caso, unico) parametro in self nella firma e ovunque nel corpo. In main,
dove chiamavamo la funzione area passando rettangolo1 come argomento,
possiamo invece usare la sintassi dei metodi per chiamare il metodo area
sull’istanza di Rettangolo. La sintassi del metodo va dopo un’istanza:
aggiungiamo un punto seguito dal nome del metodo, parentesi tonde ed eventuali
argomenti.
Nella firma di area usiamo &self invece di rettangolo: &Rettangolo. Il
&self è in realtà l’abbreviazione di self: &Self. All’interno di un blocco
impl, il type Self è un alias del type per cui il blocco impl è stato
scritto. I metodi devono avere un parametro chiamato self di type Self
come primo parametro, quindi Rust permette di abbreviare questo con soltanto il
nome self nella prima posizione dei parametri. Nota che dobbiamo comunque
usare & davanti alla forma abbreviata self per indicare che questo metodo
prende in prestito l’istanza Self, esattamente come facevamo con rettangolo: &Rettangolo. I metodi possono prendere la ownership di self, prendere un
reference immutabile a self, come abbiamo fatto qui, oppure prendere un
reference mutabile a self, proprio come possono fare con qualsiasi altro
parametro.
Qui abbiamo scelto &self per lo stesso motivo per cui abbiamo usato
&Rettangolo nella versione precedente: non serve che prendiamo la ownership,
vogliamo solo leggere i dati nella struct, non modificarli. Se volessimo
modificare l’istanza su cui chiamiamo il metodo come parte di ciò che il metodo
fa, useremmo &mut self come primo parametro. Avere un metodo che prende la
ownership dell’istanza usando semplicemente self come primo parametro è
raro; questa tecnica è solitamente usata quando il metodo trasforma self in
qualcos’altro e si vuole impedire al chiamante di usare l’istanza originale dopo
la trasformazione.
La ragione principale per usare i metodi invece delle funzioni, oltre a fornire
la sintassi dei metodi e a non dover ripetere il type di self in ogni firma
dei metodi, è per organizzazione. Abbiamo messo tutte le cose che possiamo fare
con un’istanza di un type in un unico blocco impl invece di costringere chi
dovrà in futuro leggere o manutenere il nostro codice a cercare le funzionalità
di Rettangolo in vari posti nella libreria che forniamo.
Nota che possiamo scegliere di dare a un metodo lo stesso nome di uno dei campi
della struct. Per esempio, possiamo definire un metodo su Rettangolo che si
chiama anch’esso larghezza:
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } impl Rettangolo { fn larghezza(&self) -> bool { self.larghezza > 0 } } fn main() { let rettangolo1 = Rettangolo { larghezza: 30, altezza: 50, }; if rettangolo1.larghezza() { println!("La larghezza del rettangolo è > 0; è {}", rettangolo1.larghezza); } }
Qui scegliamo di fare in modo che il metodo larghezza ritorni true se il
valore nel campo larghezza dell’istanza è maggiore di 0 e false se il
valore è 0: possiamo usare un campo all’interno di un metodo con lo stesso
nome per qualunque scopo. In main, quando seguiamo rettangolo1.larghezza con
le parentesi tonde, Rust sa che si intende il metodo larghezza. Quando non
usiamo le parentesi tonde, Rust sa che intendiamo il campo larghezza.
Spesso, ma non sempre, quando diamo a un metodo lo stesso nome di un campo vogliamo che esso ritorni soltanto il valore del campo e non faccia altro. I metodi di questo tipo sono chiamati getter (metodi di incapsulamento) e Rust non li implementa automaticamente per i campi della struct come fanno alcuni altri linguaggi di programmazione. I getter sono utili perché puoi rendere il campo privato ma il metodo pubblico, abilitando così accesso in sola lettura a quel campo come parte dell’API pubblica del type. Discuteremo cosa sono pubblico e privato e come designare un campo o un metodo come pubblico o privato nel Capitolo 7.
Dov’è l’Operatore ->?
In C e C++ si usano due operatori diversi per accedere ai membri: si usa .
quando si lavora direttamente con un oggetto, e -> quando si lavora con un
puntatore all’oggetto e prima bisogna de-referenziarlo. In C++, questi
operatori possono essere usati per chiamare i metodi; in C, sono usati solo
per accedere ai campi delle struct. In altre parole, se oggetto è un
puntatore, oggetto->qualcosa() è simile a (*oggetto).qualcosa().
Rust non ha un equivalente dell’operatore ->; invece, Rust ha una
funzionalità chiamata referenziamento e de-referenziamento automatico
(automatic referencing and dereferencing). Chiamare i metodi è uno dei pochi
posti in Rust che implementa questa funzionalità.
Ecco come funziona: quando chiami un metodo con oggetto.qualcosa(), Rust
aggiunge automaticamente &, &mut, o * affinché oggetto corrisponda
alla firma del metodo. In altre parole, i seguenti sono equivalenti:
#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Punto { x: f64, y: f64, } impl Punto { fn distanza(&self, altro: &Punto) -> f64 { let x_quad = f64::powi(altro.x - self.x, 2); let y_quad = f64::powi(altro.y - self.y, 2); f64::sqrt(x_quad + y_quad) } } let p1 = Punto { x: 0.0, y: 0.0 }; let p2 = Punto { x: 5.0, y: 6.5 }; p1.distanza(&p2); (&p1).distanza(&p2); }
Il primo sembra molto più pulito. Questo comportamento di referencing
automatico funziona perché i metodi hanno un receiver (recettore) chiaro,
il type di self. Dato il receiver e il nome di un metodo, Rust può
determinare in modo definitivo se il metodo sta leggendo (&self), mutando
(&mut self), o consumando (self). Il fatto che Rust renda implicito il
borrowing per i receiver dei metodi è una parte importante per rendere
l’ownership ergonomica nella pratica.
Metodi con Più Parametri
Esercitiamoci ad usare i metodi implementando un secondo metodo sulla struct
Rettangolo. Questa volta vogliamo che un’istanza di Rettangolo prenda
un’altra istanza di Rettangolo e ritorni true se la seconda Rettangolo può
entrare completamente dentro self (la prima Rettangolo); altrimenti dovrebbe
ritornare false. Cioè, una volta definito il metodo può_contenere, dovremmo
poter scrivere il programma mostrato nel Listato 5-14.
fn main() {
let rettangolo1 = Rettangolo {
larghezza: 30,
altezza: 50,
};
let rettangolo2 = Rettangolo {
larghezza: 10,
altezza: 40,
};
let rettangolo3 = Rettangolo {
larghezza: 60,
altezza: 45,
};
println!("Può rettangolo1 contenere rettangolo2? {}", rettangolo1.può_contenere(&rettangolo2));
println!("Può rettangolo1 contenere rettangolo3? {}", rettangolo1.può_contenere(&rettangolo3));
}può_contenere ancora da scrivereL’output atteso sarà il seguente perché entrambe le dimensioni di rettangolo2
sono più piccole delle dimensioni di rettangolo1, ma rettangolo3 è più larga
di rettangolo1:
Può rettangolo1 contenere rettangolo2? true
Può rettangolo1 contenere rettangolo3? false
Sappiamo che vogliamo definire un metodo, quindi sarà all’interno del blocco
impl Rettangolo. Il nome del metodo sarà può_contenere, e prenderà un
reference immutabile di un’altra Rettangolo come parametro. Possiamo dedurre
il type del parametro osservando il codice che chiama il metodo:
rettangolo1.può_contenere(&rettangolo2) passa &rettangolo2, che è un
reference immutabile di rettangolo2, un’istanza di Rettangolo. Questo ha
senso perché abbiamo solo bisogno di leggere rettangolo2 (invece di
modificarlo, il che richiederebbe un reference mutabile), e vogliamo che
main mantenga l’ownership di rettangolo2 così da poterlo usare di nuovo
dopo la chiamata a può_contenere. Il valore di ritorno di può_contenere sarà
un booleano, e l’implementazione verificherà se la larghezza e l’altezza di
self sono maggiori rispetto alla larghezza e all’altezza dell’altra
Rettangolo, rispettivamente. Aggiungiamo il nuovo metodo può_contenere al
blocco impl del Listato 5-13, come mostrato nel Listato 5-15.
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } impl Rettangolo { fn area(&self) -> u32 { self.larghezza * self.altezza } fn può_contenere(&self, altro: &Rettangolo) -> bool { self.larghezza > altro.larghezza && self.altezza > altro.altezza } } fn main() { let rettangolo1 = Rettangolo { larghezza: 30, altezza: 50, }; let rettangolo2 = Rettangolo { larghezza: 10, altezza: 40, }; let rettangolo3 = Rettangolo { larghezza: 60, altezza: 45, }; println!("Può rettangolo1 contenere rettangolo2? {}", rettangolo1.può_contenere(&rettangolo2)); println!("Può rettangolo1 contenere rettangolo3? {}", rettangolo1.può_contenere(&rettangolo3)); }
può_contenere in Rettangolo che riceve un’altra istanza di Rettangolo come parametroQuando eseguiamo questo codice con la funzione main del Listato 5-14,
otterremo l’output desiderato. I metodi possono prendere parametri multipli che
aggiungiamo alla firma dopo il parametro self, e quei parametri funzionano
proprio come i parametri nelle funzioni.
Funzioni Associate
Tutte le funzioni definite all’interno di un blocco impl sono chiamate
funzioni associate (associated functions) perché sono associate al type
nominato dopo la parola impl. Possiamo definire funzioni associate che non
hanno self come primo parametro (e quindi non sono metodi) perché non hanno
bisogno di un’istanza del type per svolgere il loro compito. Ne abbiamo già
usata una: la funzione String::from implementata sul type String.
Le funzioni associate che non sono metodi sono spesso usate come costruttori
che ritornano una nuova istanza della struct. Spesso si chiamano new perché
new non è una parola chiave e non è incorporata nel linguaggio. Per esempio,
potremmo decidere di fornire una funzione associata chiamata quadrato che
prende un parametro di dimensione e lo usa sia come larghezza sia come altezza,
rendendo più semplice creare un Rettangolo quadrato invece di dover
specificare lo stesso valore due volte:
File: src/main.rs
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } impl Rettangolo { fn quadrato(dimensione: u32) -> Self { Self { larghezza: dimensione, altezza: dimensione, } } } fn main() { let quad = Rectangle::quadrato(3); }
La parola chiave Self nel type di ritorno e nel corpo della funzione è un
alias per il type che appare dopo la parola chiave impl, che in questo caso
è Rettangolo.
Per chiamare questa funzione associata, usiamo la sintassi :: con il nome
della struct; let quad = Rettangolo::quadrato(3); è un esempio. Questa
funzione è organizzata nel namespace della struct: la sintassi :: è usata
sia per le funzioni associate sia per i namespace creati dai moduli. Parleremo
più approfonditamente dei moduli nel Capitolo 7.
Blocchi impl Multipli
A ogni struct è permesso avere più blocchi impl. Per esempio, il Listato
5-15 è equivalente al codice mostrato nel Listato 5-16, che ha ognuno dei metodi
nel proprio blocco impl.
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } impl Rettangolo { fn area(&self) -> u32 { self.larghezza * self.altezza } } impl Rettangolo { fn può_contenere(&self, altro: &Rectangle) -> bool { self.larghezza > altro.larghezza && self.altezza > altro.altezza } } fn main() { let rettangolo1 = Rettangolo { larghezza: 30, altezza: 50, }; let rettangolo2 = Rettangolo { larghezza: 10, altezza: 40, }; let rettangolo3 = Rettangolo { larghezza: 60, altezza: 45, }; println!("Può rettangolo1 contenere rettangolo2? {}", rettangolo1.può_contenere(&rettangolo2)); println!("Può rettangolo1 contenere rettangolo3? {}", rettangolo1.può_contenere(&rettangolo3)); }
implNon c’è motivo di separare questi metodi in più blocchi impl in questo caso,
ma questa è una sintassi valida. Vedremo un caso in cui più blocchi impl sono
utili nel Capitolo 10, dove discuteremo i type generici e i trait.
Riepilogo
Le struct ti permettono di creare type personalizzati significativi per il
tuo dominio. Usando le struct, puoi mantenere pezzi di dati correlati tra loro
e dare un nome a ciascun pezzo per rendere il codice chiaro. Nei blocchi impl
puoi definire funzioni associate al tuo type, e i metodi sono un tipo di
funzione associata che ti permette di specificare il comportamento che le
istanze delle tue struct hanno.
Ma le struct non sono l’unico modo per creare type personalizzati: passiamo ad un altro type di Rust, le enumerazioni, per aggiungere un altro strumento alla tua cassetta degli attrezzi.
Enumerazioni e Corrispondenza dei Pattern
In questo capitolo parleremo delle enumerazioni, abbreviato in enum, termine
che sarà usato d’ora in poi. Le enum permettono di definire un type
enumerando le sue possibili varianti. Per prima cosa definiremo e useremo
un’enum per mostrare come un’enum possa codificare un significato insieme ai
dati. Poi esploreremo un’enum particolarmente utile, chiamato Option, che
consente di esprimere se un valore può essere o qualcosa o niente. Poi vedremo
come la corrispondenza dei pattern nell’espressione match rende facile
eseguire codice diverso per valori diversi di un’enum. Infine, vedremo come il
costrutto if let sia un altro idioma comodo e conciso disponibile per gestire
le enum nel tuo codice.
Definire un’Enum
Laddove le struct ti danno un modo per raggruppare campi e dati correlati, per
esempio un Rettangolo con i propri larghezza e altezza, le enum ti danno
un modo per indicare che un valore è uno di un insieme possibile di valori. Per
esempio, potremmo voler dire che Rettangolo è una delle possibili forme che
include anche Cerchio e Triangolo. Per farlo, Rust ci permette di codificare
queste possibilità come un’enum.
Esaminiamo una situazione che potremmo voler esprimere nel codice e vediamo perché le enum sono utili e più appropriati delle struct in questo caso. Supponiamo di dover lavorare con gli indirizzi IP. Attualmente, per gli indirizzi IP si usano due standard principali: versione quattro e versione sei. Poiché queste sono le uniche possibilità di indirizzo IP che il nostro programma incontrerà, possiamo enumerare tutte le varianti possibili, da cui il nome enum.
Qualsiasi indirizzo IP può essere o versione quattro o versione sei, ma non entrambi contemporaneamente. Questa proprietà degli indirizzi IP rende la struttura dati enum appropriata perché un valore di enum può essere solo una delle sue varianti. Sia i versione quattro sia i versione sei sono comunque fondamentalmente indirizzi IP, quindi dovrebbero essere trattati come dati dello stesso type quando il codice andrà a gestire situazioni che si applicano agli indirizzi IP d’ogni genere.
Possiamo esprimere questo concetto nel codice definendo un’enum
VersioneIndirizzoIp e elencando le possibili tipologie che un indirizzo IP può
essere: V4 e V6. Queste sono le varianti dell’enum:
enum VersioneIndirizzoIp { V4, V6, } fn main() { let quattro = VersioneIndirizzoIp::V4; let sei = VersioneIndirizzoIp::V6; instrada(VersioneIndirizzoIp::V4); instrada(VersioneIndirizzoIp::V6); } fn instrada(verione_ip: VersioneIndirizzoIp) {}
VersioneIndirizzoIp è ora un type di dato personalizzato che possiamo usare
altrove nel nostro codice.
Valori di Enum
Possiamo creare istanze di ciascuna delle due varianti di VersioneIndirizzoIp
in questo modo:
enum VersioneIndirizzoIp { V4, V6, } fn main() { let quattro = VersioneIndirizzoIp::V4; let sei = VersioneIndirizzoIp::V6; instrada(VersioneIndirizzoIp::V4); instrada(VersioneIndirizzoIp::V6); } fn instrada(verione_ip: VersioneIndirizzoIp) {}
Nota che le varianti dell’enum sono nel namespace del suo identificatore, e
usiamo il doppio-due punti :: per separarle. Questo è utile perché ora
entrambi i valori VersioneIndirizzoIp::V4 e VersioneIndirizzoIp::V6 sono
dello stesso type: VersioneIndirizzoIp. Possiamo quindi, per esempio,
definire una funzione che accetta qualsiasi VersioneIndirizzoIp:
enum VersioneIndirizzoIp { V4, V6, } fn main() { let quattro = VersioneIndirizzoIp::V4; let sei = VersioneIndirizzoIp::V6; instrada(VersioneIndirizzoIp::V4); instrada(VersioneIndirizzoIp::V6); } fn instrada(verione_ip: VersioneIndirizzoIp) {}
E possiamo chiamare questa funzione con entrambe le varianti:
enum VersioneIndirizzoIp { V4, V6, } fn main() { let quattro = VersioneIndirizzoIp::V4; let sei = VersioneIndirizzoIp::V6; instrada(VersioneIndirizzoIp::V4); instrada(VersioneIndirizzoIp::V6); } fn instrada(verione_ip: VersioneIndirizzoIp) {}
L’uso delle enum ha ulteriori vantaggi. Pensando meglio al nostro type per gli indirizzi IP, al momento non abbiamo un modo per memorizzare il vero e proprio indirizzo IP; sappiamo solo di che tipologia si tratta. Dato che hai appena imparato le struct nel Capitolo 5, potresti essere tentato di risolvere questo problema con le struct come mostrato nel Listato 6-1.
fn main() { enum VersioneIndirizzoIp { V4, V6, } struct IpAddr { tipo: VersioneIndirizzoIp, indirizzo: String, } let home = IpAddr { tipo: VersioneIndirizzoIp::V4, indirizzo: String::from("127.0.0.1"), }; let loopback = IpAddr { tipo: VersioneIndirizzoIp::V6, indirizzo: String::from("::1"), }; }
VersioneIndirizzoIp di un indirizzo IP usando una structQui abbiamo definito una struct IpAddr che ha due campi: un campo tipo di
type VersioneIndirizzoIp (l’enum definito prima) e un campo indirizzo di
type String. Abbiamo due istanze di questa struct. La prima è home, e ha
il valore VersioneIndirizzoIp::V4 come suo tipo con l’indirizzo associato
127.0.0.1. La seconda istanza è loopback. Essa ha l’altra variante di
VersioneIndirizzoIp come valore del suo tipo, V6, e ha associato
l’indirizzo ::1. Abbiamo usato una struct per raggruppare i valori tipo e
indirizzo, così la variante è ora associata al valore.
Tuttavia, rappresentare lo stesso concetto usando solo un’enum è più conciso:
invece di un’enum dentro una struct, possiamo mettere i dati direttamente in
ogni variante dell’enum. Questa nuova definizione dell’enum IpAddr indica
che entrambe le varianti V4 e V6 avranno valori String associati:
fn main() { enum IpAddr { V4(String), V6(String), } let home = IpAddr::V4(String::from("127.0.0.1")); let loopback = IpAddr::V6(String::from("::1")); }
Alleghiamo i dati direttamente a ciascuna variante dell’enum, quindi non c’è
bisogno di una struct aggiuntiva. Qui è anche più facile vedere un altro
dettaglio di come funzionano le enum: il nome di ciascuna variante che
definiamo diventa anche una funzione che costruisce un’istanza dell’enum.
Cioè, IpAddr::V4() è una chiamata di funzione che prende un argomento String
e ritorna un’istanza del type IpAddr. Otteniamo automaticamente questa
funzione costruttrice come risultato della definizione dell’enum.
C’è un altro vantaggio nell’usare un’enum invece di una struct: ogni
variante può avere type e quantità diverse di dati associati. Gli indirizzi
versione quattro, ad esempio, avranno sempre quattro componenti numeriche con
valori tra 0 e 255. Se volessimo memorizzare gli indirizzi V4 come quattro
valori u8 ma rappresentare gli indirizzi V6 come una singola String, non
potremmo farlo con un struct. Le enum gestiscono questo caso con facilità:
fn main() { enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let home = IpAddr::V4(127, 0, 0, 1); let loopback = IpAddr::V6(String::from("::1")); }
Abbiamo mostrato diversi modi per definire strutture dati per memorizzare
indirizzi IP versione quattro e versione sei. Tuttavia, risulta che voler
memorizzare indirizzi IP e codificare di quale tipologia siano è così comune che
la libreria standard fornisce una definizione che possiamo usare! Diamo un’occhiata a come la libreria standard definisce IpAddr. Ha
l’esatta enum e le varianti che abbiamo definito e usato, ma incapsula i dati
dell’indirizzo dentro le varianti sotto forma di due diverse struct, definite
in modo differente per ciascuna variante:
#![allow(unused)] fn main() { struct Ipv4Addr { // --taglio-- } struct Ipv6Addr { // --taglio-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
Questo codice illustra che puoi mettere qualsiasi tipologia di dato dentro una variante di enum: stringhe, type numerici o struct, per esempio. Puoi persino includere un’altra enum! Inoltre, i type della libreria standard spesso non sono molto più complicati di quello che potresti creare tu.
Nota che anche se la libreria standard contiene una definizione per IpAddr,
possiamo comunque creare e usare la nostra definizione senza conflitti perché
non abbiamo importato la definizione della libreria standard nel nostro scope.
Parleremo più avanti dell’importazione dei type nello scope nel Capitolo 7.
Diamo un’occhiata a un altro esempio di enum nel Listato 6-2: questo ha una grande varietà di type incorporati nelle sue varianti.
enum Messaggio { Esci, Sposta { x: i32, y: i32 }, Scrivi(String), CambiaColore(i32, i32, i32), } fn main() {}
Messaggio le cui varianti memorizzano ciascuna quantità e type diversi di valoriQuesta enum ha quattro varianti con type diversi:
Esci: non ha dati associatiMuovi: ha campi nominati, come fa un structScrivi: include una singolaStringCambiaColore: include tre valorii32
Definire un’enum con varianti come quelle nel Listato 6-2 è simile a definire
diversi type di struct, eccetto che l’enum non usa la parola chiave
struct e tutte le varianti sono raggruppate sotto il type Messaggio. Le
seguenti struct potrebbero contenere gli stessi dati che le varianti
dell’enum precedente contengono:
struct MessaggioEsci; // unit struct struct SpostaMessaggio { x: i32, y: i32, } struct ScriviMessaggio(String); // tuple struct struct CambiaColoreMessaggio(i32, i32, i32); // tuple struct fn main() {}
Ma se usassimo le diverse struct, ognuna con il proprio type, non potremmo
definire altrettanto facilmente una funzione che accetti uno qualsiasi di questi
type di messaggi come potremmo fare con l’enum Messaggio definito nel
Listato 6-2, che è un singolo type.
C’è un’ulteriore somiglianza tra enum e struct: proprio come possiamo
definire metodi sulle struct usando impl, possiamo anche definire metodi
sulle enum. Ecco un metodo nominato chiama che potremmo definire sulla
nostra enum Messaggio:
fn main() { enum Messaggio { Esci, Sposta { x: i32, y: i32 }, Scrivi(String), CambiaColore(i32, i32, i32), } impl Messaggio { fn chiama(&self) { // il corpo del metodo sarà definito qui } } let m = Messaggio::Scrivi(String::from("ciao")); m.chiama(); }
Il corpo del metodo userebbe self per ottenere il valore su cui abbiamo
chiamato il metodo. In questo esempio, abbiamo creato una variabile m che ha
il valore Messaggio::Scrivi(String::from("ciao")), e quello sarà self nel
corpo del metodo chiama quando m.chiama() viene eseguito.
Diamo un’occhiata a un’altra enum nella libreria standard che è molto comune e
utile: Option.
L’Enum Option
Questa sezione esplora un caso di studio su Option, che è un’altra enum
definito dalla libreria standard. Il type Option codifica lo scenario molto
comune in cui un valore può essere qualcosa oppure niente.
Per esempio, se richiedi il primo elemento di una lista non vuota, otterrai un valore. Se richiedi il primo elemento di una lista vuota, non otterrai niente. Esprimere questo concetto in termini del sistema dei type permette al compilatore di verificare se hai gestito tutti i casi che dovresti gestire; questa funzionalità può prevenire bug estremamente comuni in altri linguaggi di programmazione.
La progettazione dei linguaggi di programmazione è spesso pensata in termini delle funzionalità che includi, ma anche le funzionalità che escludi sono importanti. Rust non prevede l’uso di null che molti altri linguaggi possiedono. Null è un valore che significa che non c’è alcun valore. Nei linguaggi con null, le variabili possono essere sempre in uno dei due stati: null o non-null.
Nella sua presentazione del 2009 “Null References: The Billion Dollar Mistake”, Tony Hoare, l’inventore del null, disse:
Lo chiamo il mio errore da un miliardo di dollari. All’epoca stavo progettando il primo sistema di type completo per i reference in un linguaggio orientato agli oggetti. Il mio obiettivo era garantire che ogni uso dei reference fosse assolutamente sicuro, con i controlli effettuati automaticamente dal compilatore. Ma non ho resistito alla tentazione di inserire un reference nullo, semplicemente perché era così facile da implementare. Questo ha portato a innumerevoli errori, vulnerabilità e crash di sistema, che probabilmente hanno causato un miliardo di dollari di dolore e danni negli ultimi quarant’anni.
Il problema con i valori null è che se provi a usare un valore null come se fosse un valore non-null, otterrai un errore di qualche tipo. Poiché questa proprietà null o no-null è pervasiva, è estremamente facile commettere questo tipo di errore.
Tuttavia, il concetto che il null cerca di esprimere è ancora utile: null è un valore che è attualmente invalido o assente per qualche motivo.
Il problema non è veramente il concetto ma l’implementazione. Di conseguenza,
Rust non ha i null, ma ha un’enum che può codificare il concetto di un
valore presente o assente. Questa enum è Option<T>, ed è definito dalla
libreria standard come segue:
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
L’enum Option<T> è così utile che è incluso nel prelude (preludio è
l’insieme di funzionalità che Rust include di default in ogni programma fornite
dalla libreria standard); non è necessario portarlo nello scope
esplicitamente. Le sue varianti sono anch’esse incluse nel prelude: puoi usare
Some e None direttamente senza il prefisso Option::. L’enum Option<T>
è comunque un normale enum, e Some(T) e None sono ancora varianti del
type Option<T>.
La sintassi <T> è una caratteristica di Rust di cui non abbiamo ancora
parlato. È un parametro di type generico, e tratteremo i type generici più
in dettaglio nel Capitolo 10. Per ora, tutto ciò che devi sapere è che <T>
significa che la variante Some dell’enum Option può contenere un pezzo di
dato di qualsiasi type, e che ogni type concreto che viene usato al posto di
T rende il type complessivo Option<T> un type diverso. Ecco alcuni
esempi di utilizzo di valori Option per contenere type numerici e type
carattere:
fn main() { let un_numero = Some(5); let un_carattere = Some('e'); let nessun_numero: Option<i32> = None; }
Il type di un_numero è Option<i32>. Il type di un_carattere è
Option<char>, che è un type diverso. Rust può inferire questi type perché
abbiamo specificato un valore dentro la variante Some. Per nessun_numero,
Rust ci richiede di annotare il type di Option: il compilatore non può
inferire il type che la variante Some corrispondente conterrà guardando solo
al valore None. Qui diciamo a Rust che intendiamo che nessun_numero sia di
type Option<i32>.
Quando abbiamo un valore Some, sappiamo che un valore è presente e il valore è
contenuto all’interno di Some. Quando abbiamo un valore None, in un certo
senso significa la stessa cosa di null: non abbiamo un valore valido. Quindi
perché avere Option<T> è meglio che avere null?
In breve, perché Option<T> e T (dove T può essere qualsiasi type) sono
type diversi, il compilatore non ci permetterà di usare un valore Option<T>
come se fosse sicuramente un valore valido. Per esempio, questo codice non
compilerà, perché sta cercando di sommare un Option<i8> a un i8:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let somma = x + y;
}Se eseguiamo questo codice, otteniamo un messaggio di errore come questo:
$ cargo run
Compiling enums v0.1.0 (file:///progetti/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:6:19
|
6 | let somma = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Wow, quanta roba! Nel concreto, questo messaggio di errore significa che Rust
non capisce come sommare un i8 e un Option<i8>, perché sono type diversi.
Quando abbiamo un valore di un type come i8 in Rust, il compilatore deve
assicurarsi che abbiamo sempre un valore valido. Possiamo procedere con fiducia
senza dover controllare il null prima di usare quel valore. Solo quando
abbiamo un Option<i8> (o qualunque type di valore con cui stiamo lavorando)
dobbiamo preoccuparci della possibilità di non avere un valore, e il compilatore
ci assicurerà di gestire quel caso prima di usare il valore.
In altre parole, devi convertire un Option<T> in un T prima di poter
eseguire operazioni su T. Generalmente, questo aiuta a catturare uno dei
problemi più comuni del null: presumere che qualcosa non sia null quando in
realtà lo è.
Eliminare il rischio di presumere erroneamente un valore non-null ti aiuta a
essere più sicuro nel tuo codice. Per avere un valore che può essere
eventualmente null, devi esplicitamente optare per questo facendo sì che il
type di quel valore sia Option<T>. Poi, quando usi quel valore, sei
obbligato a gestire esplicitamente il caso in cui il valore sia null. Ovunque
un valore abbia un type che non è Option<T>, puoi assumere in sicurezza
che il valore non sia null. Questa è stata una decisione di design voluta in
Rust per limitare la pervasività del null e aumentare la sicurezza del codice
Rust.
Quindi come si estrae il valore T da una variante Some quando si ha un
valore di type Option<T> in modo da poter usare quel valore? L’enum
Option<T> ha un gran numero di metodi utili in varie situazioni; puoi
consultarli nella sua documentazione. Familiarizzare con
i metodi su Option<T> sarà estremamente utile nel tuo percorso con Rust.
In generale, per usare un valore Option<T> devi avere codice che gestisca ogni
variante. Vuoi del codice che venga eseguito solo quando hai un valore
Some(T), e quel codice può usare il T interno. Vuoi altro codice che venga
eseguito solo se hai un valore None, e quel codice non ha un valore T
disponibile. L’espressione match è un costrutto di controllo del flusso che fa
esattamente questo quando viene usata con le enum: eseguirà codice diverso a
seconda di quale variante dell’enum ha, e quel codice può usare i dati
all’interno del valore che corrisponde.
Controllare il Flusso col Costrutto match
Rust offre un costrutto di controllo del flusso estremamente potente chiamato
match (corrisponde, combacia) che permette di confrontare un valore con
una serie di pattern ed eseguire codice in base al pattern che corrisponde.
I pattern possono essere composti da valori letterali, nomi di variabili,
caratteri jolly e molte altre cose; il Capitolo 19
copre tutte le diverse tipologie di pattern e cosa fanno. La potenza di
match deriva dall’espressività dei pattern e dal fatto che il compilatore
conferma che tutti i casi possibili sono gestiti.
Pensa a un’espressione match come a una macchina che smista monete: le monete
scivolano lungo una guida con fori di varie dimensioni e ciascuna moneta cade
nel primo foro in cui entra. Allo stesso modo, i valori passano attraverso ogni
pattern in un match, e al primo pattern in cui il valore «entra», il
valore viene fatto ricadere nel blocco di codice associato per essere usato
durante l’esecuzione.
Parlando di monete, usiamole come esempio con match! Possiamo scrivere una
funzione che prende una moneta USA sconosciuta e, in modo simile alla macchina
conta-monete, determina quale moneta sia e restituisce il suo valore in
centesimi, come mostrato nel Listato 6-3.
enum Moneta { Penny, Nickel, Dime, Quarter, } fn valore_in_cent(moneta: Moneta) -> u8 { match moneta { Moneta::Penny => 1, Moneta::Nickel => 5, Moneta::Dime => 10, Moneta::Quarter => 25, } } fn main() {}
match che ha come pattern le varianti dell’enumAnalizziamo il match nella funzione valore_in_cent. Prima troviamo la parola
chiave match seguita da un’espressione, che in questo caso è il valore
moneta. Questo sembra molto simile a un’espressione condizionale usata con
if, ma c’è una grande differenza: con if la condizione deve valutarsi a un
valore booleano, mentre qui può essere di qualsiasi type. Il type di
moneta in questo esempio è l’enum Moneta che abbiamo definito nella prima
riga.
Seguono i rami di match. Un ramo è composto da due parti: un pattern e del
codice. Il primo ramo qui ha come pattern il valore Moneta::Penny e poi
l’operatore => che separa il pattern dal codice da eseguire. Il codice in
questo caso è semplicemente il valore 1. Ogni ramo è separato dal successivo
da una virgola.
Quando l’espressione match viene eseguita, confronta il valore risultante con
il pattern di ogni ramo, in ordine. Se un pattern corrisponde al valore,
viene eseguito il codice associato a quel pattern. Se quel pattern non
corrisponde, l’esecuzione continua con il ramo successivo, proprio come nella
macchina che smista monete. Possiamo avere tanti rami quanti ce ne servono: nel
Listato 6-3, il nostro match ha quattro rami.
Il codice associato a ciascun ramo è un’espressione, e il valore risultante
dell’espressione nel ramo che corrisponde è il valore restituito per l’intera
espressione match.
Di solito non usiamo le parentesi graffe se il codice del ramo è breve, come nel
Listato 6-3 dove ogni ramo restituisce solo un valore. Se vuoi eseguire più
righe di codice in un ramo del match, devi usare le parentesi graffe, e la
virgola che segue il ramo diventa opzionale. Per esempio, il codice seguente
stampa “Penny fortunato!” ogni volta che il metodo viene chiamato con una
Coin::Penny, ma restituisce comunque l’ultimo valore del blocco, 1:
enum Moneta { Penny, Nickel, Dime, Quarter, } fn valore_in_cent(moneta: Moneta) -> u8 { match moneta { Moneta::Penny => { println!("Penny fortunato!"); 1 } Moneta::Nickel => 5, Moneta::Dime => 10, Moneta::Quarter => 25, } } fn main() {}
Pattern che Si Legano ai Valori
Un’altra caratteristica utile dei rami del match è che possono legarsi alle
parti dei valori che corrispondono al pattern. È così che possiamo estrarre
valori dalle varianti delle enum.
Per esempio, modifichiamo una delle nostre varianti dell’enum per contenerci
dei dati. Dal 1999 al 2008, gli Stati Uniti coniarono quarter con design
diversi per ciascuno dei 50 stati su un lato. Nessun’altra moneta aveva design
statali, quindi solo i quarter hanno questa caratteristica peculiare. Possiamo
aggiungere questa informazione al nostra enum cambiando la variante Quarter
per includere un valore StatoUSA all’interno, come fatto nel Listato 6-4.
#[derive(Debug)] // così possiamo vederne i valori tra un po' enum StatoUSA { Alabama, Alaska, // --taglio-- } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn main() {}
Moneta in cui la variante Quarter contiene anche un valore StatoUSAImmaginiamo che un amico stia cercando di collezionare tutti e 50 i quarter statali. Mentre separiamo il nostro resto per tipo di moneta, guarderemo anche il nome dello stato associato a ciascun quarter così, se è uno che al nostro amico manca, può aggiungerlo alla collezione.
Nell’espressione match per questo codice, aggiungiamo una variabile chiamata
stato al pattern che corrisponde ai valori della variante Coin::Quarter.
Quando un Coin::Quarter corrisponde, la variabile stato si legherà al valore
dello stato di quel quarter. Possiamo poi usare stato nel codice di quel
ramo, così:
#[derive(Debug)] enum StatoUSA { Alabama, Alaska, // --taglio-- } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn valore_in_cent(moneta: Moneta) -> u8 { match moneta { Moneta::Penny => 1, Moneta::Nickel => 5, Moneta::Dime => 10, Moneta::Quarter(stato) => { println!("Quarter statale del {stato:?}!"); 25 } } } fn main() { valore_in_cent(Moneta::Quarter(StatoUSA::Alaska)); }
Se chiamassimo valore_in_cent(Moneta::Quarter(StatoUSA::Alaska)), moneta
sarebbe Moneta::Quarter(StatoUSA::Alaska). Quando confrontiamo quel valore con
ciascuno dei rami del match, nessuna corrisponde fino a che non raggiungiamo
Moneta::Quarter(stato). A quel punto stato sarà vincolato al valore
StatoUSA::Alaska. Possiamo quindi usare quel vincolo nell’espressione
println!, ottenendo così il valore interno dello stato dalla variante
Moneta::Quarter.
Corrispondenza con Option<T>
Nella sezione precedente volevamo ottenere il valore interno T di Some
quando si usa Option<T>; possiamo anche gestire Option<T> usando match,
proprio come abbiamo fatto con l’enum Moneta! Invece di confrontare monete,
confronteremo le varianti di Option<T>, ma il funzionamento dell’espressione
match rimane lo stesso.
Supponiamo di voler scrivere una funzione che prende un Option<i32> e, se c’è
un valore dentro, aggiunge 1 a quel valore. Se non c’è un valore dentro, la
funzione dovrebbe restituire il valore None e non tentare di eseguire alcuna
operazione.
Questa funzione è molto semplice da scrivere, grazie a match, e apparirà come
nel Listato 6-5.
fn main() { fn più_uno(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let cinque = Some(5); let sei = più_uno(cinque); let nulla = più_uno(None); }
match su una Option<i32>Esaminiamo la prima esecuzione di più_uno in maggiore dettaglio. Quando
chiamiamo più_uno(cinque), la variabile x nel corpo di più_uno avrà il
valore Some(5). Quindi confrontiamo quello rispetto a ciascun ramo del
match:
fn main() {
fn più_uno(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let cinque = Some(5);
let sei = più_uno(cinque);
let nulla = più_uno(None);
}Il valore Some(5) non corrisponde al pattern None, quindi si continua con
il ramo successivo:
fn main() {
fn più_uno(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let cinque = Some(5);
let sei = più_uno(cinque);
let nulla = più_uno(None);
}Some(5) corrisponde a Some(i)? Sì! Abbiamo la stessa variante. i si lega
al valore contenuto in Some, quindi i assume il valore 5. Il codice nel
ramo del match viene quindi eseguito: aggiungiamo 1 al valore di i e creiamo
un nuovo valore Some con il totale 6 all’interno.
Consideriamo ora la seconda chiamata di più_uno nel Listato 6-5, dove x è
None. Entriamo nel match e confrontiamolo con il primo ramo:
fn main() {
fn più_uno(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let cinque = Some(5);
let sei = più_uno(cinque);
let nulla = più_uno(None);
}Corrisponde! Non c’è alcun valore a cui aggiungere, quindi il programma si ferma
e restituisce il valore None sul lato destro di =>. Poiché il primo ramo ha
corrisposto, nessun altro ramo viene confrontato.
Combinare match ed enum è utile in molte situazioni. Vedrai questo schema
spesso nel codice Rust: fai match su un’enum, leghi una variabile ai dati
interni e poi esegui codice basato su di essi. All’inizio è un po’ ostico, ma
una volta che ci prendi la mano vorrai averlo in tutti i linguaggi. È un
costrutto tra i preferiti dagli utenti.
Le Corrispondenze sono Esaustive
C’è un altro aspetto di match da discutere: i pattern dei rami devono
coprire tutte le possibilità. Considera questa versione della nostra funzione
più_uno, che contiene un bug e non si compilerà:
fn main() {
fn più_uno(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let cinque = Some(5);
let sei = più_uno(cinque);
let nulla = più_uno(None);
}Non abbiamo gestito il caso None, quindi questo codice provocherà un errore.
Per fortuna, è un errore che Rust sa come intercettare. Se proviamo a compilare
questo codice, otterremo questo errore:
$ cargo run
Compiling enums v0.1.0 (file:///progetti/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:4:15
|
4 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/core/src/option.rs:593:1
::: /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/core/src/option.rs:597:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
5 ~ Some(i) => Some(i + 1),
6 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust sa che non abbiamo coperto ogni possibile caso, e sa persino quale
pattern abbiamo dimenticato! I match in Rust sono esaustivi (exhaustive):
dobbiamo coprire ogni possibilità affinché il codice sia valido. Soprattutto nel
caso di Option<T>, quando Rust ci impedisce di dimenticare di gestire
esplicitamente il caso None, ci protegge dall’assumere che abbiamo un valore
quando potremmo avere null, rendendo impossibile “l’errore da un miliardo di
dollari” accennato nel capitolo precedente.
Pattern Pigliatutto e Segnaposto _
Usando le enum, possiamo anche eseguire determinate azioni per alcuni valori
particolari, ma per tutti gli altri valori adottare un’azione predefinita.
Immagina di implementare un gioco dove, se tiri un 3 in un lancio di dadi, il
tuo giocatore non si muove ma riceve un nuovo cappello buffo. Se tiri un 7, il
giocatore perde il cappello buffo. Per tutti gli altri valori, il giocatore si
muove di quel numero di spazi sulla tavola di gioco. Ecco un match che
implementa quella logica, con il risultato del lancio specificato anziché
casuale, e tutta l’altra logica rappresentata da funzioni senza corpo perché
implementarli esula da questo esempio:
fn main() { let tiro_dadi = 9; match tiro_dadi { 3 => metti_cappello_buffo(), 7 => togli_cappello_buffo(), altro => muovi_giocatore(altro), } fn metti_cappello_buffo() {} fn togli_cappello_buffo() {} fn muovi_giocatore(num_spazi: u8) {} }
Per i primi due rami, i pattern sono i valori letterali 3 e 7. Per
l’ultimo ramo che copre tutti gli altri valori possibili, il pattern è la
variabile che abbiamo scelto di chiamare altro. Il codice che viene eseguito
per il ramo altro usa la variabile passando il suo valore alla funzione
muovi_giocatore.
Questo codice compila, anche se non abbiamo elencato tutti i possibili valori
che un u8 può avere, perché l’ultimo pattern corrisponderà a tutti i valori
non specificamente elencati. Questo pattern pigliatutto (catch-all) soddisfa
il requisito che match deve essere esaustivo. Nota che dobbiamo mettere il
ramo pigliatutto per ultimo perché i pattern sono valutati in ordine. Se
mettessimo il ramo pigliatutto prima, gli altri rami non verrebbero mai
eseguiti, quindi Rust ci avvertirebbe se aggiungessimo rami dopo un pigliatutto!
Rust ha anche un pattern che possiamo usare quando vogliamo un pigliatutto ma
non vogliamo usare il valore corrispondente: _ è un pattern speciale che
corrisponde a qualsiasi valore e non si lega a quel valore. Questo dice a Rust
che non useremo il valore, quindi Rust non ci segnalerà una variabile
inutilizzata.
Cambiamo le regole del gioco: ora, se tiri qualsiasi cosa diversa da 3 o 7, devi
rilanciare. Non abbiamo più bisogno di usare il valore pigliatutto, quindi
possiamo cambiare il codice per usare _ al posto della variabile chiamata
altro:
fn main() { let tiro_dadi = 9; match tiro_dadi { 3 => metti_cappello_buffo(), 7 => togli_cappello_buffo(), _ => tira_ancora(), } fn metti_cappello_buffo() {} fn togli_cappello_buffo() {} fn tira_ancora() {} }
Anche questo esempio soddisfa il requisito di esaustività perché stiamo esplicitamente ignorando tutti gli altri valori nell’ultimo ramo; non abbiamo dimenticato nulla.
Infine, cambiamo ancora una volta le regole del gioco in modo che non succeda
nient’altro nel tuo turno se tiri qualcosa di diverso da 3 o 7. Possiamo
esprimerlo usando il valore unit (la tupla vuota)
come codice associato al ramo _:
fn main() { let tiro_dadi = 9; match tiro_dadi { 3 => metti_cappello_buffo(), 7 => togli_cappello_buffo(), _ => (), } fn metti_cappello_buffo() {} fn togli_cappello_buffo() {} }
Qui stiamo dicendo esplicitamente a Rust che non useremo alcun altro valore che non corrisponda a un pattern in un ramo precedente, e non vogliamo eseguire alcun codice in questo caso.
C’è molto altro sui pattern e sul matching che tratteremo nel Capitolo
19. Per ora, passiamo alla sintassi if let, che può essere utile nelle situazioni più semplici in cui l’espressione
match risulta un po’ verbosa.
Controllare il Flusso con if let e let else
La sintassi if let consente di combinare if e let in un modo meno verboso
per gestire i valori che corrispondono a un singolo pattern, ignorando gli
altri. Considera il programma nel Listato 6-6 che fa matching su un
Option<u8> nella variabile config_max ma vuole eseguire codice solo se il
valore è la variante Some.
fn main() { let config_max = Some(3u8); match config_max { Some(max) => println!("Il massimo è configurato per essere {max}"), _ => (), } }
match che si interessa solo di eseguire codice quando il valore è SomeSe il valore è Some, stampiamo il valore contenuto nella variante Some
legandolo alla variabile max nel pattern. Non vogliamo fare nulla per il
valore None. Per soddisfare l’espressione match dobbiamo aggiungere _ => () dopo aver processato una sola variante, il che, a ben vedere, sembra codice
un po’ inutile.
Invece, possiamo scrivere questo in modo più breve usando if let. Il codice
seguente si comporta allo stesso modo del match nel Listato 6-6:
fn main() { let config_max = Some(3u8); if let Some(max) = config_max { println!("Il massimo è configurato per essere {max}"); } }
La sintassi if let prende un pattern e un’espressione separati da un segno
di uguale. Funziona come un match, dove l’espressione è data al match e il
pattern è il suo primo ramo. In questo caso il pattern è Some(max), e
max si lega al valore dentro il Some. Possiamo quindi usare max nel corpo
del blocco if let nello stesso modo in cui lo usavamo nel corrispondente ramo
del match. Il codice nel blocco if let viene eseguito solo se il valore
corrisponde al pattern.
Usare if let significa meno digitazione, meno indentazione e meno codice poco
utile. Tuttavia si perde il controllo di esaustività che il match impone e che
garantisce di non dimenticare di gestire dei casi. La scelta tra match e if let dipende da cosa stai facendo in quella situazione particolare e se un
codice più conciso valga la perdita del controllo esaustivo.
In altre parole, puoi pensare a if let come ad una espressione match ridotta
all’osso che esegue codice quando il valore corrisponde a un pattern e poi
ignora tutti gli altri valori.
Possiamo includere un else con un if let. Il blocco di codice che accompagna
l’else è lo stesso blocco che andrebbe con il caso _ nell’espressione
match equivalente all’if let con else. Ricorda la definizione dell’enum
Moneta nel Listato 6-4, dove la variante Quarter conteneva anche un valore
StatoUSA. Se volessimo contare tutte le monete non-quarter che vediamo
annunciando anche lo stato dei quarter, potremmo farlo con un’espressione
match, così:
#[derive(Debug)] enum StatoUSA { Alabama, Alaska, // --taglio-- } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn main() { let moneta = Moneta::Penny; let mut conteggio = 0; match moneta { Moneta::Quarter(stato) => println!("Quarter statale del {stato:?}!"), _ => conteggio += 1, } }
Oppure potremmo usare un if let e un else, così:
#[derive(Debug)] enum StatoUSA { Alabama, Alaska, // --taglio-- } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn main() { let moneta = Moneta::Penny; let mut conteggio = 0; if let Moneta::Quarter(stato) = moneta { println!("Quarter statale del {stato:?}!"); } else { conteggio += 1; } }
Restare sul “Percorso Felice” con let...else
Una buona pratica è eseguire una computazione quando un valore è presente e
restituire un valore di default altrimenti. Continuando con il nostro esempio
delle monete con un valore StatoUSA, se volessimo dire qualcosa di divertente
a seconda di quanto fosse vecchio lo stato sul quarter, potremmo introdurre un
metodo su StatoUSA per verificare l’età dello stato, così:
#[derive(Debug)] // so we can inspect the state in a minute enum StatoUSA { Alabama, Alaska, // --taglio-- } impl StatoUSA { fn esistente_nel(&self, anno: u16) -> bool { match self { StatoUSA::Alabama => anno >= 1819, StatoUSA::Alaska => anno >= 1959, // --taglio-- } } } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn desc_quarter_statale(moneta: Moneta) -> Option<String> { if let Moneta::Quarter(stato) = moneta { if stato.esistente_nel(1900) { Some(format!("{stato:?} è abbastanza vecchio, per l'America!")) } else { Some(format!("{stato:?} è abbastanza recente.")) } } else { None } } fn main() { if let Some(desc) = desc_quarter_statale(Moneta::Quarter(StatoUSA::Alaska)) { println!("{desc}"); } }
Poi potremmo usare if let per fare matching sul tipo di moneta, introducendo
una variabile stato all’interno del corpo della condizione, come nel Listato
6-7.
#[derive(Debug)] // so we can inspect the state in a minute enum StatoUSA { Alabama, Alaska, // --taglio-- } impl StatoUSA { fn esistente_nel(&self, anno: u16) -> bool { match self { StatoUSA::Alabama => anno >= 1819, StatoUSA::Alaska => anno >= 1959, // --taglio-- } } } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn desc_quarter_statale(moneta: Moneta) -> Option<String> { if let Moneta::Quarter(stato) = moneta { if stato.esistente_nel(1900) { Some(format!("{stato:?} è abbastanza vecchio, per l'America!")) } else { Some(format!("{stato:?} è abbastanza recente.")) } } else { None } } fn main() { if let Some(desc) = desc_quarter_statale(Moneta::Quarter(StatoUSA::Alaska)) { println!("{desc}"); } }
if letQuesto risolve il problema, ma ha spostato il lavoro nel corpo dell’if let, e
se il lavoro da fare è più complicato potrebbe risultare difficile seguire come
i rami di alto livello si relazionano. Potremmo anche sfruttare il fatto che le
espressioni producono un valore, o per produrre stato dall’if let o per
ritornare anticipatamente, come in Listato 6-8. (Si potrebbe fare qualcosa di
simile anche con un match.)
#[derive(Debug)] // so we can inspect the state in a minute enum StatoUSA { Alabama, Alaska, // --taglio-- } impl StatoUSA { fn esistente_nel(&self, anno: u16) -> bool { match self { StatoUSA::Alabama => anno >= 1819, StatoUSA::Alaska => anno >= 1959, // --taglio-- } } } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn desc_quarter_statale(moneta: Moneta) -> Option<String> { let stato = if let Moneta::Quarter(stato) = moneta { stato } else { return None; }; if stato.esistente_nel(1900) { Some(format!("{stato:?} è abbastanza vecchio, per l'America!")) } else { Some(format!("{stato:?} è abbastanza recente.")) } } fn main() { if let Some(desc) = desc_quarter_statale(Moneta::Quarter(StatoUSA::Alaska)) { println!("{desc}"); } }
if let per produrre un valore o ritornare anticipatamenteQuesto però è un po’ scomodo da seguire: un ramo dell’if let produce un valore
e l’altro ritorna dalla funzione completamente.
Per rendere più esprimibile questo pattern comune, Rust ha let...else. La
sintassi let...else prende un pattern a sinistra e un’espressione a destra,
molto simile a if let, ma non ha un ramo if, soltanto un ramo else. Se il
pattern corrisponde, legherà il valore estratto dal pattern nello scope
esterno. Se il pattern non corrisponde, il flusso va nel ramo else, che deve
restituire dalla funzione.
Nel Listato 6-9 puoi vedere come Listato 6-8 appare usando let...else al posto
di if let.
#[derive(Debug)] // so we can inspect the state in a minute enum StatoUSA { Alabama, Alaska, // --taglio-- } impl StatoUSA { fn esistente_nel(&self, anno: u16) -> bool { match self { StatoUSA::Alabama => anno >= 1819, StatoUSA::Alaska => anno >= 1959, // --taglio-- } } } enum Moneta { Penny, Nickel, Dime, Quarter(StatoUSA), } fn desc_quarter_statale(moneta: Moneta) -> Option<String> { let Moneta::Quarter(stato) = moneta else { return None; }; if stato.esistente_nel(1900) { Some(format!("{stato:?} è abbastanza vecchio, per l'America!")) } else { Some(format!("{stato:?} è abbastanza recente.")) } } fn main() { if let Some(desc) = desc_quarter_statale(Moneta::Quarter(StatoUSA::Alaska)) { println!("{desc}"); } }
let...else per semplificare il flusso della funzioneNota che in questo modo si resta sul “percorso felice” nel corpo principale
della funzione, senza avere un controllo di flusso significativamente diverso
per i due rami come invece succedeva con if let.
Se hai una situazione in cui la logica è troppo verbosa per essere espressa con
un match, ricorda che anche if let e let...else sono nella tua cassetta
degli attrezzi di Rust.
Riepilogo
Abbiamo ora coperto come usare le enum per creare type personalizzati che
possono essere uno tra un insieme di valori enumerati. Abbiamo mostrato come il
type Option<T> della libreria standard ti aiuta a usare il sistema dei
type per prevenire errori. Quando i valori delle enum contengono dati, puoi
usare match o if let per estrarre e usare quei valori, a seconda di quanti
casi devi gestire.
I tuoi programmi Rust possono ora esprimere concetti nel tuo dominio usando
struct ed enum. Creare type personalizzati da usare nella tua API assicura
maggiore sicurezza dei dati (type safety): il compilatore garantirà che le tue
funzioni ricevano solo i valori del type che ciascuna funzione si aspetta.
Per fornire un’API ben organizzata ai tuoi utenti, chiara da usare ed esponendo solo ciò che serve, passiamo ora ai moduli di Rust.
Pacchetti, Crate, e Moduli
Quando scriverai programmi sempre più complessi, organizzare il tuo codice diventerà sempre più importante. Raccogliendo funzionalità correlate e separando il codice con caratteristiche distinte, chiarirai dove trovare il codice che implementa una particolare funzionalità e quindi dove guardare per modificare il codice di quella funzionalità se necessario.
I programmi che abbiamo scritto finora sono stati tutti implementati con un singolo modulo in un unico file. Man mano che un progetto cresce, dovresti organizzare il codice suddividendolo in più moduli e poi in più file. Un pacchetto (package) può contenere più crate binari (binary crate) e opzionalmente un crate libreria (library crate). Man mano che un pacchetto cresce, puoi estrarne parti in crate separate che diventeranno dipendenze esterne. Questo capitolo copre tutte queste tecniche. Per progetti molto grandi che comprendono un insieme di pacchetti interconnessi che evolvono insieme, Cargo fornisce degli spazi di lavoro (workspace), che tratteremo nella sezione “Cargo Workspace” del Capitolo 14.
Discuteremo anche l’incapsulamento dei dettagli di implementazione, che ti consente di riutilizzare il codice a un livello più alto: una volta implementata un’operazione, l’altro codice può chiamare il tuo codice tramite la sua interfaccia pubblica senza dover sapere come funziona l’implementazione. Il modo in cui scrivi il codice definisce quali parti sono pubbliche per l’uso da parte di altri codici e quali parti sono dettagli di implementazione privati che ti riservi il diritto di modificare. Questo è un altro modo per limitare la quantità di dettagli che devi tenere a mente.
Un concetto correlato è lo scope: il contesto annidato in cui è scritto il codice ha un insieme di nomi definiti come “in scope”. Quando si legge, si scrive e si compila il codice, i programmatori e i compilatori devono sapere se un particolare nome in un particolare punto si riferisce a una variabile, funzione, struct, enum, modulo, costante o altro elemento e cosa significa quell’elemento. Puoi creare scope e modificare quali nomi sono in o fuori scope. Non puoi avere due elementi con lo stesso nome nello stesso scope; sono disponibili strumenti per risolvere i conflitti di nomenclatura.
Rust ha una serie di funzionalità che ti consentono di gestire l’organizzazione del tuo codice, inclusi i dettagli esposti, i dettagli privati e quali nomi sono in ogni scope nei tuoi programmi. Queste funzionalità, a volte definite collettivamente sistema dei moduli (module system), includono:
- Pacchetti: Una funzionalità di Cargo che ti consente di costruire, testare e condividere crate
- Crate: Un albero di moduli che produce una libreria o un eseguibile
- Moduli e use: Ti consentono di controllare l’organizzazione, lo scope e la privacy dei percorsi (paths)
- Path: Un modo per nominare un elemento, come una struct, una funzione o un modulo
In questo capitolo, tratteremo tutte queste funzionalità, discuteremo come interagiscono e spiegheremo come usarle per gestire lo scope. Alla fine, dovresti avere una solida comprensione del module system e essere in grado di lavorare con gli scope come un professionista!
Pacchetti e Crate
Le prime parti del sistema dei moduli che tratteremo sono i pacchetti e i crate.
Un crate è la quantità minima di codice che il compilatore Rust considera in
un dato momento. Anche se esegui rustc invece di cargo e passi un singolo
file di codice sorgente (come abbiamo fatto all’inizio nella sezione “Programma
Rust Basilare” del Capitolo 1), il compilatore considera
quel file come un crate. I crate possono contenere moduli, e i moduli
possono essere definiti in altri file che vengono compilati con il crate, come
vedremo nelle sezioni successive.
Un crate può presentarsi in una delle due forme: un crate binario o un
crate libreria. I crate binari sono programmi che puoi compilare in un
eseguibile che puoi eseguire, come un programma da riga di comando o un server.
Ognuno deve avere una funzione chiamata main che definisce cosa succede quando
l’eseguibile viene eseguito. Tutti i crate che abbiamo creato finora sono
stati crate binari.
I crate libreria non hanno una funzione main, e non si compilano in un
eseguibile. Invece, definiscono funzionalità destinate a essere condivise con
progetti multipli. Ad esempio, il crate rand che abbiamo usato nel Capitolo
2 fornisce funzionalità che generano numeri casuali. La
maggior parte delle volte, quando i Rustacean dicono “crate”, intendono
crate libreria, e usano “crate” in modo intercambiabile con il concetto
generale di programmazione di una “libreria”.
La radice del crate (crate root) è un file sorgente da cui il compilatore Rust inizia e costituisce il modulo radice del tuo crate (spiegheremo i moduli in dettaglio nel capitolo “Controllare Scope e Privacy con i Moduli”).
Un pacchetto (package) è un insieme di uno o più crate che fornisce un insieme di funzionalità. Un pacchetto contiene un file Cargo.toml che descrive come costruire quei crate. Cargo è anch’esso in realtà un pacchetto che contiene il crate binario per lo strumento da riga di comando che hai usato per costruire il tuo codice finora. Il pacchetto Cargo contiene anche un crate libreria di cui il crate binario ha bisogno. Altri progetti possono dipendere dal crate libreria Cargo per utilizzare la stessa logica che utilizza lo strumento da riga di comando Cargo.
Un pacchetto può contenere quanti più crate binari desideri, ma al massimo solo un crate libreria. Un pacchetto deve contenere almeno un crate, sia esso un crate libreria o binario.
Esploriamo cosa succede quando creiamo un pacchetto. Cominciamo con il comando
cargo new mio-progetto:
$ cargo new mio-progetto
Created binary (application) `mio-progetto` package
$ ls mio-progetto
Cargo.toml
src
$ ls mio-progetto/src
main.rs
Dopo aver eseguito cargo new mio-progetto, usiamo ls per vedere cosa crea
Cargo. Nella cartella mio-progetto, c’è un file Cargo.toml, che definisce un
pacchetto. C’è anche una cartella src che contiene main.rs. Apri
Cargo.toml nel tuo editor di testo e nota che non c’è menzione di
src/main.rs. Cargo segue una convenzione secondo cui src/main.rs è la radice
del crate di un crate binario con lo stesso nome del pacchetto. Allo
stesso modo, Cargo sa che se la cartella del pacchetto contiene src/lib.rs, il
pacchetto contiene un crate libreria con lo stesso nome del pacchetto, e
src/lib.rs è la sua radice del crate. Cargo passa i file di radice del
crate a rustc per costruire la libreria o il binario.
Qui, abbiamo un pacchetto che contiene solo src/main.rs, il che significa che
contiene solo un crate binario chiamato mio-progetto. Se un pacchetto
contiene src/main.rs e src/lib.rs, avrà due crate: uno binario e uno
libreria, entrambi con lo stesso nome del pacchetto. Un pacchetto può avere più
crate binari posizionando file nella cartella src/bin: ogni file sarà un
crate binario separato.
Controllare Scope e Privacy con i Moduli
In questa sezione, parleremo dei moduli e di altre parti del sistema dei moduli,
in particolare dei path (percorsi), che ti permettono di nominare gli
elementi; la parola chiave use che porta un path in scope; e la parola
chiave pub per rendere pubblici gli elementi. Discuteremo anche della parola
chiave as, dei pacchetti esterni e dell’operatore glob.
Scheda Informativa sui Moduli
Prima di entrare nei dettagli dei moduli e dei path, qui forniamo un rapido
riferimento su come funzionano i moduli, i path, la parola chiave use e la
parola chiave pub nel compilatore, e come la maggior parte degli sviluppatori
organizza il proprio codice. Esamineremo esempi di ciascuna di queste regole nel
corso di questo capitolo, ma questo è un ottimo riassunto da consultare come
promemoria su come funzionano i moduli.
- Inizia dalla radice del crate: Quando compili un crate, il compilatore prima cerca nel file di radice del crate (di solito src/lib.rs per un crate libreria e src/main.rs per un crate binario) il codice da compilare.
- Dichiarare moduli: Nel file di radice del crate, puoi dichiarare nuovi
moduli; ad esempio, dichiari un modulo “giardino” con
mod giardino;. Il compilatore cercherà il codice del modulo in questi luoghi:- Sulla linea, all’interno delle parentesi graffe che sostituiscono il punto e
virgola dopo
mod giardino - Nel file src/giardino.rs
- Nel file src/giardino/mod.rs
- Sulla linea, all’interno delle parentesi graffe che sostituiscono il punto e
virgola dopo
- Dichiarare sottomoduli: In qualsiasi file diverso dalla radice del
crate, puoi dichiarare sottomoduli. Ad esempio, potresti dichiarare
mod verdure;in src/giardino.rs. Il compilatore cercherà il codice del sottomodulo all’interno della cartella nominata per il modulo genitore (parent) in questi luoghi:- Sulla linea, direttamente dopo
mod verdure, all’interno delle parentesi graffe invece del punto e virgola - Nel file src/giardino/verdure.rs
- Nel file src/giardino/verdure/mod.rs
- Sulla linea, direttamente dopo
- Path per il codice nei moduli: Una volta che un modulo è parte del tuo
crate, puoi fare riferimento al codice in quel modulo da qualsiasi altro
punto dello stesso crate, purché le regole di privacy lo consentano,
utilizzando il path per il codice. Ad esempio, un type
Asparaginel modulo delle verdure del giardino si troverebbe al pathcrate::giardino::verdure::Asparagi. - Privato vs. pubblico: Il codice all’interno di un modulo è non
utilizzabile, privato, dai suoi moduli genitore come impostazione
predefinita. Per rendere un modulo utilizzabile, pubblico, è necessario
dichiaralo con
pub modinvece dimod. Per rendere pubblici anche gli elementi all’interno di un modulo pubblico, usapubprima delle loro dichiarazioni. - La parola chiave
use: All’interno di uno scope, la parola chiaveusecrea scorciatoie per gli elementi per ridurre la ripetizione di lunghi path. In qualsiasi scope che può fare riferimento acrate::giardino::verdure::Asparagi, puoi creare una scorciatoia conuse crate::giardino::verdure::Asparagi;e da quel momento in poi devi scrivere soloAsparagiper utilizzare quel type nello scope.
Ora creiamo un crate binario chiamato cortile che illustra queste regole.
La cartella del crate, anch’essa chiamata cortile, contiene questi file e
cartelle:
cortile
├── Cargo.lock
├── Cargo.toml
└── src
├── giardino
│ └── verdure.rs
├── giardino.rs
└── main.rs
La radice del crate in questo caso è src/main.rs, e contiene:
use crate::giardino::verdure::Asparagi;
pub mod giardino;
fn main() {
let pianta = Asparagi {};
println!("Sto coltivando {pianta:?}!");
}La riga pub mod giardino; dice al compilatore di includere il codice che trova
in src/giardino.rs, che è:
pub mod verdure;Qui, pub mod verdure; significa che il codice in src/giardino/verdure.rs è
incluso anch’esso. Quel codice è:
#[derive(Debug)]
pub struct Asparagi {}Ora entriamo nei dettagli di queste regole e dimostriamo come funzionano!
Raggruppare Codice Correlato in Moduli
I moduli ci permettono di organizzare il codice all’interno di un crate per migliore leggibilità e facilità di riutilizzo. I moduli ci consentono anche di controllare la privacy degli elementi, poiché il codice all’interno di un modulo è privato come impostazione predefinita. Gli elementi privati sono dettagli di implementazione interni non disponibili per l’uso esterno. Possiamo scegliere di rendere pubblici i moduli e gli elementi al loro interno, il che li espone per consentire al codice esterno di utilizzarli e dipendere da essi.
Come esempio, scriviamo un crate libreria che fornisce la funzionalità di un ristorante. Definiremo le firme delle funzioni ma lasceremo i loro corpi vuoti per concentrarci sull’organizzazione del codice piuttosto che sull’implementazione vera e propria.
Nel settore della ristorazione, alcune “funzioni” di un ristorante sono chiamate sala e altre cucina. La “sala” è dove si trovano i clienti; questo comprende dove l’oste riceve i clienti, i camerieri prendono ordini e pagamenti, e i baristi preparano drink. La “cucina” è dove gli chef e i cuochi lavorano in cucina, i lavapiatti puliscono e i manager svolgono lavori amministrativi.
Per strutturare il nostro crate in questo modo, possiamo organizzare le sue
funzioni in moduli annidati. Crea una nuova libreria chiamata ristorante
eseguendo cargo new ristorante --lib. Poi inserisci il codice nel Listato 7-1
in src/lib.rs per definire alcuni moduli e firme di funzione; questo codice è
la sezione sala.
mod sala {
mod accoglienza {
fn aggiungi_in_lista() {}
fn metti_al_tavolo() {}
}
mod servizio {
fn prendi_ordine() {}
fn servi_ordine() {}
fn prendi_pagamento() {}
}
}sala contenente altri moduli che poi contengono funzioniDefiniamo un modulo con la parola chiave mod seguita dal nome del modulo (in
questo caso, sala). Il corpo del modulo va quindi all’interno delle parentesi
graffe. All’interno dei moduli, possiamo inserire altri moduli, come in questo
caso con i moduli accoglienza e servizio. I moduli possono anche contenere
definizioni per altri elementi, come struct, enum, costanti, trait e, come
nel Listato 7-1, funzioni.
Utilizzando i moduli, possiamo raggruppare definizioni correlate insieme e nominare il motivo per cui sono correlate. I programmatori che utilizzano questo codice possono navigare nel codice in base ai gruppi piuttosto che dover leggere tutte le definizioni, rendendo più facile trovare le definizioni rilevanti per loro. I programmatori che aggiungono nuove funzionalità a questo codice saprebbero dove posizionare il codice per mantenere organizzato il programma.
In precedenza, abbiamo menzionato che src/main.rs e src/lib.rs sono chiamati
radici del crate. Il motivo del loro nome è che i contenuti di uno di questi
due file formano un modulo chiamato crate alla radice della struttura del
modulo del crate, nota come albero dei moduli (module tree).
Il Listato 7-2 mostra l’albero dei moduli per la struttura nel Listato 7-1.
crate
└── sala
├── accoglienza
│ ├── aggiungi_in_lista
│ └── metti_al_tavolo
└── servizio
├── prendi_ordine
├── servi_ordine
└── prendi_pagamento
Questo albero mostra come alcuni dei moduli si annidano all’interno di altri
moduli; ad esempio, accoglienza si annida all’interno di sala. L’albero
mostra anche che alcuni moduli sono fratelli, il che significa che sono
definiti nello stesso modulo; accoglienza e servizio sono fratelli definiti
all’interno di sala. Se il modulo A è contenuto all’interno del modulo B,
diciamo che il modulo A è il figlio del modulo B e che il modulo B è il
genitore del modulo A. Nota che l’intero albero dei moduli è radicato sotto il
modulo implicito chiamato crate.
L’albero dei moduli potrebbe ricordarti l’albero delle cartelle del filesystem sul tuo computer; questo è un confronto molto appropriato! Proprio come le cartelle in un filesystem, usi i moduli per organizzare il tuo codice. E proprio come i file in una cartella, abbiamo bisogno di un modo per trovare i nostri moduli.
Percorsi per Fare Riferimento a un Elemento nell’Albero dei Moduli
Per mostrare a Rust dove trovare un elemento in un albero dei moduli, utilizziamo un path (percorso) nello stesso modo in cui usiamo un path quando navighiamo in un filesystem. Per chiamare una funzione, dobbiamo conoscere il suo path.
Un path può assumere due forme:
- Un path assoluto è il percorso completo che inizia dalla radice del crate;
per il codice di un crate esterno, il percorso assoluto inizia con il nome
del crate, e per il codice del crate corrente, inizia con il letterale
crate. - Un path relativo inizia dal modulo corrente e utilizza
self,supero un identificatore nel modulo corrente.
Sia i path assoluti che relativi sono seguiti da uno o più identificatori
separati da doppi due punti (::).
Tornando al Listato 7-1, supponiamo di voler chiamare la funzione
aggiungi_in_lista. Questo è lo stesso che chiedere: qual è il path della
funzione aggiungi_in_lista? Il Listato 7-3 contiene il Listato 7-1 con alcuni
dei moduli e delle funzioni rimossi.
Mostreremo due modi per chiamare la funzione aggiungi_in_lista da una nuova
funzione, mangiare_al_ristorante, definita nella radice del crate. Questi
path sono corretti, ma c’è un altro problema che impedirà a questo esempio di
compilare così com’è. Spiegheremo perché tra poco.
La funzione mangiare_al_ristorante fa parte dell’API pubblica del nostro
crate libreria, quindi la contrassegniamo con la parola chiave pub. Nella
sezione “Esporre Path con la Parola Chiave pub”,
entreremo nei dettagli di pub.
mod sala {
mod accoglienza {
fn aggiungi_in_lista() {}
}
}
pub fn mangiare_al_ristorante() {
// Path assoluta
crate::sala::accoglienza::aggiungi_in_lista();
// Path relativa
sala::accoglienza::aggiungi_in_lista();
}aggiungi_in_lista utilizzando path assoluti e relativiLa prima volta che chiamiamo la funzione aggiungi_in_lista in
mangiare_al_ristorante, utilizziamo un path assoluto. La funzione
aggiungi_in_lista è definita nello stesso crate di mangiare_al_ristorante,
il che significa che possiamo usare la parola chiave crate per iniziare un
path assoluto. Includiamo quindi ciascuno dei moduli successivi fino a
raggiungere aggiungi_in_lista. Puoi immaginare un filesystem con la stessa
struttura: specificheremmo il path /sala/accoglienza/aggiungi_in_lista per
eseguire il programma aggiungi_in_lista; utilizzare il nome del crate per
partire dalla radice del crate è come usare / per partire dalla radice del
filesystem nel tuo terminale.
La seconda volta che chiamiamo aggiungi_in_lista in mangiare_al_ristorante,
utilizziamo un path relativo. Il path inizia con sala, il nome del modulo
definito allo stesso livello dell’albero dei moduli di mangiare_al_ristorante.
Qui l’equivalente nel filesystem sarebbe utilizzare il path
sala/accoglienza/aggiungi_in_lista. Iniziare con un nome di modulo significa
che il path è relativo.
Scegliere se utilizzare un path relativo o assoluto è una decisione che
prenderai in base al tuo progetto, e dipende da se è più probabile che tu sposti
il codice di definizione dell’elemento separatamente o insieme al codice che
utilizza l’elemento. Ad esempio, se spostassimo il modulo sala e la funzione
mangiare_al_ristorante in un modulo chiamato gestione_cliente, dovremmo
aggiornare il path assoluto per aggiungi_in_lista, ma il path relativo
rimarrebbe valido. Tuttavia, se spostassimo la funzione mangiare_al_ristorante
separatamente in un modulo chiamato cena, il path assoluto per la chiamata a
aggiungi_in_lista rimarrebbe lo stesso, ma il path relativo dovrebbe essere
aggiornato. La nostra preferenza in generale è specificare path assoluti
perché è più probabile che vogliamo spostare le definizioni di codice e le
chiamate agli elementi in modo indipendente l’una dall’altra.
Proviamo a compilare il Listato 7-3 e scopriamo perché non si compila ancora! Gli errori che otteniamo sono mostrati nel Listato 7-4.
$ cargo build
Compiling ristorante v0.1.0 (file:///progetti/ristorante)
error[E0603]: module `accoglienza` is private
--> src/lib.rs:9:18
|
9 | crate::sala::accoglienza::aggiungi_in_lista();
| ^^^^^^^^^^^ ----------------- function `aggiungi_in_lista` is not publicly re-exported
| |
| private module
|
note: the module `accoglienza` is defined here
--> src/lib.rs:2:5
|
2 | mod accoglienza {
| ^^^^^^^^^^^^^^^
error[E0603]: module `accoglienza` is private
--> src/lib.rs:12:11
|
12 | sala::accoglienza::aggiungi_in_lista();
| ^^^^^^^^^^^ ----------------- function `aggiungi_in_lista` is not publicly re-exported
| |
| private module
|
note: the module `accoglienza` is defined here
--> src/lib.rs:2:5
|
2 | mod accoglienza {
| ^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `ristorante` (lib) due to 2 previous errors
I messaggi di errore dicono che il modulo accoglienza è privato. In altre
parole, abbiamo i path corretti per il modulo accoglienza e la funzione
aggiungi_in_lista, ma Rust non ci permette di usarli perché non ha accesso
alle sezioni private. In Rust, tutti gli elementi (funzioni, metodi, struct,
enum, moduli e costanti) sono privati rispetto ai moduli genitore come
impostazione predefinita. Se desideri rendere un elemento come una funzione o
una struct privata, lo metti in un modulo.
Gli elementi in un modulo genitore non possono utilizzare gli elementi privati all’interno dei moduli figli, ma gli elementi nei moduli figli possono utilizzare gli elementi nei loro moduli antenati. Questo perché i moduli figli incapsulano e nascondono i loro dettagli di implementazione, ma i moduli figli possono vedere il contesto in cui sono definiti. Per continuare con la nostra metafora, pensa alle regole di privacy come se fossero l’ufficio posteriore di un ristorante: ciò che accade lì è privato e nascosto per i clienti del ristorante, ma i manager dell’ufficio possono vedere e fare tutto nel ristorante che gestiscono.
Rust ha scelto che far funzionare il sistema dei moduli in questo modo,
nascondendo i dettagli di implementazione interni come impostazione predefinita.
In questo modo, sai quali parti del codice interno puoi modificare senza
compromettere il codice esterno. Tuttavia, Rust ti offre la possibilità di
esporre le parti interne del codice dei moduli figli ai moduli antenati
utilizzando la parola chiave pub per rendere pubblico un elemento.
Esporre Path con la Parola Chiave pub
Torniamo all’errore nel Listato 7-4 che ci diceva che il modulo accoglienza è
privato. Vogliamo che la funzione mangiare_al_ristorante nel modulo genitore
abbia accesso alla funzione aggiungi_in_lista nel modulo figlio, quindi
contrassegniamo il modulo accoglienza con la parola chiave pub, come
mostrato nel Listato 7-5.
mod sala {
pub mod accoglienza {
fn aggiungi_in_lista() {}
}
}
// --taglio--
pub fn mangiare_al_ristorante() {
// Path assoluta
crate::sala::accoglienza::aggiungi_in_lista();
// Path relativa
sala::accoglienza::aggiungi_in_lista();
}accoglienza come pub per usarlo da mangiare_al_ristoranteSfortunatamente, il codice nel Listato 7-5 genera ancora errori del compilatore, come mostrato nel Listato 7-6.
$ cargo build
Compiling ristorante v0.1.0 (file:///progetti/ristorante)
error[E0603]: function `aggiungi_in_lista` is private
--> src/lib.rs:12:31
|
12 | crate::sala::accoglienza::aggiungi_in_lista();
| ^^^^^^^^^^^^^^^^^ private function
|
note: the function `aggiungi_in_lista` is defined here
--> src/lib.rs:4:9
|
4 | fn aggiungi_in_lista() {}
| ^^^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `aggiungi_in_lista` is private
--> src/lib.rs:15:24
|
15 | sala::accoglienza::aggiungi_in_lista();
| ^^^^^^^^^^^^^^^^^ private function
|
note: the function `aggiungi_in_lista` is defined here
--> src/lib.rs:4:9
|
4 | fn aggiungi_in_lista() {}
| ^^^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `ristorante` (lib) due to 2 previous errors
Cosa è successo? Aggiungere la parola chiave pub davanti a mod accoglienza
rende il modulo pubblico. Con questa modifica, se possiamo accedere a sala,
possiamo accedere a accoglienza. Ma i contenuti di accoglienza sono ancora
privati; rendere pubblico il modulo non rende pubblici i suoi contenuti. La
parola chiave pub su un modulo consente solo al codice nei suoi moduli
genitore di fare riferimento ad esso, non di accedere al suo codice interno.
Poiché i moduli sono contenitori, non possiamo fare molto semplicemente rendendo
pubblico il modulo; dobbiamo andare oltre e scegliere di rendere pubblici uno o
più degli elementi all’interno del modulo.
Gli errori nel Listato 7-6 dicono che la funzione aggiungi_in_lista è privata.
Le regole di privacy si applicano a struct, enum, funzioni e metodi, così
come ai moduli.
Facciamo in modo che anche la funzione aggiungi_in_lista sia pubblica
aggiungendo la parola chiave pub prima della sua definizione, come nel Listato
7-7.
mod sala {
pub mod accoglienza {
pub fn aggiungi_in_lista() {}
}
}
// --taglio--
pub fn mangiare_al_ristorante() {
// Path assoluta
crate::sala::accoglienza::aggiungi_in_lista();
// Path relativa
sala::accoglienza::aggiungi_in_lista();
}pub a mod accoglienza e fn aggiungi_in_lista ci consente di chiamare la funzione da mangiare_al_ristoranteOra il codice si compilerà! Per capire perché aggiungere la parola chiave pub
ci consente di utilizzare questi path in mangiare_al_ristorante rispetto
alle regole di privacy, diamo un’occhiata ai path assoluti e relativi.
Nel path assoluto, iniziamo con crate, la radice dell’albero dei moduli del
nostro crate. Il modulo sala è definito nella radice del crate. Anche se
sala non è pubblico, poiché la funzione mangiare_al_ristorante è definita
nello stesso modulo di sala (cioè, mangiare_al_ristorante e sala sono
fratelli), possiamo fare riferimento a sala da mangiare_al_ristorante.
Successivamente, c’è il modulo accoglienza contrassegnato con pub. Possiamo
accedere al modulo genitore di accoglienza, quindi possiamo accedere a
accoglienza. Infine, la funzione aggiungi_in_lista è contrassegnata con
pub e possiamo accedere al suo modulo genitore, quindi questa chiamata di
funzione funziona!
Nel path relativo, la logica è la stessa del path assoluto, tranne per il
primo passaggio: invece di partire dalla radice del crate, il path inizia da
sala. Il modulo sala è definito all’interno dello stesso modulo di
mangiare_al_ristorante, quindi il path relativo che inizia dal modulo in cui
è definita mangiare_al_ristorante funziona. Poi, poiché accoglienza e
aggiungi_in_lista sono contrassegnati con pub, il resto del path funziona,
e questa chiamata di funzione è valida!
Se prevedi di condividere il tuo crate libreria affinché altri progetti possano utilizzare il tuo codice, la tua API pubblica è il tuo contratto con gli utenti del tuo crate che determina come possono interagire con il tuo codice. Ci sono molte considerazioni relative alla gestione delle modifiche alla tua API pubblica per facilitare la dipendenza delle persone dal tuo crate. Queste considerazioni vanno oltre l’ambito di questo libro; se sei interessato a questo argomento, consulta Le Linee Guida per l’API di Rust.
Buone Pratiche per Pacchetti con un Binario e una Libreria
Abbiamo menzionato che un pacchetto può contenere sia una radice di crate binario src/main.rs che una radice di crate libreria src/lib.rs, e entrambi i crate avranno il nome del pacchetto come impostazione predefinita. Tipicamente, i pacchetti che contengono sia una libreria che un crate binario avranno nel crate binario il codice strettamente necessario ad avviare un eseguibile che chiama il codice definito nel crate libreria. Questo consente ad altri progetti di beneficiare della maggior parte delle funzionalità che il pacchetto fornisce, poiché il codice del crate libreria può essere condiviso.
L’albero dei moduli dovrebbe essere definito in src/lib.rs. Quindi, qualsiasi elemento pubblico può essere utilizzato nel crate binario facendo iniziare i path con il nome del pacchetto. Il crate binario diventa un utilizzatore del crate libreria proprio come un crate completamente esterno utilizzerebbe il crate libreria: può utilizzare solo l’API pubblica. Questo ti aiuta a progettare una buona API; non solo sei l’autore, ma sei anche un cliente!
Nel Capitolo 12, dimostreremo questa pratica organizzativa con un programma da riga di comando che conterrà sia un crate binario che un crate libreria.
Iniziare Path Relative con super
Possiamo costruire path relative che iniziano nel modulo genitore, piuttosto
che nel modulo corrente o nella radice del crate, utilizzando super
all’inizio del path. Questo è simile a iniziare un path del filesystem con
la sintassi .. che significa andare nella directory genitore. Utilizzare
super ci consente di fare riferimento a un elemento che sappiamo essere nel
modulo genitore, il che può rendere più facile riorganizzare l’albero dei moduli
quando il modulo è strettamente correlato al genitore, ma il genitore potrebbe
essere spostato altrove nell’albero dei moduli in futuro.
Considera il codice nel Listato 7-8 che modella la situazione in cui un cuoco
corregge un ordine errato e lo porta personalmente al cliente. La funzione
correzione_ordine definita nel modulo cucine chiama la funzione
servi_ordine definita nel modulo genitore specificando il path per
servi_ordine, iniziando con super.
fn servi_ordine() {}
mod cucine {
fn correzione_ordine() {
cucina_ordine();
super::servi_ordine();
}
fn cucina_ordine() {}
}superLa funzione correzione_ordine si trova nel modulo cucine, quindi possiamo
usare super per andare al modulo genitore di cucine, che in questo caso è
crate, la radice. Da lì, cerchiamo servi_ordine e lo troviamo. Successo!
Pensiamo che il modulo cucine e la funzione servi_ordine siano probabilmente
destinati a rimanere nella stessa relazione l’uno con l’altro e verranno
spostati insieme se decidiamo di riorganizzare l’albero dei moduli del crate.
Pertanto abbiamo usato super in modo da avere meno posti da aggiornare nel
codice in futuro se questo codice viene spostato in un modulo diverso.
Rendere Pubbliche Struct e Enum
Possiamo anche utilizzare pub per designare struct ed enum come pubblici,
ma ci sono alcuni dettagli aggiuntivi nell’uso di pub con struct ed enum.
Se utilizziamo pub prima di una definizione di struct, rendiamo la struct
pubblica, ma i campi della struct rimarranno privati (come per i moduli).
Possiamo rendere pubblici o meno ciascun campo caso per caso. Nel Listato 7-9,
abbiamo definito una struct pubblica cucine::Colazione con un campo pubblico
toast ma un campo privato frutta_di_stagione. Questo modella il caso in un
ristorante in cui il cliente può scegliere il tipo di pane che accompagna un
pasto, ma il cuoco decide quale frutta accompagna il pasto in base a ciò che è
di stagione e disponibile. La frutta disponibile cambia rapidamente, quindi i
clienti non possono scegliere la frutta o vedere quale frutta riceveranno.
mod cucine {
pub struct Colazione {
pub toast: String,
frutta_di_stagione: String,
}
impl Colazione {
pub fn estate(toast: &str) -> Colazione {
Colazione {
toast: String::from(toast),
frutta_di_stagione: String::from("pesche"),
}
}
}
}
pub fn mangiare_al_ristorante() {
// Ordina una colazione in estate con pane tostato di segale.
let mut pasto = cucine::Colazione::estate("segale");
// Cambiare idea sul pane che vorremmo.
pasto.toast = String::from("integrale");
println!("Vorrei un toast {}, grazie.", pasto.toast);
// La riga successiva non verrà compilata se la de-commentiamo; non
// ci è permesso vedere o modificare frutta che accompagna il pasto.
// pasto.frutta_di_stagione = String::from("mirtilli");
}Poiché il campo toast nella struct cucine::Colazione è pubblico, in
mangiare_al_ristorante possiamo scrivere e leggere il campo toast
utilizzando la notazione a punto. Nota che non possiamo utilizzare il campo
frutta_di_stagione in mangiare_al_ristorante, perché frutta_di_stagione è
privato. Prova a de-commentare la riga che modifica il valore del campo
frutta_di_stagione per vedere quale errore ottieni!
Inoltre, nota che poiché cucine::Colazione ha un campo privato, la struct
deve fornire una funzione associata pubblica che costruisce un’istanza di
Colazione (qui l’abbiamo chiamata estate). Se Colazione non avesse una
funzione del genere, non potremmo creare un’istanza di Colazione in
mangiare_al_ristorante perché non potremmo impostare il valore del campo
privato frutta_di_stagione in mangiare_al_ristorante.
Al contrario, se rendiamo un’enum pubblico, tutte le sue varianti diventano
pubbliche. Abbiamo bisogno solo di pub prima della parola chiave enum, come
mostrato nel Listato 7-10.
mod cucine {
pub enum Antipasti {
Zuppa,
Insalata,
}
}
pub fn mangiare_al_ristorante() {
let ordine1 = cucine::Antipasti::Zuppa;
let ordine2 = cucine::Antipasti::Insalata;
}Poiché abbiamo reso pubblico l’enum Antipasti, possiamo utilizzare le
varianti Zuppa e Insalata in mangiare_al_ristorante.
Le enum non sono molto utili a meno che le loro varianti non siano pubbliche;
sarebbe fastidioso dover annotare tutte le varianti delle enum con pub una
ad una, quindi la norma per le varianti delle enum è essere pubbliche. Le
struct sono spesso utili senza che i loro campi siano pubblici, quindi i campi
delle struct seguono la regola generale che tutto è privato come impostazione
predefinita, a meno che non sia annotato con pub.
C’è un’ultima situazione che coinvolge pub che non abbiamo trattato, ed è la
nostra ultima caratteristica del sistema dei moduli: la parola chiave use.
Tratteremo use da solo prima, e poi mostreremo come combinare pub e use.
Portare i Percorsi in Scope con la Parola Chiave use
Dover scrivere i percorsi (path) per chiamare le funzioni può risultare
scomodo e ripetitivo. Nel Listato 7-7, sia che scegliessimo il path assoluto o
relativo per la funzione aggiungi_in_lista, ogni volta che volevamo chiamare
aggiungi_in_lista dovevamo specificare anche sala e accoglienza.
Fortunatamente esiste un modo per semplificare questo processo: possiamo creare
un collegamento rapido a un path con la parola chiave use una volta, e poi
usare il nome più corto nel resto dello scope.
Nel Listato 7-11, portiamo il modulo crate::sala::accoglienza nello scope
della funzione mangiare_al_ristorante così da dover specificare solo
accoglienza::aggiungi_in_lista per chiamare la funzione aggiungi_in_lista in
mangiare_al_ristorante.
mod sala {
pub mod accoglienza {
pub fn aggiungi_in_lista() {}
}
}
use crate::sala::accoglienza;
pub fn mangiare_al_ristorante() {
accoglienza::aggiungi_in_lista();
}useAggiungere use e un path in uno scope è simile a creare un collegamento
simbolico nel filesystem. Aggiungendo use crate::sala::accoglienza nella
radice (root) del crate, accoglienza è ora un nome valido in quello
scope, come se il modulo accoglienza fosse stato definito nella radice del
crate. I path portati nello scope con use rispettano anche la privacy,
come qualsiasi altro path.
Nota che use crea il collegamento rapido solo per lo scope particolare in
cui use è dichiarato. Il Listato 7-12 sposta la funzione
mangiare_al_ristorante in un nuovo modulo figlio chiamato cliente, che ora è
in uno scope diverso rispetto alla dichiarazione use, quindi il corpo della
funzione non si compilerà.
mod sala {
pub mod accoglienza {
pub fn aggiungi_in_lista() {}
}
}
use crate::sala::accoglienza;
mod cliente {
pub fn mangiare_al_ristorante() {
accoglienza::aggiungi_in_lista();
}
}use si applica solo allo scope in cui si trovaL’errore del compilatore mostra che il collegamento non si applica più
all’interno del modulo cliente:
$ cargo build
Compiling ristorante v0.1.0 (file:///progetti/ristorante)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `accoglienza`
--> src/lib.rs:11:9
|
11 | accoglienza::aggiungi_in_lista();
| ^^^^^^^^^^^ use of unresolved module or unlinked crate `accoglienza`
|
= help: if you wanted to use a crate named `accoglienza`, use `cargo add accoglienza` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::accoglienza;
|
warning: unused import: `crate::sala::accoglienza`
--> src/lib.rs:7:5
|
7 | use crate::sala::accoglienza;
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` (part of `#[warn(unused)]`) on by default
For more information about this error, try `rustc --explain E0433`.
warning: `ristorante` (lib) generated 1 warning
error: could not compile `ristorante` (lib) due to 1 previous error; 1 warning emitted
Nota che c’è l’avviso che il use non è più usato nel suo scope! Per
risolvere questo problema, sposta il use anche all’interno del modulo
cliente, o riferisciti al collegamento dal modulo genitore con
super::accoglienza all’interno del modulo figlio cliente.
Creare Percorsi use Idiomatici
Nel Listato 7-11, forse ti sarai chiesto perché abbiamo specificato use crate::sala::accoglienza e poi chiamato accoglienza::aggiungi_in_lista in
mangiare_al_ristorante, invece di specificare il path use fino alla
funzione aggiungi_in_lista per ottenere lo stesso risultato, come nel Listato
7-13.
mod sala {
pub mod accoglienza {
pub fn aggiungi_in_lista() {}
}
}
use crate::sala::accoglienza::aggiungi_in_lista;
pub fn mangiare_al_ristorante() {
aggiungi_in_lista();
}aggiungi_in_lista nello scope con use, che non è idiomaticoSebbene sia il Listato 7-11 sia il Listato 7-13 compiano lo stesso compito, il
Listato 7-11 è il modo idiomatico di portare una funzione nello scope con
use. Portare il modulo genitore della funzione nello scope con use
significa che dobbiamo specificare il modulo genitore quando chiamiamo la
funzione. Specificare il modulo genitore quando si chiama la funzione rende
chiaro che la funzione non è definita localmente riducendo comunque la
ripetizione del path completo. Il codice in Listato 7-13 non chiarisce dove
sia definita aggiungi_in_lista.
D’altra parte, quando portiamo struct, enum e altri elementi con use, è
idiomatico specificare il path completo. Il Listato 7-14 mostra il modo
idiomatico per portare, ad esempio, HashMap della libreria standard nello
scope di un crate binario.
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
HashMap nello scope in modo idiomaticoNon c’è una ragione forte dietro questo uso: è semplicemente la convenzione che è emersa, e le persone si sono abituate a leggere e scrivere codice Rust in questo modo.
L’eccezione a questa idioma è se stiamo portando due elementi con lo stesso nome
nello scope con use, perché Rust non lo permette. Il Listato 7-15 mostra
come portare due Result nello scope che hanno lo stesso nome ma moduli
genitore diversi, e come riferirsi a essi.
use std::fmt;
use std::io;
fn funzione1() -> fmt::Result {
// --taglio--
Ok(())
}
fn funzione2() -> io::Result<()> {
// --taglio--
Ok(())
}Come si vede, usare i moduli genitore distingue i due type Result. Se invece
avessimo specificato use std::fmt::Result e use std::io::Result, avremmo due
type Result nello stesso scope, e Rust non saprebbe quale intendessimo
quando avremmo usato Result.
Fornire Nuovi Nomi con la Parola Chiave as
C’è un’altra soluzione al problema di portare due type con lo stesso nome
nello stesso scope con use: dopo il path, possiamo specificare as e un
nuovo nome locale, o alias, per il type. Il Listato 7-16 mostra un altro
modo di scrivere il codice del Listato 7-15 rinominando uno dei due type
Result con as.
use std::fmt::Result;
use std::io::Result as IoResult;
fn funzione1() -> Result {
// --taglio--
Ok(())
}
fn funzione2() -> IoResult<()> {
// --taglio--
Ok(())
}asNella seconda dichiarazione use, abbiamo scelto il nuovo alias IoResult
per il type std::io::Result, che non entrerà in conflitto con il Result di
std::fmt che abbiamo anch’esso portato nello scope. Sia il Listato 7-15 che
il Listato 7-16 sono considerati idiomatici, quindi la scelta spetta a te!
Riesportare Nomi con pub use
Quando portiamo un nome nello scope con la parola chiave use, il nome è
privato allo scope in cui lo abbiamo importato. Per consentire al codice
esterno a quello scope di riferirsi a quel nome come se fosse stato definito
in quello scope, possiamo combinare pub e use. Questa tecnica si chiama
riesportare (re-exporting) perché portiamo un elemento nello scope ma lo
rendiamo anche disponibile affinché altri possano portarlo nel loro scope.
Il Listato 7-17 mostra il codice del Listato 7-11 con use nella radice del
modulo cambiato in pub use.
mod sala {
pub mod accoglienza {
pub fn aggiungi_in_lista() {}
}
}
pub use crate::sala::accoglienza;
pub fn mangiare_al_ristorante() {
accoglienza::aggiungi_in_lista();
}pub usePrima di questa modifica, il codice esterno avrebbe dovuto chiamare la funzione
aggiungi_in_lista usando il path
ristorante::sala::accoglienza::aggiungi_in_lista(), che avrebbe inoltre
richiesto che il modulo sala fosse marcato come pub. Ora che questo pub use ha riesportato il modulo accoglienza dalla radice del modulo, il codice
esterno può invece usare il path
ristorante::accoglienza::aggiungi_in_lista().
La riesportazione è utile quando la struttura interna del tuo codice è diversa
da come i programmatori che chiamano il tuo codice penserebbero al dominio. Per
esempio, in questa metafora del ristorante, chi gestisce il ristorante pensa in
termini di “sala” e “cucine”. Ma i clienti che visitano un ristorante
probabilmente non penseranno alle parti del ristorante in questi termini. Con
pub use, possiamo scrivere il nostro codice con una struttura e però esporre
una struttura diversa. Ciò rende la nostra libreria ben organizzata sia per i
programmatori che lavorano sulla libreria sia per i programmatori che la usano.
Vedremo un altro esempio di pub use e di come influisce sulla documentazione
del crate nella sezione “Esportare un API Pubblica
Efficace”del Capitolo 14.
Usare Pacchetti Esterni
Nel Capitolo 2, abbiamo programmato un progetto del gioco degli indovinelli che
usava un pacchetto esterno chiamato rand per ottenere numeri casuali. Per
usare rand nel nostro progetto, abbiamo aggiunto questa riga a Cargo.toml:
rand = "0.8.5"
Aggiungere rand come dipendenza in Cargo.toml dice a Cargo di scaricare il
pacchetto rand e le sue dipendenze da crates.io e di
rendere rand disponibile al nostro progetto.
Poi, per portare le definizioni di rand nello scope del nostro pacchetto,
abbiamo aggiunto una riga use che cominciava con il nome del crate, rand,
e elencava gli elementi che volevamo portare nello scope. Ricorda come nella
sezione “Generare un Numero Casuale” del Capitolo 2
abbiamo portato il trait Rng nello scope e chiamato la funzione
rand::thread_rng:
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
}Membri della community Rust hanno reso molti pacchetti disponibili su
crates.io, e includere uno di essi nel tuo pacchetto
implica gli stessi passi: elencarlo nel file Cargo.toml del tuo pacchetto e
usare use per portare elementi dai loro crate nello scope.
Nota che la libreria standard std è anch’essa un crate esterno al nostro
pacchetto. Poiché la libreria standard è distribuita con il linguaggio Rust, non
dobbiamo modificare Cargo.toml per includere std. Ma dobbiamo comunque
riferirci ad essa con use per portare elementi da lì nello scope del nostro
pacchetto. Per esempio, per HashMap useremmo questa riga:
#![allow(unused)] fn main() { use std::collections::HashMap; }
Questo è un path assoluto che inizia con std, il nome del crate della
libreria standard.
Usare Percorsi Nidificati per Accorpare Elenchi di use
Se usiamo più elementi definiti nello stesso crate o nello stesso modulo,
elencare ogni elemento su una sua riga può occupare molto spazio verticale nei
file. Per esempio, queste due dichiarazioni use che avevamo nel gioco degli
indovinelli nel Listato 2-4 portano elementi da std nello scope:
use rand::Rng;
// --taglio--
use std::cmp::Ordering;
use std::io;
// --taglio--
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
println!("Hai ipotizzato: {ipotesi}");
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => println!("Hai indovinato!"),
}
}Invece, possiamo usare path nidificati per portare gli stessi elementi nello scope in una sola riga. Lo facciamo specificando la parte comune del path, seguita da due due punti, e poi parentesi graffe intorno a una lista delle parti che differiscono dei path, come mostrato nel Listato 7-18.
use rand::Rng;
// --taglio--
use std::{cmp::Ordering, io};
// --taglio--
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: u32 = ipotesi.trim().parse().expect("Inserisci un numero!");
println!("Hai ipotizzato: {ipotesi}");
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => println!("Hai indovinato!"),
}
}Nei programmi più grandi, portare molti elementi nello scope dallo stesso
crate o modulo usando path nidificati può ridurre di molto il numero di
dichiarazioni use separate necessarie!
Possiamo usare un path nidificato a qualsiasi livello in un path, il che è
utile quando si combinano due dichiarazioni use che condividono una parte di
path. Per esempio, il Listato 7-19 mostra due dichiarazioni use: una che
porta std::io nello scope e una che porta std::io::Write nello scope.
use std::io;
use std::io::Write;use che condividono parte della pathLa parte comune di questi due path è std::io, ed è il path completo della
prima path. Per unire questi due path in una sola dichiarazione use,
possiamo usare self nel path nidificato, come mostrato nel Listato 7-20.
use std::io::{self, Write};useQuesta riga porta std::io e std::io::Write nello scope.
Importare Elementi con l’Operatore Glob
Se vogliamo portare tutti gli elementi pubblici definiti in un path nello
scope, possiamo specificare quel path seguito dall’operatore glob *:
#![allow(unused)] fn main() { use std::collections::*; }
Questa dichiarazione use porta tutti gli elementi pubblici definiti in
std::collections nello scope corrente. Stai attento quando usi l’operatore
glob! Il glob può rendere più difficile capire quali nomi sono nello scope
e da dove proviene un nome usato nel tuo programma. Inoltre, se la dipendenza
cambia le sue definizioni, ciò che hai importato cambia a sua volta, il che può
portare a errori del compilatore quando aggiorni la dipendenza se la dipendenza
aggiunge una definizione con lo stesso nome di una tua definizione nello stesso
scope, per esempio.
L’operatore glob viene spesso usato durante i test per portare tutto ciò che è
sotto test nel modulo tests; parleremo di questo nella sezione “Come Scrivere
dei Test” del Capitolo 11. L’operatore glob è
anche a volte usato come parte del pattern prelude: vedi la documentazione
della libreria standard per ulteriori informazioni su
quel pattern.
Separare i Moduli in File Diversi
Finora tutti gli esempi di questo capitolo definivano più moduli in un unico file. Quando i moduli diventano grandi, potresti voler spostare le loro definizioni in file separati per rendere il codice più facile da navigare.
Per esempio, partiamo dal codice nel Listato 7-17 che aveva più moduli del ristorante. Metteremo ogni modulo in un file invece di avere tutte le definizioni nella radice del crate. In questo caso, il file radice del crate è src/lib.rs, ma questa procedura funziona anche con crate binari il cui file radice è src/main.rs.
Per prima cosa spostiamo il modulo sala in un proprio file. Rimuovi il codice
dentro le parentesi graffe del modulo sala, lasciando solo la dichiarazione
mod sala;, così che src/lib.rs contenga il codice mostrato nel Listato 7-21.
Nota che questo non compilerà finché non creiamo il file src/sala.rs mostrato
nel Listato 7-22.
mod sala;
pub use crate::sala::accoglienza;
pub fn mangiare_al_ristorante() {
accoglienza::aggiungi_in_lista();
}sala il cui corpo sarà in src/sala.rsOra, metti il codice che era dentro le parentesi graffe in un nuovo file
chiamato src/sala.rs, come mostrato nel Listato 7-22. Il compilatore sa di
dover cercare in questo file perché ha incontrato la dichiarazione del modulo
nella radice del crate con il nome sala.
pub mod accoglienza {
pub fn aggiungi_in_lista() {}
}sala in src/sala.rsNota che è necessario caricare un file usando una dichiarazione mod una sola
volta nell’albero dei moduli. Una volta che il compilatore sa che il file fa
parte del progetto (e sa dove si trova nell’albero dei moduli grazie a dove hai
messo la dichiarazione mod), gli altri file del progetto dovrebbero riferirsi
al codice del file caricato usando un path verso il punto in cui è stato
dichiarato, come trattato nella sezione “Percorsi per fare riferimento a un
elemento nell’albero dei moduli”. In altre parole, mod
non è un’operazione di “include” come potresti aver visto in altri linguaggi.
Successivamente, sposteremo il modulo accoglienza in un suo file. Il processo
è un po’ diverso perché accoglienza è un modulo figlio di sala, non della
radice. Metteremo il file per accoglienza in una nuova cartella che sarà
chiamata come i suoi antenati nell’albero dei moduli, in questo caso src/sala.
Per iniziare a spostare accoglienza, cambiamo src/sala.rs in modo che
contenga solo la dichiarazione del modulo accoglienza:
pub mod accoglienza;Poi creiamo una cartella src/sala e un file accoglienza.rs per contenere le
definizioni del modulo accoglienza:
pub fn aggiungi_in_lista() {}Se invece mettessimo accoglienza.rs nella cartella src, il compilatore si
aspetterebbe che il codice di accoglienza.rs sia in un modulo accoglienza
dichiarato nella radice del crate, e non come figlio del modulo sala. Le
regole del compilatore su quali file cercare per il codice di quali moduli fanno
sì che cartelle e file rispecchino più da vicino l’albero dei moduli.
Percorsi di File Alternativi
Finora abbiamo coperto i percorsi di file più idiomatici che il compilatore
Rust usa, ma Rust supporta anche uno stile più vecchio. Per un modulo chiamato
sala dichiarato nella radice del crate, il compilatore cercherà il codice
del modulo in:
- src/sala.rs (quello che abbiamo visto)
- src/sala/mod.rs (stile più vecchio, ancora supportato)
Per un modulo chiamato accoglienza che è un sotto-modulo di sala, il
compilatore cercherà il codice del modulo in:
- src/sala/accoglienza.rs (quello che abbiamo visto)
- src/sala/accoglienza/mod.rs (stile più vecchio, ancora supportato)
Se usi entrambi gli stili per lo stesso modulo, otterrai un errore del compilatore. Usare una combinazione di stili diversi per moduli differenti nello stesso progetto è permesso, ma potrebbe confondere chi oltre a te prende in mano il progetto.
Lo svantaggio principale dello stile con file chiamati mod.rs è che il progetto può finire con molti file chiamati mod.rs, il che può diventare confusionario quando li hai aperti contemporaneamente nell’editor.
Abbiamo spostato il codice di ogni modulo in file separati e l’albero dei moduli
rimane lo stesso. Le chiamate di funzione in mangiare_al_ristorante
funzioneranno senza alcuna modifica, anche se le definizioni vivono in file
diversi. Questa tecnica ti permette di muovere i moduli in nuovi file man mano
che crescono di dimensione.
Nota che la dichiarazione pub use crate::sala::accoglienza in src/lib.rs non
è cambiata, né use ha alcun impatto su quali file vengono compilati come parte
del crate. La parola chiave mod dichiara moduli, e Rust cerca in un file con
lo stesso nome del modulo il codice che va in quel modulo.
Riepilogo
Rust ti permette di dividere un pacchetto in più crate e un crate in moduli
così da poter riferire elementi definiti in un modulo da un altro modulo. Puoi
farlo specificando path assoluti o relativi. Questi path possono essere
portati nello scope con una dichiarazione use così da poter usare un path
più corto per usi ripetuti dell’elemento in quello scope. Il codice dei moduli
è privato per default, ma puoi rendere le definizioni pubbliche aggiungendo la
parola chiave pub.
Nel prossimo capitolo vedremo alcune strutture dati di collezione nella libreria standard che puoi usare per rendere ancor più ordinato il tuo codice.
Collezioni Comuni
La libreria standard di Rust include diverse strutture dati molto utili chiamate collezioni (collections). La maggior parte degli altri type rappresenta un valore specifico, ma le collezioni possono contenere più valori. A differenza di array e tuple, i dati a cui puntano queste collezioni vengono memorizzati nell’heap, il che significa che la quantità di dati non deve essere nota in fase di compilazione e può aumentare o diminuire durante l’esecuzione del programma. Ogni tipo di collezione ha funzionalità e costi diversi, e sceglierne una appropriata per le necessità del momento è un’abilità che si svilupperà nel tempo. In questo capitolo, parleremo di tre collezioni utilizzate molto spesso nei programmi Rust:
- Un vector che consente di memorizzare un numero variabile di valori uno accanto all’altro.
- Una string è una raccolta di caratteri. Abbiamo menzionato il type
Stringin precedenza, ma in questo capitolo ne parleremo in modo approfondito. - Una hash map che consente di associare un valore a una chiave specifica. Si tratta di una particolare implementazione della struttura dati più generale chiamata map.
Per saperne di più sugli altri tipi di collezioni fornite dalla libreria standard, vedere la documentazione.
Parleremo di come creare e aggiornare vector, string e hash map, nonché cosa rende ciascuna di esse speciale.
Memorizzare Elenchi di Valori con Vettori
Il primo tipo di collezione che esamineremo è Vec<T>, nota anche come
vector. I vettori consentono di memorizzare più di un valore in un’unica
struttura dati che mette tutti i valori uno accanto all’altro in memoria. I
vettori possono memorizzare solo valori dello stesso type. Sono utili quando
si ha un elenco di elementi, come le righe di testo in un file o i prezzi degli
articoli in un carrello.
Creare un Nuovo Vettore
Per creare un nuovo vettore vuoto, chiamiamo la funzione Vec::new, come
mostrato nel Listato 8-1.
fn main() { let v: Vec<i32> = Vec::new(); }
i32Nota che qui abbiamo aggiunto un’annotazione di type. Poiché non stiamo
inserendo alcun valore in questo vettore, Rust non sa che tipo di elementi
intendiamo memorizzare. Questo è un punto importante. I vettori vengono
implementati utilizzando i type generici; spiegheremo come utilizzare i type
generici quando si creano type propri nel Capitolo 10. Per ora, sappiamo che
il type Vec<T> fornito dalla libreria standard può contenere qualsiasi
type. Quando creiamo un vettore per contenere uno specifico type, possiamo
specificarlo tra parentesi angolari. Nel Listato 8-1, abbiamo detto a Rust che
Vec<T> in v conterrà elementi di type i32.
Più spesso, si crea un Vec<T> con valori iniziali e Rust dedurrà il type dai
valori che si desidera memorizzare, quindi raramente è necessario eseguire
questa annotazione di type. Rust fornisce opportunamente la macro vec!, che
creerà un nuovo vettore contenente i valori che gli vengono assegnati. Il
Listato 8-2 crea un nuovo Vec<i32> che contiene i valori 1, 2 e 3. Il
type intero è i32 perché è il type intero predefinito, come discusso nella
sezione “Tipi di Dato” del Capitolo 3.
fn main() { let v = vec![1, 2, 3]; }
Poiché abbiamo assegnato valori iniziali i32, Rust può dedurre che il type
di v è Vec<i32> e l’annotazione di type non è necessaria. Successivamente,
vedremo come modificare un vettore.
Aggiornare un Vettore
Per creare un vettore e aggiungervi elementi, possiamo usare il metodo push,
come mostrato nel Listato 8-3.
fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
push per aggiungere valori a un vettoreCome per qualsiasi variabile, se vogliamo poterne modificare il valore, dobbiamo
renderla mutabile usando la parola chiave mut, come discusso nel Capitolo 3. I
numeri che inseriamo al suo interno sono tutti di type i32, e Rust lo deduce
dai dati, quindi non abbiamo bisogno dell’annotazione Vec<i32>.
Leggere Elementi dei Vettori
Esistono due modi per fare riferimento a un valore memorizzato in un vettore:
tramite indicizzazione o utilizzando il metodo get. Negli esempi seguenti,
abbiamo annotato i type dei valori restituiti da queste funzioni per maggiore
chiarezza.
Il Listato 8-4 mostra entrambi i metodi per accedere a un valore in un vettore,
con la sintassi di indicizzazione e il metodo get.
fn main() { let v = vec![1, 2, 3, 4, 5]; let terzo: &i32 = &v[2]; println!("Il terzo elemento è {terzo}"); let terzo: Option<&i32> = v.get(2); match terzo { Some(terzo) => println!("Il terzo elemento è {terzo}"), None => println!("Non c'è un terzo elemento."), } }
get per accedere a un elemento in un vettoreSono da notare alcuni dettagli. Utilizziamo il valore di indice 2 per ottenere
il terzo elemento poiché i vettori sono indicizzati per numero, a partire da
zero. Utilizzando & e [] otteniamo un reference all’elemento a
quell’indice. Quando utilizziamo il metodo get con l’indice passato come
argomento, otteniamo un Option<&T> che possiamo utilizzare con match.
Rust fornisce questi due modi per ottenere un reference ad un elemento, in modo da poter scegliere come il programma si comporta quando si tenta di utilizzare un valore di indice al di fuori dell’intervallo di elementi esistenti. Ad esempio, vediamo cosa succede quando abbiamo un vettore di cinque elementi e poi proviamo ad accedere a un elemento all’indice 100 con ciascuna tecnica, come mostrato nel Listato 8-5.
fn main() { let v = vec![1, 2, 3, 4, 5]; let non_esiste = &v[100]; let non_esiste = v.get(100); }
Quando eseguiamo questo codice, il primo metodo [] causerà un crash del
programma perché fa riferimento ad un elemento inesistente. Questo metodo è
ideale quando si desidera che il programma si blocchi in caso di tentativo di
accesso a un elemento oltre la fine del vettore.
Quando al metodo get viene passato un indice esterno al vettore, restituisce
None senza crash. Si consiglia di utilizzare questo metodo se l’accesso a un
elemento oltre l’intervallo del vettore può verificarsi occasionalmente in
circostanze normali. Il codice avrà quindi una logica per gestire sia
Some(&element) che None, come discusso nel Capitolo 6. Ad esempio, l’indice
potrebbe provenire da un utente che inserisce un numero. Se inserisce
accidentalmente un numero troppo grande e il programma ottiene un valore None,
è possibile indicare all’utente quanti elementi sono presenti nel vettore
corrente e dargli un’altra possibilità di inserire un valore valido. Sarebbe più
intuitivo che mandare in crash il programma a causa di un errore di battitura!
Quando il programma ha un reference valido, il sistema applica le regole di ownership e borrowing (trattate nel Capitolo 4) per garantire che questo reference e qualsiasi altro reference al contenuto del vettore rimangano validi. Ricordati la regola che stabilisce che non è possibile avere reference mutabili e immutabili nello stesso scope. Questa regola si applica al Listato 8-6, dove manteniamo un reference immutabile al primo elemento di un vettore e proviamo ad aggiungere un elemento alla fine. Questo programma non funzionerà se proviamo a fare reference a quell’elemento anche più avanti nella funzione.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let primo = &v[0];
v.push(6);
println!("Il primo elemento è: {primo}");
}La compilazione di questo codice genererà questo errore:
$ cargo run
Compiling collections v0.1.0 (file:///progetti/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:7:5
|
5 | let primo = &v[0];
| - immutable borrow occurs here
6 |
7 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
8 |
9 | println!("Il primo elemento è: {primo}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Il codice nel Listato 8-6 potrebbe sembrare funzionante: perché un reference al primo elemento dovrebbe preoccuparsi delle modifiche alla fine del vettore? Questo errore è dovuto al funzionamento dei vettori: poiché i vettori posizionano i valori uno accanto all’altro in memoria, se non c’è abbastanza spazio per posizionare tutti gli elementi uno accanto all’altro dove il vettore è attualmente memorizzato l’aggiunta di un nuovo elemento alla fine del vettore potrebbe richiedere l’allocazione di nuova memoria e la copia dei vecchi elementi nel nuovo spazio. In tal caso, il reference al primo elemento punterebbe alla memoria de-allocata. Le regole di borrowing impediscono ai programmi di finire in questa situazione.
Nota: per maggiori dettagli sull’implementazione del type
Vec<T>, vedere “Il Rustonomicon”.
Iterare sui Valori di un Vettore
Per accedere a ogni elemento di un vettore a turno, dovremmo iterare su tutti
gli elementi anziché utilizzare gli indici per accedervi uno alla volta. Il
Listato 8-7 mostra come utilizzare un ciclo for per ottenere reference
immutabili a ciascun elemento in un vettore di valori i32 e stamparli.
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
forPossiamo anche iterare su reference mutabili a ciascun elemento in un vettore
mutabile per apportare modifiche a tutti gli elementi. Il ciclo for nel
Listato 8-8 aggiungerà 50 a ciascun elemento.
fn main() { let mut v = vec![100, 32, 57]; for i in &mut v { *i += 50; } }
Per modificare il valore a cui punta il reference mutabile, dobbiamo usare
l’operatore di de-referenziazione * per arrivare al valore in i prima di
poter usare l’operatore +=. Approfondiremo l’operatore di de-referenziazione
nella sezione “Seguire il Reference al Valore” del
Capitolo 15.
L’iterazione su un vettore, sia immutabile che mutabile, è sicura grazie alle
regole di ownership e borrowing. Se tentassimo di inserire o rimuovere
elementi nei corpi del ciclo for nei Listati 8-7 e 8-8, otterremmo un errore
del compilatore simile a quello ottenuto con il codice nel Listato 8-6. Il
reference al vettore contenuto nel ciclo for impedisce la modifica
simultanea dell’intero vettore.
Utilizzare un’Enum per Memorizzare Più Type
I vettori possono memorizzare solo valori dello stesso type. Questo può essere scomodo; ci sono sicuramente casi d’uso in cui è necessario memorizzare un elenco di elementi di type diverso. Fortunatamente, le varianti di un’enum sono definite sotto lo stesso type di enum, quindi quando abbiamo bisogno di un type per rappresentare elementi di tipi diversi, possiamo definire e utilizzare un’enum!
Ad esempio, supponiamo di voler ottenere valori da una riga di un foglio di calcolo in cui alcune colonne della riga contengono numeri interi, alcuni numeri in virgola mobile e alcune stringhe. Possiamo definire un’enum le cui varianti conterranno i diversi tipi di valore, e tutte le varianti dell’enum saranno considerate dello stesso type: quello dell’enum. Possiamo adesso creare un vettore per contenere quell’enum e quindi, in definitiva, contenere type “diversi”. Lo abbiamo dimostrato nel Listato 8-9.
fn main() { enum CellaFoglioDiCalcolo { Int(i32), Float(f64), Text(String), } let row = vec![ CellaFoglioDiCalcolo::Int(3), CellaFoglioDiCalcolo::Text(String::from("blu")), CellaFoglioDiCalcolo::Float(10.12), ]; }
Rust deve sapere quali type saranno presenti nel vettore in fase di
compilazione, in modo da sapere esattamente quanta memoria nell’heap sarà
necessaria per memorizzare ogni elemento. Dobbiamo anche essere espliciti sui
type consentiti in questo vettore. Se Rust permettesse a un vettore di
contenere qualsiasi type, ci sarebbe la possibilità che uno o più type
causino errori nelle operazioni eseguite sugli elementi del vettore. L’utilizzo
di un’enum assieme ad un’espressione match significa che Rust garantirà in
fase di compilazione che ogni possibile caso venga gestito, come discusso nel
Capitolo 6.
Se non si conosce l’insieme esaustivo di type che un programma avrà una volta in esecuzione da memorizzare in un vettore, la tecnica dell’enum non funzionerà. In alternativa, è possibile utilizzare un oggetto trait, che tratteremo nel Capitolo 18.
Ora che abbiamo discusso alcuni dei modi più comuni per utilizzare i vettori,
assicurati di consultare la documentazione dell’API
per tutti i numerosi metodi utili definiti su Vec<T> dalla libreria standard.
Ad esempio, oltre a push, un metodo pop rimuove e restituisce l’ultimo
elemento.
Eliminare un Vettore Elimina i Suoi Elementi
Come qualsiasi altra struct, un vettore viene rilasciato quando esce dallo
scope, come annotato nel Listato 8-10.
fn main() { { let v = vec![1, 2, 3, 4]; // esegui operazioni su `v` } // <- qui `v` esce dallo scope e la memoria viene liberata }
Quando il vettore viene rilasciato, anche tutto il suo contenuto viene de-allocato, il che significa che gli interi in esso contenuti verranno de-allocati. Il borrow checker (controllo dei prestiti) garantisce che qualsiasi reference al contenuto di un vettore venga utilizzato solo finché il vettore stesso è valido.
Passiamo al tipo di collezione successivo: String!
Memorizzare Testo Codificato UTF-8 con Stringhe
Abbiamo parlato delle stringhe nel Capitolo 4, ma ora le analizzeremo più approfonditamente. I nuovi Rustacean spesso si bloccano sulle stringhe per una combinazione di tre ragioni: la propensione di Rust a esporre possibili errori, il fatto che le stringhe siano una struttura dati più complicata di quanto molti programmatori credano e la codifica UTF-8. Questi fattori si combinano in un modo che può sembrare difficile per chi proviene da altri linguaggi di programmazione.
Parleremo delle stringhe nel contesto delle collezioni perché le stringhe sono
implementate come una collezione di byte, oltre ad alcuni metodi per fornire
funzionalità utili quando tali byte vengono interpretati come testo. In questa
sezione, parleremo delle operazioni su String che ogni tipo di collezione
prevede, come creazione, aggiornamento e lettura. Discuteremo anche le
differenze tra String e le altre collezioni, in particolare come
l’indicizzazione in una String sia complicata dalle differenze tra il modo in
cui le persone e i computer interpretano i dati String.
Definire le Stringhe
Definiremo innanzitutto cosa intendiamo con il termine stringa. Rust ha un
solo type di stringa nel linguaggio principale, ovvero la slice di stringa
str che viene principalmente utilizzata come reference &str. Nel Capitolo
4 abbiamo parlato delle slice di stringa, che sono reference ad alcuni dati
stringa codificati in UTF-8 memorizzati altrove. I letterali stringa, ad
esempio, sono memorizzati nel binario del programma e sono quindi slice di
stringa.
Il type String, fornito dalla libreria standard di Rust anziché esser
definito nel linguaggio principale, è un type di stringa codificato in UTF-8,
con ownership, espandibile e modificabile. Quando i Rustacean fanno
riferimento alle “stringhe” in Rust, potrebbero riferirsi sia al type String
che alla slice di stringa &str, e non solo a uno di questi type. Sebbene
questa sezione tratterà principalmente String, entrambe le tipologie sono
ampiamente utilizzate nella libreria standard di Rust, e sia String che le
slice sono codificate in UTF-8.
Creare una Nuova String
Molte delle operazioni disponibili con Vec<T> sono disponibili anche con
String perché String è in realtà implementata come wrapper (involucro)
attorno a un vettore di byte con alcune garanzie, restrizioni e funzionalità
aggiuntive. Ad esempio, la funzione new per creare un’istanza, funziona allo
stesso modo sia con Vec<T> che con String. Eccola mostrata nel Listato 8-11.
fn main() { let mut s = String::new(); }
String vuotaQuesta riga crea una nuova stringa vuota chiamata s, in cui possiamo quindi
caricare i dati. Spesso, avremo dei dati iniziali con cui vogliamo inizializzare
la stringa. Per questo, utilizziamo il metodo to_string, disponibile su
qualsiasi type che implementi il trait Display, come fanno i letterali
stringa. Il Listato 8-12 mostra due esempi.
fn main() { let data = "contenuto iniziale"; let s = data.to_string(); // Il metodo funziona anche direttamente sul letterale: let s = "contenuto iniziale".to_string(); }
to_string per creare una String da un letterale stringaQuesto codice crea una stringa contenente contenuto iniziale.
Possiamo anche utilizzare la funzione String::from per creare una String da
un letterale stringa. Il codice nel Listato 8-13 è equivalente al codice nel
Listato 8-12 che utilizza to_string.
fn main() { let s = String::from("contenuto iniziale"); }
String::from per creare una String da un letterale stringaPoiché le stringhe vengono utilizzate per così tante cose, possiamo utilizzare
diverse API generiche per le stringhe, offrendoci numerose opzioni. Alcune
possono sembrare ridondanti, ma hanno tutte la loro importanza! In questo caso,
String::from e to_string svolgono la stessa funzione, quindi la scelta è una
questione di stile e leggibilità.
Ricorda che le stringhe sono codificate in UTF-8, quindi possiamo includere qualsiasi dato codificato correttamente, come mostrato nel Listato 8-14.
fn main() { let saluto = String::from("السلام عليكم"); let saluto = String::from("Dobrý den"); let saluto = String::from("Hello"); let saluto = String::from("שלום"); let saluto = String::from("नमस्ते"); let saluto = String::from("こんにちは"); let saluto = String::from("안녕하세요"); let saluto = String::from("你好"); let saluto = String::from("Olá"); let saluto = String::from("Здравствуйте"); let saluto = String::from("Hola"); }
Tutti questi sono valori String validi.
Aggiornare una String
Una String può crescere di dimensione e il suo contenuto può cambiare, proprio
come il contenuto di un Vec<T>, se vi si inseriscono più dati. Inoltre, è
possibile utilizzare comodamente l’operatore + o la macro format! per
concatenare valori String.
Aggiungere con push_str e push
Possiamo far crescere una String utilizzando il metodo push_str per
aggiungere una slice di stringa, come mostrato nel Listato 8-15.
fn main() { let mut s = String::from("foo"); s.push_str("bar"); }
String utilizzando il metodo push_strDopo queste due righe, s conterrà foobar. Il metodo push_str accetta una
slice di stringa perché non vogliamo necessariamente prendere ownership del
parametro. Ad esempio, nel codice del Listato 8-16, vogliamo poter utilizzare
s2 dopo averne aggiunto il contenuto a s1.
fn main() { let mut s1 = String::from("foo"); let s2 = "bar"; s1.push_str(s2); println!("s2 è {s2}"); }
StringSe il metodo push_str prendesse ownership di s2, non saremmo in grado di
stamparne il valore sull’ultima riga. Tuttavia, questo codice funziona come
previsto!
Il metodo push prende un singolo carattere come parametro e lo aggiunge alla
String. Il Listato 8-17 aggiunge la lettera l a una String utilizzando il
metodo push.
fn main() { let mut s = String::from("lo"); s.push('l'); }
String utilizzando pushDi conseguenza, s conterrà lol.
Concatenare con + o format!
Spesso, si desidera combinare due stringhe esistenti. Un modo per farlo è
utilizzare l’operatore +, come mostrato nel Listato 8-18.
fn main() { let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // nota che s1 è stato spostato qui e non può più essere utilizzato }
+ per combinare due valori String in un nuovo valore StringLa stringa s3 conterrà Hello, world!. Il motivo per cui s1 non è più
valido dopo l’aggiunta, e il motivo per cui abbiamo utilizzato un reference a
s2, ha a che fare con la firma del metodo chiamato quando utilizziamo
l’operatore +. L’operatore + utilizza il metodo add, la cui firma è simile
a questa:
fn add(self, s: &str) -> String {Nella libreria standard, add è definito utilizzando type generici e type
associati. Qui, abbiamo sostituito type concreti, che è ciò che accade quando
chiamiamo questo metodo con valori String. Parleremo dei generici nel Capitolo
10. Questa firma ci fornisce gli indizi necessari per comprendere le parti più
complesse dell’operatore +.
Innanzitutto, s2 ha un &, il che significa che stiamo aggiungendo un
reference della seconda stringa alla prima stringa. Questo è dovuto al
parametro s nella funzione add: possiamo solo aggiungere una slice di
stringa a una String; non possiamo aggiungere due valori String insieme. Ma
aspetta: il type di &s2 è &String, non &str, come specificato nel
secondo parametro di add. Quindi perché il Listato 8-18 si compila?
Il motivo per cui possiamo usare &s2 nella chiamata a add è che il
compilatore può costringere l’argomento &String in un &str. Quando
chiamiamo il metodo add , Rust usa una deref coercion (de-referenziazione
forzata), che qui trasforma &s2 in &s2[..]. Discuteremo la deref coercion
più approfonditamente nel Capitolo 15. Poiché add non prende ownership del
parametro s, s2 sarà comunque una String valida dopo questa operazione.
In secondo luogo, possiamo vedere nella firma che add prende ownership di
self perché self non ha un &. Ciò significa che s1 nel Listato 8-18
verrà spostato nella chiamata add e non sarà più valido da quel momento in
poi. Quindi, sebbene let s3 = s1 + &s2; sembri copiare entrambe le stringhe e
crearne una nuova, questa istruzione in realtà prende ownership di s1,
aggiunge una copia del contenuto di s2 per poi restituire la ownership del
risultato. In altre parole, sembra che stia facendo molte copie, ma non è così;
l’implementazione è più efficiente della semplice copia.
Se dobbiamo concatenare più stringhe, il comportamento dell’operatore +
diventa poco pratico:
fn main() { let s1 = String::from("uno"); let s2 = String::from("due"); let s3 = String::from("tre"); let s = s1 + "-" + &s2 + "-" + &s3; }
A questo punto, s diventerà uno-due-tre. Con tutti i caratteri + e ", è
difficile capire cosa sta succedendo. Per combinare stringhe in modi più
complessi, possiamo invece usare la macro format!:
fn main() { let s1 = String::from("uno"); let s2 = String::from("due"); let s3 = String::from("tre"); let s = format!("{s1}-{s2}-{s3}"); }
Anche questo codice risulterà in s che contiene uno-due-tre. La macro
format! funziona come println!, ma invece di visualizzare l’output sullo
schermo, restituisce una String con il contenuto. La versione del codice che
utilizza format! è molto più facile da leggere e il codice generato dalla
macro format! utilizza reference in modo che questa chiamata non assuma
ownership di nessuno dei suoi parametri.
Indicizzazione in String
In molti altri linguaggi di programmazione, l’accesso a singoli caratteri in una
stringa facendovi riferimento tramite indice è un’operazione valida e comune.
Tuttavia, se si tenta di accedere a parti di una String utilizzando la
sintassi di indicizzazione in Rust, si otterrà un errore. Considera il codice
non valido nel Listato 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}StringQuesto codice genererà il seguente errore:
$ cargo run
Compiling collections v0.1.0 (file:///progetti/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:4:16
|
4 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
L’errore spiega la situazione: le stringhe Rust non supportano l’indicizzazione. Ma perché no? Per rispondere a questa domanda, dobbiamo discutere come Rust memorizza le stringhe in memoria.
Rappresentazione Interna
Una String è un wrapper di un Vec<u8>. Diamo un’occhiata ad alcune delle
nostre stringhe di esempio correttamente codificate UTF-8 dal Listato 8-14.
Innanzitutto, questo:
fn main() { let saluto = String::from("السلام عليكم"); let saluto = String::from("Dobrý den"); let saluto = String::from("Hello"); let saluto = String::from("שלום"); let saluto = String::from("नमस्ते"); let saluto = String::from("こんにちは"); let saluto = String::from("안녕하세요"); let saluto = String::from("你好"); let saluto = String::from("Olá"); let saluto = String::from("Здравствуйте"); let saluto = String::from("Hola"); }
In questo caso, len sarà 4, il che significa che il vettore che memorizza la
stringa "Hola" è lungo 4 byte. Ognuna di queste lettere occupa 1 byte se
codificata in UTF-8. La riga seguente, tuttavia, potrebbe sorprenderti (nota che
questa stringa inizia con la lettera maiuscola cirillica Ze, non con il numero
3):
fn main() { let saluto = String::from("السلام عليكم"); let saluto = String::from("Dobrý den"); let saluto = String::from("Hello"); let saluto = String::from("שלום"); let saluto = String::from("नमस्ते"); let saluto = String::from("こんにちは"); let saluto = String::from("안녕하세요"); let saluto = String::from("你好"); let saluto = String::from("Olá"); let saluto = String::from("Здравствуйте"); let saluto = String::from("Hola"); }
Se ti chiedessero quanto è lunga la stringa, potresti dire 12. In realtà, la risposta di Rust è 24: questo è il numero di byte necessari per codificare “Здравствуйте” in UTF-8, perché ogni valore scalare Unicode in quella stringa occupa 2 byte di spazio. Pertanto, un indice nei byte della stringa non sarà sempre correlato a un valore scalare Unicode valido. Per dimostrarlo, consideriamo questo codice Rust non valido:
let saluto = "Здравствуйте";
let risposta = &hello[0];Sai già che risposta non sarà З, la prima lettera. Quando codificato in
UTF-8, il primo byte di З è 208 e il secondo è 151, quindi sembrerebbe che
risposta dovrebbe in effetti essere 208, ma 208 non è un carattere valido
da solo. Restituire 208 probabilmente non è ciò che un utente vorrebbe se
chiedesse la prima lettera di questa stringa; Tuttavia, questo è l’unico dato
che Rust ha all’indice di byte 0. Gli utenti generalmente non vogliono che venga
restituito il valore in byte, anche se la stringa contiene solo lettere latine:
se &"hi"[0] fosse codice valido che restituisce il valore in byte,
restituirebbe 104, non h.
La risposta, quindi, è che per evitare di restituire un valore inaspettato e causare bug che potrebbero non essere scoperti immediatamente, Rust non compila affatto questo codice e previene malintesi fin dalle prime fasi del processo di sviluppo.
Byte, Valori Scalari e Cluster di Grafemi!
Un altro punto su UTF-8 è che in realtà ci sono tre modi rilevanti per vedere le stringhe dalla prospettiva di Rust: come byte, valori scalari e cluster di grafemi (la cosa più vicina a ciò che chiameremmo lettere).
Se consideriamo la parola hindi “नमस्ते” scritta in alfabeto Devanagari, essa è
memorizzata come un vettore di valori u8 che appare così:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Sono 18 byte ed è così che i computer memorizzano questi dati. Se li
consideriamo come valori scalari Unicode, che corrispondono al type char di
Rust, quei byte appaiono così:
['न', 'म', 'स', '्', 'त', 'े']
Ci sono sei valori char qui, ma il quarto e il sesto non sono lettere: sono
segni diacritici che da soli non hanno senso. Infine, se li consideriamo come
cluster di grafemi, otterremmo ciò che una persona chiamerebbe le quattro
lettere che compongono la parola hindi:
["न", "म", "स्", "ते"]
Rust fornisce diversi modi di interpretare i dati stringa grezzi che i computer memorizzano, in modo che ogni programma possa scegliere l’interpretazione di cui ha bisogno, indipendentemente dal linguaggio umano in cui sono espressi i dati.
Un ultimo motivo per cui Rust non ci consente di indicizzare una String per
ottenere un carattere è che le operazioni di indicizzazione dovrebbero sempre
richiedere un tempo costante (O(1)). Ma non è possibile garantire tali
prestazioni con una String, perché Rust dovrebbe esaminare il contenuto
dall’inizio fino all’indice per determinare quanti caratteri validi ci sono.
Slicing delle Stringhe
Indicizzare una stringa è spesso una cattiva idea perché non è chiaro quale debba essere il type di ritorno dell’operazione di indicizzazione della stringa: un valore byte, un carattere, un cluster di grafemi o una slice. Se proprio si ha bisogno di usare gli indici per creare slice di stringa, Rust chiede di essere più specifici.
Invece di indicizzare usando [] con un singolo numero, si può usare [] con
un intervallo per creare una slice di stringa contenente byte specifici:
#![allow(unused)] fn main() { let saluto = "Здравствуйте"; let s = &saluto[0..4]; }
Qui, s sarà un &str che contiene i primi 4 byte della stringa. In
precedenza, abbiamo accennato al fatto che ognuno di questi caratteri era
composto da due byte, il che significa che s sarà Зд.
Se provassimo a suddividere solo una parte dei byte di un carattere con qualcosa
come &saluto[0..1], Rust andrebbe in panic in fase di esecuzione, proprio
come se si accedesse a un indice non valido in un vettore:
$ cargo run
Compiling collections v0.1.0 (file:///progetti/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/collections`
thread 'main' (6240) panicked at src/main.rs:4:20:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
È necessario prestare attenzione quando si creano slice di stringhe con intervalli, perché ciò potrebbe causare l’arresto anomalo del programma.
Iterare sulle Stringhe
Il modo migliore per operare su stringhe è specificare esplicitamente se si
desidera caratteri o byte. Per singoli valori scalari Unicode, utilizzare il
metodo chars. Chiamando chars su “Зд” si separano e si restituiscono due
valori di type char, ed è possibile iterare sul risultato per accedere a
ciascun elemento:
#![allow(unused)] fn main() { for c in "Зд".chars() { println!("{c}"); } }
Questo codice stamperà quanto segue:
З
д
In alternativa, il metodo bytes restituisce ogni byte grezzo, che potrebbe
essere appropriato per quello che ti serve:
#![allow(unused)] fn main() { for b in "Зд".bytes() { println!("{b}"); } }
Questo codice stamperà i 4 byte che compongono questa stringa:
208
151
208
180
Ma ricorda che i valori scalari Unicode validi possono essere composti da più di 1 byte.
Ottenere cluster di grafemi dalle stringhe, come con l’alfabeto Devanagari, è complesso, quindi questa funzionalità non è fornita dalla libreria standard. I crate sono disponibili su crates.io se questa è la funzionalità di cui hai bisogno.
Gestire le Complessità delle Stringhe
In sintesi, le stringhe sono complicate. Diversi linguaggi di programmazione
fanno scelte diverse su come presentare questa complessità al programmatore.
Rust ha scelto di rendere la corretta gestione dei dati String il
comportamento predefinito per tutti i programmi Rust, il che significa che i
programmatori devono dedicare da subito maggiore attenzione alla gestione dei
dati UTF-8. Questo compromesso rende più evidente la complessità delle stringhe
rispetto ad altri linguaggi di programmazione, ma evita di dover gestire errori
che coinvolgono caratteri non ASCII in una fase successiva del ciclo di
sviluppo.
La buona notizia è che la libreria standard offre numerose funzionalità basate
sui type String e &str per aiutare a gestire correttamente queste
situazioni complesse. Assicuratevi di consultare la documentazione per metodi
utili come contains per la ricerca in una stringa e replace per sostituire
parti di una stringa con un’altra stringa.
Passiamo a qualcosa di un po’ meno complesso: le mappe hash!
Memorizzare Chiavi con Valori Associati in Mappe Hash
L’ultima delle nostre collezioni comuni è la mappa hash. Il type HashMap<K, V> memorizza una mappatura di chiavi di type K a valori di type V
utilizzando una funzione di hashing, che determina come queste chiavi e valori
vengono inseriti in memoria. Molti linguaggi di programmazione supportano questo
tipo di struttura dati, ma spesso usano un nome diverso, come hash, map,
object, hash table, dictionary o associative array, solo per citarne
alcuni.
Le mappe hash (hash map d’ora in poi) sono utili quando si desidera ricercare dati non utilizzando un indice, come è possibile con i vettori, ma utilizzando una chiave che può essere di qualsiasi type. Ad esempio, in una partita, è possibile tenere traccia del punteggio di ogni squadra in una hash map in cui ogni chiave è il nome di una squadra e i valori sono il punteggio di ogni squadra. Dato il nome di una squadra, è possibile recuperarne il punteggio.
In questa sezione esamineremo l’API di base delle hash map, ma molte altre
funzionalità si nascondono nelle funzioni definite su HashMap<K, V> dalla
libreria standard. Come sempre, consultate la documentazione della libreria
standard per ulteriori informazioni.
Creare una Nuova Hash Map
Un modo per creare una hash map vuota è usare new e aggiungere elementi con
insert. Nel Listato 8-20, stiamo tenendo traccia del punteggio di due squadre
i cui nomi sono Blu e Gialla. La squadra Blu inizia con 10 punti, mentre la
squadra Gialla inizia con 50.
fn main() { use std::collections::HashMap; let mut punteggi = HashMap::new(); punteggi.insert(String::from("Blu"), 10); punteggi.insert(String::from("Gialla"), 50); }
Nota che dobbiamo prima portare in scope HashMap con use dalla sezione
dedicata alle collezioni della libreria standard. Delle nostre tre collezioni
comuni, questa è la meno utilizzata, quindi non è inclusa nelle funzionalità
aggiunte allo scope dal preludio. Le hash map hanno anche un supporto
minore dalla libreria standard; ad esempio, non esiste una macro integrata per
costruirle.
Proprio come i vettori, le hash map memorizzano i loro dati nell’heap.
Questa HashMap ha chiavi di type String e valori di type i32. Come i
vettori, le hash map sono omogenee: tutte le chiavi devono avere lo stesso
type e tutti i valori devono avere lo stesso type.
Accedere ai Valori in una Hash Map
Possiamo ottenere un valore dalla hash map fornendo la sua chiave al metodo
get, come mostrato nel Listato 8-21.
fn main() { use std::collections::HashMap; let mut punteggi = HashMap::new(); punteggi.insert(String::from("Blu"), 10); punteggi.insert(String::from("Gialla"), 50); let nome_squadra = String::from("Blu"); let punteggio = punteggi.get(&nome_squadra).copied().unwrap_or(0); }
Qui, punteggio avrà il valore associato alla squadra Blu e il risultato sarà
10. Il metodo get restituisce Option<&V>; se non c’è alcun valore per
quella chiave nella hash map, get restituirà None. Questo programma
gestisce Option chiamando copied per ottenere Option<i32> anziché
Option<&i32>, quindi unwrap_or per impostare punteggio a zero se
punteggio non ha una voce per la chiave.
Possiamo iterare su ogni coppia chiave-valore in una hash map in modo simile a
come facciamo con i vettori, utilizzando un ciclo for:
fn main() { use std::collections::HashMap; let mut punteggi = HashMap::new(); punteggi.insert(String::from("Blu"), 10); punteggi.insert(String::from("Gialla"), 50); for (chiave, valore) in &punteggi { println!("{chiave}: {valore}"); } }
Questo codice stamperà ogni coppia in un ordine arbitrario:
Gialla: 50
Blu: 10
Gestire Ownership nelle Hash Map
Per i type che implementano il trait Copy, come i32, i valori vengono
copiati nella hash map. Per i valori con ownership come String, i valori
verranno spostati e la hash map assumerà la ownership di tali valori, come
dimostrato nel Listato 8-22.
fn main() { use std::collections::HashMap; let nome_campo = String::from("Colore preferito"); let valore_campo = String::from("Blu"); let mut map = HashMap::new(); map.insert(nome_campo, valore_campo); // `nome_campo` e `valore_campo` non sono validi a questo punto, // prova a usarli e vedi quale errore di compilazione ottieni! }
Non possiamo utilizzare le variabili nome_campo e valore_campo dopo che sono
state spostate nella hash map con la chiamata a insert.
Se inseriamo reference a valori nella hash map, i valori non verranno spostati nella hash map. I valori a cui puntano i reference devono essere validi almeno per il tempo in cui è valida la hash map. Approfondiremo questi argomenti nella sezione “Validare i Reference con la Lifetime” del Capitolo 10.
Aggiornare una Hash Map
Sebbene il numero di coppie chiave-valore sia espandibile, a ogni chiave univoca
può essere associato un solo valore alla volta (ma non viceversa: ad esempio,
sia la squadra Blu che quella Gialla potrebbero avere il valore 10 memorizzato
nella hash map punteggi).
Quando si desidera modificare i dati in una hash map, è necessario decidere come gestire il caso in cui a una chiave sia già assegnato un valore. È possibile sostituire il vecchio valore con il nuovo valore, ignorando completamente il vecchio valore. È possibile mantenere il vecchio valore e ignorare il nuovo valore, aggiungendo il nuovo valore solo se la chiave non ha già un valore. Oppure è possibile combinare il vecchio valore e il nuovo valore. Vediamo come fare ciascuna di queste cose!
Sovrascrivere un Valore
Se inseriamo una chiave e un valore in una hash map e poi inseriamo la stessa
chiave con un valore diverso, il valore associato a quella chiave verrà
sostituito. Anche se il codice nel Listato 8-23 chiama insert due volte, la
hash map conterrà solo una coppia chiave-valore perché stiamo inserendo il
valore per la chiave della squadra Blu entrambe le volte.
fn main() { use std::collections::HashMap; let mut punteggi = HashMap::new(); punteggi.insert(String::from("Blu"), 10); punteggi.insert(String::from("Blu"), 25); println!("{punteggi:?}"); }
Questo codice stamperà {"Blu": 25}. Il valore originale di 10 è stato
sovrascritto.
Aggiungere una Chiave e un Valore Solo Se una Chiave Non è Presente
È comune verificare se una particolare chiave esiste già nella hash map con un valore e quindi eseguire le seguenti azioni: se la chiave esiste nella hash map, il valore esistente deve rimanere invariato; se la chiave non esiste, inserirla e assegnarle un valore.
Le hash map dispongono di un’API speciale per questo scopo, chiamata entry,
che accetta la chiave che si desidera controllare come parametro. Il valore
restituito dal metodo entry è un’enum chiamato Entry che rappresenta un
valore che potrebbe esistere o meno. Supponiamo di voler verificare se la chiave
per la squadra Gialla ha un valore associato. In caso contrario, vogliamo
inserire il valore 50, e lo stesso vale per la squadra Blu. Utilizzando l’API
entry, il codice appare come nel Listato 8-24.
fn main() { use std::collections::HashMap; let mut punteggi = HashMap::new(); punteggi.insert(String::from("Blu"), 10); punteggi.entry(String::from("Gialla")).or_insert(50); punteggi.entry(String::from("Blu")).or_insert(50); println!("{punteggi:?}"); }
entry per inserire solo se la chiave non ha già un valoreIl metodo or_insert su Entry è definito per restituire un reference
mutabile al valore della chiave Entry corrispondente se tale chiave esiste, e
in caso contrario, inserisce il parametro come nuovo valore per questa chiave e
restituisce un reference mutabile al nuovo valore. Questa tecnica è molto più
pulita rispetto alla scrittura manuale della logica e, inoltre, si integra
meglio con il borrow checker.
L’esecuzione del codice nel Listato 8-24 stamperà {"Gialla": 50, "Blu": 10}.
La prima chiamata a entry inserirà la chiave per la squadra Gialla con il
valore 50 perché la squadra Gialla non ha già un valore. La seconda chiamata a
entry non modificherà la hash map perché la squadra Blu ha già il valore
10.
Aggiornare un Valore in Base al Valore Precedente
Un altro caso d’uso comune per le hash map è cercare il valore di una chiave e
quindi aggiornarlo in base al valore precedente. Ad esempio, il Listato 8-25
mostra un codice che conta quante volte ogni parola appare in un testo.
Utilizziamo una hash map con le parole come chiavi e incrementiamo il valore
per tenere traccia di quante volte abbiamo visto quella parola. Quando
incontriamo una parola nuova, verrà inserita inizializzando il valore associato
a 0.
fn main() { use std::collections::HashMap; let testo = "hello world wonderful world"; let mut map = HashMap::new(); for parola in testo.split_whitespace() { let conteggio = map.entry(parola).or_insert(0); *conteggio += 1; } println!("{map:?}"); }
Questo codice stamperà {"world": 2, "hello": 1, "wonderful": 1}. Potresti
vedere le stesse coppie chiave-valore stampate in un ordine diverso: ricorda
che, come menzionato precedentemente in “Accesso ai Valori in una Hash
Map”, l’iterazione su una hash map avviene in un
ordine arbitrario.
Il metodo split_whitespace restituisce un iteratore su slice, separate da
spazi, del valore in testo. Il metodo or_insert restituisce un reference
mutabile (&mut V) al valore della chiave specificata. Qui, memorizziamo quel
reference mutabile nella variabile conteggio, quindi per assegnare quel
valore, dobbiamo prima de-referenziare conteggio usando l’asterisco (*). Il
reference mutabile esce dallo scope alla fine del ciclo for, quindi tutte
queste modifiche sono sicure e consentite dalle regole di prestito.
Funzioni di Hashing
Come impostazione predefinita, HashMap utilizza una funzione di hashing
chiamata SipHash che può fornire resistenza agli attacchi denial-of-service
(DoS) che coinvolgono tabelle di hash1. Questo non è
l’algoritmo di hashing più veloce disponibile, ma è un buon compromesso in
termini di maggiore sicurezza che ne deriva, nonostante il costo prestazionale
derivato. Se si profila il codice e si scopre che la funzione di hashing
predefinita è troppo lenta per i propri scopi, è possibile passare a un’altra
funzione specificando un hasher diverso. Un hasher è un type che
implementa il trait BuildHasher. Parleremo dei trait e di come
implementarli nel Capitolo 10. Non è necessario
implementare il proprio hasher da zero;
crates.io offre librerie
condivise da altri utenti Rust che forniscono hasher che implementano molti
algoritmi di hashing comuni.
Riepilogo
Vettori, stringhe e hash map forniranno una grande quantità di funzionalità necessarie nei programmi quando avrai necessità di memorizzare, accedere e modificare dati. Ecco alcuni esercizi che ora dovresti essere in grado di risolvere:
- Dato un elenco di interi, usa un vettore e restituisci la mediana (quando ordinati, il valore in posizione centrale) e la moda (il valore che ricorre più spesso; una hash map sarà utile in questo caso) dell’elenco.
- Converti delle stringhe in pig latin. La prima consonante di ogni parola viene spostata alla fine della parola e viene aggiunto ay, quindi primo diventa rimo-pay. Le parole che iniziano con una vocale hanno invece hay aggiunto alla fine (ananas diventa ananas-hay). Tieni a mente i dettagli sulla codifica UTF-8!
- Utilizzando hash map e vettori, crea un’interfaccia testuale che consenta a un utente di aggiungere i nomi dei dipendenti a un reparto di un’azienda; ad esempio, “Aggiungi Sally a Ingegneria” o “Aggiungi Amir a Vendite”. Quindi, consenti all’utente di recuperare un elenco di tutte le persone in un reparto o di tutte le persone in azienda per reparto, ordinate alfabeticamente.
La documentazione API della libreria standard descrive i metodi di vettori, stringhe e hash map che saranno utili per questi esercizi!
Stiamo entrando in programmi più complessi in cui le operazioni possono fallire, quindi è il momento perfetto per discutere della gestione degli errori. Lo faremo in seguito!
Gestione degli Errori
Gli errori nel software sono una realtà, quindi Rust offre diverse funzionalità per gestire le situazioni in cui qualcosa non va. In molti casi, Rust ti forza a riconoscere la possibilità di un errore e ti chiede di intraprendere un’azione prima che il codice venga compilato. Questo requisito rende il programma più robusto, garantendo che gli errori vengano rilevati e gestiti in modo appropriato prima di distribuire il tuo codice all’utente finale!
Rust raggruppa gli errori in due categorie principali: errori reversibili e irreversibili. Per un errore reversibile, come un errore file non trovato, molto probabilmente vorremo semplicemente segnalare il problema all’utente e riprovare l’operazione. Gli errori irreversibili sono sempre sintomi di bug, come il tentativo di accedere a una posizione oltre la fine di un array, e quindi vogliamo interrompere immediatamente il programma.
La maggior parte dei linguaggi non distingue tra questi due tipi di errori e li
gestisce entrambi allo stesso modo, utilizzando meccanismi come le eccezioni.
Rust non ha le eccezioni. Al contrario, ha il type Result<T, E> per gli
errori reversibili e la macro panic! che interrompe l’esecuzione quando il
programma incontra un errore irreversibile. Questo capitolo tratta prima la
chiamata a panic! e poi parla della restituzione dei valori Result<T, E>.
Inoltre, esploreremo le considerazioni da tenere presente quando si decide se
tentare di recuperare da un errore o interrompere l’esecuzione.
Errori Irreversibili con panic!
A volte si verificano problemi nel codice e non c’è nulla che si possa fare al
riguardo. In questi casi, Rust dispone della macro panic!. Esistono
praticamente due modi per causare un panic: eseguendo un’azione che causa il
panic del codice (come tentare di accedere a un array oltre la fine) o
chiamando esplicitamente la macro panic!. In entrambi i casi, causiamo un
panic nel nostro programma. Per impostazione predefinita, questi panic
stampano un messaggio di errore, eseguono un unwind, puliscono lo stack e
terminano. Tramite una variabile d’ambiente, è anche possibile fare in modo che
Rust visualizzi lo stack delle chiamate quando si verifica un panic, per
facilitare l’individuazione della causa del panic.
Unwinding dello Stack o Interruzione in Risposta a un Panic
Per impostazione predefinita, quando si verifica un panic il programma avvia
l’unwinding, il che significa che Rust risale lo stack e pulisce i dati da
ogni funzione che incontra. Tuttavia, risalire lo stack e pulire richiede
molto lavoro. Rust, quindi, consente di scegliere l’alternativa di abortire
immediatamente, che termina il programma senza pulizia. La memoria che il
programma stava utilizzando dovrà quindi essere ripulita dal sistema
operativo. Se nel progetto è necessario ridurre al minimo il binario
risultante, è possibile passare dall’unwinding all’interruzione in caso di
panic aggiungendo panic = 'abort' alle sezioni [profile] appropriate nel
file Cargo.toml. Ad esempio, se si desidera interrompere l’esecuzione in
caso di panic nell’eseguibile finale (release) ma non in fase di sviluppo,
aggiungi quanto segue:
[profile.release]
panic = 'abort'
Proviamo a chiamare panic! in un semplice programma:
fn main() { panic!("crepa e brucia"); }
Quando si esegue il programma, si vedrà qualcosa di simile a questo:
$ cargo run
Compiling panic v0.1.0 (file:///progetti/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crepa e brucia
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
La chiamata a panic! causa il messaggio di errore contenuto nelle ultime
righe. La prima riga mostra il punto del codice sorgente in cui si è verificato
l’errore: src/main.rs:2:5 indica che si tratta della seconda riga, quinto
carattere del nostro file src/main.rs.
In questo caso, la riga indicata fa parte del nostro codice e, se andiamo a
quella riga, vediamo la chiamata alla macro panic!. In altri casi, la chiamata
a panic! potrebbe essere nel codice richiamato dal nostro codice e il nome del
file e il numero di riga riportati dal messaggio di errore saranno il codice di
qualcun altro in cui viene richiamata la macro panic!, non la riga del nostro
codice che alla fine ha portato alla chiamata a panic!.
La seconda riga mostra il nostro messaggio di errore inserito nella chiamata a
panic!.
Possiamo usare il backtrace (andare a ritroso) delle funzioni da cui
proviene la chiamata panic! per capire la parte del nostro codice che sta
causando il problema. Per capire come usare un backtrace di panic!, diamo
un’occhiata a un altro esempio e vediamo cosa succede quando una chiamata
panic! proviene da una libreria a causa di un bug nel nostro codice invece
che dal nostro codice che chiama direttamente la macro. Il Listato 9-1 contiene
del codice che tenta di accedere a un indice in un vettore oltre l’intervallo di
indici validi.
fn main() { let v = vec![1, 2, 3]; v[99]; }
panic!Qui stiamo tentando di accedere al centesimo elemento del nostro vettore (che si
trova all’indice 99 perché l’indicizzazione inizia da zero), ma il vettore ha
solo tre elementi. In questa situazione, Rust andrà in panic. L’utilizzo di
[] dovrebbe restituire un elemento, ma se si passa un indice non valido, non
c’è alcun elemento valido che Rust potrebbe restituire.
In C, tentare di leggere oltre la fine di una struttura dati è un comportamento indefinito. Si potrebbe ottenere qualsiasi cosa si trovi nella posizione in memoria che corrisponderebbe a quell’elemento nella struttura dati, anche se la memoria non appartiene a quella struttura. Questo è chiamato buffer overread (lettura oltre il buffer) e può portare a vulnerabilità di sicurezza se un aggressore riesce a manipolare l’indice in modo tale da leggere dati che non dovrebbe essere autorizzato a leggere e che sono memorizzati dopo la struttura dati.
Per proteggere il programma da questo tipo di vulnerabilità, se si tenta di leggere un elemento in un indice che non esiste, Rust interromperà l’esecuzione e si rifiuterà di continuare. Proviamo e vediamo:
$ cargo run
Compiling panic v0.1.0 (file:///progetti/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.37s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Questo errore punta alla riga 4 del nostro main.rs, dove tentiamo di accedere
all’indice 99 del vettore in v.
La riga note: ci dice che possiamo impostare la variabile d’ambiente
RUST_BACKTRACE per ottenere un backtrace di ciò che ha causato l’errore. Un
backtrace è un elenco di tutte le funzioni che sono state chiamate per
arrivare a questo punto. I backtrace in Rust funzionano come in altri
linguaggi: la chiave per leggere il backtrace è iniziare dall’inizio e leggere
fino a quando non si vedono i file che si sono creati. Quello è il punto in cui
si è originato il problema. Le righe sopra quel punto sono il codice che il tuo
codice ha chiamato; le righe sottostanti sono il codice che ha chiamato il tuo
codice. Queste righe prima e dopo potrebbero includere codice Rust core, codice
di libreria standard o pacchetti che stai utilizzando. Proviamo a ottenere un
backtrace impostando la variabile d’ambiente RUST_BACKTRACE su un valore
qualsiasi tranne 0. Il Listato 9-2 mostra un output simile a quello che
vedrai.
$ RUST_BACKTRACE=1 cargo run
thread 'main' (11968) panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: __rustc::rust_begin_unwind
at /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/std/src/panicking.rs:698:5
1: core::panicking::panic_fmt
at /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/core/src/panicking.rs:280:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/core/src/slice/index.rs:18:15
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/alloc/src/vec/mod.rs:3621:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at /rustc/8e62bfd311791bfd9dca886abdfbab07ec54d8b4/library/core/src/ops/function.rs:253:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
panic! viene visualizzato quando la variabile d’ambiente RUST_BACKTRACE è impostataUn output enorme! L’output esatto che vedi potrebbe variare a seconda del
sistema operativo e della versione di Rust. Per ottenere backtrace con queste
informazioni, i simboli di debug devono essere abilitati. I simboli di debug
sono abilitati per impostazione predefinita quando si utilizza cargo build o
cargo run senza il flag --release, come in questo caso.
Nell’output del Listato 9-2, la riga 6 del backtrace punta alla riga del nostro progetto che causa il problema: la riga 4 di src/main.rs. Se non vogliamo che il nostro programma vada in panic, dovremmo iniziare la nostra analisi dalla posizione indicata dalla prima riga che menziona un file che abbiamo scritto. Nel Listato 9-1, dove abbiamo volutamente scritto codice che andrebbe in panic, il modo per risolvere il problema è non richiedere un elemento oltre l’intervallo degli indici del vettore. Quando in futuro il codice andrà in panic, dovrai capire quale azione sta eseguendo il codice con quali valori tali da causare il panic e cosa dovrebbe fare il codice al suo posto.
Torneremo su panic! e su quando dovremmo e non dovremmo usare panic! per
gestire le condizioni di errore nella sezione “panic! o non
panic!” più avanti in questo
capitolo. Ora vedremo come gestire un errore utilizzando Result.
Errori Reversibili con Result
La maggior parte degli errori non è abbastanza grave da richiedere l’arresto completo del programma. A volte, quando una funzione fallisce, è per un motivo facilmente interpretabile e a cui è possibile rispondere. Ad esempio, se si tenta di aprire un file e l’operazione fallisce perché il file non esiste, potrebbe essere opportuno crearlo anziché terminare il processo.
Come menzionato nella sezione “Gestire i potenziali errori con
Result” del Capitolo 2, l’enum Result è
definito come avente due varianti, Ok ed Err, come segue:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
T ed E sono parametri di type generico: parleremo dei generici più in
dettaglio nel Capitolo 10. Quello che devi sapere ora è che T rappresenta il
type di valore che verrà restituito in caso di successo nella variante Ok,
ed E rappresenta il type di errore che verrà restituito in caso di
fallimento nella variante Err. Poiché Result ha questi parametri di type
generico, possiamo utilizzare il type Result e le funzioni definite su di
esso in molte situazioni diverse in cui il valore di successo e il valore di
errore che vogliamo restituire potrebbero differire.
Chiamiamo una funzione che restituisca un valore Result perché la funzione
potrebbe fallire. Nel Listato 9-3 proviamo ad aprire un file.
use std::fs::File; fn main() { let file_benvenuto_result = File::open("ciao.txt"); }
Il type restituito da File::open è Result<T, E>. Il parametro generico T
è stato riempito dall’implementazione di File::open con il type del valore
di successo, std::fs::File, che è un handle al file. Il type di E
utilizzato nel valore di errore è std::io::Error. Questo type di ritorno
significa che la chiamata a File::open potrebbe avere esito positivo e
restituire un handle al file da cui è possibile leggere o scrivere. La
chiamata di funzione potrebbe anche fallire: ad esempio, il file potrebbe non
esistere o potremmo non avere i permessi per accedervi. La funzione File::open
deve avere un modo per indicarci se è riuscita o meno e allo stesso tempo
fornirci l’handle al file o le informazioni sull’errore. Queste informazioni
sono esattamente ciò che l’enum Result trasmette.
Nel caso in cui File::open abbia esito positivo, il valore nella variabile
file_benvenuto_result sarà un’istanza di Ok che contiene un handle al
file. In caso di errore, il valore in file_benvenuto_result sarà un’istanza di
Err che contiene maggiori informazioni sul tipo di errore che si è verificato.
Dobbiamo aggiungere al codice del Listato 9-3 azioni diverse a seconda del
valore restituito da File::open. Il Listato 9-4 mostra un modo per gestire il
risultato Result utilizzando uno strumento di base, l’espressione match di
cui abbiamo parlato nel Capitolo 6.
use std::fs::File; fn main() { let file_benvenuto_result = File::open("ciao.txt"); let file_benvenuto = match file_benvenuto_result { Ok(file) => file, Err(errore) => panic!("Errore nell'apertura del file: {errore:?}"), }; }
match per gestire le varianti di Result che potrebbero essere restituiteNota che, come l’enum Option, l’enum Result e le sue varianti sono state
introdotte nello scope dal preludio, quindi non è necessario specificare
Result:: prima delle varianti Ok ed Err nei rami di match.
Quando il risultato è Ok, questo codice restituirà il valore interno file
dalla variante Ok, e quindi assegneremo il valore dell’handle al file alla
variabile file_benvenuto. Dopo match, possiamo utilizzare l’handle al file
per la lettura o la scrittura.
L’altro ramo di match gestisce il caso in cui otteniamo un valore Err da
File::open. In questo esempio, abbiamo scelto di chiamare la macro panic!.
Se non c’è alcun file denominato ciao.txt nella nostra cartella corrente ed
eseguiamo questo codice, vedremo il seguente output dalla macro panic!:
$ cargo run
Compiling gestione_errore v0.1.0 (file:///progetti/gestione_errore)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.37s
Running `target/debug/gestione_errore`
thread 'main' (6304) panicked at src/main.rs:8:24:
Errore nell'apertura del file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Come al solito, questo output ci dice esattamente cosa è andato storto.
Corrispondenza in Caso di Errori Diversi
Il codice nel Listato 9-4 genererà un panic! indipendentemente dal motivo per
cui File::open ha fallito. Tuttavia, vogliamo intraprendere azioni diverse per
diversi motivi di errore. Se File::open ha fallito perché il file non esiste,
vogliamo crearlo e restituire l’handle al nuovo file. Se File::open ha
fallito per qualsiasi altro motivo, ad esempio perché non avevamo
l’autorizzazione per aprire il file, vogliamo comunque che il codice generi un
panic! come nel Listato 9-4. Per questo, aggiungiamo un’espressione match
interna, mostrata nel Listato 9-5.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let file_benvenuto_result = File::open("ciao.txt");
let file_benvenuto = match file_benvenuto_result {
Ok(file) => file,
Err(errore) => match errore.kind() {
ErrorKind::NotFound => match File::create("ciao.txt") {
Ok(fc) => fc,
Err(e) => panic!("Errore nella creazione del file: {e:?}"),
},
_ => {
panic!("Errore nell'apertura del file: {errore:?}");
}
},
};
}Il type del valore restituito da File::open all’interno della variante Err
è io::Error, una struct fornita dalla libreria standard. Questa struct ha
un metodo kind che possiamo chiamare per ottenere un valore io::ErrorKind.
L’enum io::ErrorKind è fornito dalla libreria standard e ha varianti che
rappresentano i diversi tipi di errori che potrebbero verificarsi da
un’operazione io. La variante che vogliamo utilizzare è ErrorKind::NotFound,
che indica che il file che stiamo cercando di aprire non esiste ancora. Abbiamo
in pratica fatto un matching sia su file_benvenuto_result sia, internamente,
sulla tipologia di errore in error.kind().
La condizione che vogliamo verificare nel matching interno è se il valore
restituito da error.kind() è la variante NotFound dell’enum ErrorKind.
In tal caso, proviamo a creare il file con File::create. Tuttavia, poiché
anche File::create potrebbe fallire, abbiamo bisogno di un secondo ramo
nell’espressione match interna. Quando il file non può essere creato, viene
visualizzato un messaggio di errore diverso. Il secondo ramo dell’espressione
match esterna rimane invariato, quindi il programma va in panic in caso di
qualsiasi errore diverso dall’errore di file mancante.
Alternative all’Utilizzo di match con Result<T, E>
Sono un sacco di match! L’espressione match è molto utile, ma anche molto
primitiva. Nel Capitolo 13, imparerai a conoscere le chiusure (closure), che
vengono utilizzate con molti dei metodi definiti in Result<T, E>. Questi
metodi possono essere più concisi rispetto all’utilizzo di match quando si
gestiscono i valori Result<T, E> nel codice. Ad esempio, ecco un altro modo
per scrivere la stessa logica mostrata nel Listato 9-5, questa volta
utilizzando le chiusure e il metodo unwrap_or_else:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let file_benvenuto = File::open("ciao.txt").unwrap_or_else(|errore| {
if errore.kind() == ErrorKind::NotFound {
File::create("ciao.txt").unwrap_or_else(|errore| {
panic!("Errore nella creazione del file: {errore:?}");
})
} else {
panic!("Errore nell’apertura del file: {errore:?}");
}
});
}Sebbene questo codice abbia lo stesso comportamento del Listato 9-5, non
contiene alcuna espressione match ed è più chiaro da leggere. Torna a questo
esempio dopo aver letto il Capitolo 13 e cerca il metodo unwrap_or_else
nella documentazione della libreria standard. Molti altri di questi metodi
possono sostituire enormi espressioni annidate di match quando si hanno
errori.
Scorciatoie per Panic in Caso di Errore
L’uso di match funziona abbastanza bene, ma può essere un po’ prolisso e non
sempre comunica bene l’intento. Il type Result<T, E> ha molti metodi utili
definiti al suo interno per svolgere varie attività più specifiche. Ad esempio
unwrap è un metodo di scelta rapida implementato proprio come l’espressione
match che abbiamo scritto nel Listato 9-4. Se il valore Result è la variante
Ok, unwrap restituirà il valore all’interno di Ok. Se Result è la
variante Err, unwrap richiamerà la macro panic! per noi. Ecco un esempio
di unwrap in azione:
use std::fs::File; fn main() { let file_benvenuto = File::open("ciao.txt").unwrap(); }
Se eseguiamo questo codice senza un file ciao.txt, vedremo un messaggio di
errore dalla chiamata panic! effettuata dal metodo unwrap:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Analogamente, il metodo expect ci consente anche di scegliere il messaggio di
errore panic!. Usare expect invece di unwrap e fornire messaggi di errore
efficaci può trasmettere le proprie intenzioni e facilitare l’individuazione
della fonte di un errore. La sintassi di expect è la seguente:
use std::fs::File; fn main() { let file_benvenuto = File::open("ciao.txt") .expect("ciao.txt dovrebbe essere presente in questo progetto"); }
Usiamo expect allo stesso modo di unwrap: per restituire l’handle al file
o chiamare la macro panic!. Il messaggio di errore utilizzato da expect
nella sua chiamata a panic! sarà il parametro che passeremo a expect,
anziché il messaggio predefinito panic! utilizzato da unwrap. Ecco come
appare:
thread 'main' panicked at src/main.rs:5:10:
ciao.txt dovrebbe essere presente in questo progetto: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Nel codice ottimizzato per il rilascio, la maggior parte dei Rustacean sceglie
expect invece di unwrap per fornire più contesto sul motivo per cui ci si
aspetta che l’operazione è fallita. In questo modo, se le tue ipotesi dovessero
rivelarsi sbagliate, avrai più informazioni da utilizzare per il debug.
Propagazione degli Errori
Quando l’implementazione di una funzione richiama qualcosa che potrebbe non funzionare, invece di gestire l’errore all’interno della funzione stessa, è possibile restituirlo al codice chiamante in modo che possa decidere cosa fare. Questa operazione è nota come propagazione dell’errore e conferisce maggiore controllo al codice chiamante, dove potrebbero esserci più informazioni o logica che determinano come gestire l’errore rispetto a quelle disponibili nel contesto del codice.
Ad esempio, il Listato 9-6 mostra una funzione che legge un nome utente da un file. Se il file non esiste o non può essere letto, questa funzione restituirà gli errori al codice che ha chiamato la funzione.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn leggi_nomeutente_dal_file() -> Result<String, io::Error> { let nomeutente_file_result = File::open("ciao.txt"); let mut nomeutente_file = match nomeutente_file_result { Ok(file) => file, Err(e) => return Err(e), }; let mut nomeutente = String::new(); match nomeutente_file.read_to_string(&mut nomeutente) { Ok(_) => Ok(nomeutente), Err(e) => Err(e), } } }
matchQuesta funzione può essere scritta in un modo molto più breve, ma inizieremo
eseguendo gran parte del processo manualmente per esplorare la gestione degli
errori; alla fine, mostreremo il modo più breve. Per prima cosa diamo
un’occhiata al type di ritorno della funzione: Result<String, io::Error>.
Ciò significa che la funzione restituisce un valore del type Result<T, E>,
dove il parametro generico T è stato riempito con il type concreto String
e il type generico E è stato riempito con il type concreto io::Error.
Se questa funzione ha esito positivo senza problemi, il codice che la chiama
riceverà un valore Ok che contiene una String, ovvero il nomeutente che
questa funzione ha letto dal file. Se questa funzione riscontra problemi, il
codice chiamante riceverà un valore Err che contiene un’istanza di io::Error
contenente maggiori informazioni sulla causa del problema. Abbiamo scelto
io::Error come type di ritorno di questa funzione perché è il type del
valore di errore restituito da entrambe le operazioni che stiamo chiamando nel
corpo di questa funzione che potrebbero fallire: la funzione File::open e il
metodo read_to_string.
Il corpo della funzione inizia con la chiamata alla funzione File::open.
Quindi gestiamo il valore Result con un match simile a quello nel Listato
9-4. Se File::open ha esito positivo, l’handle al file nella variabile
pattern file diventa il valore nella variabile mutabile nomeutente_file e
la funzione continua. Nel caso Err, invece di chiamare panic!, utilizziamo
la parola chiave return per uscire completamente dalla funzione e passare il
valore di errore da File::open, ora nella variabile pattern e, al codice
chiamante come valore di errore di questa funzione.
Quindi, se abbiamo un handle al file in nomeutente_file, la funzione crea
una nuova String nella variabile nomeutente e chiama il metodo
read_to_string sull’handle al file in nomeutente_file per leggere il
contenuto del file in nomeutente. Anche il metodo read_to_string restituisce
un Result perché potrebbe fallire, anche se File::open ha avuto esito
positivo. Abbiamo quindi bisogno di un altro match per gestire quel Result:
se read_to_string ha esito positivo, la nostra funzione ha avuto successo e
restituiamo il nome utente dal file che ora si trova in nomeutente incapsulato
in un Ok. Se read_to_string fallisce, restituiamo il valore di errore nello
stesso modo in cui abbiamo restituito il valore di errore nel match che
gestiva il valore di ritorno di File::open. Tuttavia, non è necessario
specificare esplicitamente return, perché questa è l’ultima espressione nella
funzione.
Il codice chiamante gestirà quindi l’ottenimento di un valore Ok che contiene
un nome utente o di un valore Err che contiene un io::Error. Spetta al
codice chiamante decidere cosa fare con questi valori. Se il codice chiamante
riceve un valore Err, potrebbe chiamare panic! e mandare in crash il
programma, utilizzare un nome utente predefinito o cercare il nome utente da una
posizione diversa da un file, ad esempio. Non abbiamo informazioni sufficienti
su cosa stia effettivamente cercando di fare il codice chiamante, quindi
propaghiamo tutte le informazioni di successo o errore verso l’alto affinché
possa gestirle in modo appropriato.
Questo schema di propagazione degli errori è così comune in Rust che Rust
fornisce l’operatore punto interrogativo ? per semplificare la procedura.
L’Operatore Scorciatoia ?
Il Listato 9-7 mostra un’implementazione di leggi_nomeutente_dal_file che ha
la stessa funzionalità del Listato 9-6, ma questa implementazione utilizza
l’operatore ?.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn leggi_nomeutente_dal_file() -> Result<String, io::Error> { let mut nomeutente_file = File::open("ciao.txt")?; let mut nomeutente = String::new(); nomeutente_file.read_to_string(&mut nomeutente)?; Ok(nomeutente) } }
?Il ? inserito dopo un valore Result è definito per funzionare quasi allo
stesso modo delle espressioni match che abbiamo definito per gestire i valori
Result nel Listato 9-6. Se il valore di Result è Ok, il valore all’interno
di Ok verrà restituito da questa espressione e il programma continuerà. Se il
valore è Err, Err verrà restituito dall’intera funzione come se avessimo
utilizzato la parola chiave return, quindi il valore di errore viene propagato
al codice chiamante.
C’è una differenza tra ciò che fa l’espressione match del Listato 9-6 e ciò
che fa l’operatore ?: i valori di errore che hanno l’operatore ? chiamato su
di essi passano attraverso la funzione from, definita nel trait From nella
libreria standard, che viene utilizzata per convertire i valori da un type
all’altro. Quando l’operatore ? chiama la funzione from, il type di errore
ricevuto viene convertito nel type di errore definito nel type di ritorno
della funzione corrente. Questo è utile quando una funzione restituisce un
type di errore per rappresentare tutti i modi in cui la funzione potrebbe
fallire, anche se alcune parti potrebbero fallire per molti motivi diversi.
Ad esempio, potremmo modificare la funzione leggi_nomeutente_dal_file nel
Listato 9-7 per restituire un type personalizzato di errore denominato
NostroErrore da noi definito. Se definiamo anche impl From<io::Error> for NostroErrore per costruire un’istanza di NostroErrore partendo da un
io::Error, l’operatore ? chiamato nel corpo di leggi_nomeutente_dal_file
chiamerà from e convertirà i type di errore senza bisogno di aggiungere
altro codice alla funzione.
Nel contesto del Listato 9-7, ? alla fine della chiamata File::open
restituirà il valore all’interno di un Ok alla variabile nomeutente_file. Se
si verifica un errore, l’operatore ? interromperà l’intera funzione in
anticipo e ritornerà un valore Err al codice chiamante. Lo stesso vale per ?
alla fine della chiamata read_to_string.
L’operatore ? elimina gran parte del codice superfluo e semplifica
l’implementazione di questa funzione. Potremmo anche accorciare ulteriormente
questo codice concatenando le chiamate ai metodi subito dopo ?, come mostrato
nel Listato 9-8.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn leggi_nomeutente_dal_file() -> Result<String, io::Error> { let mut nomeutente = String::new(); File::open("ciao.txt")?.read_to_string(&mut nomeutente)?; Ok(nomeutente) } }
?Abbiamo spostato la creazione della nuova String in nomeutente all’inizio
della funzione; questa parte non è cambiata. Invece di creare una variabile
nomeutente_file, abbiamo concatenato la chiamata a read_to_string
direttamente al risultato di File::open("hello.txt")?. Abbiamo ancora un ?
alla fine della chiamata a read_to_string e continuiamo a restituire un valore
Ok contenente nomeutente quando sia File::open che read_to_string hanno
esito positivo, anziché restituire errori. La funzionalità è ancora la stessa
dei Listati 9-6 e 9-7; questo è solo un modo diverso e più stringato di
scriverlo.
Il Listato 9-9 mostra un modo per renderlo ancora più breve usando
fs::read_to_string.
#![allow(unused)] fn main() { use std::fs; use std::io; fn leggi_nomeutente_dal_file() -> Result<String, io::Error> { fs::read_to_string("ciao.txt") } }
fs::read_to_string invece di aprire e poi leggere il fileLeggere un file in una stringa è un’operazione abbastanza comune, quindi la
libreria standard fornisce la comoda funzione fs::read_to_string che apre il
file, crea una nuova String, ne legge il contenuto, lo inserisce in quella
String e la restituisce. Ovviamente, usare fs::read_to_string non ci dà
l’opportunità di spiegare tutta la gestione degli errori, quindi l’abbiamo fatto
prima nel modo più lungo.
Dove Usare l’Operatore ?
L’operatore ? può essere utilizzato solo in funzioni il cui type di ritorno
è compatibile con il valore su cui viene utilizzato ?. Questo perché
l’operatore ? è definito per eseguire una restituzione anticipata di un valore
dalla funzione, allo stesso modo dell’espressione match che abbiamo definito
nel Listato 9-6. Nel Listato 9-6, la funzione match utilizzava un valore
Result e il ramo di ritorno anticipato restituiva un valore Err(e). Il
type di ritorno della funzione deve essere Result in modo che sia
compatibile con questo return.
Nel Listato 9-10, esaminiamo l’errore che otterremo se utilizziamo l’operatore
? in una funzione main con un type di ritorno incompatibile con il type
del valore su cui utilizziamo ?.
use std::fs::File;
fn main() {
let file_benvenuto = File::open("ciao.txt")?;
}? nella funzione main che restituisce () non verrà compilatoQuesto codice apre un file, che potrebbe non funzionare. L’operatore ? segue
il valore Result restituito da File::open, ma questa funzione main ha come
type di ritorno (), non Result. Quando compiliamo questo codice, otteniamo
il seguente messaggio di errore:
$ cargo run
Compiling gestione_errore v0.1.0 (file:///progetti/gestione_errore)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let file_benvenuto = File::open("ciao.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let file_benvenuto = File::open("ciao.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gestione_errore` (bin "gestione_errore") due to 1 previous error
Questo errore indica che possiamo utilizzare l’operatore ? solo in una
funzione che restituisce Result, Option o un altro type che implementa
FromResidual.
Per correggere l’errore, hai due possibilità. Una è modificare il type di
ritorno della funzione in modo che sia compatibile con il valore su cui stai
utilizzando l’operatore ?, a condizione che non ci siano restrizioni che lo
impediscano. L’altra possibilità è utilizzare un match o uno dei metodi
Result<T, E> per gestire Result<T, E> nel modo più appropriato.
Il messaggio di errore indica anche che ? può essere utilizzato anche con i
valori Option<T>. Come per l’utilizzo di ? su Result, è possibile
utilizzare ? solo su Option in una funzione che restituisce Option. Il
comportamento dell’operatore ? quando viene chiamato su Option<T> è simile
al suo comportamento quando viene chiamato su Result<T, E>: se il valore è
None, None verrà restituito in anticipo dalla funzione in quel punto. Se il
valore è Some, il valore all’interno di Some è il valore risultante
dell’espressione e la funzione continua. Il Listato 9-11 contiene un esempio di
una funzione che trova l’ultimo carattere della prima riga del testo dato.
fn ultimo_char_della_prima_riga(testo: &str) -> Option<char> { testo.lines().next()?.chars().last() } fn main() { assert_eq!( ultimo_char_della_prima_riga("Hello, world\nCome stai oggi?"), Some('d') ); assert_eq!(ultimo_char_della_prima_riga(""), None); assert_eq!(ultimo_char_della_prima_riga("\nhi"), None); }
? su un valore Option<T>Questa funzione restituisce Option<char> perché è possibile che ci sia un
carattere, ma è anche possibile che non ci sia. Questo codice prende l’argomento
slice testo e chiama il metodo lines su di esso, che restituisce un
iteratore sulle righe della stringa. Poiché questa funzione vuole esaminare la
prima riga, chiama next sull’iteratore per ottenere il primo valore
dall’iteratore. Se testo è una stringa vuota, questa chiamata a next
restituirà None, nel qual caso usiamo ? per fermarci e restituire None da
ultimo_char_della_prima_riga. Se testo non è una stringa vuota, next
restituirà un valore Some contenente una slice della prima riga di testo.
? estrae la slice e possiamo chiamare chars su quella slice per ottenere
un iteratore dei suoi caratteri. Siamo interessati all’ultimo carattere in
questa prima riga, quindi chiamiamo last per restituire l’ultimo elemento
nell’iteratore. Questo è un’Option perché è possibile che la prima riga sia
una stringa vuota; ad esempio, se testo inizia con una riga vuota ma ha
caratteri su altre righe, come in "\nhi". Tuttavia, se c’è un ultimo carattere
sulla prima riga, verrà restituito nella variante Some. L’operatore ? al
centro ci fornisce un modo conciso per esprimere questa logica, permettendoci di
implementare la funzione in una sola riga. Se non potessimo usare l’operatore
? su Option, dovremmo implementare questa logica utilizzando più chiamate di
metodo o un’espressione match.
Nota che è possibile utilizzare l’operatore ? su un Result in una funzione
che restituisce Result, e si può utilizzare l’operatore ? su un Option in
una funzione che restituisce Option, ma non è possibile combinare le due.
L’operatore ? non convertirà automaticamente un Result in un Option o
viceversa; in questi casi, è possibile utilizzare il metodo ok su Result o
il metodo ok_or su Option per eseguire la conversione in modo esplicito.
Finora, tutte le funzioni main che abbiamo utilizzato restituiscono (). La
funzione main è speciale perché è il punto di ingresso e di uscita di un
programma eseguibile, e ci sono delle restrizioni sul type di ritorno che può
essere usato affinché il programma si comporti come previsto.
Fortunatamente, main può anche restituire Result<(), E>. Il Listato 9-12
contiene il codice del Listato 9-10, ma abbiamo modificato il type di ritorno
di main in Result<(), Box<dyn Error>> e aggiunto un valore di ritorno
Ok(()) alla fine. Questo codice ora verrà compilato.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let file_benvenuto = File::open("ciao.txt")?;
Ok(())
}main in modo che restituisca Result<(), E> è possibile utilizzare l’operatore ? sui valori ResultIl type Box<dyn Error> è un oggetto trait, di cui parleremo nella
sezione “Usare gli Oggetti Trait per Astrarre Comportamenti
Condivisi” del Capitolo 18. Per ora, puoi leggere
Box<dyn Error> come “qualsiasi type di errore”. L’utilizzo di ? su un
valore Result in una funzione main con il type di errore Box<dyn Error>
è consentito perché consente la restituzione anticipata di qualsiasi valore
Err. Anche se il corpo di questa funzione main restituirà sempre e solo
errori di type std::io::Error, specificando Box<dyn Error>, questa firma
continuerà a essere corretta anche se al corpo di main viene aggiunto altro
codice che restituisce altri errori.
Quando una funzione main restituisce Result<(), E>, l’eseguibile terminerà
restituendo un valore di 0 se main restituisce Ok(()) e uscirà con un
valore diverso da zero se main restituisce un valore Err. Gli eseguibili
scritti in C restituiscono integer quando terminano: i programmi che terminano
correttamente restituiscono l’integer 0, e i programmi che generano un
errore restituiscono un integer diverso da 0. Anche Rust restituisce
integer dagli eseguibili per essere compatibile con questa convenzione.
La funzione main può restituire qualsiasi type che implementi il trait
std::process::Termination, contenente una
funzione report che restituisce un ExitCode. Consulta la documentazione
della libreria standard per maggiori informazioni sull’implementazione del
trait Termination per i tuoi type.
Ora che abbiamo discusso i dettagli della chiamata a panic! o della
restituzione di Result, discuteremo di come decidere in quali casi sia più
appropriato usare l’uno o l’altro.
panic! o non panic!
Quindi, come si decide quando chiamare panic! e quando restituire Result?
Quando il codice va in panic, non c’è modo di tornare indietro. Si potrebbe
chiamare panic! per qualsiasi situazione di errore, indipendentemente dal
fatto che ci sia o meno una possibile soluzione, ma in tal caso si sta prendendo
la decisione che una situazione non è reversibile per conto del codice
chiamante. Quando si sceglie di restituire un valore Result, si forniscono al
codice chiamante delle opzioni. Il codice chiamante potrebbe scegliere di
tentare di rispondere in un modo appropriato alla situazione, oppure potrebbe
decidere che un valore Err in questo caso è irreversibile, quindi può chiamare
panic! e trasformare il tuo errore reversibile in un errore irreversibile.
Pertanto, restituire Result è una buona scelta predefinita quando si definisce
una funzione che potrebbe fallire.
In situazioni come codice di esempio, prototipale e test, è più appropriato
scrivere codice che vada in panic invece di restituire un Result. Esploriamo
il motivo, poi analizziamo le situazioni in cui il compilatore non può dire che
il fallimento è impossibile, ma tu, in quanto essere umano, sì. Il capitolo si
concluderà con alcune linee guida generali su come decidere se andare in panic
quando scrivi codice per una libreria.
Codice di Esempio, Prototipale e Test
Quando si scrive un esempio per illustrare un concetto, includere anche un
codice robusto per la gestione degli errori può rendere l’esempio meno chiaro.
Negli esempi, è sufficientemente chiaro che una chiamata a un metodo come
unwrap che potrebbe andare in panico è intesa come segnaposto per il modo in
cui si desidera che l’applicazione gestisca gli errori, che può differire in
base al comportamento del resto del codice.
Allo stesso modo, i metodi unwrap ed expect sono molto utili durante la fase
di prototipazione, prima di decidere come gestire gli errori. Lasciano chiari
punti nel codice per quando si è pronti a riscriverlo per renderlo più robusto.
Se una chiamata a un metodo fallisce in un test, si desidera che l’intero test
fallisca, anche se quel metodo non è la funzionalità in fase di test. Poiché
panic! è il modo in cui un test viene contrassegnato come fallito, chiamare
unwrap o expect è esattamente ciò che dovrebbe accadere.
Quando Hai Più Informazioni Del Compilatore
Sarebbe anche appropriato chiamare expect quando si dispone di un’altra logica
che garantisce che Result abbia un valore Ok, ma la logica non è qualcosa
che il compilatore capisce. Si avrà comunque un valore Result che bisogna
gestire: qualsiasi operazione si stia chiamando ha comunque la possibilità di
fallire, anche se è logicamente impossibile nella propria situazione specifica.
Se puoi assicurarti, ispezionando manualmente il codice, che non avrai mai una
variante Err, è perfettamente accettabile chiamare expect e documentare il
motivo per cui pensi di non avere mai una variante Err nel testo
dell’argomento. Ecco un esempio:
fn main() { use std::net::IpAddr; let home: IpAddr = "127.0.0.1" .parse() .expect("Indirizzo IP definito dovrebbe essere valido"); }
Stiamo creando un’istanza di IpAddr analizzando una stringa scritta
direttamente. Possiamo vedere che 127.0.0.1 è un indirizzo IP valido, quindi è
accettabile usare expect qui. Tuttavia, avere una stringa valida specificata
nel codice non cambia il type di ritorno del metodo parse: otteniamo
comunque un valore Result e il compilatore ci farà comunque gestire Result
come se la variante Err fosse una possibilità perché il compilatore non è
abbastanza intelligente da vedere che questa stringa è sempre un indirizzo IP
valido. Se la stringa dell’indirizzo IP provenisse da un utente anziché essere
scritta direttamente nel programma e quindi avesse una possibilità di errore,
vorremmo sicuramente gestire Result in un modo più robusto. Menzionare il
presupposto che questo indirizzo IP sia definito ci indurrà a modificare
expect con un codice di gestione degli errori migliore se, in futuro,
dovessimo ottenere l’indirizzo IP da un’altra fonte.
Linee Guida Per la Gestione degli Errori
È consigliabile mandare in panic il codice quando è possibile che il codice possa finire in uno stato non valido. In questo contesto, uno stato non valido si verifica quando un presupposto, garanzia o contratto non sono rispettati, ad esempio quando vengono passati al codice valori non validi, valori contraddittori o valori mancanti, più almeno una delle seguenti cose:
- Lo stato non valido è qualcosa di inaspettato, al contrario di qualcosa che probabilmente accadrà occasionalmente, come un utente che inserisce dati nel formato sbagliato.
- Il codice da questo punto in poi deve fare affidamento sul fatto di non trovarsi in questo stato non valido, piuttosto che verificare la presenza del problema a ogni passaggio.
- Non esiste un buon modo per codificare queste informazioni nei type utilizzati. Faremo un esempio di ciò che intendiamo nella sezione “Codifica di Stati e Comportamenti Come Type” del Capitolo 18.
Se qualcuno chiama il tuo codice e passa valori che non hanno senso, è meglio
restituire un errore, se possibile, in modo che l’utente della libreria possa
decidere cosa fare in quel caso. Tuttavia, nei casi in cui continuare potrebbe
essere insicuro o dannoso, la scelta migliore potrebbe essere quella di chiamare
panic! e avvisare la persona che utilizza la tua libreria del bug nel suo
codice in modo che possa correggerlo durante lo sviluppo. Allo stesso modo,
panic! è spesso appropriato se stai chiamando codice esterno fuori dal tuo
controllo e restituisce uno stato non valido che non hai modo di correggere.
Tuttavia, quando è previsto un errore, è più appropriato restituire un Result
piuttosto che effettuare una chiamata panic!. Esempi includono un parser che
riceve dati non validi o una richiesta HTTP che restituisce uno stato che indica
il raggiungimento di un limite di connessioni. In questi casi, restituire un
Result indica che un errore è una possibilità prevista che il codice chiamante
deve decidere come gestire.
Quando il codice esegue un’operazione che potrebbe mettere a rischio un utente
se viene chiamata utilizzando valori non validi, il codice dovrebbe prima
verificare che i valori siano validi e generare un errore di panic se i valori
non sono validi. Questo avviene principalmente per motivi di sicurezza: tentare
di operare su dati non validi può esporre il codice a vulnerabilità. Questo è il
motivo principale per cui la libreria standard chiamerà panic! se si tenta un
accesso alla memoria fuori dai limiti: tentare di accedere a memoria che non
appartiene alla struttura dati corrente è un problema di sicurezza comune. Le
funzioni spesso hanno dei contracts (contratti): il loro comportamento è
garantito solo se gli input soddisfano determinati requisiti. Andare in panic
quando il contratto viene violato ha senso perché una violazione del contratto
indica sempre un bug lato chiamante, e non è un tipo di errore che si desidera
che il codice chiamante debba gestire esplicitamente. In effetti, non esiste un
modo ragionevole per il codice chiamante di recuperare; i programmatori che
chiamano il codice devono correggerlo. I contratti per una funzione, soprattutto
quando una violazione causerà un panic, dovrebbero essere spiegati nella
documentazione API della funzione.
Tuttavia, avere molti controlli di errore in tutte le funzioni sarebbe prolisso
e fastidioso. Fortunatamente, è possibile utilizzare il sistema dei type di
Rust (e quindi il controllo dei type effettuato dal compilatore) per eseguire
molti dei controlli al tuo posto. Se la tua funzione ha un type particolare
come parametro, puoi procedere con la logica del codice sapendo che il
compilatore ha già verificato la presenza di un valore valido. Ad esempio, se
hai un type anziché un’Option, il tuo programma si aspetta di avere
qualcosa anziché niente. Il codice non dovrà quindi gestire due casi per le
varianti Some e None: gestirà solo il caso che ha sicuramente un valore. Il
codice che tenta di non passare nulla alla funzione non verrà nemmeno compilato,
quindi la funzione non dovrà verificare quel caso in fase di esecuzione. Un
altro esempio è l’utilizzo di un type intero senza segno come u32, che
garantisce che il parametro non sia mai negativo.
Type Personalizzati per la Convalida
Sviluppiamo ulteriormente l’idea di utilizzare il sistema dei type di Rust per garantire un valore valido e proviamo a creare un type personalizzato per la convalida. Riprendiamo il gioco di indovinelli del Capitolo 2 in cui il nostro codice chiedeva all’utente di indovinare un numero compreso tra 1 e 100. Non abbiamo mai verificato che la risposta dell’utente fosse compresa tra quei numeri prima di confrontarla con il nostro numero segreto; abbiamo solo verificato che la risposta fosse positiva. In questo caso, le conseguenze non sono state poi così gravi: il nostro output “Troppo alto” o “Troppo basso” sarebbe stato comunque corretto. Ma sarebbe stato un utile miglioramento guidare l’utente verso risposte valide e avere un comportamento diverso quando l’utente ipotizza un numero fuori dall’intervallo rispetto a quando l’utente digita, ad esempio, delle lettere.
Un modo per farlo sarebbe analizzare l’ipotesi come i32 invece che solo come
u32 per consentire numeri potenzialmente negativi, e quindi aggiungere un
controllo per verificare che il numero sia compreso nell’intervallo, in questo
modo:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
loop {
// --taglio--
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: i32 = match ipotesi.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if ipotesi < 1 || ipotesi > 100 {
println!("Il numero segreto è compreso tra 1 e 100.");
continue;
}
match ipotesi.cmp(&numero_segreto) {
// --taglio--
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => {
println!("Hai indovinato!");
break;
}
}
}
}L’espressione if verifica se il nostro valore è fuori dall’intervallo, informa
l’utente del problema e chiama continue per avviare l’iterazione successiva
del ciclo e richiedere un’altra ipotesi. Dopo l’espressione if, possiamo
procedere con i confronti tra ipotesi e il numero segreto, sapendo che
ipotesi è compreso tra 1 e 100.
Tuttavia, questa non è una soluzione ideale: se fosse assolutamente fondamentale che il programma operasse solo su valori compresi tra 1 e 100, e avesse molte funzioni con questo requisito, avere un controllo di questo tipo in ogni funzione sarebbe ripetitivo (e potrebbe influire sulle prestazioni).
Invece, possiamo creare un nuovo type in un modulo dedicato e inserire le
validazioni in una funzione per creare un’istanza del type, anziché ripetere
le validazioni ovunque. In questo modo, le funzioni possono utilizzare il nuovo
type nelle loro firme in tutta sicurezza e utilizzare con sicurezza i valori
che ricevono. Il Listato 9-13 mostra un modo per definire un type Ipotesi
che creerà un’istanza di Ipotesi solo se la funzione new riceve un valore
compreso tra 1 e 100.
#![allow(unused)] fn main() { pub struct Ipotesi { valore: i32, } impl Ipotesi { pub fn new(valore: i32) -> Ipotesi { if valore < 1 || valore > 100 { panic!("L'ipotesi deve essere compresa tra 1 e 100, valore ottenuto: {valore}."); } Ipotesi { valore } } pub fn valore(&self) -> i32 { self.valore } } }
Ipotesi che continuerà solo con valori compresi tra 1 e 100Nota che questo codice in src/gioco_indovinello.rs dipende dall’aggiunta di
una dichiarazione di modulo mod gioco_indovinello; in src/lib.rs che non
abbiamo mostrato qui. All’interno del file di questo nuovo modulo, definiamo una
struct denominata Ipotesi che ha un campo denominato valore di type
i32. È qui che verrà memorizzato il numero.
Quindi implementiamo una funzione associata denominata new su Ipotesi che
crea istanze di valori Ipotesi. La funzione new è definita per avere un
parametro denominato valore di type i32 e restituire un Ipotesi. Il
codice nel corpo della funzione new verifica valore per assicurarsi che sia
compreso tra 1 e 100. Se valore non supera questo test, effettuiamo una
chiamata panic!, che avviserà il programmatore che sta scrivendo il codice
chiamante che ha un bug da correggere, perché creare un Ipotesi con un
valore al di fuori di questo intervallo violerebbe il contratto su cui si basa
Ipotesi::new. Le condizioni in cui Ipotesi::new potrebbe generare un errore
di panic dovrebbero essere discusse nella documentazione dell’API pubblica;
tratteremo le convenzioni di documentazione che indicano la possibilità di un
errore panic! nella documentazione delle API che creerai nel Capitolo 14. Se
valore supera il test, creiamo un nuovo Ipotesi con il suo campo valore
impostato sul parametro valore e restituiamo Ipotesi.
Successivamente, implementiamo un metodo chiamato valore che prende in
prestito (borrow) self, non ha altri parametri e restituisce un i32.
Questo tipo di metodo è talvolta chiamato getter perché il suo scopo è
ottenere alcuni dati dai suoi campi e restituirli. È necessario dichiarare
questo metodo come public perché il campo valore della struttura Ipotesi è
privato. È importante che il campo valore sia privato, in modo che il codice
che utilizza la struttura Ipotesi non possa impostare valore direttamente:
il codice esterno al modulo gioco_indovinello deve utilizzare la funzione
Ipotesi::new per creare un’istanza di Ipotesi, garantendo così che Ipotesi
non possa avere un valore che non sia stato verificato dalle condizioni della
funzione Ipotesi::new.
Una funzione che ha un parametro o restituisce solo numeri compresi tra 1 e 100
potrebbe quindi dichiarare nella sua definizione che accetta o restituisce un
Ipotesi anziché un i32 e non avrebbe bisogno di effettuare ulteriori
controlli nel suo corpo.
Riepilogo
Le funzionalità di gestione degli errori di Rust sono progettate per aiutarti a
scrivere codice più robusto. La macro panic! segnala che il programma si trova
in uno stato che non può gestire e ti consente di dire al processo di
interrompersi invece di provare a procedere con valori non validi o errati.
L’enum Result utilizza il sistema dei type di Rust per indicare che le
operazioni potrebbero fallire in un modo “recuperabile”. Puoi usare Result
anche per indicare al codice chiamante che deve gestire potenziali successi o
fallimenti. L’utilizzo di panic! e Result nelle situazioni appropriate
renderà il tuo codice più affidabile di fronte a inevitabili problemi.
Ora che hai visto i modi utili in cui la libreria standard utilizza i type
generici con le enum Option e Result, nel prossimo capitolo ne parleremo
in maniera approfondita e di come puoi usarli nel tuo codice.
Type Generici, Trait e Lifetime
Ogni linguaggio di programmazione dispone di strumenti per gestire efficacemente la duplicazione di concetti. In Rust, uno di questi strumenti sono i type generici: sostituti astratti per type concreti o altre proprietà. Possiamo esprimere il comportamento dei type generici o come si relazionano ad altri type generici senza sapere cosa ci sarà al loro posto durante la compilazione e l’esecuzione del codice.
Le funzioni possono accettare parametri di un type generico, invece di un
type concreto come i32 o String, allo stesso modo in cui accettano
parametri con valori sconosciuti per eseguire lo stesso codice su più valori
concreti. Infatti, abbiamo già utilizzato i generici nel Capitolo 6 con
Option<T>, nel Capitolo 8 con Vec<T> e HashMap<K, V> e nel Capitolo 9 con
Result<T, E>. In questo capitolo, esplorerai come definire i tuoi type,
funzioni e metodi personalizzati con i generici!
Per prima cosa, esamineremo come estrarre una funzione per ridurre la duplicazione del codice. Utilizzeremo quindi la stessa tecnica per creare una funzione generica da due funzioni che differiscono solo per il type dei loro parametri. Spiegheremo anche come utilizzare i type generici nelle definizioni di struct ed enum.
Poi imparerai come utilizzare i trait per definire il comportamento in modo generico. Puoi combinare i trait con i type generici per vincolare un type generico ad accettare solo i type che hanno un comportamento particolare, anziché qualsiasi type.
Infine, parleremo della longevità (lifetime): una varietà di generici che fornisce al compilatore informazioni su come i reference si relazionano tra loro. I lifetime ci permettono di fornire al compilatore informazioni sufficienti sui valori presi in prestito in modo che possa garantire che i reference siano validi in più situazioni di quante ne potrebbe avere senza il nostro aiuto.
Rimuovere la Duplicazione Mediante l’Estrazione di una Funzione
I type generici ci permettono di sostituire type specifici con un segnaposto che rappresenta più type per evitare la duplicazione del codice. Prima di addentrarci nella sintassi dei type generici, vediamo come rimuovere le ripetizioni in un modo che non coinvolga type generici, estraendo una funzione che sostituisce valori specifici con un segnaposto che rappresenta più valori. Poi applicheremo la stessa tecnica per estrarre una funzione generica! Analizzando come riconoscere il codice duplicato che è possibile estrarre in una funzione, comincerai a riconoscere il codice duplicato che può utilizzare i generici.
Inizieremo con il breve programma nel Listato 10-1 che trova il numero più grande in un elenco.
fn main() { let lista_numeri = vec![34, 50, 25, 100, 65]; let mut maggiore = &lista_numeri[0]; for numero in &lista_numeri { if numero > maggiore { maggiore = numero; } } println!("Il numero maggiore è {maggiore}"); assert_eq!(*maggiore, 100); }
Memorizziamo un elenco di numeri interi nella variabile lista_numeri e
inseriamo un reference al primo numero dell’elenco in una variabile denominata
maggiore. Quindi eseguiamo un’iterazione su tutti i numeri dell’elenco e, se
il numero corrente è più grande del numero memorizzato in maggiore,
sostituiamo il reference in quella variabile. Tuttavia, se il numero corrente
è minore o uguale al numero più grande visto finora, la variabile non cambia e
il codice passa al numero successivo nell’elenco. Dopo aver considerato tutti i
numeri nell’elenco, maggiore dovrebbe riferirsi al numero più grande, che in
questo caso è 100.
Ora ci è stato chiesto di trovare il numero più grande in due diversi elenchi di numeri. Per farlo, possiamo scegliere di duplicare il codice nel Listato 10-1 e utilizzare la stessa logica in due punti diversi del programma, come mostrato nel Listato 10-2.
fn main() { let lista_numeri = vec![34, 50, 25, 100, 65]; let mut maggiore = &lista_numeri[0]; for numero in &lista_numeri { if numero > maggiore { maggiore = numero; } } println!("Il numero maggiore è {maggiore}"); let lista_numeri = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut maggiore = &lista_numeri[0]; for numero in &lista_numeri { if numero > maggiore { maggiore = numero; } } println!("Il numero maggiore è {maggiore}"); }
Sebbene questo codice funzioni, duplicarlo è noioso e soggetto a errori. Dobbiamo anche ricordarci di aggiornare il codice in più punti quando vogliamo modificarlo.
Per eliminare questa duplicazione, creeremo un’astrazione definendo una funzione che opera su qualsiasi elenco di interi passati come parametro. Questa soluzione rende il nostro codice più chiaro e ci permette di esprimere il concetto di ricerca del numero più grande in un elenco in modo astratto.
Nel Listato 10-3, estraiamo il codice che trova il numero più grande in una
funzione denominata maggiore. Quindi chiamiamo la funzione per trovare il
numero più grande nelle due liste del Listato 10-2. Potremmo anche utilizzare la
funzione su qualsiasi altro elenco di valori i32 che potremmo avere in futuro.
fn maggiore(lista: &[i32]) -> &i32 { let mut maggiore = &list[0]; for elemento in lista { if elemento > maggiore { maggiore = elemento; } } maggiore } fn main() { let lista_numeri = vec![34, 50, 25, 100, 65]; let risultato = maggiore(&lista_numeri); println!("Il numero maggiore è {risultato}"); assert_eq!(*risultato, 100); let lista_numeri = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let risultato = maggiore(&lista_numeri); println!("Il numero maggiore è {risultato}"); assert_eq!(*risultato, 6000); }
La funzione maggiore ha un parametro chiamato lista, che rappresenta
qualsiasi slice concreta di valori i32 che potremmo passare alla funzione.
Di conseguenza, quando chiamiamo la funzione, il codice viene eseguito sui
valori specifici che passiamo.
In sintesi, ecco i passaggi che abbiamo seguito per modificare il codice dal Listato 10-2 al Listato 10-3
- Identificare il codice duplicato.
- Estrarre il codice duplicato nel corpo della funzione e specificare gli input e i valori restituiti da tale codice nella firma della funzione.
- Aggiornare le due istanze di codice duplicato per chiamare la funzione.
Successivamente, utilizzeremo gli stessi passaggi con i type generici per
ridurre la duplicazione del codice. Allo stesso modo in cui il corpo della
funzione può operare su una lista astratta anziché su valori specifici, i
type generici consentono al codice di operare su type astratti.
Ad esempio, supponiamo di avere due funzioni: una che trova l’elemento più
grande in un insieme di valori i32 e una che trova l’elemento più grande in un
insieme di valori char. Come elimineremmo questa duplicazione? Scopriamolo!
Tipi di Dati Generici
Utilizziamo i type generici per creare definizioni per elementi come firme di funzioni o struct, che possiamo poi utilizzare con molti tip di dati concreti diversi. Vediamo prima come definire funzioni, struct, enum e metodi utilizzando i type generici. Poi discuteremo di come i generici influiscono sulle prestazioni del codice.
Nella Definizione delle Funzioni
Quando definiamo una funzione che utilizza i type generici, li inseriamo nella firma della funzione, dove normalmente specificheremmo i type dei parametri e il type del valore restituito. In questo modo il nostro codice diventa più flessibile e fornisce maggiori funzionalità ai chiamanti della nostra funzione, evitando al contempo la duplicazione del codice.
Continuando con la nostra funzione maggiore, il Listato 10-4 mostra due
funzioni che trovano entrambe il valore più grande in una slice. Le
combineremo quindi in un’unica funzione che utilizza i type generici.
fn maggior_i32(lista: &[i32]) -> &i32 { let mut maggiore = &lista[0]; for elemento in lista { if elemento > maggiore { maggiore = elemento; } } maggiore } fn maggior_char(lista: &[char]) -> &char { let mut maggiore = &lista[0]; for elemento in lista { if elemento > maggiore { maggiore = elemento; } } maggiore } fn main() { let lista_numeri = vec![34, 50, 25, 100, 65]; let risultato = maggior_i32(&lista_numeri); println!("Il numero maggiore è {risultato}"); assert_eq!(*risultato, 100); let lista_caratteri = vec!['y', 'm', 'a', 'q']; let risultato = maggior_char(&lista_caratteri); println!("Il carattere maggiore è {risultato}"); assert_eq!(*risultato, 'y'); }
La funzione maggior_i32 è quella che abbiamo estratto nel Listato 10-3 e che
trova l’i32 più grande in una slice. La funzione maggior_char trova il
char più grande in una slice. I corpi delle funzioni hanno lo stesso codice,
quindi eliminiamo la duplicazione introducendo un parametro di type generico
in una singola funzione.
Per parametrizzare i type in una nuova singola funzione, dobbiamo assegnare un
nome al parametro di type, proprio come facciamo per i parametri di valore di
una funzione. È possibile utilizzare qualsiasi identificatore come nome di
parametro di type. Ma useremo T perché, per convenzione, i nomi dei
parametri di type in Rust sono brevi, spesso di una sola lettera, e la
convenzione di denominazione dei type di Rust è CamelCase1 (nello
specifico UpperCamelCase). Abbreviazione di type, T è la scelta predefinita
della maggior parte dei programmatori Rust.
Quando utilizziamo un parametro nel corpo della funzione, dobbiamo dichiarare il
nome del parametro nella firma in modo che il compilatore ne conosca il
significato. Allo stesso modo, quando usiamo un type come parametro nella
firma di una funzione, dobbiamo dichiarare il nome del type prima di
utilizzarlo. Per definire la funzione generica maggiore, inseriamo le
dichiarazioni del nome del type tra parentesi angolari, <>, tra il nome
della funzione e l’elenco dei parametri, in questo modo:
fn maggiore<T>(lista: &[T]) -> &T {Leggiamo questa definizione come “La funzione maggiore è generica su un certo
type T”. Questa funzione ha un parametro denominato lista, che è una
slice di valori di type T. La funzione maggiore restituirà un
reference a un valore dello stesso type T.
Il Listato 10-5 mostra la definizione combinata della funzione maggiore
utilizzando il type di dati generico nella sua firma. Il Listato mostra anche
come possiamo chiamare la funzione con una slice di valori i32 o char.
Nota che questo codice non verrà ancora compilato.
fn maggiore<T>(lista: &[T]) -> &T {
let mut maggiore = &lista[0];
for elemento in lista {
if elemento > maggiore {
maggiore = elemento;
}
}
maggiore
}
fn main() {
let lista_numeri = vec![34, 50, 25, 100, 65];
let risultato = maggiore(&lista_numeri);
println!("Il numero maggiore è {risultato}");
let lista_caratteri = vec!['y', 'm', 'a', 'q'];
let risultato = maggiore(&lista_caratteri);
println!("Il carattere maggiore è {risultato}");
}maggiore che utilizza parametri di type generico; non è ancora compilabileSe compiliamo questo codice adesso, otterremo questo errore:
$ cargo run
Compiling capitolo10 v0.1.0 (file:///progetti/capitolo10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:21
|
5 | if elemento > maggiore {
| -------- ^ -------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn maggiore<T: std::cmp::PartialOrd>(lista: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `capitolo10` (bin "capitolo10") due to 1 previous error
Il testo di aiuto menziona std::cmp::PartialOrd, che è un trait, e parleremo
dei trait nella prossima sezione. Per ora, sappi che questo errore indica che
il corpo di maggiore non funzionerà per tutti i possibili type di T.
Poiché vogliamo confrontare valori di type T nel corpo, possiamo utilizzare
solo type i cui valori possono essere ordinati. Per abilitare i confronti, la
libreria standard include il trait std::cmp::PartialOrd che è possibile
implementare sui type (vedere l’Appendice C per maggiori informazioni
su questo trait). Per correggere il Listato 10-5, possiamo seguire il
suggerimento del testo di aiuto e limitare i type validi per T solo a quelli
che implementano PartialOrd. Il Listato verrà quindi compilato, poiché la
libreria standard implementa PartialOrd sia su i32 che su char.
Nella Definizione delle Struct
Possiamo anche definire struct per utilizzare un parametro di type generico
in uno o più campi utilizzando la sintassi <>. Il Listato 10-6 definisce una
struct Punto<T> per contenere i valori delle coordinate x e y di
qualsiasi type.
struct Punto<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
Punto<T> che contiene i valori x e y di type TLa sintassi per l’utilizzo di type generici nelle definizioni di struct è simile a quella utilizzata nelle definizioni di funzione. Per prima cosa dichiariamo il nome del type tra parentesi angolari subito dopo il nome della struct. Quindi utilizziamo il type generico nella definizione della struct, dove altrimenti specificheremmo type di dati concreti.
Nota che, poiché abbiamo utilizzato un solo type generico per definire
Punto<T>, questa definizione afferma che la struct Punto<T> è generica su
un type T e che i campi x e y sono entrambi dello stesso type,
qualunque esso sia. Se creiamo un’istanza di Punto<T> che ha valori di type
diversi, come nel Listato 10-7, il nostro codice non verrà compilato.
struct Punto<T> {
x: T,
y: T,
}
fn main() {
let non_funzionante = Punto { x: 5, y: 4.0 };
}x e y devono essere dello stesso type perché entrambi hanno lo stesso type di dati generico TIn questo esempio, quando assegniamo il valore intero 5 a x, comunichiamo al
compilatore che il type generico T sarà un intero per questa istanza di
Punto<T>. Quindi, quando specifichiamo 4.0 per y, che abbiamo definito
come dello stesso type di x, otterremo un errore di mancata corrispondenza
di type come questo:
$ cargo run
Compiling capitolo10 v0.1.0 (file:///progetti/capitolo10)
error[E0308]: mismatched types
--> src/main.rs:7:44
|
7 | let non_funzionante = Punto { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `capitolo10` (bin "capitolo10") due to 1 previous error
Per definire una struct Punto in cui x e y sono entrambi type generici
ma potrebbero avere type diversi, possiamo utilizzare più parametri di type
generico. Ad esempio, nel Listato 10-8, modifichiamo la definizione di Punto
in modo che sia generico sui type T e U, dove x è di type T e y è
di type U.
struct Punto<T, U> { x: T, y: U, } fn main() { let entrambi_interi = Punto { x: 5, y: 10 }; let entrambi_float = Punto { x: 1.0, y: 4.0 }; let intero_e_float = Punto { x: 5, y: 4.0 }; }
Punto<T, U> generico su due type in modo che x e y possano essere valori di type diversiOra tutte le istanze di Punto mostrate sono consentite! Puoi usare tutti i
parametri di type generico che vuoi in una definizione, ma usarne di più rende
il codice difficile da leggere. Se ti accorgi di aver bisogno di molti type
generici nel tuo codice, potrebbe essere necessario riscriverlo in parti più
piccole.
Nella Definizione delle Enum
Come abbiamo fatto con le struct, possiamo definire le enum per contenere
type di dati generici nelle loro varianti. Diamo un’altra occhiata all’enum
Option<T> fornito dalla libreria standard, che abbiamo usato nel Capitolo 6:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
Questa definizione dovrebbe ora esserti più chiara. Come puoi vedere, l’enum
Option<T> è generico sul type T e ha due varianti: Some, che contiene un
valore di type T, e una variante None che non contiene alcun valore.
Utilizzando l’enum Option<T>, possiamo esprimere il concetto astratto di un
valore opzionale e, poiché Option<T> è generico, possiamo usare questa
astrazione indipendentemente dal type del valore opzionale.
Anche le enum possono usare più type generici. La definizione dell’enum
Result che abbiamo usato nel Capitolo 9 ne è un esempio:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
L’enum Result è generico su due type, T ed E, e ha due varianti: Ok,
che contiene un valore di type T, e Err, che contiene un valore di type
E. Questa definizione rende comodo usare l’enum Result ovunque abbiamo
un’operazione che potrebbe avere successo (restituire un valore di type T) o
fallire (restituire un errore di type E). In effetti, questo è ciò che
abbiamo usato per aprire un file nel Listato 9-3, dove T veniva riempito con
il type std::fs::File quando il file veniva aperto correttamente ed E
veniva riempito con il type std::io::Error quando si verificavano problemi
durante l’apertura del file.
Quando trovi situazioni nel codice con più definizioni di struct o enum che differiscono solo per il type dei valori che contengono, è possibile evitare la duplicazione utilizzando invece type generici.
Nella Definizione dei Metodi
Possiamo implementare metodi su struct ed enum (come abbiamo fatto nel
Capitolo 5) e utilizzare type generici anche nella loro definizione. Il
Listato 10-9 mostra la struct Punto<T> definita nel Listato 10-6 con un
metodo denominato x implementato su di essa.
struct Punto<T> { x: T, y: T, } impl<T> Punto<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Punto { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
x sulla struct Punto<T> che restituirà un reference al campo x di type TQui, abbiamo definito un metodo denominato x su Punto<T> che restituisce un
reference ai dati nel campo x.
Nota che dobbiamo dichiarare T subito dopo impl in modo da poter usare T
per specificare che stiamo implementando metodi sul type Punto<T>.
Dichiarando T come type generico dopo impl, Rust può identificare che il
type tra parentesi angolari in Punto è un type generico piuttosto che un
type concreto. Avremmo potuto scegliere un nome diverso per questo parametro
generico rispetto al parametro generico dichiarato nella definizione della
struct, ma utilizzare lo stesso nome è convenzionale. Se si scrive un metodo
all’interno di un impl che dichiara un type generico, tale metodo verrà
definito su qualsiasi istanza del type, indipendentemente dal type concreto
che finisce per sostituire il type generico.
Possiamo anche specificare vincoli sui type generici quando si definiscono
metodi sul type. Ad esempio, potremmo implementare metodi solo su istanze di
Punto<f32> piuttosto che su istanze di Punto<T> con qualsiasi type
generico. Nel Listato 10-10 utilizziamo il type concreto f32, il che
significa che non dichiariamo alcun type dopo impl.
struct Punto<T> { x: T, y: T, } impl<T> Punto<T> { fn x(&self) -> &T { &self.x } } impl Punto<f32> { fn distanza_da_origine(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Punto{ x: 5, y: 10 }; println!("p.x = {}", p.x()); }
impl che si applica solo a una struct con un particolare type concreto per il parametro di type generico TQuesto codice indica che il type Punto<f32> avrà un metodo
distanza_da_origine; altre istanze di Punto<T> in cui T non è di type
f32 non avranno questo metodo definito. Il metodo misura la distanza del
nostro punto dal punto alle coordinate (0.0, 0.0) e utilizza operazioni
matematiche disponibili solo per i type a virgola mobile.
I parametri di type generico nella definizione di una struct non sono sempre
gli stessi di quelli utilizzati nelle firme dei metodi della stessa struct. Il
Listato 10-11 utilizza i type generici X1 e Y1 per la struct Punto e
X2 e Y2 per la firma del metodo misto per rendere l’esempio più chiaro. Il
metodo crea una nuova istanza di Punto con il valore x dal self Punto
(di type X1) e il valore y dal Punto passato come argomento (di type
Y2).
struct Punto<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Punto<X1, Y1> { fn misto<X2, Y2>(self, altro: Punto<X2, Y2>) -> Punto<X1, Y2> { Punto { x: self.x, y: altro.y, } } } fn main() { let p1 = Punto { x: 5, y: 10.4 }; let p2 = Punto { x: "Ciao", y: 'c' }; let p3 = p1.misto(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
In main, abbiamo definito un Punto che ha un i32 per x (con valore 5)
e un f64 per y (con valore 10.4). La variabile p2 è una struct Punto
che ha una slice di stringa per x (con valore "Ciao") e un char per y
(con valore c). Chiamando misto su p1 con l’argomento p2 otteniamo p3,
che avrà un i32 per x perché x proviene da p1. La variabile p3 avrà un
char per y perché y proviene da p2. La chiamata alla macro println!
stamperà p3.x = 5, p3.y = c.
Lo scopo di questo esempio è dimostrare una situazione in cui alcuni parametri
generici sono dichiarati con impl e altri con la definizione del metodo. Qui,
i parametri generici X1 e Y1 sono dichiarati dopo impl perché vanno con la
definizione della struct. I parametri generici X2 e Y2 sono dichiarati
dopo fn misto perché sono rilevanti solo per il metodo.
Prestazioni del Codice Utilizzando Type Generici
Potresti chiederti se l’utilizzo di parametri di type generico costi in termini prestazionali durante l’esecuzione del codice. La buona notizia è che l’utilizzo di type generici non renderà il tuo programma più lento di quanto lo sarebbe con type concreti.
Rust ottiene questo risultato eseguendo la monomorfizzazione del codice utilizzando i generici in fase di compilazione. La monomorfizzazione è il processo di trasformazione del codice generico in codice specifico inserendo i type concreti utilizzati in fase di compilazione. In questo processo, il compilatore esegue l’opposto dei passaggi che abbiamo utilizzato per creare la funzione generica nel Listato 10-5: il compilatore esamina tutti i punti in cui viene chiamato il codice generico e genera codice per i type concreti con cui viene chiamato il codice generico.
Vediamo come funziona utilizzando l’enum generico Option<T> della libreria
standard:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
Quando Rust compila questo codice, esegue la monomorfizzazione. Durante questo
processo, il compilatore legge i valori utilizzati nelle istanze di Option<T>
e identifica due type di Option<T>: uno è i32 e l’altro è f64. Pertanto,
espande la definizione generica di Option<T> in due definizioni specializzate
per i32 e f64, sostituendo così la definizione generica con quelle
specifiche.
La versione monomorfizzata del codice è simile alla seguente (il compilatore usa nomi diversi da quelli che stiamo usando qui a scopo illustrativo):
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
Il generico Option<T> viene sostituito con le definizioni specifiche create
dal compilatore. Poiché Rust compila il codice generico in codice che specifica
il type in ogni istanza, non si paga alcun costo prestazionale durante
l’esecuzione per l’utilizzo di type generici. Quando il codice viene eseguito,
si comporta esattamente come se avessimo duplicato ogni definizione manualmente.
Il processo di monomorfizzazione rende i generici di Rust estremamente
efficienti in fase di esecuzione.
Definire il Comportamento Condiviso con i Trait
Un tratto (trait) definisce la funzionalità che un particolare type ha e può condividere con altri type. Possiamo usare i trait per definire il comportamento condiviso in modo astratto. Possiamo usare i vincoli del tratto (trait bound) per specificare che un type generico può essere qualsiasi type che abbia un determinato comportamento.
Nota: i trait sono simili a una funzionalità spesso chiamata interfacce (interfaces) in altri linguaggi, sebbene con alcune differenze.
Definire un Trait
Il comportamento di un type consiste nei metodi che possiamo chiamare su quel type. Type diversi condividono lo stesso comportamento se possiamo chiamare gli stessi metodi su tutti quei type. Le definizioni dei trait sono un modo per raggruppare le firme dei metodi per definire un insieme di comportamenti necessari per raggiungere un determinato scopo.
Ad esempio, supponiamo di avere più struct che contengono vari tipi e quantità
di testo: una struttura Articolo che contiene una notizia archiviata in una
posizione specifica e una PostSocial che può contenere, al massimo, 280
caratteri insieme a metadati che indicano se si tratta di un nuovo post, una
ripubblicazione o una risposta a un altro post.
Vogliamo creare una libreria di aggregazione multimediale denominata
aggregatore in grado di visualizzare riepiloghi dei dati che potrebbero essere
memorizzati in un’istanza di Articolo o PostSocial. Per fare ciò, abbiamo
bisogno di un riepilogo per ciascun type e richiederemo tale riepilogo
chiamando un metodo riassunto su un’istanza. Il Listato 10-12 mostra la
definizione di un trait pubblico Sommario che esprime questo comportamento.
pub trait Sommario {
fn riassunto(&self) -> String;
}Sommario che consiste nel comportamento fornito da un metodo riassuntoQui, dichiariamo un trait usando la parola chiave trait e poi il nome del
trait, che in questo caso è Sommario. Dichiariamo anche il trait come
pub in modo che anche i crate che dipendono da questo crate possano
utilizzare questo trait, come vedremo in alcuni esempi. All’interno delle
parentesi graffe, dichiariamo le firme dei metodi che descrivono i comportamenti
dei type che implementano questo trait, che in questo caso è fn riassunto(&self) -> String.
Dopo la firma del metodo, invece di fornire un’implementazione tra parentesi
graffe, utilizziamo un punto e virgola. Ogni type che implementa questo
trait deve fornire il proprio comportamento personalizzato per il corpo del
metodo. Il compilatore imporrà che qualsiasi type che abbia il trait
Sommario abbia il metodo riassunto definito esattamente con questa firma.
Una trait può avere più metodi nel suo corpo: le firme dei metodi sono elencate una per riga e ogni riga termina con un punto e virgola.
Implementare un Trait su un Type
Ora che abbiamo definito le firme desiderate dei metodi del trait Sommario,
possiamo implementarlo sui type nel nostro aggregatore multimediale. Il
Listato 10-13 mostra un’implementazione del trait Sommario sulla struct
Articolo che utilizza il titolo, l’autore e la posizione per creare il valore
di ritorno di riassunto. Per la struct PostSocial, definiamo riassunto
come il nome utente seguito dall’intero testo del post, supponendo che il
contenuto del post sia già limitato a 280 caratteri.
pub trait Sommario {
fn riassunto(&self) -> String;
}
pub struct Articolo {
pub titolo: String,
pub posizione: String,
pub autore: String,
pub contenuto: String,
}
impl Sommario for Articolo {
fn riassunto(&self) -> String {
format!("{}, di {} ({})", self.titolo, self.autore, self.posizione)
}
}
pub struct PostSocial {
pub nomeutente: String,
pub contenuto: String,
pub risposta: bool,
pub repost: bool,
}
impl Sommario for PostSocial {
fn riassunto(&self) -> String {
format!("{}: {}", self.nomeutente, self.contenuto)
}
}Sommario sui type Articolo e PostSocialImplementare un trait su un type è simile a come normalmente sono
implementati i metodi. La differenza è che dopo impl, inseriamo il nome del
trait che vogliamo implementare, poi utilizziamo la parola chiave for e
infine specifichiamo il nome del type per cui vogliamo implementare il
trait. All’interno del blocco impl, inseriamo le firme dei metodi definite
dalla definizione del trait. Invece di aggiungere un punto e virgola dopo ogni
firma, utilizziamo le parentesi graffe e riempiamo il corpo del metodo con il
comportamento specifico che vogliamo che i metodi del trait abbiano per quel
particolare type.
Ora che la libreria ha implementato il trait Sommario su Articolo e
PostSocial, gli utenti del crate possono chiamare i metodi del trait sulle
istanze di Articolo e PostSocial nello stesso modo in cui chiamiamo i metodi
normali. L’unica differenza è che l’utente deve includere il trait nello
scope oltre ai type. Ecco un esempio di come un crate binario potrebbe
utilizzare il nostro crate libreria aggregatore:
use aggregatore::{PostSocial, Sommario};
fn main() {
let post = PostSocial {
nomeutente: String::from("horse_ebooks"),
contenuto: String::from(
"ovviamente, come probabilmente già sapete, gente",
),
risposta: false,
repost: false,
};
println!("1 nuovo post: {}", post.riassunto());
}Questo codice stampa 1 nuovo post: horse_ebooks: ovviamente, come probabilmente già sapete, gente.
Anche altri crate che dipendono dal crate aggregatore possono includere il
trait Sommario nello scope per implementare Sommario sui propri type.
Una restrizione da notare è che possiamo implementare un trait su un type
solo se il trait o il type, o entrambi, sono locali al nostro crate. Ad
esempio, possiamo implementare trait della libreria standard come Display su
un type personalizzato come PostSocial come parte della funzionalità del
nostro crate aggregatore, perché il type PostSocial è locale al nostro
crate aggregatore. Possiamo anche implementare Sommario su Vec<T> nel
nostro crate aggregatore, perché il trait Sommario è locale al nostro
crate aggregatore.
Ma non possiamo implementare trait esterni su type esterni. Ad esempio, non
possiamo implementare il trait Display su Vec<T> all’interno del nostro
crate aggregatore perché Display e Vec<T> sono entrambi definiti nella
libreria standard e non sono locali al nostro crate aggregatore. Questa
restrizione fa parte di una proprietà chiamata coerenza (coherence), e più
specificamente della regola dell’orfano (orphan rule), così chiamata perché
il type genitore non è presente. Questa regola garantisce che il codice di
altri non possa rompere il tuo codice e viceversa. Senza questa regola, due
crate potrebbero implementare lo stesso trait per lo stesso type e Rust
non saprebbe quale implementazione utilizzare.
Usare le Implementazioni Predefinite
A volte è utile avere un comportamento predefinito per alcuni o tutti i metodi in un trait invece di richiedere implementazioni per tutti i metodi su ogni type. Quindi, quando implementiamo il trait su un type particolare, possiamo mantenere o sovrascrivere il comportamento predefinito di ciascun metodo.
Nel Listato 10-14, specifichiamo una stringa predefinita per il metodo
riassunto del trait Sommario invece di definire solo la firma del metodo,
come abbiamo fatto nel Listato 10-12.
pub trait Sommario {
fn riassunto(&self) -> String {
String::from("(Leggi di più...)")
}
}
pub struct Articolo {
pub titolo: String,
pub posizione: String,
pub autore: String,
pub contenuto: String,
}
impl Sommario for Articolo {}
pub struct PostSocial {
pub nomeutente: String,
pub contenuto: String,
pub risposta: bool,
pub repost: bool,
}
impl Sommario for PostSocial {
fn riassunto(&self) -> String {
format!("{}: {}", self.nomeutente, self.contenuto)
}
}Sommario con un’implementazione predefinita del metodo riassuntoPer utilizzare un’implementazione predefinita per riassumere le istanze di
Articolo, specifichiamo un blocco impl vuoto con impl Sommario for Articolo {}.
Anche se non definiamo più il metodo riassunto su Articolo direttamente,
abbiamo fornito un’implementazione predefinita e specificato che Articolo
implementa il trait Sommario. Di conseguenza, possiamo comunque chiamare il
metodo riassunto su un’istanza di Articolo, in questo modo:
fn main() {
let articolo = Articolo {
titolo: String::from("I Penguins vincono la Stanley Cup!"),
posizione: String::from("Pittsburgh, PA, USA"),
autore: String::from("Iceburgh"),
contenuto: String::from(
"I Pittsburgh Penguins sono ancora una volta\
la migliore squadra di hockey nella NHL.",
),
};
println!("Nuovo articolo disponibile! {}", articolo.riassunto());
}Questo codice stampa Nuovo articolo disponibile! (Leggi di più...).
La creazione di un’implementazione predefinita non richiede alcuna modifica
all’implementazione di Sommario su PostSocial nel Listato 10-13. Il motivo è
che la sintassi per sovrascrivere un’implementazione predefinita è la stessa
della sintassi per implementare un metodo di un trait che non ha
un’implementazione predefinita.
Le implementazioni predefinite possono chiamare altri metodi nello stesso
trait, anche se questi non hanno un’implementazione predefinita. In questo
modo, un trait può fornire molte funzionalità utili e richiedere agli
implementatori di specificarne solo una piccola parte. Ad esempio, potremmo
definire il trait Sommario in modo che abbia un metodo riassunto_autore la
cui implementazione è richiesta, e quindi definire un metodo riassunto con
un’implementazione predefinita che chiama il metodo riassunto_autore:
pub trait Sommario {
fn riassunto_autore(&self) -> String;
fn riassunto(&self) -> String {
format!("(Leggi di più da {}...)", self.riassunto_autore())
}
}
pub struct PostSocial {
pub nomeutente: String,
pub contenuto: String,
pub risposta: bool,
pub repost: bool,
}
impl Sommario for PostSocial {
fn riassunto_autore(&self) -> String {
format!("@{}", self.nomeutente)
}
}Per utilizzare questa versione di Sommario, dobbiamo definire
riassunto_autore solo quando implementiamo il trait su un type:
pub trait Sommario {
fn riassunto_autore(&self) -> String;
fn riassunto(&self) -> String {
format!("(Leggi di più da {}...)", self.riassunto_autore())
}
}
pub struct PostSocial {
pub nomeutente: String,
pub contenuto: String,
pub risposta: bool,
pub repost: bool,
}
impl Sommario for PostSocial {
fn riassunto_autore(&self) -> String {
format!("@{}", self.nomeutente)
}
}Dopo aver definito riassunto_autore, possiamo chiamare riassunto sulle
istanze della struct PostSocial e l’implementazione predefinita di
riassunto chiamerà la definizione di riassunto_autore che abbiamo fornito.
Poiché abbiamo implementato riassunto_autore, il trait Sommario ci ha
fornito il comportamento del metodo riassunto senza richiedere ulteriore
codice. Ecco come appare:
use aggregatore::{self, PostSocial, Sommario};
fn main() {
let post = PostSocial {
nomeutente: String::from("horse_ebooks"),
contenuto: String::from(
"ovviamente, come probabilmente già sapete, gente",
),
risposta: false,
repost: false,
};
println!("1 nuovo post: {}", post.riassunto());
}Questo codice stampa 1 nuovo post: (Leggi di più su @horse_ebooks...).
Nota che non è possibile chiamare l’implementazione predefinita da una implementazione sovrascritta dello stesso metodo.
Usare i Trait come Parametri
Ora che sai come definire e implementare i trait, possiamo esplorare come
usarli per definire funzioni che accettano molti type diversi. Useremo il
trait Sommario che abbiamo implementato sui type Articolo e PostSocial
nel Listato 10-13 per definire una funzione notifica che chiama il metodo
riassunto sul suo parametro elemento, che è di un type che implementa il
trait Sommario. Per fare ciò, utilizziamo la sintassi impl Trait, in
questo modo:
pub trait Sommario {
fn riassunto(&self) -> String;
}
pub struct Articolo {
pub titolo: String,
pub posizione: String,
pub autore: String,
pub contenuto: String,
}
impl Sommario for Articolo {
fn riassunto(&self) -> String {
format!("{}, di {} ({})", self.titolo, self.autore, self.posizione)
}
}
pub struct PostSocial {
pub nomeutente: String,
pub contenuto: String,
pub risposta: bool,
pub repost: bool,
}
impl Sommario for PostSocial {
fn riassunto(&self) -> String {
format!("{}: {}", self.nomeutente, self.contenuto)
}
}
pub fn notifica(elemento: &impl Sommario) {
println!("Ultime notizie! {}", elemento.riassunto());
}Invece di un type concreto per il parametro elemento, specifichiamo la
parola chiave impl e il nome del trait. Questo parametro accetta qualsiasi
type che implementi il trait specificato. Nel corpo di notifica, possiamo
chiamare qualsiasi metodo su elemento che provenga dal trait Sommario,
come riassunto. Possiamo chiamare notifica e passare qualsiasi istanza di
Articolo o PostSocial. Il codice che chiama la funzione con qualsiasi altro
type, come String o i32, non verrà compilato perché questi type non
implementano Sommario.
Sintassi del Vincolo di Trait
La sintassi impl Trait funziona per i casi più semplici, ma in realtà è solo
una sintassi semplificata di una forma più lunga nota come vincolo del tratto
(trait bound); si presenta così:
pub fn notifica<T: Sommario>(elemento: &T) {
println!("Ultime notizie! {}", elemento.riassunto());
}Questa forma più lunga è equivalente all’esempio della sezione precedente, ma è più dettagliata. Posizioniamo il vincolo di trait con la dichiarazione del parametro di type generico dopo i due punti e tra parentesi angolari.
La sintassi impl Trait è comoda e consente di scrivere codice più conciso nei
casi semplici, mentre la sintassi più completa del vincolo di trait può
esprimere una maggiore complessità in altri casi. Ad esempio, possiamo avere due
parametri che implementano Sommario. Con la sintassi impl Trait, ciò si
ottiene in questo modo:
pub fn notifica(elemento1: &impl Sommario, elemento2: &impl Sommario) {L’utilizzo di impl Trait è appropriato se vogliamo che questa funzione
consenta a elemento1 e elemento2 di avere type diversi (purché entrambi i
type implementino Sommario). Tuttavia, se vogliamo forzare entrambi i
parametri ad avere lo stesso type, dobbiamo usare un vincolo di trait, in
questo modo:
pub fn notifica<T: Sommario>(elemento1: &T, elemento2: &T) {Il type generico T specificato come type dei parametri elemento1 e
elemento2 vincola la funzione in modo che il type concreto del valore
passato come argomento per elemento1 e elemento2 debba essere lo stesso.
Specificare più Vincoli di Trait con la Sintassi +
Possiamo anche specificare più di un vincolo di trait. Supponiamo di voler che
notifica usi sia la formattazione di visualizzazione, fornita dal trait
Display, sia che usi riassunto su elemento: specifichiamo nella
definizione di notifica che elemento deve implementare sia Display che
Sommario. Possiamo farlo utilizzando la sintassi +:
pub fn notifica(elemento: &(impl Sommario + Display)) {La sintassi + è valida anche con i vincoli di trait sui type generici:
pub fn notifica<T: Sommario + Display>(elemento: &T) {Con i due vincoli di trait specificati, il corpo di notifica può chiamare
riassunto e utilizzare {} per formattare elemento.
Specificare i Vincoli di Trait con le Clausole where
L’utilizzo di troppi vincoli di trait ha i suoi svantaggi. Ogni generico ha i
suoi vincoli di trait, quindi le funzioni con più parametri di type generico
possono contenere molte informazioni sui vincoli di trait tra il nome della
funzione e il suo elenco di parametri, rendendo la firma della funzione
difficile da leggere. Per questo motivo, Rust ha una sintassi alternativa per
specificare i vincoli di trait all’interno di una clausola where dopo la
firma della funzione. Quindi, invece di scrivere:
fn una_funzione<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {possiamo usare una clausola where, in questo modo:
fn una_funzione<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}La firma di questa funzione è meno confusionaria: il nome della funzione, l’elenco dei parametri e il type di ritorno sono vicini, come in una funzione senza molti vincoli di trait.
Restituire Type che Implementano Trait
Possiamo anche usare la sintassi impl Trait nella posizione di ritorno per
restituire un valore di un type che implementa un trait, come mostrato qui:
pub trait Sommario {
fn riassunto(&self) -> String;
}
pub struct Articolo {
pub titolo: String,
pub posizione: String,
pub autore: String,
pub contenuto: String,
}
impl Sommario for Articolo {
fn riassunto(&self) -> String {
format!("{}, di {} ({})", self.titolo, self.autore, self.posizione)
}
}
pub struct PostSocial {
pub nomeutente: String,
pub contenuto: String,
pub risposta: bool,
pub repost: bool,
}
impl Sommario for PostSocial {
fn riassunto(&self) -> String {
format!("{}: {}", self.nomeutente, self.contenuto)
}
}
fn riassumibile() -> impl Sommario {
PostSocial {
nomeutente: String::from("horse_ebooks"),
contenuto: String::from(
"ovviamente, come probabilmente già sapete, gente",
),
risposta: false,
repost: false,
}
}Utilizzando impl Sommario come type di ritorno, specifichiamo che la
funzione riassumibile restituisce un type che implementa il trait
Sommario senza nominare il type concreto. In questo caso, riassumibile
restituisce un PostSocial, ma il codice che chiama questa funzione non ha
bisogno di saperlo.
La possibilità di specificare un type di ritorno solo tramite il trait che
implementa è particolarmente utile nel contesto di chiusure (closure) e
iteratori, che tratteremo nel Capitolo 13. Chiusure e iteratori creano type
che solo il compilatore conosce o type che sono molto lunghi da specificare.
La sintassi impl Trait consente di specificare in modo conciso che una
funzione restituisca un type che implementa il trait Iterator senza dover
scrivere un type molto lungo.
Tuttavia, è possibile utilizzare impl Trait solo se si restituisce un singolo
type. Ad esempio, questo codice che restituisce un Articolo o un
PostSocial con il type di ritorno specificato come impl Sommario non
funzionerebbe:
pub trait Sommario {
fn riassunto(&self) -> String;
}
pub struct Articolo {
pub titolo: String,
pub posizione: String,
pub autore: String,
pub contenuto: String,
}
impl Sommario for Articolo {
fn riassunto(&self) -> String {
format!("{}, di {} ({})", self.titolo, self.autore, self.posizione)
}
}
pub struct PostSocial {
pub nomeutente: String,
pub contenuto: String,
pub risposta: bool,
pub repost: bool,
}
impl Sommario for PostSocial {
fn riassunto(&self) -> String {
format!("{}: {}", self.nomeutente, self.contenuto)
}
}
fn riassumibile(switch: bool) -> impl Sommario {
if switch {
Articolo {
titolo: String::from(
"I Penguins vincono la Stanley Cup!",
),
posizione: String::from("Pittsburgh, PA, USA"),
autore: String::from("Iceburgh"),
contenuto: String::from(
"I Pittsburgh Penguins sono ancora una volta la migliore squadra di hockey nella NHL.",
),
}
} else {
PostSocial {
nomeutente: String::from("horse_ebooks"),
contenuto: String::from(
"ovviamente, come probabilmente già sapete, gente",
),
risposta: false,
riposta: false,
}
}
}Restituire un Articolo o un PostSocial non è consentito a causa di
restrizioni relative all’implementazione della sintassi impl Trait nel
compilatore. Spiegheremo come scrivere una funzione con questo comportamento
nella sezione “Usare gli Oggetti Trait per Astrarre Comportamenti
Condivisi” del Capitolo 18.
Utilizzare Vincoli di Trait per Implementare Metodi in Modo Condizionale
Utilizzando un vincolo di trait con un blocco impl che utilizza parametri di
type generico, possiamo implementare metodi in modo condizionale per i type
che implementano i trait specificati. Ad esempio, il type Coppia<T> nel
Listato 10-15 implementa sempre la funzione new per restituire una nuova
istanza di Coppia<T> (abbiamo menzionato nella sezione “Metodi” del Capitolo 5 che Self è un alias di type per il type del
blocco impl, che in questo caso è Coppia<T>). Ma nel blocco impl
successivo, Coppia<T> implementa il metodo mostra_comparazione solo se il
suo type interno T implementa il trait PartialOrd che abilita il
confronto e il trait Display che abilita la stampa.
use std::fmt::Display;
struct Coppia<T> {
x: T,
y: T,
}
impl<T> Coppia<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Coppia<T> {
fn mostra_comparazione(&self) {
if self.x >= self.y {
println!("Il membro più grande è x = {}", self.x);
} else {
println!("Il membro più grande è y = {}", self.y);
}
}
}Possiamo anche implementare in modo condizionale un trait per qualsiasi type
che implementa un altro trait. Le implementazioni di un trait su qualsiasi
type che soddisfi i vincoli di trait sono chiamate implementazioni
generali (blanket implementations) e sono ampiamente utilizzate nella
libreria standard di Rust. Ad esempio, la libreria standard implementa il
trait ToString su qualsiasi type che implementi il trait Display. Il
blocco impl nella libreria standard è simile a questo codice:
impl<T: Display> ToString for T {
// --taglio--
}Poiché la libreria standard ha questa implementazione generale, possiamo
chiamare il metodo to_string definito dal trait ToString su qualsiasi
type che implementi il trait Display. Ad esempio, possiamo trasformare gli
integer nei loro corrispondenti valori String in questo modo, perché gli
integer implementano Display:
#![allow(unused)] fn main() { let s = 3.to_string(); }
Le implementazioni generali compaiono nella documentazione per il trait in questione nella sezione “Implementatori” (Implementors).
I trait e i vincoli dei trait ci consentono di scrivere codice che utilizza parametri di type generico per ridurre le duplicazioni, ma anche di specificare al compilatore che desideriamo che il type generico abbia un comportamento particolare. Il compilatore può quindi utilizzare le informazioni sui vincoli di trait per verificare che tutti i type concreti utilizzati nel nostro codice forniscano il comportamento corretto. Nei linguaggi a tipizzazione dinamica, otterremmo un errore durante l’esecuzione se chiamassimo un metodo su un type che non lo definisce. Ma Rust sposta questi errori in fase di compilazione, quindi siamo costretti a correggere i problemi prima ancora che il nostro codice possa essere eseguito. Inoltre, non dobbiamo scrivere codice che verifichi il comportamento durante l’esecuzione, perché lo abbiamo già verificato in fase di compilazione. Ciò migliora le prestazioni senza dover rinunciare alla flessibilità dei type generici.
Validare i Reference con la Lifetime
Le lifetime (longevità) sono un’altra tipologia di generico che abbiamo già utilizzato. Invece di garantire che un type abbia il comportamento desiderato, le lifetime assicurano che i reference siano validi finché ne abbiamo bisogno.
Un dettaglio che non abbiamo discusso nella sezione “Reference e Borrowing” del Capitolo 4 è che ogni reference in Rust ha una certa longevità, lifetime, che è lo scope per il quale quel reference è valido. Il più delle volte, la lifetime è implicita e inferita, proprio come il più delle volte i type sono inferiti. Siamo tenuti ad annotare il type solo quando sono possibili più type. Allo stesso modo, dobbiamo annotare la longevità quando la lifetime dei reference potrebbe essere correlata in diversi modi. Rust ci richiede di annotare le relazioni utilizzando parametri di lifetime generici per garantire che i reference utilizzati in fase di esecuzione siano e rimangano sicuramente validi.
Annotare la lifetime non è un concetto presente nella maggior parte degli altri linguaggi di programmazione, quindi questo ti sembrerà poco familiare. Sebbene non tratteremo la lifetime nella sua interezza in questo capitolo, discuteremo i modi più comuni in cui potresti incontrare la sintassi di lifetime in modo che tu possa familiarizzare con il concetto.
Reference Pendenti
Lo scopo principale della lifetime è prevenire i riferimenti pendenti (dangling references), che, se fossero presenti, causerebbe al programma in esecuzione di avere reference che fanno riferimento a dati a cui non dovrebbero far riferimento. Considera il programma nel Listato 10-16, che ha uno scope esterno e uno interno.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Nota: gli esempi nei Listati 10-16, 10-17 e 10-23 dichiarano variabili senza assegnare loro un valore iniziale, quindi il nome della variabile esiste nello scope esterno. A prima vista, questo potrebbe sembrare in conflitto con il fatto che Rust non abbia valori null. Tuttavia, se proviamo a utilizzare una variabile prima di assegnarle un valore, otterremo un errore in fase di compilazione, il che dimostra che Rust in effetti non ammette valori null.
Lo scope esterno dichiara una variabile denominata r senza valore iniziale,
mentre lo scope interno dichiara una variabile denominata x con valore
iniziale 5. Nello scope interno, proviamo a impostare il valore di r come
reference a x. Quindi lo scope interno termina e proviamo a stampare il
valore in r. Questo codice non verrà compilato perché il valore a cui fa
riferimento r è uscito dallo scope prima che proviamo ad utilizzarlo. Ecco
il messaggio di errore:
$ cargo run
Compiling capitolo10 v0.1.0 (file:///progetti/capitolo10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `capitolo10` (bin "capitolo10") due to 1 previous error
Il messaggio di errore indica che la variabile x “non vive abbastanza a
lungo”. Il motivo è che x sarà fuori dallo scope quando lo scope interno
termina alla riga 7. Ma r è ancora valido per lo scope esterno; Poiché il
suo scope è più ampio, diciamo che “vive più a lungo”. Se Rust permettesse a
questo codice di funzionare, r farebbe riferimento alla memoria de-allocata
quando x è uscita dallo scope, e qualsiasi cosa provassimo a fare con r
non funzionerebbe correttamente. Quindi, come fa Rust a determinare che questo
codice non è valido? Utilizza un borrow checker.
Il Borrow Checker
Il compilatore Rust ha un borrow checker (controllore dei prestiti) che confronta gli scope per determinare se tutti i dati presi in prestito tramite reference sono validi. Il Listato 10-17 mostra lo stesso codice del Listato 10-16 ma con annotazioni che mostrano la longevità delle variabili.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+r e x, denominate rispettivamente 'a e 'bQui abbiamo annotato la lifetime di r con 'a e la lifetime di x con
'b. Come puoi vedere, il blocco 'b interno è molto più piccolo del blocco
'a esterno. In fase di compilazione, Rust confronta la dimensione delle due
longevità e vede che r ha una lifetime 'a ma che si riferisce alla memoria
con una lifetime 'b. Il programma viene rifiutato perché 'b è più breve di
'a: il soggetto del reference non ha la stessa longevità del reference
stesso.
Il Listato 10-18 corregge il codice in modo che non abbia un reference pendente e si compili senza errori.
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {r}"); // | | // | | } // --+-------+
Qui, x ha la longevità 'b, che in questo caso è maggiore di 'a. Questo
significa che r può fare riferimento a x perché Rust sa che il reference
in r sarà sempre valido finché x è valido.
Ora che sai cosa sono le lifetime dei reference e come Rust analizza la longevità per garantire che i reference siano sempre validi, esploriamo le lifetime generiche dei parametri e dei valori di ritorno nel contesto delle funzioni.
Lifetime Generica nelle Funzioni
Scriveremo una funzione che restituisce la più lunga tra due slice di stringa.
Questa funzione prenderà due slice e ne restituirà una singola. Dopo aver
implementato la funzione più_lunga, il codice nel Listato 10-19 dovrebbe
stampare La stringa più lunga è abcd.
fn main() {
let stringa1 = String::from("abcd");
let stringa2 = "xyz";
let risultato = più_lunga(stringa1.as_str(), stringa2);
println!("La stringa più lunga è {}", risultato);
}main che chiama la funzione più_lunga per trovare la più lunga tra due sliceNota che vogliamo che la funzione accetti slice, che sono reference,
piuttosto che stringhe, perché non vogliamo che la funzione più_lunga prenda
possesso dei suoi parametri. Fai riferimento alla sezione “Slice di Stringa
come Parametri” del Capitolo 4 per
una disamina più approfondita sul motivo per cui i parametri che utilizziamo nel
Listato 10-19 sono quelli che desideriamo.
Se proviamo a implementare la funzione più_lunga come mostrato nel Listato
10-20, non verrà compilata.
fn main() {
let stringa1 = String::from("abcd");
let stringa2 = "xyz";
let risultato = più_lunga(stringa1.as_str(), stringa2);
println!("La stringa più lunga è {}", risultato);
}
fn più_lunga(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}più_lunga che restituisce la più lunga tra due stringhe ma non viene ancora compilataInvece, otteniamo il seguente errore che parla di lifetime:
$ cargo run
Compiling capitolo10 v0.1.0 (file:///projects/capitolo10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:35
|
9 | fn più_lunga(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn più_lunga<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `capitolo10` (bin "capitolo10") due to 1 previous error
Il testo di aiuto rivela che il type restituito necessita di un parametro di
lifetime generico perché Rust non riesce a stabilire se il reference
restituito si riferisce a x o y. In realtà, non lo sappiamo anche perché il
blocco if nel corpo di questa funzione restituisce un reference a x e il
blocco else restituisce un reference a y!
Quando definiamo questa funzione, non conosciamo i valori concreti che verranno
passati a questa funzione, quindi non sappiamo se verrà eseguito il caso if o
il caso else. Non conosciamo nemmeno la longevità concreta dei riferimenti che
verranno passati, quindi non possiamo esaminare gli scope come abbiamo fatto
nei Listati 10-17 e 10-18 per determinare se il reference restituito sarà
sempre valido. Nemmeno il borrow checker può determinarlo, perché non sa come
la longevità di x e y si relaziona alla longevità del valore di ritorno. Per
correggere questo errore, aggiungeremo parametri di lifetime generici che
definiscono la relazione tra i reference in modo che il borrow checker possa
eseguire la sua analisi.
Sintassi dell’Annotazione di Lifetime
Le annotazioni di lifetime non modificano la longevità di alcun reference. Piuttosto, descrivono e dettagliano le relazioni tra le longevità di più riferimenti senza andare a modificarla. Proprio come le funzioni possono accettare qualsiasi type quando la firma specifica un parametro di type generico, le funzioni possono accettare reference con qualsiasi longevità specificando un parametro di lifetime generico.
Le annotazioni di lifetime hanno una sintassi leggermente insolita: i nomi dei
parametri di lifetime devono iniziare con un apostrofo (') e sono
solitamente tutti in minuscolo e molto brevi, come i type generici. La maggior
parte delle persone usa il nome 'a per la prima annotazione di lifetime.
Posizioniamo le annotazioni dei parametri di lifetime dopo la & di un
reference, utilizzando uno spazio per separare l’annotazione dal type del
reference.
Ecco alcuni esempi:
&i32 // `reference` senza parametro di longevità
&'a i32 // `reference` con annotazione della longevità
&'a mut i32 // `reference` mutabile con annotazione della longevitàUn’annotazione di longevità di per sé non ha molto significato perché le
annotazioni servono a indicare a Rust come i parametri di lifetime generici di
più reference si relazionano tra loro. Esaminiamo come le annotazioni di
longevità si relazionano tra loro nel contesto della funzione più_lunga.
Nella Firma delle Funzioni
Per utilizzare le annotazioni di longevità nelle firme delle funzioni, dobbiamo dichiarare i parametri lifetime generici all’interno di parentesi angolari tra il nome della funzione e l’elenco dei parametri, proprio come abbiamo fatto con i parametri type generici.
Vogliamo che la firma esprima la seguente restrizione: il reference restituito
sarà valido finché entrambi i parametri saranno validi. Questa è la relazione
tra le lifetime dei parametri e il valore restituito. Chiameremo la lifetime
'a e la aggiungeremo a ciascun reference, come mostrato nel Listato 10-21.
fn main() { let stringa1 = String::from("abcd"); let stringa2 = "xyz"; let risultato = più_lunga(stringa1.as_str(), stringa2); println!("La stringa più lunga è {}", risultato); } fn più_lunga<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
più_lunga specifica che tutti i reference nella firma devono avere la stessa lifetime 'aQuesto codice dovrebbe compilarsi e produrre il risultato desiderato quando lo
utilizziamo con la funzione main del Listato 10-19.
La firma della funzione ora indica a Rust che per un certo lifetime 'a, la
funzione accetta due parametri, entrambi slice di stringa che durano almeno
quanto la lifetime 'a. La firma della funzione indica anche a Rust che la
slice di stringa restituita dalla funzione avrà una longevità massima pari al
lifetime 'a. In pratica, significa che la longevità del reference
restituito dalla funzione più_lunga è minore o uguale alla minore tra le
longevità dei valori a cui fanno riferimento gli argomenti della funzione.
Queste relazioni sono ciò che vogliamo che Rust utilizzi quando analizza questo
codice.
Ricorda, quando specifichiamo i parametri di longevità nella firma di questa
funzione, non stiamo modificando le longevità dei valori passati o restituiti.
Piuttosto, stiamo specificando che il borrow checker deve rifiutare qualsiasi
valore che non rispetta questi vincoli. Nota che la funzione più_lunga non ha
bisogno di sapere esattamente quanto dureranno x e y, ma solo che esiste uno
scope che può essere sostituito ad 'a che soddisfi questa firma.
Quando si annotano le longevità nelle funzioni, le annotazioni vanno nella firma della funzione, non nel corpo della funzione. Le annotazioni di lifetime diventano parte del contratto della funzione, proprio come i type nella firma. Avere le firme delle funzioni che contengono il contratto di longevità significa che l’analisi effettuata dal compilatore Rust può essere più semplice. Se c’è un problema con il modo in cui una funzione è annotata o con il modo in cui viene chiamata, gli errori del compilatore possono indicare la parte del nostro codice e le restrizioni in modo più preciso. Se, invece, il compilatore Rust facesse più inferenze su ciò che intendevamo che fossero le relazioni tra le longevità, il compilatore potrebbe essere in grado di indicare solo un utilizzo del nostro codice molto lontano dalla causa del problema.
Quando passiamo reference concreti a più_lunga, la longevità concreta che
viene sostituita per 'a è la parte dello scope di x che si sovrappone allo
scope di y. In altre parole, la longevità generica 'a otterrà la longevità
concreta uguale alla minore tra le longevità di x e y. Poiché abbiamo
annotato il reference restituito con lo stesso parametro di longevità 'a, il
reference restituito sarà valido anche per la lunghezza della minore tra la
longevità di x e y.
Osserviamo come le annotazioni di longevità limitino la funzione più_lunga dal
ricevere reference con longevità concrete diverse. Il Listato 10-22 è un
esempio semplice.
fn main() { let stringa1 = String::from("una stringa bella lunga"); { let stringa2 = String::from("xyz"); let risultato = più_lunga(stringa1.as_str(), stringa2.as_str()); println!("La stringa più lunga è {risultato}"); } } fn più_lunga<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
più_lunga con reference a valori String con longevità concrete diverseIn questo esempio, stringa1 è valida fino alla fine dello scope esterno,
stringa2 è valida fino alla fine dello scope interno e risultato fa
riferimento a qualcosa che è valido fino alla fine dello scope interno. Esegui
questo codice e vedrai che verrà approvato dal borrow checker; compilerà e
stamperà La stringa più lunga è una stringa bella lunga.
Proviamo ora un esempio che mostra come la lifetime del reference in
risultato deve essere la lifetime più breve tra i due argomenti. Sposteremo
la dichiarazione della variabile risultato al di fuori dello scope interno,
ma lasceremo l’assegnazione del valore alla variabile risultato all’interno
dello scope con stringa2. Quindi sposteremo println! che utilizza
risultato al di fuori dello scope interno, dopo che quest’ultimo è
terminato. Il codice nel Listato 10-23 non verrà compilato.
fn main() {
let stringa1 = String::from("una stringa bella lunga");
let risultato;
{
let stringa2 = String::from("xyz");
risultato = più_lunga(stringa1.as_str(), stringa2.as_str());
}
println!("La stringa più lunga è {risultato}");
}
fn più_lunga<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}risultato dopo che stringa2 è uscita dallo scopeQuando proviamo a compilare questo codice, otteniamo questo errore:
$ cargo run
Compiling capitolo10 v0.1.0 (file:///projects/capitolo10)
error[E0597]: `stringa2` does not live long enough
--> src/main.rs:6:50
|
5 | let stringa2 = String::from("xyz");
| -------- binding `stringa2` declared here
6 | risultato = più_lunga(stringa1.as_str(), stringa2.as_str());
| ^^^^^^^^ borrowed value does not live long enough
7 | }
| - `stringa2` dropped here while still borrowed
8 | println!("La stringa più lunga è {risultato}");
| --------- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `capitolo10` (bin "capitolo10") due to 1 previous error
L’errore indica che, affinché risultato sia valido per l’istruzione
println!, stringa2 dovrebbe essere valido fino alla fine dello scope
esterno. Rust lo sa perché abbiamo annotato le lifetime dei parametri della
funzione e del valore di ritorno utilizzando lo stesso parametro 'a.
Come esseri umani, possiamo guardare questo codice e vedere che stringa1 è più
lungo di stringa2 e, pertanto, risultato conterrà un reference a
stringa1. Poiché stringa1 non è ancora uscito dallo scope, un reference
a stringa1 sarà ancora valido per l’istruzione println!. Tuttavia, il
compilatore non può verificare che il reference sia valido in questo caso.
Abbiamo detto a Rust che la lifetime del reference restituito dalla funzione
più_lunga è uguale alla più breve tra le lifetime dei riferimenti passati.
Pertanto, il borrow checker non consente il codice nel Listato 10-23 in quanto
potrebbe contenere un reference non valido.
Prova a progettare altri esperimenti che varino i valori e le lifetime dei
reference passati alla funzione più_lunga e il modo in cui il reference
restituito viene utilizzato. Formula ipotesi sul fatto che questi esperimenti
supereranno o meno il borrow checker prima di compilare; poi verifica se avevi
ragione!
Relazioni
Il modo in cui è necessario specificare i parametri di longevità dipende da cosa
sta facendo la tua funzione. Ad esempio, se modificassimo l’implementazione
della funzione più_lunga in modo che restituisca sempre il primo parametro
anziché la slice di stringa più lunga, non avremmo bisogno di specificare una
lifetime per il parametro y. Il codice seguente verrà compilato:
fn main() { let stringa1 = String::from("abcd"); let stringa2 = "efghijklmnopqrstuvwxyz"; let risultato = più_lunga(stringa1.as_str(), stringa2); println!("La stringa più lunga è {risultato}"); } fn più_lunga<'a>(x: &'a str, y: &str) -> &'a str { x }
Abbiamo specificato un parametro di longevità 'a per il parametro x e il
type di ritorno, ma non per il parametro y, perché la lifetime di y non
ha alcuna relazione con la lifetime di x o con il valore di ritorno.
Quando si restituisce un reference da una funzione, il parametro di longevità
per il type di ritorno deve corrispondere al parametro di longevità per uno
dei parametri. Se il reference restituito non fa riferimento ad uno dei
parametri, deve fare riferimento ad un valore creato all’interno di questa
funzione. Tuttavia, questo sarebbe un reference pendente perché il valore
uscirà dallo scope al termine della funzione. Considera questo tentativo di
implementazione della funzione più_lunga che non verrà compilato:
fn main() {
let stringa1 = String::from("abcd");
let stringa2 = "xyz";
let risultato = più_lunga(stringa1.as_str(), stringa2);
println!("La stringa più lunga è {risultato}");
}
fn più_lunga<'a>(x: &str, y: &str) -> &'a str {
let risultato = String::from("una stringa bella lunga");
risultato.as_str()
}Qui, anche se abbiamo specificato un parametro di longevità 'a per il type
di ritorno, questa implementazione non verrà compilata perché la lifetime del
valore di ritorno non è affatto correlata alla lifetime dei parametri. Ecco il
messaggio di errore che riceviamo:
$ cargo run
Compiling capitolo10 v0.1.0 (file:///progetti/capitolo10)
error[E0515]: cannot return value referencing local variable `risultato`
--> src/main.rs:11:5
|
11 | risultato.as_str()
| ---------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `risultato` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `capitolo10` (bin "capitolo10") due to 1 previous error; 2 warnings emitted
Il problema è che risultato esce dallo scope e viene de-allocato alla fine
della funzione più_lunga. Stiamo anche cercando di restituire un reference a
risultato dalla funzione. Non c’è modo di specificare parametri di longevità
che modifichino il reference pendente, e Rust non ci permette di creare un
reference pendente. In questo caso, la soluzione migliore sarebbe restituire
un type piuttosto che un reference, in modo che la funzione chiamante sia
responsabile della de-allocazione del valore.
In definitiva, la sintassi di longevità serve a collegare le lifetime dei vari parametri e valori di ritorno delle funzioni. Una volta messi in relazione, Rust ha informazioni sufficienti per consentire operazioni che proteggono la memoria e impedire operazioni che creerebbero reference pendenti o comunque violerebbero la sicurezza della memoria.
Nella Definizione delle Struct
Finora, tutte le struct che abbiamo definito contenevano type con
ownership. Possiamo definire struct che contengano reference, ma in tal
caso dovremmo aggiungere un’annotazione di longevità su ogni reference nella
definizione della struct. Il Listato 10-24 ha una struct denominata
ParteImportante che contiene una slice di stringa.
struct ParteImportante<'a> { parte: &'a str, } fn main() { let romanzo = String::from("Chiamami Ishmael. Alcuni anni fa..."); let prima_frase = romanzo.split('.').next().unwrap(); let i = ParteImportante { parte: prima_frase, }; }
Questa struct ha il singolo campo parte che contiene una slice di stringa,
che è un reference. Come per i type generici, dichiariamo il nome del
parametro lifetime generico tra parentesi angolari dopo il nome della
struct, in modo da poter utilizzare il parametro lifetime nel corpo della
definizione della struct. Questa annotazione significa che un’istanza di
ParteImportante avrà una longevità non superiore a quella del reference che
contiene nel suo campo parte.
La funzione main qui crea un’istanza della struct ParteImportante che
contiene un reference alla prima frase della String di proprietà della
variabile romanzo. I dati in romanzo esistono prima che l’istanza di
ParteImportante venga creata. Inoltre, romanzo non esce dallo scope finché
anche ParteImportante non esce dallo scope, quindi il reference
nell’istanza di ParteImportante è valido.
Elidere la Lifetime
Hai imparato che ogni reference ha una lifetime e che è necessario specificare parametri di longevità per funzioni o struct che utilizzano reference. Tuttavia, avevamo una funzione nel Listato 4-9, mostrata di nuovo nel Listato 10-25, che veniva compilata senza annotazioni di longevità.
fn prima_parola(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &lettera) in bytes.iter().enumerate() { if lettera == b' ' { return &s[0..i]; } } &s[..] } fn main() { let mia_stringa = String::from("hello world"); // `prima_parola` funziona con slice di `String` let parola = prima_parola(&mia_stringa[..]); let mia_stringa_letterale = "hello world"; // `prima_parola` funziona con slice di letterali di stringa let parola_letterale = prima_parola(&mia_stringa_letterale[..]); // E siccome i letterali di stringa *sono* già delle slice, // funziona pure così, senza usare la sintassi delle slice! let parola = prima_parola(mia_stringa_letterale); }
Il motivo per cui questa funzione viene compilata senza annotazioni di longevità è storico: nelle prime versioni (precedenti alla 1.0) di Rust, questo codice non sarebbe stato compilato perché ogni reference necessitava di una lifetime esplicita. A quel tempo, la firma della funzione sarebbe stata scritta in questo modo:
fn prima_parola<'a>(s: &'a str) -> &'a str {Dopo aver scritto molto codice Rust, il team Rust ha scoperto che i programmatori Rust inserivano le stesse annotazioni di longevità più e più volte in particolari situazioni. Queste situazioni erano prevedibili e seguivano alcuni schemi deterministici. Gli sviluppatori hanno programmato questi schemi nel codice del compilatore in modo che il borrow checker potesse dedurre le lifetime in queste situazioni e non avesse bisogno di annotazioni esplicite.
Questo pezzo di storia di Rust è rilevante perché è possibile che emergano e vengano aggiunti al compilatore altri schemi deterministici. In futuro, potrebbero essere necessarie ancora meno annotazioni di longevità.
Gli schemi programmati nell’analisi dei riferimenti di Rust sono chiamati regole di elisione della longevità (lifetime elision rules). Queste non sono regole che i programmatori devono seguire; sono un insieme di casi particolari che il compilatore prenderà in considerazione e, se il codice si adatta a questi casi, non sarà necessario esplicitare le lifetime.
Le regole di elisione non forniscono un’inferenza completa. Se persiste un’ambiguità sulle lifetime dei reference dopo che Rust ha applicato le regole, il compilatore non inferirà quale dovrebbe essere la longevità dei reference rimanenti. E quindi, invece di indovinare, il compilatore genererà un errore indicando dove è necessario aggiungere le annotazioni di longevità.
Le longevità dei parametri di funzione o metodo sono chiamate lifetime di input, e le longevità dei valori di ritorno sono chiamate lifetime di output.
Il compilatore utilizza tre regole per calcolare le lifetime dei reference
quando non ci sono annotazioni esplicite. La prima regola si applica ai
lifetime di input, mentre la seconda e la terza regola si applicano ai
lifetime di output. Se il compilatore arriva alla fine delle tre regole e ci
sono ancora reference per i quali non riesce a calcolare la longevità, il
compilatore si interromperà con un errore. Queste regole si applicano sia alle
definizioni fn che ai blocchi impl.
La prima regola è che il compilatore assegna un parametro di lifetime a ogni
parametro che è un reference. In altre parole, una funzione con un parametro
riceve un parametro di lifetime: fn foo<'a>(x: &'a i32); una funzione con
due parametri riceve due parametri di lifetime separati: fn foo<'a, 'b>(x: &'a i32, y: &'b i32); e così via.
La seconda regola è che, se c’è esattamente un parametro di lifetime in input,
quel lifetime viene assegnato a tutti i parametri di lifetime in output: fn foo<'a>(x: &'a i32) -> &'a i32.
La terza regola è che, se ci sono più parametri di lifetime in input, ma uno
di questi è &self o &mut self perché si tratta di un metodo, la lifetime
di self viene assegnata a tutti i parametri di lifetime in output. Questa
terza regola rende i metodi molto più facili da leggere e scrivere perché sono
necessari meno simboli.
Facciamo finta di essere il compilatore. Applicheremo queste regole per
calcolare le longevità dei reference nella firma della funzione prima_parola
nel Listato 10-25. La firma inizia senza alcuna lifetime associata ai
reference:
fn prima_parola(s: &str) -> &str {Quindi il compilatore applica la prima regola, che specifica che ogni parametro
abbia una propria longevità. La chiameremo 'a come al solito, quindi ora la
firma è questa:
fn prima_parola<'a>(s: &'a str) -> &str {La seconda regola si applica perché esiste esattamente un singolo parametro di longevità in input. La seconda regola specifica che la longevità di un parametro in input viene assegnata alla longevità in output, quindi la firma è ora questa:
fn prima_parola<'a>(s: &'a str) -> &'a str {Ora tutti i reference in questa firma di funzione hanno una longevità e il compilatore può continuare la sua analisi senza che il programmatore debba annotare le lifetime in questa firma di funzione.
Diamo un’occhiata a un altro esempio, questa volta utilizzando la funzione
più_lunga che non aveva parametri di longevità quando abbiamo iniziato a
lavorarci nel Listato 10-20:
fn più_lunga(x: &str, y: &str) -> &str {Applichiamo la prima regola: ogni parametro ha la propria longevità. Questa volta abbiamo due parametri invece di uno, quindi abbiamo due lifetime:
fn più_lunga<'a, 'b>(x: &'a str, y: &'b str) -> &str {Puoi già notare che la seconda regola non si applica perché c’è più di una
lifetime di input. Nemmeno la terza regola si applica, perché più_lunga è
una funzione e non un metodo, quindi nessuno dei parametri è self. Dopo aver
elaborato tutte e tre le regole, non abbiamo ancora capito qual è la longevità
del type di ritorno. Ecco perché abbiamo ricevuto un errore durante la
compilazione del codice nel Listato 10-20: il compilatore ha elaborato le regole
di elisione della lifetime, ma non è comunque riuscito a calcolare tutte le
lifetime dei reference nella firma.
Poiché la terza regola si applica solo alle firme dei metodi, esamineremo le lifetime in quel contesto per capire perché la terza regola ci consente di non dover annotare la longevità nelle firme dei metodi nella maggior parte dei casi.
Nella Definizione dei Metodi
Quando implementiamo metodi su una struct con lifetime, utilizziamo la stessa sintassi dei parametri di type generico, come mostrato nel Listato 10-11. Il punto in cui dichiariamo e utilizziamo i parametri di longevità dipende dal fatto che siano correlati ai campi della struct o ai parametri del metodo e ai valori di ritorno.
I nomi delle lifetime per i campi della struct devono sempre essere
dichiarati dopo la parola chiave impl e quindi utilizzati dopo il nome della
struct, poiché tali lifetime fanno parte del type della struct.
Nelle firme dei metodi all’interno del blocco impl, i reference potrebbero
essere legati alla longevità dei reference nei campi della struct, oppure
potrebbero essere indipendenti. Inoltre, le regole di elisione della lifetime
spesso fanno sì che le annotazioni della longevità non siano necessarie nelle
firme dei metodi. Diamo un’occhiata ad alcuni esempi utilizzando la struct
denominata ParteImportante che abbiamo definito nel Listato 10-24.
Per prima cosa useremo un metodo chiamato livello il cui unico parametro è un
reference a self e il cui valore di ritorno è un i32, che non è un
reference ad alcunché:
struct ParteImportante<'a> { parte: &'a str, } impl<'a> ParteImportante<'a> { fn livello(&self) -> i32 { 3 } } impl<'a> ParteImportante<'a> { fn annunciare_e_restituire_parte(&self, annuncio: &str) -> &str { println!("Attenzione per favore: {annuncio}"); self.parte } } fn main() { let romanzo = String::from("Chiamami Ishmael. Qualche anno fa..."); let prima_frase = romanzo.split('.').next().unwrap(); let i = ParteImportante { parte: prima_frase, }; }
La dichiarazione del parametro lifetime dopo impl e il suo utilizzo dopo il
nome del type sono obbligatori ma, grazie alla prima regola di elisione, non
siamo tenuti ad annotare la longevità del reference a self.
Ecco un esempio in cui si applica la terza regola di elisione della lifetime:
struct ParteImportante<'a> { parte: &'a str, } impl<'a> ParteImportante<'a> { fn livello(&self) -> i32 { 3 } } impl<'a> ParteImportante<'a> { fn annunciare_e_restituire_parte(&self, annuncio: &str) -> &str { println!("Attenzione per favore: {annuncio}"); self.parte } } fn main() { let romanzo = String::from("Chiamami Ishmael. Qualche anno fa..."); let prima_frase = romanzo.split('.').next().unwrap(); let i = ParteImportante { parte: prima_frase, }; }
Ci sono due lifetime in input, quindi Rust applica la prima regola di elisione
della lifetime e assegna sia a &self che a annuncio le corrispettive
lifetime. Quindi, poiché uno dei parametri è &self, al type di ritorno
viene assegnata la lifetime di &self. Ora tutte le lifetime sono state
considerate.
La Lifetime Statica
Una lifetime speciale di cui dobbiamo discutere è 'static, che indica che la
longevità del reference interessato corrisponde a quella del programma. Tutti
i letterali stringa hanno la lifetime 'static, che possiamo annotare come
segue:
#![allow(unused)] fn main() { let s: &'static str = "Ho una lifetime statica."; }
Il testo di questa stringa è memorizzato direttamente nel binario del programma,
che è sempre disponibile. Pertanto, la longevità di tutti i letterali stringa è
'static.
Potresti trovare suggerimenti nei messaggi di errore del compilatore di
utilizzare la lifetime 'static. Ma prima di specificare 'static come
lifetime per un reference, valuta se quel reference ha effettivamente
necessità di rimanere valido per l’intera durata dell’esecuzione del tuo
programma. Nella maggior parte dei casi, un messaggio di errore che suggerisce
la lifetime 'static deriva dal tentativo di creare un reference pendente o
da una mancata corrispondenza delle longevità disponibili. In questi casi, la
soluzione è risolvere questi problemi, non specificare la lifetime 'static.
Parametri di Type Generico, Vincoli del Trait e Lifetime
Esaminiamo brevemente la sintassi per specificare parametri di type generico, vincoli di trait e lifetime, tutto in un’unica funzione!
fn main() { let stringa1 = String::from("abcd"); let stringa2 = "xyz"; let risultato = più_lunga_con_annuncio( stringa1.as_str(), stringa2, "Oggi è il compleanno di qualcuno!", ); println!("La stringa più lunga è {risultato}"); } use std::fmt::Display; fn più_lunga_con_annuncio<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Annuncio! {ann}"); if x.len() > y.len() { x } else { y } }
Questa è la funzione più_lunga del Listato 10-21 che restituisce la più lunga
tra due slice. Ma ora ha un parametro aggiuntivo denominato ann di type
generico T, che può ricevere qualsiasi type che implementi il trait
Display come specificato dalla clausola where. Questo parametro aggiuntivo
verrà stampato utilizzando {}, motivo per cui il vincolo del trait Display
è necessario. Poiché le lifetime sono un type generico, le dichiarazioni del
parametro di longevità 'a e del parametro di type generico T vanno nella
stessa lista all’interno delle parentesi angolari dopo il nome della funzione.
Riepilogo
Abbiamo trattato molti argomenti in questo capitolo! Ora che conosci i parametri di type generico, i trait, i vincoli dei trait e i parametri di lifetime generici, sei pronto a scrivere codice senza ripetizioni che funzioni in molte situazioni diverse. I parametri di type generico consentono di applicare il codice a type diversi. I trait e i vincoli dei trait garantiscono che, anche se i type sono generici, abbiano il comportamento di cui il codice ha bisogno. Hai imparato come usare le annotazioni di longevità per garantire che questo codice flessibile non abbia reference pendenti. E tutta questa analisi avviene in fase di compilazione, il che non influisce sulle prestazioni in fase di esecuzione!
Che ci crediate o no, c’è molto altro da imparare sugli argomenti trattati in questo capitolo: il Capitolo 18 tratta degli oggetti trait, che rappresentano un altro modo di utilizzare i trait. Esistono anche scenari più complessi che coinvolgono le annotazioni della lifetime, che ti serviranno solo in scenari molto avanzati; se ti può interessare dovresti leggere The Rust Reference (in inglese). Ma ora imparerai come scrivere test in Rust in modo da poterti assicurare che il tuo codice funzioni a dovere.
Scrivere Test Automatizzati
Nel suo saggio del 1972 “The Humble Programmer”, Edsger W. Dijkstra ha affermato che “il testing dei programmi può essere un modo molto efficace per mostrare la presenza di bug, ma è irrimediabilmente inadeguato per mostrarne l’assenza.” Questo non significa che non dovremmo cercare di testare il più possibile!
La correttezza dei nostri programmi è la misura in cui il nostro codice fa ciò che intendiamo fare. Rust è stato progettato con un alto grado di preoccupazione per la correttezza dei programmi, ma la correttezza è complessa e non facile da dimostrare. Il sistema dei type di Rust si fa carico di gran parte di questo onere, ma il sistema dei type non può catturare tutto. Per questo motivo, Rust include un supporto per la scrittura di test software automatizzati.
Immaginiamo di scrivere una funzione aggiungi_due che aggiunge 2 a qualsiasi
numero le venga passato. La firma di questa funzione accetta un intero come
parametro e restituisce un intero come risultato. Quando implementiamo e
compiliamo questa funzione, Rust esegue tutti i controlli di type e di
prestito (borrow) che hai imparato finora per assicurarsi che, ad esempio, non
stiamo passando un valore String o un reference non valido a questa
funzione. Ma Rust non può controllare che questa funzione faccia esattamente
ciò che intendiamo, cioè restituire il parametro più 2 piuttosto che, ad
esempio, il parametro più 10 o il parametro meno 50! È qui che entrano in gioco
i test.
Possiamo scrivere dei test che verificano, ad esempio, che quando passiamo 3
alla funzione aggiungi_due, il valore restituito sia 5. Possiamo eseguire
questi test ogni volta che apportiamo delle modifiche al nostro codice per
assicurarci che il comportamento corretto esistente non sia cambiato.
Il testing è un’abilità complessa: anche se non possiamo trattare in un solo capitolo tutti i dettagli su come scrivere dei buoni test, in questo capitolo parleremo dei meccanismi delle strutture di test di Rust. Parleremo delle annotazioni e delle macro a tua disposizione quando scrivi i tuoi test, del comportamento predefinito e delle opzioni fornite per l’esecuzione dei tuoi test e di come organizzare i test in unità di test e test di integrazione.
Come Scrivere dei Test
I test sono funzioni di Rust che verificano che il codice non di test funzioni nel modo previsto. I corpi delle funzioni di test eseguono tipicamente queste tre azioni:
- Impostare i dati o lo stato necessari.
- Eseguire il codice che si desidera testare.
- Verificare che i risultati siano quelli attesi.
Vediamo le funzionalità che Rust mette a disposizione specificamente per
scrivere test che eseguono queste azioni, come l’attributo test, alcune macro
e l’attributo should_panic.
Strutturare le Funzioni di Test
Nella sua forma più semplice, un test in Rust è una funzione annotata con
l’attributo test. Gli attributi sono metadati relativi a pezzi di codice Rust;
un esempio è l’attributo derive che abbiamo usato con le struct nel Capitolo
5. Per trasformare una funzione in una funzione di test, aggiungi #[test]
nella riga prima di fn. Quando esegui i tuoi test con il comando cargo test,
Rust costruisce un eseguibile di test che esegue le funzioni annotate e riporta
se ogni funzione di test passa o fallisce.
Ogni volta che creiamo un nuovo progetto di libreria con Cargo, viene generato automaticamente un modulo di test con una funzione di test al suo interno. Questo modulo ti fornisce un modello per scrivere i tuoi test, in modo da non dover cercare la struttura e la sintassi esatta ogni volta che inizi un nuovo progetto. Puoi aggiungere tutte le funzioni di test e tutti i moduli di test che vuoi!
Esploreremo alcuni aspetti del funzionamento dei test sperimentando con il test predefinito prima di testare effettivamente il codice. Poi scriveremo alcuni test reali che richiamano il codice che abbiamo scritto e verificano che il suo comportamento sia corretto.
Creiamo un nuovo progetto di libreria chiamato addizione che aggiungerà due
numeri:
$ cargo new addizione --lib
Created library `addizione` project
$ cd addizione
Il contenuto del file src/lib.rs della tua libreria addizione dovrebbe
essere come il Listato 11-1.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}cargo newIl file inizia con un esempio di funzione add (aggiungi), in modo da avere
qualcosa da testare.
Per ora, concentriamoci solo sulla funzione it_works (funziona). Nota
l’annotazione #[test]: questo attributo indica che si tratta di una funzione
di test, in modo che il test runner sappia che deve trattare questa funzione
come un test. Potremmo anche avere funzioni non di test nel modulo tests per
aiutare a configurare scenari comuni o eseguire operazioni comuni, quindi
dobbiamo sempre indicare quali funzioni sono di test.
Il corpo della funzione di esempio utilizza la macro assert_eq! per verificare
che result, che contiene il risultato della chiamata a add con 2 e 2, sia
uguale a 4. Questa asserzione serve come esempio del formato di un test tipico.
Eseguiamola per vedere se il test passa.
Il comando cargo test esegue tutti i test del nostro progetto, come mostrato
nel Listato 11-2.
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.90s
Running unittests src/lib.rs (/target/debug/deps/addizione-943d072b5b568c79)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo ha compilato ed eseguito il test. Vediamo la riga running 1 test. La
riga successiva mostra il nome della funzione di test generata, chiamata
tests::it_works, e che il risultato dell’esecuzione di quel test è ok. Il
riepilogo complessivo test result: ok. significa che tutti i test sono
passati, e la parte che recita 1 passed; 0 failed tiene il conto del numero di
test che sono passati o falliti.
È possibile contrassegnare un test come da ignorare in modo che non venga
eseguito in una particolare istanza; ne parleremo nella sezione “Ignorare test
se non specificamente richiesti” più avanti in questo
capitolo. Poiché non l’abbiamo fatto qui, il riepilogo mostra 0 ignored.
Possiamo anche passare un argomento al comando cargo test per eseguire solo i
test il cui nome corrisponda a una stringa; questo si chiama filtraggio e lo
tratteremo nella sezione “Eseguire un sottoinsieme di test in base al
nome”. In questo caso non abbiamo filtrato i test in
esecuzione, quindi la fine del riepilogo mostra 0 filtered out.
La statistica 0 measured è per i test di benchmark che misurano le
prestazioni. I test di benchmark, al momento, sono disponibili solo nelle
nightly di Rust. Per saperne di più, consulta la documentazione sui test di
benchmark.
La parte successiva dell’output di test che inizia con Doc-tests addizione è
per i risultati di qualsiasi test sulla documentazione. Non abbiamo ancora test
sulla documentazione, ma Rust può compilare qualsiasi esempio di codice che
appare nella nostra documentazione. Questa funzione aiuta a mantenere
sincronizzata la documentazione e il codice! Parleremo di come scrivere test
sulla documentazione nella sezione “Commenti di documentazione come
test” del Capitolo 14. Per ora, ignoreremo
l’output Doc-tests.
Iniziamo a personalizzare il test in base alle nostre esigenze. Per prima cosa,
cambiamo il nome della funzione it_works, ad esempio esplorazione, in questo
modo:
File: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn esplorazione() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Esegui nuovamente cargo test. L’output ora mostra esplorazione invece di
it_works:
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.90s
Running unittests src/lib.rs (/target/debug/deps/addizione-943d072b5b568c79)
running 1 test
test tests::esplorazione ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ora aggiungeremo un altro test, ma questa volta faremo un test che fallisce! I
test falliscono quando qualcosa nella funzione di test va in panico. Ogni test
viene eseguito in un nuovo thread e quando il thread principale vede che un
thread di test fallisce, il test viene contrassegnato come fallito. Nel
Capitolo 9 abbiamo parlato di come il modo più semplice per mandare in panico un
programma sia quello di chiamare la macro panic!. Inserisci il nuovo test come
una funzione di nome un_altra, in modo che il tuo file src/lib.rs assuma
l’aspetto del Listato 11-3.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn esplorazione() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn un_altra() {
panic!("Fai fallire questo test");
}
}panic!Esegui di nuovo i test utilizzando cargo test. L’output dovrebbe assomigliare
al Listato 11-4, che mostra come il nostro test esplorazione sia passato e
un_altra sia fallito.
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.92s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 2 tests
test tests::esplorazione ... ok
test tests::un_altra ... FAILED
failures:
---- tests::un_altra stdout ----
thread 'tests::un_altra' (4763) panicked at src/lib.rs:17:9:
Fai fallire questo test
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::un_altra
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Al posto di ok, la riga test tests::un_altra mostra FAILED (fallito).
Tra i singoli risultati e il riepilogo compaiono due nuove sezioni: la prima
mostra il motivo dettagliato del fallimento di ogni test. In questo caso,
otteniamo il dettaglio che tests::un_altra ha fallito perché è andato in
panico con il messaggio Fai fallire questo test alla riga 17 del file
src/lib.rs. La sezione successiva elenca solo i nomi di tutti i test falliti,
il che è utile quando ci sono molti test e molti output dettagliati di test
falliti. Possiamo usare il nome di un test fallito per eseguire solo quel test e
più facilmente fare il debug del problema; parleremo più diffusamente dei modi
per eseguire i test nella sezione “Controllare come vengono eseguiti i
test”.
Alla fine viene visualizzata la riga di riepilogo: in generale, il risultato del
nostro test è FAILED. Abbiamo avuto un test superato e un test fallito.
Ora che hai visto come appaiono i risultati dei test in diversi scenari, vediamo
alcune macro diverse da panic! che sono utili nei test.
Verificare i Risultati Con assert!
La macro assert!, fornita dalla libreria standard, è utile quando vuoi
assicurarti che una condizione in un test risulti essere vera, true. Diamo
alla macro assert! un argomento che valuta in un booleano. Se il valore è
true, non succede nulla e il test passa. Se il valore è false, la macro
assert! chiama panic! per far fallire il test. L’uso della macro assert!
ci aiuta a verificare che il nostro codice funzioni nel modo in cui intendiamo.
Nel Listato 5-15 del Capitolo 5 abbiamo utilizzato una struct Rettangolo e
un metodo può_contenere, che sono ripetuti qui nel Listato 11-5. Inseriamo
questo codice nel file src/lib.rs e scriviamo alcuni test utilizzando la macro
assert!.
#[derive(Debug)]
struct Rettangolo {
larghezza: u32,
altezza: u32,
}
impl Rettangolo {
fn può_contenere(&self, altro: &Rettangolo) -> bool {
self.larghezza > altro.larghezza && self.altezza > altro.altezza
}
}Rettangolo e il suo metodo può_contenere del Capitolo 5Il metodo può_contenere restituisce un booleano, il che significa che è un
caso d’uso perfetto per la macro assert!. Nel Listato 11-6, scriviamo un test
che utilizza il metodo può_contenere creando un’istanza di Rettangolo che ha
una larghezza di 8 e un’altezza di 7 e affermando che può contenere un’altra
istanza di Rettangolo che ha una larghezza di 5 e un’altezza di 1.
#[derive(Debug)]
struct Rettangolo {
larghezza: u32,
altezza: u32,
}
impl Rettangolo {
fn può_contenere(&self, altro: &Rettangolo) -> bool {
self.larghezza > altro.larghezza && self.altezza > altro.altezza
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn grande_contiene_piccolo() {
let grande = Rettangolo {
larghezza: 8,
altezza: 7,
};
let piccolo = Rettangolo {
larghezza: 5,
altezza: 1,
};
assert!(grande.può_contenere(&piccolo));
}
}può_contenere che verifica se un rettangolo più grande può effettivamente contenere un rettangolo più piccoloNota la riga use super::*; all’interno del modulo tests. Il modulo tests è
un modulo normale che segue le solite regole di visibilità che abbiamo trattato
nella sezione “Percorsi per Fare Riferimento a un Elemento nell’Albero dei
Moduli” del
Capitolo 7. Poiché il modulo tests è un modulo interno, dobbiamo portare il
codice del modulo esterno che vogliamo testare nello scope del modulo interno.
Usiamo un glob in questo caso, in modo che tutto ciò che definiamo nel modulo
esterno sia disponibile per questo modulo tests.
Abbiamo chiamato il nostro test grande_contiene_piccolo e abbiamo creato le
due istanze di Rettangolo di cui abbiamo bisogno. Poi abbiamo chiamato la
macro assert! e le abbiamo passato il risultato della chiamata
grande.può_contenere(&piccolo). Questa espressione dovrebbe restituire true,
quindi il nostro test dovrebbe passare. Scopriamolo!
$ cargo test
Compiling rettangolo v0.1.0 (file:///progetti/rettangolo)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.33s
Running unittests src/lib.rs (target/debug/deps/rettangolo-f3dbc7f03c0e31f1)
running 1 test
test tests::grande_contiene_piccolo ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rettangolo
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Passa davvero! Aggiungiamo un altro test, questa volta per verificare che un rettangolo più piccolo non può contenere un rettangolo più grande:
File: src/lib.rs
#[derive(Debug)]
struct Rettangolo {
larghezza: u32,
altezza: u32,
}
impl Rettangolo {
fn può_contenere(&self, altro: &Rettangolo) -> bool {
self.larghezza > altro.larghezza && self.altezza > altro.altezza
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn grande_contiene_piccolo() {
// --taglio--
let grande = Rettangolo {
larghezza: 8,
altezza: 7,
};
let piccolo = Rettangolo {
larghezza: 5,
altezza: 1,
};
assert!(grande.può_contenere(&piccolo));
}
#[test]
fn piccolo_non_contiene_grande() {
let grande = Rettangolo {
larghezza: 8,
altezza: 7,
};
let piccolo = Rettangolo {
larghezza: 5,
altezza: 1,
};
assert!(!piccolo.può_contenere(&grande));
}
}Poiché il risultato corretto della funzione può_contenere in questo caso è
false, dobbiamo negare questo risultato prima di passarlo alla macro
assert!. Di conseguenza, il nostro test passerà se può_contenere restituisce
false:
$ cargo test
Compiling rettangolo v0.1.0 (file:///progetti/rettangolo)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.32s
Running unittests src/lib.rs (target/debug/deps/rettangolo-f3dbc7f03c0e31f1)
running 2 tests
test tests::grande_contiene_piccolo ... ok
test tests::piccolo_non_contiene_grande ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rettangolo
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Due test superati! Ora vediamo cosa succede ai risultati dei nostri test quando
introduciamo un bug nel nostro codice. Cambieremo l’implementazione del metodo
può_contenere sostituendo il segno maggiore (>) con il segno minore (<)
quando confronta le larghezze:
#[derive(Debug)]
struct Rettangolo {
larghezza: u32,
altezza: u32,
}
// --taglio--
impl Rettangolo {
fn può_contenere(&self, altro: &Rettangolo) -> bool {
self.larghezza < altro.larghezza && self.altezza > altro.altezza
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn grande_contiene_piccolo() {
let grande = Rettangolo {
larghezza: 8,
altezza: 7,
};
let piccolo = Rettangolo {
larghezza: 5,
altezza: 1,
};
assert!(grande.può_contenere(&piccolo));
}
#[test]
fn piccolo_non_contiene_grande() {
let grande = Rettangolo {
larghezza: 8,
altezza: 7,
};
let piccolo = Rettangolo {
larghezza: 5,
altezza: 1,
};
assert!(!piccolo.può_contenere(&grande));
}
}L’esecuzione dei test produce ora il seguente risultato:
$ cargo test
Compiling rettangolo v0.1.0 (file:///progetti/rettangolo)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.32s
Running unittests src/lib.rs (target/debug/deps/rettangolo-f3dbc7f03c0e31f1)
running 2 tests
test tests::grande_contiene_piccolo ... FAILED
test tests::piccolo_non_contiene_grande ... ok
failures:
---- tests::grande_contiene_piccolo stdout ----
thread 'tests::grande_contiene_piccolo' (6902) panicked at src/lib.rs:31:9:
assertion failed: grande.può_contenere(&piccolo)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::grande_contiene_piccolo
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Poiché grande.larghezza è 8 e piccolo.larghezza è 5, il confronto delle
larghezze in può_contenere ora restituisce false: 8 non è inferiore a 5.
Testare l’Uguaglianza Con assert_eq! e assert_ne!
Un modo comune per verificare le funzionalità è quello di testare l’uguaglianza
tra il risultato del codice in esame e il valore che ti aspetti che il codice
restituisca. Potresti farlo utilizzando la macro assert! e passandole
un’espressione con l’operatore ==. Tuttavia, questo è un test così comune che
la libreria standard fornisce una coppia di macro, assert_eq! e assert_ne!,
per eseguire questo test in modo più conveniente. Queste macro confrontano due
argomenti per l’uguaglianza o l’ineguaglianza, rispettivamente. Inoltre,
stampano i due valori se l’asserzione fallisce, il che rende più facile vedere
il perché il test è fallito; al contrario, la macro assert! indica solo che
ha ottenuto un valore false per l’espressione ==, senza stampare i valori
che hanno portato al valore false.
Nel Listato 11-7, scriviamo una funzione chiamata aggiungi_due che aggiunge
2 al suo parametro, e poi testiamo questa funzione usando la macro
assert_eq!
pub fn aggiungi_due(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn aggiungere_due() {
let risultato = aggiungi_due(2);
assert_eq!(risultato, 4);
}
}aggiungi_due utilizzando la macro assert_eq!Controlliamo che passi!
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.00s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 1 test
test tests::aggiungere_due ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Abbiamo creato una variabile chiamata risultato che contiene il risultato
della chiamata a aggiungi_due(2). Poi passiamo risultato e 4 come
argomenti alla macro assert_eq!. La riga di output per questo test è test tests::aggiungere_due ... ok, e il testo ok indica che il nostro test è
passato!
Introduciamo un bug nel nostro codice per vedere come appare assert_eq! quando
fallisce. Cambia l’implementazione della funzione aggiungi_due per aggiungere
invece 3:
pub fn aggiungi_due(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn aggiungere_due() {
let risultato = aggiungi_due(2);
assert_eq!(risultato, 4);
}
}Esegui nuovamente i test:
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.30s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 1 test
test tests::aggiungere_due ... FAILED
failures:
---- tests::aggiungere_due stdout ----
thread 'tests::aggiungere_due' (5229) panicked at src/lib.rs:14:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::aggiungere_due
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Il nostro test ha rilevato il bug! Il test tests::aggiungere_due è fallito e
il messaggio ci dice che l’asserzione fallita era left == right
(sinistra/destra) e quali sono i valori left e right. Questo messaggio
ci aiuta a iniziare il debug: l’argomento left, dove avevamo il risultato
della chiamata a aggiungi_due(2), era 5 ma l’argomento right era 4. Puoi
immaginarti quanto questo sia particolarmente utile quando abbiamo molti test in
corso.
Nota che in alcuni linguaggi e framework di test, i parametri delle funzioni di
asserzione di uguaglianza sono chiamati expected (atteso) e actual
(effettivo) e l’ordine in cui specifichiamo gli argomenti è importante.
Tuttavia, in Rust, sono chiamati left e right e l’ordine in cui
specifichiamo il valore che ci aspettiamo e il valore che il codice produce non
ha importanza. Potremmo scrivere l’asserzione in questo test come assert_eq!(4, risultato), che risulterebbe nello stesso messaggio di fallimento che mostra
assertion `left == right` failed.
La macro assert_ne! ha successo se i due valori che le diamo non sono uguali e
fallisce se sono uguali. Questa macro è molto utile nei casi in cui non siamo
sicuri di quale sarà il valore, ma sappiamo quale valore sicuramente non
dovrebbe essere. Ad esempio, se stiamo testando una funzione che ha la garanzia
di cambiare il suo input in qualche modo, ma il modo in cui l’input viene
cambiato dipende dal giorno della settimana in cui eseguiamo i test, la cosa
migliore da asserire potrebbe essere che l’output della funzione non è uguale
all’input.
Sotto la superficie, le macro assert_eq! e assert_ne! utilizzano
rispettivamente gli operatori == e !=. Quando le asserzioni falliscono,
queste macro stampano i loro argomenti utilizzando la formattazione di debug, il
che significa che i valori confrontati devono implementare i trait PartialEq
e Debug. Tutti i type primitivi e la maggior parte dei type della libreria
standard implementano questi trait. Per le struct e le enum che definisci
tu stesso, dovrai implementare PartialEq per asserire l’uguaglianza di tali
type. Dovrai anche implementare Debug per stampare i valori quando
l’asserzione fallisce. Poiché entrambi i trait sono derivabili, come
menzionato nel Listato 5-12 del Capitolo 5, questo è solitamente semplice come
aggiungere l’annotazione #[derive(PartialEq, Debug)] alla definizione della
struct o dell’enum. Vedi l’Appendice C, “Trait
Derivabili”, per ulteriori dettagli su questi
e altri trait derivabili.
Aggiungere Messaggi di Errore Personalizzati
Puoi anche aggiungere un messaggio personalizzato da stampare insieme al
messaggio di fallimento come argomenti opzionali alle macro assert!,
assert_eq! e assert_ne!. Qualsiasi argomento specificato dopo gli argomenti
obbligatori viene passato alla macro format! (di cui si parla in “Concatenare
con l’Operatore + o la Macro format!” nel
Capitolo 8), quindi puoi passare una stringa di formato che contenga dei
segnaposto {} e dei valori da inserire in quei segnaposto. I messaggi
personalizzati sono utili per documentare il significato di un’asserzione;
quando un test fallisce, avrai un’idea più precisa del problema del codice.
Ad esempio, supponiamo di avere una funzione che saluta le persone per nome e vogliamo verificare che il nome che passiamo nella funzione appaia nell’output:
File: src/lib.rs
pub fn saluto(nome: &str) -> String {
format!("Ciao {nome}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn saluto_contiene_nome() {
let risultato = saluto("Carol");
assert!(risultato.contains("Carol"));
}
}I requisiti per questo programma non sono ancora stati concordati e siamo
abbastanza sicuri che il testo Ciao all’inizio del saluto cambierà. Abbiamo
deciso di non dover aggiornare il test quando i requisiti cambiano, quindi
invece di verificare l’esatta uguaglianza con il valore restituito dalla
funzione saluto, asseriremo che l’output debba contenere il testo del
parametro di input.
Ora introduciamo un bug in questo codice cambiando saluto per non includere
nome e vedere come si presenta il fallimento del test:
pub fn saluto(nome: &str) -> String {
String::from("Ciao!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn saluto_contiene_nome() {
let risultato = saluto("Carol");
assert!(risultato.contains("Carol"));
}
}L’esecuzione di questo test produce il seguente risultato:
$ cargo test
Compiling saluto v0.1.0 (file:///progetti/saluto)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.15s
Running unittests src/lib.rs (target/debug/deps/saluto-9c4c14b7b4719873)
running 1 test
test tests::saluto_contiene_nome ... FAILED
failures:
---- tests::saluto_contiene_nome stdout ----
thread 'tests::saluto_contiene_nome' (10833) panicked at src/lib.rs:14:9:
assertion failed: risultato.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::saluto_contiene_nome
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Questo risultato indica solo che l’asserzione è fallita e su quale riga si trova
l’asserzione. Un messaggio di fallimento più utile stamperebbe il valore della
funzione saluto. Aggiungiamo un messaggio di fallimento personalizzato
composto da una stringa di formato con un segnaposto riempito con il valore
effettivo ottenuto dalla funzione saluto:
pub fn saluto(nome: &str) -> String {
String::from("Ciao!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn saluto_contiene_nome() {
let risultato = saluto("Carol");
assert!(
risultato.contains("Carol"),
"Saluto non contiene un nome, il valore era `{risultato}`"
);
}
}Ora, quando eseguiamo il test, otterremo un messaggio di errore più informativo:
$ cargo test
Compiling saluto v0.1.0 (file:///progetti/saluto)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.43s
Running unittests src/lib.rs (target/debug/deps/saluto-00f50f06a08e754d)
running 1 test
test tests::saluto_contiene_nome ... FAILED
failures:
---- tests::saluto_contiene_nome stdout ----
thread 'tests::saluto_contiene_nome' (11432) panicked at src/lib.rs:13:9:
Saluto non contiene un nome, il valore era `Ciao!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::saluto_contiene_nome
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Possiamo vedere il valore effettivamente ottenuto nell’output del test, il che ci aiuterebbe a fare il debug di ciò che è accaduto invece di ciò che ci aspettavamo che accadesse.
Verificare i Casi di Panico Con should_panic
Oltre a verificare i valori di ritorno, è importante controllare che il nostro
codice gestisca le condizioni di errore come ci aspettiamo. Ad esempio,
considera il type Ipotesi che abbiamo creato nel Capitolo 9, Listato 9-13.
Altro codice che utilizza Ipotesi dipende dalla garanzia che le istanze di
Ipotesi conterranno solo valori compresi tra 1 e 100. Possiamo scrivere un
test che verifichi che il tentativo di creare un’istanza di Ipotesi con un
valore al di fuori di questo intervallo vada in panico.
Per farlo, aggiungiamo l’attributo should_panic alla nostra funzione di test.
Il test passa se il codice all’interno della funzione va in panico; il test
fallisce se il codice all’interno della funzione non va in panico.
Il Listato 11-8 mostra un test che verifica che le condizioni di errore di
Ipotesi::new si verifichino quando ce lo aspettiamo.
pub struct Ipotesi {
valore: i32,
}
impl Ipotesi {
pub fn new(valore: i32) -> Ipotesi {
if valore < 1 || valore > 100 {
panic!("L'ipotesi deve essere compresa tra 1 e 100, valore ottenuto: {valore}.");
}
Ipotesi { valore }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn maggiore_di_100() {
Ipotesi::new(200);
}
}panic!Inseriamo l’attributo #[should_panic] dopo l’attributo #[test] e prima della
funzione di test a cui si applica. Vediamo il risultato quando questo test viene
superato:
$ cargo test
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.33s
Running unittests src/lib.rs (target/debug/deps/gioco_indovinello-bd151867e79a86ca)
running 1 test
test tests::maggiore_di_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests gioco_indovinello
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Non male! Ora introduciamo un bug nel nostro codice rimuovendo la condizione per
cui la funzione new va in panico se il valore è superiore a 100:
pub struct Ipotesi {
valore: i32,
}
// --taglio--
impl Ipotesi {
pub fn new(valore: i32) -> Ipotesi {
if valore < 1 {
panic!("L'ipotesi deve essere compresa tra 1 e 100, valore ottenuto: {valore}.");
}
Ipotesi { valore }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn maggiore_di_100() {
Ipotesi::new(200);
}
}Quando eseguiamo il test nel Listato 11-8, questo fallirà:
$ cargo test
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.19s
Running unittests src/lib.rs (target/debug/deps/gioco_indovinello-bd151867e79a86ca)
running 1 test
test tests::maggiore_di_100 - should panic ... FAILED
failures:
---- tests::maggiore_di_100 stdout ----
note: test did not panic as expected at src/lib.rs:24:8
failures:
tests::maggiore_di_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
In questo caso non riceviamo un messaggio molto utile, ma se guardiamo la
funzione di test, vediamo che è annotata con #[should_panic]. Il fallimento
ottenuto significa che il codice della funzione di test non ha causato un
panico.
I test che utilizzano should_panic possono essere imprecisi. Un test
should_panic passerebbe anche se il test va in panico per un motivo diverso da
quello atteso. Per rendere i test should_panic più precisi, possiamo
aggiungere un parametro opzionale expected all’attributo should_panic.
L’infrastruttura di test si assicurerà che il messaggio di fallimento contenga
il testo fornito. Per esempio, considera il codice modificato per Ipotesi nel
Listato 11-9 dove la funzione new va in panico con messaggi diversi a seconda
che il valore sia troppo piccolo o troppo grande.
pub struct Ipotesi {
valore: i32,
}
// --taglio--
impl Ipotesi {
pub fn new(valore: i32) -> Ipotesi {
if valore < 1 {
panic!(
"L'ipotesi deve essere maggiore di zero, valore fornito {valore}."
);
} else if valore > 100 {
panic!(
"L'ipotesi deve essere minore o uguale a 100, valore fornito {valore}."
);
}
Ipotesi { valore }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "minore o uguale a 100")]
fn maggiore_di_100() {
Ipotesi::new(200);
}
}panic! con un messaggio di panico contenente una sotto-stringa specificataQuesto test passerà perché il valore che abbiamo inserito nel parametro
expected dell’attributo should_panic è una sotto-stringa del messaggio con
cui la funzione Ipotesi::new va in panico. Avremmo potuto specificare l’intero
messaggio di panico che ci aspettiamo, che in questo caso sarebbe stato
L’ipotesi deve essere minore o uguale a 100, valore fornito 200.. Quello che
scegli di specificare dipende da quanto il messaggio di panico è unico o
dinamico e da quanto preciso vuoi che sia il tuo test. In questo caso, una
sotto-stringa del messaggio di panico è sufficiente per garantire che il codice
nella funzione di test esegua la parte con else if valore > 100.
Per vedere cosa succede quando un test should_panic con un messaggio
expected fallisce, introduciamo nuovamente un bug nel nostro codice scambiando
i corpi dei blocchi if valore < 1 e else if valore > 100:
pub struct Ipotesi {
valore: i32,
}
impl Ipotesi {
pub fn new(valore: i32) -> Ipotesi {
if valore < 1 {
panic!(
"L'ipotesi deve essere minore o uguale a 100, valore fornito {valore}."
);
} else if valore > 100 {
panic!(
"L'ipotesi deve essere maggiore di zero, valore fornito {valore}."
);
}
Ipotesi { valore }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "minore o uguale a 100")]
fn maggiore_di_100() {
Ipotesi::new(200);
}
}Questa volta il test should_panic fallirà:
$ cargo test
Compiling gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.33s
Running unittests src/lib.rs (target/debug/deps/gioco_indovinello-bd151867e79a86ca)
running 1 test
test tests::maggiore_di_100 - should panic ... FAILED
failures:
---- tests::maggiore_di_100 stdout ----
thread 'tests::maggiore_di_100' (14846) panicked at src/lib.rs:13:13:
L'ipotesi deve essere maggiore di zero, valore fornito 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: "L'ipotesi deve essere maggiore di zero, valore fornito 200."
expected substring: "minore o uguale a 100"
failures:
tests::maggiore_di_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Il messaggio di fallimento indica che questo test è andato in panic come ci
aspettavamo, ma il messaggio di panico non includeva la stringa prevista minore o uguale a 100. Il messaggio di panico che abbiamo ottenuto in questo caso è
stato L’ipotesi deve essere maggiore di zero, valore fornito 200. Ora possiamo
iniziare a capire dove si trova il nostro bug!
Utilizzare Result<T, E> nei Test
Tutti i test che abbiamo fatto finora vanno in panic quando falliscono.
Possiamo anche scrivere test che utilizzano Result<T, E>! Ecco il test del
Listato 11-1, riscritto per utilizzare Result<T, E> e restituire un Err
invece di andare in panico:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("due più due non fa quattro"))
}
}
}La funzione it_works ora ha il type di ritorno Result<(), String>. Nel
corpo della funzione, invece di richiamare la macro assert_eq!, restituiamo
Ok()) quando il test passa e un Err con una String all’interno quando il
test fallisce.
Scrivere i test in modo che restituiscano un Result<T, E> ti permette di usare
l’operatore punto interrogativo nel corpo dei test, il che può essere un modo
comodo per scrivere test che dovrebbero fallire se qualsiasi operazione al loro
interno restituisce una variante Err.
Non puoi usare l’annotazione #[should_panic] nei test che usano Result<T, E>. Per verificare che un’operazione restituisce una variante Err, non
usare l’operatore punto interrogativo sul valore Result<T, E>, ma usa
assert!(valore.is_err()).
Ora che conosci diversi modi per scrivere i test, vediamo cosa succede quando li
eseguiamo ed esploriamo le diverse opzioni che possiamo utilizzare con cargo test
Controllare Come Vengono Eseguiti i Test
Così come cargo run compila il tuo codice e poi esegue il binario risultante,
cargo test compila il tuo codice in modalità test ed esegue il binario
risultante. Il comportamento predefinito del binario prodotto da cargo test è
quello di eseguire tutti i test in parallelo e di catturare l’output generato
durante l’esecuzione dei test, impedendo la visualizzazione dell’output e
rendendo più facile la lettura dell’output relativo ai risultati dei test. Puoi,
tuttavia, specificare alcune opzioni della riga di comando per modificare questo
comportamento predefinito.
Alcune opzioni della riga di sono per cargo test, mentre altre vengono passate
al binario di test risultante.
Per separare questi due tipi di argomenti, devi elencare gli argomenti che vanno
a cargo test seguiti dal separatore -- e poi quelli che vanno al binario di
test. Eseguendo cargo test --help vengono visualizzate le opzioni che puoi
usare con cargo test, mentre eseguendo cargo test -- --help vengono
visualizzate le opzioni che puoi usare dopo il separatore. Queste opzioni sono
documentate anche nella sezione “Tests” del libro di rustc.
Eseguire i Test in Parallelo o Sequenzialmente
Quando esegui più test, come impostazione predefinita questi vengono eseguiti in parallelo utilizzando i thread, il che significa che finiscono di essere eseguiti più velocemente e che ricevi più rapidamente un feedback. Poiché i test vengono eseguiti contemporaneamente, devi assicurarti che i tuoi test non dipendano l’uno dall’altro o da un qualsivoglia stato condiviso, incluso un ambiente condiviso, come la directory di lavoro corrente o le variabili d’ambiente.
Ad esempio, supponiamo che ogni test esegua del codice che crea un file su disco chiamato test-output.txt e scrive alcuni dati in quel file. Poi ogni test legge i dati in quel file e verifica che il file contiene un particolare valore, che è diverso in ogni test. Poiché i test vengono eseguiti contemporaneamente, un test potrebbe sovrascrivere il file nel tempo che intercorre tra la scrittura e la lettura del file da parte di un altro test. Il secondo test fallirà, non perché il codice non è corretto, ma perché i test hanno interferito l’uno con l’altro durante l’esecuzione in parallelo. Una soluzione può essere nell’assicurarsi che ogni test scriva in un file diverso; un’altra soluzione consiste nell’eseguire i test uno alla volta.
Se non vuoi eseguire i test in parallelo o se vuoi un controllo più preciso sul
numero di thread utilizzati, puoi usare il flag --test-threads e il numero
di thread che vuoi utilizzare al binario di test. Guarda il seguente esempio:
$ cargo test -- --test-threads=1
Impostiamo il numero di thread di test a 1, indicando al programma di non
utilizzare alcun parallelismo. L’esecuzione dei test con un solo thread
richiederà più tempo rispetto all’esecuzione in parallelo, ma i test non
interferiranno l’uno con l’altro se condividono lo stato.
Mostrare l’Output Della Funzione
Per impostazione predefinita, se un test viene superato, la libreria di test di
Rust cattura tutto ciò che viene stampato sullo standard output. Ad esempio, se
chiamiamo println! in un test e il test viene superato, non vedremo l’output
println! nel terminale; vedremo solo la riga che indica che il test è stato
superato. Se un test fallisce, vedremo tutto ciò che è stato stampato sullo
standard output con il resto del messaggio di fallimento.
Come esempio, il Listato 11-10 contiene una funzione stupida che stampa il valore del suo parametro e restituisce 10, oltre a un test che passa e uno che fallisce.
fn stampa_e_ritorna_10(a: i32) -> i32 {
println!("Ho ricevuto il valore {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn questo_test_passerà() {
let valore = stampa_e_ritorna_10(4);
assert_eq!(valore, 10);
}
#[test]
fn questo_test_fallirà() {
let valore = stampa_e_ritorna_10(8);
assert_eq!(valore, 5);
}
}println!Quando eseguiamo i test con cargo test, vedremo il seguente output:
$ cargo test
Compiling funzione-stupida v0.1.0 (file:///progetti/funzione-stupida)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.67s
Running unittests src/lib.rs (target/debug/deps/funzione_stupida-5473422b7951e476)
running 2 tests
test tests::questo_test_passerà ... ok
test tests::questo_test_fallirà ... FAILED
failures:
---- tests::questo_test_fallirà stdout ----
Ho ricevuto il valore 8
thread 'tests::questo_test_fallirà' (8784) panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::questo_test_fallirà
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nota che in nessun punto di questo output vediamo Ho ricevuto il valore 4, che
viene stampato quando viene eseguito il test che passa. Quell’output è stato
catturato. L’output del test che è fallito, Ho ricevuto il valore 8, appare
nella sezione dell’output di riepilogo del test, che mostra anche la causa del
fallimento del test.
Se vogliamo vedere anche i valori stampati per i test superati, possiamo dire a
Rust di mostrare anche l’output dei test riusciti con --show-output:
$ cargo test -- --show-output
Quando eseguiamo nuovamente i test del Listato 11-10 con il flag
--show-output, vediamo il seguente output:
$ cargo test -- --show-output
Compiling funzione-stupida v0.1.0 (file:///progetti/funzione-stupida)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/funzione_stupida-5473422b7951e476)
running 2 tests
test tests::questo_test_fallirà ... FAILED
test tests::questo_test_passerà ... ok
successes:
---- tests::questo_test_passerà stdout ----
Ho ricevuto il valore 4
successes:
tests::questo_test_passerà
failures:
---- tests::questo_test_fallirà stdout ----
Ho ricevuto il valore 8
thread 'tests::questo_test_fallirà' (9352) panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::questo_test_fallirà
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Eseguire un Sottoinsieme di Test in Base al Nome
L’esecuzione di tutti i test che abbiamo definito a volte può richiedere molto
tempo. Se stai lavorando sul codice di una particolare area, potresti voler
eseguire solo i test relativi a quel codice. Puoi scegliere quali test eseguire
passando a cargo test il nome o i nomi dei test che vuoi eseguire come
argomento.
Per dimostrare come eseguire un sottoinsieme di test, creeremo prima tre test
per la nostra funzione aggiungi_due, come mostrato nel Listato 11-11, e
sceglieremo quali eseguire.
pub fn aggiungi_due(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn somma_due_e_due() {
let risultato = aggiungi_due(2);
assert_eq!(risultato, 4);
}
#[test]
fn somma_due_e_tre() {
let risultato = aggiungi_due(3);
assert_eq!(risultato, 5);
}
#[test]
fn cento() {
let risultato = aggiungi_due(100);
assert_eq!(risultato, 102);
}
}Se eseguiamo i test senza passare alcun argomento, come abbiamo visto in precedenza, tutti i test verranno eseguiti in parallelo:
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 3 tests
test tests::cento ... ok
test tests::somma_due_e_tre ... ok
test tests::somma_due_e_due ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Eseguire un Singolo Test
Possiamo passare il nome di qualsiasi funzione di test a cargo test per
eseguire solo quel test:
$ cargo test cento
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.81s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 1 test
test tests::cento ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Solo il test con il nome cento è stato eseguito; gli altri due test non
corrispondevano a quel nome. L’output del test ci fa sapere che ci sono altri
test che non sono stati eseguiti mostrando 2 filtered out alla fine.
Non possiamo specificare più di un nome in questo modo; verrà utilizzato solo il
primo valore dato a cargo test. Esiste però un modo per eseguire più test.
Filtrare Per Eseguire Più Test
Possiamo specificare una parte del nome di un test e ogni test il cui nome
corrisponde a quel valore verrà eseguito. Ad esempio, poiché due dei nomi dei
nostri test contengono somma, possiamo eseguirli eseguendo cargo test somma:
$ cargo test somma
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.11s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 2 tests
test tests::somma_due_e_tre ... ok
test tests::somma_due_e_due ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Questo comando ha eseguito tutti i test con somma nel nome e ha filtrato il
test chiamato cento. Nota anche che il modulo in cui appare un test diventa
parte del nome del test, quindi possiamo eseguire tutti i test di un modulo
filtrando sul nome del modulo.
Ignorare Test Se Non Specificamente Richiesti
A volte alcuni test specifici possono richiedere molto tempo per essere
eseguiti, quindi potresti volerli escludere durante la maggior parte delle
esecuzioni di cargo test. Invece di elencare come argomenti tutti i test che
vuoi eseguire, puoi annotare i test che richiedono molto tempo utilizzando
l’attributo ignore per escluderli, come mostrato qui:
File: src/lib.rs
pub fn aggiungi_due(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn somma_due_e_due() {
let risultato = aggiungi_due(2);
assert_eq!(risultato, 4);
}
#[test]
#[ignore]
fn test_impegnativo() {
// codice che richiede un'ora per completarsi
}
}Dopo #[test], aggiungiamo la riga #[ignore] al test che vogliamo escludere.
Ora quando eseguiamo i nostri test, somma_due_e_due viene eseguito, ma
test_impegnativo no:
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.32s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 2 tests
test tests::test_impegnativo ... ignored
test tests::somma_due_e_due ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
La funzione test_impegnativo è elencata come ignored. Se vogliamo eseguire
solo i test ignorati, possiamo usare cargo test -- --ignored:
$ cargo test -- --ignored
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.32s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 1 test
test tests::test_impegnativo ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Controllando quali test vengono eseguiti, puoi assicurarti che i risultati di
cargo test vengano restituiti rapidamente. Quando ha senso controllare i
risultati dei test ignored e hai il tempo di aspettare i risultati, puoi
invece eseguire cargo test -- --ignored. Se vuoi eseguire tutti i test,
indipendentemente dal fatto che siano ignorati o meno, puoi eseguire cargo test -- --include-ignored
Organizzare i Test
Come accennato all’inizio del capitolo, i test sono una disciplina complessa e diverse persone tendono ad utilizzare una terminologia e un’organizzazione diverse. La comunità di Rust pensa ai test in termini di due categorie principali: i test unitari (unit test) e i test di integrazione (integration test). Gli unit test sono piccoli e più mirati, testano un singolo modulo alla volta e possono testare interfacce private. Gli integration test sono invece esterni alla tua libreria e utilizzano il tuo codice nello stesso modo in cui lo farebbe qualsiasi altro codice esterno, utilizzando solo l’interfaccia pubblica e potenzialmente utilizzando più moduli per test.
Scrivere entrambi i tipi di test è importante per garantire che i pezzi della tua libreria facciano ciò che ti aspetti, sia separatamente che quando integrate in altro codice.
Test Unitari
Lo scopo degli unit test è quello di testare ogni unità di codice in modo
isolato dal resto del codice per individuare rapidamente i punti in cui il
codice funziona e non funziona come previsto. Gli unit test vengono inseriti
nella cartella src in ogni file con il codice che stanno testando. La
convenzione è quella di creare un modulo chiamato tests in ogni file per
contenere le funzioni di test e di annotare il modulo con cfg(test).
Il Modulo tests e #[cfg(test)]
L’annotazione #[cfg(test)] sul modulo tests dice a Rust di compilare ed
eseguire il codice di test solo quando si esegue cargo test, non quando si
esegue cargo build. In questo modo si risparmia tempo di compilazione quando
si vuole costruire solo la libreria e si risparmia spazio nell’artefatto
compilato risultante perché i test non sono inclusi. Vedrai che, poiché i test
di integrazione si trovano in una cartella diversa, non hanno bisogno
dell’annotazione #[cfg(test)]. Tuttavia, poiché gli unit test si trovano
negli stessi file del codice, dovrai specificare #[cfg(test)] per evitare che
siano inclusi nel risultato compilato.
Ricordi che quando abbiamo generato il nuovo progetto addizione nella prima
sezione di questo capitolo, Cargo ha generato questo codice per noi:
File: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Nel modulo tests generato automaticamente, l’attributo cfg sta per
configuration (configurazione) e indica a Rust che il seguente elemento deve
essere incluso solo in presenza di una determinata opzione di configurazione. In
questo caso, l’opzione di configurazione è test, che viene fornita da Rust per
la compilazione e l’esecuzione dei test. Utilizzando l’attributo cfg, Cargo
compila il nostro codice di test solo se effettivamente eseguiamo i test con
cargo test. Questo include qualsiasi funzione ausiliaria che potrebbero essere
presente in questo modulo, oltre alle funzioni annotate con #[test].
Testare Funzioni Private
All’interno della comunità dei tester si discute se le funzioni private debbano
essere testate direttamente o meno, e altri linguaggi rendono difficile o
impossibile testare le funzioni private. Indipendentemente dall’ideologia di
testing a cui aderisci, le regole sulla privacy di Rust ti permettono di testare
le funzioni private. Considera il codice nel Listato 11-12 con la funzione
privata addizione_privata.
pub fn aggiungi_due(a: u64) -> u64 {
addizione_privata(a, 2)
}
fn addizione_privata(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn privata() {
let result = addizione_privata(2, 2);
assert_eq!(result, 4);
}
}Nota che la funzione addizione_privata non è contrassegnata come pub. I test
sono solo codice Rust e il modulo tests è solo un altro modulo. Come abbiamo
discusso in “Percorsi per Fare Riferimento a un Elemento nell’Albero dei
Moduli”, gli elementi dei moduli figli possono utilizzare
gli elementi dei loro moduli antenati. In questo test, portiamo tutti gli
elementi dei moduli genitore del modulo tests nello scope con use super::*, e poi il test può chiamare addizione_privata. Se non pensi che le
funzioni private debbano essere testate, non c’è nulla in Rust che ti costringa
a farlo.
Test di Integrazione
In Rust, i test di integrazione sono esterni alla tua libreria. Utilizzano la libreria nello stesso modo in cui lo farebbe qualsiasi altro codice, il che significa che possono chiamare solo le funzioni che fanno parte dell’API pubblica della libreria. Il loro scopo è quello di verificare se molte parti della libreria funzionano correttamente insieme. Unità di codice che funzionano correttamente da sole potrebbero avere problemi quando vengono integrate, quindi creare test che verifichino queste funzionalità del codice integrato è importante. Per creare i test di integrazione, hai bisogno innanzitutto di una cartella tests.
La Cartella tests
Creiamo una cartella tests all’inizio della nostra cartella di progetto, accanto a src. Cargo sa che deve cercare i file di test di integrazione in questa cartella. Possiamo quindi creare tutti i file di test che vogliamo e Cargo compilerà ciascuno di essi come crate separati.
Creiamo un test di integrazione. Con il codice del Listato 11-12 ancora nel file src/lib.rs, crea una cartella tests e un nuovo file chiamato tests/test_integrazione.rs. La struttura delle cartelle del tuo progetto dovrebbe essere simile a questa:
addizione
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── test_integrazione.rs
Inserisci il codice del Listato 11-13 nel file tests/test_integrazione.rs.
use addizione::aggiungi_due;
#[test]
fn aggiungere_due() {
let risultato = aggiungi_due(2);
assert_eq!(risultato, 4);
}addizioneOgni file della cartella tests è un crate separato, quindi dobbiamo portare
la nostra libreria nello scope di ogni crate di test. Per questo motivo
aggiungiamo use addizione::aggiungi_due; all’inizio del codice, che non era
necessario negli unit test usati finora.
Non abbiamo bisogno di annotare alcun codice in tests/test_integrazione.rs con
#[cfg(test)]. Cargo tratta la cartella tests in modo speciale e compila i
file in questa cartella solo quando eseguiamo cargo test. Esegui ora cargo test:
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.80s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 1 test
test tests::privata ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/test_integrazione.rs (target/debug/deps/test_integrazione-a2e6a22ac01f911a)
running 1 test
test aggiungere_due ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Le tre sezioni di output comprendono gli unit test, i test di integrazione e i test di documentazione. Nota che se un test di una sezione fallisce, le sezioni successive non verranno eseguite. Ad esempio, se un unit test fallisce, non ci sarà alcun output per i test di integrazione e di documentazione perché questi test verranno eseguiti solo se tutti gli unit test passano.
La prima sezione per gli unit test è la stessa che abbiamo visto finora: una
riga per ogni unit test (una denominata privata che abbiamo aggiunto nel
Listato 11-12) e poi una riga di riepilogo per i unit test.
La sezione dei test di integrazione inizia con la riga Running test/test_integrazione.rs. Poi, c’è una riga per ogni funzione di test in quel
test di integrazione e una riga di riepilogo dei risultati del test di
integrazione appena prima dell’inizio della sezione Doc-tests addizione.
Ogni file di test di integrazione ha una propria sezione, quindi se aggiungiamo altri file nella cartella tests, ci saranno più sezioni di test di integrazione.
Possiamo comunque eseguire una particolare funzione di test di integrazione
specificando il nome della funzione di test come argomento di cargo test. Per
eseguire tutti i test in un particolare file di test di integrazione, usa
l’argomento --test di cargo test seguito dal nome del file:
$ cargo test --test test_integrazione
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running tests/test_integrazione.rs (target/debug/deps/test_integrazione-a2e6a22ac01f911a)
running 1 test
test aggiungere_due ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Questo comando esegue solo i test presenti nel file tests/test_integrazione.rs.
Sottomoduli nei Test di Integrazione
Man mano che aggiungi altri test di integrazione, potresti voler creare altri file nella cartella tests per organizzarli; ad esempio, puoi raggruppare le funzioni di test in base alla funzionalità che stanno testando. Come già detto, ogni file nella cartella tests viene compilato come un proprio crate separato, il che è utile per creare scope separati per imitare il più possibile il modo in cui gli utenti finali utilizzeranno il tuo crate. Tuttavia, questo significa che i file nella cartella tests non condividono lo stesso comportamento dei file in src, come hai appreso nel Capitolo 7 su come separare il codice in moduli e file.
Il diverso comportamento dei file della cartella tests si nota soprattutto
quando hai una serie di funzioni comuni da utilizzare in più file di test di
integrazione e cerchi di seguire i passi della sezione “Separare i Moduli in
File Diversi” del Capitolo 7 per
metterle in un modulo comune. Ad esempio, se creiamo tests/comune.rs e vi
inseriamo una funzione chiamata inizializzazione a cui aggiungere del codice
che vogliamo chiamare da più funzioni di test in più file di test:
File: tests/comune.rs
pub fn inizializzazione() {
// codice specifico di inizializzazione della libreria
}Quando eseguiamo nuovamente i test, vedremo una nuova sezione nell’output del
test per il file comune.rs, anche se questo file non contiene alcuna funzione
di test né abbiamo chiamato la funzione inizializzazione da nessuna parte:
$ cargo test
Compiling addizione v0.1.0 (file:///progetti/addizione)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.92s
Running unittests src/lib.rs (target/debug/deps/addizione-41054392f08da196)
running 1 test
test tests::privata ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/comune.rs (target/debug/deps/comune-9acf22d6dcb0de0a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/test_integrazione.rs (target/debug/deps/test_integrazione-a2e6a22ac01f911a)
running 1 test
test aggiungere_due ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests addizione
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Il fatto che comune appaia nei risultati dei test con running 0 tests
(eseguiti 0 test) non è quello che volevamo. Volevamo solo condividere un po’
di codice con gli altri file dei test di integrazione. Per evitare che comune
appaia nell’output dei test, invece di creare tests/comune.rs, creeremo
tests/comune/mod.rs. La cartella del progetto ora ha questo aspetto:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── comune
│ └── mod.rs
└── test_integrazione.rs
Questa è la vecchia convenzione di denominazione comunque compresa da Rust, di
cui abbiamo parlato nella sezione “Percorsi di File
Alternativi” del Capitolo 7. Nominare il file in
questo modo indica a Rust di non trattare il modulo comune come un file di
test di integrazione. Quando spostiamo il codice della funzione
inizializzazione in tests/comune/mod.rs e cancelliamo il file
tests/comune.rs, la sezione nell’output del test non apparirà più. I file
nelle sottocartelle della cartella tests non vengono compilati come crate
separati né hanno sezioni nell’output del test.
Dopo aver creato tests/comune/mod.rs, possiamo utilizzarlo da qualsiasi file
di test di integrazione come modulo. Ecco un esempio di chiamata della funzione
inizializzazione dal test aggiungere_due in tests/test_integrazione.rs:
File: tests/test_integrazione.rs
use addizione::aggiungi_due;
mod comune;
#[test]
fn aggiungere_due() {
comune::inizializzazione();
let risultato = aggiungi_due(2);
assert_eq!(risultato, 4);
}Nota come la dichiarazione mod comune; è uguale alla dichiarazione che abbiamo
mostrato nel Listato 7-21. Quindi, nella funzione di test, possiamo chiamare la
funzione comune::inizializzazione().
Test di Integrazione per i Crate Binari
Se il nostro progetto è un crate binario che contiene solo un file
src/main.rs e non ha un file src/lib.rs, non possiamo creare test di
integrazione nella cartella tests e testare le funzioni definite nel file
src/main.rs con una dichiarazione use. Solo i crate libreria espongono
funzioni che altri crate possono utilizzare; i crate binari sono pensati per
essere eseguiti da soli.
Per questo è buona pratica per i progetti Rust che forniscono un binario avere
un file src/main.rs semplice che si limita a richiamare la logica che risiede
nel file src/lib.rs. Utilizzando questa struttura, i test di integrazione
possono testare il crate libreria con use per rendere disponibile le
funzionalità che ci interessa testare. Se la funzionalità passa il test, anche
la piccola quantità di codice nel file src/main.rs funzionerà e quella piccola
quantità di codice non dovrà essere testata.
Riepilogo
Le funzionalità di testing di Rust forniscono un modo per specificare come il codice debba funzionare e ci si assicuri che continui a funzionare come ci si aspetta, anche quando si apportano delle modifiche. I test unitari usano e testano le diverse parti di una libreria separatamente e possono testare i dettagli privati dell’implementazione. I test di integrazione verificano che molte parti della libreria funzionino insieme correttamente e utilizzano l’API pubblica della libreria per testare il codice nello stesso modo in cui lo utilizzerà il codice esterno. Anche se il sistema dei type e le regole di ownership di Rust aiutano a prevenire alcuni tipi di bug, i test sono comunque importanti per ridurre i bug logici che hanno a che fare con il modo in cui ci si aspetta che il codice si comporti.
Combiniamo le conoscenze apprese in questo capitolo e nei capitoli precedenti per lavorare a un progetto!
Un progetto I/O: Creare un Programma da Riga di Comando
Questo capitolo è un riepilogo delle numerose competenze acquisite finora e un’esplorazione di alcune funzionalità aggiuntive della libreria standard. Creeremo uno strumento da riga di comando che interagisce con l’input/output di file e da riga di comando per mettere in pratica alcuni dei concetti di Rust che dovresti aver acquisito finora.
La velocità, la sicurezza, l’output binario singolo e il supporto
multi-piattaforma di Rust lo rendono un linguaggio ideale per la creazione di
strumenti da riga di comando, quindi per il nostro progetto creeremo la nostra
versione del classico strumento di ricerca da riga di comando grep
(globally search a regular expression and print) (cerca
globalmente tramite espressione regolare e stampa). Nel caso d’uso più
semplice, grep cerca una stringa come parametro in un file specificato. Per
farlo, grep accetta come argomenti un percorso di file e una stringa. Quindi
legge il file, trova le righe in quel file che contengono l’argomento stringa e
visualizza quelle righe.
Lungo il capitolo, mostreremo come far sì che il nostro strumento da riga di
comando utilizzi le funzionalità del terminale che molti altri strumenti da riga
di comando utilizzano. Leggeremo il valore di una variabile d’ambiente per
consentire all’utente di configurare il comportamento del nostro programma.
Mostreremo anche i messaggi di errore nel flusso di errore standard della
console (stderr) invece che nell’output standard (stdout), in modo che, ad
esempio, l’utente possa reindirizzare l’output corretto a un file continuando a
visualizzare i messaggi di errore sullo schermo.
Un membro della community Rust, Andrew Gallant, ha già creato una versione
completa e molto veloce di grep, chiamata ripgrep. In confronto, la nostra
versione sarà piuttosto semplice, ma questo capitolo ti fornirà alcune
conoscenze di base necessarie per comprendere un progetto reale come ripgrep.
Il nostro progetto grep combinerà diversi concetti che hai imparato finora:
- Organizzazione del codice (Capitolo 7)
- Utilizzo di vettori e stringhe (Capitolo 8)
- Gestione degli errori (Capitolo 9)
- Utilizzo di trait e lifetime quando opportuno (Capitolo 10)
- Scrittura di test (Capitolo 11)
Introdurremo anche brevemente chiusure, iteratori e oggetti trait, che nel Capitolo 13 e nel Capitolo 18 affronteremo in dettaglio.
Ricevere Argomenti dalla Riga di Comando
Crea un nuovo progetto con, come sempre, cargo new. Chiameremo il nostro
progetto minigrep per distinguerlo dallo strumento grep che potresti già
avere sul tuo sistema:
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
Il primo compito è fare in modo che minigrep accetti i suoi due argomenti
della riga di comando: il percorso del file e una stringa da cercare. Cioè,
vogliamo essere in grado di eseguire il nostro programma con cargo run, due
trattini per indicare che i seguenti argomenti sono per il nostro programma e
non per cargo, una stringa da cercare e un percorso a un file in cui cercare,
in questo modo:
$ cargo run -- stringa-da-trovare file-esempio.txt
Al momento, il programma generato da cargo new non può elaborare gli argomenti
che gli forniamo. Alcune librerie esistenti su crates.io
possono aiutare a scrivere un programma che accetti argomenti da riga di
comando, ma poiché stiamo apprendendo solo ora questo concetto, implementiamo
questa funzionalità da soli.
Leggere i Valori degli Argomenti
Per consentire a minigrep di leggere i valori degli argomenti da riga di
comando che gli passiamo, avremo bisogno della funzione std::env::args fornita
nella libreria standard di Rust. Questa funzione restituisce un iteratore degli
argomenti della riga di comando passati a minigrep. Tratteremo gli iteratori
in dettaglio nel Capitolo 13. Per ora, è sufficiente
conoscere solo due dettagli sugli iteratori: gli iteratori producono una serie
di valori e possiamo chiamare il metodo collect su un iteratore per
trasformarlo in una collezione, come un vettore, che contiene tutti gli elementi
prodotti dall’iteratore.
Il codice nel Listato 12-1 consente al programma minigrep di leggere qualsiasi
argomento della riga di comando passato e quindi raccogliere i valori in un
vettore.
use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
Per prima cosa, portiamo il modulo std::env nello scope con un’istruzione
use in modo da poter utilizzare la sua funzione args. Nota che la funzione
std::env::args è annidata in due livelli di moduli. Come discusso nel
Capitolo 7, nei casi in cui la funzione
desiderata è annidata in più di un modulo, abbiamo scelto di portare nello
scope il modulo genitore anziché la funzione. In questo modo, possiamo
facilmente utilizzare altre funzioni da std::env. È anche meno ambiguo
rispetto all’aggiunta di use std::env::args e quindi alla chiamata della
funzione con solo args, perché args potrebbe essere facilmente confuso con
una funzione definita nel modulo corrente.
La Funzione args e Unicode non Valido
Nota che std::env::args andrà in panic se un argomento contiene Unicode
non valido. Se il programma deve accettare argomenti contenenti Unicode non
valido, utilizzare invece std::env::args_os. Questa funzione restituisce un
iteratore che produce valori OsString invece di valori String. Abbiamo
scelto di utilizzare std::env::args qui per semplicità perché i valori
OsString variano a seconda della piattaforma e sono più complessi da gestire
rispetto ai valori String.
Nella prima riga del corpo di main, chiamiamo env::args e utilizziamo
immediatamente collect per trasformare l’iteratore in un vettore contenente
tutti i valori prodotti dall’iteratore. Possiamo usare la funzione collect per
creare molti tipi di collezioni, quindi annotiamo esplicitamente il type di
args per specificare che vogliamo un vettore di stringhe. Sebbene sia molto
raro dover annotare i type in Rust, collect è una funzione che spesso
occorre annotare perché Rust non è in grado di dedurre il tipo di collezione
desiderata.
Infine, stampiamo il vettore usando la macro di debug. Proviamo a eseguire il codice prima senza argomenti e poi con due argomenti:
$ cargo run
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- ago pagliaio
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep ago pagliaio`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"ago",
"pagliaio",
]
Nota che il primo valore nel vettore è "target/debug/minigrep", che è il nome
del nostro binario. Questo corrisponde al comportamento dell’elenco degli
argomenti in C, consentendo ai programmi di utilizzare il nome con cui sono
stati invocati durante l’esecuzione. Spesso è comodo avere accesso al nome del
programma nel caso in cui si voglia visualizzarlo nei messaggi o modificarne il
comportamento in base all’alias della riga di comando utilizzato per invocarlo.
Ma ai fini di questo capitolo, lo ignoreremo e salveremo solo i due argomenti di
cui abbiamo bisogno.
Salvare i Valori degli Argomenti nelle Variabili
Il programma è attualmente in grado di accedere ai valori specificati come argomenti della riga di comando. Ora dobbiamo salvare i valori dei due argomenti nelle variabili in modo da poterli utilizzare nel resto del programma. Lo facciamo nel Listato 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let percorso_file = &args[2];
println!("Cerco {query}");
println!("Nel file {percorso_file}");
}query e l’argomento percorso_fileCome abbiamo visto quando abbiamo stampato il vettore, il nome del programma
occupa il primo valore nel vettore in args[0], quindi gli argomenti che
servono a noi iniziano dall’indice 1. Il primo argomento preso da minigrep è
la stringa che stiamo cercando, quindi inseriamo un reference al primo
argomento nella variabile query. Il secondo argomento sarà il percorso del
file, quindi inseriamo un reference al secondo argomento nella variabile
percorso_file.
Stampiamo temporaneamente i valori di queste variabili per dimostrare che il
codice funziona come previsto. Eseguiamo di nuovo questo programma con gli
argomenti test e esempio.txt:
$ cargo run -- test esempio.txt
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test esempio.txt`
Cerco test
Nel file esempio.txt
Ottimo, il programma funziona! I valori degli argomenti di cui abbiamo bisogno vengono salvati nelle variabili corrette. In seguito aggiungeremo una gestione degli errori per gestire alcune potenziali situazioni errate, come quando l’utente non fornisce argomenti; per ora ignoreremo questa situazione e lavoreremo invece sull’aggiunta di funzionalità per la lettura dei file.
Leggere un File
Ora aggiungeremo la funzionalità per leggere il file specificato nell’argomento
percorso_file . Per prima cosa abbiamo bisogno di un file di esempio con cui
testarlo: useremo un file con una piccola quantità di testo su più righe con
alcune parole ripetute. Il Listato 12-3 contiene una poesia di Emily Dickinson
che funzionerà bene! Crea un file chiamato poesia.txt nella radice del tuo
progetto e inserisci la poesia “Io sono Nessuno! Tu chi sei?”
Io sono Nessuno! Tu chi sei?
Sei Nessuno anche tu?
Allora siamo in due!
Non dirlo! Potrebbero spargere la voce!
Che grande peso essere Qualcuno!
Così volgare — come una rana
che gracida il tuo nome — tutto giugno —
ad un pantano in estasi di lei!
Con il testo inserito, modifica src/main.rs e aggiungi il codice per leggere il file, come mostrato nel Listato 12-4.
use std::env;
use std::fs;
fn main() {
// --taglio--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let percorso_file = &args[2];
println!("Cerco {query}");
println!("Nel file {percorso_file}");
let contenuto = fs::read_to_string(percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
println!("Con il testo:\n{contenuto}");
}Per prima cosa introduciamo una parte rilevante della libreria standard con
un’istruzione use: abbiamo bisogno di std::fs per gestire i file.
In main, la nuova istruzione fs::read_to_string prende percorso_file, apre
quel file e restituisce un valore di type std::io::Result<String> che
contiene il contenuto del file.
Dopodiché, aggiungiamo di nuovo un’istruzione temporanea println! che stampa
il valore di contenuto dopo la lettura del file, in modo da poter verificare
che il programma funzioni correttamente.
Eseguiamo questo codice con una stringa qualsiasi come primo argomento della riga di comando (perché non abbiamo ancora implementato la parte di ricerca) e il file poesia.txt come secondo argomento:
$ cargo run -- ciao poesia.txt
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep ciao poesia.txt`
Cerco ciao
Nel file poesia.txt
Con il testo:
Io sono Nessuno! Tu chi sei?
Sei Nessuno anche tu?
Allora siamo in due!
Non dirlo! Potrebbero spargere la voce!
Che grande peso essere Qualcuno!
Così volgare — come una rana
che gracida il tuo nome — tutto giugno —
ad un pantano in estasi di lei!
Ottimo! Il codice ha letto e poi stampato il contenuto del file. Ma il codice
presenta alcuni difetti. Al momento, la funzione main ha più responsabilità:
in genere, le funzioni sono più chiare e facili da gestire se ogni funzione è
responsabile di una sola idea. L’altro problema è che non gestiamo gli errori al
meglio delle nostre possibilità. Il programma è ancora piccolo, quindi questi
difetti non rappresentano un grosso problema, ma man mano che il programma
cresce, sarà più difficile correggerli in modo pulito. È buona norma iniziare il
refactoring fin dall’inizio quando si sviluppa un programma, perché è molto
più facile risistemare piccole quantità di codice. Lo faremo come prossima cosa.
Refactoring per Migliorare Modularità e Gestione degli Errori
Per migliorare il nostro programma, risolveremo quattro problemi che riguardano
la struttura del programma e la gestione di potenziali errori. Innanzitutto, la
nostra funzione main ora esegue due attività: analizza gli argomenti e legge
il file. Man mano che il nostro programma cresce, il numero di attività separate
gestite dalla funzione main aumenterà. Man mano che una funzione acquisisce
responsabilità, diventa più difficile esaminare, testare e apportare modificare
senza danneggiare una delle sue parti. È meglio separare le funzionalità in modo
che ogni funzione sia responsabile di un’attività.
Questo problema si collega anche al secondo problema: sebbene query e
percorso_file siano variabili di configurazione del nostro programma,
variabili come contenuto vengono utilizzate per eseguire la struttura logica
del programma. Più main diventa lungo, più variabili dovremo includere nello
scope; più variabili abbiamo nello scope, più difficile sarà tenere traccia
di cosa faccia ciascuna. È meglio raggruppare le variabili di configurazione in
un’unica struttura per chiarirne lo scopo.
Il terzo problema è che abbiamo usato expect per visualizzare un messaggio di
errore quando la lettura del file fallisce, ma il messaggio di errore visualizza
solo Dovrebbe essere stato possibile leggere il file. La lettura di un file
può fallire in diversi modi: ad esempio, il file potrebbe essere mancante o
potremmo non avere i permessi per aprirlo. Al momento, indipendentemente dalla
situazione, visualizzeremo lo stesso messaggio di errore per tutto, il che non
fornirebbe alcuna informazione all’utente!
In quarto luogo, usiamo expect per gestire un errore e, se l’utente esegue il
nostro programma senza specificare argomenti sufficienti, riceverà un errore
index out of bounds da Rust che non spiega chiaramente il problema. Sarebbe
meglio se tutto il codice di gestione degli errori fosse in un unico posto, in
modo che chi in futuro prenderà in mano il nostro codice abbia un solo posto in
cui guardare se la struttura di gestione degli errori avesse bisogno di
cambiamenti. Avere tutto il codice di gestione degli errori in un unico posto
garantirà anche la stampa di messaggi comprensibili per gli utenti della nostra
applicazione.
Affrontiamo questi quattro problemi riscrivendo il nostro progetto.
Separare Attività nei Progetti Binari
Il problema organizzativo di allocare la responsabilità di più attività alla
funzione main è comune a molti progetti binari. Di conseguenza, molti
programmatori Rust trovano utile suddividere le attività di un programma binario
quando la funzione main inizia a diventare più grande. Questo processo prevede
i seguenti passaggi:
- Suddividere il programma in un file main.rs e un file lib.rs e spostare la logica del programma in lib.rs.
- Finché la logica di analisi della riga di comando è piccola, può rimanere
nella funzione
main. - Quando la logica di analisi della riga di comando inizia a complicarsi,
toglierla dalla funzione
maine metterla in altre funzioni o type.
Le responsabilità che rimangono nella funzione main dopo questo processo
dovrebbero essere limitate a quanto segue:
- Chiamare la logica di analisi della riga di comando con i valori degli argomenti
- Impostare qualsiasi altra configurazione
- Chiamare una funzione
eseguiin lib.rs - Gestire l’errore se
eseguirestituisce un errore
Questo schema riguarda la separazione delle attività: main.rs gestisce
l’esecuzione del programma e lib.rs gestisce tutta la logica dell’attività in
corso. Poiché non è possibile testare direttamente la funzione main, questa
struttura consente inoltre di scrivere test e quindi testare tutta la logica del
programma spostandola fuori dalla funzione main. Il codice che rimane nella
funzione main sarà sufficientemente piccolo da poterne verificare la
correttezza leggendolo. Ristrutturiamo il nostro programma seguendo questo
processo.
Estrarre il Parser degli Argomenti
Estrarremo la funzionalità per l’analisi degli argomenti in una funzione che
verrà chiamata da main. Il Listato 12-5 mostra il nuovo avvio della funzione
main che chiama una nuova funzione leggi_config, che definiremo in
src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, percorso_file) = leggi_config(&args);
// --taglio--
println!("Cerco {query}");
println!("Nel file {percorso_file}");
let contenuto = fs::read_to_string(percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
println!("Con il testo:\n{contenuto}");
}
fn leggi_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let percorso_file = &args[2];
(query, percorso_file)
}leggi_config da mainStiamo ancora raccogliendo gli argomenti della riga di comando in un vettore, ma
invece di assegnare il valore dell’argomento all’indice 1 alla variabile query
e il valore dell’argomento all’indice 2 alla variabile percorso_file
all’interno della funzione main, passiamo l’intero vettore alla funzione
leggi_config. La funzione leggi_config contiene quindi la logica che
determina quale argomento debba andare in quale variabile e restituisce i valori
a main. Creiamo ancora le variabili query e percorso_file in main, ma
main non ha più la responsabilità di determinare come gli argomenti e le
variabili della riga di comando corrispondono.
Questa riscrittura potrebbe sembrare eccessiva per il nostro piccolo programma, ma stiamo eseguendo il refactoring in piccoli passaggi incrementali. Dopo aver apportato questa modifica, esegui nuovamente il programma per verificare che l’analisi degli argomenti funzioni ancora. È consigliabile controllare spesso i progressi per aiutare a identificare la causa dei problemi quando si verificano.
Raggruppare i Valori di Configurazione
Possiamo fare un altro piccolo passo per migliorare ulteriormente la funzione
leggi_config. Al momento, restituiamo una tupla, ma poi la suddividiamo
immediatamente in singole parti. Questo è un segno che forse non abbiamo ancora
l’astrazione giusta.
Un altro indicatore che mostra che c’è margine di miglioramento è la parte
config di leggi_config, che implica che i due valori restituiti sono
correlati e fanno entrambi parte di un unico valore di configurazione. Al
momento non stiamo evidenziando questo significato nella struttura dei dati se
non raggruppando i due valori in una tupla; inseriremo invece i due valori in
un’unica struct e daremo a ciascuno dei campi della struct un nome
significativo. In questo modo, sarà più facile per i futuri manutentori di
questo codice comprendere come i diversi valori si relazionano tra loro e qual è
il loro scopo.
Il Listato 12-6 mostra i miglioramenti alla funzione leggi_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = leggi_config(&args);
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
let contenuto = fs::read_to_string(config.percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
// --taglio--
println!("Con il testo:\n{contenuto}");
}
struct Config {
query: String,
percorso_file: String,
}
fn leggi_config(args: &[String]) -> Config {
let query = args[1].clone();
let percorso_file = args[2].clone();
Config { query, percorso_file }
}leggi_config per ritornare un’istanza di una struttura ConfigAbbiamo aggiunto una struct denominata Config definita per avere campi
denominati query e percorso_file. La firma di leggi_config ora indica che
ritorna un valore Config. Nel corpo di leggi_config, dove prima ritornavamo
slice di stringa che fanno riferimento a valori String in args, ora
definiamo Config in modo che contenga valori String posseduti. La variabile
args in main ha ownership dei valori degli argomenti e consente solo alla
funzione leggi_config di prenderli in prestito, il che significa che
violeremmo le regole di Rust sui prestiti se Config tentasse di prendere la
ownership dei valori in args.
Ci sono diversi modi per gestire i dati String; il modo più semplice, anche se
un po’ inefficiente, è chiamare il metodo clone sui valori. Questo creerà una
copia completa dei dati per l’istanza di Config, che ne diverrà proprietaria,
il che richiede più tempo e memoria rispetto alla memorizzazione di un
reference ai dati stringa. Tuttavia, clonare i dati rende anche il nostro
codice molto semplice perché non dobbiamo gestire la lifetime di quei
reference; in questo caso, rinunciare a un po’ di prestazioni per guadagnare
semplicità è un compromesso che vale la pena accettare.
I Compromessi dell’Utilizzo di Clone
Molti utenti di Rust tendono a evitare di usare clone per non incorrere in
problemi di ownership a causa del suo costo di esecuzione. Nel Capitolo
13, imparerai come utilizzare metodi più efficienti in
questo tipo di situazioni. Ma per ora, va bene copiare alcune stringhe per
continuare, perché queste copie verranno eseguite solo una volta e il percorso
del file e la stringa di query sono molto piccoli. È meglio avere un programma
funzionante ma un po’ inefficiente che cercare di iper-ottimizzare il codice
al primo tentativo. Man mano che acquisirai esperienza con Rust, sarà più
facile iniziare con la soluzione più efficiente, ma per ora è perfettamente
accettabile chiamare clone.
Abbiamo aggiornato main in modo che inserisca l’istanza di Config restituita
da leggi_config in una variabile denominata config, e abbiamo aggiornato il
codice che in precedenza utilizzava le variabili separate query e
percorso_file, in modo che ora utilizzi i campi della struct Config.
Ora il nostro codice comunica più chiaramente che query e percorso_file sono
correlati e che il loro scopo è configurare il funzionamento del programma.
Qualsiasi codice che utilizza questi valori sa come trovarli nell’istanza di
config nei campi denominati appositamente per il loro scopo.
Creare un Costruttore per Config
Finora, abbiamo estratto la logica responsabile dell’analisi degli argomenti
della riga di comando da main e l’abbiamo inserita nella funzione
leggi_config. In questo modo abbiamo visto che i valori query e
percorso_file erano correlati e che questa relazione doveva essere comunicata
nel nostro codice. Abbiamo quindi aggiunto una struct Config per denominare
lo scopo correlato di query e percorso_file e per poter ritornare i nomi dei
valori come nomi di campo della struct dalla funzione leggi_config.
Ora che lo scopo della funzione leggi_config è creare un’istanza di Config,
possiamo modificare leggi_config da una semplice funzione a una funzione
chiamata new associata alla struct Config. Questa modifica renderà il
codice più idiomatico. Possiamo creare istanze di type nella libreria
standard, come String, chiamando String::new. Allo stesso modo, modificando
leggi_config in una funzione new associata a Config, saremo in grado di
creare istanze di Config chiamando Config::new. Il Listato 12-7 mostra le
modifiche che dobbiamo apportare.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
let contenuto = fs::read_to_string(config.percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
println!("Con il testo:\n{contenuto}");
// --taglio--
}
// --taglio--
struct Config {
query: String,
percorso_file: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let percorso_file = args[2].clone();
Config { query, percorso_file }
}
}leggi_config in Config::newAbbiamo cambiato in main dove veniva chiamata leggi_config con
Config::new. Abbiamo cambiato la funzione leggi_config in new e spostata
nel blocco impl così da essere associata a Config. Prova a compilare il
codice per verificare che tutto funzioni come dovrebbe.
Migliorare il Messaggio di Errore
Nel Listato 12-8, aggiungiamo un controllo nella funzione new che verificherà
che la slice sia sufficientemente lunga prima di accedere agli indici 1 e 2.
Se la slice non è sufficientemente lunga, il programma va in panico e
visualizza un messaggio di errore più chiaro.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
let contenuto = fs::read_to_string(config.percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
println!("Con il testo:\n{contenuto}");
}
struct Config {
query: String,
percorso_file: String,
}
impl Config {
// --taglio--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("non ci sono abbastanza argomenti");
}
// --taglio--
let query = args[1].clone();
let percorso_file = args[2].clone();
Config { query, percorso_file }
}
}Questo codice è simile alla funzione Ipotesi::new che abbiamo scritto nel
Listato 9-13, dove abbiamo chiamato panic!
quando l’argomento valore era fuori dall’intervallo di valori validi. Invece
di controllare un intervallo di valori, qui controlliamo che la lunghezza di
args sia di almeno 3 e che il resto della funzione possa funzionare
presupponendo che questa condizione sia stata soddisfatta. Se args ha meno di
tre elementi, questa condizione sarà true e chiameremo la macro panic! per
terminare immediatamente il programma.
Con queste poche righe di codice in new, eseguiamo di nuovo il programma senza
argomenti per vedere come appare ora l’errore:
$ cargo run
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
non ci sono abbastanza argomenti
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Questo output è migliore: ora abbiamo un messaggio di errore ragionevole.
Tuttavia, abbiamo anche informazioni estranee che non vogliamo fornire ai nostri
utenti. Forse la tecnica che abbiamo usato nel Listato 9-13 non è la migliore da
usare in questo contesto: una chiamata a panic! è più appropriata per un
problema di programmazione che per un problema di utilizzo, come discusso nel
Capitolo 9. Invece, utilizzeremo l’altra
tecnica che hai imparato nel Capitolo 9: restituire un
Result che indica un successo o un errore.
Restituire un Result Invece di Chiamare panic!
Possiamo invece ritornare un valore Result che conterrà un’istanza di Config
nel caso di successo e descriverà il problema nel caso di errore. Cambieremo
anche il nome della funzione da new a build perché è buona pratica e molti
programmatori si aspettano che le funzioni new non falliscano mai. Quando
Config::build comunica con main, possiamo usare il type Result per
segnalare che si è verificato un problema. Possiamo quindi modificare main per
convertire una variante Err in un errore più pratico per i nostri utenti,
senza sporcare l’output con il testo su thread 'main' e RUST_BACKTRACE
causata da una chiamata a panic!.
Il Listato 12-9 mostra le modifiche che dobbiamo apportare al valore di ritorno
della funzione che stiamo chiamando Config::build e al corpo della funzione
necessaria per ritornare un Result. Nota che questa funzione non verrà
compilata finché non aggiorneremo anche main, cosa che faremo nel prossimo
Listato.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
let contenuto = fs::read_to_string(config.percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
println!("Con il testo:\n{contenuto}");
}
struct Config {
query: String,
percorso_file: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("Non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}Result da Config::buildLa nostra funzione build ritorna un Result con un’istanza di Config in
caso di successo e un letterale stringa in caso di errore. I nostri valori di
errore saranno sempre letterali stringa con lifetime 'static.
Abbiamo apportato due modifiche al corpo della funzione: invece di chiamare
panic! quando l’utente non passa abbastanza argomenti, ora restituiamo un
valore Err e abbiamo racchiuso il valore restituito da Config in un Ok.
Queste modifiche rendono la funzione conforme al nuovo type ritornato.
Ritornare un valore Err da Config::build consente alla funzione main di
gestire il valore Result ritornato dalla funzione build e di uscire dal
processo in modo più pulito in caso di errore.
Chiamare Config::build e Gestire gli Errori
Per gestire il caso di errore e visualizzare un messaggio intuitivo, dobbiamo
aggiornare main per gestire il Result ritornato da Config::build, come
mostrato nel Listato 12-10. Ci assumeremo anche la responsabilità di terminare
il nostro strumento da riga di comando con un codice di errore diverso da zero
ma senza panic!, e lo implementeremo manualmente. Uno stato di uscita diverso
da zero è una convenzione per segnalare al processo chiamante che il programma è
uscito con uno stato di errore.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
// --taglio--
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
let contenuto = fs::read_to_string(config.percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
println!("Con il testo:\n{contenuto}");
}
struct Config {
query: String,
percorso_file: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("Non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}ConfigIn questo Listato, abbiamo utilizzato un metodo che non abbiamo ancora trattato
in dettaglio: unwrap_or_else, definito su Result<T, E> dalla libreria
standard. L’utilizzo di unwrap_or_else ci consente di definire una gestione
degli errori personalizzata, a differenza di panic!. Se Result è un valore
Ok, il comportamento di questo metodo è simile a unwrap: restituisce il
valore interno che Ok sta racchiudendo. Tuttavia, se il valore è un valore
Err, questo metodo richiama il codice nella closure, che è una funzione
anonima che definiamo e passiamo come argomento a unwrap_or_else. Tratteremo
le closure (chiusure) più in dettaglio nel Capitolo 13. Per ora, è sufficiente sapere che unwrap_or_else passerà il valore
interno di Err, che in questo caso è la stringa statica "Non ci sono abbastanza argomenti" che abbiamo aggiunto nel Listato 12-9, alla nostra
chiusura nell’argomento err che appare tra le barre verticali. Il codice nella
chiusura può quindi utilizzare il valore err durante l’esecuzione.
Abbiamo aggiunto una nuova riga use per portare process dalla libreria
standard nello scope. Il codice nella chiusura che verrà eseguito in caso di
errore è composto da sole due righe: stampiamo il valore err e poi chiamiamo
process::exit. La funzione process::exit interromperà immediatamente il
programma e ritornerà il numero che è stato passato come codice di stato di
uscita. Questo è simile alla gestione basata su panic! che abbiamo usato nel
Listato 12-8, ma otteniamo un output più pulito. Proviamolo:
$ cargo run
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problema nella lettura degli argomenti: Non ci sono abbastanza argomenti
Ottimo! Questo output è molto più intuitivo per i nostri utenti.
Estrarre la Logica da main
Ora che abbiamo completato il refactoring dell’analisi della configurazione,
passiamo alla logica del programma. Come scritto nel paragrafo “Separare le
Attività per i Progetti Binari”, estrarremo una funzione denominata esegui che conterrà tutta la
logica attualmente presente nella funzione main che non è coinvolta
nell’impostazione della configurazione o nella gestione degli errori. Al
termine, la funzione main sarà concisa e facile da verificare tramite
ispezione, e saremo in grado di scrivere test per tutta la restante logica.
Il Listato 12-11 mostra il piccolo miglioramento incrementale dell’estrazione di
una funzione esegui.
use std::env;
use std::fs;
use std::process;
fn main() {
// --taglio--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
esegui(config);
}
fn esegui(config: Config) {
let contenuto = fs::read_to_string(config.percorso_file)
.expect("Dovrebbe essere stato possibile leggere il file");
println!("Con il testo:\n{contenuto}");
}
// --taglio--
struct Config {
query: String,
percorso_file: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("Non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}esegui contenente il resto della logica del programmaLa funzione esegui ora contiene tutta la logica rimanente di main, a partire
dalla lettura del file. La funzione esegui prende l’istanza Config come
argomento.
Restituire Errori dalla Funzione esegui
Con la logica del programma rimanente separata nella funzione esegui, possiamo
migliorare la gestione degli errori, come abbiamo fatto con Config::build nel
Listato 12-9. Invece di lasciare che il programma vada in panico chiamando
expect, la funzione esegui ritornerà Result<T, E> quando qualcosa va
storto. Questo ci permetterà di consolidare ulteriormente la logica di gestione
degli errori in main in modo intuitivo. Il Listato 12-12 mostra le modifiche
che dobbiamo apportare alla firma e al corpo di esegui.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --taglio--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
esegui(config);
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
println!("Con il testo:\n{contenuto}");
Ok(())
}
struct Config {
query: String,
percorso_file: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("Non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}esegui per ritornare ResultAbbiamo apportato tre modifiche significative. Innanzitutto, abbiamo cambiato il
type di ritorno della funzione esegui in Result<(), Box<dyn Error>>.
Questa funzione in precedenza restituiva il type unitario, (), e lo
manteniamo come valore restituito nel caso Ok.
Per il type di errore, abbiamo utilizzato l’oggetto trait Box<dyn Error>
(e abbiamo portato std::error::Error nello scope con un’istruzione use
all’inizio). Tratteremo gli oggetti trait nel Capitolo 18. Per ora, sappi solo che Box<dyn Error> significa che la funzione
restituirà un type che implementa il trait Error, ma non dobbiamo
specificare di quale type specifico sarà il valore restituito. Questo ci offre
la flessibilità di restituire valori di errore che possono essere di type
diverso in diversi casi di errore. La parola chiave dyn è l’abbreviazione di
dynamic.
In secondo luogo, abbiamo rimosso la chiamata a expect a favore dell’operatore
?, come abbiamo illustrato nel Capitolo 9.
Invece di panic! in caso di errore, ? ritornerà il valore di errore dalla
funzione corrente affinché il chiamante possa gestirlo.
In terzo luogo, la funzione esegui ora ritorna un valore Ok in caso di
successo. Abbiamo dichiarato il type di successo della funzione esegui come
() nella firma, il che significa che dobbiamo racchiudere il valore del type
unitario nel valore Ok. Questa sintassi Ok(()) potrebbe sembrare un po’
strana a prima vista, ma usare () in questo modo è il modo idiomatico per
indicare che chiamando esegui vogliamo solo gestirne i suoi effetti
collaterali; non deve restituire un valore di cui abbiamo bisogno.
Quando esegui questo codice, verrà compilato ma verrà visualizzato un avviso:
$ cargo run -- ciao poesia.txt
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | esegui(config);
| ^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = esegui(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep ciao poesia.txt`
Cerca ciao
Nel file poesia.txt
Con il testo:
Io sono Nessuno! Tu chi sei?
Sei Nessuno anche tu?
Allora siamo in due!
Non dirlo! Potrebbero spargere la voce!
Che grande peso essere Qualcuno!
Così volgare — come una rana
che gracida il tuo nome — tutto giugno —
ad un pantano in estasi di lei!
Rust ci dice che il nostro codice ha ignorato il valore Result e il valore
Result potrebbe indicare che si è verificato un errore. Ma non stiamo
verificando se si è verificato un errore e il compilatore ci ricorda che
probabilmente intendevamo inserire del codice di gestione degli errori!
Risolviamo subito il problema.
Gestire gli Errori Restituiti da esegui in main
Verificheremo la presenza di errori e li gestiremo utilizzando una tecnica
simile a quella utilizzata con Config::build nel Listato 12-10, ma con una
leggera differenza:
File: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --taglio--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
println!("Cerco {}", config.query);
println!("Nel file {}", config.percorso_file);
if let Err(e) = esegui(config) {
println!("Errore applicazione: {e}");
process::exit(1);
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
println!("Con il testo:\n{contenuto}");
Ok(())
}
struct Config {
query: String,
percorso_file: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("Non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}Utilizziamo if let anziché unwrap_or_else per verificare se esegui
restituisce un valore Err e per chiamare process::exit(1) in tal caso. La
funzione esegui non restituisce un valore di cui abbiamo bisogno come nel caso
di Config::build che restituisce l’istanza di Config. Poiché esegui
restituisce () in caso di successo, ci interessa solo rilevare un errore,
quindi non abbiamo bisogno di unwrap_or_else per restituire il valore estratto
da Ok, che sarebbe solo ().
I corpi delle funzioni if let e unwrap_or_else sono gli stessi in entrambi i
casi: stampiamo l’errore ed usciamo.
Suddividere il Codice in un Crate Libreria
Il nostro progetto minigrep sembra funzionare bene finora! Ora suddivideremo
il file src/main.rs e inseriremo del codice nel file src/lib.rs. In questo
modo, possiamo testare il codice e avere un file src/main.rs con meno
responsabilità.
Definiamo il codice responsabile della ricerca del testo in src/lib.rs anziché
in src/main.rs, il che permetterà a noi (o a chiunque altro utilizzi la nostra
libreria minigrep) di chiamare la funzione di ricerca da più contesti rispetto
al nostro binario minigrep.
Per prima cosa, definiamo la firma della funzione cerca in src/lib.rs come
mostrato nel Listato 12-13, con un corpo che richiama la macro unimplemented!.
Spiegheremo la firma più dettagliatamente quando completeremo l’implementazione.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
unimplemented!();
}cerca in src/lib.rsAbbiamo utilizzato la parola chiave pub nella definizione della funzione per
designare cerca come parte dell’API pubblica del nostro crate libreria. Ora
abbiamo un crate libreria che possiamo utilizzare dal nostro binario e che
possiamo testare!
Ora dobbiamo inserire il codice definito in src/lib.rs nello scope del contenitore binario in src/main.rs e chiamarlo, come mostrato nel Listato 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --taglio--
use minigrep::cerca;
fn main() {
// --taglio--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
println!("Errore nell'applicazione: {e}");
process::exit(1);
}
}
// --taglio--
struct Config {
query: String,
percorso_file: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("Non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
for line in cerca(&config.query, &contenuto) {
println!("{line}");
}
Ok(())
}cerca del crate libreria minigrep in src/main.rsAggiungiamo una riga use minigrep::cerca per portare la funzione cerca dal
crate libreria nello scope del crate binario. Quindi, nella funzione
esegui, anziché stampare il contenuto del file, chiamiamo la funzione cerca
e passiamo il valore config.query e contenuto come argomenti. Quindi,
esegui utilizzerà un ciclo for per stampare ogni riga restituita da cerca
che corrisponde alla query. Questo è anche un buon momento per rimuovere le
chiamate println! nella funzione main che visualizzava la query e il
percorso del file, in modo che il nostro programma stampi solo i risultati della
ricerca (se non si verificano errori).
Nota che la funzione di ricerca raccoglierà tutti i risultati in un vettore che ritornerà prima che venga stampato alcunché. Questa implementazione potrebbe essere lenta nel visualizzare i risultati quando si cercano file di grandi dimensioni, perché i risultati non vengono stampati man mano che vengono trovati; discuteremo un possibile modo per risolvere questo problema utilizzando gli iteratori nel Capitolo 13.
Wow! È stato un duro lavoro, ma ci siamo preparati per il successo futuro. Ora è molto più facile gestire gli errori e abbiamo reso il codice più modulare. Quasi tutto il nostro lavoro sarà svolto in src/lib.rs da ora in poi.
Sfruttiamo questa nuova modularità facendo qualcosa che sarebbe stato difficile con il vecchio codice, ma è facile con il nuovo: scriveremo dei test!
Aggiungere Funzionalità con il Test-Driven Development
Ora che abbiamo la logica di ricerca in src/lib.rs separata dalla funzione
main, è molto più facile scrivere test per le funzionalità principali del
nostro codice. Possiamo chiamare le funzioni direttamente con vari argomenti e
controllare i valori di ritorno senza dover chiamare il nostro binario dalla
riga di comando.
In questa sezione, aggiungeremo la logica di ricerca al programma minigrep
utilizzando il processo di sviluppo guidato dai test (test-driven
development, abbreviato TDD) con i seguenti passaggi:
- Scrivere un test che fallisce ed eseguirlo per assicurarsi che fallisca per il motivo previsto.
- Scrivere o modificare solo il codice necessario per far passare il nuovo test.
- Riscrivere il codice appena aggiunto o modificato e assicurarsi che i test continuino a passare.
- Ripetere dal passaggio 1!
Sebbene sia solo uno dei tanti modi per scrivere software, il TDD può aiutare a guidare la progettazione del codice. Scrivere il test prima di scrivere il codice che lo supera aiuta a mantenere un’elevata copertura dei test durante l’intero processo.
Testeremo l’implementazione della funzionalità che effettivamente eseguirà la
ricerca della stringa di query nel contenuto del file e produrrà un elenco di
righe che corrispondono alla query. Aggiungeremo questa funzionalità in una
funzione chiamata cerca.
Scrivere un Test che Fallisce
In src/lib.rs, aggiungeremo un modulo tests con una funzione di test, come
abbiamo fatto nel Capitolo 11. La funzione di
test specifica il comportamento che vogliamo che abbia la funzione cerca:
accetterà una query e il testo in cui cercare e ritornerà solo le righe del
testo che contengono la query. Il Listato 12-15 mostra questo test.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --taglio--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_risultato() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
}cerca per la funzionalità che vorremmo implementareQuesto test cerca la stringa "dut". Il testo che stiamo cercando è composto da
tre righe, solo una delle quali contiene "dut" (nota che la barra rovesciata
dopo le virgolette doppie di apertura indica a Rust di non inserire un carattere
di nuova linea all’inizio del contenuto di questo letterale stringa). Affermiamo
che il valore restituito dalla funzione cerca contiene solo la riga che ci
aspettiamo.
Se eseguiamo questo test, al momento fallirà perché la macro unimplemented! si
blocca con il messaggio “not implemented” (non implementato). In conformità
con i principi TDD, aggiungeremo solo il codice necessario per evitare che il
test vada in panico quando si chiama la funzione, definendo la funzione cerca
in modo che ritorni sempre un vettore vuoto, come mostrato nel Listato 12-16.
Quindi il test dovrebbe compilare e fallire perché un vettore vuoto non
corrisponde a un vettore contenente la riga "sicuro, veloce, produttivo."
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_risultato() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
}cerca in modo che chiamarla non provochi panicOra parliamo del perché è necessario esplicitare la longevità 'a nella firma
di cerca e utilizzare tale longevità con l’argomento contenuto e con il
valore di ritorno. Ricorda che nel Capitolo 10
i parametri di lifetime specificano quale lifetime dell’argomento è
collegata a quella del valore di ritorno. In questo caso, indichiamo che il
vettore restituito deve contenere slice di stringa che fanno riferimento alla
slice dell’argomento contenuto (piuttosto che all’argomento query).
In altre parole, diciamo a Rust che i dati restituiti dalla funzione cerca
rimarranno validi finché saranno validi i dati passati alla funzione cerca
nell’argomento contenuto. Questo è importante! I dati referenziati da una
slice devono essere validi affinché il reference sia valido; se il
compilatore presume che stiamo creando slice di query anziché di
contenuto, eseguirà i suoi controlli di sicurezza in modo errato.
Se dimentichiamo le annotazioni di longevità e proviamo a compilare questa funzione, otterremo questo errore:
$ cargo build
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn cerca(query: &str, contenuto: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contenuto`
help: consider introducing a named lifetime parameter
|
1 | pub fn cerca<'a>(query: &'a str, contenuto: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust non può sapere quale dei due parametri ci serve per l’output, quindi
dobbiamo indicarlo esplicitamente. Nota che il testo di aiuto suggerisce di
specificare lo stesso parametro di longevità per tutti i parametri e il type
di output, il che è sbagliato! Poiché contenuto è il parametro che contiene
tutto il nostro testo e vogliamo restituire le parti di quel testo che
corrispondono, sappiamo che contenuto è l’unico parametro che dovrebbe essere
collegato al valore di ritorno utilizzando la sintassi di longevità.
Altri linguaggi di programmazione non richiedono di collegare gli argomenti ai valori di ritorno nella firma, ma questa pratica diventerà più semplice col tempo. Potresti confrontare questo esempio con gli esempi nella sezione “Validare i Reference con la Lifetime” del Capitolo 10.
Scrivere Codice per Superare il Test
Attualmente, il nostro test fallisce perché restituisce sempre un vettore vuoto.
Per risolvere il problema e implementare cerca, il nostro programma deve
seguire questi passaggi:
- Iterare ogni riga del contenuto.
- Verificare che la riga contenga la nostra stringa di query.
- In caso affermativo, aggiungerla all’elenco dei valori ritornati.
- In caso contrario, non fare nulla.
- Ritornare l’elenco dei risultati corrispondenti.
Esaminiamo ogni passaggio, iniziando con l’iterazione delle righe.
Iterare le Righe con il Metodo lines
Rust dispone di un metodo utile per gestire l’iterazione riga per riga delle
stringhe, opportunamente chiamato lines, che funziona come mostrato nel
Listato 12-17. Nota che questo non verrà ancora compilato.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
for line in contenuto.lines() {
// facciamo qualcosa con la riga
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_risultato() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
}contenutoIl metodo lines restituisce un iteratore. Parleremo degli iteratori in modo
approfondito nel Capitolo 13. Ma ricorda che
hai visto questo modo di usare un iteratore nel Listato 3-5, dove abbiamo usato un ciclo for con un iteratore per eseguire del
codice su ogni elemento di una collezione.
Ricercare la Query in Ogni Riga
Successivamente, controlleremo se la riga corrente contiene la nostra stringa di
query. Fortunatamente, le stringhe hanno un metodo utile chiamato contains che
fa proprio questo per noi! Aggiungiamo una chiamata al metodo contains nella
funzione cerca, come mostrato nel Listato 12-18. Nota che questo non verrà
ancora compilato.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
for line in contenuto.lines() {
if line.contains(query) {
// facciamo qualcosa con la riga
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_risultato() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
}queryAl momento, stiamo sviluppando la funzionalità. Per compilare il codice, dobbiamo restituire un valore dal corpo, come indicato nella firma della funzione.
Memorizzare le Righe Corrispondenti
Per completare questa funzione, abbiamo bisogno di un modo per memorizzare le
righe corrispondenti che vogliamo restituire. Per farlo, possiamo creare un
vettore mutabile prima del ciclo for e chiamare il metodo push per
memorizzare una line nel vettore. Dopo il ciclo for, ritorniamo il vettore,
come mostrato nel Listato 12-19.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
let mut risultato = Vec::new();
for line in contenuto.lines() {
if line.contains(query) {
risultato.push(line);
}
}
risultato
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_risultato() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
}Ora la funzione cerca dovrebbe restituire solo le righe che contengono
query, e il nostro test dovrebbe essere superato. Eseguiamo il test:
$ cargo test
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 2.28s
Running unittests src/lib.rs (target/debug/deps/minigrep-a16801c2a05e2817)
running 1 test
test tests::un_risultato ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-7b49a695afbb6602)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Il nostro test è stato superato, quindi sappiamo che la funzione fa quello che ci aspettiamo!
A questo punto, potremmo valutare l’opportunità di riscrivere e migliorare l’implementazione della funzione di ricerca, controllando che i test continuino a passare per mantenere la stessa funzionalità. Il codice nella funzione di ricerca non è male, ma non sfrutta alcune utili funzionalità degli iteratori. Torneremo su questo esempio nel Capitolo 13, dove esploreremo gli iteratori in dettaglio e vedremo come migliorarla.
Ora l’intero programma dovrebbe funzionare! Proviamolo, prima con una parola che dovrebbe restituire esattamente una riga della poesia di Emily Dickinson: rana.
$ cargo run -- rana poesia.txt
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep rana poesia.txt`
Così volgare — come una rana
Fantastico! Ora proviamo una parola che corrisponda a più righe, come uno:
$ cargo run -- uno poesia.txt
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep uno poesia.txt`
Io sono Nessuno! Tu chi sei?
Sei Nessuno anche tu?
Che grande peso essere Qualcuno!
E infine, assicuriamoci di non ottenere alcuna riga quando cerchiamo una parola che non è presente da nessuna parte nella poesia, come monomorfizzazione:
$ cargo run -- monomorfizzazione poesia.txt
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorfizzazione poesia.txt`
Ottimo! Abbiamo creato la nostra versione in miniatura di uno strumento classico e abbiamo imparato molto su come strutturare le applicazioni. Abbiamo anche imparato qualcosa sull’input e l’output dei file, sulle lifetime, sui test e sull’analisi della riga di comando.
Per completare questo progetto, mostreremo brevemente come lavorare con le variabili d’ambiente e come stampare su standard error, entrambi utili quando si scrivono programmi da riga di comando.
Lavorare con le Variabili d’Ambiente
Miglioreremo il programma minigrep implementando una funzionalità aggiuntiva:
un’opzione per la ricerca senza distinzione tra maiuscole e minuscole, che
l’utente può attivare tramite una variabile d’ambiente. Potremmo rendere questa
funzionalità un’opzione della riga di comando e richiedere che gli utenti la
inseriscano ogni volta che desiderano applicarla, ma rendendola invece una
variabile d’ambiente, consentiamo ai nostri utenti di impostare la variabile
d’ambiente una sola volta e di fare in modo che tutte le loro ricerche in quella
sessione di terminale siano senza distinzione (case-insensitive).
Scrivere un Test che Fallisce per la Ricerca Case-Insensitive
Aggiungiamo innanzitutto una nuova funzione cerca_case_insensitive alla
libreria minigrep che verrà chiamata quando la variabile d’ambiente ha un
valore. Continueremo a seguire il processo TDD, quindi il primo passo sarà di
scrivere un nuovo test che fallisce. Aggiungeremo un nuovo test per la nuova
funzione cerca_case_insensitive e rinomineremo il nostro vecchio test da
un_risultato a case_sensitive per chiarire le differenze tra i due test,
come mostrato nel Listato 12-20.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
let mut risultato = Vec::new();
for line in contenuto.lines() {
if line.contains(query) {
risultato.push(line);
}
}
risultato
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.
Duttilità.";
assert_eq!(
vec!["sicuro, veloce, produttivo."],
cerca(query, contenuto)
);
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.
Una frusta.";
assert_eq!(
vec!["Rust:", "Una frusta."],
cerca_case_insensitive(query, contenuto)
);
}
}Nota che abbiamo modificato anche il contenuto del vecchio test. Abbiamo
aggiunto una nuova riga con il testo "Duttilità." usando una D maiuscola che
non dovrebbe corrispondere alla query "dut" quando effettuiamo una ricerca con
distinzione tra maiuscole e minuscole. Modificare il vecchio test in questo modo
ci aiuta a garantire di non interrompere accidentalmente la funzionalità di
ricerca con distinzione tra maiuscole e minuscole che abbiamo già implementato.
Questo test dovrebbe ora essere superato e dovrebbe continuare a essere superato
mentre lavoriamo sulla ricerca senza distinzione tra maiuscole e minuscole.
Il nuovo test per la ricerca case-insensitive utilizza "rUsT" come query.
Nella funzione cerca_case_insensitive che stiamo per aggiungere, la query
"rUsT" dovrebbe corrispondere alla riga contenente "Rust:" con una R
maiuscola e corrispondere alla riga "Una frusta." anche se entrambe
differiscono dalla query. Questo è il nostro test che fallisce e non verrà
compilato perché non abbiamo ancora definito la funzione
cerca_case_insensitive. Sentiti libero di aggiungere un’implementazione
scheletro che restituisca sempre un vettore vuoto, simile a quella che abbiamo
fatto per la funzione cerca nel Listato 12-16 per verificare che il test si
compili correttamente e fallisca.
Implementare la Funzione cerca_case_insensitive
La funzione cerca_case_insensitive, mostrata nel Listato 12-21, sarà quasi la
stessa della funzione cerca. L’unica differenza è che metteremo in minuscolo
la query e ogni line in modo che, qualunque sia il carattere
maiuscolo/minuscolo degli argomenti di input, saranno gli stessi quando
controlleremo se la riga contiene la query.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
let mut risultato = Vec::new();
for line in contenuto.lines() {
if line.contains(query) {
risultato.push(line);
}
}
risultato
}
pub fn cerca_case_insensitive<'a>(
query: &str,
contenuto: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut risultato = Vec::new();
for line in contenuto.lines() {
if line.to_lowercase().contains(&query) {
risultato.push(line);
}
}
risultato
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.
Duttilità.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.
Una frusta.";
assert_eq!(
vec!["Rust:", "Una frusta."],
cerca_case_insensitive(query, contenuto)
);
}
}cerca_case_insensitive per rendere minuscole la query e la riga prima di confrontarlePer prima cosa, rendiamo minuscola la stringa query e la memorizziamo in una
nuova variabile con lo stesso nome, oscurando la query originale. La chiamata
a to_lowercase sulla query è necessaria affinché, indipendentemente dal fatto
che la query dell’utente sia "rust", "RUST", "Rust" o "rUsT", la query
verrà trattata come se fosse "rust" e non sarà case-sensitive. Sebbene
to_lowercase gestisca Unicode di base, non sarà accurato al 100%. Se stessimo
scrivendo un’applicazione reale, dovremmo lavorare un po’ di più qui, ma questa
sezione riguarda le variabili d’ambiente, non Unicode, quindi ci fermeremo qui.
Nota che query ora è una String anziché una slice di stringa, perché la
chiamata a to_lowercase crea nuovi dati anziché fare reference a dati
esistenti. Supponiamo che la query sia "rUsT", ad esempio: quella slice non
contiene una u o una t minuscola da utilizzare, quindi dobbiamo allocare una
nuova String contenente "rust". Quando passiamo query come argomento al
metodo contains ora, dobbiamo aggiungere una & (e commerciale) perché la firma
di contains è definita per accettare una slice di stringa.
Successivamente, aggiungiamo una chiamata a to_lowercase su ogni line per
convertire in minuscolo tutti i caratteri della riga su cui stiamo facendo la
ricerca. Ora che abbiamo convertito line e query in minuscolo, troveremo
corrispondenze indipendentemente dalle maiuscole e dalle minuscole della query.
Vediamo se questa implementazione supera i test:
$ cargo test
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ottimo! Hanno superato i test. Ora, chiamiamo la nuova funzione
cerca_case_insensitive dalla funzione esegui. Per prima cosa, aggiungeremo
un’opzione di configurazione alla struttura Config per passare dalla ricerca
case-sensitive a quella case-insensitive. L’aggiunta di questo campo causerà
errori di compilazione perché non lo stiamo ancora inizializzando da nessuna
parte:
File: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
// --taglio--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
println!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}Abbiamo aggiunto il campo ignora_maiuscole che contiene un valore booleano.
Successivamente, abbiamo bisogno della funzione esegui per controllare il
valore del campo ignora_maiuscole e utilizzarlo per decidere se chiamare la
funzione cerca o la funzione cerca_case_insensitive come mostrato nel
Listato 12-22. Questo non verrà ancora compilato.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
// --taglio--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
println!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
Ok(Config { query, percorso_file })
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}cerca o cerca_case_insensitive in base al valore in config.ignora_maiuscoleInfine, dobbiamo verificare la variabile d’ambiente. Le funzioni per lavorare
con le variabili d’ambiente si trovano nel modulo env della libreria standard,
che è già nello scope all’inizio di src/main.rs. Useremo la funzione var
del modulo env per verificare se è stato impostato un valore per una variabile
d’ambiente denominata IGNORA_MAIUSCOLE, come mostrato nel Listato 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
println!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
let ignora_maiuscole = env::var("IGNORA_MAIUSCOLE").is_ok();
Ok(Config {
query,
percorso_file,
ignora_maiuscole,
})
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}IGNORA_MAIUSCOLEQui creiamo una nuova variabile, ignora_maiuscole. Per impostarne il valore,
chiamiamo la funzione env::var e le passiamo il nome della variabile
d’ambiente IGNORA_MAIUSCOLE. La funzione env::var restituisce un Result
che sarà la variante Ok corretta che contiene il valore della variabile
d’ambiente se la variabile d’ambiente è impostata su un valore qualsiasi.
Restituirà la variante Err se la variabile d’ambiente non è impostata.
Stiamo utilizzando il metodo is_ok su Result per verificare se la variabile
d’ambiente è impostata, il che significa che il programma dovrebbe eseguire una
ricerca senza distinzione tra maiuscole e minuscole. Se la variabile d’ambiente
IGNORA_MAIUSCOLE non è impostata, is_ok restituirà false e il programma
eseguirà una ricerca facendo distinzione tra maiuscole e minuscole. Non ci
interessa il valore della variabile d’ambiente, ma solo se è impostata o meno,
quindi usare is_ok è sufficiente in questo caso anziché utilizzare unwrap,
expect o uno qualsiasi degli altri metodi che abbiamo visto su Result.
Passiamo il valore nella variabile ignora_maiuscole all’istanza Config in
modo che la funzione esegui possa leggere quel valore e decidere se chiamare
cerca_case_insensitive o cerca, come abbiamo implementato nel Listato 12-22.
Proviamo! Per prima cosa eseguiamo il nostro programma senza la variabile
d’ambiente impostata e con la query che, che dovrebbe corrispondere a
qualsiasi riga che contenga la parola che in minuscolo:
$ cargo run -- che poesia.txt
Compiling minigrep v0.1.0 (file:///progetti/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.45s
Running `target/debug/minigrep che poesia.txt`
Sei Nessuno anche tu?
che gracida il tuo nome — tutto giugno —
Sembra che funzioni ancora! Ora eseguiamo il programma con IGNORA_MAIUSCOLE
impostato a 1 ma con la stessa query che:
$ IGNORA_MAIUSCOLE=1 cargo run -- che poesia.txt
Se si utilizza PowerShell, sarà necessario impostare la variabile d’ambiente ed eseguire il programma con comandi separati:
PS> $Env:IGNORA_MAIUSCOLE=1; cargo run -- che poesia.txt
Questo farà sì che IGNORA_MAIUSCOLE persista per il resto della sessione
shell. Può essere annullato con il cmdlet Remove-Item:
PS> Remove-Item Env:IGNORA_MAIUSCOLE
Dovremmo ottenere righe che contengono che e che potrebbero contenere lettere maiuscole:
Sei Nessuno anche tu?
Che grande peso essere Qualcuno!
che gracida il tuo nome — tutto giugno —
Eccellente, abbiamo trovato anche le righe contenenti C maiuscolo! Il nostro
programma minigrep ora può effettuare ricerche case-insensitive, controllate
da una variabile d’ambiente. Ora sai come gestire le opzioni impostate
utilizzando argomenti della riga di comando o variabili d’ambiente.
Alcuni programmi consentono argomenti e variabili d’ambiente per la stessa configurazione. In questi casi, i programmi decidono che l’uno o l’altro abbia la precedenza. Come esercizio e per sperimentare un po’, prova a controllare la distinzione tra maiuscole e minuscole tramite un argomento della riga di comando o una variabile d’ambiente. Decidi se l’argomento della riga di comando o la variabile d’ambiente debbano avere la precedenza se il programma viene eseguito con uno impostato case-sensitive e l’altro impostato come case-insensitive.
Il modulo std::env contiene molte altre utili funzionalità per gestire le
variabili d’ambiente: consulta la sua documentazione per scoprire quali
sono disponibili.
Scrivere i Messaggi di Errore su Standard Error
Al momento, stiamo stampando tutto il nostro output sul terminale usando la
macro println!. Nella maggior parte dei terminali, esistono due tipi di
output: standard output (stdout) per informazioni generali e standard
error (stderr) per i messaggi di errore. Questa distinzione consente agli
utenti di scegliere di indirizzare l’output corretto di un programma a un file,
ma di visualizzare comunque i messaggi di errore sullo schermo.
La macro println! è in grado di stampare solo sullo standard output, quindi
dobbiamo usare qualcos’altro per stampare sullo standard error.
Controllare dove Vengono Scritti gli Errori
Per prima cosa osserviamo come il contenuto stampato da minigrep viene
attualmente scritto sullo standard output, inclusi eventuali messaggi di
errore che vorremmo invece scrivere sullo standard error. Lo faremo
reindirizzando il flusso di standard output a un file, causando
intenzionalmente un errore. Non reindirizzeremo il flusso di standard error,
quindi qualsiasi contenuto inviato allo standard error continuerà a essere
visualizzato sullo schermo.
Ci si aspetta che i programmi a riga di comando inviino messaggi di errore al flusso di standard error, in modo da poterli comunque visualizzare sullo schermo anche se reindirizziamo il flusso di output standard a un file. Il nostro programma al momento non si comporta bene: stiamo per vedere che salverà l’output del messaggio di errore in un file!
Per dimostrare questo comportamento, esegui il programma con > e il percorso
del file, output.txt, a cui vogliamo reindirizzare il flusso di standard
output. Non passeremo alcun argomento, il che dovrebbe causare un errore:
$ cargo run > output.txt
La sintassi > indica alla shell di scrivere il contenuto dello standard
output su output.txt invece che sullo schermo. Non abbiamo visto il messaggio
di errore che ci aspettavamo di visualizzare sullo schermo, quindi significa che
deve essere finito nel file. Ecco cosa contiene output.txt:
Problema nella lettura degli argomenti: non ci sono abbastanza argomenti
Sì, il nostro messaggio di errore viene visualizzato sullo standard output. È molto più utile che messaggi di errore come questo vengano visualizzati sullo standard error, in modo che solo i dati di un’esecuzione senza errori finiscano nel file. Cambieremo questa impostazione.
Visualizzazione degli Errori sullo Standard Error
Useremo il codice del Listato 12-24 per modificare la modalità di
visualizzazione dei messaggi di errore. A causa del refactoring effettuato in
precedenza in questo capitolo, tutto il codice che visualizza i messaggi di
errore si trova in un’unica funzione, main. La libreria standard fornisce la
macro eprintln! che stampa sullo standard error, quindi modifichiamo i due
punti in cui chiamavamo println! per visualizzare gli errori in modo che
utilizzino eprintln! al loro posto.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
eprintln!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
let ignora_maiuscole = env::var("IGNORA_MAIUSCOLE").is_ok();
Ok(Config {
query,
percorso_file,
ignora_maiuscole,
})
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}eprintln!Ora eseguiamo di nuovo il programma nello stesso modo, senza argomenti e
reindirizzando lo standard output con >:
$ cargo run > output.txt
Problema nella lettura degli argomenti: non ci sono abbastanza argomenti
Ora vediamo l’errore sullo schermo e output.txt non contiene nulla, che è il comportamento che ci aspettiamo dai programmi a riga di comando.
Eseguiamo di nuovo il programma con argomenti che non causano errori ma che comunque reindirizziamo l’output standard a un file, in questo modo:
$ cargo run -- che poesia.txt > output.txt
Non vedremo alcun output sul terminale e output.txt conterrà i nostri risultati:
File: output.txt
Sei Nessuno anche tu?
che gracida il tuo nome — tutto giugno —
Questo dimostra che ora stiamo utilizzando lo standard output per l’output corretto e lo standard error per l’output dei messaggi di errore, a seconda dei casi.
Riepilogo
Questo capitolo ha messo in pratica alcuni dei concetti principali appresi
finora e ha spiegato come eseguire operazioni di I/O comuni in Rust. Utilizzando
argomenti della riga di comando, file, variabili d’ambiente e la macro
eprintln! per la stampa degli errori, ora sei pronto a scrivere applicazioni
da riga di comando. In combinazione con i concetti dei capitoli precedenti, il
codice sarà ben organizzato, memorizzerà i dati in modo efficace nelle strutture
dati appropriate, gestirà gli errori in modo efficiente e sarà ben testato.
Andando avanti, esploreremo alcune funzionalità di Rust ispirate dai linguaggi funzionali: closure (chiusure) e iteratori.
Funzionalità dei Linguaggi Funzionali: Iteratori e Chiusure
Il design di Rust si è ispirato a molti linguaggi e tecniche esistenti, e un’influenza significativa è la programmazione funzionale. La programmazione in stile funzionale spesso include l’utilizzo di funzioni come valori, passandole come argomenti, restituendole da altre funzioni, assegnandole a variabili per l’esecuzione successiva e così via.
In questo capitolo, non discuteremo la questione di cosa sia o non sia la programmazione funzionale, ma discuteremo invece alcune caratteristiche di Rust simili a caratteristiche di molti linguaggi spesso definiti funzionali.
Più specificamente, tratteremo:
- Chiusure (Closures), un costrutto simile a una funzione che puoi memorizzare in una variabile
- Iteratori, un modo per elaborare una serie di elementi
- Come usare chiusure e iteratori per migliorare il progetto I/O del Capitolo 12
- Le prestazioni di chiusure e iteratori (spoiler: sono più veloci di quanto potresti pensare!)
Abbiamo già trattato altre funzionalità di Rust, come il pattern matching e le enum, che sono anch’esse influenzate dallo stile funzionale. Poiché padroneggiare chiusure e iteratori è una parte importante della scrittura di codice Rust veloce e idiomatico, gli dedicheremo l’intero capitolo.
Chiusure
Le chiusure (closure) di Rust sono funzioni anonime che è possibile salvare in una variabile o passare come argomenti ad altre funzioni. È possibile creare la chiusura in un punto e poi chiamarla altrove per valutarla in un contesto diverso. A differenza delle funzioni, le chiusure possono catturare valori dallo scope in cui sono definite. Dimostreremo come queste funzionalità di chiusura consentano il riutilizzo del codice e la personalizzazione del comportamento.
Catturare l’Ambiente
Esamineremo innanzitutto come possiamo utilizzare le chiusure per catturare valori dall’ambiente in cui sono definite per un uso successivo. Ecco lo scenario: ogni tanto, la nostra azienda di magliette regala una maglietta esclusiva in edizione limitata a qualcuno nella nostra mailing list come promozione. Gli utenti della mailing list possono facoltativamente aggiungere il loro colore preferito al proprio profilo. Se la persona a cui viene assegnata una maglietta gratuita ha impostato il suo colore preferito, riceverà la maglietta di quel colore. Se la persona non ha specificato un colore preferito, riceverà il colore di cui l’azienda ha attualmente la maggiore disponibilità.
Ci sono molti modi per implementarlo. Per questo esempio, useremo un’enum
chiamata ColoreMaglietta che ha le varianti Rosso e Blu (limitando il
numero di colori disponibili per semplicità). Rappresentiamo l’inventario
dell’azienda con una struct Inventario che ha un campo denominato
magliette che contiene un Vec<ColoreMaglietta> che rappresenta i colori
delle magliette attualmente disponibili in magazzino. Il metodo regalo
definito su Inventario ottiene la preferenza opzionale per il colore della
maglietta del vincitore della maglietta gratuita e restituisce il colore della
maglietta che la persona riceverà. Questa configurazione è mostrata nel Listato
13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ColoreMaglietta {
Rosso,
Blu,
}
struct Inventario {
magliette: Vec<ColoreMaglietta>,
}
impl Inventario {
fn regalo(&self, preferenze_utente: Option<ColoreMaglietta>) -> ColoreMaglietta {
preferenze_utente.unwrap_or_else(|| self.maggior_stock())
}
fn maggior_stock(&self) -> ColoreMaglietta {
let mut num_rosso = 0;
let mut num_blu = 0;
for colore in &self.magliette {
match colore {
ColoreMaglietta::Rosso => num_rosso += 1,
ColoreMaglietta::Blu => num_blu += 1,
}
}
if num_rosso > num_blu {
ColoreMaglietta::Rosso
} else {
ColoreMaglietta::Blu
}
}
}
fn main() {
let negozio = Inventario {
magliette: vec![ColoreMaglietta::Blu, ColoreMaglietta::Rosso, ColoreMaglietta::Blu],
};
let pref_utente1 = Some(ColoreMaglietta::Rosso);
let regalo1 = negozio.regalo(pref_utente1);
println!(
"L'utente con preferenza {:?} riceve {:?}",
pref_utente1, regalo1
);
let pref_utente2 = None;
let regalo2 = negozio.regalo(pref_utente2);
println!(
"L'utente con preferenza {:?} riceve {:?}",
pref_utente2, regalo2
);
}Il negozio definito in main ha due magliette blu e una rossa rimanenti da
distribuire per questa promozione in edizione limitata. Chiamiamo il metodo
regalo per un utente con preferenza per una maglietta rossa e un utente senza
alcuna preferenza.
Anche in questo caso, questo codice potrebbe essere implementato in molti modi
e, per concentrarci sulle chiusure, ci siamo attenuti ai concetti che hai già
imparato, ad eccezione del corpo del metodo regalo che utilizza una chiusura.
Nel metodo regalo, otteniamo la preferenza dell’utente come parametro di
type Option<ColoreMaglietta> e chiamiamo il metodo unwrap_or_else su
preferenza_utente. Il metodo unwrap_or_else su
Option<T> è definito dalla libreria standard.
Accetta un argomento: una chiusura senza argomenti che restituisce un valore T
(lo stesso type memorizzato nella variante Some di Option<T>, in questo
caso ColoreMaglietta). Se Option<T> è la variante Some, unwrap_or_else
restituisce il valore presente all’interno di Some. Se Option<T> è la
variante None , unwrap_or_else chiama la chiusura e restituisce il valore
restituito dalla chiusura.
Specifichiamo l’espressione di chiusura || self.maggior_stock() come argomento
di unwrap_or_else. Questa è una chiusura che non accetta parametri (se la
chiusura avesse parametri, questi apparirebbero tra le due barre verticali). Il
corpo della chiusura chiama self.maggior_stock(). Stiamo definendo la chiusura
qui, e l’implementazione di unwrap_or_else valuterà la chiusura in seguito, se
il risultato è necessario.
L’esecuzione di questo codice stampa quanto segue:
$ cargo run
Compiling azienda-magliette v0.1.0 (file:///progetti/azienda-magliette)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.07s
Running `target/debug/azienda-magliette`
L'utente con preferenza Some(Rosso) riceve Rosso
L'utente con preferenza None riceve Blu
Un aspetto interessante è che abbiamo passato una chiusura che chiama
self.maggior_stock() sull’istanza corrente di Inventario. La libreria
standard non aveva bisogno di sapere nulla sui type Inventario o
ColoreMaglietta che abbiamo definito, né sulla logica che vogliamo utilizzare
in questo scenario. La chiusura cattura un reference immutabile all’istanza
self di Inventario e lo passa con il codice che specifichiamo al metodo
unwrap_or_else. Le funzioni, d’altra parte, non sono in grado di catturare il
loro ambiente in questo modo.
Inferenza e Annotazione del Type Delle Chiusure
Esistono ulteriori differenze tra funzioni e chiusure. Le chiusure di solito non
richiedono di annotare i type dei parametri o dei valori di ritorno, come
fanno le funzioni fn. Le annotazioni del type sono necessarie sulle funzioni
perché i type fanno parte di un’interfaccia esplicita esposta agli utenti.
Definire rigidamente questa interfaccia è importante per garantire che tutti
concordino sui tipi di valori che una funzione utilizza e restituisce. Le
chiusure, d’altra parte, non vengono utilizzate in un’interfaccia esposta come
questa: vengono memorizzate in variabili e utilizzate senza denominarle ed
esporle agli utenti della nostra libreria.
Le chiusure sono in genere brevi e rilevanti solo in un contesto ristretto, piuttosto che in uno scenario arbitrario. In questi contesti limitati, il compilatore può dedurre i type dei parametri e il type restituito, in modo simile a come è in grado di dedurre i type della maggior parte delle variabili (ci sono rari casi in cui il compilatore necessita di annotazioni del type anche per le chiusure).
Come per le variabili, possiamo aggiungere annotazioni del type se vogliamo aumentare l’esplicitezza e la chiarezza, a costo di essere più prolissi del necessario. L’annotazione dei type per una chiusura sarebbe simile alla definizione mostrata nel Listato 13-2. In questo esempio, definiamo una chiusura e la memorizziamo in una variabile, anziché definirla nel punto in cui la passiamo come argomento, come abbiamo fatto nel Listato 13-1.
use std::thread; use std::time::Duration; fn genera_allenamento(intensità: u32, numero_casuale: u32) { let chiusura_lenta = |num: u32| -> u32 { println!("calcolo lentamente..."); thread::sleep(Duration::from_secs(2)); num }; if intensità < 25 { println!("Oggi, fai {} flessioni!", chiusura_lenta(intensità)); println!("Poi, fai {} piegamenti!", chiusura_lenta(intensità)); } else { if numero_casuale == 3 { println!("Oggi fai una pausa! Ricordati di idratarti!"); } else { println!( "Oggi, corri per {} minuti!", chiusura_lenta(intensità) ); } } } fn main() { let simulazione_numero_utente = 10; let simulazione_numero_casuale = 7; genera_allenamento(simulazione_numero_utente, simulazione_numero_casuale); }
Con l’aggiunta delle annotazioni del type, la sintassi delle chiusure appare più simile alla sintassi delle funzioni. Qui, per confronto, definiamo una funzione che aggiunge 1 al suo parametro e una chiusura che ha lo stesso comportamento. Abbiamo aggiunto alcuni spazi per allineare le parti rilevanti. Questo illustra come la sintassi delle chiusure sia simile a quella delle funzioni, fatta eccezione per l’uso delle barre verticali e per la quantità di sintassi che è facoltativa:
fn agg_uno_v1 (x: u32) -> u32 { x + 1 }
let agg_uno_v2 = |x: u32| -> u32 { x + 1 };
let agg_uno_v3 = |x| { x + 1 };
let agg_uno_v4 = |x| x + 1 ;La prima riga mostra una definizione di funzione e la seconda una definizione di
chiusura completamente annotata. Nella terza riga, rimuoviamo le annotazioni del
type dalla definizione della chiusura. Nella quarta riga, rimuoviamo le
parentesi, che sono facoltative perché il corpo della chiusura ha una sola
espressione. Queste sono tutte definizioni valide che produrranno lo stesso
comportamento quando vengono chiamate. Le righe agg_uno_v3 e agg_uno_v4
richiedono che le chiusure vengano valutate per essere compilabili, poiché i
type verranno dedotti dal loro utilizzo. Questo è simile a let v = Vec::new(); che richiede annotazioni del type o valori di qualche tipo da
inserire in Vec affinché Rust possa dedurne il type.
Per le definizioni delle chiusure, il compilatore dedurrà un type concreto per
ciascuno dei loro parametri e per il loro valore di ritorno. Ad esempio, il
Listato 13-3 mostra la definizione di una chiusura breve che restituisce
semplicemente il valore ricevuto come parametro. Questa chiusura non è molto
utile, se non per gli scopi di questo esempio. Nota che non abbiamo aggiunto
alcuna annotazione del type alla definizione. Poiché non ci sono annotazioni,
possiamo chiamare la chiusura con qualsiasi type, come abbiamo fatto qui con
String la prima volta. Se poi proviamo a chiamare esempio_chiusura con un
intero, otterremo un errore.
fn main() {
let esempio_chiusura = |x| x;
let s = esempio_chiusura(String::from("ciao"));
let n = esempio_chiusura(5);
}Il compilatore ci dà questo errore:
$ cargo run
Compiling esempio-chiusura v0.1.0 (file:///progetti/esempio_chiusura)
error[E0308]: mismatched types
--> src/main.rs:6:30
|
6 | let n = esempio_chiusura(5);
| ---------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:5:30
|
5 | let s = esempio_chiusura(String::from("ciao"));
| ---------------- ^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:3:29
|
3 | let esempio_chiusura = |x| x;
| ^
help: try using a conversion method
|
6 | let n = esempio_chiusura(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `esempio_chiusura` (bin "esempio_chiusura") due to 1 previous error
La prima volta che chiamiamo esempio_chiusura con il valore String, il
compilatore deduce che il type di x e il type di ritorno della chiusura
siano String. Questi type vengono quindi bloccati nella chiusura in
esempio_chiusura e si verifica un errore di type quando si tenta nuovamente
di utilizzare un type diverso con la stessa chiusura.
Catturare i Reference o Trasferire la Ownership
Le chiusure possono catturare valori dal loro ambiente in tre modi, che corrispondono direttamente ai tre modi in cui una funzione può accettare un parametro: un prestito immutabile, un prestito mutabile o prendendo la ownership. La chiusura deciderà quale di questi utilizzare in base a ciò che il corpo della funzione fa con i valori catturati.
Nel Listato 13-4, definiamo una chiusura che cattura un reference immutabile
al vettore denominato lista perché necessita solo di un riferimento immutabile
per stampare il valore.
fn main() { let lista = vec![1, 2, 3]; println!("Prima di definire la chiusura: {lista:?}"); let solo_prestito = || println!("Dalla chiusura: {lista:?}"); println!("Prima di chiamare la chiusura: {lista:?}"); solo_prestito(); println!("Dopo aver chiamato la chiusura: {lista:?}"); }
Questo esempio illustra anche che una variabile può essere associata a una definizione di chiusura, e che possiamo successivamente chiamare la chiusura utilizzando il nome della variabile e le parentesi come se il nome della variabile fosse il nome di una funzione.
Poiché possiamo avere più reference immutabili a lista contemporaneamente,
lista è comunque accessibile dal codice prima della definizione della
chiusura, dopo la definizione della chiusura ma prima che la chiusura venga
chiamata, e dopo che la chiusura viene chiamata. Questo codice si compila,
esegue e stampa:
$ cargo run
Compiling esempio-chiusura v0.1.0 (file:///progetti/esempio-chiusura)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.09s
Running `target/debug/esempio-chiusura`
Prima di definire la chiusura: [1, 2, 3]
Prima di chiamare la chiusura: [1, 2, 3]
Dalla chiusura: [1, 2, 3]
Dopo aver chiamato la chiusura: [1, 2, 3]
Successivamente, nel Listato 13-5, modifichiamo il corpo della chiusura in modo
che aggiunga un elemento al vettore list. La chiusura ora cattura un
reference mutabile.
fn main() { let mut lista = vec![1, 2, 3]; println!("Prima di definire la chiusura: {lista:?}"); let mut prestito_mutabile = || lista.push(7); prestito_mutabile(); println!("Dopo aver chiamato la chiusura: {lista:?}"); }
Questo codice si compila, esegue e stampa:
$ cargo run
Compiling esempio-chiusura v0.1.0 (file:///progetti/esempio-chiusura)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.08s
Running `target/debug/esempio-chiusura`
Prima di definire la chiusura: [1, 2, 3]
Dopo aver chiamato la chiusura: [1, 2, 3, 7]
Nota che non c’è più println! tra la definizione e la chiamata della chiusura
prestito_mutabile: quando prestito_mutabile è definita, cattura un
reference mutabile a lista. Non usiamo più la chiusura dopo che è stata
chiamata, quindi il prestito mutabile termina. Tra la definizione della chiusura
e la chiamata alla chiusura, non è consentito un prestito immutabile per
stampare perché, quando c’è un prestito mutabile, non sono consentiti altri
prestiti. Prova ad aggiungere println! per vedere quale messaggio di errore
ottieni!
Se vuoi forzare la chiusura ad assumere la ownership dei valori che usa
nell’ambiente, anche se il corpo della chiusura non ne ha strettamente bisogno,
puoi usare la parola chiave move prima dell’elenco dei parametri.
Questa tecnica è utile soprattutto quando si passa una chiusura a un nuovo
thread per spostare i dati in modo che siano di proprietà del nuovo thread.
Discuteremo i thread e perché dovreste utilizzarli in dettaglio nel Capitolo
16, quando parleremo di concorrenza, ma per ora, esploriamo brevemente la
creazione di un nuovo thread utilizzando una chiusura che richiede la parola
chiave move. Il Listato 13-6 mostra il Listato 13-4 modificato per stampare il
vettore in un nuovo thread anziché nel thread principale.
use std::thread; fn main() { let lista = vec![1, 2, 3]; println!("Prima di definire la chiusura: {lista:?}"); thread::spawn(move || println!("Dal thread: {lista:?}")) .join() .unwrap(); }
move per forzare la chiusura affinché il thread prenda la ownership di listaGeneriamo un nuovo thread, assegnandogli una chiusura da eseguire come
argomento. Il corpo della chiusura stampa la lista. Nel Listato 13-4, la
chiusura catturava solo lista utilizzando un reference immutabile, perché
questo rappresenta il minimo accesso a lista necessario per stamparlo. In
questo esempio, anche se il corpo della chiusura richiede ancora solo un
reference immutabile, dobbiamo specificare che lista debba essere spostato
nella chiusura inserendo la parola chiave move all’inizio della definizione
della chiusura. Se il thread principale eseguisse più operazioni prima di
chiamare join sul nuovo thread, il nuovo thread potrebbe terminare prima
del thread principale, oppure il thread principale potrebbe terminare per
primo. Se il thread principale mantenesse la ownership di lista ma
terminasse prima del nuovo thread e de-allocasse la memoria di lista, il
reference immutabile nel thread non sarebbe valido. Pertanto, il compilatore
richiede che lista venga spostato nella chiusura assegnata al nuovo thread,
affinché il reference sia valido. Prova a rimuovere la parola chiave move o
a utilizzare lista nel thread principale dopo la definizione della chiusura
per vedere quali errori del compilatore ottieni!
Restituire i Valori Catturati dalle Chiusure
Una volta che una chiusura ha catturato un reference o preso la ownership di un valore nell’ambiente in cui è definita (influenzando quindi cosa, se presente, viene spostato all’interno della chiusura), il codice nel corpo della chiusura definisce cosa succede ai reference o ai valori quando la chiusura viene valutata in seguito (influenzando quindi cosa, se presente, viene spostato fuori dalla chiusura).
Il corpo di una chiusura può eseguire una delle seguenti operazioni: spostare un valore catturato fuori dalla chiusura, mutare il valore catturato, non spostare né mutare il valore, oppure non catturare nulla dall’ambiente fin dall’inizio.
Il modo in cui una chiusura cattura e gestisce i valori dell’ambiente influenza
quali trait implementa la chiusura, e i trait sono il modo in cui funzioni e
struct possono specificare quali tipi di chiusure possono utilizzare. Le
chiusure implementeranno automaticamente uno, due o tutti e tre questi trait
Fn, in modo additivo, a seconda di come il corpo della chiusura gestisce i
valori:
FnOncesi applica alle chiusure che possono essere chiamate una sola volta. Tutte le chiusure implementano almeno questo trait perché tutte le chiusure possono essere chiamate. Una chiusura che sposta i valori catturati fuori dal suo corpo implementerà soloFnOncee nessuno degli altri traitFnperché può essere chiamata una sola volta.FnMutsi applica alle chiusure che non spostano i valori catturati fuori dal loro corpo, ma che potrebbero mutarli. Queste chiusure possono essere chiamate più di una volta.Fnsi applica alle chiusure che non spostano i valori catturati fuori dal loro corpo e che non mutano i valori catturati, così come alle chiusure che non catturano nulla dal loro ambiente. Queste chiusure possono essere chiamate più di una volta senza mutare il loro ambiente, il che è importante in casi come quando una chiusura viene chiamata più volte contemporaneamente.
Diamo un’occhiata alla definizione del metodo unwrap_or_else su Option<T>
che abbiamo usato nel Listato 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Ricorda che T è il type generico che rappresenta il type del valore nella
variante Some di un’Option. Quel T è anche il type restituito dalla
funzione unwrap_or_else: il codice che chiama unwrap_or_else su
un’Option<String>, ad esempio, otterrà una String.
Nota inoltre che la funzione unwrap_or_else ha il parametro di type generico
aggiuntivo F. F è il type del parametro denominato f, che è la chiusura
che forniamo quando chiamiamo unwrap_or_else.
Il vincolo di trait specificato sul type generico F è FnOnce() -> T, il
che significa che F deve poter essere chiamato una sola volta, non accettare
argomenti e restituire una T. L’utilizzo di FnOnce nel vincolo del trait
esprime il limite che unwrap_or_else non chiamerà f più di una volta. Nel
corpo di unwrap_or_else, possiamo vedere che se Option è Some, f non
verrà chiamata. Se Option è None, f verrà chiamata una volta. Poiché tutte
le chiusure implementano FnOnce, unwrap_or_else accetta tutti e tre i tipi
di chiusure ed è il più flessibile possibile.
Nota: se ciò che vogliamo fare non richiede l’acquisizione di un valore dall’ambiente, possiamo usare il nome di una funzione anziché una chiusura quando abbiamo bisogno di qualcosa che implementi uno dei trait
Fn. Ad esempio, su un valoreOption<Vec<T>>, potremmo chiamareunwrap_or_else(Vec::new)per ottenere un nuovo vettore vuoto se il valore èNone. Il compilatore implementa automaticamente qualsiasi dei traitFnapplicabile per una definizione di funzione.
Ora diamo un’occhiata al metodo della libreria standard sort_by_key, definito
sulle slice, per vedere in che modo differisce da unwrap_or_else e perché
sort_by_key utilizza FnMut invece di FnOnce come vincolo del trait. La
chiusura riceve un argomento sotto forma di reference all’elemento corrente
nella slice in esame e restituisce un valore di type K che può essere
ordinato. Questa funzione è utile quando si desidera ordinare una slice in
base a un particolare attributo di ciascun elemento. Nel Listato 13-7, abbiamo
un elenco di istanze di Rettangolo e utilizziamo sort_by_key per ordinarle
in base al loro attributo larghezza dal più stretto al più largo.
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } fn main() { let mut lista = [ Rettangolo { larghezza: 10, altezza: 1 }, Rettangolo { larghezza: 3, altezza: 5 }, Rettangolo { larghezza: 7, altezza: 12 }, ]; lista.sort_by_key(|r| r.larghezza); println!("{lista:#?}"); }
sort_by_key per ordinare i rettangoli in base alla larghezzaQuesto codice stampa:
$ cargo run
Compiling rettangoli v0.1.0 (file:///progetti/rettangoli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.15s
Running `target/debug/rettangoli`
[
Rettangolo {
larghezza: 3,
altezza: 5,
},
Rettangolo {
larghezza: 7,
altezza: 12,
},
Rettangolo {
larghezza: 10,
altezza: 1,
},
]
Il motivo per cui sort_by_key è definito per accettare una chiusura FnMut è
che chiama la chiusura più volte: una volta per ogni elemento nella slice. La
chiusura |r| r.larghezza non cattura, modifica o sposta nulla dal suo
ambiente, quindi soddisfa i requisiti del vincolo di trait.
Al contrario, il Listato 13-8 mostra un esempio di una chiusura che implementa
solo il trait FnOnce, perché sposta un valore fuori dall’ambiente. Il
compilatore non ci permette di usare questa chiusura con sort_by_key.
#[derive(Debug)]
struct Rettangolo {
larghezza: u32,
altezza: u32,
}
fn main() {
let mut lista = [
Rettangolo { larghezza: 10, altezza: 1 },
Rettangolo { larghezza: 3, altezza: 5 },
Rettangolo { larghezza: 7, altezza: 12 },
];
let mut azioni_ordinamento = vec![];
let valore = String::from("chiusura chiamata");
lista.sort_by_key(|r| {
azioni_ordinamento.push(valore);
r.larghezza
});
println!("{lista:#?}");
}FnOnce con sort_by_keyQuesto è un modo artificioso e contorto (che non funziona) per provare a contare
il numero di volte in cui sort_by_key chiama la chiusura durante l’ordinamento
di lista. Questo codice tenta di effettuare questo conteggio inserendo
valore, una String dall’ambiente della chiusura, nel vettore
azioni_ordinamento. La chiusura cattura valore e quindi sposta valore
fuori dalla chiusura trasferendo la ownership di valore al vettore
azioni_ordinamento. Questa chiusura può essere chiamata una sola volta; se
provi a chiamarla una seconda volta non funzionerebbe perché valore non
sarebbe più nell’ambiente da inserire nuovamente in azioni_ordinamento!
Pertanto, questa chiusura implementa solo FnOnce. Quando proviamo a compilare
questo codice, otteniamo questo errore che indica che valore non può essere
spostato fuori dalla chiusura perché la chiusura deve implementare FnMut:
$ cargo run
Compiling rettangoli v0.1.0 (/file:///progetti/rettangoli)
error[E0507]: cannot move out of `valore`, a captured variable in an `FnMut` closure
--> src/main.rs:18:33
|
15 | let valore = String::from("chiusura chiamata");
| ------ --------------------------------- move occurs because `valore` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | lista.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | azioni_ordinamento.push(valore);
| ^^^^^^ `valore` is moved here
|
help: `Fn` and `FnMut` closures require captured values to be able to be consumed multiple times, but `FnOnce` closures may consume them only once
--> /rust/library/alloc/src/slice.rs:247:12
|
247 | F: FnMut(&T) -> K,
| ^^^^^^^^^^^^^^
help: consider cloning the value if the performance cost is acceptable
|
18 | azioni_ordinamento.push(valore.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rettangoli` (bin "rettangoli") due to 1 previous error
L’errore punta alla riga nel corpo della chiusura che sposta valore fuori
dall’ambiente. Per risolvere questo problema, dobbiamo modificare il corpo della
chiusura in modo che non sposti valori fuori dall’ambiente. Mantenere un
contatore nell’ambiente e incrementarne il valore nel corpo della chiusura è il
modo più semplice per contare il numero di volte in cui la chiusura viene
chiamata. La chiusura nel Listato 13-9 funziona con sort_by_key perché cattura
solo un reference mutabile al contatore numero_azioni_ordinamento e può
quindi essere chiamata più volte.
#[derive(Debug)] struct Rettangolo { larghezza: u32, altezza: u32, } fn main() { let mut lista = [ Rettangolo { larghezza: 10, altezza: 1 }, Rettangolo { larghezza: 3, altezza: 5 }, Rettangolo { larghezza: 7, altezza: 12 }, ]; let mut numero_azioni_ordinamento = 0; lista.sort_by_key(|r| { numero_azioni_ordinamento += 1; r.larghezza }); println!("{lista:#?}, ordinato in {numero_azioni_ordinamento} azioni"); }
FnMut con sort_by_keyI trait Fn sono importanti quando si definiscono o si utilizzano funzioni o
type che fanno uso di chiusure. Nella prossima sezione, parleremo degli
iteratori. Molti metodi iteratori accettano argomenti chiusura, quindi tieni a
mente questi dettagli sulle chiusure mentre proseguiamo!
Elaborare una Serie di Elementi con Iteratori
Il modello dell’iteratore consente di eseguire un’attività su una sequenza di elementi a turno. Un iteratore è responsabile della logica di iterazione su ciascun elemento e di determinare quando la sequenza è terminata. Quando si utilizzano gli iteratori, non è necessario re-implementare questa logica da soli.
In Rust, gli iteratori sono lazy1 (pigri), il che
significa che non hanno effetto finché non si chiamano metodi che consumano
l’iteratore per utilizzarlo. Ad esempio, il codice nel Listato 13-10 crea un
iteratore sugli elementi nel vettore v1 chiamando il metodo iter definito su
Vec<T>. Questo codice di per sé non fa nulla di utile.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); }
L’iteratore è memorizzato nella variabile v1_iter. Una volta creato un
iteratore, possiamo utilizzarlo in diversi modi. Nel Listato 3-5, abbiamo
iterato su un array utilizzando un ciclo for per eseguire del codice su
ciascuno dei suoi elementi. In pratica, questo creava e poi consumava
implicitamente un iteratore, ma finora abbiamo omesso come funziona in pratica.
Nell’esempio del Listato 13-11, separiamo la creazione dell’iteratore dal suo
utilizzo nel ciclo for. Quando il ciclo for viene chiamato utilizzando
l’iteratore in v1_iter, ogni elemento dell’iteratore viene utilizzato in
un’iterazione del ciclo, che stampa ciascun valore.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("Ottenuto: {val}"); } }
forNei linguaggi che non hanno iteratori forniti dalle loro librerie standard, probabilmente scriveresti questa stessa funzionalità inizializzando una variabile all’indice 0, usando quella variabile per indicizzare il vettore per ottenere un valore e incrementando il valore della variabile in un ciclo fino a raggiungere il numero totale di elementi nel vettore.
Gli iteratori gestiscono tutta questa logica per te, riducendo il codice ripetitivo che potrebbe potenzialmente creare errori. Gli iteratori offrono maggiore flessibilità nell’utilizzare la stessa logica con molti tipi diversi di sequenze, non solo con strutture dati in cui puoi indicizzare, come i vettori. Esaminiamo come riescono a farlo.
Il Trait Iterator e il Metodo next
Tutti gli iteratori implementano un trait chiamato Iterator definito nella
libreria standard. La definizione del trait è la seguente:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // metodi con implementazioni predefinite tralasciati } }
Nota che questa definizione utilizza una sintassi che non abbiamo mai visto:
type Item e Self::Item, che definiscono un type associato (associated
type) a questo trait. Parleremo approfonditamente dei type associati nel
Capitolo 20. Per ora, tutto ciò che devi sapere è che questo codice afferma che
l’implementazione del trait Iterator richiede anche la definizione di un
type Item, e questo type Item viene utilizzato nel type di ritorno del
metodo next. In altre parole, il type Item sarà il type restituito
dall’iteratore.
Il trait Iterator richiede agli implementatori di definire un solo metodo:
il metodo next, che restituisce un elemento dell’iteratore alla volta,
racchiuso in Some, e, al termine dell’iterazione, restituisce None.
Possiamo chiamare direttamente il metodo next sugli iteratori; il Listato
13-12 mostra quali valori vengono restituiti da chiamate ripetute a next
sull’iteratore creato dal vettore.
#[cfg(test)]
mod tests {
#[test]
fn dimostrazione_iteratore() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}next su un iteratoreNota che è stato necessario rendere v1_iter mutabile: chiamare il metodo
next su un iteratore modifica lo stato interno che l’iteratore utilizza per
tenere traccia della propria posizione nella sequenza. In altre parole, questo
codice consuma, o esaurisce, l’iteratore. Ogni chiamata a next consuma un
elemento dall’iteratore. Non era necessario rendere v1_iter mutabile quando
abbiamo usato un ciclo for, perché il ciclo prendeva ownership di v1_iter
e lo rendeva mutabile in background.
Nota inoltre che i valori ottenuti dalle chiamate a next sono reference
immutabili ai valori nel vettore. Il metodo iter produce un iteratore su
reference immutabili. Se vogliamo creare un iteratore che prende ownership
di v1 e restituisce i valori posseduti, possiamo chiamare into_iter invece
di iter. Allo stesso modo, se vogliamo iterare su reference mutabili,
possiamo chiamare iter_mut invece di iter.
Metodi che Consumano l’Iteratore
Il trait Iterator ha diversi metodi con implementazioni predefinite fornite
dalla libreria standard; è possibile scoprire di più su questi metodi
consultando la documentazione API della libreria standard per il trait
Iterator. Alcuni di questi metodi chiamano il metodo next nella loro
definizione, motivo per cui è necessario implementare il metodo next quando si
implementa il trait Iterator su un proprio type.
I metodi che chiamano next sono chiamati consumatori (consuming adapters),
perché chiamandoli si consuma l’iteratore. Un esempio è il metodo sum, che
prende ownership dell’iteratore e itera attraverso gli elementi chiamando
ripetutamente next, consumandolo. Durante l’iterazione, aggiunge ogni elemento
a un totale parziale e restituisce il totale al termine dell’iterazione. Il
Listato 13-13 contiene un test che illustra l’uso del metodo sum.
#[cfg(test)]
mod tests {
#[test]
fn somma_con_iteratore() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let totale: i32 = v1_iter.sum();
assert_eq!(totale, 6);
}
}sum per ottenere il totale di tutti gli elementi nell’iteratoreNon è consentito utilizzare v1_iter dopo la chiamata a sum perché sum
prende ownership dell’iteratore su cui viene chiamato.
Metodi che Producono Altri Iteratori
Gli adattatori di iteratore (iterator adapter) sono metodi definiti sul
trait Iterator che non consumano l’iteratore. Invece, producono iteratori
diversi modificando qualche aspetto dell’iteratore originale.
Il Listato 13-14 mostra un esempio di chiamata del metodo dell’adattatore map,
che accetta una chiusura per chiamare ogni elemento durante l’iterazione. Il
metodo map restituisce un nuovo iteratore che produce gli elementi modificati.
La chiusura qui crea un nuovo iteratore in cui ogni elemento del vettore verrà
incrementato di 1.
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
map per creare un nuovo iteratoreTuttavia, questo codice genera un avviso:
$ cargo run
Compiling iteratori v0.1.0 (file:///progetti/iteratori)
warning: unused `Map` that must be used
--> src/main.rs:5:5
|
5 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
5 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iteratori` (bin "iteratori") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.69s
Running `target/debug/iteratori`
Il codice nel Listato 13-14 non fa nulla; la chiusura che abbiamo specificato non viene mai chiamata. L’avviso ci ricorda il motivo: gli adattatori sono lazy e qui dobbiamo consumare l’iteratore.
Per correggere questo avviso e consumare l’iteratore, useremo il metodo
collect, che abbiamo usato con env::args nel Listato 12-1. Questo metodo
consuma l’iteratore e raccoglie i valori risultanti in un collezione di type
appropriato.
Nel Listato 13-15, raccogliamo i risultati dell’iterazione sull’iteratore
restituito dalla chiamata a map in un vettore. Questo vettore finirà per
contenere ogni elemento del vettore originale, incrementato di 1.
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
map per creare un nuovo iteratore, quindi chiamata del metodo collect per consumare il nuovo iteratore e creare un vettorePoiché map accetta una chiusura, possiamo specificare qualsiasi operazione
desideriamo eseguire su ciascun elemento. Questo è un ottimo esempio di come le
chiusure consentano di personalizzare alcuni comportamenti, riutilizzando al
contempo il comportamento di iterazione fornito dal trait Iterator.
È possibile concatenare più chiamate agli adattatori per eseguire azioni complesse in modo leggibile. Tuttavia, poiché tutti gli iteratori sono lazy, è necessario chiamare uno dei metodi consumatori per ottenere risultati dalle chiamate agli adattatori.
Chiusure che Catturano il Loro Ambiente
Molti adattatori accettano le chiusure come argomenti e, di solito, le chiusure che specificheremo come argomenti degli adattatori saranno chiusure che catturano il loro ambiente.
Per questo esempio, useremo il metodo filter che accetta una chiusura. La
chiusura riceve un elemento dall’iteratore e restituisce un valore bool. Se la
chiusura restituisce true, il valore verrà incluso nell’iterazione prodotta da
filter. Se la chiusura restituisce false, il valore non verrà incluso.
Nel Listato 13-16, utilizziamo filter con una chiusura che cattura la
variabile misura_scarpe dal suo ambiente per iterare su una collezione di
istanze della struct Scarpa . Restituirà solo le scarpe della taglia
specificata.
#[derive(PartialEq, Debug)]
struct Scarpa {
misura: u32,
stile: String,
}
fn misura_scarpe(scarpe: Vec<Scarpa>, misura_scarpa: u32) -> Vec<Scarpa> {
scarpe.into_iter().filter(|s| s.misura == misura_scarpa).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filtra_per_misura() {
let scarpe = vec![
Scarpa {
misura: 10,
stile: String::from("sneaker"),
},
Scarpa {
misura: 13,
stile: String::from("sandalo"),
},
Scarpa {
misura: 10,
stile: String::from("scarpone"),
},
];
let della_mia_misura = misura_scarpe(scarpe, 10);
assert_eq!(
della_mia_misura,
vec![
Scarpa {
misura: 10,
stile: String::from("sneaker")
},
Scarpa {
misura: 10,
stile: String::from("scarpone")
},
]
);
}
}filter con una chiusura che cattura misura_scarpaLa funzione misura_scarpe prende ownership di un vettore di scarpe e una
taglia di scarpa come parametri. Restituisce un vettore contenente solo scarpe
della taglia specificata.
Nel corpo di misura_scarpe, chiamiamo into_iter per creare un iteratore che
prende ownership del vettore. Quindi chiamiamo filter per adattare
quell’iteratore in un nuovo iteratore che contiene solo elementi per i quali la
chiusura restituisce true.
La chiusura cattura il parametro misura_scarpa dall’ambiente e confronta il
valore con la taglia di ogni scarpa, mantenendo solo le scarpe della taglia
specificata. Infine, la chiamata a collect raccoglie i valori restituiti
dall’iteratore adattato in un vettore restituito dalla funzione.
Il test mostra che quando chiamiamo misura_scarpe, otteniamo solo le scarpe
che hanno la stessa taglia del valore specificato.
Migliorare il Nostro Progetto I/O
Con queste nuove conoscenze sugli iteratori, possiamo migliorare il progetto I/O
del Capitolo 12 utilizzando gli iteratori per rendere alcuni punti del codice
più chiari e concisi. Vediamo come gli iteratori possono migliorare
l’implementazione della funzione Config::build e della funzione cerca.
Rimuovere clone Utilizzando un Iteratore
Nel Listato 12-6, abbiamo aggiunto del codice che prendeva una slice di valori
String e creava un’istanza della struct Config indicizzando nella slice
e clonando i valori, consentendo alla struct Config di avere ownership di
tali valori. Nel Listato 13-17, abbiamo riprodotto l’implementazione della
funzione Config::build così com’era nel Listato 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
println!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
let ignora_maiuscole = env::var("IGNORA_MAIUSCOLE").is_ok();
Ok(Config {
query,
percorso_file,
ignora_maiuscole,
})
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}Config::build dal Listato 12-23Allora, avevamo detto di non preoccuparci delle chiamate inefficienti a clone
perché le avremmo rimosse in futuro. Bene, quel momento è arrivato!
Qui ci serviva clone perché abbiamo una slice con elementi String nel
parametro args, ma la funzione build non ha ownership su args. Per
restituire la ownership di un’istanza di Config, abbiamo dovuto clonare i
valori dai campi query e percorso_file di Config in modo che l’istanza di
Config possa possederne i valori.
Grazie alle nostre nuove conoscenze sugli iteratori, possiamo modificare la
funzione build per prendere la ownership di un iteratore come argomento
invece di prendere in prestito una slice. Utilizzeremo la funzionalità
dell’iteratore invece del codice che controlla la lunghezza della slice e la
indicizza in posizioni specifiche. Questo chiarirà cosa fa la funzione
Config::build, perché l’iteratore accederà ai valori.
Una volta che Config::build assume la ownership dell’iteratore e smette di
utilizzare le operazioni di indicizzazione che prendono in prestito, possiamo
spostare i valori String dall’iteratore a Config anziché chiamare clone ed
effettuare una nuova allocazione.
Utilizzare Direttamente l’Iteratore Restituito
Apri il file src/main.rs del tuo progetto I/O, che dovrebbe apparire così:
File: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
// --taglio--
if let Err(e) = esegui(config) {
eprintln!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
let ignora_maiuscole = env::var("IGNORA_MAIUSCOLE").is_ok();
Ok(Config {
query,
percorso_file,
ignora_maiuscole,
})
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}Per prima cosa modifichiamo l’inizio della funzione main che avevamo nel
Listato 12-24 con il codice nel Listato 13-18, che questa volta utilizza un
iteratore. Questo non verrà compilato finché non aggiorneremo anche
Config::build.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
// --taglio--
if let Err(e) = esegui(config) {
eprintln!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
let ignora_maiuscole = env::var("IGNORA_MAIUSCOLE").is_ok();
Ok(Config {
query,
percorso_file,
ignora_maiuscole,
})
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}env::args a Config::buildLa funzione env::args restituisce un iteratore! Invece di raccogliere i valori
dell’iteratore in un vettore e poi passare una slice a Config::build, ora
passiamo la ownership dell’iteratore restituito da env::args direttamente a
Config::build.
Dobbiamo quindi aggiornare la definizione di Config::build. Modifichiamo la
firma di Config::build in modo che assomigli al Listato 13-19. Questo non
verrà comunque ancora compilato, perché dobbiamo aggiornare il corpo della
funzione.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
eprintln!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --taglio--
if args.len() < 3 {
return Err("non ci sono abbastanza argomenti");
}
let query = args[1].clone();
let percorso_file = args[2].clone();
let ignora_maiuscole = env::var("IGNORA_MAIUSCOLE").is_ok();
Ok(Config {
query,
percorso_file,
ignora_maiuscole,
})
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}Config::build per aspettarsi un iteratoreLa documentazione della libreria standard per la funzione env::args mostra che
il tipo di iteratore restituito è std::env::Args, e che tale type implementa
il trait Iterator e restituisce valori String.
Abbiamo aggiornato la firma della funzione Config::build in modo che il
parametro args abbia un type generico con i vincoli del trait impl Iterator<Item = String> invece di &[String]. Questo utilizzo della sintassi
impl Trait, discusso nella sezione “Usare i Trait come
Parametri” del Capitolo 10, significa che args può
essere qualsiasi type che implementi il trait Iterator e che restituisca
elementi String.
Poiché stiamo prendendo la ownership di args e lo muteremo iterandolo,
possiamo aggiungere la parola chiave mut nella specifica del parametro args
per renderlo mutabile.
Utilizzare i Metodi del Trait Iterator
Successivamente, correggeremo il corpo di Config::build. Poiché args
implementa il trait Iterator, sappiamo di poter chiamare il metodo next su
di esso! Il Listato 13-20 aggiorna il codice del Listato 12-23 per utilizzare il
metodo next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{cerca, cerca_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problema nella lettura degli argomenti: {err}");
process::exit(1);
});
if let Err(e) = esegui(config) {
eprintln!("Errore dell'applicazione: {e}");
process::exit(1);
}
}
struct Config {
query: String,
percorso_file: String,
ignora_maiuscole: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Stringa Query non fornita"),
};
let percorso_file = match args.next() {
Some(arg) => arg,
None => return Err("Percorso file non fornito"),
};
let ignora_maiuscole = env::var("IGNORA_MAIUSCOLE").is_ok();
Ok(Config {
query,
percorso_file,
ignora_maiuscole,
})
}
}
fn esegui(config: Config) -> Result<(), Box<dyn Error>> {
let contenuto = fs::read_to_string(config.percorso_file)?;
let risultato = if config.ignora_maiuscole {
cerca_case_insensitive(&config.query, &contenuto)
} else {
cerca(&config.query, &contenuto)
};
for line in risultato {
println!("{line}");
}
Ok(())
}Config::build per utilizzare i metodi iteratoriRicorda che il primo valore restituito da env::args è il nome del programma.
Vogliamo ignorarlo e passare al valore successivo, quindi prima chiamiamo next
e non facciamo nulla con il valore restituito. Poi chiamiamo next per ottenere
il valore che vogliamo inserire nel campo query di Config. Se next
restituisce Some, usiamo match per estrarre il valore. Se restituisce
None, significa che non sono stati forniti abbastanza argomenti e restituiamo
subito un valore Err. Facciamo la stessa cosa per il valore percorso_file.
Chiarire il Codice con gli Adattatori
Possiamo anche sfruttare gli iteratori nella funzione cerca nel nostro
progetto di I/O, che è riprodotta qui nel Listato 13-21 come nel Listato 12-19.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
let mut risultato = Vec::new();
for line in contenuto.lines() {
if line.contains(query) {
risultato.push(line);
}
}
risultato
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn un_risultato() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
}cerca del Listato 12-19Possiamo scrivere questo codice in modo più conciso utilizzando gli adattatori.
In questo modo evitiamo anche di avere un vettore mutabile risultato. Lo stile
di programmazione funzionale preferisce ridurre al minimo la quantità di stato
mutabile per rendere il codice più chiaro. La rimozione dello stato mutabile
potrebbe consentire un miglioramento futuro per far sì che la ricerca avvenga in
parallelo, poiché non dovremmo gestire l’accesso simultaneo al vettore
risultati. Il Listato 13-22 mostra questa modifica.
pub fn cerca<'a>(query: &str, contenuto: &'a str) -> Vec<&'a str> {
contenuto
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn cerca_case_insensitive<'a>(
query: &str,
contenuto: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut risultato = Vec::new();
for line in contenuto.lines() {
if line.to_lowercase().contains(&query) {
risultato.push(line);
}
}
risultato
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "dut";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.
Duttilità.";
assert_eq!(vec!["sicuro, veloce, produttivo."], cerca(query, contenuto));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contenuto = "\
Rust:
sicuro, veloce, produttivo.
Scegline tre.
Una frusta.";
assert_eq!(
vec!["Rust:", "Una frusta."],
cerca_case_insensitive(query, contenuto)
);
}
}cercaRicorda che lo scopo della funzione cerca è restituire tutte le righe in
contenuto che contengono la query. Analogamente all’esempio filter nel
Listato 13-16, questo codice utilizza l’adattatore filter per conservare solo
le righe per le quali line.contains(query) restituisce true. Quindi
raccogliamo le righe corrispondenti in un altro vettore con collect. Molto più
semplice! Sentiti libero di apportare la stessa modifica utilizzando i metodi
adattatori anche nella funzione cerca_case_insensitive.
Per un ulteriore miglioramento, restituisci un iteratore dalla funzione cerca
rimuovendo la chiamata a collect e modificando il type di ritorno in impl Iterator<Item = &'a str> in modo che la funzione diventi essa stessa un
adattatore. Nota che dovrai anche aggiornare i test! Prova ad utilizzare lo
strumento minigrep per cercare in un file di grandi dimensioni prima e dopo
aver apportato questa modifica ed osserva la differenza di comportamento. Prima
di questa modifica, il programma non visualizzava alcun risultato finché non
aveva raccolto tutti i risultati, ma dopo la modifica, i risultati verranno
visualizzati man mano che viene trovata ogni riga corrispondente, perché il
ciclo for nella funzione esegui è in grado di sfruttare “la pigrizia”
(laziness) dell’iteratore.
Scegliere tra Cicli e Iteratori
La domanda logica successiva è quale stile scegliere nel proprio codice e perché: l’implementazione originale nel Listato 13-21 o la versione che utilizza gli iteratori nel Listato 13-22 (supponendo che stiamo raccogliendo tutti i risultati prima di restituirli piuttosto che restituire l’iteratore). La maggior parte dei programmatori Rust preferisce usare lo stile iteratore. È un po’ più difficile da capire all’inizio, ma una volta che si è presa familiarità con i vari adattatori e con il loro funzionamento, gli iteratori possono essere più facili da capire. Invece di armeggiare con i vari pezzi del ciclo e creare nuovi vettori, il codice si concentra sull’obiettivo di alto livello del ciclo. Questo astrae parte del codice più comune, rendendo più facile comprendere i concetti specifici di questo codice, come la condizione di filtro che ogni elemento dell’iteratore deve soddisfare.
Ma le due implementazioni sono davvero equivalenti? L’ipotesi intuitiva potrebbe essere che il ciclo di livello inferiore sia più veloce. Parliamo di prestazioni.
Prestazioni di Cicli e Iteratori
Per determinare se utilizzare cicli o iteratori, è necessario sapere quale
implementazione è più veloce: la versione della funzione cerca con un ciclo
for esplicito o la versione con iteratori.
Abbiamo eseguito un benchmark caricando l’intero contenuto di Le avventure di
Sherlock Holmes di Sir Arthur Conan Doyle in una String e cercando la parola
the nel contenuto. Ecco i risultati del benchmark sulla versione di cerca
che utilizza il ciclo for e sulla versione che utilizza gli iteratori:
test bench_cerca_for ... bench: 19.620.300 ns/iter (+/- 915.700)
test bench_cerca_iter ... bench: 19.234.900 ns/iter (+/- 657.200)
Le due implementazioni hanno prestazioni simili! Non spiegheremo il codice del benchmark qui perché lo scopo non è dimostrare che le due versioni siano equivalenti, ma avere un’idea generale di come queste due implementazioni si confrontino in termini di prestazioni.
Per un benchmark più completo, si consiglia di utilizzare testi di varie
dimensioni come contenuto, parole diverse e parole di lunghezza diversa come
query e tutti i tipi di altre variazioni che ti vengono in mente. Il punto è
questo: gli iteratori, sebbene siano un’astrazione di alto livello, vengono
compilati all’incirca nello stesso codice che si otterrebbe scrivendo il codice
di livello inferiore. Gli iteratori sono una delle astrazioni a costo zero di
Rust. Con questo intendiamo che l’utilizzo dell’astrazione non impone alcun
costo prestazionale aggiuntivo (overhead) in fase di esecuzione. Questo è
analogo a come Bjarne Stroustrup, il progettista e implementatore originale del
C++, definisce zero-overhead nella sua presentazione a ETAPS 2012 “Foundations
of C++”:
In generale, le implementazioni del C++ obbediscono al principio di zero-overhead: ciò che non usi, non paghi. E inoltre: ciò che usi, non potresti scriverlo meglio a mano.
In molti casi, il codice Rust che utilizza gli iteratori viene compilato nello stesso assembly che scriveresti a mano. Ottimizzazioni come lo srotolamento dei cicli e l’eliminazione dei limiti di controllo sull’accesso agli array si applicano e rendono il codice risultante estremamente efficiente. Ora che lo sai, puoi usare iteratori e chiusure senza timore! Fanno sembrare il codice di livello superiore, ma non impongono una penalizzazione alle prestazioni in fase di esecuzione.
Riepilogo
Chiusure e iteratori sono funzionalità di Rust ispirate alle idee dei linguaggi di programmazione funzionale. Contribuiscono alla capacità di Rust di esprimere chiaramente idee di alto livello con prestazioni di basso livello. Le implementazioni di chiusure e iteratori sono tali da non compromettere le prestazioni in fase di esecuzione. Questo fa parte dell’obiettivo di Rust di fornire astrazioni a costo zero.
Ora che abbiamo migliorato l’espressività del nostro progetto I/O, diamo
un’occhiata ad altre funzionalità di cargo che ci aiuteranno a condividere il
progetto con il mondo.
Maggiori informazioni su Cargo e Crates.io
Finora abbiamo utilizzato solo le funzioni più basilari di Cargo per costruire, eseguire e testare il nostro codice, ma può fare molto di più. In questo capitolo parleremo di alcune delle sue funzioni più avanzate per mostrarti come fare quanto segue:
- Personalizzare la tua build tramite i profili di rilascio.
- Pubblicare le librerie su crates.io.
- Organizzare progetti di grandi dimensioni con gli spazi di lavoro.
- Installare i binari da crates.io.
- Estendere Cargo usando comandi personalizzati.
Cargo può fare molto di più di quanto descritto in questo capitolo: per una spiegazione completa di tutte le sue caratteristiche, consulta la sua documentazione.
Personalizzare le Build con i Profili di Rilascio
In Rust, i profili di rilascio (release profiles) sono profili predefiniti, personalizzabili con diverse configurazioni che permettono al programmatore di avere un maggiore controllo sulle varie opzioni di compilazione del codice. Ogni profilo è configurato in modo indipendente dagli altri.
Cargo ha due profili principali: il profilo dev che Cargo utilizza quando
esegui cargo build e il profilo release che Cargo utilizza quando esegui
cargo build --release. Il profilo dev è definito con buoni valori
predefiniti per lo sviluppo, mentre il profilo release ha buoni valori
predefiniti per le build di rilascio.
I nomi di questi profili potrebbero esserti familiari dall’output che hai visto finora quando compilavi il tuo codice:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
I profili dev e release sono i diversi profili utilizzati dal compilatore.
Cargo ha delle impostazioni predefinite per ogni profilo che si applicano quando
non hai aggiunto esplicitamente alcuna sezione [profile.*] nel file
Cargo.toml del progetto. Aggiungendo le sezioni [profile.*] per ogni profilo
che vuoi personalizzare, puoi sovrascrivere qualsiasi sottoinsieme delle
impostazioni predefinite. Ad esempio, ecco i valori predefiniti per
l’impostazione opt-level per i profili dev e release:
File: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
L’impostazione opt-level controlla il numero di ottimizzazioni che Rust
applicherà al tuo codice, con un range che va da 0 a 3. L’applicazione di più
ottimizzazioni allunga i tempi di compilazione, quindi se sei in fase di
sviluppo e compili spesso il tuo codice, vorrai meno ottimizzazioni per
compilare più velocemente anche se il codice risultante avrà prestazioni non
ottimali. Il livello opt-level predefinito per dev è quindi 0. Quando sei
pronto a rilasciare il tuo codice, è meglio dedicare più tempo alla
compilazione. Compilerai in modalità release una sola volta, ma eseguirai il
programma compilato molte volte, quindi la modalità release scambia un tempo
di compilazione più lungo con un eseguibile più prestazionale. Ecco perché
opt-level predefinito per il profilo release è 3.
Puoi sovrascrivere un’impostazione predefinita aggiungendo un valore diverso nel file Cargo.toml. Ad esempio, se vogliamo utilizzare il livello di ottimizzazione 1 nel profilo di sviluppo, possiamo aggiungere queste due righe al file Cargo.toml del nostro progetto:
File: Cargo.toml
[profile.dev]
opt-level = 1
Questo codice sovrascrive l’impostazione predefinita di 0. Ora, quando
lanciamo cargo build, Cargo utilizzerà le impostazioni predefinite per il
profilo dev più la nostra personalizzazione di opt-level. Poiché abbiamo
impostato opt-level a 1, Cargo applicherà un maggior numero di
ottimizzazioni rispetto a quelle predefinite, ma non così tante come in una
build di rilascio.
Per l’elenco completo delle opzioni di configurazione e dei valori predefiniti per ogni profilo, consulta la documentazione di Cargo.
Pubblicare un Crate su Crates.io
Abbiamo utilizzato i pacchetti di crates.io come dipendenze del nostro progetto, ma puoi anche condividere il tuo codice con altre persone pubblicando i tuoi pacchetti. Il registro dei crate di crates.io distribuisce il codice sorgente dei tuoi pacchetti, quindi ospita principalmente codice open source.
Rust e Cargo hanno delle funzioni che rendono il tuo pacchetto pubblicato più facile da trovare e da usare. Parleremo di alcune di queste funzioni e poi spiegheremo come pubblicare un pacchetto.
Nota di traduzione: Quando si realizza documentazione è buona pratica che sia scritta in un linguaggio internazionale come l’inglese. In questo capitolo si è deciso di tradurre anche la documentazione del codice in italiano per facilitare la comprensione, ma se vorrai pubblicare codice e la relativa documentazione è consigliabile farlo in inglese.
Commentare il Codice a Fini di Documentazione
Documentare accuratamente i tuoi pacchetti aiuterà gli altri utenti a sapere
come e quando usarli, quindi vale la pena investire del tempo per scrivere la
documentazione. Nel Capitolo 3 abbiamo parlato di come commentare il codice di
Rust usando due barre, //. Rust ha anche un particolare tipo di commento per
la documentazione, noto come commento di documentazione, che genererà la
documentazione HTML. L’HTML mostra il contenuto dei commenti di documentazione
per gli elementi API pubblici destinati ai programmatori interessati a sapere
come usare il tuo crate piuttosto che come il tuo crate è implementato.
I commenti di documentazione utilizzano tre barre, ///, invece di due e
supportano la notazione Markdown per la formattazione del testo. Posiziona i
commenti di documentazione subito prima dell’elemento che stanno documentando.
Il Listato 14-1 mostra i commenti di documentazione per una funzione più_uno
in un crate chiamato mio_crate
/// Aggiunge uno al numero dato.
///
/// # Esempi
///
/// ```
/// let arg = 5;
/// let risposta = mio_crate::più_uno(arg);
///
/// assert_eq!(6, risposta);
/// ```
pub fn più_uno(x: i32) -> i32 {
x + 1
}Qui diamo una descrizione di cosa fa la funzione più_uno, iniziamo una sezione
con l’intestazione Esempi (Examples) e poi forniamo del codice che dimostra
come utilizzare la funzione più_uno. Possiamo generare la documentazione HTML
da questo commento di documentazione eseguendo cargo doc. Questo comando
esegue lo strumento rustdoc distribuito con Rust e mette la documentazione
HTML generata nella cartella target/doc.
Per comodità, eseguendo cargo doc --open si costruisce l’HTML della
documentazione del tuo crate attuale (così come la documentazione di tutte le
dipendenze del tuo crate) e si apre il risultato in un browser web. Naviga
alla funzione più_uno per vedere che il testo nei commenti di documentazione
apparirà come mostrato nella Figura 14-1.
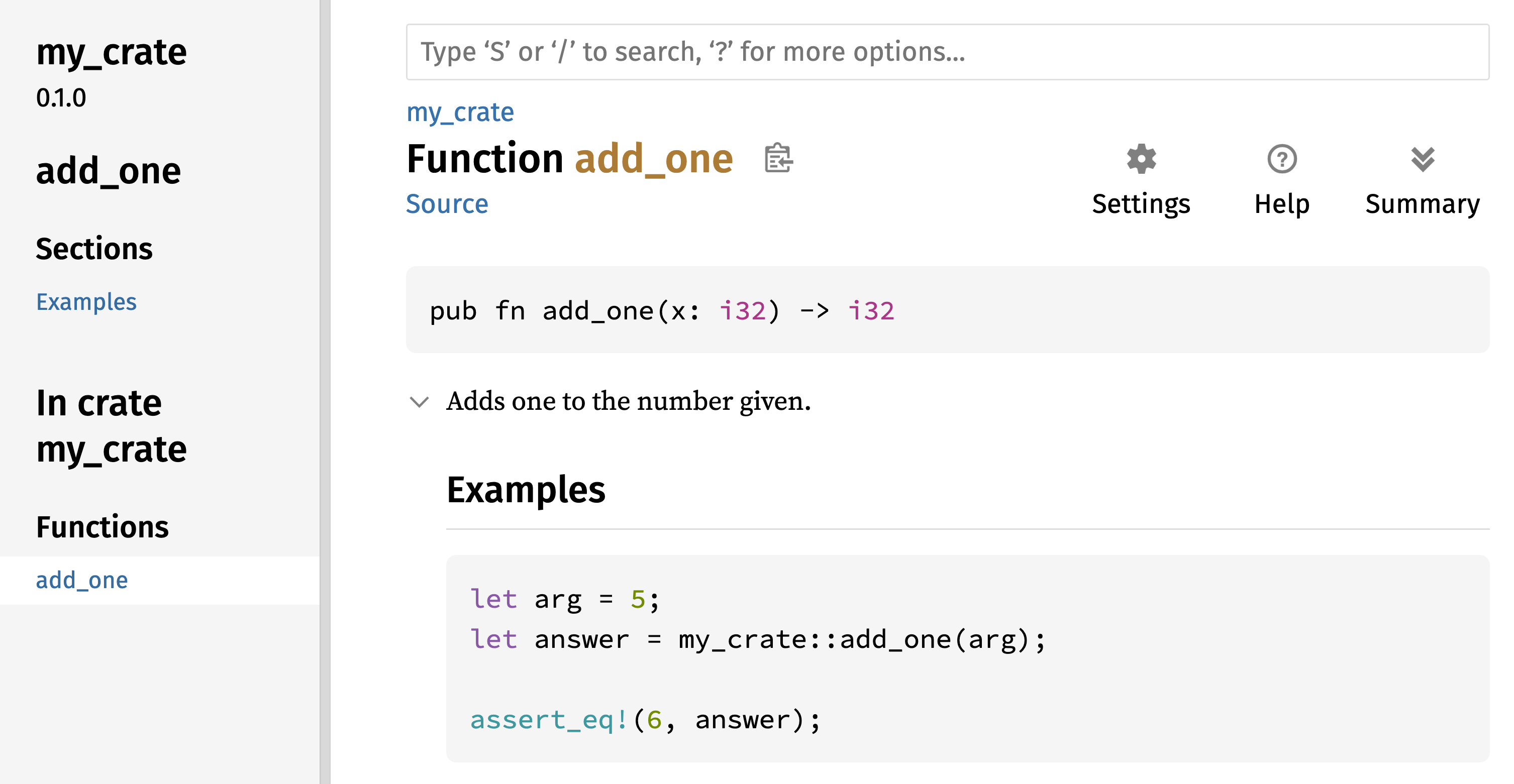
Figura 14-1: La documentazione HTML per la funzione
più_uno
Sezioni Comunemente Utilizzate
Abbiamo usato l’intestazione Markdown # Esempi nel Listato 14-1 per creare una
sezione nell’HTML con il titolo “Esempi”. Ecco altre sezioni che gli autori di
crate utilizzano comunemente nella loro documentazione:
- Panic (Panics): Questi sono gli scenari in cui la funzione documentata potrebbe andare in panic. I chiamanti della funzione che non vogliono che i loro programmi vadano in panic devono assicurarsi di non chiamare la funzione in queste situazioni.
- Errori (Errors): Se la funzione restituisce un
Result, descrivere la tipologia di errori che potrebbero verificarsi e quali condizioni potrebbero causare la restituzione di tali errori può essere utile ai chiamanti, in modo che possano scrivere codice per gestire i diversi tipi di errore in modi diversi. - Sicurezza (Safety): Se la funzione è
unsafe(ne parliamo nel Capitolo 20), deve essere presente una sezione che spieghi perché la funzione non è sicura e che descriva gli invarianti che la funzione si aspetta che i chiamanti rispettino.
La maggior parte dei commenti di documentazione non ha bisogno di tutte queste sezioni, ma questa è una buona lista da controllare per ricordarti gli aspetti del tuo codice che gli utenti saranno interessati a conoscere.
Commenti di Documentazione Come Test
L’aggiunta di blocchi di codice di esempio nei commenti di documentazione può
aiutare a dimostrare l’uso della libreria e ha un ulteriore vantaggio:
l’esecuzione di cargo test eseguirà gli esempi di codice nella documentazione
come test! Non c’è niente di meglio di una documentazione con esempi, ma non c’è
niente di peggio di esempi che non funzionano perché il codice è cambiato da
quando è stata scritta la documentazione. Se eseguiamo cargo test con la
documentazione della funzione più_uno del Listato 14-1, vedremo una sezione
nei risultati del test che assomiglia a questa:
Doc-tests mio_crate
running 1 test
test src/lib.rs - più_uno (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Ora, se modifichiamo la funzione o l’esempio in modo che assert_eq!
nell’esempio vada in panic, ed eseguiamo di nuovo cargo test, vedrai che i
Doc-tests rileveranno che l’esempio e il codice non sono compatibili tra loro!
Commentare l’Elemento Contenitore
Lo stile dei commenti di documentazione //! aggiunge la documentazione
all’elemento che contiene i commenti piuttosto che agli elementi che seguono
i commenti. Di solito usiamo questi commenti di documentazione all’interno del
file radice del crate (src/lib.rs per convenzione) o all’interno di un
modulo per documentare il crate o il modulo nel suo complesso.
Ad esempio, per aggiungere la documentazione che descrive lo scopo del crate
mio_crate che contiene la funzione più_uno, aggiungiamo i commenti di
documentazione che iniziano con //! all’inizio del file src/lib.rs, come
mostrato nel Listato 14-2.
//! # Mio Crate
//!
//! `mio_crate` è una collezione di funzioni per compiere
//! certi calcoli più facilmente.
/// Aggiunge uno al numero dato.
// --taglio--
///
/// # Esempi
///
/// ```
/// let arg = 5;
/// let risposta = mio_crate::più_uno(arg);
///
/// assert_eq!(6, risposta);
/// ```
pub fn più_uno(x: i32) -> i32 {
x + 1
}mio_crateNota che non c’è codice dopo l’ultima riga che inizia con //!. Poiché abbiamo
iniziato i commenti con //! invece che con //, stiamo documentando
l’elemento che contiene questo commento piuttosto che un elemento che segue
questo commento. In questo caso, questo elemento è il file src/lib.rs stesso,
che è la radice del crate. Questi commenti descrivono quindi l’intero crate.
Quando si esegue cargo doc --open, questi commenti verranno visualizzati nella
prima pagina della documentazione di mio_crate sopra l’elenco degli elementi
pubblici del crate, come mostrato nella Figura 14-2.
I commenti di documentazione all’interno degli elementi sono utili soprattutto per descrivere i crate e i moduli. Utilizzali per spiegare lo scopo generale del contenitore per aiutare i tuoi utenti a capire l’organizzazione del crate.
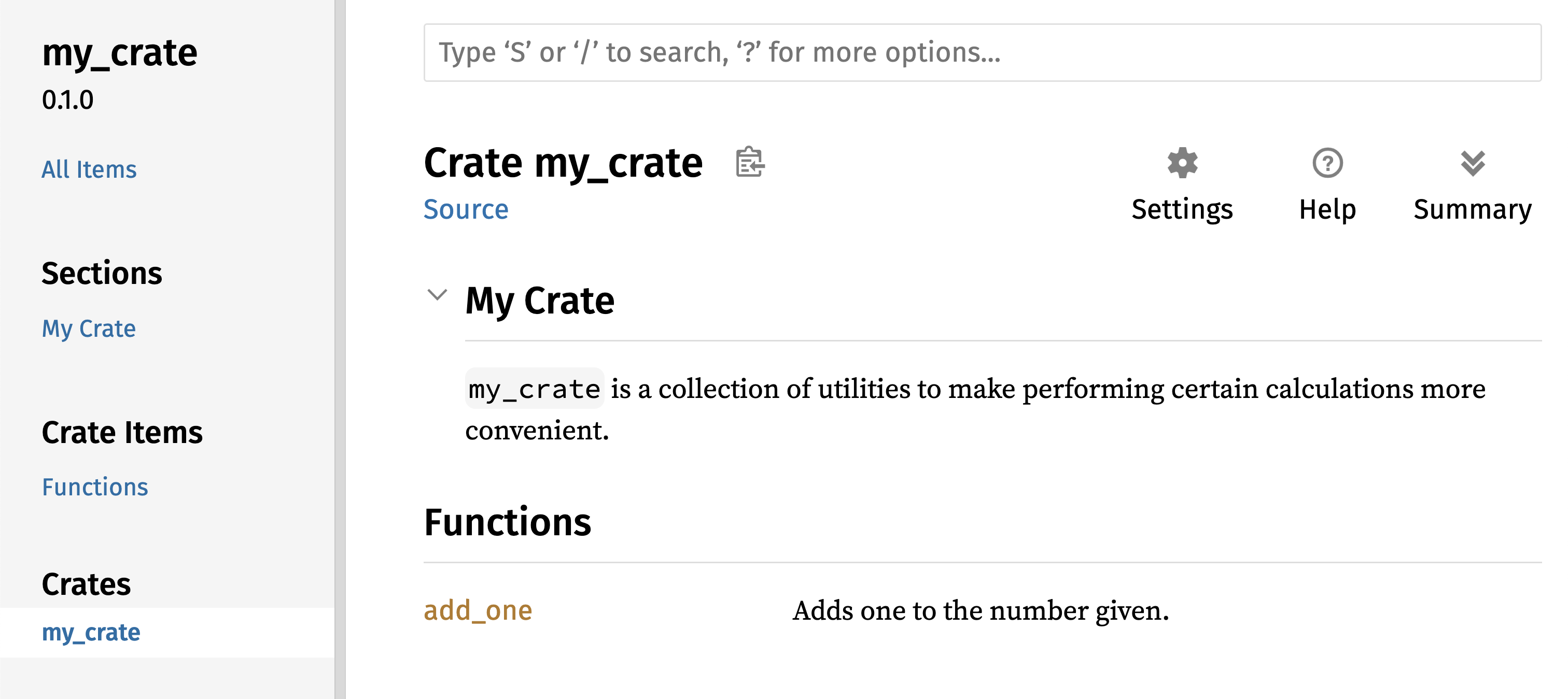
Figura 14-2: La documentazione renderizzata per
mio_crate, incluso il commento che descrive il crate nel suo
complesso
Esportare un API Pubblica Efficace
La struttura della tua API pubblica è una considerazione importante quando pubblichi un crate. Le persone che usano il tuo crate hanno meno familiarità con la struttura di te e potrebbero avere difficoltà a trovare i pezzi che vogliono usare se il tuo crate ha una gerarchia di moduli estesa.
Nel Capitolo 7 abbiamo visto come rendere pubblici gli elementi con la parola
chiave pub e come portare gli elementi nello scope con la parola chiave
use. Tuttavia, la struttura che ha senso per te mentre sviluppi un crate
potrebbe non essere molto comoda per i tuoi utenti. Potresti voler organizzare
le tue struct in una gerarchia che contiene più livelli, ma chi vuole usare un
type che hai definito in profondità nella gerarchia potrebbe avere problemi a
scoprire l’esistenza di quel type. Potrebbe anche essere infastidito dal fatto
di dover scrivere use mio_crate::un_modulo::altro_modulo::TypeUtile; piuttosto
che use mio_crate::TypeUtile;.
La buona notizia è che se la struttura non è facile per gli altri da usare da
un’altra libreria, non devi modificare la tua organizzazione interna: puoi
invece riesportare gli elementi per creare una struttura pubblica diversa da
quella privata usando pub use. Riesportare prende un elemento pubblico in
una posizione e lo rende pubblico in un’altra posizione, come se fosse stato
definito nell’altra posizione.
Ad esempio, supponiamo di aver creato una libreria chiamata arte per modellare
concetti artistici. All’interno di questa libreria ci sono due moduli: un modulo
tipologia contenente due enum chiamate ColorePrimario e ColoreSecondario
e un modulo utilità contenente una funzione chiamata mix, come mostrato nel
Listato 14-3.
//! # Arte
//!
//! Una libreria per modellare concetti artistici.
pub mod tipologia {
/// I colori primari secondo il modello RYB.
pub enum ColorePrimario {
Rosso,
Giallo,
Blu,
}
/// I colori secondari secondo il modello RYB.
pub enum ColoreSecondario {
Arancio,
Verde,
Viola,
}
}
pub mod utilità {
use crate::tipologia::*;
/// Combina due colori primari in egual quantità
/// per formare un colore secondario.
pub fn mix(c1: ColorePrimario, c2: ColorePrimario) -> ColoreSecondario {
// --taglio--
unimplemented!();
}
}arte con elementi organizzati nei moduli tipologia e utilitàLa Figura 14-3 mostra l’aspetto della prima pagina della documentazione di
questo crate generata da cargo doc.
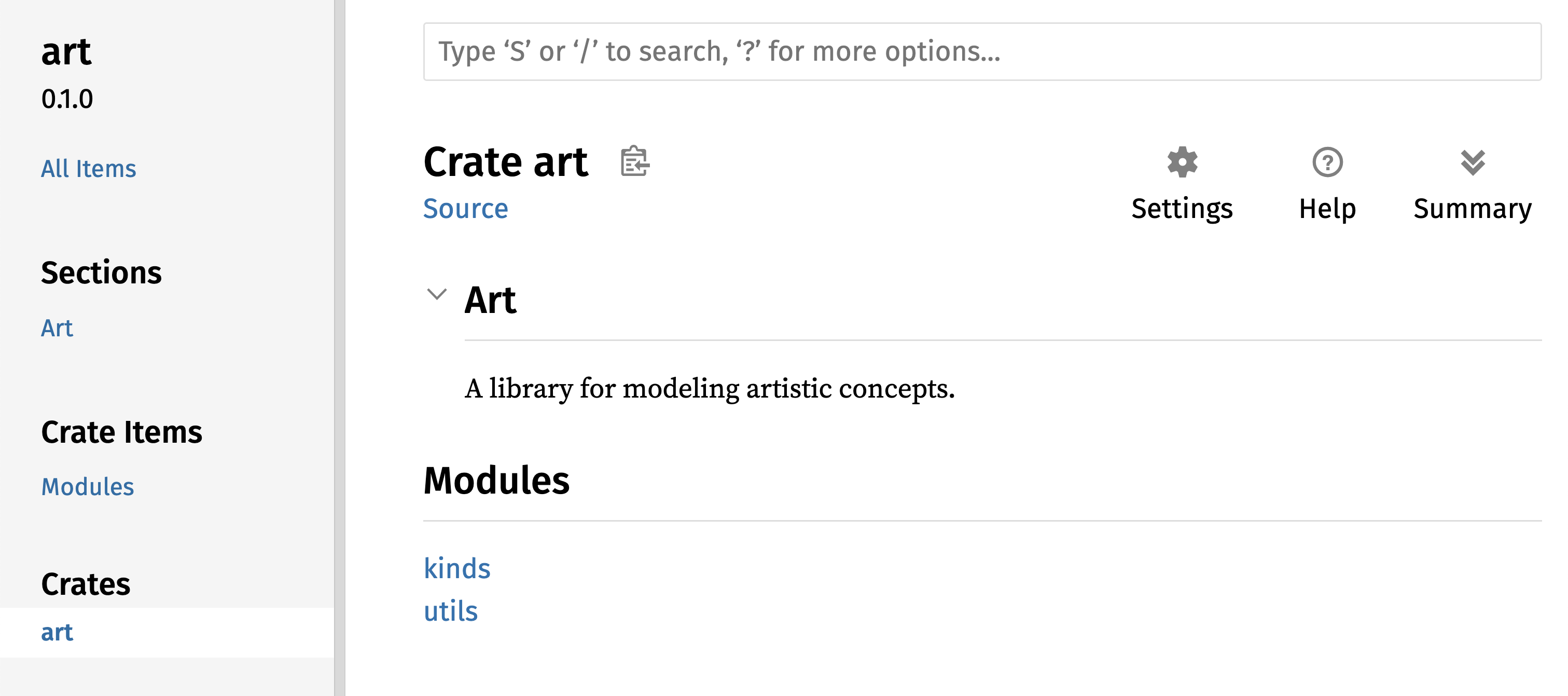
Figura 14-3: La prima pagina della documentazione per
arte che elenca i moduli tipologia e utilità
Nota che i type ColorePrimario e ColoreSecondario non sono elencati nella
prima pagina, così come la funzione mix. Dobbiamo cliccare su tipologia e
utilità per vederli.
Un altro crate che dipende da questa libreria avrebbe bisogno di dichiarazioni
use che portino gli elementi di arte nello scope, specificando la
struttura del modulo attualmente definita. Il Listato 14-4 mostra un esempio di
crate che utilizza gli elementi ColorePrimario e mix del crate arte.
use arte::tipologia::ColorePrimario;
use arte::utilità::mix;
fn main() {
let rosso = ColorePrimario::Rosso;
let giallo = ColorePrimario::Giallo;
mix(rosso, giallo);
}arte con la sua struttura interna esportataL’autore del codice del Listato 14-4, che utilizza il crate arte, ha dovuto
capire che ColorePrimario si trova nel modulo tipologia e mix nel modulo
utilità. La struttura dei moduli del crate arte è più importante per gli
sviluppatori che lavorano sul crate arte che per quelli che lo utilizzano.
La struttura interna non contiene informazioni utili per chi cerca di capire
come utilizzare il crate arte, ma piuttosto crea confusione perché gli
sviluppatori che lo utilizzano devono capire dove cercare e devono specificare i
nomi dei moduli nelle dichiarazioni use.
Per rimuovere l’organizzazione interna dall’API pubblica, possiamo modificare il
codice nel crate arte del Listato 14-3 per aggiungere le dichiarazioni pub use per riesportare gli elementi al livello superiore, come mostrato nel
Listato 14-5.
//! # Arte
//!
//! Una libreria per modellare concetti artistici.
pub use self::tipologia::ColorePrimario;
pub use self::tipologia::ColoreSecondario;
pub use self::utilità::mix;
pub mod tipologia {
// --taglio--
/// I colori primari secondo il modello RYB.
pub enum ColorePrimario {
Rosso,
Giallo,
Blu,
}
/// I colori secondari secondo il modello RYB.
pub enum ColoreSecondario {
Arancio,
Verde,
Viola,
}
}
pub mod utilità {
// --taglio--
use crate::tipologia::*;
/// Combina due colori primari in egual quantità
/// per formare un colore secondario.
pub fn mix(c1: ColorePrimario, c2: ColorePrimario) -> ColoreSecondario {
ColoreSecondario::Arancio
}
}pub use per riesportare elementiLa documentazione API che cargo doc genera per questo crate ora elencherà e
collegherà le riesportazioni (Re-exports) nella prima pagina, come mostrato
nella Figura 14-4, rendendo più facile trovare i type ColorePrimario e
ColoreSecondario e la funzione mix.
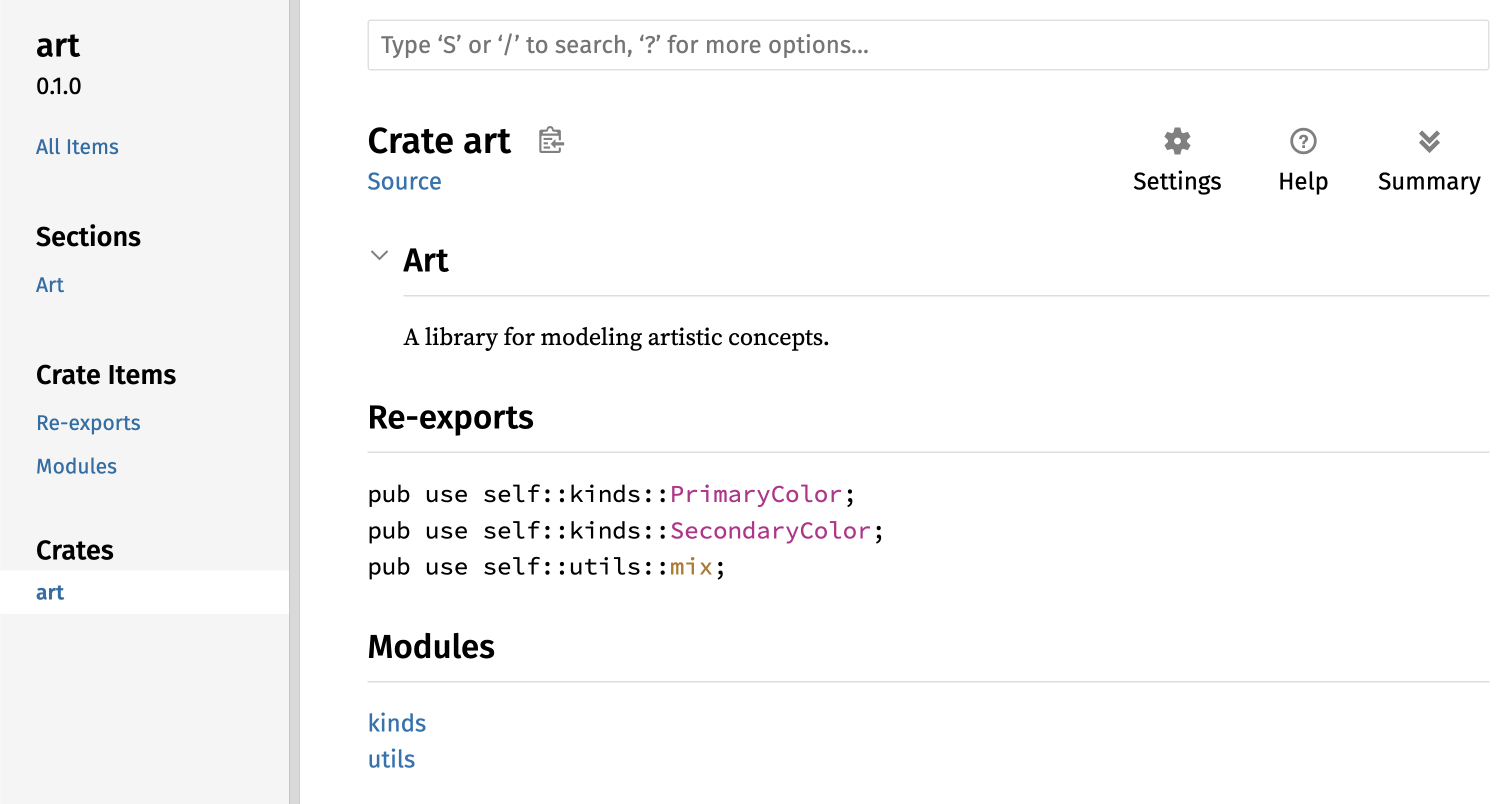
Figura 14-4: La prima pagina della documentazione per
arte che elenca le riesportazioni
Gli utenti del crate arte possono ancora vedere e usare la struttura interna
del Listato 14-3, come dimostrato nel Listato 14-4, oppure possono usare la
struttura più comoda del Listato 14-5, come mostrato nel Listato 14-6.
use arte::ColorePrimario;
use arte::mix;
fn main() {
// --taglio--
let rosso = ColorePrimario::Rosso;
let giallo = ColorePrimario::Giallo;
mix(rosso, giallo);
}arteNei casi in cui ci sono molti moduli annidati, riesportare i type al livello
superiore con pub use può fare una differenza significativa nell’esperienza
delle persone che utilizzano il crate. Un altro uso comune di pub use è
quello di riesportare le definizioni di una dipendenza nel crate corrente per
rendere le definizioni di quel crate parte dell’API pubblica del tuo crate.
Creare una struttura API pubblica efficace è più un’arte che una scienza e puoi
iterare per trovare l’API che funziona meglio per i tuoi utenti. Scegliere pub use ti dà flessibilità nel modo in cui strutturi il tuo crate internamente e
disaccoppia la struttura interna da quella che presenti ai tuoi utenti. Guarda
il codice di alcuni crate che hai installato per vedere se la loro struttura
interna differisce dalla loro API pubblica.
Creare un Account Crates.io
Prima di poter pubblicare qualsiasi crate, devi creare un account su
crates.io e ottenere un token API. Per
farlo, visita la home page di crates.io e accedi con un account GitHub
(attualmente l’account GitHub è un requisito, ma il sito potrebbe supportare
altri modi di creare un account in futuro). Una volta effettuato l’accesso,
visita le impostazioni del tuo account su
https://crates.io/me/ e genera la nuova
chiave API. Quindi esegui il comando cargo login e incolla la tua chiave API
quando ti viene richiesto, in questo modo:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Questo comando informerà Cargo del tuo token API e lo memorizzerà localmente in ~/.cargo/credentials.toml. Nota che questo token è segreto: non condividerlo con nessun altro. Se lo condividi con qualcuno per qualsiasi motivo, devi revocarlo e generare un nuovo token su crates.io.
Aggiungere Metadati a un Nuovo Crate
Supponiamo che tu abbia un crate che vuoi pubblicare. Prima di pubblicarlo,
dovrai aggiungere alcuni metadati nella sezione [package] del file
Cargo.toml del crate.
Il tuo crate avrà bisogno di un nome univoco. Mentre stai lavorando su un
crate in locale, puoi dargli il nome che preferisci. Tuttavia, i nomi dei
crate su crates.io sono assegnati in base
all’ordine di arrivo. Una volta che il nome di un crate è stato preso, nessun
altro può pubblicare un crate con quel nome. Prima di provare a pubblicare un
crate, cerca il nome che vuoi usare. Se il nome è già stato usato, dovrai
trovarne un altro e modificare il campo name nel file Cargo.toml sotto la
sezione [package] per usare il nuovo nome per la pubblicazione, in questo
modo:
File: Cargo.toml
[package]
name = "gioco_indovinello"
Anche se hai scelto un nome unico, quando esegui cargo publish per pubblicare
il crate a questo punto, riceverai un avviso e poi un errore simili a questo:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
-- test compilazione --
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Questo genera un errore perché mancano alcune informazioni cruciali: una
descrizione e una licenza sono necessarie affinché le persone sappiano cosa fa
la il tuo crate e a quali condizioni possono utilizzarla. In Cargo.toml,
aggiungi una descrizione che sia solo una frase o due, perché apparirà insieme
al tuo crate nei risultati di ricerca. Per il campo license, devi indicare
un valore identificativo della licenza. Il Linux Foundation’s Software
Package Data Exchange (SPDX) elenca gli identificativi che puoi usare per
questo valore. Per esempio, per specificare che hai concesso in licenza il tuo
crate usando la MIT License, aggiungi l’identificativo MIT:
File: Cargo.toml
[package]
name = "gioco_indovinello"
license = "MIT"
Se vuoi usare una licenza che non compare nell’SPDX, devi inserire il testo
della licenza in un file, includere il file nel tuo progetto e poi usare
license-file per specificare il nome del file invece di usare la chiave
license.
Orientarti su quale licenza sia appropriata per il tuo progetto va oltre lo
scopo di questo libro. Molte persone nella comunità di Rust concedono la licenza
per i loro progetti nello stesso modo di Rust, utilizzando una doppia licenza
MIT OR Apache-2.0. Questa pratica dimostra che puoi anche specificare più
identificatori di licenza separati da OR per avere più licenze per il tuo
progetto.
Con un nome univoco, la versione, la tua descrizione e la licenza aggiunta, il file Cargo.toml per un progetto pronto per la pubblicazione potrebbe assomigliare a questo
File: Cargo.toml
[package]
name = "gioco_indovinello"
version = "0.1.0"
edition = "2024"
description = "Un giochino divertente dove tenti di indovinare un numero casuale."
license = "MIT OR Apache-2.0"
[dependencies]
Nella documentazione di Cargo trovi la descrizione di altri metadati che puoi specificare per far sì che gli altri possano scoprire e utilizzare il tuo crate più facilmente.
Pubblicare su Crates.io
Ora che hai creato un account, salvato il tuo token API, scelto un nome per il tuo crate e specificato i metadati richiesti, sei pronto a pubblicare! Pubblicare un crate carica una versione specifica su crates.io affinché altri possano utilizzarla.
Fai attenzione, perché una pubblicazione è permanente. La versione non può mai essere sovrascritta e il codice non può essere cancellato se non in determinate circostanze. Uno degli obiettivi principali di Crates.io è quello di fungere da archivio permanente del codice in modo che le compilazioni di tutti i progetti che dipendono dai crate di crates.io continuino a funzionare. Consentire la cancellazione delle versioni renderebbe impossibile il raggiungimento di questo obiettivo. Tuttavia, non c’è limite al numero di versioni del crate che puoi pubblicare.
Esegui di nuovo il comando cargo publish: ora dovrebbe andare a buon fine:
$ cargo publish
Updating crates.io index
Packaging gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Compiling gioco_indovinello v0.1.0
(file:///progetti/gioco_indovinello/target/package/gioco_indovinello-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading gioco_indovinello v0.1.0 (file:///progetti/gioco_indovinello)
Uploaded gioco_indovinello v0.1.0 to registry `crates-io`
note: waiting for `gioco_indovinello v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published gioco_indovinello v0.1.0 at registry `crates-io`
Congratulazioni, ora hai condiviso il tuo codice con la comunità di Rust e chiunque può facilmente aggiungere il tuo crate come dipendenza del proprio progetto.
Pubblicare una Nuova Versione di un Crate
Quando hai apportato delle modifiche al tuo crate e sei pronto a rilasciare
una nuova versione, cambia il valore version specificato nel file Cargo.toml
e ripubblica. Utilizza le regole di Versionamento Semantico per
decidere quale sia il numero di versione successivo più appropriato, in base
alla tipologia di modifiche apportate. Quindi esegui cargo publish per
caricare la nuova versione.
Deprecare Versioni da Crates.io
Sebbene non sia possibile rimuovere le versioni precedenti di un crate, puoi impedire a qualsiasi progetto futuro di aggiungerle come nuova dipendenza. Questo è utile quando una versione del crate è mal funzionante per un motivo o per l’altro. In queste situazioni, Cargo supporta la disabilitazione di una versione del crate.
Disabilitare una versione impedisce ai nuovi progetti di dipendere da quella versione, mentre permette a tutti i progetti esistenti che dipendono da essa di continuare. In sostanza, una disabilitazione significa che tutti i progetti con un Cargo.lock non si romperanno e tutti i futuri file Cargo.lock generati non utilizzeranno la versione disabilitata.
Per disabilitare una versione del crate, nella directory del crate che hai
pubblicato in precedenza, esegui cargo yank e specifica quale versione vuoi
disabilitare. Ad esempio, se hai pubblicato un crate chiamato
gioco_indovinello nella versione 1.0.1 e vuoi disabilitarla, nella directory
del progetto per gioco_indovinello dovrai eseguire:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank gioco_indovinello@1.0.1
Aggiungendo --undo al comando, puoi anche annullare una disabilitazione, in
pratica riabilitare, e permettere ai progetti di ricominciare a dipendere da
quella versione:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank gioco_indovinello@1.0.1
Quando disabiliti una versione non cancelli alcun codice. Non puoi, ad esempio, cancellare dati sensibili (chiavi API, password, ecc.) che per errore hai caricato accidentalmente. Se ciò accadesse, devi immediatamente ripristinare e cambiare quei dati sensibili.
Spazi di Lavoro Cargo
Nel Capitolo 12 abbiamo costruito un pacchetto che includeva un crate binario e un crate libreria. Man mano che il tuo progetto si sviluppa, potresti scoprire che il crate libreria continua a diventare più grande e vorresti dividere ulteriormente il tuo pacchetto in più crate libreria. Cargo offre una funzione chiamata spazi di lavoro (workspace) che può aiutarti a gestire più pacchetti correlati che vengono sviluppati in tandem.
Creare un Workspace
Uno spazio di lavoro è un insieme di pacchetti che condividono lo stesso
Cargo.lock e la stessa directory di output. Creiamo un progetto utilizzando un
workspace: useremo del codice banale in modo da poterci concentrare sulla
struttura del workspace. Esistono diversi modi per strutturare uno spazio di
lavoro, quindi ci limiteremo a mostrarne uno comune. Avremo un workspace
contenente un binario e due librerie. Il binario, che fornirà la funzionalità
principale, dipenderà dalle due librerie. Una libreria fornirà una funzione
più_uno e l’altra libreria una funzione più_due. Questi tre crate faranno
parte dello stesso workspace. Inizia creando una nuova cartella per lo spazio
di lavoro:
Nota di traduzione: per i nomi di crate non è possibile utilizzare caratteri non-ASCII, a differenza della possibilità di utilizzo nei nomi di funzione. Si è scelto di usare quindi sia
piu_unochepiù_unoper rimarcare questa differenza. Fai quindi attenzione.
$ mkdir somma
$ cd somma
Successivamente, nella cartella somma, creiamo il file Cargo.toml che
configurerà l’intero workspace. Questo file non avrà una sezione [package],
ma inizierà con una sezione [workspace] che ci permetterà di aggiungere membri
al workspace. Inoltre, esplicitiamo di voler usare l’ultima versione
dell’algoritmo di risoluzione delle dipendenze di Cargo nel nostro spazio di
lavoro, impostando il valore resolver a "3":
File: Cargo.toml
[workspace]
resolver = "3"
Successivamente, creeremo il crate binario sommatore eseguendo cargo new
nella cartella somma:
$ cargo new sommatore
Created binary (application) `sommatore` package
Adding `sommatore` as member of workspace at `file:///progetti/somma`
L’esecuzione di cargo new all’interno di uno spazio di lavoro aggiunge
automaticamente il pacchetto appena creato alla chiave members nella
definizione [workspace] del file Cargo.toml, in questo modo:
[workspace]
resolver = "3"
members = ["sommatore"]
A questo punto, possiamo costruire l’intero workspace con cargo build. I
file nella tua cartella somma dovrebbero avere questo aspetto:
somma
├── Cargo.lock
├── Cargo.toml
├── sommatore
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Lo spazio di lavoro ha una cartella target al livello superiore in cui
verranno inseriti gli artefatti compilati; il pacchetto sommatore non ha una
propria cartella target. Anche se dovessimo eseguire cargo build
dall’interno della cartella sommatore, gli artefatti compilati finirebbero
comunque in somma/target piuttosto che in somma/sommatore/target. Cargo
struttura la cartella target in uno spazio di lavoro in questo modo perché i
crate in un workspace sono destinati a dipendere l’uno dall’altro. Se ogni
crate avesse la propria cartella target, ogni crate dovrebbe ricompilare
ogni altro crate nello spazio di lavoro per posizionare gli artefatti nella
propria cartella target. Condividendo una cartella target, i crate possono
evitare inutili ricostruzioni.
Creare un Secondo Pacchetto nel Workspace
Ora creiamo un altro pacchetto membro dell’area di lavoro e chiamiamolo
piu_uno. Generiamo un nuovo crate libreria chiamato piu_uno:
$ cargo new piu_uno --lib
Created library `piu_uno` package
Adding `piu_uno` as member of workspace at `file:///progetti/somma`
Il file Cargo.toml nella cartella somma ora includerà il percorso piu_uno
nell’elenco dei membri members:
File: Cargo.toml
[workspace]
resolver = "3"
members = ["sommatore", "piu_uno"]
La tua cartella somma dovrebbe ora contenere queste cartelle e questi file:
somma
├── Cargo.lock
├── Cargo.toml
├── piu_uno
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── sommatore
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Nel file piu_uno/src/lib.rs, aggiungiamo una funzione più_uno:
File: piu_uno/src/lib.rs
pub fn più_uno(x: i32) -> i32 {
x + 1
}Ora possiamo fare in modo che il pacchetto sommatore con il nostro binario
dipenda dal pacchetto piu_uno che contiene la nostra libreria. Per prima cosa,
dovremo aggiungere un percorso di dipendenza a piu_uno nel file
sommatore/Cargo.toml.
File: sommatore/Cargo.toml
[dependencies]
piu_uno = { path = "../piu_uno" }
Cargo non presuppone che i crate dello stesso workspace dipendano l’uno dall’altro, quindi dobbiamo essere espliciti sulle relazioni di dipendenza.
Quindi, utilizziamo la funzione più_uno (dal crate piu_uno) nel crate
sommatore. Apri il file sommatore/src/main.rs e modifica la funzione main
per richiamare la funzione più_uno, come nel Listato 14-7
fn main() {
let num = 10;
println!("Ciao! {num} più uno fa {}!", piu_uno::più_uno(num));
}piu_uno dal crate sommatoreCompiliamo lo spazio di lavoro eseguendo cargo build nella directory di primo
livello somma!
$ cargo build
Compiling piu_uno v0.1.0 (file:///progetti/somma/piu_uno)
Compiling sommatore v0.1.0 (file:///progetti/somma/sommatore)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Per eseguire il crate binario dalla directory somma, possiamo specificare
quale pacchetto del workspace vogliamo eseguire utilizzando l’argomento -p e
il nome del pacchetto con cargo run:
$ cargo run -p sommatore
Compiling sommatore v0.1.0 (file:///progetti/somma/sommatore)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/sommatore`
Ciao! 10 più uno fa 11!
Questo esegue il codice in sommatore/src/main.rs, che dipende dal crate
piu_uno.
Dipendere da un Pacchetto Esterno
Avrai notato che lo spazio di lavoro ha un solo file Cargo.lock al livello
superiore, invece di avere un Cargo.lock nella cartella di ogni crate.
Questo assicura che tutti i crate utilizzino la stessa versione di tutte le
dipendenze. Se aggiungiamo il pacchetto rand ai file sommatore/Cargo.toml e
piu_uno/Cargo.toml, Cargo li risolverà entrambi in un’unica versione di rand
e la registrerà nell’unico Cargo.lock. Fare in modo che tutti i crate nel
workspace utilizzino le stesse dipendenze significa che i crate saranno
sempre compatibili tra loro. Aggiungiamo il crate rand alla sezione
[dependencies] nel file piu_uno/Cargo.toml in modo da poter utilizzare il
crate rand nel crate piu_uno:
File: piu_uno/Cargo.toml
[dependencies]
rand = "0.8.5"
Ora possiamo aggiungere use rand; al file piu_uno/src/lib.rs e la creazione
dell’intero workspace eseguendo cargo build nella cartella somma
scaricherà e compilerà il crate rand. Riceveremo un avviso perché non stiamo
effettivamente usando rand che abbiamo portato nello scope:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--taglio--
Compiling rand v0.8.5
Compiling piu_uno v0.1.0 (file:///progetti/somma/piu_uno)
warning: unused import: `rand`
--> piu_uno/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `piu_uno` (lib) generated 1 warning (run `cargo fix --lib -p piu_uno` to apply 1 suggestion)
Compiling sommatore v0.1.0 (file:///progetti/somma/sommatore)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Il file Cargo.lock al livello più alto ora contiene informazioni sulla
dipendenza di piu_uno da rand. Tuttavia, anche se rand è utilizzato da
qualche parte nello spazio di lavoro, non possiamo utilizzarlo in altri crate
del workspace a meno che non aggiungiamo rand anche ai loro file
Cargo.toml. Ad esempio, se aggiungiamo use rand; al file
sommatore/src/main.rs per il pacchetto sommatore, otterremo un errore:
$ cargo build
--taglio--
Compiling sommatore v0.1.0 (file:///progetti/somma/sommatore)
error[E0432]: unresolved import `rand`
--> sommatore/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Per risolvere questo problema, modifica il file Cargo.toml per il pacchetto
sommatore e indica che rand è una dipendenza anche per esso. Costruendo il
pacchetto sommatore aggiungerà rand all’elenco delle dipendenze di
sommatore in Cargo.lock, ma non verranno scaricate copie aggiuntive di
rand. Cargo farà in modo che ogni crate in ogni pacchetto dell’area di
lavoro che utilizza il pacchetto rand utilizzi la stessa versione, a patto che
specifichi versioni compatibili di rand, risparmiando spazio e assicurando che
i crate nel workspace siano compatibili tra loro.
Se i crate nel workspace specificano versioni incompatibili della stessa dipendenza, Cargo risolverà ciascuna di esse, ma cercherà comunque di risolvere il minor numero possibile di versioni.
Aggiungere un Test a un Workspace
Per un altro miglioramento, aggiungiamo un test della funzione
piu_uno::più_uno all’interno del crate piu_uno:
File: piu_uno/src/lib.rs
pub fn più_uno(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn funziona() {
assert_eq!(3, più_uno(2));
}
}Ora esegui cargo test nella cartella di primo livello somma. Eseguendo
cargo test in un workspace strutturato come questo, verranno eseguiti i test
per tutti i crate presenti nello spazio di lavoro:
$ cargo test
Compiling piu_uno v0.1.0 (file:///progetti/somma/piu_uno)
Compiling sommatore v0.1.0 (file:///progetti/somma/sommatore)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/piu_uno-93c49ee75dc46543)
running 1 test
test tests::funziona ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/sommatore-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests piu_uno
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
La prima sezione dell’output mostra che il test funziona nel crate piu_uno
è passato. La sezione successiva mostra che sono stati trovati zero test nel
crate sommatore e l’ultima sezione mostra che sono stati trovati zero test
di documentazione nel crate piu_uno.
Possiamo anche eseguire i test per un particolare crate in un workspace
dalla directory di primo livello utilizzando il flag -p e specificando il
nome del crate che vogliamo testare:
$ cargo test -p piu_uno
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/piu_uno-93c49ee75dc46543)
running 1 test
test tests::funziona ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests piu_uno
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Questo output mostra che cargo test ha eseguito solo i test del crate
piu_uno e non ha eseguito i test del crate sommatore.
Se pubblichi i crate nello workspace su crates.io, ogni crate nello spazio di lavoro dovrà essere pubblicato
separatamente. Come nel caso di cargo test, possiamo pubblicare un particolare
crate nel nostro spazio di lavoro utilizzando il flag -p e specificando il
nome del crate che vogliamo pubblicare.
Per fare ulteriore pratica, aggiungi un crate piu_due a questo spazio di
lavoro in modo simile al crate piu_uno!
Quando il tuo progetto cresce, prendi in considerazione l’utilizzo di uno spazio di lavoro: ti permette di lavorare con componenti più piccoli e più facili da capire rispetto a un unico grande blocco di codice. Inoltre, mantenere i crate in uno spazio di lavoro può rendere più facile il coordinamento tra i crate se questi vengono spesso modificati nello stesso momento.
Installazione di Binari con cargo install
Il comando cargo install ti permette di installare e utilizzare localmente i
crate binari. Questo non è destinato a sostituire la gestione dei pacchetti di
sistema, ma è un modo comodo per gli sviluppatori di Rust di installare gli
strumenti che altri hanno condiviso su crates.io. Nota che puoi installare solo i pacchetti che hanno dei target
binari. Un target binario è il programma eseguibile che viene creato se il
crate ha un file src/main.rs o un altro file specificato come binario, in
contrapposizione a un target libreria che non è eseguibile da solo ma è adatto
per essere incluso in altri programmi. Di solito, i crate hanno informazioni
nel file README sul fatto che un crate è una libreria, è un binario o
entrambi.
Tutti i file binari installati con cargo install sono memorizzati nella
cartella bin della radice dell’installazione. Se hai installato Rust
utilizzando rustup e non hai configurazioni personalizzate, questa cartella
sarà $HOME/.cargo/bin. Assicurati che questa cartella sia presente nella tua
$PATH per poter eseguire i programmi che hai installato con cargo install.
Ad esempio, nel Capitolo 12 abbiamo accennato all’esistenza di
un’implementazione Rust dello strumento grep chiamata ripgrep per la ricerca
di file. Per installare ripgrep, possiamo usare il seguente comando:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--taglio--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
La penultima riga dell’output mostra la posizione e il nome del binario
installato, che nel caso di ripgrep è rg. Se la directory di installazione è
presente nel tuo $PATH, come detto in precedenza, puoi eseguire rg --help e
iniziare a usare uno strumento più veloce e più ruspante per la ricerca dei
file!
Estendere Cargo con Comandi Personalizzati
Cargo è stato progettato in modo che tu possa estenderlo con nuovi sotto-comandi
senza doverlo modificare. Se un binario nella tua $PATH si chiama
cargo-qualcosa, puoi eseguirlo come se fosse un sotto-comando di Cargo
eseguendo cargo qualcosa. I comandi personalizzati come questo sono anche
elencati quando esegui cargo --list. La possibilità di usare cargo install
per installare le estensioni e poi eseguirle proprio come gli strumenti
integrati di Cargo è un vantaggio super conveniente del design di Cargo!
Riepilogo
La condivisione di codice con Cargo e crates.io è parte di ciò che rende l’ecosistema Rust utile per molti compiti diversi. La libreria standard di Rust è piccola e stabile, ma i crate sono facili da condividere, usare e migliorare con una tempistica diversa da quella del linguaggio. Non essere timido nel condividere il codice che ti è utile su crates.io; è probabile che sia utile anche a qualcun altro!
Puntatori Intelligenti
Un puntatore è un concetto generale che rappresenta una variabile che contiene
un indirizzo in memoria. Questo indirizzo fa riferimento, o “punta a”, altri
dati. Il tipo più comune di puntatore in Rust è un reference, come hai
imparato nel Capitolo 4. I reference sono indicati dal simbolo & e prendono
in prestito il valore a cui puntano. Non hanno capacità speciali oltre al
riferimento ai dati, e non hanno costi prestazionali aggiuntivi (overhead).
I puntatori intelligenti (smart pointers), d’altra parte, sono strutture dati che si comportano come un puntatore ma hanno anche metadati e capacità aggiuntive. Il concetto di puntatori intelligenti non è esclusivo di Rust: i puntatori intelligenti hanno avuto origine in C++ ed esistono anche in altri linguaggi. Rust ha una varietà di puntatori intelligenti definiti nella libreria standard che forniscono funzionalità che vanno oltre quelle fornite dai reference. Per esplorare il concetto generale, esamineremo un paio di esempi diversi di puntatori intelligenti, incluso un tipo di puntatore intelligente con conteggio dei riferimenti. Questo puntatore consente ai dati di avere più proprietari tenendo traccia del loro numero e, quando non ne rimane nessuno, de-allocare i dati.
Rust, con il suo concetto di ownership e borrowing, presenta un’ulteriore differenza tra reference e i puntatori intelligenti: mentre i reference prendono solo in prestito dati, in molti casi i puntatori intelligenti posseggono i dati a cui puntano.
I puntatori intelligenti sono solitamente implementati tramite struct. A
differenza di una normale struct, i puntatori intelligenti implementano i
trait Deref e Drop. Il trait Deref consente a un’istanza della
struct del puntatore intelligente di comportarsi come un reference in modo
da poter scrivere codice che funzioni sia con reference che con puntatori
intelligenti. Il trait Drop consente di personalizzare il codice che viene
eseguito quando un’istanza del puntatore intelligente esce dallo scope. In
questo capitolo, discuteremo entrambi questi trait e dimostreremo perché sono
importanti per i puntatori intelligenti.
Dato che il puntatore intelligente è un design generale utilizzato frequentemente in Rust, questo capitolo non tratterà tutti i puntatori intelligenti esistenti. Molte librerie hanno i propri puntatori intelligenti, ed è anche possibile scriverne di propri. Tratteremo i più comuni nella libreria standard:
Box<T>, per l’allocazione di valori nell’heapRc<T>, un type di conteggio dei reference che consente la ownership multiplaRef<T>eRefMut<T>, accessibili tramiteRefCell<T>, type che applicano le regole di prestito durante l’esecuzione anziché in fase di compilazione
Inoltre, tratteremo il modello di mutabilità interna, in cui un type immutabile espone un’API per la mutazione di un valore interno. Discuteremo anche dei cicli di riferimento e di come possono causare perdite di memoria e come prevenirle.
Cominciamo!
Utilizzare Box<T> per Puntare ai Dati nell’Heap
Il puntatore intelligente più semplice è una box (scatola), il cui type è
scritto Box<T>. Le box consentono di memorizzare i dati nell’heap anziché
sullo stack. Ciò che rimane sullo stack è il puntatore ai dati nell’heap.
Fai riferimento al Capitolo 4 per rinfrescare la memoria sulla
differenza tra stack e heap.
Le box non hanno un overhead di prestazioni, a parte il fatto che memorizzano i dati nell’heap anziché sullo stack. Ma non hanno nemmeno molte funzionalità extra. Li userai più spesso in queste situazioni:
- Quando hai un type la cui dimensione non può essere conosciuta in fase di compilazione e vuoi utilizzare un valore di quel type in un contesto che richiede una dimensione esatta
- Quando hai una grande quantità di dati e vuoi trasferirne la ownership ma vuoi evitare che i dati vengano copiati quando lo fai
- Quando vuoi possedere un valore e ti interessa solo che sia un type con un determinato trait piuttosto che essere di un type specifico
Descriveremo la prima situazione in “Abilitare i Type Ricorsivi con le Box”. Nel secondo caso, il trasferimento della ownership di una grande quantità di dati può richiedere molto tempo perché i dati vengono copiati sullo stack. Per migliorare le prestazioni in questa situazione, possiamo memorizzare la grande quantità di dati nell’heap in una box. Quindi, solo la piccola quantità di dati del puntatore viene copiata sullo stack, mentre i dati a cui fa riferimento rimangono in un unico punto dell’heap. Il terzo caso è noto come oggetto trait (trait object), e la sezione “Usare gli Oggetti Trait per Astrarre Comportamenti Condivisi” del Capitolo 18 è dedicata specificamente a questo argomento. Quindi, ciò che imparerai qui lo applicherai di nuovo in quella sezione!
Memorizzare Dati nell’Heap
Prima di discutere il caso d’uso di archiviazione nell’heap per Box<T>,
tratteremo la sintassi e come interagire con i valori memorizzati all’interno di
una Box<T>.
Il Listato 15-1 mostra come utilizzare una box per memorizzare un valore i32
nell’heap.
fn main() { let b = Box::new(5); println!("b = {b}"); }
i32 nell’heap tramite una boxDefiniamo la variabile b come avente il valore di una Box che punta al
valore 5, allocato nell’heap. Questo programma stamperà b = 5; in questo
caso, possiamo accedere ai dati nella box in modo simile a come faremmo se
questi dati fossero sullo stack. Proprio come qualsiasi valore posseduto,
quando una box esce dallo scope, come accade a b alla fine di main,
verrà de-allocata. La de-allocazione avviene sia per la box (memorizzata sullo
stack) sia per i dati a cui punta (memorizzati nell’heap).
Mettere un singolo valore nell’heap non è molto utile, quindi le box non
verranno utilizzate molto spesso da sole in questo modo. Avere valori come un
singolo i32 sullo stack, dove vengono memorizzati di default, è più
appropriato nella maggior parte delle situazioni. Diamo un’occhiata a un caso in
cui le box ci consentono di definire type che non saremmo autorizzati a
definire se non avessimo le box.
Abilitare i Type Ricorsivi con le Box
Un valore di un type ricorsivo (recursive type) può avere un altro valore dello stesso type come parte di sé. I type ricorsivi pongono un problema perché Rust deve sapere in fase di compilazione quanto spazio occupa un certo type. Tuttavia, l’annidamento dei valori dei type ricorsivi potrebbe teoricamente continuare all’infinito, quindi Rust non può sapere di quanto spazio ha bisogno il valore. Poiché le box hanno dimensioni note, possiamo abilitare i type ricorsivi inserendo una box nella definizione del type ricorsivo.
Come esempio di type ricorsivo, esploriamo la cons list (lista di costrutti). Questo è un tipo di dato comunemente presente nei linguaggi di programmazione funzionale. Il type di cons list che definiremo è semplice, fatta eccezione per la ricorsione; pertanto, i concetti nell’esempio con cui lavoreremo saranno utili ogni volta che ti troverai in situazioni più complesse che coinvolgono i type ricorsivi.
Comprendere la Cons List
Una Cons List è una struttura dati derivata dal linguaggio di programmazione
Lisp e dai suoi dialetti, è composta da coppie annidate ed è la versione Lisp di
una lista concatenata. Il suo nome deriva dalla funzione cons (abbreviazione
di construct function) in Lisp, che costruisce una nuova coppia a partire dai
suoi due argomenti. Chiamando cons su una coppia composta da un valore e
un’altra coppia, possiamo costruire cons list composte da coppie ricorsive.
Ad esempio, ecco una rappresentazione in pseudo-codice di una cons list
contenente la lista 1, 2, 3 con ciascuna coppia tra parentesi:
(1, (2, (3, Nil)))
Ogni elemento in una cons list contiene due elementi: il valore dell’elemento
corrente e l’elemento successivo. L’ultimo elemento della lista contiene solo un
valore chiamato Nil senza un elemento successivo. Una cons list viene
prodotta chiamando ricorsivamente la funzione cons. Il nome canonico per
indicare il caso base della ricorsione è Nil. Nota che questo non è lo stesso
del concetto di “null” o “nil” discusso nel Capitolo 6, che indica un valore non
valido o assente.
La cons list non è una struttura dati comunemente utilizzata in Rust. Nella
maggior parte dei casi quando si ha una lista di elementi in Rust, Vec<T> è
una scelta migliore. Altri tipi di dati ricorsivi più complessi sono utili in
varie situazioni, ma iniziando con la cons list in questo capitolo, possiamo
capire come le box ci consentano di definire un tipo di dati ricorsivo senza
troppe distrazioni.
Il Listato 15-2 contiene una definizione enum per una cons list. Nota che
questo codice non verrà ancora compilato perché il type Lista non ha una
dimensione nota, che dimostreremo.
enum Lista {
Cons(i32, Lista),
Nil,
}
fn main() {}i32Nota: stiamo implementando una cons list che contiene solo valori
i32per gli scopi di questo esempio. Avremmo potuto implementarla utilizzando i generici, come discusso nel Capitolo 10, per definire un tipo di cons list in grado di memorizzare valori di qualsiasi type.
L’utilizzo del type Lista per memorizzare l’elenco 1, 2, 3 sarebbe simile
al codice nel Listato 15-3.
enum Lista {
Cons(i32, Lista),
Nil,
}
// --taglio--
use crate::Lista::{Cons, Nil};
fn main() {
let lista = Cons(1, Cons(2, Cons(3, Nil)));
}Lista per memorizzare la lista 1, 2, 3Il primo valore Cons contiene 1 e un altro valore Lista. Questo valore
Lista è un altro valore Cons che contiene 2 e un altro valore Lista.
Questo valore Lista è un altro valore Cons che contiene 3 e un valore
Lista, che è infine Nil, la variante non ricorsiva che segnala la fine della
lista.
Se proviamo a compilare il codice nel Listato 15-3, otteniamo l’errore mostrato nel Listato 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///progetti/cons-list)
error[E0072]: recursive type `Lista` has infinite size
--> src/main.rs:1:1
|
1 | enum Lista {
| ^^^^^^^^^^
2 | Cons(i32, Lista),
| ----- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<Lista>),
| ++++ +
error[E0391]: cycle detected when computing when `Lista` needs drop
--> src/main.rs:1:1
|
1 | enum Lista {
| ^^^^^^^^^^
|
= note: ...which immediately requires computing when `Lista` needs drop again
= note: cycle used when computing whether `Lista` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
L’errore indica che questo type “ha dimensione infinita”. Il motivo è che
abbiamo definito Lista con una variante che è ricorsiva: contiene direttamente
un altro valore di se stessa. Di conseguenza, Rust non riesce a calcolare quanto
spazio è necessario per memorizzare un valore Lista. Analizziamo il motivo per
cui otteniamo questo errore. Innanzitutto, vedremo come Rust determina quanto
spazio è necessario per memorizzare un valore di un type non ricorsivo.
Calcolare la Dimensione di un Type Non Ricorsivo
Riprendiamo l’enum Messaggio che abbiamo definito nel Listato 6-2 quando
abbiamo discusso le definizioni delle enum nel Capitolo 6:
enum Messaggio { Esci, Sposta { x: i32, y: i32 }, Scrivi(String), CambiaColore(i32, i32, i32), } fn main() {}
Per determinare quanto spazio allocare per un valore Messaggio, Rust esamina
ciascuna delle varianti per vedere quale variante necessita di più spazio. Rust
vede che Messaggio::Esci non necessita di spazio, Messaggio::Sposta
necessita di spazio sufficiente per memorizzare due valori i32 e così via.
Poiché verrà utilizzata una sola variante, lo spazio massimo di cui un valore
Messaggio avrà bisogno è lo spazio che richiederebbe per memorizzare la più
grande delle sue varianti.
Confrontiamo questo con ciò che accade quando Rust cerca di determinare di
quanto spazio necessita un type ricorsivo come l’enum Lista nel Listato
15-2. Il compilatore inizia esaminando la variante Cons, che contiene un
valore di type i32 e un valore di type Lista. Pertanto, Cons necessita
di una quantità di spazio pari alla dimensione di un i32 più la dimensione di
un Lista. Per calcolare la quantità di memoria necessaria per il type
Lista, il compilatore esamina le varianti, a partire dalla variante Cons. La
variante Cons contiene un valore di type i32 e un valore di type
Lista, e questo processo continua all’infinito, come mostrato nella Figura
15-1.

Figura 15-1: Una Lista infinita composta da infinite
varianti Cons
Ottenere un Type Ricorsivo con una Dimensione Nota
Poiché Rust non riesce a calcolare quanto spazio allocare per i type definiti ricorsivamente, il compilatore genera un errore con questo utile suggerimento:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<Lista>),
| ++++ +
In questo suggerimento, indirection significa che invece di memorizzare un valore direttamente, dovremmo modificare la struttura dati per memorizzarlo indirettamente, memorizzando invece un puntatore al valore.
Poiché Box<T> è un puntatore, Rust sa sempre di quanto spazio una Box<T>
necessita: la dimensione di un puntatore non cambia in base alla quantità di
dati a cui punta. Questo significa che possiamo inserire Box<T> all’interno
della variante Cons invece di un altro valore Lista direttamente. Box<T>
punterà al successivo valore Lista che si troverà nell’heap anziché
all’interno della variante Cons. Concettualmente, abbiamo ancora una lista,
creata con liste che contengono altre liste, ma questa implementazione ora è più
simile al posizionamento degli elementi uno accanto all’altro piuttosto che uno
dentro l’altro.
Possiamo modificare la definizione dell’enum Lista nel Listato 15-2 e
l’utilizzo di Lista nel Listato 15-3 con il codice nel Listato 15-5, che verrà
compilato.
enum Lista { Cons(i32, Box<Lista>), Nil, } use crate::Lista::{Cons, Nil}; fn main() { let lista = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); }
Lista utilizzando Box<T> per avere una dimensione notaLa variante Cons richiede la dimensione di un i32 più lo spazio per
memorizzare i dati del puntatore della box. La variante Nil non memorizza
alcun valore, quindi necessita di meno spazio sullo stack rispetto alla
variante Cons. Ora sappiamo che qualsiasi valore Lista occuperà le
dimensioni di un i32 più le dimensioni dei dati del puntatore di una box.
Utilizzando una box, abbiamo interrotto la catena infinita e ricorsiva, in
modo che il compilatore possa calcolare la dimensione necessaria per memorizzare
un valore Lista. La Figura 15-2 mostra l’aspetto attuale della variante
Cons.

Figura 15-2: Una Lista che non ha dimensioni infinite
perché Cons contiene una Box
Le box forniscono solo l’indirezione e l’allocazione nell’heap; non hanno altre funzionalità speciali, come quelle che vedremo con gli altri tipi di puntatori intelligenti. Inoltre, non hanno alcun overhead prestazionale che queste funzionalità speciali comporterebbero, quindi possono essere utili in casi come la cons list, in cui l’indirezione è l’unica funzionalità di cui abbiamo bisogno. Esamineremo altri casi d’uso per le box nel Capitolo 18.
Il type Box<T> è un puntatore intelligente perché implementa il trait
Deref, che consente di trattare i valori Box<T> come reference. Quando un
valore Box<T> esce dallo scope, anche i dati dell’heap a cui punta il
box vengono de-allocati grazie all’implementazione del trait Drop. Questi
due trait saranno ancora più importanti per le funzionalità fornite dagli
altri tipi di puntatore intelligente che discuteremo nel resto di questo
capitolo. Vediamo questi due trait più in dettaglio.
Trattare i Puntatori Intelligenti Come Normali Reference
L’implementazione del trait Deref consente di personalizzare il
comportamento dell’operatore di de-referenziazione (dereference operator) *
(da non confondere con l’operatore di moltiplicazione o glob). Implementando
Deref in modo tale che un puntatore intelligente possa essere trattato come un
normale reference, è possibile scrivere codice che opera sui reference e
utilizzarlo anche con i puntatori intelligenti.
Vediamo prima come funziona l’operatore di de-referenziazione con i normali
reference. Poi proveremo a definire un type personalizzato che si comporti
come Box<T> e vedremo perché l’operatore di de-referenziazione non funziona
come un reference sul nostro nuovo type che abbiamo definito. Esploreremo
come l’implementazione del trait Deref consenta ai puntatori intelligenti di
funzionare in modo simile ai reference. Infine, esamineremo la funzionalità di
Rust di de-referenziazione forzata (deref coercion) e come ci consenta di
lavorare sia con i reference che con i puntatori intelligenti.
Seguire il Reference al Valore
Un normale reference è un tipo di puntatore, un modo per pensare a un
puntatore è immaginare una freccia che punta verso un valore memorizzato
altrove. Nel Listato 15-6, creiamo un reference a un valore i32 e poi
utilizziamo l’operatore di de-referenziazione per seguire il riferimento al
valore.
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
i32La variabile x contiene un valore i32 5. Impostiamo y uguale a un
reference a x. Possiamo asserire che x è uguale a 5. Tuttavia, se
vogliamo fare un’asserzione sul valore in y, dobbiamo usare *y per seguire
il reference al valore a cui punta (da qui de-referenziazione) in modo che
il compilatore possa confrontare il valore effettivo. Una volta de-referenziato
y, abbiamo accesso al valore intero a cui punta y, che possiamo confrontare
con 5.
Se provassimo a scrivere assert_eq!(5, y);, otterremmo questo errore di
compilazione:
$ cargo run
Compiling esempio-deref v0.1.0 (file:///progetti/esempio-deref)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `esempio-deref` (bin "esempio-deref") due to 1 previous error
Il confronto tra un numero e un reference a un numero non è consentito perché sono diversi. Dobbiamo usare l’operatore di de-referenziazione per seguire il reference al valore a cui punta.
Utilizzare Box<T> Come Reference
Possiamo riscrivere il codice nel Listato 15-6 per utilizzare Box<T> invece di
un reference; l’operatore di de-referenziazione utilizzato su Box<T> nel
Listato 15-7 funziona allo stesso modo dell’operatore di de-referenziazione
utilizzato sul reference nel Listato 15-6.
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Box<i32>La differenza principale tra il Listato 15-7 e il Listato 15-6 è che qui
impostiamo y come un’istanza di una box che punta a un valore copiato di x
anziché come un reference che punta al valore di x. Nell’ultima asserzione,
possiamo usare l’operatore di de-referenziazione per seguire il puntatore della
box nello stesso modo in cui facevamo quando y era un reference.
Successivamente, esploreremo le peculiarità di Box<T> che ci consentono di
utilizzare l’operatore di de-referenziazione definendo un nostro type di
box.
Definire il Nostro Puntatore Intelligente
Creiamo un type incapsulatore, simile al type Box<T> fornito dalla
libreria standard, per sperimentare come i tipi di puntatore intelligente si
comportino diversamente dai normali reference. Poi vedremo come aggiungere la
possibilità di utilizzare l’operatore di de-referenziazione.
Nota: c’è una grande differenza tra il type
MioBox<T>che stiamo per creare e il veroBox<T>: la nostra versione non memorizzerà i dati nell’heap. Ci stiamo concentrando suDeref, quindi dove vengono effettivamente memorizzati i dati è meno importante del comportamento “simile” a un puntatore.
Il type Box<T> è essenzialmente definito come una struct tupla con un
elemento, quindi il Listato 15-8 definisce un type MioBox<T> allo stesso
modo. Definiremo anche una funzione new che corrisponda alla funzione new
definita su Box<T>.
struct MioBox<T>(T); impl<T> MioBox<T> { fn new(x: T) -> MioBox<T> { MioBox(x) } } fn main() {}
MioBox<T>Definiamo una struct denominata MioBox e dichiariamo un parametro generico
T perché vogliamo che il nostro type contenga valori di qualsiasi type. Il
type MioBox è una struct tupla con un elemento di type T. La funzione
MioBox::new accetta un parametro di type T e restituisce un’istanza di
MioBox che contiene il valore passato.
Proviamo ad aggiungere la funzione main del Listato 15-7 al Listato 15-8 e
modificarla in modo che utilizzi il type MioBox<T> che abbiamo definito
invece di Box<T>. Il codice nel Listato 15-9 non verrà compilato perché Rust
non sa come de-referenziare MioBox.
struct MioBox<T>(T);
impl<T> MioBox<T> {
fn new(x: T) -> MioBox<T> {
MioBox(x)
}
}
fn main() {
let x = 5;
let y = MioBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}MioBox<T> nello stesso modo in cui abbiamo utilizzato i reference e Box<T>Ecco l’errore di compilazione risultante:
$ cargo run
Compiling esempio-deref v0.1.0 (file:///progetti/esempio-deref)
error[E0614]: type `MioBox<{integer}>` cannot be dereferenced
--> src/main.rs:15:19
|
15 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `esempio-deref` (bin "esempio-deref") due to 1 previous error
Il nostro type MioBox<T> non può essere de-referenziato perché non abbiamo
implementato tale possibilità sul nostro type. Per abilitare la
de-referenziazione con l’operatore *, implementiamo il trait Deref.
Implementare il Trait Deref
Come discusso nella sezione “Implementare un Trait su un
Type” del Capitolo 10, per implementare un trait
dobbiamo fornire le implementazioni per i metodi richiesti dal trait. Il
trait Deref, fornito dalla libreria standard, richiede l’implementazione di
un metodo chiamato deref che prende in prestito self e restituisce un
reference ai dati interni. Il Listato 15-10 contiene un’implementazione di
Deref da aggiungere alla definizione di MioBox<T>.
use std::ops::Deref; impl<T> Deref for MioBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } struct MioBox<T>(T); impl<T> MioBox<T> { fn new(x: T) -> MioBox<T> { MioBox(x) } } fn main() { let x = 5; let y = MioBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Deref su MioBox<T>La sintassi type Target = T; definisce un type associato che il trait
Deref può utilizzare. I type associati rappresentano un modo leggermente
diverso di dichiarare un parametro generico, ma per ora non è necessario
preoccuparsene; li tratteremo più dettagliatamente nel Capitolo 20.
Nel corpo del metodo deref inseriamo &self.0 in modo che deref restituisca
un reference al valore a cui vogliamo accedere con l’operatore *; come detto
nella sezione “Creare Type Diversi con Struct Tupla ” del Capitolo 5, .0 accede al primo valore in una struct tupla. La
funzione main nel Listato 15-10 che chiama * sul valore MioBox<T> ora si
compila e le asserzioni vengono verificate!
Senza il trait Deref, il compilatore può de-referenziare solo i reference
&. Il metodo deref consente al compilatore di accettare un valore di
qualsiasi type che implementi Deref e chiamare il metodo deref per
ottenere un reference & che sa come de-referenziare.
Quando abbiamo inserito *y nel Listato 15-10, dietro le quinte Rust ha
effettivamente eseguito questo codice:
*(y.deref())Rust sostituisce l’operatore * con una chiamata al metodo deref e poi un
semplice de-referenziamento, così non dobbiamo pensare se sia necessario o meno
chiamare il metodo deref. Questa funzionalità di Rust ci permette di scrivere
codice che funziona nello stesso modo indipendentemente dal fatto che abbiamo un
normale reference o un type che implementa Deref.
Il motivo per cui il metodo deref restituisce un reference a un valore, e il
fatto che il semplice de-referenziamento al di fuori delle parentesi in
*(y.deref()) sia ancora necessario, ha a che fare con il sistema di
ownership. Se il metodo deref restituisse il valore direttamente invece di
un reference al valore, il valore verrebbe spostato fuori da self. Non
vogliamo prendere la ownership del valore interno di MioBox<T> in questo
caso, né nella maggior parte dei casi in cui utilizziamo l’operatore di
de-referenziazione.
Nota che l’operatore * viene sostituito con una chiamata al metodo deref e
poi con una chiamata all’operatore * una sola volta, ogni volta che
utilizziamo * nel nostro codice. Poiché la sostituzione dell’operatore * non
è ricorsiva all’infinito, otteniamo dati di type i32, che corrispondono al
5 in assert_eq! nel Listato 15-9.
Usare la De-Referenziazione Forzata in Funzioni e Metodi
La deref coercion converte un reference a un type che implementa il
trait Deref in un reference a un altro type. Ad esempio, la
de-referenziazione forzata può convertire &String in &str perché String
implementa il trait Deref in modo tale da restituire &str. La
de-referenziazione forzata è una funzionalità che Rust applica agli argomenti di
funzioni e metodi e funziona solo sui type che implementano il trait
Deref. Avviene automaticamente quando passiamo un reference al valore di un
type specifico come argomento a una funzione o a un metodo che non corrisponde
al type di parametro nella definizione della funzione o del metodo. Una
sequenza di chiamate al metodo deref converte il type fornito nel type
richiesto dal parametro.
La deref coercion è stata aggiunta a Rust in modo che i programmatori che
scrivono chiamate di funzioni e metodi non debbano esplicitare troppo spesso i
reference o i dereference con & e *. La funzionalità di
de-referenziazione forzata ci consente anche di scrivere più codice che può
funzionare sia per reference che per puntatori intelligenti.
Per vedere la deref coercion in azione, utilizziamo il type MioBox<T>
definito nel Listato 15-8 e l’implementazione di Deref aggiunta nel Listato
15-10. Il Listato 15-11 mostra la definizione di una funzione che ha un
parametro di type slice stringa.
fn ciao(nome: &str) { println!("Ciao, {nome}!"); } fn main() {}
ciao che ha il parametro nome di type &strPossiamo chiamare la funzione ciao con un parametro di type slice stringa
come argomento, ad esempio ciao("Rust");. La deref coercion consente di
chiamare ciao con un reference a un valore di type MioBox<String>, come
mostrato nel Listato 15-12.
use std::ops::Deref; impl<T> Deref for MioBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MioBox<T>(T); impl<T> MioBox<T> { fn new(x: T) -> MioBox<T> { MioBox(x) } } fn ciao(nome: &str) { println!("Ciao, {nome}!"); } fn main() { let m = MioBox::new(String::from("Rust")); ciao(&m); }
ciao con un reference a un valore MioBox<String>, che funziona grazie alla deref coercionQui chiamiamo la funzione ciao con l’argomento &m, che è un reference a un
valore MioBox<String>. Poiché abbiamo implementato il trait Deref su
MioBox<T> nel Listato 15-10, Rust può trasformare &MioBox<String> in
&String chiamando deref. La libreria standard fornisce un’implementazione di
Deref su String che restituisce una slice di stringa, ed è presente nella
documentazione API per Deref. Rust chiama nuovamente deref per trasformare
&String in &str, che corrisponde alla definizione della funzione ciao.
Se Rust non implementasse la de-referenziazione forzata, dovremmo scrivere il
codice nel Listato 15-13 invece del codice nel Listato 15-12 per chiamare ciao
con un valore di tipo &MioBox<String>.
use std::ops::Deref; impl<T> Deref for MioBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MioBox<T>(T); impl<T> MioBox<T> { fn new(x: T) -> MioBox<T> { MioBox(x) } } fn ciao(nome: &str) { println!("Ciao, {nome}!"); } fn main() { let m = MioBox::new(String::from("Rust")); ciao(&(*m)[..]); }
(*m) de-referenzia MioBox<String> in una String. Quindi & e [..]
prendono una slice di String che è uguale all’intera stringa per
corrispondere alla firma di ciao. Questo codice senza deref coercion con
tutti questi simboli coinvolti è più difficile da leggere, scrivere e
comprendere. La deref consente a Rust di gestire automaticamente queste
conversioni.
Quando il trait Deref è definito per i type coinvolti, Rust analizzerà i
type e utilizzerà Deref::deref tutte le volte necessarie per ottenere un
reference che corrisponda al type del parametro. Il numero di volte in cui
Deref::deref deve essere inserito viene risolto in fase di compilazione,
quindi non ci sono penalità prestazionali in fase di esecuzione per aver
sfruttato la deref coercion!
Gestire la De-referenziazione Forzata con Reference Mutabili
Analogamente a come si usa il trait Deref per sovrascrivere l’operatore *
sui reference immutabili, è possibile usare il trait DerefMut per
sovrascrivere l’operatore * sui reference mutabili.
Rust esegue la deref coercion quando trova type e implementazioni di trait in tre casi:
- Da
&Ta&UquandoT: Deref<Target=U> - Da
&mut Ta&mut UquandoT: DerefMut<Target=U> - Da
&mut Ta&UquandoT: Deref<Target=U>
I primi due casi sono gli stessi, tranne per il fatto che il secondo implementa
la mutabilità. Il primo caso afferma che se si ha un &T e T implementa
Deref a un type U, è possibile ottenere un &U in modo trasparente. Il
secondo caso afferma che la stessa de-referenziazione forzata avviene per i
reference mutabili.
Il terzo caso è più complicato: Rust convertirà anche un reference mutabile a uno immutabile. Ma il contrario non è possibile: i reference immutabili non verranno mai convertirti in reference mutabili. A causa delle regole di prestito, se si ha un reference mutabile, quel reference mutabile deve essere l’unico reference a quei dati (altrimenti, il programma non verrebbe compilato). La conversione di un reference mutabile in un reference immutabile non violerà mai le regole di prestito. La conversione di un reference immutabile in un reference mutabile richiederebbe che il reference immutabile iniziale sia l’unico reference immutabile a quei dati, ma le regole di prestito non lo garantiscono. Pertanto, Rust non può dare per scontato che sia possibile convertire un reference immutabile in un reference mutabile.
Eseguire del Codice Durante la Pulizia con il Trait Drop
Il secondo trait importante per i puntatori intelligenti è Drop, che
consente di personalizzare ciò che accade quando un valore sta per uscire dallo
scope. È possibile fornire un’implementazione per il trait Drop su
qualsiasi type e tale codice può essere utilizzato per rilasciare risorse come
file o connessioni di rete.
Stiamo introducendo Drop nel contesto dei puntatori intelligenti perché la
funzionalità del trait Drop viene quasi sempre utilizzata quando si
implementa un puntatore intelligente. Ad esempio, quando una Box<T> viene
eliminata, de-alloca lo spazio nell’heap a cui punta la box.
In alcuni linguaggi, per alcuni type, il programmatore deve richiamare il codice per liberare memoria o risorse ogni volta che termina di utilizzare un’istanza di quei type. Esempi includono handle a file, socket e lock. Se il programmatore dimentica di farlo, al sistema potrebbe riempirsi la memoria ed eventualmente bloccarsi. In Rust, è possibile specificare che un particolare pezzo di codice venga eseguito ogni volta che un valore esce dallo scope, e il compilatore inserirà questo codice automaticamente. Di conseguenza, non è necessario prestare attenzione a inserire codice di de-allocazione ovunque in un programma in cui un’istanza di un particolare type viene rilasciata: non si saranno problemi di memoria!
Si specifica il codice da eseguire quando un valore esce dallo scope
implementando il trait Drop. Il trait Drop richiede l’implementazione di
un metodo chiamato drop che accetta un reference mutabile a self. Per
vedere quando Rust chiama drop, implementiamo per ora drop con istruzioni
println!.
Il Listato 15-14 mostra una struct MioSmartPointer la cui unica funzionalità
personalizzata è quella di stampare Pulizia MioSmartPointer! quando l’istanza
esce dallo scope, per mostrare quando Rust esegue il metodo drop.
struct MioSmartPointer { data: String, } impl Drop for MioSmartPointer { fn drop(&mut self) { println!("Pulizia MioSmartPointer con dati `{}`!", self.data); } } fn main() { let c = MioSmartPointer { data: String::from("mia roba"), }; let d = MioSmartPointer { data: String::from("altra roba"), }; println!("MioSmartPointer creati."); }
MioSmartPointer che implementa il trait Drop dove inseriremo il nostro codice di de-allocazioneIl trait Drop è incluso nel preludio, quindi non è necessario portarlo in
scope. Implementiamo il trait Drop su MioSmartPointer e forniamo
un’implementazione per il metodo drop che chiama println!. Il corpo del
metodo drop è dove inseriremmo qualsiasi logica che si desidera eseguire
quando un’istanza del type esce dallo scope. Stiamo stampando del testo per
mostrare visivamente quando Rust chiamerà drop.
In main, creiamo due istanze di MioSmartPointer e poi stampiamo
MioSmartPointer creati. Alla fine di main, le nostre istanze di
MioSmartPointer usciranno dallo scope e Rust chiamerà il codice che abbiamo
inserito nel metodo drop, stampando il nostro messaggio finale. Nota che non è
stato necessario chiamare esplicitamente il metodo drop.
Quando eseguiamo questo programma, vedremo il seguente output:
$ cargo run
Compiling esempio-drop v0.1.0 (file:///progetti/esempio-drop)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.02s
Running `target/debug/esempio-drop`
MioSmartPointer creati.
Pulizia MioSmartPointer con dati `altra roba`!
Pulizia MioSmartPointer con dati `mia roba`!
Rust ha chiamato automaticamente drop per noi quando le nostre istanze sono
uscite dallo scope, eseguendo il codice che abbiamo specificato. Le variabili
vengono eliminate nell’ordine inverso alla loro creazione, quindi d è stata
eliminata prima di c. Lo scopo di questo esempio è fornire una guida visiva al
funzionamento del metodo drop; Di solito, si specifica il codice di
de-allocazione che il type deve eseguire anziché un messaggio di stampa.
Purtroppo, non è semplice disabilitare la funzionalità automatica drop.
Disabilitare drop di solito non è necessario; lo scopo del trait Drop è
che venga gestito automaticamente. Occasionalmente, tuttavia, potrebbe essere
necessario rilasciare un valore in anticipo. Un esempio è quando si utilizzano
puntatori intelligenti che gestiscono i blocchi: potresti voler forzare il
metodo drop per rilasciare il blocco in modo che altro codice nello stesso
scope possa acquisire il blocco. Rust non consente di chiamare manualmente il
metodo drop del trait Drop; invece, è necessario chiamare la funzione
std::mem::drop fornita dalla libreria standard se si desidera forzare
l’eliminazione di un valore prima della fine del suo scope.
Provare a chiamare manualmente il metodo drop del trait Drop modificando
la funzione main del Listato 15-14, come mostrato nel Listato 15-15, risulterà
in un errore del compilatore.
struct MioSmartPointer {
data: String,
}
impl Drop for MioSmartPointer {
fn drop(&mut self) {
println!("Pulizia MioSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = MioSmartPointer {
data: String::from("alcuni dati"),
};
println!("MioSmartPointer creato.");
c.drop();
println!("MioSmartPointer pulito prima della fine di main.");
}drop del trait Drop per una de-allocazione anticipataQuando proviamo a compilare questo codice, otterremo questo errore:
$ cargo run
Compiling esempio-drop v0.1.0 (file:///progetti/esempio-drop)
error[E0040]: explicit use of destructor method
--> src/main.rs:17:7
|
17 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
17 - c.drop();
17 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `esempio-drop` (bin "esempio-drop") due to 1 previous error
Questo messaggio di errore indica che non siamo autorizzati a chiamare
esplicitamente drop. Il messaggio di errore utilizza il termine destructor,
che è il termine di programmazione generale per una funzione che de-alloca
un’istanza. Un destructor è analogo a un constructor, che crea un’istanza.
La funzione drop in Rust è una forma particolare di distruttore.
Rust non ci permette di chiamare drop esplicitamente perché Rust chiamerebbe
comunque automaticamente drop sul valore alla fine di main. Questo
causerebbe un errore di tipo double free perché Rust cercherebbe di
de-allocare lo stesso valore due volte.
Non possiamo disabilitare l’inserimento automatico di drop quando un valore
esce dallo scope, e non possiamo chiamare esplicitamente il metodo drop.
Quindi, se dobbiamo forzare la de-allocazione anticipata di un valore, usiamo la
funzione std::mem::drop.
La funzione std::mem::drop è diversa dal metodo drop nel trait Drop. La
chiamiamo passando come argomento il valore di cui vogliamo forzare il rilascio.
La funzione si trova nel preludio, quindi possiamo modificare main nel Listato
15-15 per chiamare la funzione drop, come mostrato nel Listato 15-16.
struct MioSmartPointer { data: String, } impl Drop for MioSmartPointer { fn drop(&mut self) { println!("Pulizia MioSmartPointer con dati `{}`!", self.data); } } fn main() { let c = MioSmartPointer { data: String::from("alcuni dati"), }; println!("MioSmartPointer creato."); drop(c); println!("MioSmartPointer pulito prima della fine di main."); }
std::mem::drop per eliminare esplicitamente un valore prima che esca dallo scopeL’esecuzione di questo codice stamperà quanto segue:
$ cargo run
Compiling esempio-drop v0.1.0 (file:///progetti/esempio-drop)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.83s
Running `target/debug/esempio-drop`
MioSmartPointer creato.
Pulizia MioSmartPointer con dati `alcuni dati`!
MioSmartPointer pulito prima della fine di main.
Il testo Eliminazione di MioSmartPointer con dati `alcuni dati`! viene
stampato tra MioSmartPointer creato. e MioSmartPointer pulito prima della fine di main., a dimostrazione del fatto che il codice del metodo drop è
chiamato per eliminare c in quel punto.
Puoi utilizzare il codice specificato in un’implementazione del trait Drop
in molti modi per rendere la de-allocazione comoda e sicura: ad esempio, è
possibile utilizzarlo per creare il proprio allocatore di memoria! Con il
trait Drop e il sistema di ownership di Rust, non è necessario ricordarsi
di de-allocare perché Rust lo fa automaticamente.
Inoltre, non è necessario preoccuparsi dei problemi derivanti dalla
de-allocazione accidentale di valori ancora in uso: il sistema di ownership
che garantisce che i reference siano sempre validi garantisce anche che drop
venga chiamato solo una volta quando il valore non è più in uso.
Ora che abbiamo esaminato Box<T> e alcune delle caratteristiche dei puntatori
intelligenti, diamo un’occhiata ad alcuni altri puntatori intelligenti definiti
nella libreria standard.
Rc<T>, il Puntatore Intelligente con Conteggio dei Reference
Nella maggior parte dei casi, la ownership è chiara: si sa esattamente quale variabile possiede un dato valore. Tuttavia, ci sono casi in cui un singolo valore potrebbe avere più proprietari. Ad esempio, nelle strutture dati grafo1, più archi potrebbero puntare allo stesso nodo, e quel nodo è concettualmente di proprietà di tutti gli archi che puntano ad esso. Un nodo non dovrebbe essere de-allocato a meno che non abbia più archi che puntano ad esso e quindi non abbia proprietari.
È necessario abilitare esplicitamente la ownership multipla utilizzando il
type Rc<T>, che è l’abbreviazione di conteggio dei reference (reference
counting). Il type Rc<T> tiene traccia del numero di reference a un
valore per determinare se il valore è ancora in uso. Se non ci sono reference
a un valore, il valore può essere de-allocato senza che alcun reference
diventi invalido.
Immaginate Rc<T> come una TV in un soggiorno. Quando una persona entra per
guardare la TV, la accende. Altri possono entrare nella stanza e guardare la TV.
Quando l’ultima persona esce dalla stanza, spegne la TV perché non la sta più
utilizzando. Se qualcuno spegne la TV mentre altri la stanno ancora guardando,
ci sarebbe un putiferio da parte degli altri spettatori!
Usiamo il type Rc<T> quando vogliamo allocare alcuni dati nell’heap
affinché più parti del nostro programma possano leggerli e non possiamo
determinare in fase di compilazione quale parte terminerà l’utilizzo dei dati
per ultima. Se sapessimo quale parte terminerà per ultima, potremmo
semplicemente impostare quella parte come proprietaria dei dati e applicare le
normali regole di ownership che entrerebbero in vigore in fase di
compilazione.
Nota che Rc<T> è utilizzabile solo in scenari a thread singolo. Quando
parleremo di concorrenza nel Capitolo 16, spiegheremo come eseguire il conteggio
dei reference nei programmi multi-thread.
Condividere Dati
Torniamo al nostro esempio di cons list del Listato 15-5. Lo avevamo definito
utilizzando Box<T>. Questa volta creeremo due elenchi che condividono la
proprietà di un terzo elenco. Concettualmente, questo è simile alla Figura 15-3.

Figura 15-3: Due liste, b e c, che condividono la
proprietà di una terza lista, a
Creeremo la lista a che contiene 5 e poi 10. Quindi creeremo altre due
liste: b che inizia con 3 e c che inizia con 4. Entrambe le liste b e
c proseguiranno quindi con la prima lista a contenente 5 e 10. In altre
parole, entrambe le liste condivideranno la prima lista contenente 5 e 10.
Cercare di implementare questo scenario utilizzando la nostra definizione di
Lista con Box<T> non funzionerebbe, come mostrato nel Listato 15-17.
enum Lista {
Cons(i32, Box<Lista>),
Nil,
}
use crate::Lista::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Box<T> che tentano di condividere la proprietà di una terza listaQuando compiliamo questo codice, otteniamo questo errore:
$ cargo run
Compiling cons-list v0.1.0 (file:///progetti/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `Lista`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `Lista` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum Lista {
| ^^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Le varianti Cons hanno ownership dei dati che contengono, quindi quando
creiamo la lista b, a viene spostata in b e b possiede a. Quindi,
quando proviamo a usare di nuovo a durante la creazione di c, non ci viene
consentito perché a è stata spostata.
Potremmo modificare la definizione di Cons per contenere dei reference, ma
in tal caso dovremmo poi specificare anche i parametri di lifetime.
Specificando i parametri di lifetime, specificheremmo che ogni elemento della
lista avrà longevità di almeno quanto l’intera lista. Questo vale per gli
elementi e le liste nel Listato 15-17, ma non in tutti gli scenari.
Invece, modificheremo la nostra definizione di Lista per usare Rc<T> al
posto di Box<T>, come mostrato nel Listato 15-18. Ogni variante di Cons ora
conterrà un valore e un Rc<T> che punta a una Lista. Quando creiamo b,
invece di assumere la proprietà di a, cloneremo Rc<Lista> che contiene a,
aumentando così il numero di reference da 1 a 2 e lasciando che a e b
condividano la ownership dei dati in quella Rc<Lista>. Cloneremo anche a
quando creiamo c, aumentando il numero di reference da 2 a 3. Ogni volta che
chiamiamo Rc::clone, il conteggio dei reference ai dati all’interno di
Rc<Lista> aumenterà e i dati non verranno de-allocati a meno che non ci siano
zero riferimenti ad essi.
enum Lista { Cons(i32, Rc<Lista>), Nil, } use crate::Lista::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
Lista che usa Rc<T>Dobbiamo aggiungere un’istruzione use per portare Rc<T> nello scope perché
non è nel preludio. In main, creiamo la lista contenente 5 e 10 e la
memorizziamo in una nuova Rc<Lista> in a. Quindi, quando creiamo b e c,
chiamiamo la funzione Rc::clone e passiamo un reference a Rc<Lista> in a
come argomento.
Avremmo potuto chiamare a.clone() invece di Rc::clone(&a), ma la convenzione
di Rust in questo caso prevede di usare Rc::clone. L’implementazione di
Rc::clone non esegue una copia profonda (deep copy) di tutti i dati come
fanno la maggior parte delle implementazioni di clone dei vari type. La
chiamata a Rc::clone incrementa solo il conteggio dei reference, il che non
richiede molto tempo. Le copie profonde dei dati possono richiedere molto tempo.
Utilizzando Rc::clone per il conteggio dei reference, possiamo distinguere
visivamente tra i type che clonano usando la copia profonda e quelli che
aumentano il conteggio dei reference. Quando cercheremo problemi di
prestazioni nel codice, possiamo considerare solo i type che clonano tramite
copia profonda e possiamo ignorare le chiamate a Rc::clone.
Clonare per Aumentare il Conteggio dei Reference
Modifichiamo il nostro esempio di lavoro nel Listato 15-18 in modo da poter
vedere i conteggi dei reference cambiare quando creiamo ed eliminiamo
reference a Rc<Lista> in a.
Nel Listato 15-19, modificheremo main in modo che abbia uno scope interno
attorno alla lista c; poi potremo vedere come cambia il conteggio dei
reference quando c esce dallo scope.
enum Lista { Cons(i32, Rc<Lista>), Nil, } use crate::Lista::{Cons, Nil}; use std::rc::Rc; // --taglio-- fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("conteggio dopo la creazione di a = {}", Rc::strong_count(&a)); let b = Cons(3, Rc::clone(&a)); println!("conteggio dopo la creazione di b = {}", Rc::strong_count(&a)); { let c = Cons(4, Rc::clone(&a)); println!("conteggio dopo la creazione di c = {}", Rc::strong_count(&a)); } println!("conteggio dopo che c è uscita dallo scope c = {}", Rc::strong_count(&a)); }
In ogni punto del programma in cui il conteggio dei reference cambia,
stampiamo il conteggio dei reference, che otteniamo chiamando la funzione
Rc::strong_count. Questa funzione si chiama strong_count anziché count
perché il type Rc<T> ha anche un weak_count; vedremo a cosa serve
weak_count in “Prevenire Cicli di Riferimento Usando
Weak<T>”.
Questo codice stampa quanto segue:
$ cargo run
Compiling cons-list v0.1.0 (file:///progetti/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.17s
Running `target/debug/cons-list`
conteggio dopo la creazione di a = 1
conteggio dopo la creazione di b = 2
conteggio dopo la creazione di c = 3
conteggio dopo che c è uscita dallo scope c = 2
Possiamo vedere che Rc<Lista> in a ha un conteggio dei reference iniziale
pari a 1; quindi ogni volta che chiamiamo clone, il conteggio aumenta di 1.
Quando c esce dallo scope, il conteggio diminuisce di 1. Non dobbiamo
chiamare una funzione per diminuire il conteggio dei reference, come dobbiamo
chiamare Rc::clone per aumentarlo: l’implementazione del trait Drop
diminuisce il conteggio dei reference automaticamente quando un valore Rc<T>
esce dallo scope.
Ciò che non possiamo vedere in questo esempio è che quando b e poi a escono
dallo scope alla fine di main, il conteggio diventa 0 e Rc<Lista> viene
de-allocato completamente. L’utilizzo di Rc<T> consente a un singolo valore di
avere più proprietari e il conteggio garantisce che il valore rimanga valido
finché uno qualsiasi dei proprietari esiste ancora.
Tramite reference immutabili, Rc<T> consente di condividere dati tra più
parti del programma in sola lettura. Se Rc<T> consentisse di avere anche più
reference mutabili, si potrebbe violare una delle regole di prestito discusse
nel Capitolo 4: più prestiti mutabili nello stesso posto possono causare
conflitti di dati e incongruenze. Ma poter mutare i dati è molto utile! Nella
prossima sezione, discuteremo di mutabilità interna e del type RefCell<T>
che è possibile utilizzare insieme a Rc<T> per lavorare con questa restrizione
di immutabilità.
RefCell<T> e il Modello di Mutabilità Interna
Interior mutability è un modello di design in Rust che consente di mutare i
dati anche in presenza di reference immutabili a tali dati; normalmente,
questa azione non è consentita dalle regole di prestito. Per mutare i dati, il
modello utilizza codice unsafe all’interno di una struttura dati per
modificare le normali regole di Rust che governano la mutabilità e il prestito.
Il codice unsafe indica al compilatore che stiamo controllando le regole
manualmente invece di affidarci al compilatore affinché le controlli per noi;
approfondiremo il codice unsafe nel Capitolo 20.
Possiamo utilizzare type che utilizzano il modello di mutabilità interna solo
quando possiamo garantire che le regole di prestito vengano rispettate durante
l’esecuzione, anche se il compilatore non può garantirlo. Il codice unsafe
coinvolto viene quindi racchiuso in un’API sicura e il type esterno rimane
immutabile.
Esploriamo questo concetto esaminando il type RefCell<T> che segue il
modello di mutabilità interna.
Applicare le Regole di Prestito in Fase di Esecuzione
A differenza di Rc<T>, il type RefCell<T> rappresenta la ownership
singola sui dati che contiene. Quindi, cosa rende RefCell<T> diverso da un
type come Box<T>? Ricorda le regole di prestito apprese nel Capitolo 4:
- In qualsiasi momento, puoi avere o un reference mutabile o un numero qualsiasi di reference immutabili (ma non entrambi).
- I reference devono essere sempre validi.
Con i reference e Box<T>, le invarianti delle regole di prestito vengono
applicate in fase di compilazione. Con RefCell<T>, queste invarianti vengono
applicate in fase di esecuzione. Con i reference, se si violano queste regole,
si otterrà un errore di compilazione. Con RefCell<T>, se si violano queste
regole, il programma andrà in panic e si chiuderà.
I vantaggi del controllo delle regole di prestito in fase di compilazione sono che gli errori vengono rilevati durante il processo di sviluppo e non vi è alcun impatto sulle prestazioni in fase di esecuzione perché tutta l’analisi viene completata in anticipo. Per questi motivi, il controllo delle regole di prestito in fase di compilazione è la scelta migliore nella maggior parte dei casi, ed è per questo che questa è la scelta predefinita di Rust.
Il vantaggio del controllo delle regole di prestito in fase di esecuzione è che vengono consentiti determinati scenari di sicurezza della memoria, laddove sarebbero stati non consentiti dai controlli in fase di compilazione. L’analisi statica, come quella effettuata dal compilatore Rust, è intrinsecamente conservativa. Alcune proprietà del codice sono impossibili da rilevare analizzando il codice: l’esempio più famoso è il problema della terminazione (Halting Problem), che esula dall’ambito di questo libro ma è un argomento interessante da approfondire se vuoi.
Poiché alcune analisi sono impossibili, se il compilatore Rust non può essere
sicuro che il codice sia conforme alle regole di ownership, potrebbe rifiutare
di compilare un programma corretto; in questo modo, è conservativo. Se Rust
accettasse un programma errato, gli utenti non potrebbero fidarsi delle garanzie
fornite da Rust. Tuttavia, se Rust rifiuta di compilare un programma corretto,
il programmatore non sarà certo contento, anche se non è nulla di catastrofico.
Il type RefCell<T> è utile quando si è certi che il codice segua le regole
di prestito, ma il compilatore non è in grado di comprenderlo e garantirlo.
Simile a Rc<T>, RefCell<T> è utilizzabile solo in scenari a thread singolo
e genererà un errore in fase di compilazione se si tenta di utilizzarlo in un
contesto multi-thread. Parleremo di come ottenere la funzionalità di
RefCell<T> in un programma multi-thread nel Capitolo 16.
Ecco un riepilogo delle ragioni per scegliere Box<T>, Rc<T> o RefCell<T>:
Rc<T>consente più proprietari degli stessi dati;Box<T>eRefCell<T>hanno proprietari singoli.Box<T>consente prestiti immutabili o mutabili controllati in fase di compilazione;Rc<T>consente solo prestiti immutabili controllati in fase di compilazione;RefCell<T>consente prestiti immutabili o mutabili controllati in fase di esecuzione.- Poiché
RefCell<T>consente prestiti mutabili controllati in fase di esecuzione, è possibile modificare il valore all’interno diRefCell<T>anche quandoRefCell<T>è immutabile.
Mutare il valore all’interno di un valore immutabile è il modello di Interior Mutability . Esaminiamo una situazione in cui la mutabilità interna è utile e vediamo come sia possibile.
Usare la Mutabilità Interna
Una conseguenza delle regole di prestito è che quando si ha un valore immutabile, non è possibile prenderlo in prestito mutabilmente. Ad esempio, questo codice non verrà compilato:
fn main() {
let x = 5;
let y = &mut x;
}Se provassi a compilare questo codice, otterresti il seguente errore:
$ cargo run
Compiling borrowing v0.1.0 (file:///progetti/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Tuttavia, ci sono situazioni in cui sarebbe utile che un valore mutasse se
stesso nei suoi metodi, ma apparisse immutabile ad altro codice. Il codice
esterno ai metodi del valore non sarebbe in grado di mutare il valore. Usare
RefCell<T> è un modo per ottenere la possibilità di avere una mutabilità
interna, senza però aggirare completamente le regole di prestito: il controllore
di prestito nel compilatore consente questa mutabilità interna e le regole di
prestito vengono invece verificate durante l’esecuzione. Se si violano le
regole, si otterrà un panic! invece di un errore del compilatore.
Esaminiamo un esempio pratico in cui possiamo usare RefCell<T> per mutare un
valore immutabile e vediamo perché è utile.
Testare con gli Oggetti Mock
A volte, durante i test, un programmatore usa un type al posto di un altro, per osservare un comportamento particolare e verificare che sia implementato correttamente. Questo type segnaposto è chiamato test double (doppione di test). Pensalo come ad una controfigura nel cinema, dove una persona interviene e sostituisce un attore per girare una scena particolarmente difficile. I test double sostituiscono altri type durante l’esecuzione dei test. Gli oggetti mock sono type specifici di test double che registrano ciò che accade durante un test, in modo da poter verificare che sono state eseguite le azioni corrette.
Rust non ha oggetti nello stesso senso in cui li hanno altri linguaggi, e Rust non ha funzionalità di oggetti mock integrate nella libreria standard come altri linguaggi. Tuttavia, è sicuramente possibile creare una struct che svolgerà le stesse funzioni di un oggetto mock.
Ecco lo scenario che testeremo: creeremo una libreria che tiene traccia di un valore rispetto a un valore massimo e invia messaggi in base a quanto il valore corrente è vicino al valore massimo. Questa libreria potrebbe essere utilizzata, ad esempio, per tenere traccia della quota di un utente per il numero di chiamate API che gli è consentito effettuare.
La nostra libreria fornirà solo la funzionalità di tracciare quanto un valore è
vicino al massimo e quali messaggi dovrebbero essere inviati e in quali momenti.
Le applicazioni che utilizzano la nostra libreria dovranno fornire il meccanismo
per l’invio dei messaggi: l’applicazione potrebbe mostrare il messaggio
direttamente all’utente, inviare un’email, inviare un messaggio di testo o fare
altro. La libreria non ha bisogno di conoscere questo dettaglio. Tutto ciò di
cui ha bisogno è qualcosa che implementi un trait che forniremo chiamato
Messaggero. Il Listato 15-20 mostra il codice della libreria.
pub trait Messaggero {
fn invia(&self, msg: &str);
}
pub struct TracciaLimiti<'a, T: Messaggero> {
messaggero: &'a T,
valore: usize,
max: usize,
}
impl<'a, T> TracciaLimiti<'a, T>
where
T: Messaggero,
{
pub fn new(messaggero: &'a T, max: usize) -> TracciaLimiti<'a, T> {
TracciaLimiti {
messaggero,
valore: 0,
max,
}
}
pub fn setta_valore(&mut self, valore: usize) {
self.valore = valore;
let percentuale_di_max = self.valore as f64 / self.max as f64;
if percentuale_di_max >= 1.0 {
self.messaggero
.invia("Errore: Hai superato la tua quota!");
} else if percentuale_di_max >= 0.9 {
self.messaggero
.invia("Avviso urgente: Hai utilizzato oltre il 90% della tua quota!");
} else if percentuale_di_max >= 0.75 {
self.messaggero
.invia("Avviso: Hai utilizzato oltre il 75% della tua quota!");
}
}
}Una parte importante di questo codice è che il trait Messaggero ha un metodo
chiamato invia che accetta un reference immutabile a self e il testo del
messaggio. Questo trait è l’interfaccia che il nostro oggetto mock deve
implementare in modo che il mock possa essere utilizzato allo stesso modo di
un oggetto reale. L’altra parte importante è che vogliamo testare il
comportamento del metodo setta_valore su TracciaLimiti. Possiamo modificare
ciò che passiamo per il parametro valore, ma setta_valore non restituisce
nulla su cui fare asserzioni. Vogliamo poter dire che se creiamo un
TracciaLimiti con qualcosa che implementa il trait Messaggero e un valore
specifico per max, al messaggero viene detto di inviare i messaggi appropriati
quando passiamo numeri diversi per valore.
Abbiamo bisogno di un oggetto mock che, invece di inviare un’email o un
messaggio di testo quando chiamiamo invia, tenga traccia solo dei messaggi che
gli viene detto di inviare. Possiamo creare una nuova istanza dell’oggetto
mock, creare un TracciaLimiti che utilizzi l’oggetto mock, chiamare il
metodo setta_valore su TracciaLimiti e quindi verificare che l’oggetto
mock contenga i messaggi che ci aspettiamo. Il Listato 15-21 mostra un
tentativo di implementare un oggetto mock per fare proprio questo, ma il
controllo dei prestiti non lo consente.
pub trait Messaggero {
fn invia(&self, msg: &str);
}
pub struct TracciaLimiti<'a, T: Messaggero> {
messaggero: &'a T,
valore: usize,
max: usize,
}
impl<'a, T> TracciaLimiti<'a, T>
where
T: Messaggero,
{
pub fn new(messaggero: &'a T, max: usize) -> TracciaLimiti<'a, T> {
TracciaLimiti {
messaggero,
valore: 0,
max,
}
}
pub fn setta_valore(&mut self, valore: usize) {
self.valore = valore;
let percentuale_di_max = self.valore as f64 / self.max as f64;
if percentuale_di_max >= 1.0 {
self.messaggero.invia("Errore: Hai superato la tua quota!");
} else if percentuale_di_max >= 0.9 {
self.messaggero
.invia("Avviso urgente: Hai utilizzato oltre il 90% della tua quota!");
} else if percentuale_di_max >= 0.75 {
self.messaggero
.invia("Avviso: Hai utilizzato oltre il 75% della tua quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessaggero {
messaggi_inviati: Vec<String>,
}
impl MockMessaggero {
fn new() -> MockMessaggero {
MockMessaggero {
messaggi_inviati: vec![],
}
}
}
impl Messaggero for MockMessaggero {
fn invia(&self, messaggio: &str) {
self.messaggi_inviati.push(String::from(messaggio));
}
}
#[test]
fn invia_un_messaggio_di_avviso_di_superamento_del_75_percento() {
let mock_messaggero = MockMessaggero::new();
let mut traccia_limiti = TracciaLimiti::new(&mock_messaggero, 100);
traccia_limiti.setta_valore(80);
assert_eq!(mock_messaggero.messaggi_inviati.len(), 1);
}
}MockMessaggero non consentito dal controllo dei prestitiQuesto codice di test definisce una struct MockMessaggero che ha un campo
messaggi_inviati con un Vec di valori String per tenere traccia dei
messaggi che gli viene chiesto di inviare. Definiamo anche una funzione
associata new per semplificare la creazione di nuovi valori MockMessaggero
che iniziano con un elenco vuoto di messaggi. Implementiamo quindi il trait
Messaggero per MockMessaggero in modo da poter assegnare un MockMessaggero
a un TracciaLimiti. Nella definizione del metodo invia, prendiamo il
messaggio passato come parametro e lo memorizziamo nella lista MockMessaggero
di messaggi_inviati.
Nel test, stiamo testando cosa succede quando a TracciaLimiti viene chiesto di
impostare valore a un valore superiore al 75% del valore max. Per prima cosa
creiamo un nuovo MockMessaggero, che inizierà con una lista vuota di messaggi.
Quindi creiamo un nuovo TracciaLimiti e gli diamo un reference al nuovo
MockMessaggero e un valore max di 100. Chiamiamo il metodo setta_valore
su TracciaLimiti con un valore di 80, che è superiore al 75% di 100. Quindi
verifichiamo che la lista di messaggi di cui MockMessaggero sta tenendo
traccia dovrebbe ora contenere un messaggio.
Tuttavia, c’è un problema con questo test, come mostrato qui:
$ cargo test
Compiling traccia-limiti v0.1.0 (file:///progetti/traccia-limiti)
error[E0596]: cannot borrow `self.messaggi_inviati` as mutable, as it is behind a `&` reference
--> src/lib.rs:59:13
|
59 | self.messaggi_inviati.push(String::from(messaggio));
| ^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn invia(&mut self, msg: &str);
3 | }
...
57 | impl Messaggero for MockMessaggero {
58 ~ fn invia(&mut self, messaggio: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `traccia-limiti` (lib test) due to 1 previous error
Non possiamo modificare MockMessaggero per tenere traccia dei messaggi perché
il metodo invia accetta un reference immutabile a self. Inoltre, non
possiamo accettare il suggerimento dal testo di errore di utilizzare &mut self
sia nel metodo impl che nella definizione del trait. Non vogliamo modificare
il trait Messaggero solo per il funzionamento del test. Dobbiamo invece
trovare un modo per far funzionare il nostro codice di test correttamente con il
nostro design esistente.
Questa è una situazione in cui la mutabilità interna può essere d’aiuto!
Memorizzeremo messaggi_inviati all’interno di un RefCell<T>, e poi il metodo
invia sarà in grado di modificare messaggi_inviati per memorizzare i
messaggi che abbiamo visto. Il Listato 15-22 mostra come fare.
pub trait Messaggero {
fn invia(&self, msg: &str);
}
pub struct TracciaLimiti<'a, T: Messaggero> {
messaggero: &'a T,
valore: usize,
max: usize,
}
impl<'a, T> TracciaLimiti<'a, T>
where
T: Messaggero,
{
pub fn new(messaggero: &'a T, max: usize) -> TracciaLimiti<'a, T> {
TracciaLimiti {
messaggero,
valore: 0,
max,
}
}
pub fn set_valore(&mut self, valore: usize) {
self.valore = valore;
let percentuale_di_max = self.valore as f64 / self.max as f64;
if percentuale_di_max >= 1.0 {
self.messaggero.invia("Errore: Hai superato la tua quota!");
} else if percentuale_di_max >= 0.9 {
self.messaggero
.invia("Avviso urgente: Hai utilizzato oltre il 90% della tua quota!");
} else if percentuale_di_max >= 0.75 {
self.messaggero
.invia("Avviso: Hai utilizzato oltre il 75% della tua quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessaggero {
messaggi_inviati: RefCell<Vec<String>>,
}
impl MockMessaggero {
fn new() -> MockMessaggero {
MockMessaggero {
messaggi_inviati: RefCell::new(vec![]),
}
}
}
impl Messaggero for MockMessaggero {
fn invia(&self, messaggio: &str) {
self.messaggi_inviati.borrow_mut().push(String::from(messaggio));
}
}
#[test]
fn invia_un_messaggio_di_avviso_di_superamento_del_75_percento() {
// --taglio--
let mock_messaggero = MockMessaggero::new();
let mut traccia_limiti = TracciaLimiti::new(&mock_messaggero, 100);
traccia_limiti.set_valore(80);
assert_eq!(mock_messaggero.messaggi_inviati.borrow().len(), 1);
}
}RefCell<T> per modificare un valore interno mentre il valore esterno è considerato immutabileIl campo messaggi_inviati è ora di type RefCell<Vec<String>> invece di
Vec<String>. Nella funzione new, creiamo una nuova istanza di
RefCell<Vec<String>> incapsulando il vettore vuoto.
Per l’implementazione del metodo send, il primo parametro è ancora un prestito
immutabile di self, che corrisponde alla definizione del trait. Chiamiamo
borrow_mut su RefCell<Vec<String>> in self.messaggi_inviati per ottenere
un reference mutabile al valore all’interno di RefCell<Vec<String>>, che è
il vettore. Quindi possiamo chiamare push sul reference mutabile al vettore
per tenere traccia dei messaggi inviati durante il test.
L’ultima modifica che dobbiamo apportare riguarda l’asserzione: per vedere
quanti elementi ci sono nel vettore interno, chiamiamo borrow su
RefCell<Vec<String>> per ottenere un reference immutabile al vettore.
Ora che hai visto come usare RefCell<T>, approfondiamo il suo funzionamento!
Tracciare i Prestiti in Fase di Esecuzione
Quando creiamo reference immutabili e mutabili, utilizziamo rispettivamente la
sintassi & e &mut. Con RefCell<T>, utilizziamo i metodi borrow e
borrow_mut, che fanno parte dell’API sicura di RefCell<T>. Il metodo
borrow restituisce il type di puntatore intelligente Ref<T>, mentre
borrow_mut restituisce il type di puntatore intelligente RefMut<T>.
Entrambi i type implementano Deref, quindi possiamo trattarli come normali
reference.
RefCell<T> tiene traccia di quanti puntatori intelligenti Ref<T> e
RefMut<T> sono attualmente attivi. Ogni volta che chiamiamo borrow,
RefCell<T> aumenta il conteggio dei prestiti immutabili attivi. Quando un
valore Ref<T> esce dallo scope, il conteggio dei prestiti immutabili
diminuisce di 1. Proprio come per le regole di prestito in fase di compilazione,
RefCell<T> ci consente di avere molti prestiti immutabili o un prestito
mutabile in qualsiasi momento.
Se proviamo a violare queste regole, anziché ottenere un errore di compilazione
come accadrebbe con i reference, l’implementazione di RefCell<T> andrà in
panic in fase di esecuzione. Il Listato 15-23 mostra una modifica
dell’implementazione di invia nel Listato 15-22. Stiamo deliberatamente
cercando di creare due prestiti mutabili attivi nello stesso scope per
dimostrare che RefCell<T> ci impedisce di farlo in fase di esecuzione.
pub trait Messaggero {
fn invia(&self, msg: &str);
}
pub struct TracciaLimiti<'a, T: Messaggero> {
messaggero: &'a T,
valore: usize,
max: usize,
}
impl<'a, T> TracciaLimiti<'a, T>
where
T: Messaggero,
{
pub fn new(messaggero: &'a T, max: usize) -> TracciaLimiti<'a, T> {
TracciaLimiti {
messaggero,
valore: 0,
max,
}
}
pub fn set_valore(&mut self, valore: usize) {
self.valore = valore;
let percentuale_di_max = self.valore as f64 / self.max as f64;
if percentuale_di_max >= 1.0 {
self.messaggero.invia("Errore: Hai superato la tua quota!");
} else if percentuale_di_max >= 0.9 {
self.messaggero
.invia("Avviso urgente: Hai utilizzato oltre il 90% della tua quota!");
} else if percentuale_di_max >= 0.75 {
self.messaggero
.invia("Avviso: Hai utilizzato oltre il 75% della tua quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessaggero {
messaggi_inviati: RefCell<Vec<String>>,
}
impl MockMessaggero {
fn new() -> MockMessaggero {
MockMessaggero {
messaggi_inviati: RefCell::new(vec![]),
}
}
}
impl Messaggero for MockMessaggero {
fn invia(&self, messaggio: &str) {
let mut borrow_uno = self.messaggi_inviati.borrow_mut();
let mut borrow_due = self.messaggi_inviati.borrow_mut();
borrow_uno.push(String::from(messaggio));
borrow_due.push(String::from(messaggio));
}
}
#[test]
fn invia_un_messaggio_di_avviso_di_superamento_del_75_percento() {
let mock_messaggero = MockMessaggero::new();
let mut traccia_limiti = TracciaLimiti::new(&mock_messaggero, 100);
traccia_limiti.set_valore(80);
assert_eq!(mock_messaggero.messaggi_inviati.borrow().len(), 1);
}
}RefCell<T> generi un panicCreiamo una variabile borrow_uno per il puntatore intelligente RefMut<T>
restituito da borrow_mut. Quindi creiamo un altro prestito mutabile allo
stesso modo nella variabile borrow_due. Questo crea due reference mutabili
nello stesso scope, cosa non consentita. Quando eseguiamo i test per la nostra
libreria, il codice nel Listato 15-23 verrà compilato senza errori, ma il test
fallirà:
$ cargo test
Compiling traccia-limiti v0.1.0 (file:///progetti/traccia-limiti)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.01s
Running unittests src/lib.rs (target/debug/deps/traccia_limiti-b118b9738b4f0e54)
running 1 test
test tests::invia_un_messaggio_di_avviso_di_superamento_del_75_percento ... FAILED
failures:
---- tests::invia_un_messaggio_di_avviso_di_superamento_del_75_percento stdout ----
thread 'tests::invia_un_messaggio_di_avviso_di_superamento_del_75_percento' panicked at src/lib.rs:61:56:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::invia_un_messaggio_di_avviso_di_superamento_del_75_percento
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nota che il codice è andato in panic con il messaggio already borrowed: BorrowMutError. Ecco come RefCell<T> gestisce le violazioni delle regole di
prestito in fase di esecuzione.
Scegliere di rilevare gli errori di prestito durante l’esecuzione anziché in
fase di compilazione, come abbiamo fatto qui, significa che potenzialmente si
troverebbero errori nel codice in una fase successiva del processo di sviluppo:
probabilmente non prima del rilascio del codice in produzione. Inoltre, il
codice subirebbe una piccola penalizzazione delle prestazioni durante
l’esecuzione a causa del monitoraggio dei prestiti durante l’esecuzione anziché
in fase di compilazione. Tuttavia, l’utilizzo di RefCell<T> consente di
scrivere un oggetto fittizio in grado di modificarsi per tenere traccia dei
messaggi visualizzati durante l’utilizzo in un contesto in cui sono consentiti
solo valori immutabili. È possibile utilizzare RefCell<T> nonostante i suoi
compromessi per ottenere più funzionalità rispetto a quelle fornite dai
reference standard.
Consentire più Proprietari di Dati Mutabili
Un modo comune per utilizzare RefCell<T> è in combinazione con Rc<T>.
Ricorda che Rc<T> consente di avere più proprietari di alcuni dati, ma
fornisce solo un accesso immutabile a tali dati. Se hai un Rc<T> che contiene
un RefCell<T>, puoi ottenere un valore che può avere più proprietari e che
puoi mutare!
Ad esempio, ricorda l’esempio della cons list nel Listato 15-18, dove abbiamo
utilizzato Rc<T> per consentire a più liste di condividere la proprietà di
un’altra lista. Poiché Rc<T> contiene solo valori immutabili, non possiamo
modificare nessuno dei valori nell’elenco una volta creato. Aggiungiamo
RefCell<T> per la sua capacità di modificare i valori negli elenchi. Il
Listato 15-24 mostra che utilizzando RefCell<T> nella definizione di Cons,
possiamo modificare il valore memorizzato in tutte le liste.
#[derive(Debug)] enum Lista { Cons(Rc<RefCell<i32>>, Rc<Lista>), Nil, } use crate::Lista::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let valore = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&valore), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); *valore.borrow_mut() += 10; println!("a dopo = {a:?}"); println!("b dopo = {b:?}"); println!("c dopo = {c:?}"); }
Rc<RefCell<i32>> per creare una Lista che possiamo modificareCreiamo un valore che è un’istanza di Rc<RefCell<i32>> e lo memorizziamo in
una variabile denominata valore in modo da potervi accedere direttamente in
seguito. Quindi creiamo una Lista in a con una variante Cons che contiene
valore. Dobbiamo clonare valore in modo che sia a che valore abbiano la
ownership del valore 5 interno, anziché trasferire la proprietà da valore
ad a o far sì che a prenda il prestito da valore.
Racchiudiamo la lista a in un Rc<T> in modo che quando creiamo le liste b
e c, possano entrambe fare riferimento ad a, come abbiamo fatto nel Listato
15-18.
Dopo aver creato le liste in a, b e c, vogliamo aggiungere 10 al valore in
valore. Lo facciamo chiamando borrow_mut su valore, che utilizza la
funzione di de-referenziazione automatica di cui abbiamo parlato nella sezione
“Dov’è l’operatore ->?” del Capitolo 5
per de-referenziare Rc<T> al valore interno RefCell<T>. Il metodo
borrow_mut restituisce un puntatore intelligente RefMut<T>, su cui
utilizziamo l’operatore di de-referenziazione e modifichiamo il valore interno.
Quando stampiamo a, b e c, possiamo vedere che hanno tutti il valore
modificato di 15 anziché 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///progetti/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 3.78s
Running `target/debug/cons-list`
a dopo = Cons(RefCell { value: 15 }, Nil)
b dopo = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c dopo = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Questa tecnica è davvero interessante! Utilizzando RefCell<T>, abbiamo un
valore Lista esternamente immutabile. Ma possiamo usare i metodi su
RefCell<T> che forniscono l’accesso alla sua mutabilità interna, così da poter
modificare i nostri dati quando necessario. I controlli durante l’esecuzione
delle regole di prestito ci proteggono dalle data race, e a volte vale la pena
sacrificare un po’ di prestazioni per questa flessibilità nelle nostre strutture
dati. Nota che RefCell<T> non funziona per il codice multi-thread!
Mutex<T> è la versione di RefCell<T> che funzioni ai ambito multi-thread e
ne parleremo nel Capitolo 16.
Cicli di Riferimento Possono Causare Perdite di Memoria
Le garanzie di sicurezza della memoria di Rust rendono difficile, ma non
impossibile, creare accidentalmente memoria che non viene mai de-allocata (noto
come memory leak, perdita di memoria). Prevenire completamente le perdite di
memoria non è una delle garanzie di Rust, il che significa che le perdite di
memoria sono sicure in Rust. Possiamo vedere che Rust consente perdite di
memoria utilizzando Rc<T> e RefCell<T>: è possibile creare reference in
cui gli elementi si riferiscono l’uno all’altro in un ciclo. Questo crea perdite
di memoria perché il conteggio dei reference di ciascun elemento nel ciclo non
raggiungerà mai 0 e i valori non verranno mai de-allocati.
Creare un Ciclo di Riferimento
Esaminiamo come potrebbe verificarsi un ciclo di riferimento e come prevenirlo,
iniziando con la definizione dell’enum Lista e di un metodo coda nel
Listato 15-25.
use crate::Lista::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum Lista { Cons(i32, RefCell<Rc<Lista>>), Nil, } impl Lista { fn coda(&self) -> Option<&RefCell<Rc<Lista>>> { match self { Cons(_, elemento) => Some(elemento), Nil => None, } } } fn main() {}
RefCell<T> in modo da poter modificare a cosa fa riferimento una variante ConsStiamo utilizzando un’altra variante della definizione Lista del Listato 15-5.
Il secondo elemento nella variante Cons è ora RefCell<Rc<Lista>>, il che
significa che invece di poter modificare il valore i32 come abbiamo fatto nel
Listato 15-24, vogliamo modificare il valore Lista a cui punta una variante
Cons. Stiamo anche aggiungendo un metodo coda per facilitare l’accesso al
secondo elemento se abbiamo una variante Cons.
Nel Listato 15-26, stiamo aggiungendo una funzione main che utilizza le
definizioni nel Listato 15-25. Questo codice crea una lista in a e una lista
in b che punta alla lista in a. Quindi modifica la lista in a per puntare
a b, creando un ciclo di riferimento. Ci sono istruzioni println! lungo il
codice per mostrare quali sono i conteggi dei reference in vari punti di
questo processo.
use crate::Lista::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum Lista { Cons(i32, RefCell<Rc<Lista>>), Nil, } impl Lista { fn coda(&self) -> Option<&RefCell<Rc<Lista>>> { match self { Cons(_, elemento) => Some(elemento), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a conteggio rc iniziale = {}", Rc::strong_count(&a)); println!("a prossimo elemento = {:?}", a.coda()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a conteggio rc dopo creazione b = {}", Rc::strong_count(&a)); println!("b conteggio rc iniziale = {}", Rc::strong_count(&b)); println!("b prossimo elemento = {:?}", b.coda()); if let Some(link) = a.coda() { *link.borrow_mut() = Rc::clone(&b); } println!("b conteggio rc dopo modifica a = {}", Rc::strong_count(&b)); println!("a conteggio rc dopo modifica a = {}", Rc::strong_count(&a)); // Togli il commento alla prossima riga per vedere che // abbiamo un ciclo; causerà un overflow dello stack. // println!("a prossimo elemento = {:?}", a.coda()); }
Lista che puntano l’uno all’altroCreiamo un’istanza Rc<Lista> che contiene un valore Lista nella variabile
a con una lista iniziale di 5, Nil. Creiamo quindi un’istanza Rc<Lista>
che contiene un altro valore Lista nella variabile b che contiene il valore
10 e punta alla lista in a.
Modifichiamo a in modo che punti a b invece che a Nil, creando un ciclo.
Lo facciamo utilizzando il metodo coda per ottenere un reference a
RefCell<Rc<Lista>> in a, che inseriamo nella variabile link. Quindi
utilizziamo il metodo borrow_mut su RefCell<Rc<Lista>> per modificare il
valore al suo interno da Rc<Lista> che contiene un valore Nil a Rc<Lista>
in b.
Quando eseguiamo questo codice, lasciando l’ultimo println! commentato per il
momento, otterremo questo output:
$ cargo run
Compiling cons-list v0.1.0 (file:///progetti/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.36s
Running `target/debug/cons-list`
a conteggio rc iniziale = 1
a prossimo elemento = Some(RefCell { value: Nil })
a conteggio rc dopo creazione b = 2
b conteggio rc iniziale = 1
b prossimo elemento = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b conteggio rc dopo modifica a = 2
a conteggio rc dopo modifica a = 2
Il conteggio dei reference delle istanze di Rc<Lista> sia in a che in b
è 2 dopo aver modificato la lista in a in modo che punti a b. Alla fine di
main, Rust elimina la variabile b, che riduce il conteggio dei reference
dell’istanza b Rc<Lista> da 2 a 1. La memoria che Rc<Lista> ha nell’heap
non verrà de-allocata in questo punto perché il suo conteggio dei reference è
1, non 0. Quindi Rust elimina a, che riduce anche il conteggio dei reference
dell’istanza a Rc<Lista> da 2 a 1. Anche la memoria di questa istanza non
può essere de-allocata, perché l’altra istanza Rc<Lista> fa ancora riferimento
ad essa. La memoria allocata alla lista rimarrà non utilizzata per sempre. Per
visualizzare questo ciclo di riferimento, abbiamo creato il diagramma in Figura
15-4.

Figura 15-4: Un ciclo di riferimento delle liste a e b
che puntano l’una all’altra
Se si rimuove il commento dall’ultimo println! e si esegue il programma, Rust
proverà a stampare questo ciclo con a che punta a b che punta a a e così
via fino a quando lo stack non si riempie completamente (stack overflow).
Rispetto a un programma reale, le conseguenze della creazione di un ciclo di riferimento in questo esempio non sono poi così gravi: subito dopo aver creato il ciclo di riferimento, il programma termina. Tuttavia, se un programma più complesso allocasse molta memoria in un ciclo e la mantenesse per un lungo periodo, utilizzerebbe più memoria del necessario e potrebbe sovraccaricare il sistema, causando l’esaurimento della memoria disponibile.
Creare cicli di riferimento non è facile, ma non è nemmeno impossibile. Se si
hanno valori RefCell<T> che contengono valori Rc<T> o simili combinazioni
annidate di type con mutabilità interna e conteggio dei reference, è
necessario assicurarsi di non creare cicli; non ci si può affidare a Rust per
individuarli. Creare un ciclo di riferimento rappresenterebbe un bug logico nel
programma che bisognerebbe minimizzare tramite test automatizzati, revisioni del
codice e altre pratiche di sviluppo software.
Un’altra soluzione per evitare i cicli di riferimento è riorganizzare le
strutture dati in modo che alcuni reference esprimano la ownership e altri
no. Di conseguenza, si possono avere cicli composti da alcune relazioni di
ownership e alcune relazioni di non ownership, e solo le relazioni di
ownership influiscono sulla possibilità o meno di eliminare un valore. Nel
Listato 15-25, vogliamo sempre che le varianti Cons posseggano la propria
lista, quindi riorganizzare la struttura dati non è possibile. Diamo un’occhiata
a un esempio che utilizza grafi composti da nodi genitore e nodi figlio per
vedere quando le relazioni di non ownership sono un modo appropriato per
prevenire i cicli di riferimento.
Prevenire Cicli di Riferimento Usando Weak<T>
Finora, abbiamo dimostrato che la chiamata a Rc::clone aumenta lo
strong_count di un’istanza di Rc<T> e che un’istanza di Rc<T> viene
de-allocata solo se il suo strong_count è 0. È anche possibile creare un
reference debole (weak reference) al valore all’interno di un’istanza di
Rc<T> chiamando Rc::downgrade e passando un reference a Rc<T>. I
reference forti (strong reference) rappresentano il modo in cui è
possibile condividere la ownership di un’istanza di Rc<T>. I reference
deboli non esprimono una relazione di ownership e il loro conteggio non
influisce sulla de-allocazione di un’istanza di Rc<T>. Non causeranno un ciclo
di riferimento perché qualsiasi ciclo che coinvolga reference deboli verrà
interrotto quando il conteggio dei valori coinvolti nei reference forti sarà
pari a 0.
Quando si chiama Rc::downgrade, si ottiene un puntatore intelligente di type
Weak<T>. Invece di aumentare di 1 il valore strong_count nell’istanza di
Rc<T>, la chiamata Rc::downgrade aumenta di 1 il valore weak_count. Il
type Rc<T> utilizza weak_count per tenere traccia del numero di
reference Weak<T> esistenti, in modo simile a strong_count. La differenza
è che weak_count non deve essere 0 affinché l’istanza Rc<T> venga
de-allocata.
Poiché il valore a cui fa riferimento Weak<T> potrebbe essere stato eliminato,
per fare qualsiasi cosa con il valore a cui Weak<T> punta, è necessario
assicurarsi che il valore esista ancora. Per farlo, devi chiamare il metodo
upgrade su un’istanza Weak<T> che restituirà Option<Rc<T>>. Otterrai il
risultato Some se il valore Rc<T> non è stato ancora eliminato e il
risultato None se il valore Rc<T> è stato eliminato. Poiché upgrade
restituisce Option<Rc<T>>, Rust garantirà che i casi Some e None vengano
gestiti e che non ci saranno puntatori non validi.
Ad esempio, invece di utilizzare una lista i cui elementi conoscono solo l’elemento successivo, creeremo un albero i cui elementi conoscono i loro elementi figlio e il loro elemento genitore.
Creare una Struttura Dati ad Albero
Per iniziare, creeremo un albero con nodi che conoscono i loro nodi figlio.
Creeremo una struct denominata Nodo che contiene il proprio valore i32 e i
reference ai valori dei suoi Nodo figli:
File: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Nodo { valore: i32, figli: RefCell<Vec<Rc<Nodo>>>, } fn main() { let foglia = Rc::new(Nodo { valore: 3, figli: RefCell::new(vec![]), }); let ramo = Rc::new(Nodo { valore: 5, figli: RefCell::new(vec![Rc::clone(&foglia)]), }); }
Vogliamo che un Nodo possieda i suoi figli e vogliamo condividere tale
ownership con le variabili in modo da poter accedere direttamente a ciascun
Nodo nell’albero. Per fare ciò, definiamo gli elementi Vec<T> come valori di
type Rc<Nodo>. Vogliamo anche modificare quali nodi sono figli di un altro
nodo, quindi abbiamo una RefCell<T> in figli che incapsula Vec<Rc<Nodo>>.
Successivamente, utilizzeremo la nostra struct qui definita e creeremo
un’istanza Nodo denominata foglia con valore 3 e nessun elemento figlio, e
un’altra istanza denominata ramo con valore 5 e foglia come elemento
figlio, come mostrato nel Listato 15-27.
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Nodo { valore: i32, figli: RefCell<Vec<Rc<Nodo>>>, } fn main() { let foglia = Rc::new(Nodo { valore: 3, figli: RefCell::new(vec![]), }); let ramo = Rc::new(Nodo { valore: 5, figli: RefCell::new(vec![Rc::clone(&foglia)]), }); }
foglia senza figli e di un nodo ramo con foglia come figlioCloniamo Rc<Nodo> in foglia e lo memorizziamo in ramo, il che significa
che il Nodo in foglia ora ha due proprietari: foglia e ramo. Possiamo
passare da ramo a foglia tramite ramo.figli, ma non c’è modo di passare da
foglia a ramo. Il motivo è che foglia non ha alcun reference a ramo e
non sa che sono correlati. Vogliamo che anche foglia sappia che ramo è il
suo genitore. Lo faremo ora.
Aggiungere un Reference da un Nodo Figlio al Genitore
Per far sì che il nodo figlio riconosca il suo genitore, dobbiamo aggiungere un
campo genitore alla definizione della nostra struct Nodo. Il problema sta
nel decidere quale tipo di genitore debba essere. Sappiamo che non può
contenere un Rc<T>, perché ciò creerebbe un ciclo di riferimenti con
foglia.genitore che punta a ramo e ramo.figlio che punta a foglia, il
che farebbe sì che i loro valori strong_count non siano mai pari a 0.
Pensando alle relazioni in un altro modo, un nodo genitore dovrebbe possedere i suoi figli: se un nodo genitore viene eliminato, anche i suoi nodi figli dovrebbero essere eliminati. Tuttavia, un figlio non dovrebbe possedere il suo genitore: se eliminiamo un nodo figlio, il genitore dovrebbe comunque continuare ad esistere. Questa è una situazione in cui i reference deboli sono utili!
Quindi, invece di Rc<T>, faremo in modo che il type di genitore sia
Weak<T>, in particolare RefCell<Weak<Nodo>>. Ora la definizione della
struct Nodo appare così:
File: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Nodo { valore: i32, genitore: RefCell<Weak<Nodo>>, figli: RefCell<Vec<Rc<Nodo>>>, } fn main() { let foglia = Rc::new(Nodo { valore: 3, genitore: RefCell::new(Weak::new()), figli: RefCell::new(vec![]), }); println!("genitore `foglia` = {:?}", foglia.genitore.borrow().upgrade()); let ramo = Rc::new(Nodo { valore: 5, genitore: RefCell::new(Weak::new()), figli: RefCell::new(vec![Rc::clone(&foglia)]), }); *foglia.genitore.borrow_mut() = Rc::downgrade(&ramo); println!("genitore `foglia` = {:?}", foglia.genitore.borrow().upgrade()); }
Un nodo potrà fare riferimento al suo nodo genitore, ma non ne sarà il
proprietario. Nel Listato 15-28, aggiorniamo main per utilizzare questa nuova
definizione, in modo che il nodo foglia abbia un modo per fare riferimento al
suo genitore, ramo.
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Nodo { valore: i32, genitore: RefCell<Weak<Nodo>>, figli: RefCell<Vec<Rc<Nodo>>>, } fn main() { let foglia = Rc::new(Nodo { valore: 3, genitore: RefCell::new(Weak::new()), figli: RefCell::new(vec![]), }); println!("genitore `foglia` = {:?}", foglia.genitore.borrow().upgrade()); let ramo = Rc::new(Nodo { valore: 5, genitore: RefCell::new(Weak::new()), figli: RefCell::new(vec![Rc::clone(&foglia)]), }); *foglia.genitore.borrow_mut() = Rc::downgrade(&ramo); println!("genitore `foglia` = {:?}", foglia.genitore.borrow().upgrade()); }
foglia con un reference debole al suo nodo genitore, ramoLa creazione del nodo foglia è simile a quella del Listato 15-27, ad eccezione
del campo genitore: foglia inizia senza un genitore, quindi creiamo una
nuova istanza reference vuota Weak<Nodo>.
A questo punto, quando proviamo a ottenere un reference al genitore di
foglia utilizzando il metodo upgrade, otteniamo il valore None. Lo vediamo
nell’output della prima istruzione println!:
genitore `foglia` = None
Quando creiamo il nodo ramo, avrà anche un nuovo reference Weak<Nodo> nel
campo genitore perché ramo non ha un nodo genitore. Abbiamo ancora foglia
come uno dei figli di ramo. Una volta che abbiamo l’istanza Nodo in ramo,
possiamo modificare foglia per assegnargli un reference Weak<Nodo> al suo
genitore. Utilizziamo il metodo borrow_mut su RefCell<Weak<Nodo>> nel campo
genitore di foglia, quindi utilizziamo la funzione Rc::downgrade per
creare un reference Weak<Nodo> a ramo da Rc<Nodo> in ramo.
Quando stampiamo di nuovo il genitore di foglia, questa volta otterremo una
variante Some che contiene ramo: ora foglia può accedere al suo genitore!
Quando stampiamo foglia, evitiamo anche il ciclo che alla fine si è concluso
con uno stack overflow come nel Listato 15-26; i riferimenti Weak<Nodo>
vengono stampati come (Weak):
genitore `foglia` = None
genitore `foglia` = Some(Nodo { valore: 5, genitore: RefCell { value: (Weak) }, figlio: RefCell { value: [Nodo { valore: 3, genitore: RefCell { value: (Weak) }, figlio: RefCell { value: [] } }] } })
L’assenza di output infinito indica che questo codice non ha creato un ciclo di
riferimento. Possiamo anche dedurlo osservando i valori ottenuti chiamando
Rc::strong_count e Rc::weak_count.
Visualizzare le Modifiche a strong_count e weak_count
Osserviamo come i valori di strong_count e weak_count delle istanze di
Rc<Nodo> cambiano creando un nuovo scope interno e spostando la creazione di
ramo in tale scope. In questo modo, possiamo vedere cosa succede quando
ramo viene creato e poi eliminato quando esce dallo scope. Le modifiche sono
mostrate nel Listato 15-29.
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Nodo { valore: i32, genitore: RefCell<Weak<Nodo>>, figli: RefCell<Vec<Rc<Nodo>>>, } fn main() { let foglia = Rc::new(Nodo { valore: 3, genitore: RefCell::new(Weak::new()), figli: RefCell::new(vec![]), }); println!( "foglia forte = {}, debole = {}", Rc::strong_count(&foglia), Rc::weak_count(&foglia), ); { let ramo = Rc::new(Nodo { valore: 5, genitore: RefCell::new(Weak::new()), figli: RefCell::new(vec![Rc::clone(&foglia)]), }); *foglia.genitore.borrow_mut() = Rc::downgrade(&ramo); println!( "ramo forte = {}, debole = {}", Rc::strong_count(&ramo), Rc::weak_count(&ramo), ); println!( "foglia forte = {}, debole = {}", Rc::strong_count(&foglia), Rc::weak_count(&foglia), ); } println!("genitore `foglia` = {:?}", foglia.genitore.borrow().upgrade()); println!( "foglia forte = {}, debole = {}", Rc::strong_count(&foglia), Rc::weak_count(&foglia), ); }
ramo in uno scope interno ed esame dei conteggi dei reference forti e deboliDopo la creazione di foglia, il suo Rc<Nodo> ha un conteggio forte di 1 e un
conteggio debole di 0. Nello scope interno, creiamo ramo e lo associamo a
foglia; a quel punto, quando stampiamo i conteggi, Rc<Nodo> in ramo avrà
un conteggio forte di 1 e un conteggio debole di 1 (per foglia.genitore che
punta a ramo con un Weak<Nodo>). Quando stampiamo i conteggi in foglia,
vedremo che avrà un conteggio forte di 2 perché ramo ora ha un clone di
Rc<Nodo> di foglia memorizzato in ramo.figlio, ma avrà ancora un conteggio
debole di 0.
Quando lo scope interno termina, ramo esce dallo scope e il conteggio
forte di Rc<Nodo> scende a 0, quindi il suo Nodo viene eliminato. Il
conteggio debole di 1 da foglia.genitore non ha alcuna influenza
sull’eliminazione o meno di Nodo, quindi non si verificano perdite di memoria!
Se proviamo ad accedere al genitore di foglia dopo la fine dello scope,
otterremo di nuovo None. Alla fine del programma, Rc<Nodo> in foglia ha un
conteggio forte di 1 e un conteggio debole di 0 perché la variabile foglia è
ora di nuovo l’unico reference a Rc<Nodo>.
Tutta la logica che gestisce i conteggi e l’eliminazione dei valori è integrata
in Rc<T> e Weak<T> e nelle loro implementazioni del trait Drop.
Specificando che la relazione tra un figlio e il suo genitore debba essere un
reference Weak<T> nella definizione di Nodo, è possibile fare in modo che
i nodi genitore puntino ai nodi figlio e viceversa senza creare un ciclo di
riferimento e perdite di memoria.
Riepilogo
Questo capitolo ha spiegato come utilizzare i puntatori intelligenti per
ottenere garanzie e compromessi diversi da quelli che Rust applica di default
con i normali reference. Il type Box<T> ha una dimensione nota e punta ai
dati allocati nell’heap. Il type Rc<T> tiene traccia del numero di
reference ai dati nell’heap, in modo che i dati possano avere più
proprietari. Il type RefCell<T> con la sua mutabilità interna ci fornisce un
type che possiamo usare quando abbiamo bisogno di un type immutabile ma con
la possibilità di modificare un valore interno di quel type; inoltre, applica
le regole di prestito in fase di esecuzione anziché in fase di compilazione.
Sono stati inoltre discussi i trait Deref e Drop, che abilitano molte
delle funzionalità dei puntatori intelligenti. Abbiamo esplorato i cicli di
riferimento che possono causare perdite di memoria e come prevenirle utilizzando
Weak<T>.
Se questo capitolo ha suscitato il tuo interesse e desideri implementare i tuoi puntatori intelligenti, consulta “The Rustonomicon” per ulteriori informazioni utili.
In seguito, parleremo della concorrenza in Rust. Imparerai anche a conoscere alcuni nuovi puntatori intelligenti.
Concorrenza Senza Paura
Gestire la programmazione concorrente in modo sicuro ed efficiente è un altro degli obiettivi principali di Rust. La programmazione concorrente, in cui le diverse parti di un programma vengono eseguite in modo indipendente, e la programmazione parallela, in cui le diverse parti di un programma vengono eseguite contemporaneamente, stanno diventando sempre più importanti per sfruttare i processori multi-core dei moderni computer. Storicamente, la programmazione in questi contesti è stata difficile e soggetta a errori. Rust spera di cambiare questa situazione.
Inizialmente, il team di Rust pensava che garantire la sicurezza della memoria e prevenire i problemi di concorrenza fossero due sfide distinte da risolvere con metodi diversi. Con il tempo, il team ha scoperto che i sistemi di ownership e dei type sono un potente insieme di strumenti che aiutano a gestire la sicurezza della memoria e i problemi di concorrenza! Sfruttando la ownership e il controllo dei type, molti errori di concorrenza in Rust sono rilevati in fase di compilazione piuttosto che presentarsi durante l’esecuzione. Pertanto, invece di farti perdere molto tempo a cercare di riprodurre le circostanze esatte in cui si verifica un bug di concorrenza in fase di esecuzione, il codice errato non verrà compilato e presenterà un errore che spiega il problema. Di conseguenza, puoi correggere il tuo codice mentre ci stai lavorando piuttosto che potenzialmente dopo che è stato compilato e distribuito a chi lo utilizza. Abbiamo soprannominato questo aspetto di Rust fearless concurrency (concorrenza senza paura). La concorrenza senza paura ti permette di scrivere codice privo di bug subdoli e facile da riscrivere senza introdurre nuovi bug.
Nota: per semplicità, ci riferiremo a molti problemi come concorrenti piuttosto che essere più precisi dicendo concorrenti e/o paralleli. Per questo capitolo, sostituisci mentalmente concorrenti e/o paralleli ogni volta che usiamo concorrenti. Nel prossimo capitolo, dove la distinzione è più importante, saremo più specifici.
Molti linguaggi sono dogmatici sulle soluzioni che offrono per gestire i problemi di concorrenza. Ad esempio, Erlang dispone di eleganti funzionalità per la concomitanza con il passaggio di messaggi, ma mette a disposizione solo metodi astrusi per condividere lo stato tra i thread. Supportare solo un sottoinsieme di soluzioni possibili è una strategia ragionevole per i linguaggi di livello superiore, perché un linguaggio di livello superiore promette di trarre vantaggio dalla rinuncia a un po’ di controllo per ottenere astrazioni. Tuttavia, i linguaggi di livello inferiore devono fornire la soluzione con le migliori prestazioni in ogni situazione e hanno meno astrazioni sull’hardware. Per questo motivo, Rust offre una varietà di strumenti per modellare i problemi in qualsiasi modo sia appropriato per la tua situazione e i tuoi requisiti.
Ecco gli argomenti che tratteremo in questo capitolo:
- Come creare thread per eseguire più parti di codice contemporaneamente
- Concorrenza con passaggio di messaggi (Message-passing concurrency), in cui i canali inviano messaggi tra i thread
- Concorrenza con stato condiviso (Shared-state concurrency), in cui più thread hanno accesso ad alcuni dati
- I trait
SynceSend, che estendono le garanzie di concorrenza di Rust ai type definiti dall’utente oltre che ai type forniti dalla libreria standard
Usare i Thread Per Eseguire Codice Simultaneamente
Nella maggior parte dei sistemi operativi attuali, il codice di un programma viene eseguito in un processo e il sistema operativo gestisce più processi contemporaneamente. All’interno di un programma, è possibile avere anche parti indipendenti che vengono eseguite simultaneamente. Le funzionalità che eseguono queste parti indipendenti sono chiamate thread. Ad esempio, un server web potrebbe avere più thread in modo da poter rispondere a più richieste contemporaneamente.
Suddividere i calcoli del tuo programma in più thread per eseguire più attività contemporaneamente può migliorare le prestazioni, ma aggiunge anche complessità. Poiché i thread possono essere eseguiti simultaneamente, non c’è alcuna garanzia intrinseca sull’ordine di esecuzione dei thread del tuo codice. Questo può portare a problemi, come ad esempio:
- Competizione (race condition), in cui i thread accedono ai dati o alle risorse in un ordine incoerente
- Stallo (deadlock), in cui due thread sono in attesa l’uno dell’altro, impedendo a entrambi di continuare
- Bug che si verificano solo in determinate situazioni e sono difficili da riprodurre e risolvere in modo affidabile
Rust cerca di mitigare gli effetti negativi dell’uso dei thread, ma programmare in un contesto multi-thread richiede comunque un’attenta riflessione e una struttura del codice diversa da quella dei programmi eseguiti in un singolo thread.
I linguaggi di programmazione implementano i thread in diversi modi e molti sistemi operativi forniscono un’API che il linguaggio di programmazione può richiamare per creare nuovi thread. La libreria standard di Rust utilizza un modello 1:1 di implementazione dei thread, in base al quale un programma utilizza un thread del sistema operativo per ogni thread del linguaggio. Esistono dei crate che implementano altri modelli di threading che fanno dei compromessi diversi rispetto al modello 1:1. (Anche il sistema async di Rust, che vedremo nel prossimo capitolo, fornisce un ulteriore approccio alla concorrenza.)
Creare un Nuovo Thread con spawn
Per creare un nuovo thread, chiamiamo la funzione thread::spawn e le
passiamo una chiusura (abbiamo parlato delle chiusure nel Capitolo
13) contenente il codice che vogliamo eseguire nel nuovo thread.
L’esempio nel Listato 16-1 stampa del testo da un thread principale e altro
testo da un nuovo thread.
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("ciao numero {i} dal thread generato!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("ciao numero {i} dal thread principale!"); thread::sleep(Duration::from_millis(1)); } }
Come puoi notare dall’output quando il thread main del programma Rust finisce anche il thread generato viene interrotto, che abbia o meno finito di fare quello che doveva fare. Eccolo qui:
ciao numero 1 dal thread principale!
ciao numero 1 dal thread generato!
ciao numero 2 dal thread principale!
ciao numero 2 dal thread generato!
ciao numero 3 dal thread principale!
ciao numero 3 dal thread generato!
ciao numero 4 dal thread principale!
ciao numero 4 dal thread generato!
ciao numero 5 dal thread generato!
Le chiamate a thread::sleep costringono un thread a interrompere la sua
esecuzione per un breve periodo, consentendo a un altro thread di funzionare.
I thread probabilmente si alterneranno, ma questo non è garantito: dipende da
come il sistema operativo pianifica i thread. In questa esecuzione, il
thread principale ha stampato per primo, anche se l’istruzione di stampa del
thread generato (spawned) appare per prima nel codice. E anche se abbiamo
detto al thread generato di stampare finché i non è 9, è arrivato solo a
5 prima che il thread principale si concludesse.
Se esegui questo codice e vedi solo l’output del thread principale o non vedi alcuna sovrapposizione, prova ad aumentare i numeri negli intervalli per creare più opportunità per il sistema operativo di passare da un thread all’altro.
Attendere Che Tutti i Thread Finiscano
Il codice nel Listato 16-1 non solo arresta il thread generato prematuramente nella maggior parte dei casi a causa della fine del thread principale, ma poiché non c’è alcuna garanzia sull’ordine di esecuzione dei thread, non possiamo nemmeno garantire che il thread generato venga eseguito!
Possiamo risolvere il problema del thread generato che non viene eseguito o
che termina prematuramente salvando il valore di ritorno di thread::spawn in
una variabile. Il type restituito da thread::spawn è JoinHandle<T>. Un
JoinHandle<T> è un valore posseduto che, quando chiamiamo il metodo join su
di esso, aspetterà che il suo thread finisca. Il Listato 16-2 mostra come
utilizzare il JoinHandle<T> del thread creato nel Listato 16-1 e come
chiamare join per assicurarsi che il thread generato finisca prima che
main si concluda.
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("ciao numero {i} dal thread generato!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("ciao numero {i} dal thread principale!"); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); }
JoinHandle<T> da thread::spawn per garantire che il thread venga eseguito fino al completamentoLa chiamata a join sull’handle blocca il thread attualmente in esecuzione
fino a quando il thread rappresentato dall’handle non termina. Bloccare un
thread significa che a quel thread viene impedito di eseguire lavori o di
uscire. Poiché abbiamo inserito la chiamata a join dopo il ciclo for del
thread principale, l’esecuzione del Listato 16-2 dovrebbe produrre un
risultato simile a questo:
ciao numero 1 dal thread principale!
ciao numero 1 dal thread generato!
ciao numero 2 dal thread principale!
ciao numero 2 dal thread generato!
ciao numero 3 dal thread principale!
ciao numero 3 dal thread generato!
ciao numero 4 dal thread principale!
ciao numero 4 dal thread generato!
ciao numero 5 dal thread generato!
ciao numero 6 dal thread generato!
ciao numero 7 dal thread generato!
ciao numero 8 dal thread generato!
ciao numero 9 dal thread generato!
I due thread continuano ad alternarsi, ma il thread principale attende a
causa della chiamata a handle.join() e non termina finché il thread generato
non è terminato.
Ma vediamo cosa succede se spostiamo handle.join() prima del ciclo for di
main, in questo modo:
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("ciao numero {i} dal thread generato!"); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("ciao numero {i} dal thread principale!"); thread::sleep(Duration::from_millis(1)); } }
Il thread principale aspetterà che il thread generato finisca e poi eseguirà
il suo ciclo for, quindi l’output non sarà più alternato, come mostrato qui:
ciao numero 1 dal thread generato!
ciao numero 2 dal thread generato!
ciao numero 3 dal thread generato!
ciao numero 4 dal thread generato!
ciao numero 5 dal thread generato!
ciao numero 6 dal thread generato!
ciao numero 7 dal thread generato!
ciao numero 8 dal thread generato!
ciao numero 9 dal thread generato!
ciao numero 1 dal thread principale!
ciao numero 2 dal thread principale!
ciao numero 3 dal thread principale!
ciao numero 4 dal thread principale!
Piccoli dettagli, come il punto in cui viene chiamato join, possono
influenzare l’esecuzione simultanea o meno dei thread.
Usare le Chiusure move con i Thread
Spesso useremo la parola chiave move con le chiusure passate a thread::spawn
perché la chiusura prenderà la ownership dei valori che utilizza
dall’ambiente, trasferendo così la ownership di quei valori da un thread
all’altro. In “Catturare i Reference o Trasferire la
Ownership” del Capitolo 13, abbiamo parlato di move
nel contesto delle chiusure. Ora ci concentreremo maggiormente sull’interazione
tra move e thread::spawn.
Nota nel Listato 16-1 che la chiusura che passiamo a thread::spawn non accetta
argomenti: non stiamo utilizzando alcun dato del thread principale nel codice
del thread generato. Per utilizzare i dati del thread principale nel
thread generato, la chiusura del thread generato deve catturare i valori di
cui ha bisogno. Il Listato 16-3 mostra un tentativo di creare un vettore nel
thread principale e di utilizzarlo nel thread generato. Tuttavia, questo non
funziona ancora, come vedrai tra poco.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Ecco un vettore: {v:?}");
});
handle.join().unwrap();
}La chiusura utilizza v, quindi catturerà v e lo renderà parte dell’ambiente
della chiusura. Poiché thread::spawn esegue questa chiusura in un nuovo
thread, dovremmo essere in grado di accedere a v all’interno di questo nuovo
thread. Ma quando compiliamo questo esempio, otteniamo il seguente errore:
$ cargo run
Compiling threads v0.1.0 (file:///progetti/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Ecco un vettore: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Ecco un vettore: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust inferisce come catturare v e, poiché println! ha bisogno solo di un
reference a v, la chiusura cerca di prendere in prestito v. Tuttavia, c’è
un problema: Rust non può sapere per quanto tempo verrà eseguito il thread
generato, quindi non sa se il reference a v sarà sempre valido.
Il Listato 16-4 mostra uno scenario in cui è più probabile che un reference a
v non sia valido.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Ecco un vettore: {v:?}");
});
drop(v); // oh, no!
handle.join().unwrap();
}v da un thread principale che libera vSe Rust ci permettesse di eseguire questo codice, è possibile che il thread
generato venga immediatamente messo in background senza essere eseguito affatto.
Il thread generato ha un reference a v al suo interno, ma il thread
principale libera immediatamente v, utilizzando la funzione drop di cui
abbiamo parlato nel Capitolo 15. Poi, quando il thread generato viene
eseguito, v non è più valido, quindi anche il reference ad esso non è
valido. Oh, no!
Per risolvere l’errore del compilatore nel Listato 16-3, possiamo utilizzare i consigli del messaggio di errore:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Aggiungendo la parola chiave move prima della chiusura, obblighiamo la
chiusura a prendere ownership dei valori che sta utilizzando, invece di
permettere a Rust di dedurre che deve prendere in prestito i valori. La modifica
al Listato 16-3 mostrata nel Listato 16-5 verrà compilata ed eseguita come
previsto.
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Ecco un vettore: {v:?}"); }); handle.join().unwrap(); }
move per forzare una chiusura a prendere ownership dei valori che utilizzaPotremmo essere tentati di fare la stessa cosa per correggere il codice del
Listato 16-4 in cui il thread principale chiamava drop utilizzando una
chiusura move. Tuttavia, questa correzione non funzionerà perché ciò che il
Listato 16-4 sta cercando di fare è vietato per un motivo diverso. Se
aggiungessimo move alla chiusura, sposteremmo v nell’ambiente della chiusura
e non potremmo più chiamare drop su di essa nel thread principale.
Otterremmo invece questo errore del compilatore:
$ cargo run
Compiling threads v0.1.0 (file:///progetti/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Ecco un vettore: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Ecco un vettore: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Le regole di ownership di Rust ci hanno salvato ancora una volta! Abbiamo
ricevuto un errore dal codice del Listato 16-3 perché Rust era conservativo e
prendeva solo in prestito v per il thread, il che significava che il
thread principale poteva teoricamente invalidare il reference del thread
generato. Dicendo a Rust di spostare la ownership di v al thread generato,
garantiamo a Rust che il thread principale non userà più v. Se modifichiamo
il Listato 16-4 nello stesso modo, violeremo le regole di ownership quando
cercheremo di usare v nel thread principale. La parola chiave move
sovrascrive il comportamento conservativo di Rust di prendere in prestito; non
ci permette di violare le regole di ownership.
Ora che abbiamo analizzato cosa sono i thread e i metodi forniti dall’API dei thread, vediamo alcune situazioni in cui possiamo utilizzarli.
Trasferire Dati tra Thread Usando il Passaggio di Messaggi
Un approccio sempre più diffuso per garantire una concomitanza sicura è il passaggio di messaggi (message passing), in cui i thread o gli attori comunicano inviandosi messaggi contenenti dati. Ecco l’idea in uno slogan tratto dalla documentazione del linguaggio Go: “Non comunicare condividendo la memoria; condividi invece la memoria comunicando.”
Per realizzare la concomitanza tramite invio di messaggi, la libreria standard di Rust fornisce un’implementazione dei canali. Un canale è un concetto generale di programmazione con cui i dati vengono inviati da un thread all’altro.
Puoi immaginare un canale nella programmazione come un canale d’acqua direzionale, come un ruscello o un fiume. Se metti una paperella di gomma in un fiume, questa viaggerà a valle fino alla fine del corso d’acqua.
Un canale ha due estremità: una trasmettitore e una ricevitore. L’estremità del trasmettitore è il punto a monte in cui metti la paperella di gomma nel fiume, mentre l’estremità del ricevitore è il punto in cui la paperella di gomma finisce a valle. Una parte del tuo codice chiama i metodi del trasmettitore con i dati che vuoi inviare, mentre un’altra parte controlla la ricezione dei messaggi in arrivo. Un canale si dice chiuso se una delle due estremità del trasmettitore o del ricevitore viene cancellata.
Qui lavoreremo su un programma che ha un thread che genera valori e li invia attraverso un canale, e un altro thread che riceve i valori e li stampa. Per illustrare la funzione, invieremo semplici valori tra i thread utilizzando un canale. Una volta che avrai acquisito familiarità con la tecnica, potrai utilizzare i canali per qualsiasi thread che abbia bisogno di comunicare tra loro, come ad esempio un sistema di chat o un sistema in cui molti thread eseguono parti di un calcolo e inviano i risultati parziali a un thread che aggrega i risultati.
Iniziamo nel Listato 16-6 creando semplicemente un canale senza fargli fare nulla. Nota che questo non verrà ancora compilato perché Rust non può dire che tipo di valori vogliamo inviare attraverso il canale.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}tx e rxCreiamo un nuovo canale utilizzando la funzione mpsc::channel; mpsc sta per
multiple producer, single consumer. In breve, il modo in cui la libreria
standard di Rust implementa i canali significa che un canale può avere più punti
di invio (produttori) che producono valori, ma un solo punto di ricezione
(consumatore) che li riceve. Immagina più ruscelli che confluiscono in un
unico grande fiume: tutto ciò che viene inviato lungo uno qualsiasi dei ruscelli
finirà in un unico fiume alla fine. Inizieremo con un singolo produttore per
ora, ma aggiungeremo più produttori quando questo esempio funzionerà.
La funzione mpsc::channel restituisce una tupla, in cui il primo elemento è
l’estremità di invio, il trasmettitore, e il secondo elemento è l’estremità di
ricezione, il ricevitore. Le abbreviazioni tx e rx sono tradizionalmente
utilizzate in molti campi per indicare rispettivamente il trasmettitore e il
ricevitore, quindi chiamiamo le nostre variabili in questo modo per indicare
ciascuna estremità. Stiamo utilizzando un’istruzione let con un pattern che
destruttura la tupla; parleremo più approfonditamente dell’uso dei pattern
nelle istruzioni let e della destrutturazione nel Capitolo 19. Per ora, sappi
che l’utilizzo di un’istruzione let in questo modo è un approccio conveniente
per estrarre i pezzi della tupla restituita da mpsc::channel.
Spostiamo l’estremità di trasmissione in un thread generato e facciamogli inviare una stringa in modo che il thread generato comunichi con il thread principale, come mostrato nel Listato 16-7. Questo è come mettere una paperella di gomma nel fiume a monte o inviare un messaggio di chat da un thread all’altro.
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("ciao"); tx.send(val).unwrap(); }); }
tx in un thread generato e invio di “ciao”Anche in questo caso, usiamo thread::spawn per generare un nuovo thread e
poi usiamo move per spostare tx nella chiusura in modo che il thread
generato possieda tx. Il thread generato deve possedere il trasmettitore per
poter inviare messaggi attraverso il canale.
Il trasmettitore ha un metodo send (invio) che accetta il valore che
vogliamo inviare. Il metodo send restituisce un type Result<T, E>, quindi
se il ricevitore è già stato cancellato e non c’è nessuno che possa ricevere
quanto inviato, l’operazione di invio restituirà un errore. In questo esempio,
chiamiamo unwrap per andare in panic in caso di errore. Ma in
un’applicazione reale, lo gestiremmo in modo corretto: torna al Capitolo 9 per
rivedere le strategie per una corretta gestione degli errori.
Nel Listato 16-8, otterremo il valore dal ricevitore nel thread principale. È come recuperare la paperella di gomma dall’acqua alla fine del fiume o ricevere un messaggio di chat.
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("ciao"); tx.send(val).unwrap(); }); let ricevuto = rx.recv().unwrap(); println!("Ricevuto: {ricevuto}"); }
“ciao” nel thread principale e stamparloIl ricevitore ha due metodi utili: recv e try_recv. Utilizzeremo recv,
abbreviazione di receive (ricevi), che bloccherà l’esecuzione del thread
principale e aspetterà che un valore venga ricevuto dal canale. Una volta
ricevuto un valore, recv lo restituirà in un Result<T, E>. Quando il
trasmettitore si chiude, recv restituirà un errore per segnalare che non
arriveranno altri valori.
Il metodo try_recv invece non aspetterà, ma restituisce immediatamente un
Result<T, E>: un valore Ok che contiene un messaggio se è disponibile e un
valore Err se non ci sono messaggi questa volta. L’uso di try_recv è utile
se questo thread ha altro lavoro da fare mentre aspetta i messaggi: potremmo
scrivere un ciclo che chiama try_recv di tanto in tanto, gestisce un messaggio
se è disponibile e altrimenti svolge altro lavoro per un po’ di tempo fino a
quando non viene controllato di nuovo.
In questo esempio abbiamo usato recv per semplicità; non abbiamo altro lavoro
da fare per il thread principale oltre all’attesa dei messaggi, quindi
bloccare il thread principale è appropriato.
Quando eseguiamo il codice nel Listato 16-8, vedremo il valore stampato dal thread principale:
Ricevuto: ciao
Perfetto!
Trasferire Ownership Attraverso i Canali
Le regole di ownership giocano un ruolo fondamentale nell’invio dei messaggi
perché ti aiutano a scrivere codice sicuro e concorrente. Prevenire gli errori
nella programmazione concorrente è il vantaggio di pensare in termini di
ownership in tutti i tuoi programmi Rust. Facciamo un esperimento per mostrare
come i canali e la ownership lavorino insieme per prevenire i problemi:
proveremo a usare un valore val nel thread generato dopo che lo abbiamo
inviato nel canale. Prova a compilare il codice nel Listato 16-9 per vedere
perché questo codice non è consentito.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("ciao");
tx.send(val).unwrap();
println!("val è {val}");
});
let ricevuto = rx.recv().unwrap();
println!("Ricevuto: {ricevuto}");
}val dopo averlo inviato nel canaleIn questo caso, cerchiamo di stampare val dopo averlo inviato nel canale
tramite tx.send. Consentire questa operazione sarebbe una cattiva idea: una
volta che il valore è stato inviato a un altro thread, questo thread
potrebbe modificarlo o liberarne la memoria prima che noi cerchiamo di
utilizzarlo di nuovo. Potenzialmente, le modifiche dell’altro thread
potrebbero causare errori o risultati inaspettati a causa di dati incoerenti o
inesistenti. Tuttavia, Rust ci dà un errore se proviamo a compilare il codice
del Listato 16-9:
$ cargo run
Compiling passaggio-messaggio v0.1.0 (file:///progetti/passaggio-messaggio)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:26
|
8 | let val = String::from("ciao");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val è {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `passaggio-messaggio` (bin "passaggio-messaggio") due to 1 previous error
Il nostro errore di concorrenza ha causato un errore in fase di compilazione. La
funzione send prende ownership del suo parametro e quando il valore viene
inviato, è il destinatario che ne prende la ownership. Questo ci impedisce di
utilizzare accidentalmente il valore dopo averlo inviato; il sistema di
ownership controlla che tutto sia a posto.
Inviare Più Valori
Il codice del Listato 16-8 è stato compilato ed eseguito, ma non mostrava chiaramente che due thread separati stavano parlando tra loro attraverso il canale.
Nel Listato 16-10, abbiamo apportato alcune modifiche che dimostreranno che il codice del Listato 16-8 è in esecuzione simultanea: il thread generato ora invierà più messaggi e farà una pausa di un secondo tra un messaggio e l’altro.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let valori = vec![
String::from("ciao"),
String::from("dal"),
String::from("thread"),
String::from("!!!"),
];
for valore in valori {
tx.send(valore).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for ricevuto in rx {
println!("Ricevuto: {ricevuto}");
}
}Questa volta, il thread generato ha un vettore di stringhe che vogliamo
inviare al thread principale. Le iteriamo, inviandole singolarmente, e
facciamo una pausa tra una e l’altra chiamando la funzione thread::sleep con
un valore Duration di 1 secondo.
Nel thread principale, non chiamiamo più esplicitamente la funzione recv, ma
trattiamo rx come un iteratore. Per ogni valore ricevuto, lo stampiamo. Quando
il canale viene chiuso perché i messaggi inviati finiscono, l’iterazione
termina.
Quando esegui il codice del Listato 16-10, dovresti vedere il seguente output con una pausa di 1 secondo tra una riga e l’altra:
Ricevuto: ciao
Ricevuto: dal
Ricevuto: thread
Ricevuto: !!!
Poiché non abbiamo alcun codice che mette in pausa o ritarda il ciclo for nel
thread principale, possiamo dire che il thread principale sta effettivamente
aspettando di ricevere i valori dal thread generato.
Creare più Produttori
Prima abbiamo detto che mpsc è l’acronimo di multiple producer, single
consumer. Mettiamo in pratica mpsc ed espandiamo il codice del Listato 16-10
per creare thread multipli che tutti inviano i valori allo stesso ricevitore.
Possiamo farlo clonando il trasmettitore, come mostrato nel Listato 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --taglio--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let valori = vec![
String::from("ciao"),
String::from("dal"),
String::from("thread"),
String::from("!!!"),
];
for valore in valori {
tx1.send(valore).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let valori = vec![
String::from("ancora"),
String::from("messaggi"),
String::from("per"),
String::from("te"),
];
for valore in valori {
tx.send(valore).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for ricevuto in rx {
println!("Ricevuto: {ricevuto}");
}
// --taglio--
}Questa volta, prima di creare il primo thread generato, chiamiamo clone sul
trasmettitore. In questo modo avremo un nuovo trasmettitore da passare al primo
thread generato. Passiamo poi il trasmettitore originale a un secondo thread
generato. In questo modo avremo due thread, ognuno dei quali invierà messaggi
diversi all’unico ricevitore.
Quando esegui il codice, l’output dovrebbe essere simile a questo:
Ricevuto: ciao
Ricevuto: altri
Ricevuto: dal
Ricevuto: messaggi
Ricevuto: thread
Ricevuto: per
Ricevuto: !!!
Ricevuto: te
Potresti vedere i valori in un altro ordine, a seconda del tuo sistema. Questo è
ciò che rende la concorrenza interessante e difficile. Se sperimenti con
thread::sleep, dandogli vari valori nei diversi thread, ogni esecuzione sarà
più non deterministica e creerà ogni volta un output diverso.
Ora che abbiamo visto come funzionano i canali, analizziamo un altro metodo di concorrenza.
Concorrenza a Stato Condiviso
Il passaggio di messaggi è un buon modo per gestire la concorrenza, ma non è l’unico. Un altro metodo potrebbe essere quello di far accedere più thread agli stessi dati condivisi. Considera ancora una volta questa parte dello slogan della documentazione del linguaggio Go: “Non comunicare condividendo la memoria”.
Come funzionerebbe comunicare condividendo la memoria? Inoltre, perché gli appassionati della tecnica del passaggio di messaggi raccomandano di non utilizzare la condivisione della memoria?
In un certo senso, i canali in qualsiasi linguaggio di programmazione sono simili alla proprietà singola, perché una volta che trasferisci un valore lungo un canale, non dovresti più utilizzarlo. La concorrenza della memoria condivisa è simile alla proprietà multipla: più thread possono accedere alla stessa posizione di memoria nello stesso momento. Come hai visto nel Capitolo 15, dove i puntatori intelligenti rendono possibile la ownership multipla, questo può aggiungere complessità perché questi diversi proprietari devono essere gestiti. Il sistema dei type e le regole di ownership di Rust aiutano molto a gestire correttamente questo aspetto. Per fare un esempio, vediamo i mutex, uno dei type primitivi di concorrenza più comuni per la memoria condivisa.
Controllare l’Accesso con i Mutex
Mutex è l’abbreviazione di mutual exclusion (mutua esclusione), ovvero un mutex permette a un solo thread di accedere ad alcuni dati in un determinato momento. Per accedere ai dati di un mutex, un thread deve prima segnalare che vuole accedervi chiedendo di acquisire il blocco del mutex. Il blocco (lock) è una struttura di dati che fa parte del mutex e che tiene traccia di chi attualmente ha accesso esclusivo ai dati. Per questo motivo, il mutex può esser visto come un custode di dati a cui garantisce accesso tramite il sistema di blocco.
I mutex hanno la reputazione di essere difficili da usare perché devi ricordare due regole:
- Devi cercare di acquisire il blocco prima di utilizzare i dati.
- Quando hai finito di utilizzare i dati che il mutex custodisce, devi sbloccare i dati in modo che altri thread possano acquisirne il blocco.
Per una metafora del mondo reale di un mutex, immagina una tavola rotonda a una conferenza con un solo microfono. Prima che un relatore possa parlare, deve chiedere o segnalare che vuole usare il microfono. Quando ottiene il microfono, può parlare per tutto il tempo che vuole e poi passare il microfono al relatore successivo che chiede di parlare. Se un relatore dimentica di passare il microfono quando ha finito, nessun altro potrà parlare. Se chi gestisce la condivisione del microfono condiviso non fa il suo lavoro correttamente, la tavola rotonda non funzionerà come previsto!
La gestione dei mutex può essere incredibilmente complicata, per questo molte persone sono entusiaste dei canali. Tuttavia, grazie al sistema dei type e alle regole di ownership di Rust, non è possibile sbagliare il blocco e lo sblocco.
L’API di Mutex<T>
Come esempio di utilizzo di un mutex, iniziamo con l’utilizzo di un mutex in un contesto a thread singolo, come mostrato nel Listato 16-12.
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; } println!("m = {m:?}"); }
Mutex<T> in un contesto a thread singolo per semplicitàCome per molti altri type, creiamo un Mutex<T> utilizzando la funzione
associata new. Per accedere ai dati all’interno del mutex, utilizziamo il
metodo lock per acquisire il blocco. Questa chiamata bloccherà il thread
corrente in modo che non possa svolgere alcuna attività finché non sarà il
nostro turno di avere il blocco.
La chiamata a lock fallirebbe se un altro thread che detiene il lock andasse
in panic. In questo caso, nessuno sarebbe in grado di ottenere il lock, quindi
abbiamo scelto di usare unwrap e di far andare in panic questo thread se
ci troviamo in quella situazione.
Dopo aver acquisito il blocco, possiamo trattare il valore di ritorno, chiamato
num in questo caso, come un reference mutabile ai dati all’interno. Il
sistema dei type assicura che acquisiamo un blocco prima di utilizzare il
valore in m. Il type di m è Mutex<i32>, non i32, quindi dobbiamo
chiamare lock per poter utilizzare il valore i32. Non possiamo
dimenticarcene; altrimenti il sistema dei type non ci permetterà di accedere
al valore interno i32.
La chiamata a lock restituisce un type chiamato MutexGuard, incapsulato in
un LockResult che abbiamo gestito con la chiamata a unwrap. Il type
MutexGuard implementa Deref per puntare ai nostri dati interni; il type ha
anche un’implementazione Drop che rilascia automaticamente il blocco quando un
MutexGuard esce dallo scope, cosa che accade alla fine dello scope
interno. Di conseguenza, non rischiamo di dimenticarci di rilasciare il blocco e
di bloccare l’utilizzo del mutex da parte di altri thread perché il rilascio
del blocco avviene automaticamente.
Dopo aver rilasciato il blocco, possiamo stampare il valore del mutex e vedere
che siamo riusciti a cambiare l’interno i32 in 6.
Condividere Accesso a Mutex<T>
Ora proviamo a condividere un valore tra più thread utilizzando Mutex<T>.
Avvieremo 10 thread e faremo in modo che ognuno di essi incrementi il valore
di un contatore di 1, in modo che il contatore vada da 0 a 10. L’esempio nel
Listato 16-13 avrà un errore del compilatore, che useremo per imparare di più
sull’uso di Mutex<T> e su come Rust ci aiuta a usarlo correttamente.
use std::sync::Mutex;
use std::thread;
fn main() {
let contatore = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = contatore.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Risultato: {}", *contatore.lock().unwrap());
}Mutex<T>Creiamo una variabile contatore per contenere un i32 all’interno di un
Mutex<T>, come abbiamo fatto nel Listato 16-12. Poi creiamo 10 thread
iterando su un intervallo di numeri. Usiamo thread::spawn e diamo a tutti i
thread la stessa chiusura: una che sposta il contatore nel thread,
acquisisce un blocco sul Mutex<T> chiamando il metodo lock e poi aggiunge 1
al valore nel mutex. Quando un thread termina l’esecuzione della sua chiusura,
num uscirà dallo scope e rilascerà il blocco in modo che un altro thread
possa acquisirlo.
Nel thread principale, sugli handle dei thread raccolti in un vettore,
come fatto nel Listato 16-2, chiamiamo join su ognuno di essi per assicurarci
che tutti i thread finiscano. A quel punto, il thread principale acquisirà
il blocco e stamperà il risultato di questo programma.
Abbiamo accennato al fatto che questo esempio non sarebbe stato compilato. Ora scopriamo perché!
$ cargo run
Compiling stato-condiviso v0.1.0 (file:///progetti/stato-condiviso)
error[E0382]: borrow of moved value: `contatore`
--> src/main.rs:21:32
|
5 | let contatore = Mutex::new(0);
| --------- move occurs because `contatore` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Risultato: {}", *contatore.lock().unwrap());
| ^^^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = contatore.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `stato-condiviso` (bin "stato-condiviso") due to 1 previous error
Il messaggio di errore indica che il valore contatore è stato spostato
nell’iterazione precedente del ciclo. Rust ci sta dicendo che non possiamo
spostare la ownership del blocco contatore in più thread. Risolviamo
l’errore del compilatore con il metodo della ownership multipla di cui abbiamo
parlato nel Capitolo 15.
Ownership Multipla con Thread Multipli
Nel Capitolo 15, abbiamo dato un valore a più proprietari utilizzando il
puntatore intelligente Rc<T> per creare un conteggio di reference. Facciamo
lo stesso qui e vediamo cosa succede. Incapsuleremo il Mutex<T> in Rc<T> nel
Listato 16-14 e cloneremo Rc<T> prima di spostare la ownership al thread.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let contatore = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let contatore = Rc::clone(&contatore);
let handle = thread::spawn(move || {
let mut num = contatore.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Risultato: {}", *contatore.lock().unwrap());
}Rc<T> per consentire a più thread di possedere il Mutex<T>Ancora una volta, compiliamo e otteniamo… errori diversi! Il compilatore ci sta insegnando molto.
$cargo run
Compiling stato-condiviso v0.1.0 (file:///progetti/stato-condiviso)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = contatore.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rust/library/std/src/thread/mod.rs:726:8
|
723 | pub fn spawn<F, T>(f: F) -> JoinHandle<T>
| ----- required by a bound in this function
...
726 | F: Send + 'static,
| ^^^^ required by this bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `stato-condiviso` (bin "stato-condiviso") due to 1 previous error
Wow, questo messaggio di errore è molto prolisso! Ecco la parte importante su
cui concentrarsi: `Rc<Mutex<i32>>` cannot be sent between threads safely
(Rc<Mutex<i32>> non può essere inviato tra i thread in modo sicuro). Il
compilatore ci dice anche il motivo: the trait `Send` is not implemented for `Rc<Mutex<i32>>` ( (il trait Send non è implementato per
Rc<Mutex<i32>>). Parleremo di Send nella prossima sezione: è uno dei trait
che garantisce che i type che utilizziamo con i thread siano pensati per
l’uso in situazioni concorrenti.
Sfortunatamente, Rc<T> non è sicuro da condividere tra i thread. Quando
Rc<T> gestisce il conteggio dei reference, aggiunge al conteggio per ogni
chiamata a clone e sottrae dal conteggio quando ogni clone viene rilasciato.
Ma non utilizza alcun type primitivo di concorrenza per assicurarsi che le
modifiche al conteggio non possano essere interrotte da un altro thread.
Questo potrebbe portare a conteggi sbagliati; bug che potrebbero a loro volta
portare a perdite di memoria o alla de-allocazione di un valore prima che
abbiamo finito di usarlo. Ciò di cui abbiamo bisogno è un type che sia
esattamente come Rc<T>, ma che apporti modifiche al conteggio dei reference
in modo sicuro quando usato con i thread.
Conteggio di Reference Atomico con Arc<T>
Fortunatamente, Arc<T> è un type come Rc<T> che è sicuro da usare in
situazioni di concorrenza (thread-safe). La A sta per atomico, cioè è un
type contatore di reference atomico. Gli atomici sono un ulteriore
type di primitivo di concorrenza che non tratteremo in dettaglio in questa
sede: per maggiori dettagli, consulta la documentazione della libreria standard
per std::sync::atomic. A questo punto, ti basterà
sapere che gli atomici funzionano come i type primitivi ma sono sicuri da
condividere tra i thread.
Potresti chiederti perché tutti i type primitivi non sono atomici e perché i
type della libreria standard non sono implementati in modo da utilizzare
Arc<T> come impostazione predefinita. Il motivo è che la sicurezza dei
thread comporta una penalizzazione delle prestazioni che vorrai scegliere di
usare solo quando ne hai veramente bisogno. Se stai eseguendo operazioni su
valori all’interno di un singolo thread, il tuo codice può funzionare più
velocemente se non deve applicare le garanzie che gli atomici forniscono.
Torniamo al nostro esempio: Arc<T> e Rc<T> hanno la stessa API, quindi
correggiamo il nostro programma cambiando la riga use, la chiamata a new e
la chiamata a clone. Il codice nel Listato 16-15 verrà finalmente compilato ed
eseguito.
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let contatore = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let contatore = Arc::clone(&contatore); let handle = thread::spawn(move || { let mut num = contatore.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Risultato: {}", *contatore.lock().unwrap()); }
Arc<T> per incapsulare il Mutex<T> per poter condividere la ownership tra più threadQuesto codice stamperà quanto segue:
Risultato: 10
Ce l’abbiamo fatta! Abbiamo contato da 0 a 10, il che può non sembrare molto
impressionante, ma ci ha insegnato molto su Mutex<T> e sulla sicurezza dei
thread. Puoi anche utilizzare la struttura di questo programma per fare
operazioni più complicate del semplice incremento di un contatore. Utilizzando
questa strategia, puoi dividere un calcolo in parti indipendenti, suddividere
queste parti tra i vari thread e poi utilizzare un Mutex<T> per far sì che
ogni thread aggiorni il risultato finale con la sua parte.
Nota che se stai eseguendo semplici operazioni numeriche, esistono type più
semplici di Mutex<T> forniti dal modulo std::sync::atomic della libreria
standard. Questi type forniscono un accesso sicuro,
concorrente e atomico ai type primitivi. Abbiamo scelto di utilizzare
Mutex<T> con un type primitivo per questo esempio, in modo da poterci
concentrare sul funzionamento di Mutex<T>.
Comparazione tra RefCell<T>/Rc<T> e Mutex<T>/Arc<T>
Avrai notato che contatore è immutabile ma possiamo ottenere un reference
mutabile al valore al suo interno; questo significa che Mutex<T> fornisce la
mutabilità interna, come fa la famiglia Cell. Nello stesso modo in cui abbiamo
usato RefCell<T> nel Capitolo 15 per permetterci di mutare i contenuti
all’interno di un Rc<T>, usiamo Mutex<T> per mutare i contenuti all’interno
di un Arc<T>.
Un altro dettaglio da notare è che Rust non può proteggerti da tutti i tipi di
errori logici quando usi Mutex<T>. Ricordiamo dal Capitolo 15 che l’uso di
Rc<T> comporta il rischio di creare cicli di riferimento, in cui due valori
Rc<T> fanno riferimento l’uno all’altro, causando perdite di memoria. Allo
stesso modo, Mutex<T> comporta il rischio di creare dei deadlock (stallo).
Questi si verificano quando un’operazione deve bloccare due risorse e due
thread hanno acquisito ciascuno uno dei blocchi, facendoli attendere
all’infinito l’un l’altro. Se ti interessano i deadlock, prova a creare un
programma Rust che abbia un deadlock; quindi ricerca le strategie di
mitigazione degli stalli per i mutex in qualsiasi altro linguaggio e prova a
implementarle in Rust. La documentazione API della libreria standard per
Mutex<T> e MutexGuard offre informazioni utili.
Concluderemo questo capitolo parlando dei trait Send e Sync e di come
possiamo utilizzarli con i type personalizzati.
Concorrenza Estensibile con Send e Sync
È interessante notare che quasi tutte le funzioni di concorrenza di cui abbiamo parlato finora in questo capitolo fanno parte della libreria standard, non del linguaggio stesso. Le opzioni per gestire la concorrenza non sono limitate al linguaggio o alla libreria standard; puoi scrivere le tue funzioni di concorrenza o usare quelle scritte da altri.
Tuttavia, tra i concetti chiave della concorrenza che sono incorporati nel
linguaggio piuttosto che nella libreria standard ci sono i trait
std::marker, Send e Sync.
Trasferire Ownership tra Thread
Il trait marcatore Send indica che la ownership dei valori del type che
implementa Send può essere trasferita tra i thread. Quasi tutti i type di
Rust implementano Send, ma ci sono alcune eccezioni, tra cui Rc<T>: questo
non può implementare Send perché se si clona un valore Rc<T> e si cerca di
trasferire la ownership del clone a un altro thread, entrambi i thread
potrebbero aggiornare il conteggio dei reference allo stesso tempo. Per questo
motivo, Rc<T> è implementato per essere utilizzato in situazioni a thread
singolo in cui non si vuole pagare una penalizzazione in prestazioni rispetto ad
una maggiore sicurezza.
Pertanto, il sistema dei type di Rust e i vincoli di trait assicurano che
non si possa mai inviare accidentalmente un valore Rc<T> tra i thread in
modo non sicuro. Quando abbiamo provato a farlo nel Listato 16-14, abbiamo
ottenuto l’errore the trait `Send` is not implemented for `Rc<Mutex<i32>>.
Quando siamo passati ad Arc<T>, che implementa Send, il codice è stato
compilato.
Qualsiasi type composto interamente da type che implementano Send,
anch’esso implementerà automaticamente il trait Send. Quasi tutti i type
primitivi implementano Send, a parte i puntatori grezzi, di cui parleremo nel
Capitolo 20.
Accedere da Più Thread
Il trait marcatore Sync indica che il type che implementa Sync può
essere referenziato da più thread. In altre parole, qualsiasi type T
implementa Sync se &T (un reference immutabile a T) implementa Send,
il che significa che il reference può essere inviato in modo sicuro a un altro
thread. Analogamente a Send, i type primitivi implementano tutti Sync e
i type composti interamente da type che implementano Sync, anch’essi
implementano Sync.
Il puntatore intelligente Rc<T> non implementa neanche Sync per le stesse
ragioni per cui non implementa Send. Il type RefCell<T> (di cui abbiamo
parlato nel Capitolo 15) e la famiglia correlata di type Cell<T> non
implementano Sync. L’implementazione del controllo dei prestiti che
RefCell<T> fa durante l’esecuzione non è sicura per l’uso coi thread. Invece
il puntatore intelligente Mutex<T> implementa Sync e può essere utilizzato
per condividere l’accesso con più thread, come hai visto in “Condividere
Accesso a Mutex<T>”.
Implementare Manualmente Send e Sync È Insicuro
Poiché i type composti interamente da altri type che implementano i trait
Send e Sync implementano automaticamente anche Send e Sync, non dobbiamo
implementare questi trait manualmente. Come trait marcatori, non hanno
nemmeno metodi da implementare. Sono solo utili per far rispettare gli
invarianti relativi alla concorrenza.
L’implementazione manuale di questi trait comporta l’implementazione di codice
Rust insicuro. Parleremo dell’utilizzo di codice Rust insicuro (Unsafe Rust)
nel Capitolo 20; per ora, l’informazione importante è che la creazione di nuovi
type concorrenti non costituiti da parti Send e Sync richiede un’attenta
riflessione per mantenere le garanzie di sicurezza. “The
Rustonomicon” contiene maggiori informazioni su queste garanzie e su
come rispettarle.
Riepilogo
Non è l’ultima volta che vedrai la concorrenza in questo libro: il prossimo capitolo si concentra sulla programmazione asincrona e il progetto del Capitolo 21 utilizzerà i concetti di questo capitolo in una situazione più realistica rispetto agli esempi minori discussi qui.
Come accennato in precedenza, dato che la gestione della concorrenza in Rust fa parte del linguaggio solo in minima parte, molte soluzioni per la concorrenza sono implementate sotto forma di crate. Questi si evolvono più rapidamente rispetto alla libreria standard, quindi assicurati di cercare online i crate più aggiornati e all’avanguardia da utilizzare in situazioni in cui necessiti di elaborazioni multi-thread.
La libreria standard di Rust fornisce canali per il passaggio di messaggi e i
puntatori intelligenti, come Mutex<T> e Arc<T>, che sono sicuri da usare in
contesti concorrenti (detti thread-safe). Il sistema dei type e il controllo
di prestiti assicurano che il codice che utilizza queste soluzioni non finisca
con accessi ai dati conflittuali o riferimenti non validi. Una volta che avrai
compilato il tuo codice, potrai essere certo che verrà eseguito felicemente su
più thread senza i tipi di bug difficili da rintracciare comuni in altri
linguaggi. La programmazione concorrente non è più un concetto di cui aver
paura: vai avanti e rendi i tuoi programmi concorrenti, senza paura!
Fondamenti di Programmazione Asincrona: Async, Await, Future e Stream
Molte operazioni che chiediamo al computer di fare possono richiedere del tempo per completarsi. Sarebbe bello poter fare altro mentre aspettiamo che questi processi che richiedo molto tempo finiscano. I computer moderni offrono due tecniche per lavorare su più operazioni contemporaneamente: parallelismo e concorrenza. La logica dei nostri programmi, tuttavia, è scritta in modo prevalentemente lineare. Ci piacerebbe poter specificare le operazioni che un programma dovrebbe eseguire e i punti in cui una funzione potrebbe mettersi in pausa e un’altra parte del programma potrebbe essere eseguita al suo posto, senza dover specificare in anticipo l’ordine e il modo esatto in cui ogni parte di codice dovrebbe essere eseguita. La programmazione asincrona è un’astrazione che ci permette di esprimere il nostro codice in termini di potenziali punti di pausa e risultati finali, occupandosi per noi dei dettagli di coordinamento.
Questo capitolo espande quanto spiegato nel Capitolo 16 sull’uso dei thread
per parallelismo e concorrenza, introducendo un approccio alternativo alla
scrittura del codice: le Future , gli Stream, la sintassi async e await
che ci consente di esprimere il modo in cui un’operazione possa essere
asincrona, e crate di terze parti che implementano runtime asincrone: codice
che gestisce e coordina l’esecuzione di operazioni asincrone.
Consideriamo un esempio. Immagina di esportare un video che hai creato di una celebrazione familiare, un’operazione che potrebbe durare da alcuni minuti a ore. L’esportazione del video userà tutta la potenza disponibile di CPU e GPU. Se avessi solo un core CPU e il tuo sistema operativo non mettesse in pausa quell’esportazione fino al suo completamento - cioè, se la eseguisse sincronicamente - non potresti fare nient’altro sul tuo computer mentre quel compito è in esecuzione. Sarebbe un’esperienza davvero frustrante. Fortunatamente, il sistema operativo del tuo computer può, e lo fa, interrompere invisibilmente l’esportazione abbastanza spesso da permetterti di fare altro lavoro contemporaneamente.
Ora immagina di scaricare un video condiviso da qualcun altro, che può richiedere del tempo ma non occupa altrettanta potenza CPU. In questo caso, la CPU deve aspettare che i dati arrivino dalla rete. Puoi iniziare a leggere i dati non appena iniziano ad arrivare, ma potrebbe volerci del tempo perché siano completamente disponibili. Anche una volta che tutti i dati sono presenti, se il video è molto grande, potrebbe volerci almeno un secondo o due per caricarlo completamente. Potrebbe non sembrare molto, ma è un tempo lunghissimo per un processore moderno, che può eseguire miliardi di operazioni ogni secondo. Ancora una volta, il tuo sistema operativo interromperà invisibilmente il tuo programma per permettere alla CPU di eseguire altro lavoro mentre aspetta che la chiamata di rete finisca.
L’esportazione video è un esempio di operazione vincolata dalla CPU o vincolata dal calcolo. È limitata dalla velocità potenziale di elaborazione dati all’interno della CPU o GPU e da quanto di quella velocità può dedicare all’operazione. Il download video è un esempio di operazione vincolata da I/O, perché è limitata dalla velocità di input e output del computer; può andare solo veloce quanto i dati possono essere inviati attraverso la rete.
In entrambi questi esempi, le invisibili interruzioni del sistema operativo forniscono una forma di concorrenza. Quella concorrenza avviene solo al livello dell’intero programma: il sistema operativo interrompe un programma per permettere ad altri programmi di fare lavoro. In molti casi, poiché comprendiamo i nostri programmi a un livello molto più granulare di quanto faccia il sistema operativo, possiamo individuare opportunità di concorrenza che il sistema operativo non vede.
Ad esempio, se stiamo costruendo uno strumento per gestire download di file, dovremmo essere in grado di scrivere il nostro programma in modo che l’avvio di un download non blocchi l’interfaccia utente, e gli utenti dovrebbero essere in grado di avviare più download contemporaneamente. Molte API del sistema operativo per interagire con la rete sono bloccanti; ovvero, bloccano il progresso del programma finché i dati che stanno elaborando non sono completamente pronti.
Nota: È così che funzionano la maggior parte delle chiamate di funzione, se ci pensi. Tuttavia, il termine bloccante è solitamente riservato per chiamate di funzioni che interagiscono con file, rete o altre risorse del computer, perché questi sono i casi in cui un singolo programma trarrebbe beneficio se l’operazione fosse non-bloccante.
Potremmo evitare di bloccare il nostro thread principale creando un thread dedicato per scaricare ogni file. Tuttavia, l’overhead delle risorse usate da questi thread diventerebbe presto un problema. Sarebbe preferibile se la chiamata non bloccasse fin dall’inizio, e invece potessimo definire un numero di compiti che vogliamo che il nostro programma porti a termine e lasciamo al runtime di scegliere l’ordine migliore per eseguirli.
Proprio questo è ciò che l’astrazione async di Rust ci offre. In questo capitolo, imparerai tutto su async mentre affronteremo i seguenti argomenti:
- Come usare la sintassi
asynceawaitdi Rust ed eseguire funzioni asincrone con un runtime - Come usare il modello async per risolvere alcune delle sfide che abbiamo esaminato nel Capitolo 16
- Come multi-threading e async forniscono soluzioni complementari, che in molti casi puoi combinare
Prima di vedere come async funziona nella pratica, però, dobbiamo fare una breve deviazione per discutere le differenze tra parallelismo e concorrenza.
Parallelismo e Concorrenza
Finora abbiamo trattato parallelismo e concorrenza come quasi intercambiabili. Ora dobbiamo distinguerli più precisamente, perché le differenze emergeranno man mano che inizieremo a lavorarci.
Considera i diversi modi in cui un team potrebbe dividere il lavoro in un progetto software. Potresti assegnare a un singolo membro più compiti, assegnare a ciascun membro un compito, o usare un mix dei due approcci.
Quando un individuo lavora su diversi compiti prima che uno di essi sia completato, questo è concorrenza. Un modo di implementare la concorrenza è simile ad avere due progetti diversi aperti sul tuo computer, e quando ti annoi o ti blocchi su un progetto, passi all’altro. Sei una sola persona, quindi non puoi fare progressi su entrambi i compiti esattamente nello stesso momento, ma puoi fare multi-tasking, facendo progressi su uno alla volta passando dall’uno all’altro (vedi Figura 17-1).

Figura 17-1: Un flusso di lavoro concorrente, passando tra Compito A e Compito B
Quando il team divide un insieme di compiti facendo sì che ogni membro prenda un compito e lo porti avanti da solo, questo è parallelismo. Ogni persona del team può fare progressi esattamente nello stesso momento (vedi Figura 17-2).

Figura 17-2: Un flusso di lavoro parallelo, dove il lavoro avviene sui Compiti A e B indipendentemente
In entrambi questi flussi di lavoro, potresti dover coordinare tra diversi compiti. Forse pensavi che il compito assegnato a una persona fosse totalmente indipendente dal lavoro di tutti gli altri, ma in realtà richiede che un’altra persona del team completi prima il proprio compito. Parte del lavoro potrebbe essere eseguita in parallelo, ma parte di esso sarebbe effettivamente seriale: potrebbe avvenire solo in serie, un compito dopo l’altro, come nella Figura 17-3.

Figura 17-3: Un flusso di lavoro parzialmente parallelo, dove il lavoro sui Compiti A e B procede indipendentemente finché A3 non è bloccato aspettando i risultati di B3.
Allo stesso modo, potresti renderti conto che uno dei tuoi compiti dipende da un altro dei tuoi compiti. Ora il tuo lavoro concorrente è diventato seriale.
Parallelismo e concorrenza possono anche intersecarsi tra loro. Se scopri che un collega è bloccato finché non completi uno dei tuoi compiti, probabilmente concentrerai tutti i tuoi sforzi su quel compito per “sbloccare” il tuo collega. Tu e il tuo collega non siete più in grado di lavorare in parallelo, e non siete nemmeno più in grado di lavorare concorrentemente sui vostri compiti.
Le stesse dinamiche di base si applicano al software e all’hardware. Su una macchina con un singolo core CPU, la CPU può eseguire solo un’operazione alla volta, ma può comunque lavorare concorrentemente. Utilizzando strumenti come thread, processi e async, il computer può mettere in pausa un’attività e passare ad altre prima di tornare eventualmente a quella prima attività. Su una macchina con più core CPU, può anche eseguire lavoro in parallelo. Un core può eseguire un compito mentre un altro core esegue un compito completamente indipendente, e quelle operazioni accadono effettivamente nello stesso momento.
L’esecuzione di codice async in Rust solitamente avviene concorrentemente. A seconda dell’hardware, del sistema operativo e del runtime async che stiamo utilizzando (parleremo presto dei runtime async), quella concorrenza potrebbe anche star utilizzando in realtà il parallelismo.
Ora, immergiamoci in come funziona effettivamente la programmazione asincrona in Rust.
Future e la Sintassi Async
Gli elementi chiave della programmazione asincrona in Rust sono le future e le
parole chiave async e await di Rust.
Una future è un valore che potrebbe non essere pronto ora, ma lo diventerà in
qualche momento in futuro. (Questo stesso concetto compare in molti linguaggi, a
volte sotto altri nomi come task o promise.) Rust fornisce un trait
Future come blocco costruttivo in modo che diverse operazioni async possano
essere implementate con strutture dati diverse ma con un’interfaccia comune. In
Rust, le future sono type che implementano il trait Future. Ogni
future contiene le proprie informazioni sui progressi fatti e su cosa
significa essere “pronti”.
Puoi applicare la parola chiave async a blocchi e funzioni per specificare che
possono essere interrotti e ripresi. All’interno di un blocco async o di una
funzione async, puoi usare la parola chiave await per attendere una future
(cioè, aspettare che sia pronta). Ogni punto in cui attendi una future
all’interno di un blocco o funzione async è un potenziale punto in cui quel
blocco o funzione può mettersi in pausa e riprendere. Il processo di verifica
con una future per vedere se il suo valore è già disponibile è chiamato
polling.
Alcuni altri linguaggi, come C# e JavaScript, usano parole chiave async e
await per la programmazione asincrona. Se hai familiarità con questi
linguaggi, potresti notare alcune differenze significative nel modo in cui Rust
gestisce la sintassi. E questo è per una buona ragione, come vedremo!
Quando scriviamo codice async in Rust, usiamo la maggior parte delle volte le
parole chiave async e await. Rust le compila in codice equivalente usando il
trait Future, proprio come compila i cicli for in codice equivalente
usando il trait Iterator. Poiché Rust fornisce il trait Future, puoi
anche implementarlo per i type da te definiti quando ne hai bisogno. Molte
delle funzioni che vedremo in questo capitolo restituiscono type con le
proprie implementazioni di Future. Torneremo alla definizione del trait alla
fine del capitolo e approfondiremo come funziona, ma questi dettagli sono
sufficienti per procedere.
Tutto questo potrebbe sembrare un po’ astratto, quindi scriviamo il nostro primo programma async: un piccolo web scraper (estrattore di informazioni da pagine web). Passeremo due URL dalla riga di comando, li recupereremo contemporaneamente e restituiremo il risultato di quello che finisce per primo. Questo esempio avrà parecchia nuova sintassi, ma non preoccuparti, spiegheremo tutto ciò che serve sapere man mano che procediamo.
Il Nostro Primo Programma Async
Per mantenere l’attenzione di questo capitolo sull’apprendimento di async
piuttosto che sulla gestione di parti dell’ecosistema, abbiamo creato il crate
trpl (trpl è abbreviazione di “The Rust Programming
Language”). Riesporta tutti i type, i trait e le funzioni di cui avrai
bisogno, principalmente dai crate futures e
tokio. Il crate futures è una sede ufficiale per
la sperimentazione Rust del codice async, ed è in realtà dove il trait
Future è stato originariamente progettato. Tokio è il runtime async più
utilizzato in Rust oggi, specialmente per applicazioni web. Ci sono altri ottimi
runtime là fuori, e potrebbero essere più adatti ai tuoi scopi. Usiamo il
crate tokio come base per trpl perché è ben testato e ampiamente
utilizzato.
In alcuni casi, trpl rinomina o incapsula le API originali per mantenerti
concentrato sui dettagli rilevanti per questo capitolo. Se vuoi capire cosa fa
il crate, ti incoraggiamo a controllare il suo codice
sorgente. Sarai in grado di vedere da quale crate proviene ogni
riesportazione, e abbiamo lasciato commenti esaustivi che spiegano cosa fa il
crate.
Crea un nuovo progetto binario chiamato hello-async e aggiungi il crate
trpl come dipendenza:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Ora possiamo usare i vari pezzi forniti da trpl per scrivere il nostro primo
programma async. Costruiremo un piccolo strumento da riga di comando che
recupera due pagine web, estrae l’elemento <title> da ciascuna e stampa il
titolo della pagina che completa per prima l’intero processo.
Definire la Funzione titolo_pagina
Iniziamo scrivendo una funzione che prende un URL di una pagina come parametro,
la scarica e restituisce il testo dell’elemento <title> (vedi Listato 17-1).
extern crate trpl; // necessario per test mdbook fn main() { // TODO: lo aggiungeremo in seguito! } use trpl::Html; async fn titolo_pagina(url: &str) -> Option<String> { let risposta = trpl::get(url).await; let testo_risposta = risposta.text().await; Html::parse(&testo_risposta) .select_first("title") .map(|titolo| titolo.inner_html()) }
title da una pagina HTMLPer prima cosa, definiamo una funzione chiamata titolo_pagina e la
contrassegniamo con la parola chiave async. Poi usiamo la funzione trpl::get
per recuperare l’URL passato e aggiungiamo la parola chiave await per
aspettare la risposta. Per ottenere il testo di risposta, chiamiamo il suo
metodo text e di nuovo aspettiamo con la parola chiave await. Entrambi
questi passaggi sono asincroni.
Per la funzione get, dobbiamo aspettare che il server invii la prima parte
della sua risposta, che includerà intestazioni HTTP, cookie e così via, e può
essere consegnata separatamente dal corpo della risposta. Soprattutto se il
corpo è molto grande, può volerci del tempo perché arrivi tutto. Poiché dobbiamo
aspettare l’intera risposta, anche il metodo text è asincrono.
Dobbiamo esplicitamente attendere entrambe queste future, perché le future
in Rust sono lazy (pigre): non fanno nulla finché non le chiedi di farlo con
la parola chiave await. (In effetti, Rust mostrerà un avviso del compilatore
se non usi una future.) Questo potrebbe ricordarti la discussione sugli
iteratori nella sezione “Elaborare una Serie di Elementi con
Iteratori” del Capitolo 13. Gli iteratori non
fanno nulla a meno che non chiami il loro metodo next, sia direttamente che
usando cicli for o metodi come map che usano next sotto il cofano. Allo
stesso modo, le future non fanno nulla a meno che tu non le chieda
esplicitamente di farlo. Questa pigrizia permette a Rust di evitare di
eseguire codice asincrono finché non è effettivamente necessario.
Nota: Questo è diverso dal comportamento che abbiamo visto quando abbiamo usato
thread::spawnnella sezione “Creare un Nuovo Thread conspawn” del Capitolo 16, dove la chiusura passata a un altro thread veniva eseguita immediatamente. È anche diverso da come molti altri linguaggi gestiscono l’asincronia. Ma è importante per Rust poter fornire le sue garanzie di prestazioni, proprio come accade con gli iteratori.
Una volta che abbiamo testo_risposta, possiamo analizzarlo in un’istanza del
type Html usando Html::parse. Invece di una stringa grezza, ora abbiamo un
tipo di dato che possiamo usare per lavorare con l’HTML come una struttura dati
più funzionale. In particolare, possiamo usare il metodo select_first per
trovare la prima istanza di un dato selettore CSS. Passando la stringa
"title", otterremo il primo elemento <title> nel documento, se presente.
Poiché potrebbe non esserci alcun elemento corrispondente, select_first
restituisce un Option<ElementRef>. Infine, usiamo il metodo Option::map, che
ci permette di lavorare sull’elemento nell’Option se è presente, e non fare
nulla se non lo è. (Potremmo anche usare un’espressione match, ma map è più
idiomatico.) Nel corpo della funzione che forniamo a map, chiamiamo
inner_html su titolo per ottenere il suo contenuto, che è una String. Alla
fine dei conti, abbiamo un Option<String>.
Nota che la parola chiave await di Rust va dopo l’espressione che stai
attendendo, non prima. Cioè, è una parola chiave post-fissa. Questo potrebbe
differire da ciò a cui sei abituato se hai usato async in altri linguaggi, ma
in Rust rende le catene di metodi molto più gradevoli da gestire. Di
conseguenza, potremmo modificare il corpo di titolo_pagina per concatenare le
chiamate di funzione trpl::get e text con await in mezzo, come mostrato
nel Listato 17-2.
extern crate trpl; // necessario per test mdbook use trpl::Html; fn main() { // TODO: lo aggiungeremo in seguito! } async fn titolo_pagina(url: &str) -> Option<String> { let testo_risposta = trpl::get(url).await.text().await; Html::parse(&testo_risposta) .select_first("title") .map(|titolo| titolo.inner_html()) }
awaitCon questo, abbiamo scritto con successo la nostra prima funzione asincrona!
Prima di aggiungere del codice in main per chiamarla, parliamo un po’ di più
di cosa abbiamo scritto e cosa significa.
Quando Rust vede un blocco contrassegnato con la parola chiave async, lo
compila in un type anonimo e univoco che implementa il trait Future.
Quando Rust vede una funzione contrassegnata con async, la compila in una
funzione non asincrona il cui corpo è un blocco asincrono. Il type di ritorno
di una funzione asincrona è il type anonimo che il compilatore crea per quel
blocco asincrono.
Quindi, scrivere async fn è equivalente a scrivere una funzione che
restituisce una future del type di ritorno. Per il compilatore, una
definizione di funzione come async fn titolo_pagina nel Listato 17-1 è più o
meno equivalente a una funzione non asincrona definita in questo modo:
#![allow(unused)] fn main() { extern crate trpl; // necessario per test mdbook use std::future::Future; use trpl::Html; fn titolo_pagina(url: &str) -> impl Future<Output = Option<String>> { async move { let testo_risposta = trpl::get(url).await.testo_risposta().await; Html::parse(&testo_risposta) .select_first("title") .map(|titolo| titolo.inner_html()) } } }
Analizziamo ogni parte della versione trasformata:
- Usa la sintassi
impl Traitche abbiamo discusso nel Capitolo 10 nella sezione “Usare i Trait come Parametri”. - Il valore restituito implementa il trait
Futurecon un type associato diOutput. Nota che il typeOutputèOption<String>, che è lo stesso type di ritorno della versioneasync fndititolo_pagina. - Tutto il codice chiamato nel corpo della funzione originale è racchiuso in un
blocco
async move. Ricorda che i blocchi sono espressioni. Questo intero blocco è l’espressione restituita dalla funzione. - Questo blocco asincrono produce un valore di type
Option<String>, come appena descritto. Quel valore corrisponde al typeOutputnel type di ritorno. È proprio come altri blocchi che hai visto. - Il nuovo corpo della funzione è un blocco
async moveper come usa il parametrourl. (Confronteremo molto più approfonditamenteasynceasync movepiù avanti in questo capitolo).
Ora possiamo chiamare titolo_pagina in main.
Eseguire un Funzione Asincrona con un Runtime
Per iniziare, prenderemo il titolo di una singola pagina come mostrato nel Listato 17-3. Purtroppo, questo codice non si compila per adesso.
extern crate trpl; // necessario per test mdbook
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match titolo_pagina(url).await {
Some(titolo) => println!("Il titolo per {url} era {titolo}"),
None => println!("{url} non aveva titolo"),
}
}
async fn titolo_pagina(url: &str) -> Option<String> {
let testo_risposta = trpl::get(url).await.text().await;
Html::parse(&testo_risposta)
.select_first("title")
.map(|titolo| titolo.inner_html())
}titolo_pagina da main con un argomento fornito dall’utenteSeguiamo lo stesso schema che abbiamo usato nella sezione “Ricevere Argomenti
dalla Riga di Comando” del Capitolo 12. Poi passiamo
il primo URL a titolo_pagina e attendiamo il risultato. Poiché il valore
prodotto dalla future è un Option<String>, usiamo un’espressione match per
stampare messaggi diversi a seconda che la pagina abbia o meno un <title>.
L’unico posto in cui possiamo usare la parola chiave await è in funzioni o
blocchi async, e Rust non ci permette di contrassegnare la funzione main
speciale come async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
Il motivo per cui main non può essere contrassegnata async è che il codice
async ha bisogno di un runtime: un crate Rust che gestisce i dettagli
dell’esecuzione del codice asincrono. La funzione main di un programma può
inizializzare un runtime, ma non è un runtime in sé. (Vedremo più avanti
perché è così.) Ogni programma Rust che esegue codice asincrono ha almeno un
punto in cui configura un runtime che esegue le future.
La maggior parte dei linguaggi che supportano async includono un runtime, ma Rust no. Invece, ci sono molti runtime asincroni disponibili, ognuno dei quali fa compromessi diversi adatti al caso d’uso che intende coprire. Ad esempio, un server web che gestisce grandi quantità di dati eseguito su CPU multi-core e una grande quantità di RAM ha esigenze molto diverse da un micro-controllore con un singolo core, poca RAM e nessuna capacità di allocazione nell’heap. I crate che forniscono questi runtime spesso forniscono anche versioni async di funzionalità comuni come I/O su file o di rete.
Qui, e nel resto di questo capitolo, useremo la funzione block_on del crate
trpl, che prende una future come argomento e blocca il thread corrente
fino al completamento di questa future. Dietro le quinte, chiamare block_on
configura un runtime usando il crate tokio usato per eseguire la future
passata (il comportamento di block_on del crate trpl è simile a come si
comportano funzioni block_on di altri crate runtime). Una volta che la
future è completata, block_on restituisce qualsiasi valore che la future
ha prodotto.
Potremmo passare direttamente la future restituita da titolo_pagina a
block_on, e una volta completata, potremmo fare il match sul risultante
Option<String>, come abbiamo provato a fare nel Listato 17-3. Tuttavia, per la
maggior parte degli esempi in questo capitolo (e per la maggior parte del codice
async nel mondo reale), faremo più di una singola chiamata di funzione
async, quindi invece passeremo un blocco async ed esplicitamente attendiamo
il risultato della chiamata titolo_pagina, come nel Listato 17-4.
extern crate trpl; // necessario per test mdbook
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match titolo_pagina(url).await {
Some(titolo) => println!("Il titolo per {url} era {titolo}"),
None => println!("{url} non aveva titolo"),
}
})
}
async fn titolo_pagina(url: &str) -> Option<String> {
let testo_risposta = trpl::get(url).await.text().await;
Html::parse(&testo_risposta)
.select_first("title")
.map(|titolo| titolo.inner_html())
}trpl::block_onQuando eseguiamo questo codice, otteniamo il comportamento che avevamo inizialmente previsto:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
Il titolo per https://www.rust-lang.org era
Rust Programming Language
Bene! Finalmente abbiamo del codice async funzionante! Ma prima di aggiungere il codice per mettere a gara i due siti l’uno contro l’altro, dedichiamo brevemente la nostra attenzione a come funzionano le future.
Ogni punto di attesa (await point) - cioè, ogni punto in cui il codice usa
la parola chiave await - rappresenta un punto in cui il controllo viene
restituito al runtime. Perché la cosa funzioni, Rust deve tenere traccia dello
stato nel blocco async in modo che il runtime possa avviare altro lavoro e
poi tornare quando è pronto per provare a far avanzare il primo. Questa è in
pratica una macchina a stati finiti1, come se avessi scritto un enum
come questo per salvare lo stato corrente ad ogni punto di attesa:
#![allow(unused)] fn main() { extern crate trpl; // necessario per test mdbook enum TitoloPaginaFuture<'a> { Iniziale { url: &'a str }, PrendiPuntoAttesa { url: &'a str }, TestoPuntoAttesa { risposta: trpl::Response }, } }
Scrivere il codice per passare manualmente tra ogni stato sarebbe laborioso e soggetto a errori, soprattutto quando è necessario aggiungere più funzionalità e più stati al codice in seguito. Fortunatamente, il compilatore Rust crea e gestisce automaticamente le strutture dati della macchina a stati per il codice async. Tutte le normali regole di prestito e ownership intorno alle strutture dati si applicano ancora, e felicemente, il compilatore gestisce anche la verifica di quelle per noi e fornisce messaggi di errore utili. Ne esamineremo alcuni più avanti in questo capitolo.
Alla fine, qualcosa deve eseguire questa macchina a stati, e quella cosa è un runtime. (Questo è il motivo per cui potresti imbatterti in menzioni a executor quando cerchi informazioni sui runtime: un executor è la parte di un runtime responsabile dell’esecuzione del codice async.)
Ora puoi vedere perché il compilatore ci ha impedito di rendere main stesso
una funzione async nel Listato 17-3. Se main fosse una funzione async,
qualcos’altro dovrebbe gestire la macchina a stati per qualsiasi future che
main restituisse, ma main è il punto di partenza del programma! Invece,
abbiamo chiamato la funzione trpl::block_on in main per configurare un
runtime ed eseguire la future restituita dal blocco async fino al suo
completamento.
Nota: Alcuni runtime forniscono macro in modo che tu possa scrivere una funzione
mainasync. Quelle macro riscrivonoasync fn main() { ... }per essere un normalefn main, che fa la stessa cosa che abbiamo fatto a mano nel Listato 17-4: chiamare una funzione che esegue una future fino al completamento proprio come fatrpl::block_on.
Ora mettiamo insieme questi pezzi e vediamo come possiamo scrivere codice concorrente.
Mettere a Gara i Due URL l’Uno Contro l’Altro
Nel Listato 17-5, chiamiamo titolo_pagina con due URL diversi passati dalla
riga di comando e li mettiamo a gara selezionando la future che finisce prima.
extern crate trpl; // necessario per test mdbook
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let titolo_fut_1 = titolo_pagina(&args[1]);
let titolo_fut_2 = titolo_pagina(&args[2]);
let (url, forse_titolo) =
match trpl::select(titolo_fut_1, titolo_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} ritornato per primo");
match forse_titolo {
Some(titolo) => println!("Il suo titolo era: '{titolo}'"),
None => println!("Non aveva titolo."),
}
})
}
async fn titolo_pagina(url: &str) -> (&str, Option<String>) {
let testo_risposta = trpl::get(url).await.text().await;
let titolo = Html::parse(&testo_risposta)
.select_first("title")
.map(|titolo| titolo.inner_html());
(url, titolo)
}titolo_pagina per due URL per vedere quale ritorna per primaIniziamo chiamando titolo_pagina per ciascuno degli URL forniti dall’utente.
Salviamo le future risultanti come titolo_fut_1 e titolo_fut_2. Ricorda,
queste non fanno ancora nulla, perché le future sono lazy e non le abbiamo
ancora messe in coda. Poi passiamo le future a trpl::select, che restituisce
un valore per indicare quale delle future a esso passate finisce per prima.
Nota: Sotto il cofano,
trpl::selectè costruito su una funzione più generale,select, definita nel cratefutures. Questa funzioneselectpuò fare molte cose che la funzionetrpl::selectnon può, ma ha anche alcune complessità aggiuntive che possiamo tralasciare per ora.
Può legittimamente “vincere” una qualsiasi delle future, quindi non ha senso
restituire un Result. Invece, trpl::select restituisce un type che non
abbiamo ancora visto, trpl::Either. Il type Either è in qualche modo
simile a un Result in quanto ha due casi. A differenza di Result, però, non
c’è alcuna nozione di successo o fallimento incorporata in Either. Invece, usa
Left e Right per indicare “l’uno o l’altro”:
#![allow(unused)] fn main() { enum Either<A, B> { Left(A), Right(B), } }
La funzione select restituisce Left con l’output dalla future del primo
argomento se è la più veloce a terminare, o Right con l’output della future
del secondo argomento se è invece quella che è stata più veloce. Questo
corrisponde all’ordine in cui appaiono gli argomenti quando si chiama la
funzione: il primo argomento è a sinistra del secondo argomento.
Aggiorniamo anche titolo_pagina per restituire lo stesso URL passato. In modo
che, se la pagina che restituisce per prima non ha un <title> che possiamo
risolvere, possiamo comunque stampare un messaggio significativo. Con queste
informazioni disponibili, concludiamo aggiornando l’output di println! per
indicare sia quale URL ha finito per primo, sia qual è il <title>, se
presente, per la pagina web a quell’URL.
Hai costruito ora un piccolo web scraper funzionante! Scegli un paio di URL ed esegui lo strumento da riga di comando. Potresti scoprire che alcuni siti sono costantemente più veloci di altri, mentre in altri casi il sito più veloce varia da un’esecuzione all’altra. Cosa più importante, hai imparato le basi del lavoro con le future, quindi ora possiamo approfondire cosa possiamo fare con async.
Applicare la Concorrenza con Async
In questa sezione, vedremo come usare async per affrontare alcune sfide di concorrenza che abbiamo già visto con i thread nel Capitolo 16. Dato che abbiamo già parlato dei concetti chiave, ci concentreremo sulle differenze tra thread e future.
In molti casi, le API per lavorare con la concorrenza usando async sono molto simili a quelle per usare i thread. In altri casi, finiscono per essere piuttosto diverse. Anche quando le API sembrano simili tra thread e async, spesso hanno comportamenti diversi e quasi sempre caratteristiche di prestazioni differenti.
Creare un Nuovo Task con spawn_task
La prima operazione che abbiamo affrontato nella sezione “Creare un Nuovo
Thread con spawn” del Capitolo 16 era
effettuare un conteggio su due thread separati. Facciamo la stessa cosa usando
async. Il crate trpl fornisce una funzione spawn_task che sembra molto
simile all’API thread::spawn, e una funzione sleep che è una versione
async dell’API thread::sleep. Possiamo usarle insieme per implementare
l’esempio di conteggio, come mostrato nel Listato 17-6.
extern crate trpl; // necessario per test mdbook use std::time::Duration; fn main() { trpl::block_on(async { trpl::spawn_task(async { for i in 1..10 { println!("ciao numero {i} dal primo task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("ciao numero {i} dal secondo task!"); trpl::sleep(Duration::from_millis(500)).await; } }); }
Come punto di partenza, impostiamo la nostra funzione main con
trpl::block_on in modo che la nostra funzione di livello superiore possa
essere async.
Nota: Da questo punto in poi nel capitolo, ogni esempio includerà lo stesso esatto codice di incapsulamento con
trpl::block_oninmain, quindi spesso lo salteremo proprio come facciamo conmain. Ricordati di includerlo nel tuo codice!
Poi scriviamo due loop all’interno di quel blocco, ciascuno contenente una
chiamata a trpl::sleep, che aspetta mezzo secondo (500 millisecondi) prima di
inviare il prossimo messaggio. Mettiamo un ciclo nel corpo di un
trpl::spawn_task e l’altro è un ciclo for nel task principale. Aggiungiamo
anche un await dopo le chiamate sleep.
Questo codice si comporta in modo simile all’implementazione basata su thread, inclusa la possibilità che tu possa vedere i messaggi apparire in un ordine diverso nel tuo terminale quando lo esegui:
ciao numero 1 dal secondo task!
ciao numero 1 dal primo task!
ciao numero 2 dal primo task!
ciao numero 2 dal secondo task!
ciao numero 3 dal primo task!
ciao numero 3 dal secondo task!
ciao numero 4 dal primo task!
ciao numero 4 dal secondo task!
ciao numero 5 dal primo task!
Questa versione si ferma non appena il ciclo for nel corpo del blocco async
principale finisce, perché il task avviato da spawn_task viene chiuso quando
la funzione main termina. Se vuoi che si esegua fino al completamento del
task, dovrai usare un join handle per aspettare che il primo task si
completi. Con i thread, abbiamo usato il metodo join per “bloccare” fino a
quando il thread avesse finito di eseguirsi. Nel Listato 17-7, possiamo usare
await per fare la stessa cosa, perché l’handle del task stesso è una
future. Il suo type Output è un Result, quindi dopo averlo atteso
(await), dobbiamo anche esporlo (unwrap).
extern crate trpl; // necessario per test mdbook use std::time::Duration; fn main() { trpl::run(async { let handle = trpl::spawn_task(async { for i in 1..10 { println!("ciao numero {i} dal primo task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("ciao numero {i} dal secondo task!"); trpl::sleep(Duration::from_millis(500)).await; } handle.await.unwrap(); }); }
await con un join handle per eseguire un task fino al completamentoQuesta versione aggiornata si esegue fino a quando entrambi i cicli finiscono:
ciao numero 1 dal secondo task!
ciao numero 1 dal primo task!
ciao numero 2 dal primo task!
ciao numero 2 dal secondo task!
ciao numero 3 dal primo task!
ciao numero 3 dal secondo task!
ciao numero 4 dal primo task!
ciao numero 4 dal secondo task!
ciao numero 5 dal primo task!
ciao numero 6 dal primo task!
ciao numero 7 dal primo task!
ciao numero 8 dal primo task!
ciao numero 9 dal primo task!
Finora, sembra che async e thread ci diano simili risultati, solo con una
sintassi diversa: usando await invece di chiamare join sull’handle, e
aspettando le chiamate sleep.
La differenza più grande è che non abbiamo dovuto avviare un altro thread del
sistema operativo per farlo. In realtà, non dobbiamo nemmeno avviare un task
qui. Poiché i blocchi async si compilano in future anonime, possiamo mettere
ogni ciclo in un blocco async e far eseguire al runtime entrambe fino al
completamento usando la funzione trpl::join.
Nella sezione “Attendere Che Tutti i Thread Finiscano” del Capitolo 16, abbiamo mostrato come usare il metodo join sul
type JoinHandle restituito quando si chiama std::thread::spawn. La
funzione trpl::join è simile, ma per le future. Quando gli dai due future,
produce una singola nuova future il cui output è una tupla che contiene
l’output di ciascuna future che hai passato una volta che entrambe si
completano. Quindi, nel Listato 17-8, usiamo trpl::join per aspettare che sia
fut1 che fut2 finiscano. Non aspettiamo fut1 e fut2 ma invece la nuova
future prodotta da trpl::join. Ignoriamo l’output, perché è solo una tupla
che contiene due valori unitari.
extern crate trpl; // necessario per test mdbook use std::time::Duration; fn main() { trpl::run(async { let fut1 = async { for i in 1..10 { println!("ciao numero {i} dal primo task!"); trpl::sleep(Duration::from_millis(500)).await; } }; let fut2 = async { for i in 1..5 { println!("ciao numero {i} dal secondo task!"); trpl::sleep(Duration::from_millis(500)).await; } }; trpl::join(fut1, fut2).await; }); }
trpl::join per aspettare due future anonimeQuando lo eseguiamo, vediamo entrambe le future eseguirsi fino al completamento:
ciao numero 1 dal primo task!
ciao numero 1 dal secondo task!
ciao numero 2 dal primo task!
ciao numero 2 dal secondo task!
ciao numero 3 dal primo task!
ciao numero 3 dal secondo task!
ciao numero 4 dal primo task!
ciao numero 4 dal secondo task!
ciao numero 5 dal primo task!
ciao numero 6 dal primo task!
ciao numero 7 dal primo task!
ciao numero 8 dal primo task!
ciao numero 9 dal primo task!
Ora, vedrai lo stesso ordine ogni volta, il che è molto diverso da quello che
abbiamo visto con i thread e con trpl::spawn_task nel Listato 17-7. Questo
perché la funzione trpl::join è equa, il che significa che controlla
ciascuna future con la stessa frequenza, alternando tra loro, e non lascia che
una “corra avanti” se l’altra è pronta. Con i thread, il sistema operativo
decide quale thread controllare e per quanto tempo farlo eseguire. Con async
Rust, il runtime decide quale task controllare. (Nella pratica, i dettagli
si complicano perché un runtime async potrebbe in realtà usare i thread
del sistema operativo come parte della gestione della concorrenza, quindi
garantire l’equità può essere più lavoro per un runtime, ma è comunque
possibile!) I runtime non devono garantire l’equità per qualsiasi operazione
data, e spesso offrono diverse API per farti scegliere se vuoi l’equità o meno.
Prova alcune di queste varianti sull’attesa delle future e vedi cosa fanno:
- Rimuovi il blocco async da uno o entrambi i cicli.
- Aspetta ogni blocco async immediatamente dopo averlo definito.
- Incapsula solo il primo ciclo in un blocco async e aspetta la future risultante dopo il corpo del secondo ciclo.
Per una sfida extra, cerca di capire quale sarà l’output in ciascun caso prima di eseguire il codice!
Inviare Dati Tra Due Task Usando il Passaggio di Messaggi
Condividere dati tra future sarà anch’esso familiare: useremo di nuovo il passaggio di messaggi, ma questa volta con le versioni async dei type e delle funzioni. Prenderemo una strada leggermente diversa rispetto a quella che abbiamo preso nella sezione “Trasferire Dati tra Thread Usando il Passaggio di Messaggi” del Capitolo 16 per illustrare alcune delle differenze chiave tra concorrenza basata su thread e concorrenza basata su future. Nel Listato 17-9, inizieremo con un singolo blocco async, non creando un task separato come avevamo creato un thread separato.
extern crate trpl; // necessario per test mdbook fn main() { trpl::block_on(async { let (tx, mut rx) = trpl::channel(); let val = String::from("ciao"); tx.send(val).unwrap(); let ricevuto = rx.recv().await.unwrap(); println!("ricevuto '{ricevuto}'"); }); }
tx e rxQui, usiamo trpl::channel, una versione async dell’API del canale
multi-produttore, singolo-consumatore che abbiamo usato con i thread nel
Capitolo 16. La versione async dell’API è solo un po’ diversa dalla versione
basata su thread: usa un ricevitore rx mutabile piuttosto che immutabile, e
il suo metodo recv produce una future che dobbiamo aspettare piuttosto che
produrre il valore direttamente. Ora possiamo inviare messaggi dal mittente al
ricevitore. Nota che non dobbiamo avviare un thread separato o nemmeno un
task; dobbiamo solo aspettare la chiamata rx.recv.
Il metodo sincrono Receiver::recv in std::mpsc::channel blocca fino a quando
non riceve un messaggio. Il metodo trpl::Receiver::recv non lo fa, perché è
async. Invece di bloccare, restituisce il controllo al runtime fino a quando
non viene ricevuto un messaggio o la estremità di invio del canale si chiude. Al
contrario, non aspettiamo la chiamata send, perché non blocca. Non ne ha
bisogno, perché il canale in cui lo stiamo inviando è senza vincoli.
Nota: Poiché tutto questo codice async si esegue in un blocco async in una chiamata
trpl::block_on, tutto al suo interno può evitare di bloccare. Tuttavia, il codice fuori da esso si bloccherà sulla funzioneblock_onche restituisce. Questo è proprio lo scopo della funzionetrpl::block_on: ci permette di scegliere dove bloccare in un insieme di codice async, e quindi dove passare tra codice sincrono e asincrono.
Nota due cose in questo esempio. Prima di tutto, il messaggio arriverà subito. Secondo, anche se usiamo una future qui, non c’è ancora concorrenza. Tutto nell’elenco accade in sequenza, proprio come farebbe se non ci fossero future coinvolte.
Affrontiamo la prima parte inviando una serie di messaggi e “dormendo” tra di loro, come mostrato nel Listato 17-10.
extern crate trpl; // necessario per test mdbook
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let valori = vec![
String::from("ciao"),
String::from("dalla"),
String::from("future"),
String::from("!!!"),
];
for valore in valori {
tx.send(valore).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(val) = rx.recv().await {
println!("ricevuto '{val}'");
}
});
}await tra ogni messaggioOltre ad inviare i messaggi, dobbiamo riceverli. In questo caso, poiché sappiamo
quanti messaggi stanno arrivando, potremmo farlo manualmente chiamando
rx.recv().await quattro volte. Nel mondo reale, tuttavia, di solito stiamo
aspettando un numero sconosciuto di messaggi, quindi dobbiamo continuare ad
aspettare fino a quando non determiniamo che non ci sono più messaggi.
Nel Listato 16-10, abbiamo usato un ciclo for per elaborare tutti gli elementi
ricevuti da un canale sincrono. Rust non ha ancora un modo per scrivere un ciclo
for su una serie di elementi prodotta asincronamente, quindi dobbiamo usare
un ciclo che non avevamo ancora visto: il ciclo condizionale while let. Questo
è la versione ciclo del costrutto if let che abbiamo visto nella sezione
“Controllare il Flusso con if let e let else” del Capitolo 6. Il ciclo continuerà ad eseguirsi finché il pattern
specificato continua a corrispondere al valore.
La chiamata rx.recv produce una future, che aspettiamo. Il runtime metterà
in pausa la future fino a quando non sarà pronta. Una volta che arriva un
messaggio, la future si risolverà in Some(messaggio) tutte le volte che
arriva un messaggio. Quando il canale si chiude, indipendentemente dal fatto che
siano arrivati alcuni messaggi, la future si risolverà invece in None per
indicare che non ci sono più valori e quindi dobbiamo smettere di aspettare.
Il ciclo while let mette insieme tutto questo. Se il risultato della chiamata
rx.recv().await è Some(messaggio), otteniamo accesso al messaggio e possiamo
usarlo nel corpo del ciclo, proprio come potremmo fare con if let. Se il
risultato è None, il ciclo termina. Ogni volta che il ciclo si completa,
raggiunge di nuovo il punto di attesa, quindi il runtime lo mette di nuovo in
pausa fino a quando non arriva un altro messaggio.
Il codice invia e riceve ora tutti i messaggi con successo. Purtroppo, ci sono ancora un paio di problemi. Innanzitutto, i messaggi non arrivano a intervalli di mezzo secondo. Arrivano tutti insieme, 2 secondi (2.000 millisecondi) dopo aver avviato il programma. In secondo luogo, questo programma non si arresta mai! Invece, aspetta per sempre nuovi messaggi. Dovrai interromperlo usando ctrl-C.
Il Codice Dentro Un Blocco Async Viene Eseguito Linearmente
Iniziamo esaminando perché i messaggi arrivano tutti insieme dopo il ritardo
cumulativo, piuttosto che arrivare con ritardi tra ciascuno. All’interno di un
dato blocco async, l’ordine in cui compaiono le parole chiave await nel
codice è anche l’ordine in cui vengono eseguite quando il programma si avvia.
C’è un singolo blocco async nel Listato 17-10, quindi tutto in esso si esegue
linearmente. Non c’è ancora concorrenza. Tutte le chiamate a tx.send accadono,
intercalate con tutte le chiamate trpl::sleep e i loro punti di attesa
associati. Solo allora il ciclo while let può passare in rassegna alcuni dei
punti di attesa sulle chiamate recv.
Per ottenere il comportamento che vogliamo, dove il ritardo accade tra ogni
messaggio, dobbiamo mettere le operazioni tx e rx nei loro blocchi async
separati, come mostrato nel Listato 17-11. In questo modo il runtime può
eseguire ciascuno di essi separatamente usando trpl::join, proprio come nel
Listato 17-8. Ancora una volta, aspettiamo il risultato della chiamata a
trpl::join, non le future singole. Se avessimo aspettato le future singole
in sequenza, saremmo tornati a un flusso sequenziale, proprio quello che stiamo
cercando di non fare.
extern crate trpl; // necessario per test mdbook
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let valori = vec![
String::from("ciao"),
String::from("dalla"),
String::from("future"),
String::from("!!!"),
];
for valore in valori {
tx.send(valore).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(val) = rx.recv().await {
println!("ricevuto '{val}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}send e recv nei loro blocchi async e aspettare le future per quei blocchiCon il codice aggiornato nel Listato 17-11, i messaggi vengono stampati a intervalli di 500 millisecondi, piuttosto che tutti insieme dopo 2 secondi.
Spostare la Ownership Dentro un Blocco Async
Il programma non si arresta comunque, per il modo in cui il ciclo while let
interagisce con trpl::join:
- La future restituita da
trpl::joinsi completa solo una volta che entrambe le future passate ad esso si sono completate. - La future
tx_futsi completa una volta che ha finito di dormire dopo aver inviato l’ultimo messaggio invals. - La future
rx_futnon si completerà fino a quando il ciclowhile letnon termina. - Il ciclo
while letnon terminerà fino a quando l’attesa dirx.recvproduceNone. - L’attesa di
rx.recvrestituiràNonesolo una volta che l’altra estremità del canale è chiusa. - Il canale si chiuderà solo se chiamiamo
rx.closeo quando l’estremità di invio,tx, viene eliminata. - Non chiamiamo
rx.closeda nessuna parte, etxnon verrà eliminato fino a quando il blocco async più esterno passato atrpl::block_onnon termina. - Il blocco non può terminare perché è bloccato su
trpl::joinin attesa di completamento, il che ci riporta all’inizio di questo elenco.
Al momento, il blocco async in cui inviamo i messaggi prende solo in prestito
tx perché inviare un messaggio non richiede la ownership, ma se potessimo
spostare tx in quel blocco async, verrebbe eliminato una volta che quel
blocco termina. Nella sezione “Catturare i Reference o Trasferire la
Ownership” del Capitolo 13, hai imparato come
usare la parola chiave move con le chiusure, e, come discusso nella sezione
“Usare le Chiusure move con i Thread” del
Capitolo 16, spesso dobbiamo spostare i dati nelle chiusure quando lavoriamo con
i thread. Le stesse dinamiche di base si applicano ai blocchi async, quindi
la parola chiave move funziona con i blocchi async proprio come fa con le
chiusure.
Nel Listato 17-12, cambiamo il blocco usato per inviare messaggi da async a
async move.
extern crate trpl; // necessario per test mdbook use std::time::Duration; fn main() { trpl::block_on(async { let (tx, mut rx) = trpl::channel(); let tx_fut = async move { // --taglio-- let valori = vec![ String::from("ciao"), String::from("dalla"), String::from("future"), String::from("!!!"), ]; for valore in valori { tx.send(valore).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(val) = rx.recv().await { println!("ricevuto '{val}'"); } }; trpl::join(tx_fut, rx_fut).await; }); }
Quando eseguiamo questa versione del codice, si chiude correttamente dopo che l’ultimo messaggio è stato inviato e ricevuto. Adesso vediamo cosa deve cambiare per consentirci di inviare dati da più di una future.
Unire un Certo Numero di Future Con la Macro join!
Questo canale async è anche un canale multi-produttore, quindi possiamo
chiamare clone su tx se vogliamo inviare messaggi da più future, come
mostrato nel Listato 17-13.
extern crate trpl; // necessario per test mdbook use std::time::Duration; fn main() { trpl::block_on(async { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = async move { let valori = vec![ String::from("ciao"), String::from("dalla"), String::from("future"), String::from("!!!"), ]; for val in valori { tx1.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(valore) = rx.recv().await { println!("ricevuto '{valore}'"); } }; let tx_fut = async move { let valori = vec![ String::from("altri"), String::from("messaggi"), String::from("per"), String::from("te"), ]; for val in valori { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(1500)).await; } }; trpl::join!(tx1_fut, tx_fut, rx_fut); }); }
Prima di tutto, cloniamo tx, creando tx1 fuori dal primo blocco async.
Spostiamo tx1 in quel blocco proprio come abbiamo fatto prima con tx. Poi,
in seguito, spostiamo l’originale tx in un nuovo blocco async, dove
inviamo più messaggi con un ritardo leggermente maggiore. Abbiamo messo questo
nuovo blocco async dopo il blocco async per ricevere messaggi, ma andrebbe
bene anche se messo prima. La chiave è l’ordine in cui le future vengono
attese, non quello in cui vengono create.
Entrambi i blocchi async per inviare messaggi devono essere blocchi async move in modo che sia tx che tx1 vengano eliminati quando quei blocchi
finiscono. Altrimenti, finiremo di nuovo nello stesso ciclo infinito da cui
siamo partiti.
Infine, passiamo da trpl::join a trpl::join! per gestire la future
aggiuntiva: la macro join! accetta un numero arbitrario di future come
parametro, ma questo numero deve essere conosciuto durante la compilazione.
Discuteremo come gestire un numero non definito di future più avanti nel
capitolo.
Ora vediamo tutti i messaggi da entrambe le future di invio, e poiché le future di invio usano ritardi leggermente diversi dopo l’invio, i messaggi vengono anche ricevuti a quegli intervalli diversi:
ricevuto 'ciao'
ricevuto 'altri'
ricevuto 'dalla'
ricevuto 'future'
ricevuto 'messaggi'
ricevuto '!!!'
ricevuto 'per'
ricevuto 'te'
Abbiamo visto come gestire il passaggio di messaggi per inviare dati tra future, come il codice sia eseguito sequenzialmente all’interno di un blocco async, come spostare la ownership dentro il blocco async, e come unire più future. Ora vedremo come e perché informare il runtime di passare all’esecuzione di un altro task.
Restituire il Controllo al Runtime
Ricorda da “Il Nostro Primo Programma Async” che ad ogni punto di attesa, Rust dà a un runtime la possibilità di mettere in pausa il compito e passare a un altro se la future in attesa non è pronta. Anche l’inverso è vero: Rust mette in pausa solo i blocchi async e restituisce il controllo a un runtime in un punto di attesa. Tutto ciò che si trova tra i punti di attesa è sincrono.
Questo significa che se fai un sacco di lavoro in un blocco async senza un punto di attesa, quella future bloccherà qualsiasi altra future dal fare progressi. A volte potresti sentire menzionato questo comportamento come ad una future che affama (starving) altre future. In alcuni casi, potrebbe non essere un grosso problema. Tuttavia, se stai facendo qualche tipo di elaborazione dispendiosa o lavoro a lungo termine, o se hai una future che continuerà a fare un particolare compito indefinitamente, dovrai pensare a quando e dove restituire il controllo al runtime.
Simuliamo un’operazione a lungo termine per illustrare il problema
dell’affamamento e come risolverlo. Il Listato 17-14 introduce una funzione
lenta.
extern crate trpl; // necessario per test mdbook use std::{thread, time::Duration}; fn main() { trpl::block_on(async { // Più tardi chiameremo `lenta` da qui }); } fn lenta(nome: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{nome}' eseguita per {ms}ms"); }
thread::sleep per simulare operazioni lenteQuesto codice utilizza std::thread::sleep invece di trpl::sleep in modo che
chiamare lenta blocchi il thread corrente per un certo numero di
millisecondi. Possiamo usare lenta per rappresentare operazioni del mondo
reale che sono sia a lungo termine che bloccanti.
Nel Listato 17-15, utilizziamo lenta per emulare questo tipo di lavoro legato
alla CPU in un paio di future.
extern crate trpl; // necessario per test mdbook use std::{thread, time::Duration}; fn main() { trpl::block_on(async { let a = async { println!("'a' iniziata."); lenta("a", 30); lenta("a", 10); lenta("a", 20); trpl::sleep(Duration::from_millis(50)).await; println!("'a' finita."); }; let b = async { println!("'b' iniziata."); lenta("b", 75); lenta("b", 10); lenta("b", 15); lenta("b", 350); trpl::sleep(Duration::from_millis(50)).await; println!("'b' finita."); }; trpl::select(a, b).await; }); } fn lenta(nome: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{nome}' eseguita per {ms}ms"); }
lenta per simulare operazioni che vanno a rilentoOgni future restituisce il controllo al runtime solo dopo aver eseguito alcune operazioni lente. Se esegui questo codice, vedrai questo output:
'a' iniziata.
'a' eseguita per 30ms
'a' eseguita per 10ms
'a' eseguita per 20ms
'b' iniziata.
'b' eseguita per 75ms
'b' eseguita per 10ms
'b' eseguita per 15ms
'b' eseguita per 350ms
'a' finita.
Come per il Listato 17-5 dove abbiamo usato trpl::select per mettere a gara
due future che elaboravano un URL, select termina non appena a è
completata. Non c’è “intreccio” tra le due future, però. La future a fa
tutto il suo lavoro fino a quando la chiamata a trpl::sleep viene attesa con
await, poi la future b fa tutto il suo lavoro fino a quando la sua
chiamata a trpl::sleep viene attesa, e infine la future a finisce. Per
consentire a entrambe le future lente di fare progressi, abbiamo bisogno di
punti di attesa in modo da poter restituire il controllo al runtime di tanto
in tanto per consentire anche all’altra di proseguire!
Possiamo già vedere questo tipo di passaggio avvenire nel Listato 17-15: se
rimuovessimo trpl::sleep alla fine della future a, essa completerebbe la
propria esecuzione senza che la future b nemmeno cominciasse. Proviamo a
utilizzare la funzione trpl::sleep come punto di partenza per consentire alle
operazioni di alternarsi nel fare progressi, come mostrato nel Listato 17-16.
extern crate trpl; // necessario per test mdbook use std::{thread, time::Duration}; fn main() { trpl::block_on(async { let un_ms = Duration::from_millis(1); let a = async { println!("'a' iniziata."); lenta("a", 30); trpl::sleep(un_ms).await; lenta("a", 10); trpl::sleep(un_ms).await; lenta("a", 20); trpl::sleep(un_ms).await; println!("'a' finita."); }; let b = async { println!("'b' iniziata."); lenta("b", 75); trpl::sleep(un_ms).await; lenta("b", 10); trpl::sleep(un_ms).await; lenta("b", 15); trpl::sleep(un_ms).await; lenta("b", 350); trpl::sleep(un_ms).await; println!("'b' finita."); }; trpl::select(a, b).await; }); } fn lenta(nome: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{nome}' eseguita per {ms}ms"); }
trpl::sleep per consentire alle operazioni di alternarsi nel fare progressiAbbiamo aggiunto chiamate a trpl::sleep con punti di attesa tra ogni chiamata
a lenta. Ora il lavoro delle due future è intervallato:
'a' iniziata.
'a' eseguita per 30ms
'b' iniziata.
'b' eseguita per 75ms
'a' eseguita per 10ms
'b' eseguita per 10ms
'a' eseguita per 20ms
'b' eseguita per 15ms
'a' finita.
La future a continua a lavorare per un po’ prima di restituire il controllo
a b, perché chiama lenta prima di chiamare trpl::sleep, ma dopo ciò le
future si alternano ogni volta che una di esse incontra un punto di attesa. In
questo caso, abbiamo fatto ciò dopo ogni chiamata a lenta, ma potremmo
suddividere il lavoro in qualsiasi modo abbia più senso per noi.
Ma non vogliamo davvero dormire qui, però: vogliamo eseguire le nostre
operazioni il più velocemente possibile e restituire il controllo al runtime
quando possibile. Possiamo farlo direttamente, utilizzando la funzione
trpl::yield_now. Nel Listato 17-17, sostituiamo tutte quelle chiamate a
trpl::sleep con trpl::yield_now.
extern crate trpl; // necessario per test mdbook use std::{thread, time::Duration}; fn main() { trpl::block_on(async { let a = async { println!("'a' iniziata."); lenta("a", 30); trpl::yield_now().await; lenta("a", 10); trpl::yield_now().await; lenta("a", 20); trpl::yield_now().await; println!("'a' finita."); }; let b = async { println!("'b' iniziata."); lenta("b", 75); trpl::yield_now().await; lenta("b", 10); trpl::yield_now().await; lenta("b", 15); trpl::yield_now().await; lenta("b", 350); trpl::yield_now().await; println!("'b' finita."); }; trpl::select(a, b).await; }); } fn lenta(nome: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{nome}' eseguita per {ms}ms"); }
trpl::yield_now per consentire alle operazioni di alternarsi nel fare progressiQuesto codice è sia più chiaro riguardo all’intento reale sia può essere
significativamente più veloce rispetto all’uso di sleep, perché i timer come
quello usato da sleep hanno spesso limiti su quanto possono essere granulari.
La versione di sleep che stiamo usando, ad esempio, dormirà sempre per almeno
un millisecondo, anche se le passiamo una Duration di un nanosecondo. Ancora
una volta, i computer moderni sono veloci: possono fare molto in un
millisecondo!
Questo significa che l’async può essere utile anche per compiti legati al calcolo, a seconda di cosa sta facendo il tuo programma, perché fornisce uno strumento utile per strutturare le relazioni tra le diverse parti del programma (ma con un costo prestazionale per la macchina a stati async). Questa è una forma di multitasking cooperativo, in cui ogni future ha il potere di determinare quando restituisce il controllo tramite i punti di attesa. Ogni future ha quindi anche la responsabilità di evitare di bloccarsi troppo a lungo. In alcuni sistemi operativi embedded basati su Rust, questo è l’unico tipo di multi-tasking!
Nel codice reale, di solito non lavorerai direttamente alternando chiamate di funzione con punti di attesa su ogni singola riga, ovviamente. Anche se restituire il controllo in questo modo è relativamente poco costoso, non è gratuito. In molti casi, cercare di suddividere un compito legato al calcolo potrebbe renderlo significativamente più lento, quindi a volte è meglio per le prestazioni complessive lasciare che un’operazione si blocchi brevemente. Misura sempre per vedere quali sono i veri colli di bottiglia delle prestazioni del tuo codice. Tuttavia, la dinamica sottostante è importante da tenere a mente, se stai vedendo molto lavoro avvenire in serie che ti aspettavi avvenisse in parallelo!
Costruire le Nostre Astrazioni Async
Possiamo anche comporre le future insieme per creare nuovi modelli. Ad
esempio, possiamo costruire una funzione timeout con i blocchi async che
abbiamo già. Quando abbiamo finito, il risultato sarà un altro blocco di
costruzione che potremmo usare per creare ancora più astrazioni async.
Il Listato 17-18 mostra come ci aspettiamo che funzioni questo timeout con una
future lento.
extern crate trpl; // necessario per test mdbook
use std::time::Duration;
fn main() {
trpl::block_on(async {
let lento = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finalmente finito"
};
match timeout(lento, Duration::from_secs(2)).await {
Ok(messaggio) => println!("Completato con '{messaggio}'"),
Err(durata) => {
println!("Fallito dopo {} secondi", durata.as_secs())
}
}
});
}timeout per eseguire un’operazione lenta con un limite di tempoImplementiamolo! Per cominciare, pensiamo all’API per timeout:
- Deve essere essa stessa una funzione async in modo da poterla attendere.
- Il suo primo parametro dovrebbe essere una future da eseguire. Possiamo renderla generica per consentirle di funzionare con qualsiasi future.
- Il suo secondo parametro sarà il tempo massimo da attendere. Se usiamo una
Duration, sarà facile passarla atrpl::sleep. - Dovrebbe restituire un
Result. Se la future completa con successo, ilResultsaràOkcon il valore prodotto dalla future. Se il timeout scade prima, ilResultsaràErrcon la durata che il timeout ha atteso.
Il Listato 17-19 mostra questa dichiarazione.
extern crate trpl; // necessario per test mdbook
use std::time::Duration;
fn main() {
trpl::block_on(async {
let lento = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finalmente finito"
};
match timeout(lento, Duration::from_secs(2)).await {
Ok(messaggio) => println!("Completato con '{messaggio}'"),
Err(durata) => {
println!("Fallito dopo {} secondi", durata.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_da_testare: F,
tempo_massimo: Duration,
) -> Result<F::Output, Duration> {
// Qui è dove metteremo l'implementazione!
}timeoutQuesto soddisfa i nostri obiettivi per i type. Ora pensiamo al comportamento
di cui abbiamo bisogno: vogliamo far competere la future passata contro la
durata fornita. Possiamo usare trpl::sleep per creare una future che duri
quanto richiesto e usare trpl::select per eseguirla contro la future che il
chiamante passa.
Nel Listato 17-20, implementiamo timeout facendo il match sul risultato
dell’attesa di trpl::select.
extern crate trpl; // necessario per test mdbook use std::time::Duration; use trpl::Either; // --taglio-- fn main() { trpl::block_on(async { let lento = async { trpl::sleep(Duration::from_secs(5)).await; "Finalmente finito" }; match timeout(lento, Duration::from_secs(2)).await { Ok(messaggio) => println!("Completato con '{messaggio}'"), Err(durata) => { println!("Fallito dopo {} secondi", durata.as_secs()) } } }); } async fn timeout<F: Future>( future_da_testare: F, tempo_massimo: Duration, ) -> Result<F::Output, Duration> { match trpl::select(future_da_testare, trpl::sleep(tempo_massimo)).await { Either::Left(output) => Ok(output), Either::Right(_) => Err(tempo_massimo), } }
timeout con select e sleepL’implementazione di trpl::select non è equa: processa gli argomenti sempre
nell’ordine in cui sono passati (altre implementazioni di select scelgono a
caso quale argomento processare per primo). Pertanto, passiamo
future_da_testare a select per prima in modo che abbia la possibilità di
completare anche se tempo_massimo è una durata molto breve. Se
future_da_testare finisce prima, select restituirà Left con l’output da
future_da_testare. Se il timer finisce prima, select restituirà Right con
l’output del timer di ()
Se future_da_testare ha successo e otteniamo un Left(output), restituiamo
Ok(output). Se invece il timer finisce prima e otteniamo un Right(()),
ignoriamo il () con _ e restituiamo Err(tempo_massimo).
Con questo, abbiamo un timeout funzionante combinando più blocchi async. Se
eseguiamo il nostro codice, stamperà la modalità di errore dopo il timeout:
Fallito dopo 2 secondi
Poiché le future si compongono con altre future, puoi costruire strumenti davvero potenti utilizzando blocchi di costruzione async più piccoli. Ad esempio, puoi utilizzare questo stesso approccio per combinare timeout con ripetizioni, e a loro volta usarli con operazioni come chiamate di rete (come quelli nel Listato 17-5).
Nella pratica, di solito lavorerai direttamente con async e await, e
secondariamente con funzioni come select e macro come join! per controllare
come vengano eseguite le varie future.
Abbiamo ora visto diversi modi per lavorare con più future contemporaneamente. Prossimamente, vedremo come possiamo lavorare con più future in una sequenza nel tempo con gli stream.
Stream: Future in Sequenza
Ricorda come abbiamo utilizzato il ricevitore per il nostro canale async in
precedenza nella sezione “Inviare Dati Tra Due Task Usando il Passaggio di
Messaggi” di questo capitolo. Il metodo async
recv produce una sequenza di elementi nel tempo. Questo è un esempio di un
modello molto più generale noto come stream. Molti concetti sono naturalmente
rappresentati come stream: elementi che diventano disponibili in una coda,
blocchi di dati che vengono estratti in modo incrementale dal filesystem quando
l’intero set di dati è troppo grande per la memoria del computer, o dati che
arrivano attraverso la rete nel tempo. Poiché gli stream sono future,
possiamo usarli con qualsiasi altro tipo di future e combinarli in modi
interessanti. Ad esempio, possiamo raggruppare gli eventi per evitare di
innescare troppe chiamate di rete, impostare timeout su sequenze di operazioni
di lunga durata o limitare gli eventi dell’interfaccia utente per evitare di
svolgere lavori inutili.
Abbiamo visto una sequenza di elementi nel Capitolo 13, quando abbiamo esaminato
il trait Iterator nella sezione “Il Trait Iterator e il Metodo
next”, ma ci sono due differenze tra gli
iteratori e il ricevitore del canale async. La prima differenza sono le
tempistiche: gli iteratori sono sincroni, mentre il ricevitore del canale è
asincrono. La seconda è l’API. Quando lavoriamo direttamente con Iterator,
chiamiamo il suo metodo sincrono next. Con lo stream trpl::Receiver, in
particolare, abbiamo invece chiamato un metodo asincrono recv. A parte questo,
le API si somigliano molto, e questa somiglianza non è una coincidenza. Uno
stream è come una forma asincrona di iterazione. Mentre il trpl::Receiver
aspetta specificamente di ricevere messaggi, però, l’API dello stream di uso
generale è molto più ampia: fornisce il prossimo elemento come fa Iterator, ma
in modo asincrono.
La somiglianza tra iteratori e stream in Rust significa che possiamo
effettivamente creare uno stream da qualsiasi iteratore. Come con un
iteratore, possiamo lavorare con uno stream chiamando il suo metodo next e
poi aspettare l’output, come nel Listato 17-21, che per ora non si compilerà.
extern crate trpl; // necessario per test mdbook
fn main() {
trpl::block_on(async {
let valori = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = valori.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(valore) = stream.next().await {
println!("Il valore era: {valore}");
}
});
}Iniziamo con un array di numeri, che convertiamo in un iteratore e poi chiamiamo
map su di esso per raddoppiare tutti i valori. Poi convertiamo l’iteratore in
uno stream usando la funzione trpl::stream_from_iter. Successivamente,
iteriamo sugli elementi nello stream man mano che arrivano con il ciclo while let.
Sfortunatamente, quando proviamo a eseguire il codice, non si compila ma invece
riporta che non c’è alcun metodo next disponibile:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter<I>` in the current scope
--> src/main.rs:10:41
|
10 | while let Some(valore) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(valore) = stream.try_next().await {
| ++++
Come spiega questo output, la ragione dell’errore del compilatore è che abbiamo
bisogno del trait giusto in scope per poter utilizzare il metodo next.
Dato il nostro discorso finora, potresti ragionevolmente aspettarti che quel
trait sia Stream, ma in realtà è StreamExt. Abbreviazione di estensione,
Ext è un modello comune nella comunità Rust per estendere un trait con un
altro.
Il trait Stream definisce un’interfaccia a basso livello che combina
efficacemente i trait Iterator e Future. StreamExt fornisce un insieme
di API di livello superiore costruite sulla base di Stream, inclusi il metodo
next e altri metodi utili simili a quelli forniti dal trait Iterator.
Stream e StreamExt non fanno ancora parte della libreria standard di Rust,
ma la maggior parte dei crate dell’ecosistema utilizza definizioni simili.
La soluzione all’errore del compilatore è aggiungere una dichiarazione use per
trpl::StreamExt, come nel Listato 17-22.
extern crate trpl; // necessario per test mdbook use trpl::StreamExt; fn main() { trpl::block_on(async { let valori = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; // --taglio-- let iter = valori.iter().map(|n| n * 2); let mut stream = trpl::stream_from_iter(iter); while let Some(valore) = stream.next().await { println!("Il valore era: {valore}"); } }); }
Con tutti questi pezzi messi insieme, questo codice funziona come vogliamo!
Inoltre, ora che abbiamo StreamExt in scope, possiamo utilizzare tutti i
suoi metodi utili, proprio come con gli iteratori.
Uno Sguardo Più Da Vicino ai Trait per Async
Nel corso del capitolo, abbiamo utilizzato i trait Future, Stream e
StreamExt in vari modi. Finora, però, abbiamo evitato di addentrarci troppo
nei dettagli di come funzionano o di come interagiscono, il che va bene per la
maggior parte delle volte che li userai nel tuo lavoro quotidiano con Rust. A
volte, però, ti capiterà di incontrare situazioni in cui avrai bisogno di
comprendere queste cose più in dettaglio. In questa sezione, ci addentreremo il
giusto in questi dettagli per aiutarti in quegli scenari, lasciando comunque il
vero e proprio approfondimento completo alla documentazione specifica di
quello che ti interessa.
Il Trait Future
Iniziamo a dare un’occhiata più da vicino a come funziona il trait Future.
Ecco come Rust lo definisce:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
Quella definizione di trait include alcuni nuovi type e anche una sintassi che non abbiamo visto prima d’ora, quindi esaminiamola un pezzo per volta.
Per prima cosa, il type associato Output di Future dice in cosa si risolve
la future. Questo è analogo al type associato Item per il trait
Iterator. In secondo luogo, Future ha il metodo poll, che prende un
reference speciale Pin per il suo parametro self e un reference mutabile
a un type Context, e restituisce un Poll<Self::Output>. Parleremo più
avanti di Pin e Context. Per ora, concentriamoci su cosa restituisce il
metodo, il type Poll:
#![allow(unused)] fn main() { pub enum Poll<T> { Ready(T), Pending, } }
Questo type Poll è simile a un Option. Ha una variante che ha un valore,
Ready(T), e una che non ce l’ha, Pending (occupata). Tuttavia, Poll
significa qualcosa di molto diverso da Option! La variante Pending indica
che la future ha ancora lavoro da fare, quindi il chiamante dovrà controllare
di nuovo più tardi. La variante Ready indica che la Future ha finito il suo
lavoro e il valore T è disponibile.
Nota: È raro dover chiamare
polldirettamente, ma se devi, tieni a mente che con la maggior parte delle future, il chiamante non dovrebbe chiamarepolldi nuovo dopo che la future ha restituitoReady. Molte future andranno in panic se interrogate di nuovo dopo essere diventate pronte. Le future che possono essere interrogate di nuovo lo diranno esplicitamente nella loro documentazione. Questo è simile a come si comportaIterator::next.
Quando vedi codice che usa await, Rust lo compila dietro le quinte in codice
che chiama poll. Ritornando per un attimo al Listato 17-4, dove abbiamo
stampato il titolo della pagina per un singolo URL, Rust lo compila in qualcosa
di simile (anche se non esattamente) a questo:
match titolo_pagina(url).poll() {
Ready(valore) => match titolo_pagina {
Some(titolo) => println!("Il titolo per {url} era {titolo}"),
None => println!("{url} non aveva titolo"),
}
Pending => {
// Ma cosa mettiamo qui?
}
}Cosa dovremmo fare quando la future è ancora Pending? Abbiamo bisogno di un
modo per riprovare, e riprovare, e riprovare, fino a quando la future è
finalmente pronta. In altre parole, abbiamo bisogno di un ciclo:
let mut titolo_pagina_fut = titolo_pagina(url);
loop {
match titolo_pagina_fut.poll() {
Ready(valore) => match titolo_pagina {
Some(titolo) => println!("Il titolo per {url} era {titolo}"),
None => println!("{url} non aveva titolo"),
}
Pending => {
// continua
}
}
}Se Rust lo compilasse esattamente in quel codice, però, ogni await sarebbe
bloccante, esattamente l’opposto di ciò che volevamo! Invece, Rust si assicura
che il ciclo possa cedere il controllo a qualcosa che può mettere in pausa il
lavoro su questa future per lavorare su altre future e poi controllare di
nuovo questo più tardi. Come abbiamo visto, quel qualcosa è un runtime
async, e questo lavoro di pianificazione e coordinamento è uno dei suoi
compiti principali.
Nella sezione “Inviare Dati Tra Due Task Usando il Passaggio di
Messaggi”, abbiamo descritto l’attesa su
rx.recv. La chiamata recv restituisce una future, e attendere la future
la richiama. Abbiamo notato che un runtime metterà in pausa la future fino a
quando è pronta o con Some(messaggio) o con None quando il canale si chiude.
Ora che comprendi meglio il trait Future, e specificamente Future::poll,
possiamo vedere come funziona. Il runtime sa che la future non è pronta
quando restituisce Poll::Pending. Al contrario, il runtime sa che la
future è pronta e la avanza quando poll restituisce
Poll::Ready(Some(messaggio)) o Poll::Ready(None).
I dettagli esatti di come un runtime faccia ciò vanno oltre lo scopo di questo libro, ma la chiave è vedere i meccanismi di base delle future: un runtime interroga ogni future di cui è responsabile, rimettendo la future a dormire quando non è ancora pronta.
Il Type Pin e il Trait Unpin
Nel Listato 17-13 abbiamo usato la macro trpl::join! per unire e aspettare tre
future. È tuttavia comune avere una collezione come un vettore che contiene un
certo numero di future non conoscibile se non durante l’esecuzione del
programma. Apportiamo delle modifiche al Listato 17-13 per mettere le tre
future in un vettore e chiamare la funzione trpl::join_all al posto della
macro, cosa che per ora non si compilerà.
extern crate trpl; // necessario per test mdbook
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let valori = vec![
String::from("ciao"),
String::from("dalla"),
String::from("future"),
String::from("!!!"),
];
for val in valori {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(valore) = rx.recv().await {
println!("ricevuto '{valore}'");
}
};
let tx_fut = async move {
// --taglio--
let valori = vec![
String::from("altri"),
String::from("messaggi"),
String::from("per"),
String::from("te"),
];
for val in valori {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let future: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(future).await;
});
}Incapsuliamo ciascuna future in una Box rendendole oggetti trait, proprio
come abbiamo fatto nella sezione “Restituire Errori dalla Funzione
esegui” del Capitolo 12. (Parleremo degli oggetti trait
in dettaglio nel Capitolo 18.) Usare oggetti trait ci permette di trattare
ciascuna delle future anonime prodotte da questi type come fossero il
medesimo type, perché tutti implementano il trait Future.
Questo potrebbe essere sorprendente. Dopotutto, nessuno dei blocchi async
restituisce nulla, quindi ciascuno produce un Future<Output = ()>. Ricorda che
Future è un trait, e che il compilatore crea una enum univoca per ogni
blocco async anche se hanno type di output identici. Non puoi mettere due
struct scritte a mano diverse in un Vec, e la stessa regola si applica alle
enum diverse generate dal compilatore.
Passiamo quindi la collezione di future alla funzione trpl::join_all e
aspettiamo il risultato. Tuttavia, questa modifica non viene compilata; ecco la
parte rilevante dei messaggi di errore:
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:51:32
|
51 | trpl::join_all(future).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
La nota in questo messaggio di errore ci dice che dovremmo usare la macro pin!
per fissare i valori, il che significa incapsularli nel type Pin che
garantisce il fatto che questi valori non vengano spostati nella memoria. Il
messaggio di errore dice che il pinning è richiesto perché dyn Future<Output = ()> deve implementare il trait Unpin, cosa che al momento non fa.
La funzione trpl::join_all restituisce una struct chiamata JoinAll. Quella
struct è generica su un type F, che è vincolato a implementare il trait
Future. Attendere direttamente una future con await blocca implicitamente
la future. Ecco perché non abbiamo bisogno di usare pin! ovunque vogliamo
attendere le future.
Tuttavia, qui non stiamo attendendo direttamente una future. Invece,
costruiamo un nuova future, JoinAll, passando una collezione di future
alla funzione join_all. La firma per join_all richiede che i type degli
elementi nella collezione implementino tutti il trait Future, e Box<T>
implementa Future solo se il T che incapsula è una future che implementa
il trait Unpin.
Sono un sacco di informazioni da assorbire! Per capire davvero, approfondiamo un
po’ di più come funziona effettivamente il trait Future, in particolare
riguardo al pinning. Guarda di nuovo la definizione del trait Future:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; // Metodo richiesto fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
Il parametro cx e il suo type Context sono la chiave per capire come un
runtime sa effettivamente quando controllare una data future pur rimanendo
lazy. Ancora una volta, i dettagli di come ciò funzioni vanno oltre lo scopo
di questo capitolo, e generalmente devi pensare a questo solo quando scrivi
un’implementazione personalizzata di Future. Ci concentreremo invece sul
type per self, poiché è la prima volta che vediamo un metodo in cui self
ha un’annotazione di type. Un’annotazione di type per self funziona come
le annotazioni di type per altri parametri di funzione ma con due differenze
chiave:
- Indica a Rust di quale type deve essere
selfaffinché il metodo possa essere chiamato. - Non può essere semplicemente qualsiasi type. È limitato al type su cui il
metodo è implementato, a un reference o a un puntatore intelligente a quel
type, o a un
Pinche incapsula un reference a quel type.
Esploreremo maggiormente questa sintassi nel Capitolo 18. Per ora, è sufficiente sapere che se vogliamo interrogare una future per
controllare se è Pending o Ready(Output), abbiamo bisogno di un reference
mutabile al type incapsulato in Pin.
Pin è un wrapper per type simili a puntatori come &, &mut, Box e
Rc. (Tecnicamente, Pin funziona con type che implementano i trait
Deref o DerefMut, ma questo è effettivamente equivalente a lavorare solo con
reference e puntatori intelligenti.) Pin di per sé non è un puntatore e non
ha alcun comportamento proprio, come invece Rc e Arc fanno con il conteggio
dei reference; è puramente uno strumento che il compilatore può utilizzare per
imporre vincoli sull’uso dei puntatori.
Ricordando che await è implementato in termini di chiamate a poll, iniziamo
a capire il messaggio di errore che abbiamo visto in precedenza, ma quello era
in termini di Unpin, non di Pin. Quindi, come si relazionano esattamente
Pin e Unpin, e perché il Future ha bisogno che self sia in un type
Pin per chiamare poll?
Come menzionato in precedenza nel capitolo, una serie di punti di attesa in una future viene compilata in una macchina a stati, e il compilatore si assicura che quella macchina a stati segua tutte le normali regole di sicurezza di Rust, inclusi il prestito e la ownership. Per far funzionare tutto ciò, Rust guarda quali dati sono necessari tra un punto di attesa e l’altro, o tra il punto di attesa e la fine del blocco async. Crea quindi una variante corrispondente nella macchina a stati compilata. Ogni variante ottiene l’accesso di cui ha bisogno ai dati che verranno utilizzati in quella sezione del codice sorgente, o prendendo possesso di quei dati o ottenendo un reference mutabile o immutabile ad essi.
Finora, tutto bene: se commettiamo errori riguardo alla ownership o ai
reference in un dato blocco async, il borrow checker ce lo dirà. Quando
vogliamo spostare la future che corrisponde a quel blocco, come spostarla in
un Vec da passare a join_all, le cose diventano più complicate.
Quando spostiamo una future, sia mettendola in una struttura dati da
utilizzare come iteratore con join_all o restituendola da una funzione,
significa effettivamente spostare la macchina a stati che Rust crea per noi. E a
differenza della maggior parte degli altri type in Rust, le future che Rust
crea per i blocchi async può capitare abbiano riferimenti a se stesse nei
campi di una data variante, come mostrato nell’illustrazione semplificata nella
Figura 17-4.

Figura 17-4: Un tipo di dato auto-referenziale
Per impostazione predefinita, però, qualsiasi oggetto che ha un riferimento a se stesso è insicuro da spostare, perché i riferimenti puntano sempre all’indirizzo di memoria effettivo di ciò a cui si riferiscono (vedi Figura 17-5). Se sposti la struttura dati stessa, quei riferimenti interni rimarranno puntati alla vecchia posizione. Tuttavia, quella posizione di memoria è ora non valida. Per un verso, il suo valore non verrà aggiornato quando apporti modifiche alla struttura dati. Per un altro e più importante motivo, il computer è ora libero di riutilizzare quella memoria per altri scopi! Potresti finire per leggere dati completamente non correlati in seguito.

Figura 17-5: Il risultato non sicuro di spostare un tipo di dato auto-referenziale
Teoricamente, il compilatore Rust potrebbe cercare di aggiornare ogni riferimento a un oggetto ogni volta che viene spostato, ma ciò potrebbe aggiungere un notevole sovraccarico di operazioni impattando le prestazioni, specialmente se un’intera rete di riferimenti deve essere aggiornata. Se potessimo invece assicurarci che la struttura dati in questione non si muova in memoria, non dovremmo aggiornare alcun riferimento. Questo è esattamente a ciò che serve il borrow checker di Rust: nel codice sicuro, impedisce di spostare qualsiasi elemento con un riferimento attivo.
Pin si basa su questo per darci la garanzia esatta di cui abbiamo bisogno.
Quando fissiamo un valore incapsulando un puntatore a quel valore in Pin,
non può più muoversi. Quindi, se hai Pin<Box<QualcheType>>, in realtà fissi il
valore QualcheType, non il puntatore Box. La Figura 17-6 illustra questo
processo.

Figura 17-6: Pinning di una Box che punta a un type
future auto-referenziale
In effetti, il puntatore Box può ancora muoversi liberamente. Ricorda: ci
interessa assicurarci che i dati a cui si fa riferimento rimangano al loro
posto. Se un puntatore si muove, ma i dati a cui punta sono nello stesso
posto, come nella Figura 17-7, non c’è alcun problema potenziale. (Come
esercizio indipendente, dai un’occhiata alla documentazione per i type così
come a quella del modulo std::pin e prova a capire come faresti questo con un
Pin che incapsula una Box.) La chiave è che il type auto-referenziale
stesso non può muoversi, perché è ancora fissato.

Figura 17-7: Spostare una Box che punta a un type
future auto-referenziale
Tuttavia, la maggior parte dei type è perfettamente sicura da spostare, anche
se sono incapsulati da Pin. Dobbiamo pensare al pinning solo quando gli
elementi hanno reference interni. I valori primitivi come numeri e booleani
sono sicuri perché ovviamente non hanno reference interni. Né la maggior parte
dei type con cui normalmente lavori in Rust. Puoi spostare un Vec, ad
esempio, senza preoccuparti. Dato ciò che abbiamo visto finora, se hai un
Pin<Vec<String>>, dovresti fare tutto tramite le API sicure ma restrittive
fornite da Pin, anche se un Vec<String> è sempre sicuro da spostare se non
ci sono altri riferimenti ad esso. Abbiamo bisogno di un modo per dire al
compilatore che va bene spostare gli elementi in casi come questo, ed è qui che
entra in gioco Unpin.
Unpin è un trait marcatore, simile ai trait Send e Sync che abbiamo
visto nel Capitolo 16, e quindi non ha funzionalità propria. I trait marcatori
esistono solo per dire al compilatore che è sicuro utilizzare il type che
implementa un dato trait in un contesto particolare. Unpin informa il
compilatore che un dato type non ha bisogno di verificare alcuna garanzia
sul fatto che il valore in questione possa essere spostato in sicurezza.
Proprio come per Send e Sync, il compilatore implementa automaticamente
Unpin per tutti i type per i quali può dimostrare che è sicuro. Un caso
speciale, di nuovo simile a Send e Sync, è dove Unpin non è implementato
per un type. La notazione per questo è impl !Unpin for
QualcheType, dove QualcheType è il nome di
un type che deve mantenere quelle garanzie per essere sicuro ogni volta che
un puntatore a quel type viene utilizzato in un Pin.
In altre parole, ci sono due cose da tenere a mente riguardo alla relazione tra
Pin e Unpin. Prima di tutto, Unpin è il caso “normale”, e !Unpin è il
caso speciale. In secondo luogo, se un type implementa Unpin o !Unpin
importa solo quando stai usando un puntatore fissato a quel type come
Pin<&mut QualcheType>.
Per andare nel concreto, pensa a una String: ha una lunghezza e i caratteri
Unicode che la compongono. Possiamo incapsulare una String in Pin, come
vedi nella Figura 17-8. Tuttavia, String implementa automaticamente Unpin,
così come la maggior parte degli altri type in Rust.

Figura 17-8: Pinning di una String; la linea
tratteggiata indica che la String implementa il trait Unpin e quindi non è
fissata
Di conseguenza, possiamo fare cose che sarebbero illegali se String
implementasse !Unpin, come sostituire una stringa con un’altra nella stessa
posizione in memoria, come nella Figura 17-9. Questo non viola il contratto di
Pin, perché String non ha riferimenti interni che la rendano insicura da
spostare. È proprio per questo che implementa Unpin piuttosto che !Unpin.

Figura 17-9: Sostituzione della String con un’altra
String completamente diversa in memoria
Ora sappiamo abbastanza per comprendere gli errori segnalati per quella chiamata
a join_all dal Listato 17-23. Inizialmente abbiamo cercato di spostare le
future prodotte dai blocchi async in un Vec<Box<dyn Future<Output = ()>>>,
ma come abbiamo visto, quelle future possono avere riferimenti interni, quindi
non implementano automaticamente Unpin. Una volta fissate, poi possiamo
passare il risultante type Pin nel Vec, certi che i dati sottostanti nelle
future non verranno spostati. Il Listato 17-24 mostra come sistemare il
codice chiamando la macro pin! dove ognuna delle tre future è definita e
sistemare il type dell’oggetto trait.
extern crate trpl; // necessario per test mdbook use std::pin::{Pin, pin}; // --taglio-- use std::time::Duration; fn main() { trpl::block_on(async { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = pin!(async move { // --taglio-- let valori = vec![ String::from("ciao"), String::from("dalla"), String::from("future"), String::from("!!!"), ]; for val in valori { tx1.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }); let rx_fut = pin!(async { // --taglio-- while let Some(valore) = rx.recv().await { println!("ricevuto '{valore}'"); } }); let tx_fut = pin!(async move { // --taglio-- let valori = vec![ String::from("altri"), String::from("messaggi"), String::from("per"), String::from("te"), ]; for val in valori { tx.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }); let future: Vec<Pin<&mut dyn Future<Output = ()>>> = vec![tx1_fut, rx_fut, tx_fut]; trpl::join_all(future).await; }); }
pin! per consentire alle future di essere spostate nel vettoreQuesto esempio ora si compila ed esegue, e possiamo aggiungere o togliere future dal vettore durante l’esecuzione aspettandole tutte.
Pin e Unpin sono principalmente importanti per costruire librerie di basso
livello, o quando stai costruendo un vero e proprio runtime, piuttosto che per
il codice Rust quotidiano. Tuttavia, quando vedi questo trait nei messaggi di
errore, ora avrai un’idea migliore di come correggere il tuo codice!
Nota: Questa combinazione di
PineUnpinrende possibile implementare in modo sicuro un’intera classe di type complessi in Rust che altrimenti risulterebbero difficili a causa della loro auto-referenzialità. I type che richiedonoPinsi presentano più comunemente nella programmazione asincrona di Rust, ma di tanto in tanto potresti vederli anche in altri contesti.I dettagli specifici su come funzionano
PineUnpin, e le regole che devono rispettare, sono trattati ampiamente nella documentazione API perstd::pin, quindi se sei interessato a saperne di più, quello è un ottimo punto di partenza.Se vuoi capire come funzionano le cose sotto il cofano in modo ancora più dettagliato, consulta i capitoli su gestione dell’esecuzione e pinning di Asynchronous Programming in Rust.
Il Trait Stream
Ora che hai una comprensione più profonda dei trait Future e Unpin,
possiamo rivolgere la nostra attenzione al trait Stream. Come hai appreso in
precedenza nel capitolo, gli stream sono simili agli iteratori asincroni. A
differenza di Iterator e Future, tuttavia, Stream non ha una definizione
nella libreria standard al momento della scrittura, ma c’è una definizione
molto comune dal crate futures utilizzata in tutto l’ecosistema.
Rivediamo le definizioni dei trait Iterator e Future prima di vedere come
un trait Stream potrebbe unirne le caratteristiche. Da Iterator, abbiamo
l’idea di una sequenza: il suo metodo next fornisce un Option<Self::Item>.
Da Future, abbiamo l’idea di prontezza nel tempo: il suo metodo poll
fornisce un Poll<Self::Output>. Per rappresentare una sequenza di elementi che
diventano pronti nel tempo, definiamo un trait Stream che mette insieme
queste caratteristiche:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; } }
Il trait Stream definisce un type associato chiamato Item per il type
degli elementi prodotti dallo stream. Questo è simile a Iterator, dove
possono esserci da zero a molti elementi, e diverso da Future, dove c’è sempre
un singolo Output, anche se è il type unitario ().
Stream definisce anche un metodo per ottenere quegli elementi. Lo chiamiamo
poll_next, per chiarire che interroga nello stesso modo in cui fa
Future::poll e produce una sequenza di elementi nello stesso modo in cui fa
Iterator::next. Il suo type di ritorno combina Poll con Option. Il
type esterno è Poll, perché deve essere controllato per prontezza, proprio
come una future. Il type interno è Option, perché deve segnalare se ci
sono altri messaggi, proprio come fa un iteratore.
Qualcosa di molto simile a questa definizione diverrà probabilmente parte della libreria standard di Rust in futuro. Nel frattempo, fa parte dell’arsenale della maggior parte dei runtime, quindi puoi fare affidamento su di essa, e tutto ciò che copriremo successivamente dovrebbe generalmente applicarsi!
Nell’esempio che abbiamo visto nella sezione “Stream: Future in
Sequenza”, però, non abbiamo usato poll_next o
Stream, ma invece abbiamo usato next e StreamExt. Potremmo lavorare
direttamente in termini dell’API poll_next scrivendo a mano le nostre macchine
a stati Stream, ovviamente, proprio come potremmo lavorare con le future
direttamente tramite il loro metodo poll. Tuttavia, usare await è molto più
piacevole, e il trait StreamExt fornisce il metodo next in modo da poter
fare proprio questo:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Option<Self::Item>>; } trait StreamExt: Stream { async fn next(&mut self) -> Option<Self::Item> where Self: Unpin; // altri metodi... } }
Nota: La definizione effettiva che abbiamo utilizzato in precedenza nel capitolo appare leggermente diversa da questa, perché supporta versioni di Rust che non supportavano ancora l’uso di funzioni async nei trait. Di conseguenza, appare in questo modo:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;Quel type
Nextè unastructche implementaFuturee ci consente di nominare la lifetime del reference aselfconNext<'_, Self>, in modo cheawaitpossa funzionare con questo metodo.
Il trait StreamExt è anche la casa di tutti i metodi interessanti
disponibili per l’uso con gli stream. StreamExt è implementato
automaticamente per ogni type che implementa Stream, ma questi trait sono
definiti separatamente per consentire alla comunità di aggiungere API extra
senza influenzare il trait fondamentale.
Nella versione di StreamExt utilizzata nel crate trpl, il trait non solo
definisce il metodo next, ma fornisce anche un’implementazione predefinita di
next che gestisce correttamente i dettagli della chiamata a
Stream::poll_next. Questo significa che anche quando hai bisogno di scrivere
il tuo type di stream, devi solo implementare Stream, e poi chiunque
utilizzi il tuo type può utilizzare StreamExt e i suoi metodi con esso
automaticamente.
Questo è tutto ciò che tratteremo per i dettagli di basso livello su questi trait. Per concludere, vedremo come future (inclusi gli stream), task e thread si integrano tutti insieme!
Future, Task e Thread
Come abbiamo visto nel Capitolo 16, i thread offrono un approccio alla concorrenza. Abbiamo visto un altro approccio in questo capitolo: utilizzare async con future e stream. Se ti stai chiedendo quando scegliere un metodo rispetto all’altro, la risposta è: dipende! E in molti casi, la scelta non è tra thread o async, ma piuttosto tra thread e async.
Molti sistemi operativi hanno fornito modelli di concorrenza basati su thread per decenni, e molti linguaggi di programmazione di conseguenza li supportano. Tuttavia, questi modelli non sono privi di compromessi. Su molti sistemi operativi, utilizzano una buona quantità di memoria per ogni thread. I thread sono anche un’opzione solo quando il tuo sistema operativo e hardware li supportano. A differenza dei computer desktop e smartphone moderni, alcuni sistemi embedded non hanno affatto un OS, quindi non hanno nemmeno thread.
Il modello async fornisce un insieme di compromessi diverso, e alla fine
complementare. Nel modello async, le operazioni concorrenti non richiedono i
propri thread. Invece, possono essere eseguite su task, come quando abbiamo
utilizzato trpl::spawn_task per avviare un lavoro da una funzione sincrona
nella sezione degli stream. Un task è simile a un thread, ma invece di
essere gestito dal sistema operativo, è gestito da codice a livello di libreria:
il runtime.
C’è un motivo per cui le API per generare thread e task sono così simili. I thread agiscono come un confine per insiemi di operazioni sincrone; la concorrenza è possibile tra i thread. I task agiscono come un confine per insiemi di operazioni asincrone; la concorrenza è possibile sia tra che all’interno dei task, perché un task può passare tra future nel suo corpo. Infine, le future sono l’unità di concorrenza più granulare di Rust, e ogni future può rappresentare un albero di altre future. Il runtime, e nello specifico il suo esecutore, gestisce i task, e i task gestiscono le future. In questo senso, i task sono simili a thread leggeri gestiti dal runtime con capacità aggiuntive che derivano dal fatto di essere gestiti da un runtime anziché dal sistema operativo.
Questo non significa che i task async siano sempre migliori dei thread (o
viceversa). La concorrenza con i thread è in alcuni modi un modello di
programmazione più semplice rispetto alla concorrenza con async. Questo può
essere un punto di forza o una debolezza. I thread sono in un certo senso
“esegui e dimenticatene”; non hanno un equivalente nativo a una future, quindi
semplicemente eseguono fino al completamento senza essere interrotti, tranne che
dal sistema operativo stesso.
E se non bastasse, i thread e i task spesso funzionano molto bene insieme,
perché i task possono (almeno in alcuni runtime) essere spostati tra i
thread. Infatti, dietro le quinte, il runtime che abbiamo utilizzato,
comprese le funzioni spawn_blocking e spawn_task, è multi-thread per
impostazione predefinita! Molti runtime utilizzano un approccio chiamato work
stealing per spostare in modo trasparente i task tra i thread, in base a
come i thread vengono attualmente utilizzati, per migliorare le prestazioni
complessive del sistema. Questo approccio richiede effettivamente sia thread
che task, e quindi future.
Quando si pensa a quale metodo utilizzare, considera queste regole pratiche:
- Se il lavoro è molto parallelizzabile (limitato dalla potenza di calcolo), come l’elaborazione di un insieme di dati in cui ogni parte può essere elaborata separatamente, i thread sono una scelta migliore.
- Se il lavoro è molto concorrente (limitato da I/O), come gestire messaggi provenienti da diverse fonti che possono arrivare a intervalli o velocità diversi, async è una scelta migliore.
E se hai bisogno sia di parallelismo che di concorrenza, non devi scegliere tra thread e async. Puoi usarli insieme liberamente, lasciando a ciascuno il compito che svolge meglio. Ad esempio, il Listato 17-42 mostra un esempio piuttosto comune di questo tipo di mix nel codice Rust reale.
extern crate trpl; // necessario per test mdbook use std::{thread, time::Duration}; fn main() { let (tx, mut rx) = trpl::channel(); thread::spawn(move || { for i in 1..11 { tx.send(i).unwrap(); thread::sleep(Duration::from_secs(1)); } }); trpl::block_on(async { while let Some(messaggio) = rx.recv().await { println!("{messaggio}"); } }); }
Iniziamo creando un canale async, quindi avviamo un thread che prende
possesso dell’estremità del mittente del canale usando la parola chiave move.
All’interno del thread, inviamo i numeri da 1 a 10, dormendo per un secondo
tra ciascuno. Infine, eseguiamo una future creata con un blocco async
passato a trpl::block_on, proprio come abbiamo fatto in tutto il capitolo. In
quella future, attendiamo quei messaggi, proprio come negli altri esempi di
invio messaggi che abbiamo visto.
Per tornare allo scenario con cui abbiamo aperto il capitolo, immagina di eseguire un insieme di task di codifica video utilizzando un thread dedicato (perché la codifica video è vincolata al calcolo) ma notificando l’interfaccia utente che quelle operazioni sono terminate con un canale async. Ci sono innumerevoli esempi di queste combinazioni in casi d’uso reali.
Riepilogo
Questa non è l’ultima volta che vedrai la concorrenza in questo libro. Il progetto nel Capitolo 21 applicherà questi concetti in una situazione più realistica rispetto agli esempi più semplici discussi qui e confronterà la risoluzione dei problemi con i thread rispetto ai task e future in modo più diretto.
Indipendentemente da quale di questi approcci scegli, Rust ti offre gli strumenti necessari per scrivere codice concorrente sicuro e veloce, sia per un server web ad alta capacità che per un sistema operativo embedded.
Nel prossimo capitolo, parleremo di modi idiomatici per modellare problemi e strutturare soluzioni man mano che i tuoi programmi Rust crescono. Inoltre, discuteremo di come gli idiomi di Rust si relazionano a quelli con cui potresti avere familiarità provenienti dalla programmazione orientata agli oggetti.
Funzionalità della Programmazione Orientata agli Oggetti
La programmazione orientata agli oggetti (OOP) è un modo per modellare i programmi. Il concetto di oggetti è stato introdotto negli anni ’60 nel linguaggio Simula. Quegli oggetti hanno influenzato l’architettura di Alan Kay, dove gli oggetti si scambiano messaggi tra loro. Per descrivere questa architettura, lui ha coniato il termine programmazione orientata agli oggetti nel 1967. Ci sono un sacco di definizioni diverse su cosa sia esattamente la OOP, e secondo alcune Rust è orientato agli oggetti, secondo altre no. In questo capitolo vedremo alcune caratteristiche che di solito si considerano tipiche della programmazione orientata agli oggetti e come queste si traducono in Rust in modo naturale. Poi ti mostreremo come implementare un modello di design orientato agli oggetti in Rust e discuteremo i pro e i contro rispetto a soluzioni che sfruttano i punti di forza di Rust in altri modi.
Caratteristiche dei Linguaggi Orientati agli Oggetti
Non c’è consenso nella comunità di programmatori su quali caratteristiche un linguaggio deve avere per essere considerato orientato agli oggetti. Rust è influenzato da molti paradigmi di programmazione, inclusa la OOP; per esempio, abbiamo esplorato le caratteristiche provenienti dalla programmazione funzionale nel Capitolo 13. Si può dire che i linguaggi OOP condividano certe caratteristiche comuni, come oggetti, incapsulamento ed ereditarietà. Vediamo cosa significa ognuna di queste caratteristiche e se Rust le supporta.
Gli Oggetti Contengono Dati e Comportamenti
Il libro Design Patterns: Elements of Reusable Object-Oriented Software di Erich Gamma, Richard Helm, Ralph Johnson e John Vlissides (Addison-Wesley, 1994) (traduzione in italiano pubblicata da Pearson, 2002), noto come il libro della Gang of Four (Banda dei quattro), è un catalogo di modelli di progettazione orientati agli oggetti. Definisce la OOP in questo modo:
I programmi orientati agli oggetti sono composti da oggetti. Un oggetto raggruppa sia i dati sia le procedure che operano su quei dati. Le procedure sono tipicamente chiamate metodi o operazioni.
Secondo questa definizione, Rust è orientato agli oggetti: struct ed enum
contengono dati, e i blocchi impl forniscono metodi su struct ed enum.
Anche se struct ed enum con metodi non sono chiamati oggetti, forniscono
la stessa funzionalità, secondo la definizione della Gang of Four.
Incapsulamento che Nasconde i Dettagli di Implementazione
Un altro aspetto comunemente associato alla OOP è l’idea di incapsulamento, che significa che i dettagli di implementazione di un oggetto non sono accessibili al codice che usa quell’oggetto. Quindi, l’unico modo per interagire con un oggetto è attraverso la sua API pubblica; il codice che usa l’oggetto non dovrebbe poter modificare direttamente i dati o il comportamento interni. Questo permette al programmatore di cambiare e ristrutturare l’implementazione interna di un oggetto senza dover modificare il codice che usa l’oggetto.
Abbiamo visto come controllare l’incapsulamento nel Capitolo 7: possiamo usare
la parola chiave pub per decidere quali moduli, type, funzioni e metodi del
nostro codice devono essere pubblici e, di default, tutto il resto è privato.
Per esempio, possiamo definire una struct CollezioneConMedia che ha un campo
contenente un vettore di valori i32. La struct può avere anche un campo che
contiene la media dei valori nel vettore, quindi la media non deve essere
calcolata ogni volta che serve. In altre parole, CollezioneConMedia tiene
memorizzata la media calcolata di volta in volta al posto nostro. Il Listato
18-1 mostra la definizione della struct CollezioneConMedia.
pub struct CollezioneConMedia {
lista: Vec<i32>,
media: f64,
}CollezioneConMedia che mantiene una lista di interi e la media degli elementi nella collezioneLa struct è marcata pub così il resto del codice può usarla, ma i campi
interni restano privati. Questo è importante perché vogliamo assicurarci che
ogni volta che un valore viene aggiunto o rimosso dalla lista, anche la media
venga aggiornata. Lo facciamo implementando i metodi aggiungi, rimuovi e
media sulla struct, come nel Listato 18-2.
pub struct CollezioneConMedia {
lista: Vec<i32>,
media: f64,
}
impl CollezioneConMedia {
pub fn aggiungi(&mut self, valore: i32) {
self.lista.push(valore);
self.aggiorna_media();
}
pub fn rimuovi(&mut self) -> Option<i32> {
let risultato = self.lista.pop();
match risultato {
Some(valore) => {
self.aggiorna_media();
Some(valore)
}
None => None,
}
}
pub fn media(&self) -> f64 {
self.media
}
fn aggiorna_media(&mut self) {
let totale: i32 = self.lista.iter().sum();
self.media = totale as f64 / self.lista.len() as f64;
}
}aggiungi, rimuovi e media su CollezioneConMediaI metodi pubblici aggiungi, rimuovi e media sono gli unici modi con cui
accedere o modificare i dati in un’istanza di CollezioneConMedia. Quando si
aggiunge un elemento alla lista usando aggiungi o si rimuove con rimuovi,
questi metodi chiamano il metodo privato aggiorna_media che si occupa di
aggiornare il campo media.
Lasciamo i campi lista e media privati, in questo modo il codice esterno non
può aggiungere o rimuovere elementi direttamente dalla lista; altrimenti, il
campo media potrebbe diventare non più corrispondente a quello che rappresenta
rispetto alla lista. Il metodo media restituisce il valore nel campo media,
permettendo al codice esterno di leggere la media ma non di modificarla.
Poiché abbiamo incapsulato i dettagli dell’implementazione della struct
CollezioneConMedia, possiamo cambiare facilmente aspetti come la struttura
dati in futuro. Per esempio, potremmo usare un HashSet<i32> al posto di un
Vec<i32> per il campo lista. Finché le firme dei metodi pubblici aggiungi,
rimuovi e media rimangono uguali, il codice esterno che usa
CollezioneConMedia non deve cambiare. Se invece avessimo reso lista
pubblico, non sarebbe così: HashSet<i32> e Vec<i32> hanno metodi diversi per
aggiungere e rimuovere elementi, quindi il codice esterno dovrebbe cambiare se
modificasse la lista direttamente.
Se l’incapsulamento è un requisito necessario per considerare un linguaggio
orientato agli oggetti, allora Rust lo soddisfa. La possibilità di usare o meno
pub per parti diverse del codice abilita l’incapsulamento dei dettagli di
implementazione.
Ereditarietà come Sistema dei Type e come Condivisione di Codice
L’ereditarietà è un meccanismo per cui un oggetto può ereditare elementi dalla definizione di un altro oggetto, ottenendo i dati e i comportamenti dell’oggetto genitore senza doverli ridefinire.
Se un linguaggio deve avere l’ereditarietà per essere orientato agli oggetti, allora Rust non lo è. Non c’è modo di definire una struct che erediti i campi e i metodi del genitore senza usare una macro.
Tuttavia, se sei abituato a usare l’ereditarietà, puoi usare in Rust altre soluzioni a seconda del motivo per cui la vorresti usare.
Le due ragioni principali per scegliere l’ereditarietà sono: il riuso del codice e il sistema dei type.
Per il riuso del codice, puoi implementare un comportamento particolare per un
type e l’ereditarietà ti consente di riusarlo per un altro type. In Rust
puoi farlo in modo limitato con le implementazioni dei metodi default dei
trait, come nel Listato 10-14 quando abbiamo dato una implementazione di
default al metodo riassunto sul trait Sommario. Qualsiasi type che
implementa Sommario avrà il metodo riassunto senza dover scrivere ulteriore
codice. Questo è simile a una classe genitore che ha un’implementazione di un
metodo e una classe figlia che eredita quella implementazione. Possiamo anche
sovrascrivere l’implementazione di default di riassunto quando implementiamo
il trait Sommario, simile a una classe figlia che modifica un metodo
ereditato.
L’altra ragione per usare l’ereditarietà riguarda il sistema dei type: permettere a un type figlio di essere usato nei posti in cui si usa il type genitore. Questo si chiama anche polimorfismo, che significa poter sostituire oggetti diversi durante l’esecuzione se hanno certe caratteristiche in comune.
Polimorfismo
Per molti, polimorfismo è sinonimo di ereditarietà. Ma in realtà è un concetto più generale che si riferisce a codice in grado di lavorare con dati di tipi diversi. Per l’ereditarietà, questi tipi sono solitamente sottoclassi.
Rust invece usa i generici per astrarre su type diversi e i vincoli di trait per imporre cosa questi type devono fornire. Questo viene solitamente chiamato polimorfismo parametrico vincolato.
Rust ha scelto un set di compromessi diverso non offrendo ereditarietà. L’ereditarietà spesso condivide più codice del necessario. Le sottoclassi non dovrebbero sempre condividere tutte le caratteristiche della classe genitore, ma con l’ereditarietà lo fanno, il che può rendere il design del programma meno flessibile. Può anche introdurre la possibilità di chiamare metodi su sottoclassi che non hanno senso o causano errori perché quei metodi non si applicano. Inoltre, alcuni linguaggi permettono solo l’ereditarietà singola (cioè una sottoclasse può ereditare da una sola classe genitore), limitando ulteriormente la flessibilità nel design.
Per questi motivi, Rust usa un approccio diverso basato sugli oggetti trait invece dell’ereditarietà per ottenere il polimorfismo durante l’esecuzione. Vediamo come funzionano gli oggetti trait.
Usare gli Oggetti Trait per Astrarre Comportamenti Condivisi
Nel Capitolo 8, abbiamo detto che un limite dei vettori è che possono contenere
elementi di un solo type. Abbiamo trovato una soluzione nel Listato 8-9
definendo una enum CellaFoglioDiCalcolo che aveva varianti per interi, float
e testo. Questo ci permetteva di mettere type diversi in ogni cella e comunque
avere un vettore che rappresentava una riga di celle. Questa è una soluzione
perfetta quando gli elementi intercambiabili sono un insieme fisso di type
noti a tempo di compilazione.
Però a volte vogliamo che chi usa la nostra libreria possa estendere l’insieme
di type validi in una situazione. Per mostrare come farlo, creeremo un esempio
di interfaccia grafica (GUI) che scorre una lista di elementi, chiamando per
ognuno un metodo disegna per disegnarlo a schermo, una tecnica comune negli
strumenti GUI. Creeremo un crate libreria chiamato gui che contiene la
struttura base di una libreria GUI. Questo crate includerà type da usare,
come Bottone o CampoTesto. Inoltre, gli utenti della libreria vorranno
creare i propri type disegnabili: per esempio, uno aggiungerà un Immagine e
un altro una BoxSelezione.
Quando scriviamo la libreria, non possiamo sapere e definire tutti i type che
altri programmatori potrebbero voler creare. Ma sappiamo che gui deve tenere
traccia di molti valori di type diversi e deve chiamare un metodo disegna su
ognuno di questi valori. Non deve sapere esattamente cosa succede quando chiama
disegna, solo che quel metodo è disponibile.
In un linguaggio con ereditarietà, potremmo definire una classe Componente con
un metodo disegna. Le altre classi, come Bottone, Immagine e
BoxSelezione, erediterebbero da Componente e quindi avrebbero il metodo
disegna. Ognuno potrebbe sovrascriverlo per comportamenti personalizzati, ma
il framework tratterebbe tutti i type come istanze di Componente e chiamare
disegna. Ma dato che Rust non ha ereditarietà, serve un altro modo per
strutturare gui permettendo agli utenti di creare nuovi type compatibili con
la libreria.
Definire un Trait per un Comportamento Comune
Per implementare il comportamento che vogliamo in gui, definiamo un trait
chiamato Disegna con un metodo disegna. Poi definiamo un vettore che
contiene oggetti trait. Un oggetto trait punta sia a un’istanza di un type
che implementa il trait, sia a una tabella usata per cercare durante
l’esecuzione i metodi trait su quel type. Creiamo un oggetto trait
specificando un puntatore, come un reference & o uno puntatore intelligente
Box<T>, poi la parola chiave dyn e infine specifichiamo il trait
rilevante. (Parleremo del motivo per cui gli oggetti trait devono usare un
puntatore nella sezione “Type a Dimensione Dinamica e il Trait
Sized” del Capitolo 20.) Possiamo usare
oggetti trait al posto di type generici o concreti. Ovunque usiamo un
oggetto trait, il sistema dei type di Rust garantisce durante la
compilazione che ogni valore in quel contesto implementi il trait dell’oggetto
trait, quindi non serve conoscere tutti i type possibili al momento della
compilazione.
Abbiamo detto che in Rust evitiamo di chiamare “oggetti” struct ed enum per
distinguerli dagli oggetti di altri linguaggi. In una struct o enum, dati e
comportamento in blocchi impl sono separati, mentre in altri linguaggi dati e
comportamento uniti formano un oggetto. E quindi gli oggetti trait sono in
qualche modo simili agli oggetti in altri linguaggi nel senso che combinano dati
e comportamento. Ma gli oggetti trait differiscono dalla tradizionale
definizione di oggetto in altri linguaggi perché non possono contenere dati. Gli
oggetti trait non hanno la completezza che si trova in altri linguaggi:
servono specificamente solo per astrarre comportamenti comuni.
Il Listato 18-3 mostra come definire un trait Disegna con un metodo
disegna.
pub trait Disegna {
fn disegna(&self);
}DisegnaLa sintassi dovrebbe essere familiare dalle discussioni sui trait nel Capitolo
10. Poi, nel Listato 18-4, definiamo una struct Schermo che contiene un
vettore componenti. Questo vettore è di type Box<dyn Disegna>, che è un
oggetto trait; è un contenitore per qualunque type in una Box che
implementi il trait Disegna.
pub trait Disegna {
fn disegna(&self);
}
pub struct Schermo {
pub componenti: Vec<Box<dyn Disegna>>,
}Schermo con una campo componenti contenente un vettore di oggetti trait che implementano DisegnaDefiniamo un metodo esegui su Schermo che chiama disegna su ogni elemento
di componenti, come nel Listato 18-5.
pub trait Disegna {
fn disegna(&self);
}
pub struct Schermo {
pub componenti: Vec<Box<dyn Disegna>>,
}
impl Schermo {
pub fn esegui(&self) {
for componente in self.componenti.iter() {
componente.disegna();
}
}
}esegui in Schermo che chiama disegna per ogni componenteQuesto funziona diversamente da una struct con un parametro di type generico
con vincoli di trait. Un type generico può essere sostituito da un solo
type concreto alla volta, mentre gli oggetti trait permettono a più type
concreti di poter essere usati per quel ruolo durante l’esecuzione. Per esempio,
potremmo aver definito la struct Schermo con un type generico e un vincolo
di trait, come nel Listato 18-6.
pub trait Disegna {
fn disegna(&self);
}
pub struct Schermo<T: Disegna> {
pub componenti: Vec<T>,
}
impl<T> Screen<T>
where
T: Disegna,
{
pub fn esegui(&self) {
for componente in self.componenti.iter() {
componente.disegna();
}
}
}Schermo e del metodo esegui usando type generici e vincoli di traitQuesto limita a istanze di Schermo con una lista di componenti tutte dello
stesso type, per esempio tutti Bottone o tutti CampoTesto. Se si hanno
solo collezioni omogenee, usare generici è preferibile perché il codice sarà
monomorfizzato durante la compilazione usando i type concreti.
Con gli oggetti trait, invece, una singola istanza di Schermo può contenere
un Vec<T> con una Box<Bottone> e una Box<CampoTesto> insieme. Vediamo come
funziona e poi parleremo delle implicazioni sulle prestazioni durante
l’esecuzione.
Implementare il Trait
Ora aggiungiamo type che implementano il trait Disegna. Aggiungiamo un
type Bottone. Scrivere una vera e propria libreria GUI va oltre lo scopo
del libro, quindi il metodo disegna in non contiene nulla di utile nel corpo.
Per farsi un’idea di una possibile implementazione, un Bottone potrebbe avere
campi larghezza, altezza e etichetta, come nel Listato 18-7.
pub trait Disegna {
fn disegna(&self);
}
pub struct Schermo {
pub componenti: Vec<Box<dyn Disegna>>,
}
impl Schermo {
pub fn esegui(&self) {
for componente in self.componenti.iter() {
componente.disegna();
}
}
}
pub struct Bottone {
pub larghezza: u32,
pub altezza: u32,
pub etichetta: String,
}
impl Disegna for Bottone {
fn disegna(&self) {
// codice per disegnare il bottone
}
}Bottone che implementa il trait DisegnaI campi larghezza, altezza e etichetta su Bottone sono diversi dagli
altri componenti; per esempio, un type CampoTesto potrebbe avere gli stessi
campi più un campo temporaneo. Ogni type che vogliamo disegnare implementerà
il trait Disegna usando codice diverso in disegna per definire come
disegnarsi, come fa Bottone (senza codice GUI reale). Bottone potrebbe
anche avere altri metodi nel suo blocco impl, ad esempio per gestire cosa
succede al click, metodi che non si applicano a type come CampoTesto.
Se qualcuno che usa la libreria definisce una BoxSelezione con campi
larghezza, altezza e opzioni, implementerà il trait Disegna anche su
BoxSelezione, come nel Listato 18-8.
use gui::Disegna;
struct BoxSelezione {
larghezza: u32,
altezza: u32,
opzioni: Vec<String>,
}
impl Disegna for BoxSelezione {
fn disegna(&self) {
// codice per disegnare il box di selezione
}
}
fn main() {}gui e implementa Disegna su BoxSelezioneChi userà la nostra libreria può quindi scrivere la funzione main creando
un’istanza di Schermo. All’istanza di Schermo aggiunge una BoxSelezione e
un Bottone mettendoli in Box<T>, facendoli diventare oggetti trait. Poi
chiama esegui sull’istanza di Schermo, che a sua volta chiama disegna su
ogni componente. Il Listato 18-9 mostra l’implementazione:
use gui::Disegna;
struct BoxSelezione {
larghezza: u32,
altezza: u32,
opzioni: Vec<String>,
}
impl Disegna for BoxSelezione {
fn disegna(&self) {
// code to actually draw a select box
}
}
use gui::{Bottone, Schermo};
fn main() {
let schermo = Schermo {
componenti: vec![
Box::new(BoxSelezione {
larghezza: 75,
altezza: 10,
opzioni: vec![
String::from("Sì"),
String::from("Forse"),
String::from("No"),
],
}),
Box::new(Bottone {
larghezza: 50,
altezza: 10,
etichetta: String::from("OK"),
}),
],
};
schermo.esegui();
}Quando scriviamo la libreria, non sapevamo che qualcuno avrebbe aggiunto
BoxSelezione, ma l’implementazione di Schermo funziona comunque con quel
type perché BoxSelezione implementa il trait Disegna che quindi ha il
metodo disegna.
Questo concetto, preoccuparsi solo dei messaggi a cui un valore risponde invece
che del type concreto, somiglia al duck typing (tipizzazione ad anatra)
nei linguaggi a tipizzazione dinamica: se cammina come un’anatra e fa “qua
qua”, allora è un’anatra! Nel metodo esegui di Schermo nel Listato 18-5,
esegui non sa di che type concreto è ogni componente, non controlla se è
un’istanza di Bottone o BoxSelezione, chiama semplicemente disegna sul
componente. Specificando Box<dyn Disegna> come type dei valori nel vettore
componenti, abbiamo definito Schermo per accettare solo valori su cui si può
chiamare disegna.
Il vantaggio di usare oggetti trait e il sistema dei type di Rust per scrivere codice simile a quello con duck typing è che non dobbiamo mai controllare durante l’esecuzione se un valore implementa un metodo o temere errori se non l’implementa ma lo chiamiamo comunque. Rust non compila il codice se i valori non implementano i trait richiesti dagli oggetti trait.
Per esempio, il Listato 18-10 mostra cosa succede se proviamo a creare uno
Schermo con una String come componente.
use gui::Schermo;
fn main() {
let schermo = Schermo {
componenti: vec![Box::new(String::from("Ciao"))],
};
schermo.esegui();
}Avremo questo errore perché String non implementa il trait Disegna:
$ cargo run
Compiling gui v0.1.0 (file:///progetti/gui)
error[E0277]: the trait bound `String: Disegna` is not satisfied
--> src/main.rs:5:26
|
5 | componenti: vec![Box::new(String::from("Ciao"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Disegna` is not implemented for `String`
|
= help: the trait `Disegna` is implemented for `Bottone`
= note: required for the cast from `Box<String>` to `Box<dyn Disegna>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
L’errore ci dice che o stiamo passando a Schermo qualcosa che non volevamo,
oppure dobbiamo implementare Disegna su String per permettere che Schermo
chiami disegna anche su quel type.
Eseguire il Dynamic Dispatch
Come detto nella sezione “Prestazioni del Codice utilizzando Type Generici” del Capitolo 10 sulla monomorfizzazione eseguita dal compilatore per i type generici: il compilatore genera implementazioni non generiche di funzioni e metodi per ogni type concreto usato al posto del type generico. Il codice che risulta dalla monomorfizzazione usa static dispatch, durante la compilazione il compilatore conosce quale metodo stai chiamando. Questo è all’opposto del dynamic dispatch, dove il compilatore non può sapere durante la compilazione quale metodo stai chiamando. Nel caso di dynamic dispatch, il compilatore genera codice che solo durante l’esecuzione saprà quale metodo chiamare.
Quando usiamo oggetti trait, Rust deve usare il dynamic dispatch. Il compilatore non conosce tutti i type che possono essere usati con il codice che usa oggetti trait, quindi non sa quale metodo di quale type chiamare. Durante l’esecuzione, Rust usa i puntatori dentro l’oggetto trait per decidere il metodo da chiamare. Questa ricerca ha un costo prestazionale che non c’è con lo static dispatch. Inoltre, il dynamic dispatch impedisce che il compilatore possa fare alcune ottimizzazioni, e Rust ha regole su dove si può usare dynamic dispatch, chiamate compatibilità dyn. Queste regole esulano da questa discussione, ma puoi leggere di più a riguardo nella documentazione. Però abbiamo guadagnato più flessibilità nel codice del Listato 18-5 e possiamo supportarla come nel Listato 18-9, quindi è un compromesso da considerare.
Implementare un Modello di Design Orientato agli Oggetti
Lo state pattern è un modello di design orientato agli oggetti. Il punto centrale di questo modello è definire un insieme di stati che un valore può avere internamente. Gli stati sono rappresentati da un insieme di oggetti stato, e il comportamento del valore cambia in base allo stato in cui si trova. Vedremo un esempio con una struct di un post del blog che ha un campo per mantenere il suo stato, che può essere uno stato “bozza”, “in revisione” o “pubblicato”.
Gli oggetti stato condividono la funzionalità: in Rust, ovviamente, usiamo struct e trait invece di oggetti e ereditarietà. Ogni oggetto stato è responsabile del proprio comportamento e di decidere quando deve cambiare stato. Il valore che contiene l’oggetto stato non sa nulla del comportamento specifico degli stati o di quando avvengono le transizioni tra stati.
Il vantaggio dello state pattern è che, quando cambiano i requisiti del programma, non serve modificare il codice del valore che contiene lo stato né quello che usa il valore. Basterà aggiornare il codice dentro uno degli oggetti stato per cambiare le regole o aggiungere nuovi stati.
Inizieremo implementando lo state pattern in un modo più tradizionalmente orientato agli oggetti, poi vedremo un approccio più naturale in Rust. Cominciamo implementando passo passo un flusso di lavoro per un post del blog usando lo state pattern.
La funzionalità finale sarà questa:
- Un post inizia come bozza vuota.
- Quando la bozza è pronta, si richiede la revisione del post.
- Quando il post è approvato, viene pubblicato.
- Solo i post pubblicati restituiscono contenuto da stampare, in modo che i post non approvati non possano essere pubblicati accidentalmente.
Qualsiasi altra modifica tentata su un post non avrà effetto. Per esempio, se proviamo ad approvare una bozza prima di richiedere la revisione, il post resterà una bozza non pubblicata.
Tentativo in Tradizionale Stile Orientato agli Oggetti
Ci sono infiniti modi per strutturare il codice per risolvere lo stesso problema, ciascuno con compromessi diversi. Questa implementazione è più in uno stile orientato agli oggetti tradizionale, possibile in Rust, ma che non sfrutta appieno i punti di forza di Rust. Più avanti mostreremo una soluzione diversa che usa comunque lo state pattern ma in modo meno familiare a chi ha esperienza solo con OOP. Confronteremo le due soluzioni per capire i compromessi di progettare in Rust in modo diverso da altri linguaggi.
Il Listato 18-11 mostra questo flusso di lavoro in forma di codice: un esempio
dell’uso dell’API che implementeremo nel crate blog. Ancora non si compila
perché il crate blog non è implementato.
use blog::Post;
fn main() {
let mut post = Post::new();
post.aggiungi_testo("Oggi a pranzo ho mangiato un'instalata");
assert_eq!("", post.contenuto());
post.richiedi_revisione();
assert_eq!("", post.contenuto());
post.approva();
assert_eq!("Oggi a pranzo ho mangiato un'instalata", post.contenuto());
}blogVogliamo permettere all’utente di creare una nuova bozza con Post::new.
Vogliamo permettere di aggiungere testo al post. Se proviamo a richiedere
subito il contenuto del post, prima dell’approvazione, non dobbiamo ricevere
alcun testo perché il post è ancora una bozza. Abbiamo aggiunto assert_eq!
come dimostrazione, che in un test potrebbe verificare che il metodo contenuto
di una bozza restituisca una stringa vuota, ma non scriveremo test in questo
esempio.
Vogliamo poi abilitare la richiesta di revisione, e contenuto deve restituire
una stringa vuota durante l’attesa di revisione. Quando il post riceve
l’approvazione, viene pubblicato e il testo sarà disponibile quando chiamiamo
contenuto.
Nota che l’unico type con cui interagiamo dal crate è Post. Questo type
userà lo state pattern e conterrà un valore che sarà uno tra tre oggetti
stato: bozza, revisione o pubblicato. Il passaggio da uno stato all’altro sarà
gestito internamente da Post. Gli stati cambiano rispondendo ai metodi
chiamati dall’utente sull’istanza di Post, ma l’utente non gestisce
direttamente le transizioni. Inoltre, l’utente non può sbagliare gli stati, per
esempio pubblicando senza revisione.
Definire Post e Creare una Nuova Istanza
Cominciamo l’implementazione della libreria! Sappiamo di aver bisogno di una
struct pubblica Post che tenga un contenuto, quindi partiamo dalla
definizione della struct e da una funzione associata pubblica new per creare
istanze di Post, come mostrato nel Listato 18-12. Creeremo anche un trait
privato Stato che definisce il comportamento che tutti gli oggetti stato per
Post devono avere.
Post terrà un oggetto trait Box<dyn Stato> dentro un Option<T> in un
campo privato chiamato stato per memorizzare l’oggetto stato. Vediamo dopo
perché serve Option<T>.
pub struct Post {
stato: Option<Box<dyn Stato>>,
contenuto: String,
}
impl Post {
pub fn new() -> Post {
Post {
stato: Some(Box::new(Bozza {})),
contenuto: String::new(),
}
}
}
trait Stato {}
struct Bozza {}
impl Stato for Bozza {}Post, con funzione new che crea una nuova istanza di Post, un trait Stato, e una struct BozzaIl trait Stato definisce il comportamento condiviso tra gli stati del
post. Gli oggetti stato sono Bozza, AttesaRevisione e Pubblicato, e
implementeranno tutti il trait Stato. Per ora il trait non ha alcun
metodo; inizieremo definendo Bozza perché è lo stato iniziale del post.
Quando creiamo un nuovo Post, impostiamo il campo stato con Some che
contiene una Box che punta a un’istanza della struct Bozza. Questo
assicura che quando creiamo una nuova istanza di Post, inizia sempre come
bozza. Poiché il campo stato è privato, non si può creare un Post in altri
stati! La funzione Post::new imposta il campo contenuto come una String
vuota.
Memorizzare il Testo del Post
Abbiamo visto nel Listato 18-11 che vogliamo la possibilità di chiamare un
metodo aggiungi_testo che prende un &str e lo aggiunge al contenuto del
post. Lo facciamo come metodo, non esponendo il campo contenuto come pub,
così poi possiamo in seguito implementare un metodo per controllare come leggere
contenuto. Il metodo aggiungi_testo è semplice; lo aggiungiamo nel blocco
impl Post come nel Listato 18-13.
pub struct Post {
stato: Option<Box<dyn Stato>>,
contenuto: String,
}
impl Post {
// --taglio--
pub fn new() -> Post {
Post {
stato: Some(Box::new(Bozza {})),
contenuto: String::new(),
}
}
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
}
trait Stato {}
struct Bozza {}
impl Stato for Bozza {}aggiungi_testo per aggiungere testo al contenuto del postIl metodo aggiungi_testo prende un reference mutabile a self perché stiamo
modificando l’istanza Post su cui chiamiamo il metodo aggiungi_testo.
Chiamiamo poi push_str sulla stringa contenuto aggiungendovi testo. Questo
comportamento non dipende dallo stato in cui si trova il post, quindi non fa
parte dello state pattern. Il metodo aggiungi_testo non interagisce affatto
con il campo stato, ma fa parte del comportamento che vogliamo supportare.
Garantire che il Contenuto di una Bozza sia Vuoto
Anche dopo aver chiamato aggiungi_testo aggiungendo del contenuto al nostro
post, vogliamo che il metodo contenuto ritorni una slice vuota perché il
post è ancora una bozza, come mostrato dal primo assert_eq! nel Listato
18-11. Per ora implementiamo il metodo contenuto con la cosa più semplice che
possa soddisfare questo requisito: restituire semplicemente una slice vuota.
Lo cambieremo in seguito quando aggiungeremo la possibilità di cambiare stato
per la pubblicazione. Per ora, i post possono essere solo bozze, e quindi il
contenuto del post è sempre vuoto. Il Listato 18-14 mostra questa
implementazione temporanea.
pub struct Post {
stato: Option<Box<dyn Stato>>,
contenuto: String,
}
impl Post {
// --taglio--
pub fn new() -> Post {
Post {
stato: Some(Box::new(Bozza {})),
contenuto: String::new(),
}
}
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
pub fn contenuto(&self) -> &str {
""
}
}
trait Stato {}
struct Bozza {}
impl Stato for Bozza {}contenuto di Post che restituisce sempre una slice vuotaCon l’aggiunta del metodo contenuto, tutto nel Listato 18-11 fino al primo
assert_eq! funziona come previsto.
Richiedere una Revisione, Che Cambia lo Stato del Post
Ora dobbiamo aggiungere la funzionalità per richiedere una revisione di un
post, che dovrebbe cambiare il suo stato da Bozza a AttesaRevisione. Il
Listato 18-15 mostra questo codice.
pub struct Post {
stato: Option<Box<dyn Stato>>,
contenuto: String,
}
impl Post {
// --taglio--
pub fn new() -> Post {
Post {
stato: Some(Box::new(Bozza {})),
contenuto: String::new(),
}
}
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
pub fn contenuto(&self) -> &str {
""
}
pub fn richiedi_revisione(&mut self) {
if let Some(s) = self.stato.take() {
self.stato = Some(s.richiedi_revisione())
}
}
}
trait Stato {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato>;
}
struct Bozza {}
impl Stato for Bozza {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
Box::new(AttesaRevisione {})
}
}
struct AttesaRevisione {}
impl Stato for AttesaRevisione {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
self
}
}richiedi_revisione su Post e il trait StatoDiamo a Post un metodo pubblico chiamato richiedi_revisione che prende un
reference mutabile a self. Poi chiamiamo un metodo interno
richiedi_revisione sullo stato corrente di Post, e questo secondo metodo
consuma lo stato corrente e restituisce un nuovo stato.
Aggiungiamo il metodo richiedi_revisione al trait Stato; tutti i type
che implementano il trait dovranno implementare questo metodo. Nota che invece
di avere self, &self o &mut self come primo parametro del metodo, abbiamo
self: Box<Self>. Questa sintassi significa che il metodo è valido solo
chiamandolo su una Box che contiene il type. Questa sintassi prende
ownership di Box<Self>, invalidando il vecchio stato in modo che il valore
di stato del Post possa trasformarsi in un nuovo stato.
Per consumare il vecchio stato, il metodo richiedi_revisione prende
ownership del valore di stato. Qui entra in gioco l’Option nel campo stato
di Post: chiamiamo il metodo take per estrarre il valore Some dal campo
stato e sostituirlo con un None al suo posto, perché Rust non permette campi
non popolati nelle struct. Questo ci permette di spostare il valore stato
fuori da Post invece di prenderlo in prestito. Poi assegniamo al campo stato
del post il risultato di questa operazione.
Dobbiamo impostare temporaneamente stato a None invece di assegnarlo
direttamente con codice come self.stato = self.stato.richiedi_revisione(); per
ottenere la ownership del valore stato. Questo evita che Post usi il
vecchio stato dopo averlo trasformato.
Il metodo richiedi_revisione su Bozza restituisce una nuova istanza
incapsulata in Box di una nuova struct AttesaRevisione, che rappresenta lo
stato di un post in attesa di revisione. Anche la struct AttesaRevisione
implementa il metodo richiedi_revisione ma senza trasformazioni, semplicemente
restituisce sé stessa perché richiedere una revisione su un post già in stato
AttesaRevisione lo mantiene nello stesso stato.
Qui si cominciano a comprendere i vantaggi dello state pattern: il metodo
richiedi_revisione su Post è lo stesso qualunque sia il valore di stato.
Ogni stato gestisce le sue regole.
Lasciamo il metodo contenuto su Post così com’è, che restituisce una slice
di stringa vuota. Ora possiamo avere un Post sia nello stato AttesaRevisione
sia nello stato Bozza, ma vogliamo lo stesso comportamento in entrambi gli
stati. Il Listato 18-11 funziona ora fino al secondo assert_eq!!
Aggiungere approva per Cambiare il Comportamento di contenuto
Il metodo approva sarà simile a richiedi_revisione: imposterà stato al
valore che lo stato corrente dice debba avere quando è stato approvato, come
mostrato nel Listato 18-16.
pub struct Post {
stato: Option<Box<dyn Stato>>,
contenuto: String,
}
impl Post {
// --taglio--
pub fn new() -> Post {
Post {
stato: Some(Box::new(Bozza {})),
contenuto: String::new(),
}
}
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
pub fn contenuto(&self) -> &str {
""
}
pub fn richiedi_revisione(&mut self) {
if let Some(s) = self.stato.take() {
self.stato = Some(s.richiedi_revisione())
}
}
pub fn approva(&mut self) {
if let Some(s) = self.stato.take() {
self.stato = Some(s.approva())
}
}
}
trait Stato {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato>;
fn approva(self: Box<Self>) -> Box<dyn Stato>;
}
struct Bozza {}
impl Stato for Bozza {
// --taglio--
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
Box::new(AttesaRevisione {})
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
self
}
}
struct AttesaRevisione {}
impl Stato for AttesaRevisione {
// --taglio--
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
self
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
Box::new(Pubblicato {})
}
}
struct Pubblicato {}
impl Stato for Pubblicato {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
self
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
self
}
}approva su Post e il trait StatoAggiungiamo il metodo approva al trait Stato e una nuova struct che
implementa Stato, lo stato Pubblicato.
Simile a come funziona richiedi_revisione su AttesaRevisione, se chiamiamo
il metodo approva su una Bozza, non avrà effetto perché approva restituirà
self. Quando chiamiamo approva su AttesaRevisione, restituisce una nuova
istanza incapsulata in Box di Pubblicato. La struct Pubblicato
implementa il trait Stato, e sia per richiedi_revisione che per approva
restituisce se stessa perché il post dovrebbe rimanere nello stato
Pubblicato in quei casi.
Ora dobbiamo aggiornare il metodo contenuto su Post. Vogliamo che il valore
restituito da contenuto dipenda dallo stato corrente di Post, quindi faremo
in modo che Post deleghi a un metodo contenuto definito sul suo stato,
come mostrato nel Listato 18-17.
pub struct Post {
stato: Option<Box<dyn Stato>>,
contenuto: String,
}
impl Post {
// --taglio--
pub fn new() -> Post {
Post {
stato: Some(Box::new(Bozza {})),
contenuto: String::new(),
}
}
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
pub fn contenuto(&self) -> &str {
self.stato.as_ref().unwrap().contenuto(self)
}
// --taglio--
pub fn richiedi_revisione(&mut self) {
if let Some(s) = self.stato.take() {
self.stato = Some(s.richiedi_revisione())
}
}
pub fn approva(&mut self) {
if let Some(s) = self.stato.take() {
self.stato = Some(s.approva())
}
}
}
trait Stato {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato>;
fn approva(self: Box<Self>) -> Box<dyn Stato>;
}
struct Bozza {}
impl Stato for Bozza {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
Box::new(AttesaRevisione {})
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
self
}
}
struct AttesaRevisione {}
impl Stato for AttesaRevisione {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
self
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
Box::new(Pubblicato {})
}
}
struct Pubblicato {}
impl Stato for Pubblicato {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
self
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
self
}
}contenuto su Post per delegare a un metodo contenuto su StatoPoiché l’obiettivo è tenere tutte queste regole dentro le struct che
implementano Stato, chiamiamo un metodo contenuto sul valore in stato
passando l’istanza del post (self) come argomento. Quindi restituiamo il
valore restituito dall’uso del metodo contenuto sul valore stato.
Chiamiamo il metodo as_ref sull’Option perché vogliamo un reference al
valore dentro l’Option piuttosto che la ownership del valore. Poiché stato
è un Option<Box<dyn Stato>>, chiamando as_ref otteniamo un Option<&Box<dyn Stato>>. Se non chiamassimo as_ref, otterremmo un errore perché non possiamo
spostare stato fuori dal parametro in prestito &self della funzione.
Chiamiamo poi il metodo unwrap, che sappiamo non andrà mai in panic perché i
metodi su Post assicurano che stato conterrà sempre un valore Some quando
quei metodi sono terminati. Questo è uno di quei casi discussi in “Quando Hai
Più Informazioni Del Compilatore” nel
Capitolo 9 quando sappiamo che un valore None è impossibile, anche se il
compilatore non è in grado di inferirlo.
A questo punto, quando chiamiamo contenuto su &Box<dyn Stato>, la
de-referenziazione forzata agirà su & e Box così che il metodo contenuto
sarà chiamato sul type che implementa il trait Stato. Ciò significa che
dobbiamo aggiungere contenuto alla definizione del trait Stato e lì
metteremo la logica per cosa restituire in base allo stato, come mostrato nel
Listato 18-18.
pub struct Post {
stato: Option<Box<dyn Stato>>,
contenuto: String,
}
impl Post {
pub fn new() -> Post {
Post {
stato: Some(Box::new(Bozza {})),
contenuto: String::new(),
}
}
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
pub fn contenuto(&self) -> &str {
self.stato.as_ref().unwrap().contenuto(self)
}
pub fn richiedi_revisione(&mut self) {
if let Some(s) = self.stato.take() {
self.stato = Some(s.richiedi_revisione())
}
}
pub fn approva(&mut self) {
if let Some(s) = self.stato.take() {
self.stato = Some(s.approva())
}
}
}
trait Stato {
// --taglio--
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato>;
fn approva(self: Box<Self>) -> Box<dyn Stato>;
fn contenuto<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --taglio--
struct Bozza {}
impl Stato for Bozza {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
Box::new(AttesaRevisione {})
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
self
}
}
struct AttesaRevisione {}
impl Stato for AttesaRevisione {
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
self
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
Box::new(Pubblicato {})
}
}
struct Pubblicato {}
impl Stato for Pubblicato {
// --taglio--
fn richiedi_revisione(self: Box<Self>) -> Box<dyn Stato> {
self
}
fn approva(self: Box<Self>) -> Box<dyn Stato> {
self
}
fn contenuto<'a>(&self, post: &'a Post) -> &'a str {
&post.contenuto
}
}contenuto al trait StatoAggiungiamo un’implementazione di default per il metodo contenuto che
restituisce una slice di stringa vuota. Ciò significa che non dobbiamo
implementare contenuto nelle struct Bozza e AttesaRevisione. La struct
Pubblicato sovrascriverà il metodo contenuto e restituirà il valore in
post.contenuto. Anche se comodo, avere il metodo contenuto su Stato che
determina il contenuto di Post sfuma i confini tra la responsabilità di
Stato e quella di Post.
Nota che abbiamo bisogno di annotazioni di lifetime su questo metodo, come
discusso nel Capitolo 10. Stiamo prendendo un reference a un post come
argomento e restituiamo un reference ad una parte di quel post, quindi la
longevità del reference restituito è legata alla longevità dell’argomento
post.
E abbiamo finito: tutto il Listato 18-11 ora funziona! Abbiamo implementato lo
state pattern con le regole del flusso di lavoro del blog. La logica relativa
alle regole vive negli oggetti di stato invece di essere sparsa in Post.
Perché Non un’enum?
Potresti chiederti perché non abbiamo usato un’enum con i diversi possibili
stati del post come varianti. È certamente una soluzione possibile; provalo
e confronta i risultati finali per vedere cosa preferisci! Uno svantaggio
dell’uso di un’enum è che ogni posto che verifica il valore dell’enum avrà
bisogno di un’espressione match o simile per gestire ogni variante
possibile. Questo potrebbe diventare più ripetitivo rispetto a questa
soluzione con un oggetto trait.
Valutazione dello State Pattern
Abbiamo mostrato che Rust è capace di implementare lo state pattern orientato
agli oggetti per incapsulare i diversi tipi di comportamento che un post
dovrebbe avere in ogni stato. I metodi su Post non sanno nulla dei vari
comportamenti. Siccome abbiamo organizzando il codice in questo modo, dobbiamo
guardare in un solo posto per conoscere i diversi modi in cui un post
pubblicato può comportarsi: l’implementazione del trait Stato sulla struct
Pubblicato.
Se creassimo un’implementazione alternativa che non usasse lo state pattern,
potremmo invece usare espressioni match nei metodi su Post o anche nel
codice main che verifica lo stato del post e cambia comportamento in quei
posti. Ciò significherebbe dover guardare in più posti per capire tutte le
implicazioni di un post che è nello stato “pubblicato”.
Con lo state pattern, i metodi Post e i posti dove usiamo Post non hanno
bisogno di espressioni match, e per aggiungere un nuovo stato dovremmo solo
aggiungere una nuova struct e implementare i metodi del trait su quella
struct in un solo punto.
L’implementazione usando lo state pattern è facile da estendere per aggiungere più funzionalità. Per vedere la semplicità di mantenere codice che usa lo state pattern, prova ad implementare qualcuna di queste proposte:
- Aggiungi un metodo
respingiche cambia lo stato del post daAttesaRevisioneaBozza. - Richiedi due chiamate al metodo
approvaprima che lo stato possa essere cambiato inPubblicato. - Permetti agli utenti di aggiungere testo al contenuto solo quando il post è
nello stato
Bozza. Suggerimento: fai in modo che l’oggetto stato sia responsabile di cosa può cambiare del contenuto ma non responsabile di modificarePost.
Un lato negativo dello state pattern è che, siccome gli stati implementano le
transizioni tra stati, alcuni stati sono accoppiati tra loro. Se aggiungessimo
un altro stato tra AttesaRevisione e Pubblicato, come Programmato,
dovremmo modificare il codice in AttesaRevisione per passare a Programmato.
Sarebbe meno lavoro se AttesaRevisione non dovesse cambiare con l’aggiunta di
un nuovo stato, ma ciò significherebbe passare a un altro modello di design.
Un altro lato negativo è che abbiamo duplicato un po’ di logica. Per eliminare
la duplicazione, potremmo provare a fare implementazioni predefinite per i
metodi richiedi_revisione e approva sul trait Stato che restituiscono
self. Tuttavia, questo non funzionerebbe: quando usiamo Stato come oggetto
trait, il trait non conosce esattamente il type concreto di self, quindi
il type di ritorno non è noto durante la compilazione. (Questa è una delle
regole di compatibilità dyn menzionate prima.)
Altra duplicazione è nelle implementazioni simili dei metodi
richiedi_revisione e approva su Post. Entrambi i metodi usano
Option::take con il campo stato di Post, e se stato è Some, delegano
all’implementazione del metodo con lo stesso nome del valore incapsulato e
impostano il nuovo valore del campo stato al risultato. Se avessimo molti
metodi su Post che seguono questo schema, potremmo considerare di definire una
macro per eliminare la ripetizione (vedi la sezione “Macro” del Capitolo 20).
Implementando lo state pattern esattamente come definito per i linguaggi
orientati agli oggetti, non sfruttiamo appieno i punti di forza di Rust come
potremmo. Vediamo qualche cambiamento da fare al crate blog che può
trasformare stati e transizioni invalide in errori durante la compilazione.
Codifica di Stati e Comportamenti Come Type
Ti mostreremo come ripensare lo state pattern per ottenere un diverso set di compromessi. Invece di incapsulare completamente gli stati e le transizioni così che il codice esterno non ne sappia nulla, codificheremo gli stati in type differenti. Di conseguenza, il sistema di controllo dei type di Rust impedirà tentativi di usare post in bozze dove sono permessi solo post pubblicati, generando un errore di compilazione.
Consideriamo la prima parte di main nel Listato 18-11:
use blog::Post;
fn main() {
let mut post = Post::new();
post.aggiungi_testo("Oggi a pranzo ho mangiato un'instalata");
assert_eq!("", post.contenuto());
post.richiedi_revisione();
assert_eq!("", post.contenuto());
post.approva();
assert_eq!("Oggi a pranzo ho mangiato un'instalata", post.contenuto());
}Continuiamo a permettere la creazione di nuovi post nello stato bozza usando
Post::new e la possibilità di aggiungere testo al contenuto del post. Ma
invece di avere un metodo contenuto su un post bozza che restituisce una
stringa vuota, facciamo in modo che i post bozza non abbiano affatto il metodo
contenuto. In questo modo, se proviamo a ottenere il contenuto di un post
bozza, otterremo un errore di compilazione che ci dice che il metodo non esiste.
Di conseguenza, sarà impossibile mostrare accidentalmente il contenuto di un
post bozza in produzione perché quel codice nemmeno si compila. Il Listato
18-19 mostra la definizione di una struct Post e una PostBozza, oltre ai
metodi su ciascuna.
pub struct Post {
contenuto: String,
}
pub struct PostBozza {
contenuto: String,
}
impl Post {
pub fn new() -> PostBozza {
PostBozza {
contenuto: String::new(),
}
}
pub fn contenuto(&self) -> &str {
&self.contenuto
}
}
impl PostBozza {
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
}Post con un metodo contenuto e un PostBozza senza metodo contenutoSia le struct Post che PostBozza hanno un campo privato contenuto che
memorizza il testo del post. Le struct non hanno più il campo stato perché
stiamo spostando la codifica dello stato nei type delle struct. La struct
Post rappresenta un post pubblicato e ha un metodo contenuto che
restituisce il contenuto.
Abbiamo ancora una funzione Post::new, ma invece di restituire un’istanza di
Post, restituisce un’istanza di PostBozza. Poiché contenuto è privato e
non ci sono funzioni che restituiscono Post, al momento non è possibile creare
un’istanza di Post.
La struct PostBozza ha un metodo aggiungi_testo, quindi possiamo
aggiungere testo a contenuto come prima, ma nota che PostBozza non ha un
metodo contenuto definito! Quindi ora il programma assicura che tutti i post
inizino come bozze, e i post bozza non hanno il loro contenuto disponibile per
la visualizzazione. Qualsiasi tentativo di aggirare questi vincoli causerà un
errore di compilazione.
Come facciamo allora a ottenere un post pubblicato? Vogliamo imporre la regola
che un post bozza deve essere revisionato e approvato prima di poter essere
pubblicato. Un post nello stato di attesa di revisione non dovrebbe comunque
mostrare contenuti. Implementiamo questi vincoli aggiungendo un’altra struct,
PostAttesaRevisione, definendo il metodo richiedi_revisione su PostBozza
che restituisce un PostAttesaRevisione e un metodo approva su
PostAttesaRevisione che restituisce un Post, come mostrato nel Listato
18-20.
pub struct Post {
contenuto: String,
}
pub struct PostBozza {
contenuto: String,
}
impl Post {
pub fn new() -> PostBozza {
PostBozza {
contenuto: String::new(),
}
}
pub fn contenuto(&self) -> &str {
&self.contenuto
}
}
impl PostBozza {
// --taglio--
pub fn aggiungi_testo(&mut self, testo: &str) {
self.contenuto.push_str(testo);
}
pub fn richiedi_revisione(self) -> PostAttesaRevisione {
PostAttesaRevisione {
contenuto: self.contenuto,
}
}
}
pub struct PostAttesaRevisione {
contenuto: String,
}
impl PostAttesaRevisione {
pub fn approva(self) -> Post {
Post {
contenuto: self.contenuto,
}
}
}PostAttesaRevisione creato chiamando richiedi_revisione su PostBozza e un metodo approva che trasforma un PostAttesaRevisione in un Post pubblicatoI metodi richiedi_revisione e approva prendono ownership di self,
consumando così le istanze PostBozza e PostAttesaRevisione trasformandole
rispettivamente in un PostAttesaRevisione e un Post pubblicato. In questo
modo non avremo istanze residue di PostBozza dopo aver chiamato
richiedi_revisione su di loro, e così via. La struct PostAttesaRevisione
non ha un metodo contenuto definito, quindi tentare di leggere il suo
contenuto causa un errore di compilazione, come per PostBozza. Poiché l’unico
modo per ottenere un’istanza di Post pubblicato che ha un metodo contenuto
definito è chiamare approva su un PostAttesaRevisione, e l’unico modo per
ottenere un PostAttesaRevisione è chiamare richiedi_revisione su un
PostBozza, abbiamo ora codificato il flusso di lavoro del blog col sistema dei
type.
Dobbiamo anche fare qualche piccolo cambiamento in main. I metodi
richiedi_revisione e approva restituiscono nuove istanze invece di
modificare la struct su cui sono chiamati, quindi dobbiamo aggiungere più
assegnazioni di shadowing let post = per salvare le istanze restituite. Non
possiamo nemmeno avere le asserzioni sui contenuti vuoti dei post bozza e
revisione pendente, né ne abbiamo bisogno: non possiamo più compilare codice che
tenta di usare il contenuto dei post in quegli stati. Il codice aggiornato in
main è mostrato nel Listato 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.aggiungi_testo("Oggi a pranzo ho mangiato un'instalata");
let post = post.richiedi_revisione();
let post = post.approva();
assert_eq!("Oggi a pranzo ho mangiato un'instalata", post.contenuto());
}main per usare la nuova implementazione del flusso di lavoro del blogI cambiamenti necessari per riassegnare post significano che questa
implementazione non segue più esattamente lo state pattern orientato agli
oggetti: le trasformazioni tra gli stati non sono più completamente incapsulate
nella implementazione di Post. Tuttavia, abbiamo guadagnato che stati invalidi
ora sono impossibili grazie al sistema dei type e al controllo durante la
compilazione! Questo assicura che alcuni bug, come la visualizzazione del
contenuto di un post non pubblicato, vengano scoperti prima che arrivino in
produzione.
Prova a realizzare i compiti suggeriti all’inizio di questa sezione sul crate
blog così com’è dopo il Listato 18-21 per vedere cosa pensi del design di
questa versione del codice. Nota che alcune attività potrebbero essere già
implementate con questo design.
Abbiamo visto che anche se Rust è capace di implementare modelli di design orientati agli oggetti, altri modelli, come la codifica dello stato nel sistema dei type, sono disponibili in Rust. Questi modelli hanno diversi compromessi. Anche se potresti essere molto familiare con i modelli orientati agli oggetti, ripensare il problema per sfruttare le caratteristiche di Rust può offrire benefici, come prevenire alcuni bug già in fase di compilazione. I modelli orientati agli oggetti non saranno sempre la miglior soluzione in Rust a causa di alcune caratteristiche come la ownership, che i linguaggi orientati agli oggetti non hanno.
Riepilogo
Indipendentemente dal fatto che tu pensi che Rust sia un linguaggio orientato agli oggetti dopo aver letto questo capitolo, ora sai che puoi usare oggetti trait per ottenere alcune funzionalità orientate agli oggetti in Rust. Il dynamic dispatch può dare al tuo codice un po’ di flessibilità in cambio di una piccola perdita in prestazioni durante l’esecuzione. Puoi usare questa flessibilità per implementare modelli orientati agli oggetti che possono aiutare nella manutenibilità del tuo codice. Rust ha anche altre caratteristiche, come la ownership, che i linguaggi orientati agli oggetti non hanno. Un modello orientato agli oggetti non sarà sempre il modo migliore per sfruttare i punti di forza di Rust, ma è un’opzione disponibile.
In seguito parleremo di pattern, un’altra delle caratteristiche di Rust che consente molta flessibilità. Li abbiamo visti brevemente in precedenza nel libro, ma non ne abbiamo ancora visto tutto il potenziale. Cominciamo!
Pattern e Corrispondenza
I Pattern sono una sintassi speciale in Rust per la corrispondenza
(matching) con la struttura dei type, sia complessi che semplici. L’utilizzo
di pattern insieme a espressioni match e altri costrutti offre un maggiore
controllo sul flusso di controllo di un programma. Un pattern consiste in una
combinazione dei seguenti elementi:
- Letterali
- Array destrutturati, enum, struct o tuple
- Variabili
- Caratteri jolly
- Segnaposto
Alcuni esempi di pattern includono x, (a, 3) e Some(Colore::Rosso). Nei
contesti in cui i pattern sono validi, questi componenti descrivono la forma
dei dati. Il nostro programma confronta quindi i valori con i pattern per
determinare se ha la forma corretta dei dati per continuare a eseguire una
particolare porzione di codice.
Per utilizzare un pattern, lo confrontiamo con un valore. Se il pattern
corrisponde al valore, utilizziamo le parti del valore nel nostro codice.
Ricorda le espressioni match nel Capitolo 6 che utilizzavano pattern, come
l’esempio della macchina smista monete. Se il valore corrisponde alla forma del
pattern, possiamo usare i pezzi indicati. In caso contrario, il codice
associato al pattern non verrà eseguito.
Questo capitolo è un riferimento su tutto ciò che riguarda i pattern. Tratteremo le situazioni valide in cui utilizzare i pattern, la differenza tra pattern confutabili e inconfutabili e i diversi tipi di sintassi dei pattern che potresti incontrare. Alla fine del capitolo, saprai come usare i pattern per esprimere molti concetti in modo chiaro.
Tutti i Posti Dove Possiamo Utilizzare i Pattern
I pattern compaiono in diversi punti di Rust e li hai usati senza rendertene conto! Questa sezione illustra tutti i posti in cui i pattern sono validi.
Rami di match
Come discusso nel Capitolo 6, utilizziamo i pattern nei rami delle espressioni
match. Formalmente, le espressioni match sono definite come la parola chiave
match, un valore su cui effettuare la corrispondenza e uno o più rami di
corrispondenza costituiti da un pattern e un’espressione da eseguire se il
valore corrisponde al pattern di quel ramo, in questo modo:
match VALORE {
PATTERN => ESPRESSIONE,
PATTERN => ESPRESSIONE,
PATTERN => ESPRESSIONE,
}Ad esempio, ecco l’espressione match del Listato 6-5 che fa la corrispondenza
su un valore Option<i32> nella variabile x:
match x {
None => None,
Some(i) => Some(i + 1),
}I pattern in questa espressione match sono None e Some(i) a sinistra di
ciascuna freccia.
Un requisito per le espressioni match è che siano esaustive, nel senso che
tutte le possibilità per il valore nell’espressione match devono essere
considerate. Un modo per assicurarsi di aver coperto ogni possibilità è avere un
pattern pigliatutto per l’ultimo ramo: ad esempio, un nome di variabile che
corrisponde a qualsiasi valore non può mai fallire e quindi copre tutti i casi
rimanenti.
Il pattern specifico _ corrisponderà a qualsiasi cosa, ma non si vincola mai
a una variabile, quindi viene spesso utilizzato nell’ultimo ramo di
corrispondenza. Il pattern _ può essere utile quando si desidera ignorare
qualsiasi valore non specificato, ad esempio. Tratteremo il pattern _ più
dettagliatamente in “Ignorare Valori In un
Pattern” più avanti in questo
capitolo.
Dichiarazioni let
Prima di questo capitolo, avevamo discusso esplicitamente dell’uso dei pattern
solo con match e if let, ma in realtà abbiamo utilizzato pattern anche in
altri contesti, incluse le dichiarazioni let. Ad esempio, si consideri questa
semplice assegnazione di variabile con let:
#![allow(unused)] fn main() { let x = 5; }
Ogni volta che hai utilizzato una dichiarazione let come questa, hai
utilizzato dei pattern, anche se potresti non essertene accorto! Più
formalmente, una dichiarazione let si presenta così:
let PATTERN = ESPRESSIONE;
In dichiarazioni come let x = 5; con un nome di variabile nel posto di
PATTERN, il nome della variabile è solo una forma particolarmente semplice di
pattern. Rust confronta l’espressione con il pattern e assegna qualsiasi
nome trovi. Quindi, nell’esempio let x = 5;, x è un pattern che significa
“associa ciò che corrisponde qui alla variabile x”. Poiché il nome x è
l’intero pattern, questo pattern significa effettivamente “associa tutto
alla variabile x, qualunque sia il valore”.
Per comprendere più chiaramente l’aspetto di corrispondenza del pattern di
let, considera il Listato 19-1, che utilizza un pattern con let per
destrutturare una tupla.
fn main() { let (x, y, z) = (1, 2, 3); }
Qui, confrontiamo una tupla con un pattern. Rust confronta il valore (1, 2, 3) con il pattern (x, y, z) e verifica che il valore corrisponde al
pattern, in quanto vede che il numero di elementi è lo stesso in entrambi,
quindi Rust associa 1 a x, 2 a y e 3 a z. Si può pensare a questo
pattern di tupla come all’annidamento di tre pattern di variabili
individuali al suo interno.
Se il numero di elementi nel pattern non corrisponde al numero di elementi nella tupla, il type complessivo non corrisponderà e si verificherà un errore del compilatore. Ad esempio, il Listato 19-2 mostra un tentativo di destrutturare una tupla con tre elementi in due variabili, che non funzionerà.
fn main() {
let (x, y) = (1, 2, 3);
}Il tentativo di compilare questo codice genera questo tipo di errore:
$ cargo run
Compiling patterns v0.1.0 (file:///progetti/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Per correggere l’errore, potremmo ignorare uno o più valori nella tupla usando
_ o .., come vedrai nella sezione “Ignorare Valori In un
Pattern”. Se il problema è che
abbiamo troppe variabili nel pattern, la soluzione è far corrispondere i
type rimuovendo le variabili in modo che il numero di variabili sia uguale al
numero di elementi nella tupla.
Espressioni Condizionali if let
Nel Capitolo 6, abbiamo discusso come utilizzare le espressioni if let
principalmente come un modo più breve per scrivere l’equivalente di un match
che corrisponde a un solo caso. Facoltativamente, if let può avere un else
corrispondente contenente il codice da eseguire se il pattern in if let non
corrisponde.
Il Listato 19-3 mostra che è anche possibile combinare e abbinare le espressioni
if let, else if e else if let. Ciò offre maggiore flessibilità rispetto a
un’espressione match in cui possiamo esprimere un solo valore da confrontare
con i pattern. Inoltre, Rust non richiede che le condizioni in una serie di
rami if let, else if e else if let siano correlate tra loro.
Il codice nel Listato 19-3 determina il colore da utilizzare per lo sfondo in base a una serie di controlli per diverse condizioni. Per questo esempio, abbiamo creato variabili con valori predefiniti che un programma reale potrebbe ricevere dall’input dell’utente.
fn main() { let colore_preferito: Option<&str> = None; let è_martedi = false; let età: Result<u8, _> = "34".parse(); if let Some(color) = colore_preferito { println!("Usando il tuo colore preferito, {color}, come sfondo"); } else if è_martedi { println!("Martedì è il giorno verde!"); } else if let Ok(età) = età { if età > 30 { println!("Usando il viola come colore di sfondo"); } else { println!("Usando l'arancione come colore di sfondo"); } } else { println!("Usando il blu come colore di sfondo"); } }
if let, else if, else if let e elseSe l’utente specifica un colore preferito, quel colore viene utilizzato come sfondo. Se non viene specificato alcun colore preferito e oggi è martedì, il colore di sfondo è verde. Altrimenti, se l’utente specifica la propria età come stringa e possiamo analizzarla come un numero correttamente, il colore sarà viola o arancione a seconda del valore del numero. Se nessuna di queste condizioni si applica, il colore di sfondo è blu.
Questa struttura condizionale ci consente di supportare requisiti complessi. Con
i valori specificati che abbiamo qui, questo esempio stamperà Usando il viola come colore di sfondo.
Si può notare che if let può anche introdurre nuove variabili che oscurano le
variabili esistenti allo stesso modo in cui match può farlo: la riga if let Ok(età) = età introduce una nuova variabile età che contiene il valore
all’interno della variante Ok, oscurando la variabile età esistente. Ciò
significa che dobbiamo inserire la condizione if età > 30 all’interno di quel
blocco: non possiamo combinare queste due condizioni in if let Ok(età) = età && età > 30. Il nuovo età che vogliamo confrontare con 30 non è valido finché il
nuovo scope non inizia con la parentesi graffa.
Lo svantaggio dell’utilizzo di espressioni if let è che il compilatore non
verifica l’esaustività, mentre con le espressioni match lo fa. Se omettessimo
l’ultimo blocco else e quindi non gestissimo alcuni casi, il compilatore non
ci avviserebbe del possibile bug logico.
Cicli Condizionali while let
Simile nella costruzione a if let, il ciclo condizionale while let consente
a un ciclo while di essere eseguito finché un pattern continua a
corrispondere. Nel Listato 19-4 mostriamo un ciclo while let che attende i
messaggi inviati tra thread, ma in questo caso controlla un Result invece di
un Option.
fn main() { let (tx, rx) = std::sync::mpsc::channel(); std::thread::spawn(move || { for val in [1, 2, 3] { tx.send(val).unwrap(); } }); while let Ok(valore) = rx.recv() { println!("{valore}"); } }
while let per stampare valori finché rx.recv() restituisce OkQuesto esempio stampa 1, 2 e poi 3. Il metodo recv prende il primo
messaggio dall’estremità ricevente del canale e restituisce Ok(valore). Quando
abbiamo visto per la prima volta recv nel Capitolo 16, abbiamo analizzato
direttamente l’errore, o abbiamo interagito con esso come un iteratore usando un
ciclo for. Come mostra il Listato 19-4, tuttavia, possiamo anche usare while let, perché il metodo recv restituisce Ok ogni volta che arriva un
messaggio, finché il mittente esiste, e poi produce un Err una volta che il
mittente si disconnette.
Cicli for
In un ciclo for, il valore che segue direttamente la parola chiave for è un
pattern. Ad esempio, in for x in y, x è il pattern. Il Listato 19-5
mostra come utilizzare un pattern in un ciclo for per destrutturare, o
scomporre, una tupla come parte del ciclo for.
fn main() { let v = vec!['a', 'b', 'c']; for (indice, valore) in v.iter().enumerate() { println!("{valore} è all'indice {indice}"); } }
for per destrutturare una tuplaIl codice nel Listato 19-5 stamperà quanto segue:
$ cargo run
Compiling patterns v0.1.0 (file:///progetti/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a è all'indice 0
b è all'indice 1
c è all'indice 2
Adattiamo un iteratore utilizzando il metodo enumerate in modo che produca un
valore e l’indice per quel valore, inserito in una tupla. Il primo valore
prodotto è la tupla (0, 'a'). Quando questo valore viene confrontato con il
pattern (indice, valore), indice sarà 0 e valore sarà a, stampando
la prima riga dell’output.
Parametri di Funzione
Anche i parametri di funzione possono essere pattern. Il codice nel Listato
19-6, che dichiara una funzione chiamata foo che accetta un parametro chiamato
x di type i32, dovrebbe ormai risultare familiare.
fn foo(x: i32) { // codice va qui } fn main() {}
La parte x è un pattern! Come abbiamo fatto con let, potremmo abbinare una
tupla negli argomenti di una funzione al pattern. Il Listato 19-7 suddivide i
valori in una tupla mentre la passiamo a una funzione.
fn stampa_coordinate(&(x, y): &(i32, i32)) { println!("Posizione corrente: ({x}, {y})"); } fn main() { let punto = (3, 5); stampa_coordinate(&punto); }
Questo codice stampa Posizione corrente: (3, 5). I valori &(3, 5)
corrispondono al pattern &(x, y), quindi x è il valore 3 e y è il
valore 5.
Possiamo anche usare i pattern nelle liste di parametri delle chiusure allo stesso modo delle liste di parametri di funzione, perché le chiusure sono simili alle funzioni, come discusso nel Capitolo 13.
A questo punto, hai visto diversi modi per usare i pattern, ma i pattern non funzionano allo stesso modo in tutti i casi in cui possiamo usarli. In alcuni casi, i pattern devono essere inconfutabili; in altre circostanze, possono essere confutabili. Discuteremo questi due concetti nella prossima sezione.
Confutabilità: Quando un Pattern Potrebbe non Corrispondere
I pattern si presentano in due forme: confutabili e inconfutabili
(refutable/irrefutable). I pattern che corrispondono per qualsiasi possibile
valore passato sono inconfutabili. Un esempio sarebbe x nella dichiarazione
let x = 5; perché x corrisponde a qualsiasi cosa e quindi non può non
corrispondere. I pattern che possono non corrispondere per un possibile valore
sono confutabili. Un esempio sarebbe Some(x) nell’espressione if let Some(x) = un_valore perché se il valore nella variabile un_valore è None
anziché Some, il pattern Some(x) non corrisponderà.
I parametri di funzione, le dichiarazioni let e i cicli for possono
accettare solo pattern inconfutabili perché il programma non può fare nulla di
significativo quando i valori non corrispondono. Le espressioni if let e
while let e la dichiarazione let...else accettano sia pattern confutabili
che inconfutabili, ma il compilatore mette in guardia contro i pattern
inconfutabili perché, per definizione, sono pensati per gestire possibili
fallimenti: la funzionalità di una condizione risiede nella sua capacità di
comportarsi in modo diverso a seconda del successo o del fallimento.
In generale, non ci si dovrebbe preoccupare della distinzione tra pattern confutabili e inconfutabili; tuttavia, è necessario avere familiarità con il concetto di confutabilità in modo da poterlo comprendere quando lo si vede in un messaggio di errore. In questi casi, sarà necessario modificare il pattern o il costrutto con cui si sta utilizzando il pattern, a seconda del comportamento previsto per il codice.
Esaminiamo un esempio di cosa succede quando proviamo a utilizzare un pattern
confutabile dove Rust richiede un pattern inconfutabile e viceversa. Il
Listato 19-8 mostra una dichiarazione let, ma per il pattern abbiamo
specificato Some(x), un pattern confutabile. Come ci si potrebbe aspettare,
questo codice non verrà compilato.
fn main() {
let un_valore_option: Option<i32> = None;
let Some(x) = un_valore_option;
}letSe un_valore_option fosse un valore None, non corrisponderebbe al pattern
Some(x), il che significa che il pattern è confutabile. Tuttavia, la
dichiarazione let può accettare solo un pattern inconfutabile perché non c’è
nulla di valido che il codice possa fare con un valore None. In fase di
compilazione, Rust ci segnalerà il fatto che abbiamo provato a utilizzare un
pattern confutabile laddove è richiesto un pattern inconfutabile:
$ cargo run
Compiling patterns v0.1.0 (file:///progetti/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = un_valore_option;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = un_valore_option else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Poiché non abbiamo coperto (e non potevamo coprire!) ogni valore valido con il
pattern Some(x), Rust genera giustamente un errore di compilazione.
Se abbiamo un pattern confutabile laddove è necessario un pattern
inconfutabile, possiamo correggerlo modificando il codice che utilizza il
pattern: invece di usare let, possiamo usare let...else. Quindi, se il
pattern non corrisponde, il codice salterà semplicemente il codice tra
parentesi graffe, consentendogli di continuare validamente. Il Listato 19-9
mostra come correggere il codice nel Listato 19-8.
fn main() { let un_valore_option: Option<i32> = None; let Some(x) = un_valore_option else { return; }; }
let...else e un blocco con pattern confutabili invece di letAbbiamo dato al codice una via d’uscita! Questo codice è perfettamente valido,
anche se significa che non potremmo usare un pattern inconfutabile senza
ricevere un avviso. Se diamo a let...else un pattern che corrisponderà
sempre, ed esempio x, come mostrato nel Listato 19-10, il compilatore genererà
un avviso.
fn main() { let x = 5 else { return; }; }
let...elseRust segnala che non ha senso utilizzare let...else con un pattern
inconfutabile:
$ cargo run
Compiling patterns v0.1.0 (file:///progetti/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
Per questo motivo, i rami di match devono utilizzare pattern inconfutabili,
ad eccezione dell’ultimo ramo, che dovrebbe corrispondere a tutti i valori
rimanenti con un pattern inconfutabile. Rust ci consente di utilizzare un
pattern inconfutabile in un match con singolo ramo, ma questa sintassi non è
particolarmente utile e potrebbe essere sostituita con una più semplice
dichiarazione let.
Ora che sappiamo dove usare i pattern e la differenza tra pattern confutabili e inconfutabili, esaminiamo tutta la sintassi che possiamo usare per creare pattern.
Sintassi dei Pattern
In questa sezione, raccogliamo tutta la sintassi valida nei pattern e discutiamo perché e quando potresti voler utilizzare ciascuna di esse.
Corrispondenza di Letterali
Come hai visto nel Capitolo 6, puoi confrontare i pattern direttamente con i letterali. Il codice seguente fornisce alcuni esempi:
fn main() { let x = 1; match x { 1 => println!("uno"), 2 => println!("due"), 3 => println!("tre"), _ => println!("altro"), } }
Questo codice stampa uno perché il valore in x è 1. Questa sintassi è
utile quando vuoi che il codice esegua un’azione se ottiene un particolare
valore concreto.
Corrispondenza di Variabili Denominate
Le variabili denominate sono pattern inconfutabili che corrispondono a
qualsiasi valore e le abbiamo utilizzate molte volte in questo libro. Tuttavia,
si verifica una complicazione quando si utilizzano variabili denominate nelle
espressioni match, if let o while let. Poiché ciascuna di queste
espressioni inizia un nuovo scope, le variabili dichiarate come parte di un
pattern all’interno di queste espressioni oscureranno quelle con lo stesso
nome all’esterno dei costrutti, come è il caso di tutte le variabili. Nel
Listato 19-11, dichiariamo una variabile denominata x con il valore Some(5)
e una variabile y con il valore 10. Creiamo quindi un’espressione match
sul valore x. Osserva i pattern nel campo match e println! alla fine, e
cerca di capire cosa stamperà il codice prima di eseguirlo o di proseguire con
la lettura.
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Ricevuto 50"), Some(y) => println!("Corrisponde, y = {y}"), _ => println!("Caso predefinito, x = {x:?}"), } println!("alla fine: x = {x:?}, y = {y}"); }
match con un ramo che introduce una nuova variabile che oscura una variabile esistente yEsaminiamo cosa succede quando viene eseguita l’espressione match. Il
pattern nel primo ramo di corrispondenza non corrisponde al valore definito di
x, quindi il codice continua.
Il pattern nel secondo ramo di corrispondenza introduce una nuova variabile
denominata y che corrisponderà a qualsiasi valore all’interno di un valore
Some. Poiché ci troviamo in un nuovo scope all’interno dell’espressione
match, questa è una nuova variabile y, non la y che abbiamo dichiarato
all’inizio con il valore 10. Questa nuova y corrisponderà a qualsiasi valore
all’interno di Some, che è ciò che abbiamo in x. Pertanto, questa nuova y
si lega al valore interno di Some in x. Quel valore è 5, quindi
l’espressione per quel ramo viene eseguita e stampa Corrisponde, y = 5.
Se x fosse stato un valore None invece di Some(5), i pattern nei primi
due rami non avrebbero trovato corrispondenza, quindi il valore avrebbe trovato
corrispondenza con il trattino basso. Non abbiamo introdotto la variabile x
nel pattern del ramo con trattino basso, quindi la x nell’espressione è
ancora la x esterna che non è stata oscurata. In questo caso ipotetico,
match stamperebbe Caso predefinito, x = None.
Quando l’espressione match termina, il suo scope termina, così come quello
della y interna. L’ultimo println! produce alla fine: x = Some(5), y = 10.
Per creare un’espressione match che confronti i valori delle variabili esterne
x e y, anziché introdurre una nuova variabile che oscura la variabile y
esistente, dovremmo usare una condizione di controllo della corrispondenza. Ne
parleremo più avanti nella sezione “Aggiungere Istruzioni Condizionali con le
Match Guard”.
Corrispondenza di Più Pattern
Nelle espressioni match, è possibile confrontare più pattern utilizzando la
sintassi |, che è l’operatore OR di controllo della corrispondenza. Ad
esempio, nel codice seguente confrontiamo il valore di x con i valori
corrispondenti, il primo dei quali ha un’opzione or, il che significa che se
il valore di x corrisponde a l’uno o l’altro dei valori del ramo, verrà
eseguito il codice di quel ramo:
fn main() { let x = 1; match x { 1 | 2 => println!("uno o due"), 3 => println!("tre"), _ => println!("altro"), } }
Questo codice stampa uno o due.
Corrispondenza di Intervalli di Valori con ..=
La sintassi ..= ci consente di confrontare con un intervallo di valori
inclusivo. Nel codice seguente, quando un pattern corrisponde a uno qualsiasi
dei valori all’interno dell’intervallo indicato, quel ramo verrà eseguito:
fn main() { let x = 5; match x { 1..=5 => println!("da uno a cinque"), _ => println!("altro"), } }
Se x è 1, 2, 3, 4 o 5, il primo ramo corrisponderà. Questa sintassi
è più comoda per più valori di corrispondenza rispetto all’utilizzo
dell’operatore | per esprimere la stessa idea; se dovessimo usare |,
dovremmo specificare 1 | 2 | 3 | 4 | 5. Specificare un intervallo è molto più
conciso, soprattutto se vogliamo trovare una corrispondenza, ad esempio, con un
numero qualsiasi compreso tra 1 e 1.000!
Il compilatore verifica che l’intervallo non sia vuoto in fase di compilazione
e, poiché gli unici type per cui Rust può stabilire se un intervallo è vuoto o
meno sono char e i valori numerici, gli intervalli sono consentiti solo con
valori numerici o char.
Ecco un esempio che utilizza intervalli di valori char:
fn main() { let x = 'c'; match x { 'a'..='j' => println!("lettere ASCII iniziali"), 'k'..='z' => println!("lettere ASCII finali"), _ => println!("altro"), } }
Rust può capire che 'c' si trova all‘interno del primo intervallo e stamperà
lettere ASCII iniziali.
Destrutturare per Separare Valori
Possiamo inoltre usare i pattern per destrutturare struct, enum e tuple per estrarre parti diverse di questi valori. Passiamo in rassegna ognuna di queste strutture dati.
Struct
Il Listato 19-12 mostra una struct Punto con due campi, x e y, che
possiamo separare usando un pattern con una dichiarazione let.
struct Punto { x: i32, y: i32, } fn main() { let p = Punto { x: 0, y: 7 }; let Punto { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
Questo codice crea le variabili a e b che corrispondono ai valori dei campi
x e y della struct p. Questo esempio mostra che i nomi delle variabili
nel pattern non devono necessariamente corrispondere ai nomi dei campi della
struct. Tuttavia, è comune far corrispondere i nomi delle variabili ai nomi
dei campi per rendere più facile ricordare quali variabili provengono da quali
campi. A causa di questo uso comune, e poiché scrivere let Punto { x: x, y: y } = p; contiene molte duplicazioni, Rust ha una scorciatoia per i pattern che
corrispondono ai campi della struct: è sufficiente elencare il nome del campo
della struct e le variabili create dal pattern avranno gli stessi nomi. Il
Listato 19-13 si comporta allo stesso modo del codice del Listato 19-12, ma le
variabili create nel pattern let sono x e y invece di a e b.
struct Punto { x: i32, y: i32, } fn main() { let p = Punto { x: 0, y: 7 }; let Punto { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
Questo codice crea le variabili x e y che corrispondono ai campi x e y
della variabile p. Il risultato è che le variabili x e y contengono i
valori della struct p.
Possiamo anche destrutturare con valori letterali come parte del pattern struct piuttosto che creare variabili per tutti i campi. In questo modo possiamo testare alcuni campi per valori specifici mentre creiamo variabili per destrutturare gli altri campi.
Nel Listato 19-14, abbiamo un’espressione match che separa i valori Punto in
tre casi: punti che giacciono direttamente sull’asse x (che è vero quando y = 0), sull’asse y (x = 0) o su nessuno dei due assi.
struct Punto { x: i32, y: i32, } fn main() { let p = Punto { x: 0, y: 7 }; match p { Punto { x, y: 0 } => println!("Sull'asse x a {x}"), Punto { x: 0, y } => println!("Sull'asse y a {y}"), Punto { x, y } => println!("Su nessun asse: ({x}, {y})"), } }
Il primo caso corrisponderà a qualsiasi punto che si trovi sull’asse x
specificando che il campo y corrisponde se il suo valore corrisponde al
letterale 0. Il pattern crea comunque una variabile x che possiamo
utilizzare nel codice per questo ramo.
Analogamente, il secondo caso corrisponde a qualsiasi punto sull’asse y
specificando che il campo x corrisponde se il suo valore è 0 e crea una
variabile y per il valore del campo y. Il terzo ramo non specifica alcun
letterale, quindi corrisponde a qualsiasi altro Punto e crea variabili per
entrambi i campi x e y.
In questo esempio, il valore p corrisponde al secondo ramo in virtù del fatto
che x contiene uno 0, quindi questo codice stamperà Sull’asse y a 7.
Ricorda che un’espressione match interrompe il controllo dei rami una volta
trovato il primo pattern corrispondente, quindi anche se Punto { x: 0, y: 0 } si trova sull’asse x e sull’asse y, questo codice stamperà solo
Sull'asse x a 0.
Enum
Abbiamo destrutturato gli enum in questo libro (ad esempio, Listato 6-5 nel
Capitolo 6), ma non abbiamo ancora spiegato esplicitamente che il pattern per
destrutturare un’enum corrisponde al modo in cui sono definiti i dati
memorizzati all’interno dell’enum stesso. Ad esempio, nel Listato 19-15
utilizziamo l’enum Messaggio del Listato 6-2 e scriviamo un match con
pattern che destruttureranno ogni valore interno.
enum Messaggio { Esci, Muovi { x: i32, y: i32 }, Scrivi(String), CambiaColore(i32, i32, i32), } // ANCHOR: here fn main() { let msg = Messaggio::CambiaColore(0, 160, 255); match msg { Messaggio::Esci => { println!("La variante Esci non ha dati da destrutturare."); } Messaggio::Muovi { x, y } => { println!("Muovi in direzione x {x} e in direzione y {y}"); } Messaggio::Scrivi(text) => { println!("Messaggio di testo: {text}"); } Messaggio::CambiaColore(r, g, b) => { println!("Cambia colore in rosso {r}, verde {g}, e blu {b}"); } } }
Questo codice stamperà Cambia colore in rosso 0, verde 160 e blu 255. Prova a
modificare il valore di msg per vedere l’esecuzione del codice degli altri
rami.
Per le varianti di enum senza dati, come Messaggio::Esci, non possiamo
destrutturare ulteriormente il valore. Possiamo trovare corrispondenze solo sul
valore letterale Messaggio::Esci, e non ci sono variabili in quel pattern.
Per varianti di enum di tipo struct, come Messaggio::Muovi, possiamo usare
un pattern simile a quello che specifichiamo per la corrispondenza con le
struct. Dopo il nome della variante, inseriamo parentesi graffe e poi
elenchiamo i campi con le variabili, in modo da separare i pezzi da usare nel
codice per questo ramo. Qui usiamo la forma abbreviata come abbiamo fatto nel
Listato 19-13.
Per varianti di enum di type tupla, come Messaggio::Scrivi che contiene
una tupla con un elemento e Messaggio::CambiaColore che contiene una tupla con
tre elementi, il pattern è simile a quello che specifichiamo per la
corrispondenza con le tuple. Il numero di variabili nel pattern deve
corrispondere al numero di elementi nella variante che stiamo correlando.
Struct ed Enum Annidate
Finora, i nostri esempi hanno tutti confrontato struct o enum con un solo
livello di profondità, ma la corrispondenza può funzionare anche su elementi
annidati! Ad esempio, possiamo riscrivere il codice nel Listato 19-15 per
supportare i colori RGB e HSV nel messaggio CambiaColore come mostrato nel
Listato 19-16.
enum Colore { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Messaggio { Esci, Muovi { x: i32, y: i32 }, Scrivi(String), CambiaColore(Colore), } fn main() { let msg = Messaggio::CambiaColore(Colore::Hsv(0, 160, 255)); match msg { Messaggio::CambiaColore(Colore::Rgb(r, g, b)) => { println!("Cambia colore in rosso {r}, verde {g}, e blu {b}"); } Messaggio::CambiaColore(Colore::Hsv(h, s, v)) => { println!("Cambia colore in tonalità {h}, saturazione {s}, valore {v}"); } _ => (), } }
Il pattern del primo ramo nell’espressione match corrisponde a una variante
dell’enum Messaggio::CambiaColore che contiene una variante Colore::Rgb;
quindi il pattern si lega ai tre valori i32 interni. Anche il pattern del
secondo ramo corrisponde a una variante dell’enum Messaggio::CambiaColore,
ma l’enum interno corrisponde invece a Colore::Hsv. Possiamo specificare
queste condizioni complesse in un’unica espressione match, anche se sono
coinvolte due enum.
Struct e Tuple
Possiamo combinare, abbinare e annidare pattern di destrutturazione in modi ancora più complessi. L’esempio seguente mostra una destrutturazione complessa in cui annidiamo struct e tuple all’interno di una tupla e destrutturiamo tutti i valori primitivi:
fn main() { struct Punto { x: i32, y: i32, } let ((piedi, pollici), Punto { x, y }) = ((3, 10), Punto { x: 3, y: -10 }); }
Questo codice ci permette di scomporre i type complessi nelle loro componenti in modo da poter utilizzare i valori che ci interessano separatamente.
La destrutturazione con i pattern è un modo comodo per utilizzare parti di valori, come il valore di ciascun campo in una struct, separatamente l’uno dall’altro.
Ignorare Valori In un Pattern
Hai visto che a volte è utile ignorare i valori in un pattern, come
nell’ultimo ramo di un match, per ottenere un pigliatutto che in realtà non fa
nulla ma tiene conto di tutti i valori possibili rimanenti. Esistono diversi
modi per ignorare interi valori o parti di valori in un pattern: utilizzare il
pattern _ (che hai visto), utilizzare il pattern _ all’interno di un
altro pattern, utilizzare un nome che inizia con un trattino basso o
utilizzare .. per ignorare le parti rimanenti di un valore. Esploriamo come e
perché utilizzare ciascuno di questi pattern.
Un Intero Valore con _
Abbiamo utilizzato il trattino basso come pattern pigliatutto che corrisponde
a qualsiasi valore ma non si lega al valore. Questo è particolarmente utile come
ultimo ramo in un’espressione match , ma possiamo utilizzarlo anche in
qualsiasi pattern, inclusi i parametri di funzione, come mostrato nel Listato
19-17.
fn foo(_: i32, y: i32) { println!("Questa funzione utilizza solo il parametro y: {y}"); } fn main() { foo(3, 4); }
_ in una firma di funzioneQuesto codice ignorerà completamente il valore 3 passato come primo argomento
e stamperà Questa funzione usa solo il parametro y: 4.
Nella maggior parte dei casi, quando non è più necessario un particolare parametro di funzione, si modifica la firma in modo che non includa il parametro non utilizzato. Ignorare un parametro di funzione può essere particolarmente utile nei casi in cui, ad esempio, si sta implementando un trait per il quale è necessaria una certa firma di type, ma il corpo della funzione nell’implementazione non richiede uno dei parametri. Si evita così di ricevere un avviso del compilatore sui parametri di funzione non utilizzati, come si farebbe utilizzando un nome.
Parti di un Valore Con un _ Annidato
Possiamo anche usare _ all’interno di un altro pattern per ignorare solo una
parte di un valore, ad esempio, quando vogliamo testare solo una parte di un
valore ma non abbiamo bisogno delle altre parti nel codice corrispondente che
vogliamo eseguire. Il Listato 19-18 mostra il codice responsabile della gestione
del valore di un’impostazione. I requisiti aziendali prevedono che l’utente non
possa sovrascrivere una personalizzazione esistente di un’impostazione, ma possa
annullarla e assegnarle un valore se è attualmente non impostata.
fn main() { let mut val_impostazioni = Some(5); let nuovo_val_impostazioni = Some(10); match (val_impostazioni, nuovo_val_impostazioni) { (Some(_), Some(_)) => { println!("Non è possibile sovrascrivere un valore personalizzato esistente"); } _ => { val_impostazioni = nuovo_val_impostazioni; } } println!("Valore impostazioni è {val_impostazioni:?}"); }
Some quando non è necessario utilizzare il valore all’interno di SomeQuesto codice stamperà Non è possibile sovrascrivere un valore personalizzato esistente e poi Valore impostazioni è Some(5). Nel primo ramo di
corrispondenza, non è necessario abbinare o utilizzare i valori all’interno di
una delle varianti Some, ma è necessario testare il caso in cui
val_impostazioni e nuovo_val_impostazioni siano la variante Some. In tal
caso, stampiamo il motivo della mancata modifica di val_impostazioni, e quindi
non viene modificato.
In tutti gli altri casi (se val_impostazioni o nuovo_val_impostazioni è
None) espressi dal pattern _ nel secondo ramo, vogliamo consentire a
nuovo_val_impostazioni di diventare val_impostazioni.
Possiamo anche utilizzare il trattino basso in più punti all’interno di un pattern per ignorare valori specifici. Il Listato 19-19 mostra un esempio di come ignorare il secondo e il quarto valore in una tupla di cinque elementi.
fn main() { let numeri = (2, 4, 8, 16, 32); match numeri { (primo, _, terzo, _, quinto) => { println!("Alcuni numeri: {primo}, {terzo}, {quinto}"); } } }
Questo codice stamperà Alcuni numeri: 2, 8, 32, e i valori 4 e 16 saranno
ignorati.
Una Variabile Inutilizzata Iniziando il Suo Nome con _
Se si crea una variabile ma non la si utilizza da nessuna parte, Rust di solito genera un avviso perché una variabile inutilizzata potrebbe essere un bug. Tuttavia, a volte è utile poter creare una variabile che non si utilizzerà ancora, ad esempio quando si sta realizzando un prototipo o si è nelle prime fasi di un progetto. In questa situazione, puoi dire a Rust di non avvisarti della variabile inutilizzata facendo iniziare il nome della variabile con un trattino basso. Nel Listato 19-20, creiamo due variabili inutilizzate, ma quando compiliamo questo codice, dovremmo ricevere un avviso solo per una di esse.
fn main() { let _x = 5; let y = 10; }
Qui, riceviamo un avviso sul mancato utilizzo della variabile y, ma non
riceviamo un avviso sul mancato utilizzo di _x.
Nota che c’è una sottile differenza tra l’utilizzo di solo _ e l’utilizzo di
un nome che inizia con un trattino basso. La sintassi _x vincola comunque il
valore alla variabile, mentre _ non lo vincola affatto. Per mostrare un caso
in cui questa distinzione è importante, il Listato 19-21 ci fornirà un errore.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("trovata una stringa");
}
println!("{s:?}");
}Riceveremo un errore perché il valore s verrà comunque spostato in _s, il
che ci impedisce di utilizzare nuovamente s. Tuttavia, l’utilizzo del trattino
basso da solo non vincola mai il valore. Il Listato 19-22 verrà compilato senza
errori perché s non viene spostato in _.
fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("trovata una stringa"); } println!("{s:?}"); }
Questo codice funziona perfettamente perché non vincola mai s a nulla; non
viene spostato.
Parti Rimanenti di un Valore con ..
Con valori composti da molte parti, possiamo usare la sintassi .. per usare
parti specifiche e ignorare il resto, evitando la necessità di elencare trattini
bassi per ogni valore ignorato. Il pattern .. ignora qualsiasi parte di un
valore che non abbiamo corrisposto esplicitamente nel resto del pattern. Nel
Listato 19-23, abbiamo una struct Punto che contiene coordinate nello spazio
tridimensionale. Nell’espressione match, vogliamo operare solo sulla
coordinata x e ignorare i valori nei campi y e z.
fn main() { struct Punto { x: i32, y: i32, z: i32, } let origine = Punto { x: 0, y: 0, z: 0 }; match origine { Punto { x, .. } => println!("x è {x}"), } }
Punto tranne x usando ..Elenchiamo il valore x e poi includiamo semplicemente il pattern ...
Questo è più veloce che dover elencare y: _ e z: _, soprattutto quando
lavoriamo con struct che hanno molti campi in situazioni in cui solo uno o due
campi sono rilevanti.
La sintassi .. si espanderà a tutti i valori necessari. Il Listato 19-24
mostra come usare .. con una tupla.
fn main() { let numeri = (2, 4, 8, 16, 32); match numeri { (primo, .., ultimo) => { println!("Alcuni numeri: {primo}, {ultimo}"); } } }
In questo codice, il primo e l’ultimo valore vengono confrontati con primo e
ultimo. .. corrisponderà e ignorerà tutto ciò che si trova nel mezzo.
Tuttavia, l’utilizzo di .. deve essere univoco. Se non è chiaro quali valori
siano destinati alla corrispondenza e quali debbano essere ignorati, Rust
restituirà un errore. Il Listato 19-25 mostra un esempio di utilizzo ambiguo di
.., che quindi non verrà compilato.
fn main() {
let numeri = (2, 4, 8, 16, 32);
match numeri {
(.., secondo, ..) => {
println!("Alcuni numeri: {secondo}")
},
}
}.. in modo ambiguoQuando compiliamo questo esempio, otteniamo questo errore:
$ cargo run
Compiling patterns v0.1.0 (file:///progetti/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:23
|
5 | (.., secondo, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
È impossibile per Rust determinare quanti valori nella tupla ignorare prima di
abbinare un valore con secondo e poi quanti altri valori ignorare
successivamente. Questo codice potrebbe significare che vogliamo ignorare 2,
associare secondo a 4 e quindi ignorare 8, 16 e 32; oppure che
vogliamo ignorare 2 e 4, associare secondo a 8 e quindi ignorare 16 e
32; e così via. Il nome della variabile secondo non ha alcun significato
particolare in Rust, quindi otteniamo un errore del compilatore perché usare
.. in due punti come questo è ambiguo.
Aggiungere Istruzioni Condizionali con le Match Guard
Una match guard è una condizione if aggiuntiva, specificata dopo il
pattern in un ramo match, che deve corrispondere affinché quel ramo venga
scelto. Le match guard sono utili per esprimere idee più complesse di quelle
consentite dal solo pattern. Nota, tuttavia, che sono disponibili solo nelle
espressioni match, non nelle espressioni if let o while let.
La condizione può utilizzare variabili create nel pattern. Il Listato 19-26
mostra un match in cui il primo ramo ha il pattern Some(x) e ha anche una
match guard if x % 2 == 0 (che sarà true se il numero è pari).
fn main() { let num = Some(4); match num { Some(x) if x % 2 == 0 => println!("Il numero {x} è pari"), Some(x) => println!("Il numero {x} è dispari"), None => (), } }
Questo esempio stamperà Il numero 4 è pari. Quando num viene confrontato con
il pattern nel primo ramo, corrisponde perché Some(4) corrisponde a
Some(x). Quindi la match guard controlla se il resto della divisione di x
per 2 è uguale a 0 e, poiché lo è, viene selezionato il primo ramo.
Se num fosse stato Some(5), la match guard nel primo ramo sarebbe stata
false perché il resto di 5 diviso 2 è 1, che è diverso da 0. Rust passerebbe
quindi al secondo ramo, che corrisponderebbe perché il secondo ramo non ha una
match guard e quindi corrisponde a qualsiasi variante di Some.
Non c’è modo di esprimere la condizione if x % 2 == 0 all’interno di un
pattern, quindi la match guard ci dà la possibilità di esprimere questa
logica. Lo svantaggio di questa espressività aggiuntiva è che il compilatore non
cerca di verificare l’esaustività quando sono coinvolte espressioni con match
guard.
Nel Listato 19-11, avevamo accennato alla possibilità di utilizzare le match
guard per risolvere il nostro problema di oscuramento della variabili. Ricorda
che avevamo creato una nuova variabile all’interno del pattern
nell’espressione match invece di utilizzare la variabile esterna a match.
Questa nuova variabile ci impediva di testare il valore della variabile esterna.
Il Listato 19-27 mostra come possiamo usare una match guard per risolvere
questo problema.
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Ricevuto 50"), Some(n) if n == y => println!("Corrisponde, n = {n}"), _ => println!("Caso predefinito, x = {x:?}"), } println!("alla fine: x = {x:?}, y = {y}"); }
Questo codice ora stamperà Caso predefinito, x = Some(5). Il pattern nel
secondo ramo di corrispondenza non introduce una nuova variabile y che
oscurerebbe la y esterna, il che significa che possiamo usare la y esterna
nella match guard. Invece di specificare il pattern come Some(y), che
avrebbe oscurato la y esterna, specifichiamo Some(n). Questo crea una nuova
variabile n che non oscura nulla perché non esiste alcuna variabile n al di
fuori del match.
La match guard if n == y non è un pattern e quindi non introduce nuove
variabili. Questa y è la y esterna anziché una nuova y che la oscura, e
possiamo cercare un valore che abbia lo stesso valore della y esterna
confrontando n con y.
È anche possibile utilizzare l’operatore or | in una match guard per
specificare più pattern; la match guard si applicherà a tutti i pattern.
Il Listato 19-28 mostra la precedenza quando si combina un pattern che
utilizza | con una match guard. La parte importante di questo esempio è che
la match guard if y si applica a 4, 5 e 6, anche se potrebbe sembrare
che if y si applichi solo a 6.
fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("sì"), _ => println!("no"), } }
La condizione di corrispondenza stabilisce che il ramo corrisponde solo se il
valore di x è uguale a 4, 5 o 6 e se y è true. Quando questo codice
viene eseguito, il pattern del primo ramo corrisponde perché x è 4, ma la
match guard if y è false, quindi il primo ramo non viene scelto. Il codice
passa al secondo ramo, che corrisponde, e questo programma stampa no. Il
motivo è che la condizione if si applica all’intero pattern 4 | 5 | 6, non
solo all’ultimo valore 6. In altre parole, la precedenza di una match guard
rispetto a un pattern si comporta in questo modo:
(4 | 5 | 6) if y => ...
piuttosto che in questo modo:
4 | 5 | (6 if y) => ...
Dopo aver eseguito il codice, il comportamento della precedenza è evidente: se
la match guard fosse stata applicata solo al valore finale nell’elenco di
valori specificato utilizzando l’operatore |, il ramo avrebbe trovato una
corrispondenza e il programma avrebbe stampato sì.
Utilizzare il Binding @
L’operatore at @ ci consente di creare una variabile che contiene un valore
mentre stiamo testando quel valore per una corrispondenza con il pattern. Nel
Listato 19-29, vogliamo verificare che il campo id di Messaggio::Ciao sia
compreso nell’intervallo 3..=7. Vogliamo anche associare il valore alla
variabile id in modo da poterlo utilizzare nel codice associato al ramo.
fn main() { enum Messaggio { Ciao { id: i32 }, } let msg = Messaggio::Ciao { id: 5 }; match msg { Messaggio::Ciao { id: id @ 3..=7 } => { println!("Trovato un id nell'intervallo: {id}") } Messaggio::Ciao { id: 10..=12 } => { println!("Trovato un id in un altro intervallo") } Messaggio::Ciao { id } => println!("Trovato un altro id: {id}"), } }
@ per associare un valore in un pattern e testarloQuesto esempio stamperà Trovato un id nell'intervallo: 5. Specificando id @
prima dell’intervallo 3..=7, catturiamo qualsiasi valore corrispondente
all’intervallo in una variabile denominata id, verificando anche che il valore
corrisponda al pattern dell’intervallo.
Nel secondo ramo, dove abbiamo specificato solo un intervallo nel pattern, il
codice associato al ramo non ha una variabile che contenga il valore effettivo
del campo id. Il valore del campo id avrebbe potuto essere 10, 11 o 12, ma
il codice associato a quel pattern non sa quale sia. Il codice del pattern
non è in grado di utilizzare il valore del campo id, perché non abbiamo
salvato il valore id in una variabile.
Nell’ultimo ramo, dove abbiamo specificato una variabile senza intervallo,
abbiamo il valore disponibile da utilizzare nel codice del ramo in una variabile
denominata id. Il motivo è che abbiamo utilizzato la sintassi abbreviata del
campo struct. Ma non abbiamo applicato alcun test al valore del campo id in
questo ramo, come abbiamo fatto con i primi due rami: qualsiasi valore
corrisponderebbe a questo pattern.
L’utilizzo di @ ci consente di testare un valore e salvarlo in una variabile
all’interno di un pattern.
Riepilogo
I pattern di Rust sono molto utili per distinguere tra diversi tipi di dati.
Quando vengono utilizzati nelle espressioni match, Rust garantisce che i
pattern coprano ogni valore possibile, altrimenti il programma non verrà
compilato. I pattern nelle dichiarazioni let e nei parametri di funzione
rendono questi costrutti più utili, consentendo la destrutturazione dei valori
in parti più piccole e l’assegnazione di tali parti a variabili. Possiamo creare
pattern semplici o complessi in base alle nostre esigenze.
Successivamente, nel penultimo capitolo del libro, esamineremo alcuni aspetti avanzati di una varietà di funzionalità di Rust.
Funzionalità Avanzate
A questo punto, hai imparato le parti più comunemente usate del linguaggio di programmazione Rust. Prima di fare un altro progetto, nel Capitolo 21, esamineremo alcuni aspetti del linguaggio che potresti incontrare di tanto in tanto, ma che potresti non usare tutti i giorni. Puoi usare questo capitolo come riferimento quando incontri qualcosa di sconosciuto. Le caratteristiche trattate qui sono utili in situazioni molto specifiche. Anche se potresti non usarle spesso, vogliamo assicurarci che tu abbia una comprensione di tutte le funzionalità che Rust ha da offrire.
In questo capitolo, tratteremo:
- Unsafe Rust: come rinunciare ad alcune delle garanzie di Rust e assumersi la responsabilità di mantenere manualmente tali garanzie
- Trait avanzati: type associati, type default dei parametri, sintassi completamente qualificata, supertrait e il modello newtype in relazione ai trait
- Type avanzati: approfondimento sul modello newtype, type alias, il type never e type a dimensione dinamica
- Funzioni avanzate e chiusure: puntatori a funzione e restituzione di chiusure
- Macro: modi per definire codice che definisce altro codice durante la compilazione
È un insieme variegato di funzionalità di Rust con qualcosa per tutti! Iniziamo!
Unsafe Rust
Tutto il codice di cui abbiamo parlato finora ha avuto le garanzie di sicurezza della memoria di Rust applicate durante la compilazione. Però, Rust ha un secondo linguaggio nascosto al suo interno che non applica queste garanzie: si chiama unsafe Rust e funziona come il Rust regolare, ma ci dà dei superpoteri extra.
Unsafe Rust esiste perché, per natura, l’analisi statica è conservativa. Quando il compilatore cerca di capire se il codice rispetta le garanzie, è meglio per lui rifiutare qualche programma valido piuttosto che accettarne uno non valido. Anche se il codice potrebbe andare bene, se il compilatore Rust non ha abbastanza informazioni per esserne sicuro, rifiuterà di compilare il codice. In questi casi, puoi usare codice unsafe per dire al compilatore: “Fidati, so cosa sto facendo.” Attenzione però, usare unsafe Rust è un rischio tuo: se usi codice unsafe in modo sbagliato, possono succedere problemi legati alla sicurezza della memoria, tipo il de-referenziamento di puntatori nulli.
Un altro motivo per cui Rust ha un alter ego unsafe è che l’hardware del computer è intrinsecamente unsafe. Se Rust non ti permettesse di fare operazioni unsafe, non potresti fare certi compiti. Rust deve permetterti di fare programmazione di sistema a basso livello, tipo interagire direttamente con il sistema operativo o persino scrivere il tuo sistema operativo. La programmazione di sistema a basso livello è uno degli obiettivi del linguaggio. Vediamo cosa si può fare con unsafe Rust e come farlo.
Usare i Superpoteri Unsafe
Per passare a unsafe Rust, usa la parola chiave unsafe e poi inizia un nuovo
blocco dove metti il codice unsafe. Ci sono cinque azioni che puoi fare in
unsafe Rust che non puoi fare in safe Rust, che chiamiamo superpoteri
unsafe. Questi superpoteri includono la possibilità di:
- De-referenziare un puntatore grezzo.
- Chiamare una funzione o un metodo unsafe.
- Accedere o modificare una variabile statica mutabile.
- Implementare un trait unsafe.
- Accedere ai campi di
union.
È importante capire che unsafe non disabilita il borrow checker né gli altri
controlli di sicurezza di Rust: se usi un reference in codice unsafe, esso
verrà comunque controllato. La parola chiave unsafe ti dà solo accesso a
queste cinque caratteristiche che non sono controllate dal compilatore
nell’aspetto della sicurezza della memoria. Avrai comunque un certo grado di
sicurezza dentro un blocco unsafe.
Inoltre, unsafe non significa che il codice dentro il blocco sia
necessariamente pericoloso o che sicuramente avrà problemi di sicurezza della
memoria: l’intento è che tu, programmatore, garantisca che il codice dentro un
blocco unsafe accederà alla memoria in modo valido.
Gli esseri umani sbagliano, possono fare errori, ma richiedendo che queste
cinque operazioni unsafe siano usate dentro blocchi annotati con unsafe,
saprai che ogni errore legato alla sicurezza della memoria deve per forza essere
dentro un blocco unsafe. Mantieni i blocchi unsafe piccoli; ne sarai
contento quando dovrai cercare bug di memoria.
Per isolare il codice unsafe il più possibile, è meglio racchiuderlo in
un’astrazione safe e offrire un’API safe, di cui parleremo più avanti nel
capitolo quando esamineremo funzioni e metodi unsafe. Parti della libreria
standard sono implementate come astrazioni safe su codice unsafe che è stato
controllato. Racchiudere il codice unsafe in un’astrazione safe evita che
gli usi di unsafe vadano a infiltrarsi in tutte le parti del codice dove tu o
i tuoi utenti potreste voler usare la funzionalità scritta con codice unsafe,
perché usare un’astrazione safe è sicuro.
Ora vediamo uno per uno i cinque superpoteri unsafe. Daremo anche un’occhiata ad alcune astrazioni che forniscono una interfaccia safe a codice unsafe.
De-referenziare un Puntatore Grezzo
Nel Capitolo 4, nella sezione “Reference Pendenti”, abbiamo detto che il compilatore si assicura che i reference siano
sempre validi. Unsafe Rust ha due nuovi type chiamati puntatori grezzi
(raw pointer) simili ai reference. Come con i reference, i puntatori
grezzi possono essere immutabili o mutabili e si scrivono *const T e *mut T
rispettivamente. L’asterisco non è l’operatore di de-referenziazione; fa parte
del nome del type. Nel contesto dei puntatori grezzi, immutabile significa
che il puntatore non può essere assegnato direttamente dopo essere stato
de-referenziato.
Diversamente da reference e puntatori intelligenti, i puntatori grezzi:
- Possono ignorare le regole di borrowing avendo sia puntatori immutabili che mutabili o molteplici puntatori mutabili allo stesso dato
- Non è garantito che puntino a memoria valida
- Possono essere nulli
- Non fanno nessuna pulizia automatica
Rinunciando a far rispettare queste garanzie da parte di Rust, puoi rinunciare alla sicurezza garantita in cambio di maggiori prestazioni o della possibilità di interfacciarti con altri linguaggi o hardware dove le garanzie di Rust non valgono.
Il Listato 20-1 mostra come creare un puntatore grezzo immutabile e uno mutabile.
fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; }
Nota che in questo codice non usiamo la parola chiave unsafe. Possiamo creare
puntatori grezzi in codice safe; non possiamo però de-referenziarli fuori da
un blocco unsafe, come vedremo tra poco.
Abbiamo creato puntatori grezzi usando gli operatori di prestito grezzi (raw
borrow): &raw const num crea un puntatore grezzo immutabile *const i32,
mentre &raw mut num crea un puntatore grezzo mutabile *mut i32. Siccome li
abbiamo creati direttamente da una variabile locale, sappiamo che questi
puntatori grezzi sono validi, ma non possiamo fare questa assunzione per
qualsiasi puntatore grezzo.
Per dimostrarlo, creiamo un puntatore grezzo di cui non possiamo essere così
certi che sia valido, usando la parola chiave as per fare un cast invece di
usare l’operatore di prestito grezzo. Il Listato 20-2 mostra come creare un
puntatore grezzo verso una posizione arbitraria in memoria. Usare un indirizzo
di memoria arbitrario è un comportamento indefinito: potrebbe esserci qualche
dato a quell’indirizzo o magari no, il compilatore potrebbe ottimizzare il
codice e evitare l’accesso alla memoria, oppure il programma potrebbe terminare
con un errore accesso non valido alla memoria. Di solito non c’è una buona
ragione per scrivere codice così, specialmente quando si può usare un operatore
di prestito grezzo, ma è possibile farlo.
fn main() { let indirizzo = 0x012345usize; let r = indirizzo as *const i32; }
Ricorda che possiamo creare puntatori grezzi in codice safe, però non possiamo
de-referenziarli per leggere i dati a cui puntano. Nel Listato 20-3 usiamo
l’operatore di de-referenziazione * su un puntatore grezzo che richiede un
blocco unsafe.
fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; unsafe { println!("r1 è: {}", *r1); println!("r2 è: {}", *r2); } }
Creare un puntatore non fa danno; è solo quando proviamo a leggere il valore a cui punta che potremmo avere a che fare con un valore invalido.
Nota anche che nei Listati 20-1 e 20-3 abbiamo creato puntatori grezzi *const i32 e *mut i32 dove entrambi puntavano alla stessa locazione di memoria, dove
si trova num. Se invece avessimo provato a creare un reference immutabile e
uno mutabile a num, il codice non sarebbe stato compilato perché le regole di
ownership di Rust non permettono un reference mutabile contemporaneamente a
reference immutabili. Con i puntatori grezzi possiamo creare un puntatore
mutabile e uno immutabile sugli stessi dati in memoria e modificarli tramite il
puntatore mutabile, creando potenzialmente una data race. Fai attenzione!
Con tutti questi pericoli, perché mai usare i puntatori grezzi? Un uso molto comune è quando ci si interfaccia con codice in C, come vedremo nella prossima sezione. Un altro caso è quando si costruiscono astrazioni safe che il borrow checker non capisce. Introdurremo le funzioni unsafe e poi vedremo un esempio di astrazione safe che usa codice unsafe.
Chiamare una Funzione o Metodo Unsafe
Il secondo tipo di operazione che puoi fare in un blocco unsafe è chiamare
funzioni unsafe. Le funzioni e i metodi unsafe appaiono esattamente come
normali funzioni e metodi, ma hanno unsafe prima della definizione. La parola
chiave unsafe qui indica che la funzione ha dei requisiti che dobbiamo
rispettare quando la chiamiamo, perché Rust non può garantire che li
rispettiamo. Chiamando una funzione unsafe dentro un blocco unsafe stiamo
dicendo che abbiamo letto la documentazione di quella funzione e ci assumiamo la
responsabilità di rispettarne i contratti.
Ecco una funzione unsafe chiamata pericolosa che non fa nulla nel corpo:
fn main() { unsafe fn pericolosa() {} unsafe { pericolosa(); } }
Dobbiamo chiamare la funzione pericolosa dentro un blocco unsafe separato.
Se proviamo a chiamarla senza il blocco unsafe, avremo un errore:
$ cargo run
Compiling esempio-unsafe v0.1.0 (file:///progetti/esempio-unsafe)
error[E0133]: call to unsafe function `pericolosa` is unsafe and requires unsafe block
--> src/main.rs:5:5
|
5 | pericolosa();
| ^^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `esempio-unsafe` (bin "esempio-unsafe") due to 1 previous error
Con il blocco unsafe, stiamo dicendo a Rust che abbiamo letto la documentazione della funzione, sappiamo come usarla correttamente e abbiamo verificato di rispettarne il contratto.
Per fare operazioni unsafe dentro una funzione unsafe, serve comunque un blocco unsafe anche dentro il corpo, e il compilatore ti avvertirà se lo dimentichi. Questo ci aiuta a tenere i blocchi unsafe più piccoli possibile, perché spesso non servono in tutto il corpo della funzione.
Creare un’Astrazione Safe su Codice Unsafe
Solo perché una funzione contiene codice unsafe non significa che debba essere
tutta marcata come unsafe. Infatti, incapsulare codice unsafe in una
funzione safe è una pratica comune. Come esempio, studiamo la funzione
split_at_mut della libreria standard, che richiede un po’ di codice unsafe.
Vedremo come potremmo implementarla. Questo metodo safe è definito per slice
mutabili: prende una slice e la divide in due a partire da un indice passato
come argomento. Il Listato 20-4 mostra come usare split_at_mut.
fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = r.split_at_mut(3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
split_at_mutNon possiamo implementare questa funzione usando solo safe Rust. Una prova
potrebbe essere il Listato 20-5, che non si compila. Per semplicità,
implementeremo split_at_mut come funzione invece che come metodo, e solo per
slice di i32, non per un type generico T.
fn split_at_mut(valori: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = valori.len();
assert!(mid <= len);
(&mut valori[..mid], &mut valori[mid..])
}
fn main() {
let mut vettore = vec![1, 2, 3, 4, 5, 6];
let (sinistra, destra) = split_at_mut(&mut vettore, 3);
}split_at_mut usando solo safe RustQuesta funzione prima prende la lunghezza totale della slice. Poi si assicura che l’indice passato stia dentro la slice, verificando che sia minore o uguale alla lunghezza. Questa asserzione significa che se passiamo un indice maggiore della lunghezza, la funzione farà panic prima di usare quell’indice.
Poi ritorna due slice mutabili in una tupla: una dalla parte iniziale fino a
mid e l’altra da mid fino alla fine della slice.
Quando proviamo a compilare il codice in Listato 20-5, otteniamo un errore:
$ cargo run
Compiling esempio-unsafe v0.1.0 (file:///progetti/esempio-unsafe)
error[E0499]: cannot borrow `*valori` as mutable more than once at a time
--> src/main.rs:7:31
|
2 | fn split_at_mut(valori: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
7 | (&mut valori[..mid], &mut valori[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*valori` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `esempio-unsafe` (bin "esempio-unsafe") due to 1 previous error
Il borrow checker di Rust non capisce che stiamo prendendo due parti diverse della stessa slice; sa solo che stiamo prendendo la stessa slice due volte. Prendere in prestito parti diverse di una stessa slice è fondamentalmente non problematico perché le due slice non si sovrappongono, ma Rust non è abbastanza intelligente da capire questo. Quando sappiamo che il codice va bene, ma Rust no, è ora di usare codice unsafe.
Il Listato 20-6 mostra come usare un blocco unsafe, un puntatore grezzo e
alcune chiamate a funzioni unsafe per far funzionare split_at_mut.
use std::slice; fn split_at_mut(valori: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = valori.len(); let ptr = valori.as_mut_ptr(); assert!(mid < len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut vector = vec![1, 2, 3, 4, 5, 6]; let (left, right) = split_at_mut(&mut vector, 3); }
split_at_mutRicorda dalle sezione “Il Type Slice” del
capitolo 4 che una slice è un puntatore a un dato e la sua lunghezza. Usiamo
il metodo len per avere la lunghezza e il metodo as_mut_ptr per accedere al
puntatore grezzo della slice. In questo caso, poiché abbiamo una slice
mutabile di i32, as_mut_ptr ritorna un puntatore grezzo di type *mut i32
che conserviamo nella variabile ptr.
Manteniamo l’asserzione che mid stia dentro la slice. Poi arriviamo al
codice unsafe: la funzione slice::from_raw_parts_mut prende un puntatore
grezzo e una lunghezza e crea una slice. La usiamo per creare una slice che
parte da ptr ed è lunga mid elementi. Poi chiamiamo il metodo add su ptr
con mid come argomento per ottenere un puntatore grezzo che punta a mid, e
creiamo una slice usando quel puntatore e la lunghezza rimanente dopo mid.
La funzione slice::from_raw_parts_mut è unsafe perché prende un puntatore
grezzo e deve fidarsi che quel puntatore sia valido. Anche il metodo add su
puntatore grezzo è unsafe perché deve fidarsi che la locazione di memoria
puntata sia valida. Per questo abbiamo messo un blocco unsafe attorno alle
nostre chiamate a slice::from_raw_parts_mut e add per poterle chiamare.
Guardando il codice e aggiungendo l’asserzione che mid deve essere minore o
uguale a len, possiamo dire che tutti i puntatori grezzi usati nel blocco
unsafe saranno validi e punteranno a dati nella slice. Questo è un uso
accettabile e appropriato di unsafe.
Nota che non dobbiamo marcare la funzione split_at_mut risultante come
unsafe e possiamo chiamarla da safe Rust. Abbiamo creato un’astrazione
safe su codice unsafe con un’implementazione che usa codice unsafe in modo
safe, perché crea solo puntatori validi dai dati a cui quella funzione ha
accesso.
Al contrario, usare slice::from_raw_parts_mut come nel Listato 20-7
probabilmente terminerebbe con un errore quando si usa la slice. Quel codice
prende una locazione arbitraria di memoria e crea una slice lunga 10.000
elementi.
fn main() { use std::slice; let indirizzo = 0x01234usize; let r = indirizzo as *mut i32; let valori: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; }
Non abbiamo ownership della memoria in quella posizione arbitraria, e non ci
sono garanzie che la slice così creata contenga valori i32 validi. Usare
quei valori come se fosse una slice valida è comportamento indefinito.
Usare Funzioni extern per Chiamare Codice Esterno
A volte il tuo codice Rust potrebbe aver bisogno di interagire con codice
scritto in un altro linguaggio. Per questo, Rust ha la parola chiave extern
che facilita la creazione e l’uso di una interfaccia per funzioni esterne,
abbreviato in FFI (Foreign Function Interface), cioè un modo per un
linguaggio di definire funzioni e consentire a un diverso linguaggio (esterno)
di chiamarle.
Il Listato 20-8 mostra come impostare l’integrazione con la funzione abs dalla
libreria standard di C. Le funzioni dichiarate dentro blocchi extern sono
generalmente unsafe da chiamare da codice Rust, quindi anche i blocchi
extern devono essere marcati come unsafe. Il motivo è che altri linguaggi
non impongono le regole e garanzie di Rust, e Rust non può controllarle, quindi
la responsabilità è del programmatore.
unsafe extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Valore assoluto di -3 secondo C: {}", abs(-3)); } }
extern definita in un altro linguaggioDentro il blocco unsafe extern "C", elenchiamo nomi e firme delle funzioni
esterne di un altro linguaggio che vogliamo chiamare. La parte "C" definisce
quale interfaccia binaria dell’applicazione, abbreviato in ABI (application
binary interface), quella funzione usa: l’ABI definisce come chiamare la
funzione a livello assembly. L’ABI "C" è il più comune ed è l’ABI del
linguaggio C. Informazioni su tutte le ABI supportate da Rust sono disponibili
nella Rust Reference.
Ogni elemento dichiarato dentro un blocco unsafe extern è implicitamente
unsafe. Però, alcune funzioni FFI sono sicure da chiamare. Per esempio, la
funzione abs della libreria standard C non ha considerazioni di sicurezza
della memoria di cui preoccuparsi e sappiamo che può essere chiamata con
qualunque i32. In questi casi possiamo usare la parola chiave safe per dire
che quella funzione specifica è sicura da chiamare anche se si trova dentro un
blocco unsafe extern. Dopo questa modifica, chiamarla non richiede più un
blocco unsafe, come mostra il Listato 20-9.
unsafe extern "C" { safe fn abs(input: i32) -> i32; } fn main() { println!("Valore assoluto di -3 secondo C: {}", abs(-3)); }
unsafe extern e chiamata in maniera sicuraMarcare una funzione come safe non la rende automaticamente sicura! È come una
promessa a Rust che è sicura. Sta comunque a te fare in modo che la promessa sia
mantenuta!
Chiamare Funzioni Rust da Altri Linguaggi
Possiamo anche usare extern per creare un’interfaccia che permetta ad altri
linguaggi di chiamare funzioni Rust. Invece di creare un blocco extern
completo, mettiamo la parola chiave extern e specifichiamo l’ABI da usare
subito prima della parola fn per la funzione interessata. Dobbiamo anche
aggiungere l’annotazione #[unsafe(no_mangle)] per disabilitare il mangling
da parte del compilatore per quella funzione. Il mangling è quando un
compilatore cambia il nome di una funzione in un nome diverso che contiene più
info per altre parti della compilazione, ma è meno leggibile dall’uomo. Ogni
linguaggio compila in modo diverso, quindi per permettere a una funzione Rust di
essere chiamata da altri linguaggi dobbiamo disabilitare il name mangling, ma
questo è unsafe perché potrebbero esserci collisioni di nomi tra varie
librerie, quindi sta a noi scegliere un nome sicuro da esportare senza
mangling.
Nell’esempio seguente rendiamo la funzione call_from_c accessibile da codice
C, dopo essere stata compilata in una libreria condivisa e collegata da C:
#![allow(unused)] fn main() { #[unsafe(no_mangle)] pub extern "C" fn call_from_c() { println!("Chiamata una funzione Rust da C!"); } }
Questo uso di extern richiede unsafe solo nell’attributo, non nel blocco
extern.
Accedere o Modificare una Variabile Statica Mutabile
Nel libro finora non abbiamo parlato di variabili globali, che Rust supporta ma che possono dare problemi con le regole di ownership. Se due thread accedono contemporaneamente alla stessa variabile globale mutabile, può succedere una data race.
In Rust, le variabili globali si chiamano variabili static. Il Listato 20-10 mostra un esempio di dichiarazione e uso di una variabile statica con una slice di stringa come valore.
static HELLO_WORLD: &str = "Hello, world!"; fn main() { println!("valore è: {HELLO_WORLD}"); }
Le variabili statiche sono simili alle costanti, di cui abbiamo parlato nella
sezione “Dichiarare le Costanti” del Capitolo 3. I
nomi delle variabili statiche sono, per convenzione, in SNAKE_CASE_MAIUSCOLO.
Le variabili statiche possono contenere solo reference con longevità
'static, quindi il compilatore Rust può ricavarne la lifetime e non serve
annotarla esplicitamente. Accedere a una variabile statica immutabile è sicuro.
Una sottile differenza tra costanti e variabili statiche immutabili è che i
valori in una variabile statica hanno un indirizzo fisso in memoria. Usare quel
valore significa sempre accedere agli stessi dati. Le costanti invece possono
duplicare i dati ogni volta che sono usate. Un’altra differenza è che le
variabili statiche possono essere mutabili. Accedere e modificare variabili
statiche mutabili è unsafe. Il Listato 20-11 mostra come dichiarare, accedere
e modificare una variabile statica mutabile chiamata CONTATORE.
static mut CONTATORE: u32 = 0; /// SAFETY: Chiamarlo da più di un unico thread alla volta è un comportamento /// non definito, *devi* quindi garantire che verra chiamato da un singolo /// thread alla volta unsafe fn aggiungi_a_contatore(inc: u32) { unsafe { CONTATORE += inc; } } fn main() { unsafe { // SAFETY: È chiamato da un singolo thread in `main`. aggiungi_a_contatore(3); println!("CONTATORE: {}", *(&raw const CONTATORE)); } }
Come per le variabili normali, specifichiamo la mutabilità con la parola chiave
mut. Qualsiasi codice che legge o scrive da CONTATORE deve stare dentro un
blocco unsafe. Il codice nel Listato 20-11 viene compilato e stampa
CONTATORE: 3, come ci aspettiamo perché è a singolo thread. Se più thread
accedessero a CONTATORE probabilmente si creerebbero data races, quindi è un
comportamento indefinito. Per questo dobbiamo marcare tutta la funzione come
unsafe e documentarne i limiti di sicurezza, così chi la chiama sa cosa può e
non può fare in sicurezza.
Quando scriviamo una funzione unsafe, è pratica comune scrivere un commento
che inizi con SAFETY per spiegare cosa deve fare chi chiama la funzione per
farla funzionare in sicurezza. Allo stesso modo, quando facciamo un’operazione
unsafe, scriviamo un commento con SAFETY per spiegare come vengono
rispettate le regole di sicurezza.
Il compilatore blocca di default ogni tentativo di creare reference a
variabili statiche mutabili tramite i controlli del linter. Devi quindi o
disabilitare esplicitamente il lint con #[allow(static_mut_refs)] o accedere
alla variabile statica mutabile tramite un puntatore grezzo creato con uno degli
operatori di prestito grezzi. Questo include i casi in cui il reference è
creato in modo invisibile, come quando è usato in println! in quel codice.
Richiedere che i reference alle variabili statiche mutabili siano creati
tramite puntatore grezzo rende più evidente quali sono i requisiti di sicurezza
per usarle.
Con dati mutabili che sono accessibili globalmente, è difficile assicurarsi che non ci siano data race, motivo per cui Rust considera le variabili statiche mutabili unsafe. Quando possibile, è preferibile usare tecniche di concorrenza e puntatori intelligenti thread-safe di cui abbiamo parlato nel Capitolo 16, così il compilatore verifica che l’accesso da thread diversi sia sicuro.
Implementare un Trait Unsafe
Possiamo usare unsafe per implementare un trait unsafe. Un trait è
unsafe quando almeno uno dei suoi metodi ha una proprietà che il compilatore
non può verificare. Dichiariamo un trait unsafe mettendo la parola chiave
unsafe prima di trait e marcando anche l’implementazione del trait come
unsafe, come mostra il Listato 20-12.
unsafe trait Foo { // metodi vanno qui } unsafe impl Foo for i32 { // implementazioni dei metodi vanno qui } fn main() {}
Usando unsafe impl promettiamo che rispetteremo le proprietà che il
compilatore non può verificare.
Per esempio, ricordiamo i trait marcatori Send e Sync di cui abbiamo
parlato nella sezione “Concorrenza Estensibile con Send e
Sync” del Capitolo 16: il compilatore
implementa automaticamente questi trait se i nostri type sono composti solo
da type che implementano Send e Sync. Se implementiamo un type che
contiene un type che non implementa Send o Sync, come i puntatori grezzi
ad esempio, e vogliamo marcare quel type come Send o Sync, dobbiamo usare
unsafe. Rust non può verificare che il nostro type rispetti le garanzie per
poterlo spostare in sicurezza tra thread o essere usato da più thread,
quindi dobbiamo fare quei controlli manualmente e indicarlo con unsafe.
Accedere ai Campi di una Union
L’ultima cosa che si può fare solo con unsafe è accedere ai campi di una
union. Una union è simile a una struct, ma solo uno dei campi dichiarati è
usato in una certa istanza in un dato momento. Le union sono usate soprattutto
per interfacciarsi con le union di codice C. Accedere ai campi di una union
è unsafe perché Rust non può garantire il tipo dei dati conservati in quel
momento nell’istanza di union. Puoi imparare di più sulle union nella Rust
Reference.
Usare Miri per Controllare il Codice Unsafe
Quando scrivi codice unsafe, potresti voler controllare che quello che hai scritto sia davvero sicuro e corretto. Uno dei modi migliori per farlo è usare Miri, uno strumento ufficiale Rust per rilevare comportamenti indefiniti. Mentre il borrow checker è uno strumento statico che lavora durante la compilazione, Miri è uno strumento dinamico che lavora durante l’esecuzione. Controlla il tuo codice eseguendo il programma o i vari test e rilevando quando violi le regole che conosce su come dovrebbe funzionare Rust.
Usare Miri richiede una build nightly di Rust (di cui parleremo più
approfonditamente nell’Appendice G). Puoi installare
sia la versione nightly di Rust che lo strumento Miri digitando rustup +nightly component add miri. Questo non cambia la versione di Rust che usa il
tuo progetto; aggiunge solo lo strumento al tuo sistema per poterlo usare quando
vuoi. Puoi far girare Miri su un progetto digitando cargo +nightly miri run
o cargo +nightly miri test.
Per esempio, guarda cosa succede se lo usiamo con il codice nel Listato 20-7.
$ cargo +nightly miri run
Compiling esempio-unsafe v0.1.0 (file:///progetti/esempio-unsafe)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `/bin/cargo-miri runner target/miri/x86_64-unknown-linux-gnu/debug/esempio-unsafe`
warning: integer-to-pointer cast
--> src/main.rs:6:13
|
6 | let r = indirizzo as *mut i32;
| ^^^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:6:13: 6:34
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:8:35
|
8 | let valori: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:8:35: 8:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 2 warnings emitted
Miri ci avverte correttamente che stiamo facendo un cast da intero a puntatore, che potrebbe essere un problema, ma Miri non può determinare se è un problema perché non conosce l’origine del puntatore. Poi Miri segnala un errore perché il Listato 20-7 ha un comportamento indefinito dovuto a un puntatore pendente. Grazie a Miri, sappiamo che c’è un rischio di comportamento indefinito e possiamo pensare a come mettere in sicurezza il codice. In certi casi Miri può perfino suggerire come correggere gli errori.
Miri non cattura tutto quello che potresti sbagliare scrivendo codice unsafe. È uno strumento di analisi dinamica, quindi cattura solo i problemi nel codice che viene realmente eseguito. Questo significa che devi usarlo insieme a buone tecniche di testing per aumentare la fiducia nel codice unsafe che hai scritto. Miri non copre tutti i possibili modi in cui il tuo codice può essere insicuro.
In altre parole: se Miri rileva un problema, sai che c’è un bug, ma non è detto che se Miri non trova bug, il codice sia sicuro. Però in molti casi aiuta davvero tanto. Prova a farlo girare sugli altri esempi di codice unsafe in questo capitolo e vedi cosa dice!
Puoi saperne di più su Miri nel suo repository GitHub.
Usare il Codice Unsafe Correttamente
Usare unsafe per sfruttare uno dei cinque superpoteri appena visti non è
sbagliato o malvisto, ma è più difficile scrivere codice unsafe corretto
perché il compilatore non può garantire la sicurezza della memoria. Quando hai
una buona ragione per usare codice unsafe, puoi farlo, e avere la marcatura
esplicita unsafe ti aiuta a rintracciare più facilmente la fonte di problemi
quando capitano. Ogni volta che scrivi codice unsafe, puoi usare Miri per
essere più sicuro che il codice scritto rispetti le regole di Rust.
Per una trattazione molto più approfondita su come lavorare efficacemente con
unsafe Rust, leggi la guida ufficiale di Rust per unsafe, il
Rustonomicon.
Trait Avanzati
Abbiamo già visto i trait nella sezione “Definire il Comportamento Condiviso con i Trait” del Capitolo 10, ma non abbiamo trattato i dettagli più avanzati. Ora che sai di più su Rust, possiamo mettere le mani in pasta in certi dettagli più complessi.
Definire Trait con Type Associati
I type associati collegano un type segnaposto con un trait in modo che le definizioni dei metodi del trait possano usare questi segnaposto nelle loro firme. Chi implementa il trait specificherà il type concreto da usare per quella particolare implementazione. In questo modo possiamo definire un trait che usa qualche type senza dover sapere esattamente quali siano fino a quando il trait non verrà implementato.
Abbiamo detto che molte delle funzionalità avanzate di questo capitolo sono usate raramente. I type associati stanno a metà: si usano meno rispetto ad altre funzionalità spiegate nel resto del libro, ma più frequentemente di altre funzionalità in questo capitolo.
Un esempio di trait con un type associato è il trait Iterator della
libreria standard. Il type associato si chiama Item e rappresenta il type
dei valori su cui il type che implementa Iterator itera. La definizione del
trait Iterator è mostrata nel Listato 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Iterator con type associato ItemIl type Item è un segnaposto, e la definizione del metodo next mostra che
restituirà valori di type Option<Self::Item>. Chi implementa il trait
Iterator specifica il type concreto per Item, e il metodo next ritorna
un Option che contiene un valore di quel type.
I type associati potrebbero sembrare simili ai generici, visto che anche
questi ultimi permettono di definire una funzione senza specificare i type.
Per capirne la differenza, vediamo un’implementazione di Iterator su un type
chiamato Contatore che specifica Item come u32:
struct Contatore {
conteggio: u32,
}
impl Contatore {
fn new() -> Contatore {
Contatore { conteggio: 0 }
}
}
impl Iterator for Contatore {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --taglio--
if self.conteggio < 5 {
self.conteggio += 1;
Some(self.conteggio)
} else {
None
}
}
}Questa sintassi ricorda i type generici. Allora perché non definire Iterator
usando solo generici, come mostra il Listato 20-14?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Iterator usando i genericiLa differenza è che usando i generici, come nel Listato 20-14, dobbiamo annotare
i type in ogni implementazione; siccome potremmo anche implementare
Iterator<String> for Contatore o qualsiasi altro type, potremmo avere più
implementazioni di Iterator per Contatore. In altre parole, quando un
trait ha un parametro generico, può essere implementato per un type più
volte, cambiando i type concreti dei parametri generici ogni volta. Quando
usiamo il metodo next su Contatore, dovremmo fornire annotazioni di type
per indicare quale implementazione di Iterator vogliamo usare.
Con i type associati non serve annotare i type perché non possiamo
implementare un trait più volte su uno stesso type. Nel Listato 20-13, con i
type associati, scegliamo il type di Item una sola volta perché c’è una
sola impl Iterator for Contatore. Non serve indicare che vogliamo un iteratore
di u32 ogni volta che chiamiamo next su Contatore.
I type associati diventano parte del contratto del trait: chi implementa il trait deve fornire un type per sostituire il segnaposto. Spesso i type associati hanno nomi che descrivono come saranno usati, ed è buona prassi documentarli nelle API.
Usare Parametri Generici di Default e Sovrascrivere gli Operatori
Quando usiamo type generici, possiamo specificare un type concreto di
default per il type generico. Questo elimina la necessità per chi implementa
il trait di specificare un type concreto se il type di default va bene. Si
specifica un type di default dichiarando il generico con la sintassi
<TypeSegnaposto=TypeConcreto>.
Un ottimo esempio di questa tecnica è la sovrascrittura degli operatori, dove
personalizzi il comportamento di un operatore (come +) in situazioni
particolari.
Rust non permette di creare operatori propri o sovrascrivere operatori
arbitrari. Ma puoi sovrascrivere le operazioni e i trait corrispondenti
elencati in std::ops implementando i trait associati all’operatore. Per
esempio, nel Listato 20-15 sovrascriviamo l’operatore + per sommare due
istanze di Punto. Lo facciamo implementando il trait Add per la struct
Punto.
use std::ops::Add; #[derive(Debug, Copy, Clone, PartialEq)] struct Punto { x: i32, y: i32, } impl Add for Punto { type Output = Punto; fn add(self, altro: Punto) -> Punto { Punto { x: self.x + altro.x, y: self.y + altro.y, } } } fn main() { assert_eq!( Punto { x: 1, y: 0 } + Punto { x: 2, y: 3 }, Punto { x: 3, y: 3 } ); }
Add per sovrascrivere l’operatore + per le istanze di PuntoIl metodo add somma i valori x di due istanze Punto e i valori y di due
istanze Punto per creare un nuovo Punto. Il trait Add ha un type
associato chiamato Output che determina il type restituito dal metodo add.
Il type generico di default in questo codice si trova all’interno del trait
Add. Ecco la sua definizione:
#![allow(unused)] fn main() { trait Add<Rhs=Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
Questo codice dovrebbe sembrarti familiare: un trait con un metodo e un type
associato. La novità è Rhs=Self: questa sintassi si chiama default type
parameters (parametri per type di default). Il parametro generico Rhs
(abbreviazione di right-hand side, lato destro) definisce il type del
parametro rhs nel metodo add. Se non specifichiamo un type concreto per
Rhs nell’implementazione di Add, il type di Rhs di default sarà Self,
il type su cui stiamo implementando Add.
Quando abbiamo implementato Add per Punto, abbiamo usato il default per
Rhs perché volevamo sommare due Punto. Passiamo ora a un esempio di
implementazione del trait Add in cui vogliamo personalizzare il type Rhs
invece di usare il default.
Abbiamo due struct, Millimetri e Metri, che contengono valori in unità
diverse. Questo tipo di “incapsulamento sottile” attorno a un type esistente è
chiamato newtype pattern, di cui parleremo più avanti nella sezione
“Implementare Trait Esterni con il Modello Newtype”. Vogliamo sommare valori in millimetri a valori in metri e far sì che
l’implementazione di Add si occupi di fare la conversione corretta. Possiamo
implementare Add per Millimetri con Metri come Rhs, come mostrato nel
Listato 20-16.
use std::ops::Add;
struct Millimetri(u32);
struct Metri(u32);
impl Add<Metri> for Millimetri {
type Output = Millimetri;
fn add(self, altro: Metri) -> Millimetri {
Millimetri(self.0 + (altro.0 * 1000))
}
}Add su Millimetri per sommare Millimetri con MetriPer sommare Millimetri e Metri, specifichiamo impl Add<Metri> per
impostare il valore del parametro di type Rhs invece di usare il default
Self.
Userai i type di default per i parametri in due modi principali:
- Per estendere un type senza rompere il codice esistente
- Per permettere personalizzazioni in casi specifici che la maggior parte degli utenti non userà
Il trait Add della libreria standard è un esempio del secondo punto: di
solito si sommano due type uguali, ma il trait Add permette di
personalizzare questo comportamento. L’uso di un type di default come
parametro nella definizione di Add significa che non devi specificare quel
parametro extra la maggior parte delle volte, riducendo il codice ripetitivo e
facilitandone l’uso.
Il primo punto è simile ma all’opposto: se vuoi aggiungere un type come parametro a un trait esistente, puoi dargli un default per permettere l’estensione della funzionalità del trait senza rompere il codice esistente.
Disambiguare Tra Metodi Con lo Stesso Nome
Nulla in Rust vieta ad un trait di avere metodi che hanno lo stesso nome di metodi in un altro trait. E Rust non ti impedisce di implementare entrambi i trait su di un type. È possibile anche definire un metodo sul type con lo stesso nome di un metodo del trait.
Quando chiami metodi con lo stesso nome devi indicare a Rust quale vuoi usare.
Considera il codice nel Listato 20-17, dove sono definiti due trait, Pilota
e Mago, entrambi con un metodo chiamato vola. Entrambi i trait sono
implementati su un type Umano, in cui è già definito un metodo vola. Ogni
metodo vola fa qualcosa di diverso.
trait Pilota { fn vola(&self); } trait Mago { fn vola(&self); } struct Umano; impl Pilota for Umano { fn vola(&self) { println!("Qui parla il capitano."); } } impl Mago for Umano { fn vola(&self) { println!("Sali!"); } } impl Umano { fn vola(&self) { println!("*sbatte furiosamente le braccia*"); } } fn main() {}
vola implementati sul type Umano, e un metodo vola definito direttamente su UmanoQuando chiamiamo vola su un’istanza Umano, come impostazione predefinita il
compilatore chiama il metodo definito direttamente sul type, come mostrato nel
Listato 20-18.
trait Pilota { fn vola(&self); } trait Mago { fn vola(&self); } struct Umano; impl Pilota for Umano { fn vola(&self) { println!("Qui parla il capitano."); } } impl Mago for Umano { fn vola(&self) { println!("Sali!"); } } impl Umano { fn vola(&self) { println!("*sbatte furiosamente le braccia*"); } } fn main() { let persona = Umano; persona.vola(); }
vola su un’istanza di UmanoQuesto codice stampa *sbatte furiosamente le braccia*, mostrando che Rust
chiama il metodo vola definito direttamente su Umano.
Per chiamare i metodi vola dal trait Pilota o Mago serve una sintassi
più esplicita per indicare quale metodo si intende. Il Listato 20-19 mostra
questa sintassi.
trait Pilota { fn vola(&self); } trait Mago { fn vola(&self); } struct Umano; impl Pilota for Umano { fn vola(&self) { println!("Qui parla il capitano."); } } impl Mago for Umano { fn vola(&self) { println!("Sali!"); } } impl Umano { fn vola(&self) { println!("*sbatte furiosamente le braccia*"); } } fn main() { let persona = Umano; Pilota::vola(&persona); Mago::vola(&persona); persona.vola(); }
vola di quale trait si vuole chiamareSpecificare il nome del trait prima del metodo chiarisce a Rust quale
implementazione di vola vogliamo chiamare. Possiamo anche scrivere
Umano::vola(&persona), che è equivalente a person.vola(), ma è più verboso
se non serve disambiguare.
Questo codice stampa:
$ cargo run
Compiling esempio-trait v0.1.0 (file:///progetti/esempio-trait)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 5.07s
Running `target/debug/esempio-trait`
Qui parla il capitano.
Sali!
*sbatte furiosamente le braccia*
Poiché il metodo vola prende self come parametro, se avessimo due type che
implementano entrambi un trait, Rust potrebbe inferire quale implementazione
del trait usare in base al type di self.
Tuttavia, le funzioni associate che non sono metodi non hanno self. Quando ci
sono più type o trait che definiscono funzioni con lo stesso nome, Rust non
sa sempre quale type intendi, a meno che non si usi la sintassi completamente
qualificata. Per esempio, nel Listato 20-20 creiamo un trait per un rifugio
per animali che vuole chiamare tutti i cuccioli di cane Rex. Realizziamo un
trait Animale con una funzione associata chiamata nomignolo. Il trait
Animale è implementato per la struct Cane, sulla quale definiamo una
funzione associata nomignolo.
trait Animale { fn nomignolo() -> String; } struct Cane; impl Cane { fn nomignolo() -> String { String::from("Rex") } } impl Animale for Cane { fn nomignolo() -> String { String::from("cucciolo") } } fn main() { println!("Un piccolo di cane è detto {}", Cane::nomignolo()); }
Implementiamo il codice che chiama tutti i cuccioli Rex nella funzione associata
nomignolo definita direttamente in Cane. Il type Cane implementa anche
il trait Animale, che descrive caratteristiche comuni a tutti gli animali. I
piccoli di cane sono chiamati cuccioli, e questo è espresso nell’implementazione
del trait Animale per Cane nella funzione nomignolo associata al trait
Animale.
In main, chiamando Cane::nomignolo chiamiamo la funzione associata definita
direttamente su Cane. Questo codice stampa:
$ cargo run
Compiling esempio-trait v0.1.0 (file:///progetti/esempio-trait)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 5.10s
Running `target/debug/esempio-trait`
Un piccolo di cane è detto Rex
Questo output non è quello voluto: vogliamo chiamare la funzione nomignolo del
trait Animale implementato su Cane così che il codice stampi Un piccolo di cane è detto cucciolo. La tecnica di specificare il nome del trait come
nel Listato 20-19 non aiuta; se cambiamo main con il codice del Listato 20-21,
otterremo un errore di compilazione.
trait Animale {
fn nomignolo() -> String;
}
struct Cane;
impl Cane {
fn nomignolo() -> String {
String::from("Rex")
}
}
impl Animale for Cane {
fn nomignolo() -> String {
String::from("cucciolo")
}
}
fn main() {
println!("Un piccolo di cane è detto {}", Animale::nomignolo());
}nomignolo del trait Animale, ma Rust non sa quale implementazione usarePoiché Animale::nomignolo non ha il parametro self, e potrebbero esserci
altri type che implementano il trait Animale, Rust non riesce a inferire
quale implementazione di Animale::nomignolo usare. Otterremo questo errore del
compilatore:
$ cargo run
Compiling esempio-trait v0.1.0 (file:///progetti/esempio-trait)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:21:47
|
2 | fn nomignolo() -> String;
| ------------------------- `Animale::nomignolo` defined here
...
21 | println!("Un piccolo di cane è detto {}", Animale::nomignolo());
| ^^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
21 | println!("Un piccolo di cane è detto {}", <Cane as Animale>::nomignolo());
| ++++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `esempio-trait` (bin "esempio-trait") due to 1 previous error
Per disambiguare e indicare a Rust che vogliamo usare l’implementazione del
trait Animale per Cane anziché quella per un altro type, usiamo la
sintassi completamente qualificata. Il Listato 20-22 mostra come.
trait Animale { fn nomignolo() -> String; } struct Cane; impl Cane { fn nomignolo() -> String { String::from("Rex") } } impl Animale for Cane { fn nomignolo() -> String { String::from("cucciolo") } } fn main() { println!("Un piccolo di cane è detto {}", <Cane as Animale>::nomignolo()); }
nomignolo del trait Animale implementato su CaneForniamo un’annotazione di type tra parentesi angolari < > per dire a Rust
che vogliamo chiamare il metodo nomignolo del trait Animale implementato
su Cane, trattando il type Cane come un type Animale per questa
chiamata. Ora il codice stampa quello che vogliamo:
$ cargo run
Compiling esempio-trait v0.1.0 (file:///progetti/esempio-trait)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.11s
Running `target/debug/esempio-trait`
Un piccolo di cane è detto cucciolo
In generale la sintassi completamente qualificata è:
<Tipo as Trait>::funzione(ricevente_se_metodo, prossimo_argomento,...);Per funzioni associate che non sono metodi, non c’è un parametro self, solo la
lista degli altri argomenti. Puoi usare la sintassi completamente qualificata
ovunque chiami funzioni o metodi. Tuttavia, puoi omettere parti che Rust può
dedurre dal contesto. Devi usarla solo quando ci sono più implementazioni con lo
stesso nome e Rust ha bisogno di aiuto per distinguere quale usare.
Usare Supertrait
A volte puoi scrivere un trait che dipende da un altro trait: per un type che implementa il primo trait, richiedi che implementi anche il secondo trait. Lo fai perché la definizione del trait può usare gli elementi associati del secondo. Il trait da cui il trait che implementi dipende viene chiamato supertrait del tuo trait.
Per esempio, supponiamo di voler creare un trait StampaContorno con un
metodo stampa_contorno che stampa un valore delimitato da un contorno di
asterischi. Data una struct Punto che implementa il trait Display della
libreria standard per mostrare (x, y), quando chiami stampa_contorno su
un’istanza di Punto con x=1 e y=3, dovrebbe stampare:
**********
* *
* (1, 3) *
* *
**********
Nell’implementazione di stampa_contorno vogliamo usare le funzionalità del
trait Display. Quindi il trait StampaContorno dovrebbe funzionare solo
per type che implementano anche Display. Lo specifichiamo nella definizione
con StampaContorno: Display. Questo è simile ad aggiungere un vincolo di
trait al trait in questione. Il Listato 20-23 mostra un implementazione del
trait StampaContorno.
use std::fmt; trait StampaContorno: fmt::Display { fn stampa_contorno(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {output} *"); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } fn main() {}
StampaContorno che richiede le funzionalità di DisplayDichiarando che StampaContorno richiede il trait Display, possiamo usare
la funzione to_string che è implementata automaticamente su tutti i type che
implementano Display. Se provassimo a usare to_string senza specificare
Display, otterremmo un errore perché il metodo to_string non sarebbe trovato
per il type &Self nello scope corrente.
Vediamo cosa succede se provassimo a implementare StampaContorno su un type
che non implementa Display come la struct Punto:
use std::fmt;
trait StampaContorno: fmt::Display {
fn stampa_contorno(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Punto {
x: i32,
y: i32,
}
impl StampaContorno for Punto {}
fn main() {
let p = Punto { x: 1, y: 3 };
p.stampa_contorno();
}Riceveremmo un errore che dice che Display è richiesto ma non implementato:
$ cargo run
Compiling esempio-trait v0.1.0 (file:///progetti/esempio-trait)
error[E0277]: `Punto` doesn't implement `std::fmt::Display`
--> src/main.rs:21:25
|
21 | impl StampaContorno for Punto {}
| ^^^^^ unsatisfied trait bound
|
help: the trait `std::fmt::Display` is not implemented for `Punto`
--> src/main.rs:16:1
|
16 | struct Punto {
| ^^^^^^^^^^^^
note: required by a bound in `StampaContorno`
--> src/main.rs:3:23
|
3 | trait StampaContorno: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `StampaContorno`
error[E0277]: `Punto` doesn't implement `std::fmt::Display`
--> src/main.rs:26:7
|
26 | p.stampa_contorno();
| ^^^^^^^^^^^^^^^ unsatisfied trait bound
|
help: the trait `std::fmt::Display` is not implemented for `Punto`
--> src/main.rs:16:1
|
16 | struct Punto {
| ^^^^^^^^^^^^
note: required by a bound in `StampaContorno::stampa_contorno`
--> src/main.rs:3:23
|
3 | trait StampaContorno: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `StampaContorno::stampa_contorno`
4 | fn stampa_contorno(&self) {
| --------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `esempio-trait` (bin "esempio-trait") due to 2 previous errors
Lo risolviamo implementando Display su Punto e soddisfiamo le necessità di
StampaContorno:
trait StampaContorno: fmt::Display { fn stampa_contorno(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {output} *"); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } struct Punto { x: i32, y: i32, } impl StampaContorno for Punto {} use std::fmt; impl fmt::Display for Punto { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { let p = Punto { x: 1, y: 3 }; p.stampa_contorno(); }
A questo punto l’implementazione di StampaContorno per Punto si compila
correttamente e possiamo chiamare stampa_contorno su un’istanza di Punto per
stamparlo con un contorno di asterischi.
Implementare Trait Esterni con il Modello Newtype
Nella sezione “Implementare un Trait su un Type” del Capitolo 10 abbiamo parlato della orphan rule che dice che possiamo implementare un trait su un type solo se il trait o il type (o entrambi) sono locali al crate. Si può aggirare questa restrizione usando il modello newtype, che consiste nel creare un nuovo type come struct tupla. (Ne abbiamo già parlato in “Creare Type Diversi con Struct Tupla” del Capitolo 5.) La struct tupla avrà un solo campo e sarà un “incapsulamento sottile” attorno al type su cui vuoi implementare un trait. L’incapsulamento è locale al crate e puoi implementare il trait sull’incapsulatore. La parola newtype deriva dal linguaggio Haskell. Non c’è alcuna penalità in prestazioni nell’uso di questo modello, e il type dell’involucro viene eliso in fase di compilazione.
Per esempio, supponiamo di voler implementare Display su Vec<T>, cosa che la
orphan rule ci impedisce perché sia il trait Display che il type
Vec<T> sono definiti fuori dal nostro crate. Possiamo invece creare una
struct Capsula che contiene un’istanza di Vec<T>, poi implementare
Display su Capsula e usare il valore Vec<T> all’interno, come mostrato nel
Listato 20-24.
use std::fmt; struct Capsula(Vec<String>); impl fmt::Display for Capsula { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Capsula(vec![String::from("hello"), String::from("world")]); println!("w = {w}"); }
Capsula attorno a Vec<String> per implementare DisplayL’implementazione di Display usa self.0 per accedere a Vec<T> perché
Capsula è una struct tupla e Vec<T> è il campo all’indice 0 della tupla.
Così possiamo usare la funzionalità del trait Display su Capsula.
Lo svantaggio di questa tecnica è che Capsula è un nuovo type e non ha i
metodi del valore che incapsula. Dovresti implementare manualmente tutti i
metodi di Vec<T> in Capsula, in modo che i metodi deleghino a self.0, per
poter usare Capsula come fosse effettivamente un Vec<T>. Se volessimo che il
nuovo type abbia tutti i metodi del type interno, implementare il trait
Deref su Capsula per restituire il type interno potrebbe essere una
soluzione (abbiamo parlato dell’implementazione di Deref in “Trattare i
Puntatori Intelligenti Come Normali Reference” in Chapter 15). Se invece non vogliamo che Capsula abbia tutti i
metodi del type interno, ad esempio per restringerne le funzionalità, dovremmo
implementare i metodi che vogliamo manualmente.
Il modello newtype è utile anche quando non si tratta di trait. Passiamo ora a delle tecniche avanzate per interagire col sistema dei type di Rust.
Type Avanzati
Il sistema dei type di Rust ha alcune caratteristiche che abbiamo già
menzionato ma non ancora discusso. Inizieremo parlando dei newtype in
generale, esaminando perché i newtype sono utili come type. Poi passeremo
agli alias di type, una caratteristica simile ai newtype ma con una
semantica leggermente diversa. Discuteremo anche del type ! e dei type a
dimensione dinamica.
Sicurezza dei Type e Astrazione Con il Modello Newtype
Questa sezione presuppone che tu abbia letto la sezione precedente
“Implementare Trait Esterni con il Modello
Newtype”. Il modello newtype è
utile anche per compiti oltre quelli che abbiamo già discusso, tra cui far
rispettare staticamente che i valori non vengano confusi e indicare le unità di
misura di un valore. Hai visto un esempio dell’uso dei newtype per indicare
unità di misura nel Listato 20-16: ricorda che le struct Millimetri e
Metri incapsulavano valori u32 come newtype. Se scrivessimo una funzione
con un parametro di type Millimetri, non potremmo compilare un programma che
accidentalmente provasse a chiamare quella funzione con un valore di type
Metri o con un semplice u32.
Possiamo anche usare il modello newtype per astrarre alcuni dettagli di implementazione di un type: il nuovo type può esporre una API pubblica diversa dall’API del type interno privato.
I newtype possono anche nascondere l’implementazione interna. Ad esempio,
potremmo fornire un type Persone per incapsulare un HashMap<i32, String>
che associa l’ID di una persona al nome. Il codice che usa Persone
interagirebbe solo con l’API pubblica che definiamo, ad esempio un metodo per
aggiungere un nome alla collezione Persone; quel codice non avrebbe bisogno di
sapere che internamente associamo un ID i32 ai nomi. Il modello newtype è un
modo leggero di ottenere l’incapsulamento per nasconde dettagli di
implementazione, come abbiamo discusso in “Incapsulamento che Nasconde i
Dettagli di Implementazione” nel
Capitolo 18.
Sinonimi e Alias di Type
Rust permette di dichiarare un alias di type per dare a un type esistente
un altro nome. Per fare questa cosa usiamo la parola chiave type. Ad esempio,
possiamo creare l’alias Chilometri per i32 così:
fn main() { type Chilometri = i32; let x: i32 = 5; let y: Chilometri = 5; println!("x + y = {}", x + y); }
Ora Chilometri è un sinonimo di i32; a differenza dei type Millimetri
e Metri che abbiamo creato nel Listato 20-16, Chilometri non è un type
distinto e separato. I valori di type Chilometri saranno trattati allo
stesso modo di quelli di type i32:
fn main() { type Chilometri = i32; let x: i32 = 5; let y: Chilometri = 5; println!("x + y = {}", x + y); }
Poiché Chilometri e i32 sono lo stesso type, possiamo sommare valori di
entrambi i type e passare valori di type Chilometri a funzioni che
accettano parametri i32. Tuttavia, usando questo metodo non otteniamo i
benefici di controllo dei type che otterremmo con il modello newtype
discusso prima. In altre parole, se confondiamo valori di type Chilometri e
i32 da qualche parte, il compilatore non ci darà errore.
Il caso d’uso principale per i sinonimi di type è ridurre la ripetizione. Ad esempio, potremmo avere una definizione di type un po’ lunga:
Box<dyn Fn() + Send + 'static>Scrivere questo type lungo nelle firme delle funzioni e come annotazioni di type in tutto il codice può essere verboso e soggetto a errori. Immagina un progetto pieno di codice come quello del Listato 20-25.
fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("ciao")); fn prende_type_lungo(f: Box<dyn Fn() + Send + 'static>) { // --taglio-- } fn ritorna_type_lungo() -> Box<dyn Fn() + Send + 'static> { // --taglio-- Box::new(|| ()) } }
Un alias di type rende questo codice più gestibile riducendo la ripetizione.
Nel Listato 20-26, abbiamo introdotto un alias chiamato Thunk per il type
verboso e possiamo sostituire tutti gli usi di quel type con l’alias più
corto Thunk.
fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("ciao")); fn prende_type_lungo(f: Thunk) { // --taglio-- } fn ritorna_type_lungo() -> Thunk { // --taglio-- Box::new(|| ()) } }
Thunk, per ridurre la ripetizioneQuesto codice è molto più facile da leggere e scrivere! Scegliere un nome significativo per un alias di type può anche aiutare a comunicare chiaramente la nostra intenzione (thunk è una parola tecnica usata per indicare codice che verrà eseguito e valutato in un secondo momento, quindi è un nome appropriato per una closure che viene memorizzata).
Gli alias di type sono anche comunemente usati con il type Result<T, E>
per ridurre la ripetizione. Considera il modulo std::io nella libreria
standard. Le operazioni I/O spesso restituiscono un Result<T, E> per gestire
le situazioni in cui le operazioni possono fallire. Questa libreria ha una
struct std::io::Error che rappresenta tutti i possibili errori di I/O. Molte
funzioni in std::io restituiscono un Result<T, E> dove E è
std::io::Error, come nelle funzioni del trait Write:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Il Result<..., Error> si ripete molto. Per questo motivo, std::io ha questa
dichiarazione di alias di type:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Poiché questa dichiarazione è nel modulo std::io, possiamo usare l’alias
completamente qualificato std::io::Result<T>; cioè, un Result<T, E> con E
riempito come std::io::Error. Le firme delle funzioni del trait Write
diventano così:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}L’alias di type aiuta in due modi: rende il codice più facile da scrivere e
leggere e ci fornisce un’interfaccia coerente in tutto std::io. Poiché è un
alias, è solo un altro Result<T, E>, il che significa che possiamo usare
tutti i metodi che funzionano su Result<T, E>, oltre alla sintassi speciale
come l’operatore ?.
Il Type Never Che Non Ritorna Mai
Rust ha un type speciale chiamato ! che in gergo di teoria dei type è
chiamato type vuoto perché non ha valori. Preferiamo chiamarlo type
never (type mai) perché rappresenta il type di ritorno di una funzione
che non restituirà mai nulla. Ecco un esempio:
fn bar() -> ! {
// --taglio--
panic!();
}Questo codice significa “la funzione bar non restituirà mai”. Le funzioni che
non restituiscono mai sono chiamate funzioni divergenti. Non possiamo creare
valori di type !, per cui bar non potrà mai restituirli.
Ma a cosa serve un type per cui non si possono creare valori? Ricorda il codice del Listato 2-5, parte del gioco degli indovinelli; ne riproduciamo un pezzo qui nel Listato 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Indovina il numero!");
let numero_segreto = rand::thread_rng().gen_range(1..=100);
println!("Il numero segreto è: {numero_segreto}");
loop {
println!("Inserisci la tua ipotesi.");
let mut ipotesi = String::new();
// --taglio--
io::stdin()
.read_line(&mut ipotesi)
.expect("Errore di lettura");
let ipotesi: u32 = match ipotesi.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Hai ipotizzato: {ipotesi}");
// --taglio--
match ipotesi.cmp(&numero_segreto) {
Ordering::Less => println!("Troppo piccolo!"),
Ordering::Greater => println!("Troppo grande!"),
Ordering::Equal => {
println!("Hai indovinato!");
break;
}
}
}
}match con un ramo che finisce con continueAll’epoca abbiamo trascurato alcuni dettagli di questo codice. Nella sezione
“Controllare il Flusso con il costrutto
match” del Capitolo 6 abbiamo spiegato che
tutti i rami di un match devono ritornare lo stesso type. Quindi, per
esempio, il seguente codice non funziona:
fn main() {
let ipotesi = "3";
let ipotesi = match ipotesi.trim().parse() {
Ok(_) => 5,
Err(_) => "ciao",
};
}Il type di ipotesi in questo codice dovrebbe essere un intero e una
stringa, e Rust richiede che ipotesi sia di un solo type. Allora cosa
ritorna continue? Come facciamo a ritornare un u32 da un ramo e avere un
altro ramo che termina con continue nel Listato 20-27?
Come avrai intuito, continue ha un valore di type !. Questo significa che
quando Rust calcola il type di ipotesi, guarda entrambi i rami: il primo con
valore u32 e il secondo con valore !. Poiché ! non può avere un valore,
Rust decide che il type di ipotesi è u32.
Il modo formale di descrivere questo comportamento è che le espressioni di
type ! possono essere forzate in qualsiasi altro type. È permesso
terminare questo ramo di match con continue perché continue non
restituisce un valore; invece, sposta il controllo in cima al ciclo, quindi nel
caso di Err non assegniamo mai un valore a ipotesi.
Il type never è utile anche con la macro panic!. Ricorda la funzione
unwrap che chiamiamo sui valori Option<T> per ottenere un valore o fare
panic, con questa definizione:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("chiamato `Option::unwrap()` su un valore `None`"),
}
}
}In questo codice, succede la stessa cosa vista nel match del Listato 20-27:
Rust vede che val ha type T e panic! ha type !, quindi il risultato
dell’espressione complessiva match è T. Questo codice funziona perché
panic! non produce un valore; termina il programma. Nel caso None non
ritorneremo un valore da unwrap, quindi questo codice è valido.
Un’ultima espressione che ha type ! è un loop:
fn main() {
print!("sempre ");
loop {
print!("e per sempre ");
}
}Qui il loop non termina mai, per cui il valore dell’espressione è !. Questo
non varrebbe se usassimo un break perché il ciclo terminerebbe quando incontra
break.
Type a Dimensione Dinamica e il Trait Sized
Rust ha bisogno di conoscere alcune informazioni sui type, tipo quanto spazio allocare per un valore di quel type. Questo rende un po’ complicato il concetto di type a dimensione dinamica. Detti anche DST o type non dimensionati, consentono di scrivere codice che usa valori la cui dimensione è nota solo in fase di esecuzione.
Parliamo nel dettaglio di un type a dimensione dinamica chiamato str, che
abbiamo usato spesso nel libro. Proprio così, non &str ma str da solo è un
DST. In molti casi, come nel caso di stringhe inserite da un utente, non
possiamo sapere la lunghezza della stringa a priori se non durante l’esecuzione.
Questo significa che non possiamo creare una variabile di type str, né
ricevere un argomento di type str. Considera il seguente codice, che non
funziona:
fn main() {
let s1: str = "Ciao!";
let s2: str = "Come va?";
}Rust deve sapere quanto spazio allocare per un valore di un qualsiasi type e
tutti i valori di quel type devono occupare la stessa quantità di memoria. Se
Rust ci permettesse di scrivere questo codice, quei due valori str dovrebbero
occupare la stessa quantità di spazio, ma hanno lunghezze diverse: s1
necessita di 5 byte, s2 di 8. Ecco perché non è possibile creare una variabile
contenente un type a dimensione dinamica.
Quindi cosa facciamo? La risposta la conosci già: cambiamo i type di s1 e
s2 in slice di stringa (&str) anziché str. Come detto nella sezione
“Slice di Stringa” del Capitolo 4, la struttura dati slice
memorizza solo l’indirizzo di partenza e la lunghezza della slice. Perciò,
anche se un &T è un singolo valore che memorizza l’indirizzo di memoria di
T, una slice è due valori: l’indirizzo di str e la sua lunghezza. Perciò
sappiamo sempre la dimensione statica di un valore slice stringa durante la
compilazione: è doppia rispetto alla lunghezza di un usize. E quindi,
conosciamo sempre la dimensione di una slice indipendentemente dalla lunghezza
della stringa. In generale, questo è il modo in cui si usano i type a
dimensione dinamica in Rust: hanno un pezzettino di metadati in più per
memorizzare la dimensione dell’informazione dinamica. La regola d’oro dei DST
è che dobbiamo sempre mettere valori di type a dimensione dinamica dietro a
qualche tipo di puntatore.
Possiamo combinare str con tanti type di puntatori: ad esempio, Box<str> o
Rc<str>. È una cosa che hai già visto, ma con un altro type a dimensione
dinamica: i trait. Ogni trait è un type a dimensione dinamica che può
essere indicato usando il nome del trait. Nella sezione “Usare Oggetti
Trait per Astrarre Comportamenti Condivisi” del Capitolo 18 abbiamo menzionato che per usare trait come oggetti
trait dobbiamo metterli dietro a un puntatore, come &dyn Trait o Box<dyn Trait> (anche Rc<dyn Trait> andrebbe bene).
Per lavorare con i DST, Rust fornisce il trait Sized, che determina se la
dimensione di un type è nota a tempo di compilazione. Questo trait è
implementato automaticamente per tutto ciò che ha dimensione nota nel momento
della compilazione. Inoltre, Rust aggiunge implicitamente un vincolo su Sized
per ogni funzione generica: questo vuol dire che la definizione di una funzione
generica come questa:
fn generica<T>(t: T) {
// --taglio--
}viene trattata come se fosse scritta così:
fn generica<T: Sized>(t: T) {
// --taglio--
}Per default, le funzioni generiche funzionano solo su type con dimensione nota nel momento della compilazione. Però puoi usare questa sintassi speciale per allentare questa restrizione:
fn generica<T: ?Sized>(t: &T) {
// --taglio--
}Un vincolo ?Sized significa “T può essere o non essere di dimensione fissa”,
e questa notazione sovrascrive il comportamento predefinito che i generici
debbano avere dimensione nota nel momento della compilazione. La sintassi
?Trait con questo significato è disponibile solo per Sized e non per altri
trait.
Nota anche che abbiamo cambiato il type del parametro t da T a &T.
Poiché il type potrebbe non essere Sized, dobbiamo usarlo dietro a un
qualche tipo di puntatore. In questo caso usiamo un reference.
Ed ora, continuiamo parlando di funzioni e chiusure!
Funzioni e Chiusure Avanzate
Questa sezione esplora alcune funzionalità avanzate legate a funzioni e chiusure, inclusi i puntatori a funzione e il ritorno di chiusure.
Puntatori a Funzione
Abbiamo parlato di come passare chiusure alle funzioni; puoi anche passare
funzioni normali a funzioni! Questa tecnica è utile quando vuoi passare una
funzione che hai già definito piuttosto che definire una nuova chiusura. Le
funzioni si convertono automaticamente al type fn (con la f minuscola), da
non confondere con il trait Fn delle chiusure. Il type fn è chiamato
puntatore a funzione. Passare funzioni con puntatori a funzione ti permette di
utilizzare funzioni come argomenti per altre funzioni.
La sintassi per specificare che un parametro è un puntatore a funzione è simile
a quella delle chiusure, come mostrato nel Listato 20-28, dove abbiamo definito
una funzione più_uno che aggiunge 1 al suo parametro. La funzione due_volte
prende due parametri: un puntatore a funzione verso qualsiasi funzione che
prende un parametro i32 e ritorna un i32, e un valore i32. La funzione
due_volte chiama la funzione f due volte, passando il valore arg, poi
somma i risultati delle due chiamate. La funzione main chiama due_volte con
gli argomenti più_uno e 5.
fn più_uno(x: i32) -> i32 { x + 1 } fn due_volte(f: fn(i32) -> i32, arg: i32) -> i32 { f(arg) + f(arg) } fn main() { let risposta = due_volte(più_uno, 5); println!("La risposta è: {risposta}"); }
fn per accettare un puntatore a funzione come argomentoQuesto codice stampa La risposta è: 12. Specifichiamo che il parametro f in
due_volte è un fn che prende un parametro di type i32 e ritorna un
i32. Possiamo quindi chiamare f nel corpo di due_volte. In main,
possiamo passare il nome della funzione più_uno come primo argomento a
due_volte.
A differenza delle chiusure, fn è un type, non un trait, quindi
specifichiamo fn come type del parametro direttamente piuttosto che
dichiarare un type generico con uno dei trait Fn come vincolo.
I puntatori a funzione implementano tutti e tre i trait delle chiusure (Fn,
FnMut e FnOnce), il che significa che puoi sempre passare un puntatore a
funzione come argomento a una funzione che si aspetta una chiusura. È meglio
scrivere funzioni usando un type generico e uno dei trait delle chiusure
così che le tue funzioni possano accettare sia funzioni che chiusure.
Detto questo, un esempio in cui potresti voler accettare solo fn e non
chiusure è quando ti interfacci con codice esterno che non ha chiusure: le
funzioni in C possono accettare funzioni come argomenti, ma C non ha chiusure.
Come esempio di dove potresti usare sia una chiusura definita che una funzione
nominata, diamo un’occhiata all’uso del metodo map fornito dal trait
Iterator nella libreria standard. Per usare il metodo map per trasformare un
vettore di numeri in un vettore di stringhe, potremmo usare una chiusura, come
nel Listato 20-29.
fn main() { let lista_di_numeri = vec![1, 2, 3]; let lista_di_stringhe: Vec<String> = lista_di_numeri.iter().map(|i| i.to_string()).collect(); }
map per convertire numeri in stringheOppure potremmo nominare una funzione come argomento di map al posto della
chiusura. Il Listato 20-30 mostra come sarebbe.
fn main() { let lista_di_numeri = vec![1, 2, 3]; let lista_di_stringhe: Vec<String> = lista_di_numeri.iter().map(ToString::to_string).collect(); }
String::to_string con il metodo map per convertire numeri in stringheNota che dobbiamo usare la sintassi completamente qualificata di cui abbiamo
parlato nella sezione “Trait Avanzati”
perché ci sono più funzioni con nome to_string.
Qui usiamo la funzione to_string definita nel trait ToString, che la
libreria standard ha implementato per ogni type che implementa Display.
Ricorda dalla sezione “Valori di Enum” del Capitolo 6 che il nome di ogni variante enum diventa anche una funzione inizializzatrice. Possiamo usare queste funzioni inizializzatrici come puntatori a funzione che implementano i trait delle chiusure, il che significa che possiamo specificare le funzioni inizializzatrici come argomenti per metodi che accettano chiusure, come nel Listato 20-31.
fn main() { enum Stato { Valore(u32), Stop, } let lista_stati: Vec<Stato> = (0u32..20).map(Stato::Valore).collect(); }
map per creare un’istanza Stato dai numeriQui creiamo istanze di Stato::Valore usando ogni valore u32 nell’intervallo
su cui è chiamato map, usando la funzione inizializzatrice di Stato::Valore.
Alcuni preferiscono questo stile, altri preferiscono usare chiusure. Entrambi i
metodi si compilano allo stesso modo, quindi usa quello che trovi più chiaro.
Restituire Chiusure
Le chiusure sono rappresentate da trait, il che significa che non puoi
restituire direttamente una chiusura. Nella maggior parte dei casi in cui
potresti voler ritornare un trait, puoi invece usare il type concreto che
implementa il trait come type di ritorno della funzione. Tuttavia, di solito
non puoi fare questo con le chiusure perché non hanno un type concreto
restituibile; per esempio, non puoi usare il puntatore a funzione fn come
type di ritorno se la chiusura cattura qualche valore dal suo scope.
Al contrario, normalmente userai la sintassi impl Trait che hai imparato nel
Capitolo 10. Puoi restituire qualsiasi tipo di funzione usando Fn, FnOnce e
FnMut. Per esempio, il codice nel Listato 20-32 verrà compilato senza
problemi.
#![allow(unused)] fn main() { fn ritorna_chiusura() -> impl Fn(i32) -> i32 { |x| x + 1 } }
impl TraitTuttavia, come abbiamo notato nella sezione “Inferenza e Annotazione del Type delle Chiusure” del Capitolo 13, ogni chiusura è anche il suo type distinto. Se ti serve lavorare con più funzioni che hanno la stessa firma ma implementazioni diverse, dovrai usare un oggetto trait per loro. Considera cosa succede se scrivi del codice come nel Listato 20-33.
fn main() {
let handlers = vec![ritorna_chiusura(), ritorna_chiusura_inizializzata(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn ritorna_chiusura() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn ritorna_chiusura_inizializzata(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}Vec<T> di chiusure definite tramite funzioni che restituiscono type impl FnQui abbiamo due funzioni, ritorna_chiusura e ritorna_chiusura_inizializzata,
che entrambe ritornano impl Fn(i32) -> i32. Nota che le chiusure restituite
sono diverse anche se implementano lo stesso type. Se provi a compilare, Rust
ti dice che non funziona:
$ cargo run
Compiling esempio-funzioni v0.1.0 (file:///progetti/esempio-funzioni)
error[E0308]: mismatched types
--> src/main.rs:2:45
|
2 | let handlers = vec![ritorna_chiusura(), ritorna_chiusura_inizializzata(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn ritorna_chiusura() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn ritorna_chiusura_inizializzata(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `esempio-funzioni` (bin "esempio-funzioni") due to 1 previous error
Il messaggio di errore dice che ogni volta che ritorni un impl Trait, Rust
crea un type opaco univoco, un type di cui non possiamo conoscere i
dettagli di come Rust l’ha costruito né sapere il type generato. Quindi anche
se queste funzioni ritornano chiusure che implementano lo stesso trait, i
type opachi che Rust genera sono diversi. (Questo è simile a come Rust genera
type concreti distinti per blocchi async diversi anche se hanno lo stesso
type di output, come abbiamo visto nella sezione “Il Type Pin e il
Trait Unpin” del Capitolo 17.) Abbiamo già
visto una soluzione a questo problema: possiamo usare un oggetto trait, come
nel Listato 20-34.
fn main() { let handlers = vec![ritorna_chiusura(), ritorna_chiusura_inizializzata(123)]; for handler in handlers { let output = handler(5); println!("{output}"); } } fn ritorna_chiusura() -> Box<dyn Fn(i32) -> i32> { Box::new(|x| x + 1) } fn ritorna_chiusura_inizializzata(init: i32) -> Box<dyn Fn(i32) -> i32> { Box::new(move |x| x + init) }
Vec<T> di chiusure definite tramite funzioni che ritornano Box<dyn Fn>Questo codice si compila correttamente. Per più informazioni sugli oggetti trait, vedi la sezione “Usare gli Oggetti Trait per Astrarre Comportamenti Condivisi” del Capitolo 18.
Passiamo ora a vedere le macro!
Macro
Abbiamo usato macro come println! in tutto il libro, ma non abbiamo ancora
esplorato appieno cosa sia una macro e come funzioni. Il termine macro si
riferisce a una famiglia di funzionalità in Rust, le macro dichiarative con
macro_rules! e tre tipi di macro procedurali:
- Macro
#[derive]personalizzate che specificano codice aggiunto con l’attributoderiveusato su struct ed enum. - Macro simil-attributo che definiscono attributi personalizzati usabili su qualsiasi elemento.
- Macro simil-funzione che sembrano chiamate di funzione ma operano sui token specificati come argomento.
Parleremo di ciascuna di queste a turno, ma prima vediamo perché abbiamo bisogno delle macro se abbiamo già le funzioni.
Differenza Tra Macro e Funzioni
Fondamentalmente, le macro sono un modo di scrivere codice che scrive altro
codice, noto come meta-programmazione. Nell’Appendice C parliamo
dell’attributo derive, che genera per te l’implementazione di vari trait.
Abbiamo anche usato le macro println! e vec! in tutto il libro. Tutte queste
macro espandono il codice, producendo più codice di quello scritto
manualmente.
La meta-programmazione è utile per ridurre la quantità di codice da scrivere e mantenere, che è uno degli scopi delle funzioni. Tuttavia, le macro hanno poteri aggiuntivi che le funzioni non hanno.
La firma di una funzione deve dichiarare il numero ed il type dei parametri.
Le macro, invece, possono accettare un numero variabile di parametri: possiamo
chiamare println!("ciao") con un argomento o println!("ciao {}", nome) con
due. Inoltre, le macro sono espanse prima che il compilatore interpreti il
codice, quindi una macro può, ad esempio, implementare un trait su un type.
Una funzione non può farlo, perché viene chiamata durante l’esecuzione e i
trait devono essere implementati durante la compilazione.
Lo svantaggio delle macro rispetto alle funzioni è che definire macro è più complesso, perché stai scrivendo codice Rust che scrive codice Rust. Per questo, definire macro è generalmente più difficile da leggere, capire e mantenere rispetto alle funzioni.
Un’altra differenza importante è che devi definire o importare le macro prima di usarle in un file, mentre le funzioni possono essere definite e chiamate ovunque.
Macro Dichiarative Per la Meta-Programmazione Generale
La forma di macro più diffusa in Rust è la macro dichiarativa. A volte queste
sono anche chiamate “macro per esempio”, “macro macro_rules!” o semplicemente
“macro”. Nella loro essenza, le macro dichiarative permettono di scrivere
qualcosa di simile a un’espressione match di Rust. Come discusso nel Capitolo
6, le espressioni match sono strutture di controllo che prendono
un’espressione, confrontano il valore risultante con dei pattern, e quindi
eseguono il codice associato al pattern corrispondente. Le macro confrontano
anch’esse un valore con dei pattern associati a codice particolare: in questa
situazione, il valore è il codice sorgente letterale di Rust passato alla macro;
i pattern sono confrontati con la struttura di quel codice sorgente; e il
codice associato a ciascun pattern, quando corrisponde, sostituisce il codice
passato alla macro. Tutto ciò accade durante la compilazione.
Per definire una macro, si usa il costrutto macro_rules!. Esploriamo come
utilizzare macro_rules! osservando come viene definita la macro vec!. Il
Capitolo 8 ha trattato come possiamo usare la macro vec! per creare un nuovo
vettore con valori particolari. Per esempio, la seguente macro crea un nuovo
vettore contenente tre interi:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
Potremmo anche usare la macro vec! per creare un vettore di due interi o un
vettore di cinque stringhe. Non potremmo usare una funzione per fare lo stesso
perché non sapremmo a priori il numero o il tipo di valori.
Il Listato 20-35 mostra una definizione leggermente semplificata della macro
vec!.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}vec!Nota: La definizione reale della macro
vec!nella libreria standard include codice per pre-allocare la quantità corretta di memoria anticipatamente. Quel codice è un’ottimizzazione che non includiamo qui, per rendere l’esempio più semplice.
L’annotazione #[macro_export] indica che questa macro deve essere resa
disponibile ogni volta che il crate in cui è definita la macro viene incluso
nello scope. Senza questa annotazione, la macro non può essere portata nello
scope.
Iniziamo quindi la definizione della macro con macro_rules! e il nome della
macro che stiamo definendo senza il punto esclamativo. Il nome, in questo caso
vec, è seguito da parentesi graffe che indicano il corpo della definizione
della macro.
La struttura nel corpo di vec! è simile alla struttura di un’espressione
match. Qui abbiamo un ramo con il pattern ( $( $x:expr ),* ), seguito da
=> e dal blocco di codice associato a questo pattern. Se il pattern
corrisponde, il blocco di codice associato verrà espanso. Poiché questo è
l’unico pattern in questa macro, c’è solo un modo valido per farlo
corrispondere; qualsiasi altro pattern porterà a un errore. Macro più
complesse avranno più rami.
La sintassi valida dei pattern nelle definizioni di macro è diversa dalla sintassi dei pattern trattata nel Capitolo 19 perché i pattern delle macro vengono confrontati con la struttura del codice Rust piuttosto che con valori. Vediamo cosa significano le parti del pattern nel Listato 20-35; per la sintassi completa dei pattern nelle macro, consultare il Rust Reference.
Prima usiamo una coppia di parentesi tonde per racchiudere tutto il pattern.
Usiamo un segno del dollaro $ per dichiarare una variabile nel sistema macro
che conterrà il codice Rust che corrisponde al pattern. Il segno del dollaro
rende chiaro che questa è una variabile macro e non una variabile Rust normale.
Poi viene una coppia di parentesi tonde che cattura i valori che corrispondono
al pattern dentro le parentesi per l’uso nel codice di sostituzione. Dentro
$() c’è $x:expr, che corrisponde a qualsiasi espressione Rust e assegna il
nome $x a quell’espressione.
La virgola che segue $() indica che deve apparire un carattere letterale di
separazione virgola tra ogni istanza del codice che corrisponde al codice in
$(). L’asterisco * specifica che il pattern corrisponde a zero o più
occorrenze di qualunque cosa preceda l’asterisco.
Quando chiamiamo questa macro con vec![1, 2, 3];, il pattern $x
corrisponde tre volte con le tre espressioni 1, 2 e 3.
Ora vediamo il pattern nel corpo del codice associato a questo ramo:
temp_vec.push() dentro $()* viene generato per ciascuna parte che
corrisponde a $() nel pattern da zero a più volte a seconda di quante volte
il pattern corrisponde. Il $x viene sostituito con ogni espressione trovata.
Quando chiamiamo questa macro con vec![1, 2, 3];, il codice generato che
sostituisce questa chiamata di macro sarà il seguente:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Abbiamo definito una macro che può prendere qualsiasi numero di argomenti di qualsiasi type e può generare codice per creare un vettore contenente gli elementi specificati.
Per imparare di più su come scrivere macro, consultare la documentazione online o altre risorse, come “The Little Book of Rust Macros” iniziato da Daniel Keep e continuato da Lukas Wirth.
Macro Procedurali Per Generare Codice da Attributi
La seconda forma di macro è la macro procedurale, che si comporta più come una
funzione (e è un tipo di procedura). Le macro procedurali accettano del codice
come input, operano su quel codice, e producono del codice come output, invece
di fare match su dei pattern e sostituire il codice con altro codice come
fanno le macro dichiarative. Le tre tipologie di macro procedurali sono derive
personalizzate, macro simil-attributi, e macro simil-funzioni, e tutte
funzionano in modo simile.
Quando si creano macro procedurali, le definizioni devono risiedere in un
proprio crate con un tipo speciale di crate. Questo per ragioni tecniche
complesse che si spera di eliminare in futuro. Nel Listato 20-36 mostriamo come
definire una macro procedurale, dove qualche_attributo è un segnaposto per
l’uso di una specifica varietà di macro.
use proc_macro::TokenStream;
#[qualche_attributo]
pub fn qualche_attributo(input: TokenStream) -> TokenStream {
}La funzione che definisce una macro procedurale prende un TokenStream come
input e produce un TokenStream come output. Il type TokenStream è definito
dal crate proc_macro incluso in Rust e rappresenta una sequenza di token.
Questo è il nucleo della macro: il codice sorgente su cui la macro opera
costituisce il TokenStream di input, e il codice che la macro produce è il
TokenStream di output. La funzione ha anche un attributo che specifica quale
tipo di macro procedurale stiamo creando. Possiamo avere più tipi di macro
procedurali nello stesso crate.
Vediamo le diverse tipologie di macro procedurali. Inizieremo con una macro
derive personalizzata per poi spiegare le piccole differenze che
caratterizzano le altre forme.
Macro derive Personalizzate
Creiamo un crate chiamato hello_macro che definisce un trait chiamato
HelloMacro con una funzione associata chiamata hello_macro. Invece di far
implementare agli utenti il trait HelloMacro per ogni loro type, forniremo
una macro procedurale che consente agli utenti di annotare il loro type con
#[derive(HelloMacro)] per ottenere un’implementazione di default della
funzione hello_macro. L’implementazione di default stamperà Ciao, Macro! Il mio nome è NomeType! dove NomeType è il nome del type su cui il trait è
stato definito. In altre parole, scriveremo un crate che permette a un altro
programmatore di scrivere codice come nel Listato 20-37 usando il nostro
crate.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancake;
fn main() {
Pancake::hello_macro();
}Questo codice stamperà Ciao, Macro! Il mio nome è Pancake! quando sarà
eseguito. Il primo passo è creare un nuovo crate libreria come segue:
$ cargo new hello_macro --lib
Successivamente, nel Listato 20-38, definiremo il trait HelloMacro e la sua
funzione associata.
pub trait HelloMacro {
fn hello_macro();
}deriveAbbiamo un trait e la sua funzione. A questo punto, l’utente del nostro crate potrebbe implementare il trait per ottenere la funzionalità desiderata, come mostrato nel Listato 20-39.
use hello_macro::HelloMacro;
struct Pancake;
impl HelloMacro for Pancake {
fn hello_macro() {
println!("Ciao, Macro! Il mio nome è Pancake!");
}
}
fn main() {
Pancake::hello_macro();
}HelloMacroTuttavia, gli utenti dovrebbero scrivere il blocco di implementazione per ogni
type su cui vogliono usare hello_macro; vogliamo risparmiarli da questo
lavoro.
Inoltre, non possiamo ancora fornire alla funzione hello_macro
un’implementazione di default che stampi il nome del type su cui il trait è
implementato: Rust non possiede capacità riflessive (reflection), cioè non
può ricavare il nome del type durante l’esecuzione. Abbiamo bisogno di una
macro per generare il codice a durante la compilazione.
Il passo successivo è definire la macro procedurale. Al momento della scrittura,
le macro procedurali devono risiedere in un crate a parte. Questa restrizione
potrebbe essere rimossa in futuro. La convenzione per strutturare crate e
crate macro è la seguente: per un crate chiamato foo, un crate di macro
procedurali derive personalizzate si chiama foo_derive. Creiamo quindi un
nuovo crate chiamato hello_macro_derive all’interno del progetto
hello_macro:
$ cargo new hello_macro_derive --lib
I due crate sono strettamente correlati, quindi creiamo il crate di macro
procedurali nella cartella del crate hello_macro. Se cambiamo la definizione
del trait in hello_macro, dovremo cambiare anche l’implementazione della
macro procedurale in hello_macro_derive. I due crate dovranno essere
pubblicati separatamente, e i programmatori che usano questi crate dovranno
aggiungerli entrambi come dipendenze e importarli entrambi nello scope.
Potremmo invece far sì che il crate hello_macro utilizzi
hello_macro_derive come dipendenza e rimandi il codice della macro
procedurale. Tuttavia, la struttura scelta consente ai programmatori di usare
hello_macro anche se non vogliono la funzionalità derive.
Dobbiamo dichiarare il crate hello_macro_derive come crate di macro
procedurali. Avremo anche bisogno della funzionalità dai crate syn e
quote, come vedremo a breve, quindi dobbiamo aggiungerli come dipendenze.
Aggiungi quanto segue al file Cargo.toml di hello_macro_derive:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Per iniziare a definire la macro procedurale, inserisci il codice del Listato
20-40 nel file src/lib.rs del crate hello_macro_derive. Nota che questo
codice non si compila fino a quando non aggiungiamo una definizione per la
funzione impl_hello_macro.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Costruisci una rappresentazione di codice Rust come
// albero sintattico che possiamo manipolare
let ast = syn::parse(input).unwrap();
// Costruisci l'implementazione del trait
impl_hello_macro(&ast)
}Nota che abbiamo diviso il codice in una funzione hello_macro_derive,
responsabile della lettura ed elaborazione del TokenStream, e una funzione
impl_hello_macro, responsabile della trasformazione dell’albero sintattico:
questo rende la scrittura di una macro procedurale più comoda. Il codice nella
funzione esterna (hello_macro_derive in questo caso) sarà simile in quasi
tutti i crate di macro procedurali che vedrai o creerai. Il codice che
specifichiamo nel corpo della funzione interna (impl_hello_macro in questo
caso) sarà diverso a seconda dello scopo della macro procedurale.
Abbiamo introdotto tre nuovi crate: proc_macro, syn
e quote. Il crate proc_macro fa parte di Rust,
quindi non abbiamo dovuto aggiungerlo alle dipendenze in Cargo.toml. Il
crate proc_macro è l’API del compilatore che consente di leggere e
manipolare codice Rust dal nostro codice.
Il crate syn analizza e trasforma il codice Rust da una stringa in una
struttura dati su cui possiamo eseguire operazioni. Il crate quote trasforma
le strutture dati di syn nuovamente in codice Rust. Questi crate rendono
molto più semplice analizzare qualsiasi tipo di codice Rust che vogliamo
gestire: scrivere un parser completo per Rust non è un compito semplice.
La funzione hello_macro_derive verrà chiamata quando un utente della nostra
libreria specifica #[derive(HelloMacro)] su di un type. Questo è possibile
perché abbiamo annotato la funzione hello_macro_derive con proc_macro_derive
e specificato il nome HelloMacro, che corrisponde al nostro nome di trait;
questa è la convenzione che la maggior parte delle macro procedurali segue.
La funzione hello_macro_derive prima converte l’input da un TokenStream a
una struttura dati che possiamo interpretare ed elaborare. Qui entra in gioco
syn. La funzione parse di syn prende un TokenStream e restituisce una
struttura DeriveInput che rappresenta il codice Rust analizzato. Il Listato
20-41 mostra le parti rilevanti della struttura DeriveInput ottenuta
analizzando la stringa struct Pancake;.
DeriveInput {
// --taglio--
ident: Ident {
ident: "Pancake",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}DeriveInput che otteniamo analizzando il codice con l’attributo macro del Listato 20-37I campi di questa struttura mostrano che il codice Rust che abbiamo analizzato è
una struct unit con ident (identificatore, cioè il nome) Pancake. Ci
sono altri campi in questa struttura per descrivere ogni tipo di codice Rust;
consulta la documentazione syn per DeriveInput per maggiori
dettagli.
Presto definiremo la funzione impl_hello_macro, dove costruiremo il nuovo
codice Rust da includere. Ma prima nota che l’output della nostra macro derive
è anch’esso un TokenStream. Il TokenStream ritornato viene aggiunto al
codice scritto dai nostri utenti, così che quando compilano il loro crate
ottengano la funzionalità aggiuntiva che forniamo nel TokenStream modificato.
Potresti aver notato che chiamiamo unwrap per far generare un panic alla
funzione hello_macro_derive se la chiamata a syn::parse fallisce. È
necessario che la macro procedurale vada in panic su errori perché le funzioni
proc_macro_derive devono restituire un TokenStream e non un Result per
conformarsi all’API delle macro procedurali. Abbiamo semplificato questo esempio
usando unwrap; nei codici di produzione, si dovrebbero fornire messaggi di
errore più specifici usando panic! o expect.
Ora che abbiamo il codice per trasformare il codice Rust annotato da un
TokenStream a un’istanza DeriveInput, generiamo il codice che implementa il
trait HelloMacro sul type annotato, come mostrato nel Listato 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Costruisci una rappresentazione di codice Rust come
// albero sintattico che possiamo manipolare
let ast = syn::parse(input).unwrap();
// Costruisci l'implementazione del trait
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let nome = &ast.ident;
let generato = quote! {
impl HelloMacro for #nome {
fn hello_macro() {
println!("Ciao, Macro! Il mio nome è {}!", stringify!(#nome));
}
}
};
generato.into()
}HelloMacro usando il codice Rust analizzatoOtteniamo un’istanza Ident contenente il nome (identificatore) del type
annotato usando ast.ident. La struct nel Listato 20-41 mostra che quando
eseguiamo la funzione impl_hello_macro sul codice nel Listato 20-37, il campo
ident sarà Pancake. Quindi la variabile nome nel Listato 20-42 sarà
un’istanza di Ident che quando stampata sarà la stringa "Pancake", il nome
della struct del Listato 20-37.
La macro quote! ci permette di definire il codice Rust che vogliamo
restituire. Il compilatore si aspetta qualcosa di diverso dal risultato diretto
dell’esecuzione della macro quote!, quindi dobbiamo convertirlo in un
TokenStream. Lo facciamo chiamando il metodo into, che consuma questa
rappresentazione intermedia e ritorna un valore del type richiesto
TokenStream.
La macro quote! fornisce anche un meccanismo di sostituzione molto
interessante: possiamo inserire #nome, e quote! lo sostituirà con il valore
contenuto nella variabile nome. Si possono anche fare ripetizioni simili alle
macro normali. Consulta la documentazione del crate quote per
un’introduzione completa.
Vogliamo che la nostra macro procedurale generi un’implementazione del trait
HelloMacro per il type annotato dall’utente, che otteniamo usando #nome.
L’implementazione del trait ha una funzione, hello_macro, il cui corpo
contiene la funzionalità che vogliamo fornire: stampare Ciao, Macro! Il mio nome è e poi il nome del type annotato.
La macro stringify! utilizzata qui è incorporata in Rust. Prende
un’espressione Rust, come 1 + 2, e durante la compilazione la trasforma in una
stringa letterale, in questo caso "1 + 2". Questo è diverso da format! o
println!, che sono macro che valutano l’espressione e poi trasformano il
risultato in una String. C’è la possibilità che l’input #nome possa essere
un’espressione da stampare letteralmente, quindi usiamo stringify!. Usare
stringify! evita anche un’allocazione convertendo #nome in una stringa
letterale durante la compilazione.
A questo punto, il comando cargo build dovrebbe completarsi con successo sia
in hello_macro che in hello_macro_derive. Colleghiamo questi crate al
codice nel Listato 20-37 per vedere la macro procedurale in azione! Creiamo un
nuovo progetto binario nella directory progetti con cargo new pancake.
Dobbiamo aggiungere hello_macro e hello_macro_derive come dipendenze nel
file Cargo.toml del crate pancake. Se pubblichi le tue versioni di
hello_macro e hello_macro_derive su crates.io, saranno
dipendenze normali; altrimenti puoi specificarle come dipendenze di tipo path
come segue:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Inserisci il codice del Listato 20-37 in src/main.rs, ed esegui cargo run:
dovrebbe stampare Ciao, Macro! Il mio nome è Pancake!. L’implementazione del
trait HelloMacro dalla macro procedurale è stata inclusa senza che il
crate pancakes dovesse implementarla; il #[derive(HelloMacro)] ha aggiunto
l’implementazione del trait.
Successivamente, esploreremo come le altre tipologie di macro procedurali
differiscono dalle macro derive personalizzate.
Macro Simil-Attributo
Le macro simil-attributo sono simili alle macro derive personalizzate, ma
invece di generare codice per l’attributo derive, permettono di creare nuovi
attributi. Sono anche più flessibili: derive funziona solo per struct ed
enum; gli attributi possono essere applicati anche ad altri elementi, come
funzioni. Ecco un esempio di utilizzo di una macro simil-attributo. Supponiamo
di avere un attributo chiamato route che annota funzioni in un framework per
applicazioni web:
#[route(GET, "/")]
fn index() {Questo attributo #[route] sarebbe definito dal framework come una macro
procedurale. La firma della funzione che definisce la macro sarebbe simile a
questa:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Qui abbiamo due parametri di type TokenStream. Il primo è per il contenuto
dell’attributo: la parte GET, "/". Il secondo è il corpo dell’elemento a cui
l’attributo è associato: in questo caso, fn index() {} e il resto del corpo
della funzione.
A parte questo, le macro simil-attributo funzionano come le macro derive
personalizzate: si crea un crate con tipo crate proc-macro e si implementa
una funzione che genera il codice desiderato.
Macro Simil-Funzione
Le macro simil-funzione definiscono macro che sembrano chiamate di funzione.
Come le macro macro_rules!, sono più flessibili delle funzioni; per esempio,
possono prendere un numero variabile di argomenti. Tuttavia, le macro
macro_rules! possono essere definite solo usando la sintassi simile a match
vista nella sezione “Macro Dichiarative Per la Meta-Programmazione
Generale” vista in precedenza. Le macro simil-funzioni prendono un
parametro TokenStream e la loro definizione manipola quel TokenStream usando
codice Rust, come fanno le altre due tipologie di macro procedurali.
Un esempio di macro simil-funzione è una macro sql! che potrebbe essere
chiamata in questo modo:
let sql = sql!(SELECT * FROM posts WHERE id=1);Questa macro potrebbe analizzare la dichiarazione SQL al suo interno e
verificare che sia sintatticamente corretta, un’elaborazione molto più complessa
di quella che una macro macro_rules! può fare. La macro sql! sarebbe
definita così:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Questa definizione è simile alla firma di una macro derive personalizzata:
riceviamo i token che stanno dentro le parentesi e restituiamo il codice che
vogliamo generare.
Riepilogo
Wow! Ora hai appreso alcune funzionalità di Rust che probabilmente non userai troppo spesso, ma sarà utile sapere che sono disponibili in circostanze particolari. Abbiamo introdotto diversi argomenti complessi in modo che, quando li incontrerai nei suggerimenti dei messaggi di errore o nel codice scritto da altri, tu possa riconoscere questi concetti e sintassi. Usa questo capitolo come riferimento per guidarti nelle soluzioni.
Adesso metteremo in pratica tutto ciò di cui abbiamo discusso durante il libro e realizzeremo un altro progetto!
Progetto Finale: Costruire un Server Web Multi-Thread
È stato un lungo viaggio, ma siamo arrivati alla fine del libro. In questo capitolo, realizzeremo insieme un ultimo progetto per dimostrare alcuni dei concetti trattati negli ultimi capitoli, oltre a ripassare alcune lezioni precedenti.
Per il nostro progetto finale, realizzeremo un server web che dice “Ciao!” e appare come nella Figura 21-1 in un browser web.
Ecco il nostro piano per la costruzione del server web:
- Imparare un po’ su TCP e HTTP.
- Ascoltare le connessioni TCP su un socket.
- Analizzare un numero limitato di richieste HTTP.
- Creare una risposta HTTP appropriata.
- Migliorare le prestazioni del server implementando un pool di thread.
Figura 21-1: Il nostro progetto finale condiviso
Prima di iniziare, dovremmo menzionare due dettagli. Primo, il metodo che useremo non sarà il modo migliore per costruire un server web con Rust. I membri della community hanno pubblicato un numero di crate pronti per la produzione disponibili su crates.io che forniscono implementazioni più complete di server web e pool di thread rispetto a quelle che costruiremo. Tuttavia, la nostra intenzione in questo capitolo è aiutarti a imparare, non prendere la strada facile. Poiché Rust è un linguaggio di programmazione di sistema, possiamo scegliere il livello di astrazione con cui lavorare e possiamo scendere a un livello inferiore rispetto a quanto sia possibile o pratico in altri linguaggi.
Secondo, non useremo async e await qui. Costruire un pool di thread è già una sfida abbastanza grande da sola, senza aggiungere la costruzione di un runtime async! Tuttavia, noteremo come async e await potrebbero essere applicabili ad alcuni dei stessi problemi che vedremo in questo capitolo. In definitiva, come abbiamo notato nel Capitolo 17, molti runtime async usano pool di thread per gestire il loro lavoro.
Scriveremo quindi il server HTTP di base e il pool di thread manualmente in modo che tu possa imparare le idee e le tecniche generali dietro i crate che potresti usare in futuro.
Costruire un Server Web Single-Thread
Inizieremo facendo funzionare un server web con un singolo thread. Prima di cominciare, vediamo una breve panoramica dei protocolli coinvolti nella costruzione di un server web. I dettagli di questi protocolli sono oltre lo scopo di questo libro, ma una breve panoramica ti fornirà le informazioni di cui hai bisogno.
I due protocolli principali coinvolti nei server web sono Hypertext Transfer Protocol (HTTP) e Transmission Control Protocol (TCP). Entrambi i protocolli sono protocolli request-response, il che significa che un client avvia le richieste e un server ascolta le richieste e fornisce una risposta al client. I contenuti di quelle richieste e risposte sono definiti dai protocolli.
TCP è il protocollo di livello inferiore che descrive i dettagli su come le informazioni vengono trasferite da un server all’altro, ma non specifica cosa siano quelle informazioni. HTTP si basa su TCP definendo i contenuti delle richieste e delle risposte. Tecnicamente è possibile utilizzare HTTP con altri protocolli, ma nella stragrande maggioranza dei casi, HTTP invia i suoi dati su TCP. Lavoreremo con i byte grezzi delle richieste e risposte TCP e HTTP.
Ascoltare la Connessione TCP
Il nostro server web deve ascoltare una connessione TCP, quindi questa è la
prima parte su cui lavoreremo. La libreria standard offre un modulo std::net
che ci permette di farlo. Creiamo un nuovo progetto nel modo abituale:
$ cargo new ciao
Created binary (application) `ciao` project
$ cd ciao
Ora inserisci il codice nel Listato 21-1 in src/main.rs per iniziare. Questo
codice ascolterà all’indirizzo locale 127.0.0.1:7878 per flussi TCP in arrivo.
Quando riceve un flusso in arrivo, stamperà Connessione stabilita!.
use std::net::TcpListener; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); println!("Connessione stabilita!"); } }
Utilizzando TcpListener, possiamo ascoltare le connessioni TCP all’indirizzo
127.0.0.1:7878. Nell’indirizzo, la sezione prima dei due punti è un indirizzo
IP che rappresenta il tuo computer (è lo stesso su ogni computer e non
rappresenta specificamente il computer degli autori), e 7878 è la porta.
Abbiamo scelto questa porta per due motivi: HTTP non è normalmente accettato su
questa porta, quindi il nostro server è improbabile che entri in conflitto con
qualsiasi altro server web che potresti avere in esecuzione sulla tua macchina,
e 7878 è rust digitato sul tastierino numerico di un telefono.
La funzione bind in questo scenario funziona come la funzione new nel senso
che restituirà una nuova istanza di TcpListener. La funzione si chiama bind
perché, in ambito di connessioni di rete, connettersi a una porta per ascoltare
è noto come “binding a una porta”.
La funzione bind restituisce un Result<T, E>, il che indica che è possibile
che il binding fallisca, ad esempio, se eseguissimo due istanze del nostro
programma e quindi avessimo due programmi che ascoltano sulla stessa porta.
Poiché stiamo scrivendo un server di base solo per scopi di apprendimento, non
ci preoccuperemo di gestire questo tipi di errori; invece, usiamo unwrap per
interrompere il programma se si verificano errori.
Il metodo incoming su TcpListener restituisce un iteratore che ci fornisce
una sequenza di stream (più specificamente, stream di type TcpStream).
Un singolo stream rappresenta una connessione aperta tra il client e il
server. Connessione è il nome per l’intero processo di richiesta e risposta
in cui un client si connette al server, il server genera una risposta e il
server chiude la connessione. Di conseguenza, leggeremo dal TcpStream per
vedere cosa il client ha inviato e poi scriveremo la nostra risposta sullo
stream per inviare dati indietro al client. Nel complesso, questo ciclo
for elaborerà ogni connessione a turno e produrrà per noi una serie di
stream da gestire.
Per ora, la nostra gestione dello stream consiste nel chiamare unwrap per
terminare il nostro programma se lo stream ha errori; se non ci sono errori,
il programma stampa un messaggio. Aggiungeremo più funzionalità per il caso di
successo nel prossimo Listato. Il motivo per cui potremmo ricevere errori dal
metodo incoming quando un client si connette al server è che non stiamo
effettivamente iterando sulle connessioni. Invece, stiamo iterando sui
tentativi di connessione. La connessione potrebbe non riuscire per un certo
numero di motivi, molti dei quali specifici del sistema operativo. Ad esempio,
molti sistemi operativi hanno un limite al numero di connessioni aperte
simultanee che possono supportare; i nuovi tentativi di connessione oltre quel
numero produrranno un errore finché alcune delle connessioni aperte non vengono
chiuse.
Proviamo a eseguire questo codice! Invoca cargo run nel terminale e poi apri
127.0.0.1:7878 in un browser web. Il browser dovrebbe mostrare un messaggio di
errore come “Connection reset” perché il server non sta attualmente inviando
indietro alcun dato. Ma quando guardi il tuo terminale, dovresti vedere diversi
messaggi che sono stati stampati quando il browser si è connesso al server!
Running `target/debug/ciao`
Connessione stabilita!
Connessione stabilita!
Connessione stabilita!
A volte vedrai più messaggi stampati per una singola richiesta del browser; il motivo potrebbe essere che il browser sta facendo una richiesta per la pagina nonché una richiesta per altre risorse, come l’icona favicon.ico che appare nella scheda del browser.
Potrebbe anche essere che il browser stia cercando di connettersi al server più
volte perché il server non sta rispondendo con alcun dato. Quando stream esce
dallo scope e viene de-allocato alla fine del ciclo, la connessione viene
chiusa come parte dell’implementazione di drop. I browser a volte gestiscono
le connessioni chiuse tentando di ristabilirle, perché il problema potrebbe
essere temporaneo.
A volte i browser aprono più connessioni al server senza inviare alcuna richiesta, in modo che se devono poi fare delle richieste, quelle richieste possano avvenire più rapidamente. Quando ciò accade, il nostro server vedrà ogni connessione, indipendentemente dal fatto che ci siano richieste su quella connessione. Molte versioni di browser basati su Chrome fanno questo, ad esempio; puoi disabilitare quell’ottimizzazione utilizzando la modalità di navigazione privata o utilizzando un browser diverso.
Il fattore importante è che abbiamo ottenuto con successo un handle a una connessione TCP!
Ricorda di fermare il programma premendo ctrl-C quando hai
finito di eseguire una versione particolare del codice. Poi, riavvia il
programma invocando il comando cargo run dopo aver apportato ogni modifica al
codice per assicurarti di eseguire il codice più recente.
Leggere la Richiesta
Implementiamo ora la funzionalità per leggere la richiesta dal browser! Per
separare le responsabilità di ottenere prima una connessione e poi intraprendere
qualche azione con la connessione, inizieremo una nuova funzione per elaborare
le connessioni. In questa nuova funzione gestisci_connessione, leggeremo dati
dal flusso TCP e li stamperemo in modo da poter vedere i dati inviati dal
browser. Modifica il codice per essere come nel Listato 21-2.
use std::{ io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); gestisci_connessione(stream); } } fn gestisci_connessione(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); println!("Richiesta: {http_request:#?}"); }
TcpStream e stampa dei datiPortiamo std::io::BufReader e std::io::prelude nello scope per ottenere
accesso a trait e type che ci permettono di “leggere da” e “scrivere sullo”
stream. Nel ciclo for nella funzione main, invece di stampare un messaggio
che dice che abbiamo fatto una connessione, ora chiamiamo la nuova funzione
gestisci_connessione e le passiamo lo stream.
Nella funzione gestisci_connessione, creiamo una nuova istanza di BufReader
che incapsula un reference allo stream. Il BufReader aggiunge buffering
gestendo le chiamate ai metodi del trait std::io::Read per noi.
Creiamo una variabile chiamata http_request per raccogliere le righe della
richiesta che il browser invia al nostro server. Indichiamo che vogliamo
raccogliere queste righe in un vettore aggiungendo l’annotazione Vec<_>.
BufReader implementa il trait std::io::BufRead, che fornisce il metodo
lines. Il metodo lines restituisce un iteratore di Result<String, std::io::Error> dividendo lo stream di dati ogni volta che vede un byte
newline (nuova riga). Per ottenere ogni String, usiamo map e unwrap su
ogni Result. Il Result potrebbe essere un errore se i dati non sono UTF-8
validi o se c’è stato un problema durante la lettura dallo stream. Di nuovo,
un programma di produzione dovrebbe gestire questi errori in modo più elegante,
ma stiamo scegliendo di fermare il programma in caso di errore per semplicità.
Il browser segnala la fine di una richiesta HTTP inviando due caratteri newline di seguito, quindi per ottenere una richiesta dallo stream, prendiamo righe fino a ottenere una riga che è una stringa vuota. Una volta che abbiamo raccolto le righe nel vettore, le stampiamo usando una formattazione debug in modo da poter dare un’occhiata alle istruzioni che il browser web sta inviando al nostro server.
Proviamo questo codice! Avvia il programma e fai una richiesta nel browser web di nuovo. Nota che otterremo ancora una pagina di errore nel browser, ma l’output del nostro programma nel terminale ora apparirà simile a questo:
$ cargo run
Compiling ciao v0.1.0 (file:///progetti/ciao)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/ciao`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:144.0) Gecko/20100101 Firefox/144.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language: it-IT,it;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding: gzip, deflate, br, zstd",
"Sec-GPC: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: cross-site",
"Priority: u=0, i",
]
A seconda del tuo browser, potresti ottenere un output leggermente diverso. Ora
che stiamo stampando i dati della richiesta, possiamo vedere perché otteniamo
più connessioni da una singola richiesta del browser guardando il percorso dopo
GET nella prima riga della richiesta. Se le connessioni ripetute stanno tutte
richiedendo /, sappiamo che il browser sta cercando di recuperare /
ripetutamente perché non sta ottenendo una risposta dal nostro programma.
Scomponiamo questi dati di richiesta per capire cosa il browser sta chiedendo al nostro programma.
Guardare Più da Vicino una Richiesta HTTP
HTTP è un protocollo basato su testo, e una richiesta assume questo formato:
Metodo URI-Richiesto Versione-HTTP CRLF
headers CRLF
corpo-messaggio
La prima riga è la request line che contiene informazioni su cosa il client
sta richiedendo. La prima parte della request line indica il metodo usato,
come GET o POST, che descrive come il client sta facendo questa richiesta.
Il nostro client ha usato una richiesta GET, che significa che sta
richiedendo informazioni.
La parte successiva della request line è /, che indica l’uniform resource
identifier (URI) che il client sta richiedendo: un URI è quasi, ma non del
tutto, lo stesso di un uniform resource locator (URL). La differenza tra URI
e URL non è importante per i nostri scopi in questo capitolo, ma la specifica
HTTP usa il termine URI, quindi possiamo sostituire mentalmente URL per
URI qui.
L’ultima parte è la versione HTTP che il client usa, e poi la request line
termina con una sequenza CRLF. (CRLF sta per carriage return e line feed,
che sono termini dai giorni della macchina da scrivere!) La sequenza CRLF può
anche essere scritta come \r\n, dove \r è un “ritorno a capo” e \n è un
“nuova linea”. La sequenza CRLF separa la request line dal resto dei dati
della richiesta. Nota che quando la CRLF viene stampata, vediamo iniziare una
nuova riga piuttosto che \r\n.
Guardando i dati della request line che abbiamo ricevuto eseguendo il nostro
programma finora, vediamo che GET è il metodo, / è l’URI della richiesta, e
HTTP/1.1 è la versione.
Dopo la request line, le righe rimanenti a partire da Host: in poi sono
header (intestazioni). Le richieste GET non hanno corpo.
Prova a fare una richiesta da un browser diverso o chiedendo un indirizzo diverso, come 127.0.0.1:7878/test, per vedere come cambiano i dati della richiesta.
Ora che sappiamo cosa il browser sta chiedendo, rispondiamo con qualche dato!
Scrivere una Risposta
Stiamo per implementare l’invio di dati in risposta a una richiesta del client. Le risposte hanno il seguente formato:
Versione-HTTP Codice-di-Stato Enunciazione CRLF
headers CRLF
corpo-messaggio
La prima riga è una status line che contiene la versione HTTP usata nella risposta, un codice di stato numerico che riassume il risultato della richiesta, e una enunciazione che fornisce una descrizione testuale del codice di stato. Dopo la sequenza CRLF ci sono eventuali header, un’altra sequenza CRLF, e il corpo della risposta.
Ecco un esempio di risposta che usa la versione HTTP 1.1 e ha un codice di stato di 200, una enunciazione OK, nessun header, e nessun corpo:
HTTP/1.1 200 OK\r\n\r\n
Il codice di stato 200 è la risposta standard di successo. Il testo è una
minuscola risposta HTTP di successo. Scriviamola sullo stream come nostra
risposta a una richiesta di successo! Dalla funzione gestisci_connessione,
rimuovi il println! che stava stampando i dati della richiesta e sostituiscilo
con il codice nel Listato 21-3.
use std::{ io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); gestisci_connessione(stream); } } fn gestisci_connessione(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let risposta = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(risposta.as_bytes()).unwrap(); }
La prima nuova riga definisce la variabile risposta che contiene i dati del
messaggio di successo. Poi, chiamiamo as_bytes sulla nostra risposta per
convertire i dati della stringa in byte. Il metodo write_all su stream
prende un &[u8] e invia quei byte direttamente sulla connessione. Poiché
l’operazione write_all potrebbe fallire, usiamo unwrap su qualsiasi
risultato di errore come prima. Di nuovo, in un’applicazione reale,
aggiungeresti la gestione degli errori qui.
Con questi cambiamenti, eseguiamo il nostro codice e facciamo una richiesta. Non stiamo più stampando alcun dato sul terminale, quindi non vedremo alcun output diverso dall’output di Cargo. Quando carichi 127.0.0.1:7878 in un browser web, dovresti ottenere una pagina vuota invece di un errore. Hai appena codificato manualmente la ricezione di una richiesta HTTP e l’invio di una risposta!
Restituire Vero HTML
Implementiamo la funzionalità per restituire qualcosa più di una pagina vuota. Crea un nuovo file ciao.html nella radice della directory del tuo progetto, non nella directory src. Puoi inserire qualsiasi HTML tu voglia; il Listato 21-4 mostra una possibilità.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Ciao!</title>
</head>
<body>
<h1>Ciao!</h1>
<p>Un saluto da Rust</p>
</body>
</html>
Questo è un documento HTML5 minimale con un’intestazione e del testo. Per
restituire questo dal server quando viene ricevuta una richiesta,
modificheremo gestisci_connessione come mostrato nel Listato 21-5 per leggere
il file HTML, aggiungerlo alla risposta come corpo, e inviarlo.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; // --taglio-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); gestisci_connessione(stream); } } fn gestisci_connessione(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let status_line = "HTTP/1.1 200 OK"; let contenuto = fs::read_to_string("ciao.html").unwrap(); let lunghezza = contenuto.len(); let risposta = format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}"); stream.write_all(risposta.as_bytes()).unwrap(); }
Abbiamo aggiunto fs all’istruzione use per portare il modulo filesystem
della libreria standard nello scope. Il codice per leggere i contenuti di un
file in una stringa dovrebbe apparire familiare; l’abbiamo usato quando abbiamo
letto i contenuti di un file per il nostro progetto I/O nel Listato 12-4.
Poi usiamo format! per aggiungere il contenuto del file come corpo della
risposta di successo. Per garantire una risposta HTTP valida, aggiungiamo
l’header Content-Length, che è impostato alla dimensione del nostro corpo
della risposta, in questo caso la dimensione di ciao.html.
Esegui questo codice con cargo run e carica 127.0.0.1:7878 nel tuo browser;
dovresti vedere il tuo HTML renderizzato!
Attualmente, stiamo ignorando i dati della richiesta in http_request e stiamo
solo inviando indietro i contenuti del file HTML incondizionatamente. Questo
significa che se provi a richiedere 127.0.0.1:7878/altra-pagina nel tuo
browser, otterrai ancora questa stessa risposta HTML. Al momento, il nostro
server è molto limitato e non fa quello che fanno la maggior parte dei server
web. Vogliamo personalizzare le nostre risposte a seconda della richiesta e
rispondere con il file HTML solo alle richieste corrette a /.
Validare la Richiesta e Rispondere Selettivamente
Al momento, il nostro server web restituirà l’HTML nel file indipendentemente da
cosa il client abbia richiesto. Aggiungiamo funzionalità al nostro codice per
controllare che il browser stia richiedendo / prima di restituire il file HTML
e per restituire un errore se il browser richiede qualcos’altro. Per questo
dobbiamo modificare gestisci_connessione, come mostrato nel Listato 21-6.
Questo nuovo codice controlla il contenuto della richiesta ricevuta rispetto a
quello che sappiamo essere una richiesta per /, e aggiunge blocchi if e
else per trattare le richieste in modo diverso.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); gestisci_connessione(stream); } } // --taglio-- fn gestisci_connessione(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contenuto = fs::read_to_string("ciao.html").unwrap(); let lunghezza = contenuto.len(); let risposta = format!( "{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}" ); stream.write_all(risposta.as_bytes()).unwrap(); } else { // qualche altra richiesta } }
Guarderemo solo alla prima riga della richiesta HTTP, quindi piuttosto che
leggere l’intera richiesta in un vettore, stiamo chiamando next per ottenere
il primo elemento dall’iteratore. Il primo unwrap si occupa dell’Option e
ferma il programma se l’iteratore non ha elementi. Il secondo unwrap gestisce
il Result e ha lo stesso effetto dell’unwrap che era nella map aggiunta
nel Listato 21-2.
Successivamente, controlliamo la request_line per vedere se è uguale alla
request line di una richiesta GET al percorso / . Se lo è, il blocco if
restituisce i contenuti del nostro file HTML.
Se la request_line non è uguale alla richiesta GET al percorso / ,
significa che abbiamo ricevuto qualche altra richiesta. Aggiungeremo codice al
blocco else tra un momento per rispondere a tutte le altre richieste.
Esegui questo codice ora e richiedi 127.0.0.1:7878; dovresti ottenere l’HTML in ciao.html. Se fai qualsiasi altra richiesta, come 127.0.0.1:7878/altra-pagina, otterrai un errore di connessione come quelli che hai visto eseguendo il codice dei Listati 21-1 e 21-2.
Ora aggiungiamo il codice nel Listato 21-7 al blocco else per restituire una
risposta con il codice di stato 404, che segnala che il contenuto per la
richiesta non è stato trovato. Restituiremo anche un po’ di HTML per una pagina
da renderizzare nel browser indicando la risposta all’utente finale.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); gestisci_connessione(stream); } } fn gestisci_connessione(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contenuto = fs::read_to_string("ciao.html").unwrap(); let lunghezza = contenuto.len(); let risposta = format!( "{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}" ); stream.write_all(risposta.as_bytes()).unwrap(); // --taglio-- } else { let status_line = "HTTP/1.1 404 NOT FOUND"; let contenuto = fs::read_to_string("404.html").unwrap(); let lunghezza = contenuto.len(); let risposta = format!( "{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}" ); stream.write_all(risposta.as_bytes()).unwrap(); } }
Qui, la nostra risposta ha una status line con codice di stato 404 ed
enunciazione NOT FOUND. Il corpo della risposta sarà l’HTML nel file
404.html. Dovrai creare un file 404.html accanto a ciao.html per la pagina
di errore; di nuovo, sentiti libero di usare qualsiasi HTML tu voglia, o usa
l’esempio HTML nel Listato 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Oops!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Scusa, non so cosa stai cercando.</p>
</body>
</html>
Con questi cambiamenti, esegui di nuovo il tuo server. Richiedere 127.0.0.1:7878 dovrebbe restituire i contenuti di ciao.html, e qualsiasi altra richiesta, come 127.0.0.1:7878/altra-pagina, dovrebbe restituire l’HTML di errore da 404.html.
Riscrittura
Al momento, i blocchi if e else hanno molta ripetizione: entrambi stanno
leggendo file e scrivendo i contenuti dei file sullo stream. Le uniche
differenze sono la status line e il nome del file. Rendiamo il codice più
conciso estraendo quelle differenze in righe if e else separate che
assegneranno i valori della status line e del nome del file a variabili;
possiamo poi usare quelle variabili incondizionatamente nel codice per leggere
il file e scrivere la risposta. Il Listato 21-9 mostra il codice risultante dopo
aver sostituito i blocchi if e else.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); gestisci_connessione(stream); } } // --taglio-- fn gestisci_connessione(mut stream: TcpStream) { // --taglio-- let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = if request_line == "GET / HTTP/1.1" { ("HTTP/1.1 200 OK", "ciao.html") } else { ("HTTP/1.1 404 NOT FOUND", "404.html") }; let contenuto = fs::read_to_string(filename).unwrap(); let lunghezza = contenuto.len(); let risposta = format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}"); stream.write_all(risposta.as_bytes()).unwrap(); }
if e else per contenere solo il codice che differisce tra i due casiOra i blocchi if e else restituiscono solo i valori appropriati per la
status line e il nome del file in una tupla; poi usiamo la destrutturazione
per assegnare questi due valori a status_line e filename usando un pattern
nella dichiarazione let, come discusso nel Capitolo 19.
Il codice precedentemente duplicato è ora fuori dai blocchi if e else e usa
le variabili status_line e filename. Questo rende più facile vedere la
differenza tra i due casi, e significa che abbiamo solo un posto dove guardare
per aggiornare il codice se vogliamo cambiare come funziona la lettura del file
e la scrittura della risposta. Il comportamento del codice nel Listato 21-9 sarà
lo stesso di quello nel Listato 21-7.
Fantastico! Ora abbiamo un semplice server web in circa 40 righe di codice Rust che risponde a una richiesta con una pagina di contenuto e risponde a tutte le altre richieste con una risposta 404.
Attualmente, il nostro server gira in un singolo thread, il che significa che può servire solo una richiesta alla volta. Esaminiamo come questo possa essere un problema simulando alcune richieste lente. Poi, lo risolveremo in modo che il nostro server possa gestire più richieste contemporaneamente.
Da Server Single-Thread a Server Multi-Thread
Al momento, il server elaborerà ogni richiesta a turno, il che significa che non elaborerà una seconda connessione fino a quando la prima connessione non avrà finito di essere elaborata. Se il server riceve sempre più richieste, questa esecuzione seriale sarebbe sempre meno ottimale. Se il server riceve una richiesta che richiede molto tempo per essere elaborata, le richieste successive dovranno aspettare fino a quando la richiesta lunga non sarà finita, anche se le nuove richieste potrebbero essere elaborate rapidamente. Dovremo risolvere questo problema, ma prima osserviamo il problema in azione.
Simulare una Richiesta Lenta
Vedremo come una richiesta che impiega molto tempo a essere processata possa influenzare le altre richieste fatte alla nostra implementazione attuale del server. Il Listato 21-10 implementa la gestione di una richiesta ad /attesa con una risposta lenta simulata, che farà attendere il server per cinque secondi prima di rispondere.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; // --taglio-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); gestisci_connessione(stream); } } fn gestisci_connessione(mut stream: TcpStream) { // --taglio-- let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "ciao.html"), "GET /attesa HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "ciao.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; // --taglio-- let contenuto = fs::read_to_string(filename).unwrap(); let lunghezza = contenuto.len(); let risposta = format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}"); stream.write_all(risposta.as_bytes()).unwrap(); }
Siamo passati da if a match ora che abbiamo tre casi. Dobbiamo
esplicitamente fare match su una slice di request_line per trovare
corrispondenza con dei valori letterali stringa; match non fa riferimenti e
de-referenziamenti automatici, come fa il metodo di uguaglianza.
Il primo ramo è uguale al blocco if del Listato 21-9. Il secondo ramo fa
match di una richiesta ad /attesa. Quando viene ricevuta quella richiesta,
il server attende per cinque secondi prima di inviare la pagina HTML di
successo. Il terzo ramo è lo stesso del blocco else del Listato 21-9.
Puoi vedere quanto sia primitivo il nostro server: librerie reali gestirebbero il riconoscimento di richieste multiple in un modo molto meno verboso!
Avvia il server usando cargo run. Poi, apri due finestre del browser: una per
http://127.0.0.1:7878 e l’altra per http://127.0.0.1:7878/attesa. Se
inserisci l’URI / alcune volte, come prima, vedrai che risponde rapidamente.
Ma se inserisci /attesa e poi carichi /, vedrai che / aspetta fino a
quando sleep non ha completato l’attesa per i suoi cinque secondi completi
prima di caricarsi.
Ci sono molteplici tecniche che potremmo usare per evitare che le richieste si accumulino dietro a una richiesta lenta, inclusa l’uso di async come abbiamo fatto nel Capitolo 17; quella che implementeremo è un thread pool.
Migliorare la Produttività con un Thread Pool
Un thread pool è un gruppo di thread generati che sono pronti e in attesa di gestire un compito. Quando il programma riceve un nuovo compito, assegna uno dei thread nel gruppo al compito, e quel thread elaborerà il compito. I thread rimanenti nel gruppo sono disponibili per gestire qualsiasi altro compito che arrivi mentre il primo thread sta elaborando. Quando il primo thread ha finito di elaborare il suo compito, viene restituito al gruppo di thread inattivi, pronto per gestire un nuovo compito. Un thread pool ti permette quindi di elaborare connessioni concorrentemente, aumentando la produttività del tuo server.
Limiteremo il numero di thread nel gruppo a un numero piccolo per proteggerci da attacchi DoS; se il programma creasse un nuovo thread per ogni richiesta in arrivo, qualcuno che fa 10 milioni di richieste al nostro server potrebbe causare grossi problemi utilizzando tutte le risorse del nostro server e bloccando l’elaborazione delle richieste fino a fermarla.
Quindi, invece di generare thread illimitati, avremo un numero fisso di
thread in attesa nel gruppo. Le richieste in arrivo vengono mandate al gruppo
per l’elaborazione. Il gruppo manterrà una coda di richieste in arrivo. Ogni
thread del gruppo prenderà una richiesta da questa coda, la gestirà e poi
chiederà un’altra richiesta dalla coda. Con questo modello, possiamo elaborare
fino a N richieste simultaneamente, dove N è il numero di thread. Se
ogni thread sta rispondendo a una richiesta a lungo termine, le richieste
successive possono ancora accumularsi nella coda, ma abbiamo aumentato il numero
di richieste a lungo termine che possiamo gestire prima di raggiungere quel
punto.
Questa tecnica è solo una delle molte maniere per migliorare la produttività di un server web. Altre opzioni che potresti esplorare sono il modello fork/join, il modello I/O async a singolo thread, e il modello I/O async multi-thread. Se sei interessato a questo argomento, puoi leggere ed informarti su queste ed altre soluzioni e provare a implementarle; con un linguaggio di basso livello come Rust, tutte queste opzioni sono possibili.
Prima di iniziare a implementare un pool di thread, parliamo prima di come dovrebbe essere usato un pool. Quando stai cercando di progettare codice, scrivere prima l’interfaccia client può aiutare a guidare il tuo design. Scrivi l’API del codice così che sia strutturata nel modo in cui vuoi chiamarla; poi implementa la funzionalità dentro questa struttura invece di implementare prima la funzionalità e poi progettare l’API pubblica.
In modo simile a come abbiamo usato lo sviluppo guidato dai test nel progetto del Capitolo 12, qui invece useremo lo sviluppo guidato dal compilatore. Scriveremo il codice che chiama le funzioni che vogliamo, e poi guarderemo agli errori dal compilatore per determinare cosa dovremmo cambiare dopo per far funzionare il codice. Prima di farlo, tuttavia, esploreremo la tecnica che non useremo come punto di partenza.
Generare un Thread per Ogni Richiesta
Per prima cosa, esploriamo come potrebbe apparire il nostro codice se creasse un nuovo thread per ogni connessione. Come detto, questa non è la nostra soluzione finale a causa dei problemi legati al numero illimitato di thread che potrebbero essere creati, ma è un punto di partenza per avere un server multi-thread funzionante. Poi, aggiungeremo il thread pool come miglioramento, e confrontare le due soluzioni sarà più facile.
Il Listato 21-11 mostra le modifiche da fare a main per generare un nuovo
thread per gestire ogni stream nel ciclo for.
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); thread::spawn(|| { gestisci_connessione(stream); }); } } fn gestisci_connessione(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "ciao.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "ciao.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; let contenuto = fs::read_to_string(filename).unwrap(); let lunghezza = contenuto.len(); let risposta = format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}"); stream.write_all(risposta.as_bytes()).unwrap(); }
Come hai imparato nel Capitolo 16, thread::spawn creerà un nuovo thread e
poi eseguirà il codice della chiusura nel nuovo thread. Se esegui questo
codice e carichi /attesa nel tuo browser, poi / in altre due schede del
browser, vedrai infatti che le richieste a / non devono aspettare che
/attesa finisca. Tuttavia, come abbiamo menzionato, questo alla fine
sovraccaricherà il sistema perché staresti creando nuovi thread senza alcun
limite.
Potresti anche ricordare dal Capitolo 17 che questa è esattamente la situazione in cui async e await eccellono! Tieni a mente questo mentre costruiamo il thread pool e pensa a come le cose sarebbero diverse o uguali con async.
Creare un Numero Finito di Thread
Vogliamo che il nostro thread pool funzioni in un modo simile e familiare in
modo che passare dai thread a un thread pool non richieda grandi
cambiamenti al codice che usa la nostra API. Il Listato 21-12 mostra
l’interfaccia ipotetica per una struct ThreadPool che vogliamo usare invece di
thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
gestisci_connessione(stream);
});
}
}
fn gestisci_connessione(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "ciao.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "ciao.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contenuto = fs::read_to_string(filename).unwrap();
let lunghezza = contenuto.len();
let risposta =
format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}");
stream.write_all(risposta.as_bytes()).unwrap();
}ThreadPoolUsiamo ThreadPool::new per creare un nuovo gruppo di thread con un numero
configurabile di thread, in questo caso 4. Poi, nel ciclo for,
pool.execute ha un interfaccia simile a thread::spawn nel senso che prende
una chiusura che il gruppo dovrebbe eseguire per ogni stream. Dobbiamo
implementare pool.execute in modo che prenda la chiusura e la dia a un
thread nel gruppo per eseguirla. Questo codice non si compilerà ancora, ma lo
proveremo in modo che il compilatore ci guidi su come sistemarlo.
Costruire ThreadPool Usando lo Sviluppo Guidato dal Compilatore
Apporta le modifiche riportate nel Listato 21-12 a src/main.rs, quindi
utilizziamo gli errori del compilatore da cargo check per guidare il nostro
sviluppo. Ecco il primo errore che otteniamo:
$ cargo check
Checking ciao v0.1.0 (file:///progetti/ciao)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `ciao` (bin "ciao") due to 1 previous error
Ottimo! Questo errore ci dice che abbiamo bisogno di un type o modulo
ThreadPool, quindi ne creeremo uno adesso. La nostra implementazione di
ThreadPool sarà indipendente dal tipo di lavoro svolto dal nostro server web.
Quindi, trasformiamo il crate ciao da un crate binario a un crate
libreria per contenere la nostra implementazione di ThreadPool. Dopo essere
passati a un crate libreria, potremmo anche utilizzare la libreria del thread
pool separata per qualsiasi lavoro che vogliamo svolgere utilizzando un gruppo
di thread, non solo per eseguire richieste web.
Creiamo un file src/lib.rs che contenga quanto segue, ovvero la definizione
più semplice di una struct ThreadPool che possiamo avere per ora:
pub struct ThreadPool;Quindi, modifichiamo il file main.rs per portare ThreadPool nello scope
dal crate della libreria aggiungendo il seguente codice all’inizio di
src/main.rs:
use ciao::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
gestisci_connessione(stream);
});
}
}
fn gestisci_connessione(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "ciao.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "ciao.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contenuto = fs::read_to_string(filename).unwrap();
let lunghezza = contenuto.len();
let risposta =
format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}");
stream.write_all(risposta.as_bytes()).unwrap();
}Questo codice ancora non funzionerà, ma controlliamolo di nuovo per ottenere il prossimo errore che dobbiamo risolvere:
$ cargo check
Checking ciao v0.1.0 (file:///progetti/ciao)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `ciao` (bin "ciao") due to 1 previous error
Questo errore indica che ora dobbiamo creare una funzione associata denominata
new per ThreadPool. Sappiamo anche che new deve avere un parametro che può
accettare 4 come argomento e dovrebbe restituire un’istanza ThreadPool.
Implementiamo la funzione new più semplice che abbia queste caratteristiche:
pub struct ThreadPool;
impl ThreadPool {
pub fn new(dimensione: usize) -> ThreadPool {
ThreadPool
}
}Abbiamo scelto usize come type del parametro dimensione perché sappiamo
che un numero negativo di thread non ha alcun senso. Sappiamo anche che
useremo questo 4 come numero di elementi in una collezione di thread, che è
lo scopo del type usize, come discusso nella sezione “Il Type
Intero”del Capitolo 3.
Controlliamo nuovamente il codice:
$ cargo check
Checking ciao v0.1.0 (file:///progetti/ciao)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `ciao` (bin "ciao") due to 1 previous error
Ora l’errore si verifica perché non abbiamo un metodo execute su ThreadPool.
Ricorda dalla sezione “Creare un Numero Finito di
Thread” che abbiamo deciso che il nostro
thread pool dovrebbe avere un’interfaccia simile a thread::spawn. In
aggiunta, implementeremo la funzione execute in modo che prenda la chiusura
che riceve e la dia a un thread inattivo nel gruppo per eseguirla.
Definiremo il metodo execute su ThreadPool in modo che accetti una chiusura
come parametro. Ricorda dalla sezione “Restituire i Valori Catturati dalle
Chiusure” del Capitolo 13 che possiamo
accettare chiusure come parametri con tre diversi trait: Fn, FnMut e
FnOnce. Dobbiamo decidere quale tipo di chiusura utilizzare in questo caso.
Sappiamo che finiremo per fare qualcosa di simile all’implementazione della
libreria standard thread::spawn, quindi possiamo guardare quali sono i vincoli
definiti nella firma di thread::spawn sul suo parametro. La documentazione ci
mostra quanto segue:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Il parametro di type F è quello che ci interessa in questo caso; il
parametro di type T è relativo al valore di ritorno, e non ci interessa.
Possiamo vedere che spawn utilizza FnOnce come vincolo di trait su F.
Probabilmente è quello che vogliamo anche noi, perché alla fine passeremo
l’argomento che otteniamo in execute a spawn. Possiamo essere ulteriormente
sicuri che FnOnce sia il trait che vogliamo utilizzare perché il thread
per l’esecuzione di una richiesta eseguirà solo una volta la chiusura di quella
richiesta, il che corrisponde a Once in FnOnce.
Il parametro di type F ha anche il vincolo di trait Send e il vincolo di
lifetime 'static, che sono utili nella nostra situazione: abbiamo bisogno di
Send per trasferire la chiusura da un thread all’altro e di 'static perché
non sappiamo quanto tempo impiegherà il thread per eseguire quanto richiesto.
Creiamo un metodo execute su ThreadPool che prenderà un parametro generico
di type F con questi vincoli:
pub struct ThreadPool;
impl ThreadPool {
// --taglio--
pub fn new(dimensione: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Continuiamo a usare () dopo FnOnce perché questo FnOnce rappresenta una
chiusura che non accetta parametri e restituisce il type unitario ().
Proprio come nelle definizioni delle funzioni, il type di ritorno può essere
omesso dalla firma, ma anche se non abbiamo parametri, abbiamo comunque bisogno
delle parentesi.
Ancora una volta, questa è l’implementazione più semplice del metodo execute:
non fa nulla, ma stiamo solo cercando di far compilare il nostro codice.
Controlliamo di nuovo:
$ cargo check
Checking ciao v0.1.0 (file:///progetti/ciao)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
Si compila! Ma nota che se provi cargo run e fai una richiesta nel browser,
vedrai gli errori nel browser che abbiamo visto all’inizio del capitolo. La
nostra libreria non sta ancora chiamando la chiusura passata a execute!
Nota: un detto che potreste sentire riguardo ai linguaggi con compilatori rigorosi, come Haskell e Rust, è “Se il codice si compila, funziona”. Ma questo detto non è universalmente vero. Il nostro progetto si compila, ma non fa assolutamente nulla! Se stessimo realizzando un progetto reale e completo, questo sarebbe un buon momento per iniziare a scrivere dei test unitari per verificare che il codice si compili e abbia il comportamento che desideriamo.
Una considerazione: cosa cambierebbe qui se eseguissimo una future invece di una chiusura?
Validare il Numero di Thread in new
Non stiamo facendo nulla con i parametri di new e execute. Implementiamo il
corpo di queste funzioni con il comportamento desiderato. Per iniziare, pensiamo
a new. In precedenza abbiamo scelto un type senza segno per il parametro
dimensione perché un gruppo con un numero negativo di thread non ha senso.
Tuttavia, anche un gruppo con zero thread non ha senso, ma zero è un usize
perfettamente valido. Aggiungeremo del codice per verificare che dimensione
sia maggiore di zero prima di restituire un’istanza ThreadPool e faremo andare
in panic il programma se riceve uno zero utilizzando la macro assert!, come
mostrato nel Listato 21-13.
pub struct ThreadPool;
impl ThreadPool {
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
ThreadPool
}
// --taglio--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool::new per generare un errore se dimensione è zeroAbbiamo anche aggiunto della documentazione per il nostro ThreadPool con
commenti di documentazione. Nota che abbiamo seguito le buone pratiche di
documentazione aggiungendo una sezione che evidenzia le situazioni in cui la
nostra funzione può generare un panic, come discusso nel Capitolo 14. Prova ad
eseguire cargo doc --open e clicca sulla struct ThreadPool per vedere come
appare la documentazione generata per new!
Invece di aggiungere la macro assert! come abbiamo fatto qui, potremmo
cambiare new in build e restituire un Result come abbiamo fatto con
Config::build nel progetto I/O nel Listato 12-9. Ma in questo caso abbiamo
deciso che cercare di creare un thread pool senza alcun thread dovrebbe
essere un errore irrecuperabile. Se ti senti ambizioso, prova a scrivere una
funzione chiamata build con la seguente firma per confrontarla con la funzione
new:
pub fn build(size: usize) -> Result<ThreadPool, ErroreCreazionePool>Creare Spazio per Memorizzare i Thread
Ora che abbiamo un modo per sapere che abbiamo un numero valido di thread da
memorizzare nel gruppo, possiamo creare quei thread e memorizzarli nella
struct ThreadPool prima di restituire la struct. Ma come si “memorizza” un
thread? Diamo un’altra occhiata alla firma di thread::spawn:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,La funzione spawn restituisce un JoinHandle<T>, dove T è il type che la
chiusura restituisce. Proviamo anche noi a usare JoinHandle e vediamo cosa
succede. Nel nostro caso, le chiusure che stiamo passando al thread pool
gestiranno la connessione e non restituiranno nulla, quindi T sarà il type
unitario ().
Il codice nel Listato 21-14 verrà compilato, ma non creerà ancora alcun
thread. Abbiamo modificato la definizione di ThreadPool per contenere un
vettore di istanze thread::JoinHandle<()>, inizializzato il vettore con una
capacità di dimensione, impostato un ciclo for che eseguirà del codice per
creare i thread e restituito un’istanza ThreadPool che li contiene.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --taglio--
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let mut threads = Vec::with_capacity(dimensione);
for _ in 0..dimensione {
// crea qualche thread e memorizzali in un vettore
}
ThreadPool { threads }
}
// --taglio--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool per contenere i threadAbbiamo portato std::thread nello scope della libreria crate perché stiamo
utilizzando thread::JoinHandle come type degli elementi nel vettore in
ThreadPool.
Una volta ricevuta una dimensione valida, il nostro ThreadPool crea un nuovo
vettore in grado di contenere dimensione elementi. La funzione with_capacity
svolge lo stesso compito di Vec::new, ma con un’importante differenza:
pre-alloca lo spazio nel vettore. Poiché sappiamo che dobbiamo memorizzare
dimensione elementi nel vettore, eseguire questa allocazione in anticipo è
leggermente più efficiente rispetto all’utilizzo di Vec::new, che ridimensiona
se stesso man mano che vengono inseriti gli elementi.
Quando esegui nuovamente cargo check, dovrebbe avere esito positivo.
Inviare Codice da ThreadPool a un Thread
Abbiamo lasciato un commento nel ciclo for nel Listato 21-14 riguardo alla
creazione di thread. Qui vedremo come creare effettivamente i thread. La
libreria standard fornisce thread::spawn come metodo per creare thread, e
thread::spawn si aspetta di ricevere del codice che il thread deve eseguire
non appena viene creato. Tuttavia, nel nostro caso, vogliamo creare i thread e
farli attendere il codice che invieremo in seguito. L’implementazione dei
thread della libreria standard non include alcun modo per farlo; dobbiamo
implementarlo manualmente.
Implementeremo questo comportamento introducendo una nuova struttura dati
intermedia tra ThreadPool e i thread che gestirà questo nuovo comportamento.
Chiameremo questa struttura dati Worker, che è un termine comune nelle
implementazioni di pooling. Il Worker raccoglie il codice che deve essere
eseguito ed esegue il codice nel suo thread.
Pensate alle persone che lavorano in cucina in un ristorante: i lavoratori aspettano che arrivino le ordinazioni dai clienti, quindi sono responsabili di prendere quelle ordinazioni e soddisfarle.
Invece di memorizzare un vettore di istanze JoinHandle<()> nel thread
pool, memorizzeremo le istanze della struct Worker. Ogni Worker
memorizzerà una singola istanza JoinHandle<()>. Quindi, implementeremo un
metodo su Worker che prenderà una chiusura di codice da eseguire e la invierà
al thread già in esecuzione per l’esecuzione. Assegneremo anche a ciascun
Worker un id in modo da poter distinguere tra le diverse istanze di Worker
nel gruppo quando facciamo logging o debugging.
Ecco il nuovo processo che avverrà quando creeremo un ThreadPool.
Implementeremo il codice che invia la chiusura al thread dopo aver impostato
Worker in questo modo:
- Definire una struttura
Workerche contenga unide unJoinHandle<()>. - Modificare
ThreadPoolin modo che contenga un vettore di istanzeWorker. - Definire una funzione
Worker::newche accetta un numeroide restituisce un’istanzaWorkerche contiene l’ide un thread generato con una chiusura vuota. - In
ThreadPool::new, utilizzare il contatore del cicloforper generare unid, creare un nuovoWorkercon quell’ide memorizzare ilWorkernel vettore.
Se sei pronto per una sfida, prova a implementare queste modifiche da solo prima di guardare il codice nel Listato 21-15.
Pronto? Ecco il Listato 21-15 con un modo per apportare le modifiche precedenti.
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --taglio--
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera _panic_ se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --taglio--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool per contenere istanze Worker invece di contenere direttamente i threadAbbiamo cambiato il nome del campo su ThreadPool da threads a workers
perché ora contiene istanze Worker invece di istanze JoinHandle<()>. Usiamo
il contatore nel ciclo for come argomento per Worker::new e memorizziamo
ogni nuovo Worker nel vettore chiamato workers.
Il codice esterno (come il nostro server in src/main.rs) non ha bisogno di
conoscere i dettagli di implementazione relativi all’uso di una struct
Worker all’interno di ThreadPool, quindi rendiamo privata la struct
Worker e la sua funzione new. La funzione Worker::new utilizza l’id che
le forniamo e memorizza un’istanza JoinHandle<()> creata generando un nuovo
thread utilizzando una chiusura vuota.
Nota: se il sistema operativo non è in grado di creare un thread perché non ci sono risorse di sistema sufficienti,
thread::spawnandrà in panic. Ciò causerà il panic dell’intero server, anche se la creazione di alcuni thread potrebbe avere esito positivo. Per semplicità, questo comportamento va bene, ma in un’implementazione di thread pool di produzione, probabilmente si preferirà utilizzarestd::thread::Buildere il suospawnche restituisce inveceResult.
Questo codice verrà compilato e memorizzerà il numero di istanze Worker che
abbiamo specificato come argomento di ThreadPool::new. Ma non stiamo ancora
elaborando la chiusura che otteniamo in execute. Vediamo come farlo.
Inviare Richieste ai Thread Tramite Canali
Il prossimo problema che affronteremo è che le chiusure fornite a
thread::spawn non fanno assolutamente nulla. Attualmente, otteniamo la
chiusura che vogliamo eseguire nel metodo execute. Ma dobbiamo fornire a
thread::spawn una chiusura da eseguire quando creiamo ogni Worker durante la
creazione del ThreadPool.
Vogliamo che le struct Worker che abbiamo appena creato recuperino il codice
da eseguire da una coda contenuta nel ThreadPool e lo inviino al proprio
thread per l’esecuzione.
I canali che abbiamo imparato a conoscere nel Capitolo 16, un modo semplice per
comunicare tra due thread, sarebbero perfetti per questo caso d’uso. Useremo
un canale da far funzionare come coda di lavori, e execute invierà un lavoro
dal ThreadPool alle istanze Worker, che invieranno il lavoro al proprio
thread. Ecco il piano:
- Il
ThreadPoolcreerà un canale e diverrà l’estremità mittente. - Ogni
Workerdiverrà il ricevitore. - Creeremo una nuova struct
Jobche conterrà le chiusure che vogliamo inviare lungo il canale. - Il metodo
executeinvierà il lavoro che vuole eseguire tramite il mittente. - Nel suo thread, il
Workereseguirà un ciclo sul suo ricevitore ed eseguirà le chiusure di tutti i lavori che riceve.
Iniziamo creando un canale in ThreadPool::new e conservando il mittente
nell’istanza ThreadPool, come mostrato nel Listato 21-16. La struttura Job
per ora non contiene nulla, ma sarà il type di elemento che invieremo nel
canale.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --taglio--
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id));
}
ThreadPool { workers, mittente }
}
// --taglio--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool per memorizzare il mittente di un canale che trasmette istanze JobIn ThreadPool::new, creiamo il nostro nuovo canale e facciamo in modo che il
gruppo mantenga l’estremità del mittente. Questo verrà compilato con successo.
Proviamo a passare un ricevitore del canale a ciascun Worker mentre il
thread pool crea il canale. Sappiamo che vogliamo utilizzare il ricevitore
nel thread che le istanze Worker generano, quindi faremo riferimento al
parametro ricevitore nella chiusura. Il codice nel Listato 21-17 non è ancora
completamente compilabile.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --taglio--
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, ricevitore));
}
ThreadPool { workers, mittente }
}
// --taglio--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --taglio--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, ricevitore: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
ricevitore;
});
Worker { id, thread }
}
}WorkerAbbiamo apportato alcune piccole e semplici modifiche: passiamo il ricevitore a
Worker::new, per poi usarlo all’interno della chiusura.
Quando proviamo a controllare questo codice, otteniamo questo errore:
$ cargo check
Checking ciao v0.1.0 (file:///progetti/ciao)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:30:42
|
25 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
29 | for id in 0..dimensione {
| ----------------------- inside of this loop
30 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:57:33
|
57 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
29 ~ let mut value = Worker::new(id, receiver);
30 ~ for id in 0..dimensione {
31 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ciao` (lib) due to 1 previous error
Il codice sta cercando di passare ricevitore a più istanze Worker. Questo
non funzionerà, come ricorderai dal Capitolo 16: l’implementazione del canale
che Rust fornisce è multi-produttore, singolo consumatore. Ciò significa che
non possiamo semplicemente clonare l’estremità di ricezione del canale per
correggere questo codice. Inoltre, non vogliamo inviare un messaggio più volte a
più ricevitori; vogliamo un unico elenco di messaggi con più istanze Worker in
modo che ogni messaggio venga elaborato una sola volta.
Inoltre, rimuovere un lavoro dalla coda del canale comporta la mutazione del
ricevitore, quindi i thread hanno bisogno di un modo sicuro per condividere
e modificare ricevitore; altrimenti, potremmo ottenere condizioni di
competizione (come descritto nel capitolo 16).
Ricorda i puntatori intelligenti thread-safe discussi nel Capitolo 16: per
condividere la ownership tra più thread e consentire ai thread di
modificare il valore, dobbiamo utilizzare Arc<Mutex<T>>. Il type Arc
consentirà a più istanze Worker di possedere il ricevitore, mentre Mutex
garantirà che solo un Worker alla volta riceva un lavoro dal ricevitore. Il
Listato 21-18 mostra le modifiche che dobbiamo apportare.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --taglio--
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --taglio--
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool { workers, mittente }
}
// --taglio--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --taglio--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --taglio--
let thread = thread::spawn(|| {
ricevitore;
});
Worker { id, thread }
}
}Worker utilizzando Arc e MutexIn ThreadPool::new, inseriamo il ricevitore in un Arc e in un Mutex. Per
ogni nuovo Worker, cloniamo l’Arc per aumentare il conteggio dei reference
in modo che le istanze Worker possano condividere la ownership del
ricevitore.
Con queste modifiche, il codice viene compilato! Ci siamo quasi!
Implementare il Metodo execute
Implementiamo infine il metodo execute su ThreadPool. Modificheremo anche
Job da una struct a un alias di type per un oggetto trait che contiene
il type della chiusura che execute riceve. Come discusso nella sezione
“Sinonimi e Alias di Type” nel Capitolo 20,
gli alias di type ci consentono di abbreviare i type lunghi per
facilitarne l’uso. Guarda il Listato 21-19.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: mpsc::Sender<Job>,
}
// --taglio--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --taglio--
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool { workers, mittente }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.mittente.send(job).unwrap();
}
}
// --taglio--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
ricevitore;
});
Worker { id, thread }
}
}Job per una Box che contiene ogni chiusura e quindi invio del lavoro al canaleDopo aver creato una nuova istanza Job utilizzando la chiusura ottenuta in
execute, inviamo quel lavoro tramite l’estremità mittente del canale.
Chiamiamo unwrap su send nel caso in cui l’invio fallisca. Ciò potrebbe
accadere se, ad esempio, interrompiamo l’esecuzione di tutti i nostri thread,
il che significa che l’estremità ricevente ha smesso di ricevere nuovi messaggi.
Al momento, non possiamo interrompere l’esecuzione dei nostri thread: i nostri
thread continuano a essere eseguiti finché esiste il pool. Il motivo per cui
utilizziamo unwrap è che sappiamo che il caso di errore non si verificherà, ma
il compilatore non lo sa.
Ma non abbiamo ancora finito! Nel Worker, la nostra chiusura passata a
thread::spawn continua a fare riferimento solo all’estremità ricevente del
canale. Invece, abbiamo bisogno che la chiusura continui a girare all’infinito,
chiedendo all’estremità ricevente del canale un lavoro ed eseguendolo quando lo
riceve. Apportiamo la modifica mostrata nel Listato 21-20 a Worker::new.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool { workers, mittente }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.mittente.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --taglio--
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = ricevitore.lock().unwrap().recv().unwrap();
println!("Worker {id} ha un lavoro; in esecuzione.");
job();
}
});
Worker { id, thread }
}
}WorkerQui, chiamiamo prima lock sul ricevitore per acquisire il mutex, quindi
chiamiamo unwrap per generare un panic in caso di errori. L’acquisizione di
un blocco potrebbe non riuscire se il mutex è in uno stato poisoned
(avvelenato), cosa che può accadere se un altro thread va in panic mentre
mantiene il blocco invece di rilasciarlo. In questa situazione, chiamare
unwrap per far andare in panic questo thread è l’azione corretta da
intraprendere. Potresti anche cambiare questo unwrap in un expect con un
messaggio di errore che sia significativo per te.
Se otteniamo il blocco sul mutex, chiamiamo recv per ricevere un Job dal
canale. Un ultimo unwrap supera anche qui eventuali errori, che potrebbero
verificarsi se il thread che detiene il mittente si è arrestato, in modo
simile a come il metodo send restituisce Err se il ricevente si arresta.
La chiamata a recv blocca, quindi se non ci sono ancora lavori, il thread
corrente attenderà fino a quando non sarà disponibile un lavoro. Il Mutex<T>
assicura che solo un thread Worker alla volta tenti di richiedere un lavoro.
Il nostro gruppo di thread è ora in uno stato funzionante! Esegui cargo run
e fai alcune richieste:
$ cargo run
Compiling ciao v0.1.0 (file:///progetti/ciao)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `ciao` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.57s
Running `target/debug/ciao`
Worker 1 ha un lavoro; in esecuzione.
Worker 1 ha un lavoro; in esecuzione.
Worker 0 ha un lavoro; in esecuzione.
Worker 3 ha un lavoro; in esecuzione.
Worker 2 ha un lavoro; in esecuzione.
Worker 1 ha un lavoro; in esecuzione.
Successo! Ora abbiamo un thread pool che esegue le connessioni in modo asincrono. Non vengono mai creati più di quattro thread, quindi il nostro sistema non andrà in sovraccarico se il server riceve molte richieste. Se effettuiamo una richiesta a /attesa, il server sarà in grado di servire altre richieste facendo in modo che un altro thread le esegua.
Nota: se apri /attesa in più finestre del browser contemporaneamente, potrebbero caricarsi una alla volta a intervalli di cinque secondi. Alcuni browser web eseguono più istanze della stessa richiesta in sequenza per motivi di cache. Questa limitazione non è causata dal nostro server web.
Questo è un buon momento per fare una pausa e considerare come il codice nei Listati 21-18, 21-19 e 21-20 sarebbe diverso se utilizzassimo le future invece di una chiusura per il lavoro da svolgere. Quali type cambierebbero? In che modo le firme dei metodi sarebbero diverse, se lo fossero? Quali parti del codice rimarrebbero invariate?
Dopo aver appreso il funzionamento del ciclo while let nei capitoli 17 e 19,
potresti chiederti perché non abbiamo scritto il codice del thread Worker
come mostrato nel Listato 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool { workers, mittente }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.mittente.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --taglio--
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = ricevitore.lock().unwrap().recv() {
println!("Worker {id} ha un lavoro; in esecuzione.");
job();
}
});
Worker { id, thread }
}
}Worker::new utilizzando while letQuesto codice viene compilato ed eseguito, ma non produce il comportamento
concorrente desiderato: una richiesta lenta continuerà a causare l’attesa delle
altre richieste per essere elaborate. Il motivo è piuttosto sottile: la struct
Mutex non ha un metodo pubblico unlock perché la ownership del blocco si
basa sulla longevità di MutexGuard<T> all’interno del
LockResult<MutexGuard<T>> che il metodo lock restituisce. In fase di
compilazione, il controllo dei prestiti può quindi applicare la regola secondo
cui non è possibile accedere a una risorsa protetta da un Mutex a meno che non
si detenga il blocco. Tuttavia, questa implementazione può anche comportare il
mantenimento del blocco più a lungo del previsto se non si presta attenzione
alla lifetime del MutexGuard<T>.
Il codice nel Listato 21-20 che utilizza let job = ricevitore.lock().unwrap().recv().unwrap(); funziona perché con let,
qualsiasi valore temporaneo utilizzato nell’espressione a destra del segno di
uguale viene immediatamente eliminato al termine dell’istruzione let.
Tuttavia, while let (e if let e match) non elimina i valori temporanei
fino alla fine del blocco associato. Nel Listato 21-21, il blocco rimane attivo
per tutta la durata della chiamata a job(), il che significa che altre istanze
Worker non possono ricevere lavori.
Arresto Ordinato e Pulizia
Il codice nel Listato 21-20 risponde alle richieste in modo asincrono attraverso
l’uso di un thread pool, come volevamo. Riceviamo alcuni avvisi sui campi
workers, id e thread che non stiamo utilizzando in modo diretto, il che ci
ricorda che non stiamo ripulendo alcunché. Quando utilizziamo il metodo meno
elegante ctrl-C per arrestare il thread principale,
anche tutti gli altri thread vengono immediatamente arrestati, anche se sono
nel mezzo dell’elaborazione di una richiesta.
A seguire, implementeremo il trait Drop per chiamare join su ciascuno dei
thread nel gruppo in modo che possano completare le richieste su cui stanno
lavorando prima della chiusura. Quindi implementeremo un modo per comunicare ai
thread che devono smettere di accettare nuove richieste e chiudersi. Per
vedere questo codice in azione, modificheremo il nostro server in modo che
accetti solo due richieste prima di chiudere correttamente il suo gruppo di
thread.
Una cosa da notare mentre procediamo: nulla di tutto ciò influisce sulle parti del codice che gestiscono l’esecuzione delle chiusure, quindi tutto qui sarebbe esattamente lo stesso se utilizzassimo un thread pool per un runtime asincrono.
Implementare il Trait Drop su ThreadPool
Iniziamo con l’implementazione di Drop sul nostro thread pool. Quando il
gruppo viene eliminato, tutti i nostri thread dovrebbero unirsi per
assicurarsi di completare il loro lavoro. Il Listato 21-22 mostra un primo
tentativo di implementazione di Drop; questo codice non funziona ancora
perfettamente.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool { workers, mittente }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.mittente.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Spegnimento worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = ricevitore.lock().unwrap().recv().unwrap();
println!("Worker {id} ha un lavoro; in esecuzione.");
job();
}
});
Worker { id, thread }
}
}Per prima cosa, eseguiamo un ciclo su ciascuno dei thread del gruppo
workers. Usiamo &mut per questo perché self è un reference mutabile e
abbiamo anche bisogno di poter mutare worker. Per ogni worker, stampiamo un
messaggio che dice che questa particolare istanza di Worker si sta spegnendo,
quindi chiamiamo join sul thread di quell’istanza di Worker. Se la
chiamata a join fallisce, utilizziamo unwrap per far andare Rust in panic
e procedere a uno spegnimento non ordinato.
Ecco l’errore che otteniamo quando compiliamo questo codice:
$ cargo check
Checking ciao v0.1.0 (file:///progetti/ciao)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:53:13
|
53 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rust/library/std/src/thread/mod.rs:1921:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `ciao` (lib) due to 1 previous error
L’errore ci dice che non possiamo chiamare join perché abbiamo solo un
prestito mutabile di ogni worker e join assume la ownership del suo
argomento. Per risolvere questo problema, dobbiamo spostare il thread fuori
dall’istanza Worker che possiede thread in modo che join possa consumare
il thread. Un modo per farlo è quello di adottare lo stesso approccio che
abbiamo usato nel Listato 18-15. Se Worker contenesse un
Option<thread::JoinHandle<()>>, potremmo chiamare il metodo take su Option
per spostare il valore fuori dalla variante Some e lasciare una variante
None al suo posto. In altre parole, un Worker in esecuzione avrebbe una
variante Some in thread e, quando volessimo ripulire un Worker,
sostituiremmo Some con None in modo che il Worker non abbia più un
thread da eseguire.
Tuttavia, l’unico caso in cui ciò si verificherebbe sarebbe quando si elimina
Worker. In cambio, dovremmo gestire un Option<thread::JoinHandle<()>>
ovunque accedessimo a worker.thread. Il Rust idiomatico usa abbastanza spesso
Option, ma quando ti ritrovi a incapsulare qualcosa che sai sarà sempre
presente in un Option come scappatoia, è una buona idea cercare approcci
alternativi per rendere il tuo codice più pulito e meno soggetto a errori.
In questo caso, esiste un’alternativa migliore: il metodo Vec::drain. Accetta
un parametro di intervallo per specificare quali elementi rimuovere dal vettore
e restituisce un iteratore di tali elementi. Passando la sintassi
dell’intervallo .. si rimuoveranno tutti i valori dal vettore.
Quindi, dobbiamo aggiornare l’implementazione drop di ThreadPool in questo
modo:
#![allow(unused)] fn main() { use std::{ sync::{Arc, Mutex, mpsc}, thread, }; pub struct ThreadPool { workers: Vec<Worker>, mittente: mpsc::Sender<Job>, } type Job = Box<dyn FnOnce() + Send + 'static>; impl ThreadPool { /// Crea un nuovo ThreadPool. /// /// La dimensione é il numero di thread nel gruppo. /// /// # Panics /// /// La funzione `new` genera panic se la dimensione é zero. pub fn new(dimensione: usize) -> ThreadPool { assert!(dimensione > 0); let (mittente, ricevitore) = mpsc::channel(); let ricevitore = Arc::new(Mutex::new(ricevitore)); let mut workers = Vec::with_capacity(dimensione); for id in 0..dimensione { workers.push(Worker::new(id, Arc::clone(&ricevitore))); } ThreadPool { workers, mittente } } pub fn execute<F>(&self, f: F) where F: FnOnce() + Send + 'static, { let job = Box::new(f); self.mittente.send(job).unwrap(); } } impl Drop for ThreadPool { fn drop(&mut self) { for worker in self.workers.drain(..) { println!("Spegnimento worker {}", worker.id); worker.thread.join().unwrap(); } } } struct Worker { id: usize, thread: thread::JoinHandle<()>, } impl Worker { fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { let thread = thread::spawn(move || { loop { let job = ricevitore.lock().unwrap().recv().unwrap(); println!("Worker {id} ha un lavoro; in esecuzione."); job(); } }); Worker { id, thread } } } }
Questo risolve l’errore del compilatore e non richiede altre modifiche al nostro codice. Nota che, poiché drop può essere chiamato in caso di panic, anche unwrap potrebbe andare in panic e causare un doppio panic, che blocca immediatamente il programma e interrompe qualsiasi operazione di pulizia in corso. Questo va bene per un programma di esempio, ma non è consigliabile per il codice di produzione.
Segnalare ai Thread di Interrompere l’Attesa di Lavori
Con tutte le modifiche apportate, il nostro codice viene compilato senza alcun
avviso. Tuttavia, la cattiva notizia è che questo codice non funziona ancora nel
modo desiderato. La chiave è la logica nelle chiusure eseguite dai thread
delle istanze Worker: al momento, chiamiamo join, ma questo non chiude i
thread, perché il loop che eseguono cerca continuamente lavori. Se proviamo
a cancellare il nostro ThreadPool con la nostra attuale implementazione di
drop, il thread principale rimarrà bloccato per sempre, in attesa che il
primo thread finisca.
Per risolvere questo problema, dovremo modificare l’implementazione di drop in
ThreadPool e poi modificare il ciclo Worker.
Per prima cosa, modificheremo l’implementazione di drop in ThreadPool per
eliminare esplicitamente il mittente prima di attendere il completamento dei
thread. Il Listato 21-23 mostra le modifiche apportate a ThreadPool per
eliminare esplicitamente il mittente. A differenza del thread, qui abbiamo
bisogno di usare un Option per poter spostare mittente fuori da
ThreadPool con Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: Option<mpsc::Sender<Job>>,
}
// --taglio--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
// --taglio--
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool {
workers,
mittente: Some(mittente),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.mittente.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.mittente.take());
for worker in self.workers.drain(..) {
println!("Spegnimento worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = ricevitore.lock().unwrap().recv().unwrap();
println!("Worker {id} ha un lavoro; in esecuzione.");
job();
}
});
Worker { id, thread }
}
}mittente prima di unire i thread WorkerL’eliminazione di mittente chiude il canale, indicando che non verranno più
inviati messaggi. Quando ciò accade, tutte le chiamate a recv che le istanze
Worker eseguono nel ciclo infinito restituiranno un errore. Nel Listato 21-24,
modifichiamo il ciclo Worker per uscire correttamente dal ciclo in tal caso,
il che significa che i thread termineranno quando l’implementazione drop di
ThreadPool chiamerà join su di essi.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool {
workers,
mittente: Some(mittente),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.mittente.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.mittente.take());
for worker in self.workers.drain(..) {
println!("Spegnimento worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let messaggio = ricevitore.lock().unwrap().recv();
match messaggio {
Ok(job) => {
println!("Worker {id} ha un lavoro; in esecuzione.");
job();
}
Err(_) => {
println!("Worker {id} disconnesso; spegnimento.");
break;
}
}
}
});
Worker { id, thread }
}
}recv restituisce un errorePer vedere questo codice in azione, modifichiamo main in modo che accetti solo
due richieste prima di chiudere correttamente il server, come mostrato nel
Listato 21-25.
use ciao::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
gestisci_connessione(stream);
});
}
println!("Spegnimento.");
}
fn gestisci_connessione(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "ciao.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "ciao.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contenuto = fs::read_to_string(filename).unwrap();
let lunghezza = contenuto.len();
let risposta =
format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}");
stream.write_all(risposta.as_bytes()).unwrap();
}Non vorresti che un server web reale si spegnesse dopo aver servito solo due richieste. Questo codice dimostra semplicemente che lo spegnimento avviene ordinatamente e la pulizia funziona correttamente.
Il metodo take è definito nel trait Iterator e limita l’iterazione al
massimo ai primi due elementi. Il ThreadPool uscirà dallo scope alla fine di
main e verrà eseguita l’implementazione drop.
Avvia il server con cargo run ed effettua tre richieste. La terza richiesta
dovrebbe generare un errore e nel terminale dovresti vedere un output simile a
questo:
$ cargo run
Compiling ciao v0.1.0 (file:///progetti/ciao)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/ciao`
Worker 0 ha un lavoro; in esecuzione.
Spegnimento.
Spegnimento worker 0
Worker 3 ha un lavoro; in esecuzione.
Worker 1 disconnesso; spegnimento.
Worker 2 disconnesso; spegnimento.
Worker 3 disconnesso; spegnimento.
Worker 0 disconnesso; spegnimento.
Spegnimento worker 1
Spegnimento worker 2
Spegnimento worker 3
Potresti vedere un ordine diverso degli ID Worker e dei messaggi stampati.
Possiamo vedere come funziona questo codice dai messaggi: le istanze Worker 0
e 3 hanno ricevuto le prime due richieste. Il server ha smesso di accettare
connessioni dopo la seconda connessione e l’implementazione Drop su
ThreadPool inizia l’esecuzione prima ancora che Worker 3 inizi il suo
lavoro. L’eliminazione di mittente disconnette tutte le istanze Worker e
dice loro di chiudersi. Ciascuna istanza Worker stampa un messaggio quando si
disconnette, quindi il thread pool chiama join per attendere che ogni
thread Worker finisca.
Nota un aspetto interessante di questa particolare esecuzione: il ThreadPool
ha eliminato il mittente e, prima che qualsiasi Worker ricevesse un errore,
abbiamo provato a unire Worker 0. Worker 0 non aveva ancora ricevuto un
errore da recv, quindi il thread principale si è bloccato, in attesa che
Worker 0 terminasse. Nel frattempo, Worker 3 ha ricevuto un lavoro e poi
tutti i thread hanno ricevuto un errore. Quando Worker 0 ha terminato, il
thread principale ha atteso che le restanti istanze Worker terminassero. A
quel punto, tutte erano uscite dai loro cicli e si erano fermate.
Congratulazioni! Abbiamo completato il nostro progetto: ora abbiamo un server web di base che utilizza un thread pool per rispondere in modo asincrono. Siamo in grado di eseguire un arresto ordinato del server, che pulisce tutti i thread nel pool.
Ecco il codice completo come riferimento:
use ciao::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
gestisci_connessione(stream);
});
}
println!("Spegnimento.");
}
fn gestisci_connessione(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "ciao.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "ciao.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contenuto = fs::read_to_string(filename).unwrap();
let lunghezza = contenuto.len();
let risposta =
format!("{status_line}\r\nContent-Length: {lunghezza}\r\n\r\n{contenuto}");
stream.write_all(risposta.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
mittente: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Crea un nuovo ThreadPool.
///
/// La dimensione é il numero di thread nel gruppo.
///
/// # Panics
///
/// La funzione `new` genera panic se la dimensione é zero.
pub fn new(dimensione: usize) -> ThreadPool {
assert!(dimensione > 0);
let (mittente, ricevitore) = mpsc::channel();
let ricevitore = Arc::new(Mutex::new(ricevitore));
let mut workers = Vec::with_capacity(dimensione);
for id in 0..dimensione {
workers.push(Worker::new(id, Arc::clone(&ricevitore)));
}
ThreadPool {
workers,
mittente: Some(mittente),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.mittente.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.mittente.take());
for worker in &mut self.workers {
println!("Spegnimento worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, ricevitore: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let messaggio = ricevitore.lock().unwrap().recv();
match messaggio {
Ok(job) => {
println!("Worker {id} ha un lavoro; in esecuzione.");
job();
}
Err(_) => {
println!("Worker {id} disconnesso; spegnimento.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Potremmo fare di più qui! Se vuoi continuare a migliorare questo progetto, ecco alcune idee:
- Aggiungi altra documentazione a
ThreadPoole ai suoi metodi pubblici. - Aggiungi dei test delle funzionalità della libreria.
- Modifica le chiamate a
unwrapper una gestione degli errori più robusta. - Utilizza
ThreadPoolper eseguire alcune attività diverse dalla gestione delle richieste web. - Trova un crate che gestisce thread pool su crates.io e implementa un server web simile utilizzando il crate. Quindi, confronta la sua API e la sua robustezza con il thread pool che abbiamo implementato.
Riepilogo
Complimenti! Sei arrivato alla fine del libro! Ti ringraziamo per averci accompagnato in questo viaggio alla scoperta di Rust. Ora sei pronto per implementare i tuoi progetti Rust e aiutare gli altri nei loro. Ricorda che esiste una comunità accogliente di altri Rustacean che saranno felici di aiutarti con qualsiasi sfida incontrerai nel tuo viaggio con Rust.
Appendice
Le seguenti sezioni contengono materiale di riferimento che potrebbe esserti utile nel tuo percorso con Rust.
Appendice A: Parole chiave
I seguenti elenchi contengono parole chiave che sono riservate per l’uso attuale o futuro del linguaggio Rust. In quanto tali, non possono essere utilizzate come identificatori (tranne che come identificatori grezzi, come discuteremo nella sezione dedicata). Gli identificatori sono nomi di funzioni, variabili, parametri, elementi di struct, moduli, crate, costanti, macro, valori statici, attributi, type, trait o lifetime.
Parole Chiave Attualmente in Uso
Di seguito è riportato un elenco di parole chiave attualmente in uso, con la loro funzionalità descritta.
as- Eseguire un casting primitivo, disambiguare il trait specifico. che contiene un elemento o rinominare elementi nelle dichiarazioniuse.async- Restituire unFutureinvece di bloccare il thread corrente.await- Sospendere l’esecuzione fino a quando il risultato di unFutureè pronto.break- Uscire immediatamente da un ciclo.const- Definire elementi costanti o puntatori raw costanti.continue- Continuare all’iterazione successiva del ciclo.crate- In un percorso di modulo, si riferisce alla radice del crate.dyn- Dispatch dinamico a un oggetto trait.else- Alternativa per i costrutti di controllo di flussoifeif let.enum- Definire un’enumerazione.extern- Collegare una funzione o una variabile esterna.false- Letterale booleano falso.fn- Definire una funzione o il tipo di puntatore a funzione.for- Iterare su elementi da un iteratore, implementare un trait o specificare una lifetime di rango superiore.if- Ramificazione in base al risultato di un’espressione condizionale.impl- Implementare funzionalità innate o di trait.in- Parte della sintassi del ciclofor.let- Inizializzare una variabile.loop- Ciclo senza condizioni.match- Abbinare un valore a pattern.mod- Definire un modulo.move- Fare in modo che una closure prenda possesso di tutte le sue catture.mut- Denotare mutabilità in reference, puntatori raw o binding di pattern.pub- Denotare visibilità pubblica nei campi delle strutture, nei blocchiimplo nei moduli.ref- Inizializzare per reference.return- Ritorno dalla funzione.Self- Un alias di type per il type che stiamo definendo o implementando.self- Soggetto del metodo o modulo corrente.static- Variabile globale o lifetime che dura per l’intera esecuzione del programma.struct- Definire una struttura.super- Modulo genitore del modulo corrente.trait- Definire un trait.true- Letterale booleano vero.type- Definire un alias di type o un type associato.union- Definire un’unione; è una parola chiave solo quando usata in una dichiarazione di unione.unsafe- Annotare codice, funzioni, trait o implementazioni come non sicure.use- Portare simboli in scope; specificare catture precise per vincoli generici e di lifetime.where- Denotare clausole che vincolano un type.while- Ciclo condizionato al risultato di un’espressione.
Parole Chiave Riservate per Usi Futuri
Le seguenti parole chiave non hanno ancora alcuna funzionalità ma sono riservate da Rust per un potenziale uso futuro.
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Identificatori Grezzi
Gli Identificatori grezzi (raw identifiers) sono la sintassi che ti permette
di utilizzare parole chiave dove normalmente non sarebbero consentite. Utilizzi
un identificatore grezzo anteponendo a una parola chiave il prefisso r#. Ad
esempio, match è una parola chiave. Se provi a compilare la seguente funzione
che utilizza match come nome:
File: src/main.rs
fn match(ago: &str, pagliaio: &str) -> bool {
pagliaio.contains(ago)
}otterrai questo errore:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(ago: &str, pagliaio: &str) -> bool {
| ^^^^^ expected identifier, found keyword
L’errore indica che non è possibile utilizzare la parola chiave match come
identificatore di funzione. Per utilizzare match come nome di funzione, devi
utilizzare la sintassi dell’identificatore grezzo, in questo modo:
File: src/main.rs
fn r#match(ago: &str, pagliaio: &str) -> bool { pagliaio.contains(ago) } fn main() { assert!(r#match("foo", "foobar")); }
Questo codice verrà compilato senza errori. Nota il prefisso r# sul nome della
funzione nella sua definizione e il punto in cui la funzione viene chiamata in
main.
Gli identificatori grezzi ti permettono di utilizzare qualsiasi parola che
scegli come identificatore, anche se si tratta di una parola chiave riservata.
Questo ci dà maggiore libertà nella scelta dei nomi degli identificatori e ci
permette di integrarci con programmi scritti in un linguaggio in cui queste
parole non sono parole chiave. Inoltre, gli identificatori grezzi ti
permettono di utilizzare librerie scritte in un’edizione di Rust diversa da
quella utilizzata dal tuo crate. Per esempio, try non è una parola chiave
nell’edizione 2015, ma lo è nelle edizioni 2018, 2021 e 2024. Se dipendi da una
libreria scritta con l’edizione 2015 e che ha una funzione try, dovrai
utilizzare la sintassi dell’identificatore grezzo, r#try in questo caso, per
richiamare quella funzione dal tuo codice nelle edizioni successive. Per
ulteriori informazioni sulle edizioni, consulta Appendice E.
Appendice B: Operatori e Simboli
Questa appendice contiene un glossario della sintassi di Rust, compresi gli operatori e altri simboli che appaiono da soli o nel contesto di percorsi, generics, traits, macro, attributi, commenti, tuple e parentesi.
Operatori
La Tabella B-1 contiene gli operatori in Rust, un esempio di come l’operatore appare nel contesto, una breve spiegazione e se l’operatore in questione è sovrascrivibile. Se un operatore è sovrascrivibile, viene elencato il relativo trait da utilizzare per sovrascriverlo.
Tabella B-1: Operatori
| Operatore | Esempio | Spiegazione | Sovrascrivibile |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Espansione delle macro | |
! | !expr | Complemento logico o bit per bit | Not |
!= | expr != expr | Differente | PartialEq |
% | expr % expr | Resto aritmetico | Rem |
%= | var %= expr | Resto aritmetico con assegnazione | RemAssign |
& | &expr, &mut expr | Prestito (Borrow) | |
& | &type, &mut type, &'a type, &'a mut type | Type Puntatore a Prestito | |
& | expr & expr | AND Bit per Bit | BitAnd |
&= | var &= expr | AND Bit per Bit con assegnazione | BitAndAssign |
&& | expr && expr | AND logico | |
* | expr * expr | Moltiplicazione aritmetica | Mul |
*= | var *= expr | Moltiplicazione aritmetica con assegnazione | MulAssign |
* | *expr | De-referenziazione | Deref |
* | *const type, *mut type | Puntatore grezzo (Raw pointer) | |
+ | trait + trait, 'a + trait | Vincolo per type composto | |
+ | expr + expr | Addizione aritmetica | Add |
+= | var += expr | Addizione aritmetica con assegnazione | AddAssign |
, | expr, expr | Separatore di argomenti ed elementi | |
- | - expr | Negazione aritmetica | Neg |
- | expr - expr | Sottrazione aritmetica | Sub |
-= | var -= expr | Sottrazione aritmetica con assegnazione | SubAssign |
-> | fn(...) -> type, |…| -> type | Type di ritorno per funzioni e chiusure | |
. | expr.ident | Accesso a campo | |
. | expr.ident(expr, ...) | Chiamata a metodo | |
. | expr.0, expr.1, e così via | Indicizzazione tupla | |
.. | .., expr.., ..expr, expr..expr | Range esclusivo | PartialOrd |
..= | ..=expr, expr..=expr | Range inclusivo | PartialOrd |
.. | ..expr | Aggiornamento struct | |
.. | variant(x, ..), struct_type { x, .. } | “E il resto” con assegnazione tramite pattern | |
... | expr...expr | (Non più utilizzabile, usa ..=) In un pattern: range inclusivo | |
/ | expr / expr | Divisione aritmetica | Div |
/= | var /= expr | Divisione aritmetica con assegnazione | DivAssign |
: | pat: type, ident: type | Vincoli | |
: | ident: expr | Inizializzazione campo di struct | |
: | 'a: loop {...} | Etichetta loop | |
; | expr; | Terminatore di dichiarazioni ed elementi | |
; | [...; len] | Parte della sintassi per vettori a grandezza fissa | |
<< | expr << expr | Shift a sinistra | Shl |
<<= | var <<= expr | Shift a sinistra con assegnazione | ShlAssign |
< | expr < expr | Minore | PartialOrd |
<= | expr <= expr | Minore o uguale | PartialOrd |
= | var = expr, ident = type | Assegnazione/equivalenza | |
== | expr == expr | Comparazione di uguaglianza | PartialEq |
=> | pat => expr | Parte della sintassi del ramo di match | |
> | expr > expr | Maggiore | PartialOrd |
>= | expr >= expr | Maggiore o uguale | PartialOrd |
>> | expr >> expr | Shift a destra | Shr |
>>= | var >>= expr | Shift a destra con assegnazione | ShrAssign |
@ | ident @ pat | Vincolo di Pattern | |
^ | expr ^ expr | OR esclusivo Bit per Bit | BitXor |
^= | var ^= expr | OR esclusivo Bit per Bit con assegnazione | BitXorAssign |
| | pat | pat | Pattern alternativi | |
| | expr | expr | OR Bit per Bit | BitOr |
|= | var |= expr | OR Bit per Bit con assegnazione | BitOrAssign |
|| | expr || expr | OR logico | |
? | expr? | Propagazione errore |
Simboli
La tabella seguente contiene tutti i simboli che non funzionano come operatori, cioè non si comportano come una funzione o una chiamata di metodo.
La Tabella B-2 mostra i simboli che appaiono da soli e sono validi in diverse posizioni.
Tabella B-2: Sintassi stand alone
| Simbolo | Spiegazione |
|---|---|
'ident | Lifetime nominale o etichetta loop |
Numeri immediatamente seguiti da u8, i32, f64, usize, e così via | Letterale numerico di un type specifico |
"..." | Letterale stringa |
r"...", r#"..."#, r##"..."##, e così via | Letterale stringa grezzo, senza elaborazione dei caratteri di escape |
b"..." | Letterale byte di stringa; costituisce un vettore di byte anziché una stringa |
br"...", br#"..."#, br##"..."##, e così via | Letterale byte di stringa grezzo |
'...' | Letterale carattere |
b'...' | Letterale byte ASCII |
|…| expr | Chiusure |
! | Type vuoto per funzioni divergenti |
_ | Pattern “Ignorato” nel ramo di match; usato anche per rendere i letterali più leggibili |
La Tabella B-3 mostra i simboli che vengono usati nel contesto dei percorsi di un elemento nella gerarchia dei moduli.
Tabella B-3: Sintassi relativa ai Percorsi
| Simbolo | Spiegazione |
|---|---|
ident::ident | Nomenclatura percorso |
::path | Percorso relativo alla radice del crate (cioè un percorso assoluto esplicito) |
self::path | Percorso relativo al modulo corrente (cioè un percorso relativo esplicito). |
super::path | Percorso relativo al genitore del modulo corrente |
type::ident, <type as trait>::ident | Costanti, funzioni o type associati |
<type>::... | Elemento associato per un type generico (ad esempio, <&T>::..., <[T]>::..., e così via) |
trait::method(...) | Disambiguare una chiamata a un metodi specificando il trait che lo definisce |
type::method(...) | Disambiguare una chiamata a un metodo specificando il type in cui per cui è definito |
<type as trait>::method(...) | Disambiguare una chiamata a un metodo specificando il trait e il type |
La Tabella B-4 mostra i simboli che appaiono quando si usano type generici come parametri.
Table B-4: Generici
| Simbolo | Spiegazione |
|---|---|
percorso<...> | Specifica parametri a type generici in u n type (per esempio, Vec<u8>) |
percorso::<...>, metodo::<...> | Specifica parametri a type, funzioni o metodi generici in un’espressione; spesso chiamato operatore turbofish (per esempio, "42".parse::<i32>()) |
fn ident<...> ... | Definizione di funzione generica |
struct ident<...> ... | Definizione di struct generica |
enum ident<...> ... | Definizione di enum generica |
impl<...> ... | Definizione di implementazione generica |
for<...> type | Vincolo di lifetime prioritario |
type<ident=type> | Un type generico dove uno o più type associati hanno assegnazioni specifiche (per esempio, Iteratore<Elemento=T>) |
La Tabella B-5 mostra i simboli che appaiono nel contesto della dichiarazioni di type generici come parametri e dei corrispettivi vincoli di trait.
Table B-5: Vincoli di Trait
| Simbolo | Spiegazione |
|---|---|
T: U | Parametro generico T vincolato a type che implementano U |
T: 'a | Type generico type T con longevità 'a (implica che non possa contenere reference con lifetime inferiore ad 'a) |
T: 'static | Type generico T contenente solo reference con longevità infinita |
'b: 'a | Lifetime generica 'b deve essere maggiore di lifetime 'a |
T: ?Sized | Consente a parametri con type generico di essere type a dimensione dinamica |
'a + trait, trait + trait | Definizione di vincolo multiplo |
La Tabella B-6 mostra i simboli utilizzati nell’ambito della invocazione o definizione di macro e degli attributi di un dato elemento.
Table B-6: Macro e Attributi
| Simbolo | Spiegazione |
|---|---|
#[meta] | Attributo esterno |
#![meta] | Attributo interno |
$ident | Sostituzione macro |
$ident:kind | Metavariabile macro |
$(...)... | Ripetizione macro |
ident!(...), ident!{...}, ident![...] | Invocazione macro |
La Tabella B-7 mostra i simboli che creano commenti.
Tabella B-7: Commenti
| Simbolo | Spiegazione |
|---|---|
// | Commento in linea |
//! | Linea interna commento documentazione |
/// | Linea esterna commento documentazione |
/*...*/ | Blocco di commento, commento multi-linea |
/*!...*/ | Blocco interno commento documentazione |
/**...*/ | Blocco esterno commento documentazione |
La Tabella B-8 mostra i contesti in cui sono usate le parentesi tonde.
Table B-8: Parentesi Tonde
| Simbolo | Spiegazione |
|---|---|
() | Tupla vuota (unit), sia letterale che type |
(expr) | Espressione tra parentesi |
(expr,) | Espressione di tupla con singolo elemento |
(type,) | Tupla con singolo type |
(expr, ...) | Espressione tupla |
(type, ...) | Type tupla |
expr(expr, ...) | Espressione di chiamata di funzione; usato anche per inizializzare le varianti struct tupla e enum tupla |
La Tabella B-9 mostra i contesti di utilizzo delle parentesi graffe.
Tabella B-9: Parentesi Graffe
| Contesto | Spiegazione |
|---|---|
{...} | Blocco di codice |
Type {...} | Struct letterali |
La Tabella B-10 mostra i contesti in cui vengono utilizzate le parentesi quadre.
Tabella B-10: Parentesi Quadre
| Contesto | Spiegazione |
|---|---|
[...] | Vettore letterale |
[x; n] | Vettore letterale contenente n copie di x |
[type; n] | Vettore tipizzato contenente n istanze di type |
collezione[i] | Indicizzazione di una collezione; sovrascrivibile (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Indicizzazione in collezioni per estrazione slice, usando Range, RangeFrom, RangeTo, o RangeFull come “indici” |
Appendice C: Trait Derivabili
In vari punti del libro, abbiamo discusso dell’attributo derive, che si può
applicare a una definizione di struct o enum. L’attributo derive genera
codice che implementerà un trait con la sua implementazione predefinita sul
type annotato con la sintassi derive.
In questa appendice, forniamo un riferimento di tutti i trait nella libreria
standard che si possono usare con derive. Ogni sezione copre:
- Quali operatori e metodi l’implementazione derivata di questo trait abilita
- Cosa fa l’implementazione del trait fornita da
derive - Cosa significa per il type implementare questo trait
- Le condizioni in cui è consentito o non consentito implementare il trait
- Esempi di operazioni che richiedono il trait
Se si desidera un comportamento diverso da quello fornito dall’attributo
derive, consultare la documentazione della libreria standard per ogni
trait per dettagli su come implementarli manualmente.
I trait elencati qui sono gli unici definiti dalla libreria standard che
possono essere implementati sui vostri type usando derive. Altri trait
definiti nella libreria standard non hanno un comportamento predefinito sensato,
quindi sta a voi implementarli in modo coerente con gli obiettivi del vostro
codice.
Un esempio di trait che non può essere derivato è Display, che gestisce la
formattazione per gli utenti finali. Bisogna sempre considerare il modo
appropriato per mostrare un type all’utente finale. Quali parti del type
dovrebbero essere visibili? Quali parti sarebbero rilevanti? Quale formato dati
sarebbe più utile? Il compilatore Rust non ha questa conoscenza, quindi non può
fornire un comportamento predefinito adeguato per voi.
Questa lista di trait derivabili non è esaustiva: le librerie possono
implementare derive per i propri trait, rendendo la lista di trait che si
possono derivare praticamente aperta. L’implementazione di derive coinvolge
l’uso di macro procedurali, trattate nella sezione “Macro derive
Personalizzate” del Capitolo 20.
Debug per Output da Programmatore
Il trait Debug abilita la formattazione per il debug nelle stringhe di
formato, indicata aggiungendo :? all’interno dei segnaposto {}.
Il trait Debug permette di stampare istanze di un type a scopo di debug,
così tu e altri programmatori che usano il tuo type potete ispezionare
un’istanza in un punto particolare dell’esecuzione di un programma.
Il trait Debug è richiesto, ad esempio, nell’uso della macro assert_eq!.
Questa macro stampa i valori delle istanze passate come argomenti se
l’asserzione di uguaglianza fallisce, così i programmatori possono vedere perché
le due istanze non erano uguali.
PartialEq ed Eq per Confronti di Uguaglianza
Il trait PartialEq permette di confrontare istanze di un type per
verificarne l’uguaglianza e abilita l’uso degli operatori == e !=.
Derivare PartialEq implementa il metodo eq. Quando PartialEq è derivato su
struct, due istanze sono uguali solo se tutti i campi sono uguali, e sono
diverse se anche solo un campo è diverso. Quando è derivato su enum, ogni
variante è uguale a se stessa e diversa dalle altre varianti.
Il trait PartialEq è richiesto, ad esempio, dall’uso della macro
assert_eq!, che necessita di poter confrontare due istanze per l’uguaglianza.
Il trait Eq non ha metodi. Il suo scopo è segnalare che per ogni valore del
type annotato, il valore è uguale a se stesso. Il trait Eq può essere
applicato solo a type che implementano anche PartialEq, sebbene non tutti i
type che implementano PartialEq possano implementare Eq. Un esempio sono i
type numerici float: l’implementazione del float stabilisce che due
istanze di valore “non-numerico” (“not-a-number”, NaN) non sono uguali.
Un esempio di quando Eq è richiesto è per le chiavi in una HashMap<K, V>,
così che la HashMap<K, V> possa dire se due chiavi sono uguali.
PartialOrd ed Ord per Confronti di Ordinamento
Il trait PartialOrd permette di confrontare istanze di un type a scopo di
ordinamento. Un type che implementa PartialOrd può essere usato con gli
operatori <, >, <= e >=. Il trait PartialOrd può essere applicato
solo a type che implementano anche PartialEq.
Derivare PartialOrd implementa il metodo partial_cmp, che restituisce un
Option<Ordering> e restituisce None quando i valori dati non producono un
ordinamento valido. Un esempio di valore che non produce ordinamento, sebbene la
maggior parte dei valori di quel type possano essere confrontati, è il valore
float NaN. Chiamare partial_cmp con qualunque numero float e il valore
NaN restituirà None.
Quando derivato su struct, PartialOrd confronta due istanze confrontando i
campi in ordine di apparizione nella definizione della struct. Quando derivato
su enum, le varianti dichiarate prima sono considerate minori rispetto a
quelle definite dopo.
Il trait PartialOrd è richiesto, ad esempio, dalla funzione gen_range del
crate rand che genera un valore casuale nell’intervallo specificato da
un’espressione range.
Il trait Ord permette di sapere che per qualunque coppia di valori del
type annotato, esiste un ordinamento valido. Il trait Ord implementa il
metodo cmp, che restituisce un Ordering anziché un Option<Ordering>,
poiché un ordinamento valido sarà sempre possibile. Il trait Ord può essere
applicato solo a type che implementano anche PartialOrd ed Eq (e Eq
richiede PartialEq). Quando derivato su struct ed enum, cmp si comporta
allo stesso modo di partial_cmp derivato per PartialOrd.
Un esempio di quando Ord è richiesto è per la memorizzazione di valori in un
BTreeSet<T>, una struttura dati che memorizza dati i dati in base
all’ordinamento dei valori.
Clone e Copy per Duplicare Valori
Il trait Clone permette di creare esplicitamente una copia profonda di un
valore, e il processo di duplicazione può coinvolgere l’esecuzione di codice
arbitrario e la copia di dati nell’heap. Consulta la sezione “Interazione tra
Variabili e Dati con Clone” nel capitolo 4 per
ulteriori informazioni.
Derivare Clone implementa il metodo clone, che per il type chiama clone
su ciascuna parte del type. Questo significa che tutti i campi o valori del
type devono implementare anch’essi Clone per poter derivare Clone.
Un esempio di quando Clone è richiesto è quando si chiama il metodo to_vec
su una slice. La slice non possiede le istanze di type che contiene, ma il
vettore restituito da to_vec deve possedere le sue istanze, quindi to_vec
chiama clone su ogni elemento. Di conseguenza, il type contenuto nella
slice deve implementare Clone.
Il trait Copy permette di duplicare un valore copiando solo i dati
memorizzati sullo stack; non è necessario eseguire codice arbitrario. Consulta
la sezione “Duplicare Dati Sullo Stack” del
Capitolo 4 per ulteriori informazioni su Copy.
Il trait Copy non definisce alcun metodo, per prevenire che i programmatori
ne sovrascrivano i metodi e violino l’assunto che nessun codice arbitrario venga
eseguito. In questo modo, tutti possono assumere che copiare un valore sia molto
veloce.
Si può derivare Copy su qualunque type in cui tutte le parti implementano
Copy. Un type che implementa Copy deve anche implementare Clone, perché
un type che implementa Copy avrà già una semplice implementazione di Clone
che replicherà quanto fa Copy.
Il trait Copy è raramente richiesto; i type che implementano Copy hanno
ottimizzazioni disponibili, il che significa che non bisogna chiamare clone,
rendendo il codice più conciso.
Tutto ciò che si può fare con Copy si può anche fare con Clone, ma il codice
potrebbe essere più lento o dover usare clone in più punti.
Hash per Mappare un Valore a un Valore di Dimensione Fissa
Il trait Hash permette di prendere un’istanza di un type di dimensione
arbitraria e mappare quell’istanza a un valore di dimensione fissa usando una
funzione di hash. Derivare Hash implementa il metodo hash.
L’implementazione derivata del metodo hash combina il risultato di chiamare
hash su ciascuna parte del type, quindi tutti i campi o valori devono
anch’essi implementare Hash per poter derivare Hash.
Un esempio di quando Hash è richiesto è per memorizzare chiavi in una
HashMap<K, V> per archiviare dati in modo efficiente.
Default per Valori Predefiniti
Il trait Default permette di creare un valore predefinito per un type.
Derivare Default implementa la funzione default. L’implementazione derivata
della funzione default chiama la funzione default su ogni parte del type,
quindi tutti i campi o valori devono anch’essi implementare Default per
derivare Default.
La funzione Default::default è comunemente usata in combinazione con la
sintassi di aggiornamento delle struct discussa in “Creare Istanze con la
Sintassi di Aggiornamento delle Struct” nel
Capitolo 5. Si possono personalizzare alcuni campi di una struct e poi
impostare un valore predefinito per gli altri campi usando
..Default::default().
Il trait Default è richiesto per esempio quando si usa il metodo
unwrap_or_default su istanze Option<T>. Se l’Option<T> è None, il metodo
unwrap_or_default restituirà il risultato di Default::default per il type
T contenuto nell’Option<T>.
Appendice D: Utili Strumenti di Sviluppo
In questa appendice parliamo di alcuni utili strumenti di sviluppo che il progetto Rust mette a disposizione: la formattazione automatica, i modi rapidi per applicare le correzioni degli avvisi, un linter e l’integrazione con gli IDE.
Formattazione Automatica con rustfmt
Lo strumento rustfmt riformatta il tuo codice secondo lo stile di codice della
comunità. Molti progetti collaborativi utilizzano rustfmt per evitare
discussioni su quale stile utilizzare quando si scrive Rust: tutti formattano il
loro codice utilizzando lo strumento.
Le installazioni di Rust includono rustfmt come impostazione predefinita,
quindi dovresti già avere i programmi rustfmt e cargo-fmt sul tuo sistema.
Questi due comandi hanno lo stesso rapporto che esiste tre rustc e cargo,
nel senso che rustfmt è il formattatore vero e proprio mentre cargo-fmt
usa e comprende le convenzioni di un progetto che utilizza Cargo per quanto
riguarda la formattazione di quel progetto. Per formattare un qualsiasi
progetto, inserisci quanto segue:
$ cargo fmt
L’esecuzione di questo comando riformatta tutto il codice Rust nel crate
corrente. Questo dovrebbe cambiare solo lo stile del codice, non la sua
semantica. Per maggiori informazioni su rustfmt, consulta la sua
documentazione.
Correggere il Tuo Codice con rustfix
Lo strumento rustfix è incluso nelle installazioni di Rust ed è in grado di
correggere automaticamente gli avvertimenti del compilatore in cui è specificato
in modo preciso come quell’errore vada risolto. Probabilmente hai già visto
degli avvertimenti del compilatore. Per esempio, considera questo codice:
File: src/main.rs
fn main() { let mut x = 42; println!("{x}"); }
In questo caso, stiamo definendo la variabile x come mutabile, ma in realtà
non la mutiamo mai. Rust ci avverte di questo:
$ cargo build
Compiling mioprogramma v0.1.0 (file:///progetti/mioprogramma)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
L’avviso suggerisce di rimuovere la parola chiave mut. Possiamo applicare
automaticamente questo suggerimento utilizzando lo strumento rustfix eseguendo
il comando cargo fix:
$ cargo fix
Checking mioprogramma v0.1.0 (file:///progetti/mioprogramma)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Se guardiamo di nuovo src/main.rs, vedremo che cargo fix ha modificato il
codice:
File: src/main.rs
fn main() { let x = 42; println!("{x}"); }
La variabile x è ora immutabile e l’avviso non appare più.
Puoi anche usare il comando cargo fix per far passare il tuo codice tra
diverse edizioni di Rust. Le edizioni sono trattate nell’Appendice
E.
Altri Strumenti di Analisi del Codice con Clippy
Lo strumento Clippy è una raccolta di strumenti di analisi, lint in inglese, per analizzare il tuo codice in modo da individuare gli errori più comuni e migliorare il tuo codice Rust. Clippy è incluso nelle installazioni standard di Rust.
Per eseguire i lint di Clippy su qualsiasi progetto Cargo, inserisci quanto segue:
$ cargo clippy
Ad esempio, supponiamo di scrivere un programma che utilizza un’approssimazione di una costante matematica, come il pi greco, come fa questo programma:
fn main() { let x = 3.1415; let r = 8.0; println!("l'area del cerchio è {}", x * r * r); }
Eseguendo cargo clippy su questo progetto si ottiene questo errore:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Questo errore ti informa che in Rust c’è già definita una costante PI più
precisa e che il tuo programma sarebbe più corretto se usassi questa costante.
Dovresti quindi modificare il tuo codice per usare la costante PI.
Il codice seguente non produce alcun errore o avviso da parte di Clippy:
fn main() { let x = std::f64::consts::PI; let r = 8.0; println!("l'area del cerchio è {}", x * r * r); }
Per maggiori informazioni su Clippy, consulta la sua documentazione.
Integrazione nell’IDE con rust-analyzer
Per aiutare l’integrazione con l’IDE, la comunità di Rust raccomanda l’uso di
rust-analyzer. Questo strumento è un insieme
di utility incentrate sul compilatore che parlano in Language Server
Protocol, che è una specifica per gli IDE e i linguaggi
di programmazione per comunicare tra loro. Diversi client possono usare
rust-analyzer, come ad esempio il plug-in Rust Analyzer per Visual Studio
Code.
Visita la home page del progetto rust-analyzer
per le istruzioni di installazione, quindi installa il supporto per il server
linguistico nel tuo IDE specifico. Il tuo IDE otterrà funzionalità come
l’auto-completamento, il salto alla definizione e gli errori in linea.
Appendice E - Edizioni
Nel Capitolo 1, hai visto visto che il comando cargo new aggiunge un po’ di
metadata al tuo file Cargo.toml riguardo a un’edizione. Questa appendice parla
di cosa significhi!
Il linguaggio Rust e il suo compilatore hanno un ciclo di rilascio di sei settimane, il che significa che gli utenti ricevono un flusso continuo di nuove funzionalità. Altri linguaggi di programmazione rilasciano cambiamenti più grandi meno frequentemente; Rust rilascia aggiornamenti più piccoli più frequentemente. Dopo un po’, tutti questi piccoli cambiamenti si sommano. Ma da una versione all’altra, può essere difficile guardare indietro e dire: “Wow, tra Rust 1.10 e Rust 1.31, Rust è cambiato molto!”
Ogni circa tre anni, il team di Rust produce una nuova edizione di Rust. Ogni edizione raccoglie insieme le funzionalità introdotte in un pacchetto chiaro con documentazione e strumenti completamente aggiornati. Le nuove edizioni vengono rilasciate come parte del consueto processo di rilascio ogni sei settimane.
Le edizioni servono a scopi diversi per persone diverse:
- Per gli utenti attivi di Rust, una nuova edizione raccoglie i cambiamenti incrementali in un pacchetto facile da comprendere.
- Per chi non usa Rust, una nuova edizione segnala che sono stati introdotti miglioramenti importanti, che potrebbero far valere la pena di dare un’altra occhiata a Rust.
- Per chi sviluppa Rust, una nuova edizione fornisce un punto di aggregazione per l’intero progetto.
Al momento della scrittura, sono disponibili quattro edizioni di Rust: Rust 2015, Rust 2018, Rust 2021 e Rust 2024. Questo libro è scritto usando le idiomatiche dell’edizione Rust 2024.
La chiave edition in Cargo.toml indica quale edizione il compilatore deve
usare per il vostro codice. Se la chiave non esiste, Rust usa 2015 come valore
di edizione per ragioni di retro-compatibilità.
Ogni progetto può optare per un’edizione diversa dalla predefinita 2015. Le edizioni possono contenere cambiamenti incompatibili, come l’inclusione di una nuova parola chiave che confligge con identificatori nel codice. Tuttavia, a meno che non si scelga di adottare questi cambiamenti, il vostro codice continuerà a compilarsi anche aggiornando la versione del compilatore Rust.
Tutte le versioni di compilatore Rust supportano qualsiasi edizione esistita prima del rilascio di quel compilatore, e possono collegare crate di tutte le edizioni supportate insieme. I cambiamenti di edizione influenzano solo il modo in cui il compilatore analizza inizialmente il codice. Pertanto, se state usando Rust 2015 e una delle vostre dipendenze usa Rust 2018, il vostro progetto si compilerà e potrà usare quella dipendenza. Anche la situazione opposta, in cui il vostro progetto usa Rust 2018 e una dipendenza usa Rust 2015, funziona altrettanto bene.
Per essere chiari: la maggior parte delle funzionalità sarà disponibile in tutte le edizioni. Gli sviluppatori che usano qualsiasi edizione di Rust vedranno continuare a migliorare il linguaggio con nuovi rilasci stabili. Tuttavia, in alcuni casi, principalmente quando vengono aggiunte nuove parole chiave, alcune funzionalità nuove potrebbero essere disponibili solo nelle edizioni successive. Sarà necessario cambiare edizione se si vuole usufruire di tali funzionalità.
Per ulteriori dettagli, la Guida alle edizioni è un libro (in
inglese) completo sulle edizioni che elenca le differenze tra le edizioni e
spiega come aggiornare automaticamente il vostro codice a una nuova edizione
tramite cargo fix.
Appendice F: Traduzioni del Libro
Per le risorse in lingue diverse dall’inglese, la maggior parte sono ancora in traduzione; consulta l’etichetta Traduzioni per aiutarci o segnalarci una nuova traduzione!
- Original English
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
Appendice G: Come è Fatto Rust e “Nightly Rust”
Questa appendice parla di come viene sviluppato Rust e di come ciò influisca su di te come sviluppatore Rust.
Stabilità Senza Stagnazione
Come linguaggio, Rust si preoccupa molto della stabilità del tuo codice. Vogliamo che Rust sia una base solida su cui costruire, e se le cose cambiassero costantemente, questo sarebbe impossibile. Allo stesso tempo, se non possiamo sperimentare nuove funzionalità, potremmo non scoprire difetti importanti fino a dopo il rilascio, quando non possiamo più apportare cambiamenti.
La nostra soluzione a questo problema si chiama “stabilità senza stagnazione”, e il nostro principio guida è questo: non dovrai mai temere di aggiornarti a una nuova versione di Rust stabile. Ogni aggiornamento dovrebbe essere indolore, ma dovrebbe anche portarti nuove funzionalità, meno bug e tempi di compilazione più veloci.
Choo, Choo! I Canali di Rilascio e Viaggiare sui Treni
Lo sviluppo di Rust segue un orario ferroviario. Cioè, tutto lo sviluppo avviene sul ramo principale del repository di Rust. I rilasci seguono un “modello ferroviario” del rilascio software, usato da Cisco IOS e altri progetti software. Ci sono tre canali di rilascio per Rust:
- Nightly
- Beta
- Stable
La maggior parte degli sviluppatori Rust usa principalmente il canale stable (stabile), ma chi vuole provare funzionalità sperimentali può usare nightly o beta.
Ecco un esempio di come funziona il processo di sviluppo e rilascio: supponiamo che il team di Rust stia lavorando al rilascio di Rust 1.5. Quel rilascio è avvenuto nel dicembre 2015, ma ci fornisce numeri di versione realistici. Viene aggiunta una nuova funzionalità a Rust: un nuovo commit arriva sul branch principale. Ogni notte, viene prodotto un nuovo rilascio nightly di Rust. Ogni giorno è un giorno di rilascio, e questi rilasci sono creati automaticamente dalla nostra infrastruttura. Quindi, col passare del tempo, i nostri rilasci appaiono così, una volta per notte:
nightly: * - - * - - *
Ogni sei settimane, è il momento di preparare un nuovo rilascio! Il branch
beta del repository Rust si dirama dal branch principale usato da nightly.
Ora, ci sono due rilasci:
nightly: * - - * - - *
|
beta: *
La maggior parte degli utenti Rust non usa attivamente i rilasci beta, ma li testa nel loro sistema CI per aiutare Rust a scoprire possibili regressioni. Nel frattempo, c’è ancora un rilascio nightly ogni notte:
nightly: * - - * - - * - - * - - *
|
beta: *
Supponiamo che venga trovata una regressione. È un bene aver avuto tempo per
testare la beta prima che la regressione entrasse in un rilascio stabile! La
correzione viene applicata a al branch principale, così nightly viene
sistemato, poi la correzione viene portata anche sul branch beta, e viene
prodotto un nuovo rilascio beta:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Sei settimane dopo la creazione della prima beta, è il momento per un rilascio
stabile! Il branch stable viene prodotto dal branch beta:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Evviva! Rust 1.5 è pronto! Però abbiamo dimenticato una cosa: dato che sono
passate sei settimane, abbiamo bisogno anche di una nuova beta della
prossima versione di Rust, la 1.6. Quindi, dopo che stable si dirama da
beta, la prossima versione di beta si dirama di nuovo da nightly:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
Questo si chiama “modello ferroviario” perché ogni sei settimane un rilascio “parte dalla stazione”, ma deve ancora viaggiare attraverso il canale beta prima di arrivare come rilascio stabile.
Rust rilascia ogni sei settimane, come un orologio. Se conosci la data di un rilascio Rust, puoi conoscere la data del prossimo: è sei settimane dopo. Un aspetto piacevole di avere rilasci programmati ogni sei settimane è che il prossimo treno arriverà a breve. Se una funzionalità salta un rilascio, non c’è bisogno di preoccuparsi: ce n’è un altro in arrivo a breve! Questo aiuta a ridurre la pressione di inserire funzionalità possibilmente non finite vicino alla scadenza del rilascio.
Grazie a questo processo, puoi sempre scaricare la prossima build di Rust e
verificare di persona che è facile da aggiornare: se un rilascio beta non
funziona come previsto, puoi segnalarlo al team e farlo correggere prima che
avvenga il prossimo rilascio stabile! I problemi in un rilascio beta sono
relativamente rari, ma rustc è comunque un software, e i bug esistono.
Tempo di Manutenzione
Il progetto Rust supporta la versione stabile più recente. Quando una nuova versione stabile viene rilasciata, la vecchia versione raggiunge la fine della sua vita (EOL). Questo significa che ogni versione è supportata per sei settimane.
Funzionalità Instabili
C’è un altro aspetto in questo modello di rilascio: le funzionalità instabili. Rust utilizza una tecnica chiamata “feature flags” per determinare quali funzionalità sono abilitate in un certo rilascio. Se una nuova funzionalità è in sviluppo attivo, arriva sul branch principale e quindi in nightly, ma dietro a una feature flag. Se tu, come utente, vuoi provare questa funzionalità ancora in sviluppo, puoi farlo, ma devi usare un rilascio nightly di Rust e annotare il codice sorgente con il flag appropriato per abilitare la funzionalità.
Se stai usando una versione beta o stable di Rust, non puoi usare alcuna feature flag. Questa è la chiave che ci permette di usare praticamente le nuove funzionalità prima di dichiararle stabili per sempre. Chi vuole provare le funzionalità più avanzate può farlo, e chi vuole un’esperienza solida può restare sul canale stabile sapendo che il proprio codice non si romperà. Stabilità senza stagnazione.
Questo libro contiene solo informazioni sulle funzionalità stabili, poiché quelle in sviluppo sono ancora in cambiamento e sicuramente saranno diverse tra il momento in cui questo libro è stato scritto e quando saranno abilitate nei build stabili. Puoi trovare la documentazione per funzionalità presenti solo in rilasci nightly online.
Rustup e il Ruolo di Rust Nightly
Rustup rende facile passare tra i diversi canali di rilascio di Rust, a livello globale o per progetto. Di default verrà installato Rust stabile. Per installare nightly, ad esempio:
$ rustup toolchain install nightly
Puoi vedere tutte le toolchain (versioni di Rust e componenti associati) che
hai installato con rustup. Ecco un esempio sul computer Windows di uno degli
autori:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
Come vedi, la toolchain stable è quella predefinita. La maggior parte degli
utenti Rust usa stable la maggior parte del tempo. Potresti voler usare
stable la maggior parte del tempo, ma usare nightly su un progetto
specifico, perché ti interessa una funzionalità all’avanguardia. Per farlo, puoi
usare rustup override nella directory di quel progetto per impostare la
toolchain nightly come quella che rustup deve usare quando sei in quella
directory:
$ cd ~/progetti/usare-nightly
$ rustup override set nightly
Ora, ogni volta che chiami rustc o cargo dentro ~/progetti/usare-nightly,
rustup si assicurerà che stai usando Rust nightly invece del default
stable. Questo è molto comodo quando hai molti progetti Rust!
Il Processo RFC e i Team
Come si viene a sapere di queste nuove funzionalità? Il modello di sviluppo di Rust segue il processo Request For Comments (RFC). Se vuoi un miglioramento in Rust, puoi scrivere una proposta chiamata RFC.
Chiunque può scrivere RFC per migliorare Rust, e le proposte vengono revisionate e discusse dal team Rust, che è composto da molti sotto-team tematici. C’è una lista completa dei team sul sito di Rust, che include team per ogni area del progetto: design del linguaggio, implementazione del compilatore, infrastruttura, documentazione e altro ancora. Il team appropriato legge la proposta e i commenti, scrive qualche commento a sua volta, e infine si raggiunge un consenso per accettare o rifiutare la funzionalità.
Se la funzionalità è accettata, viene aperta una issue sul repository Rust, e qualcuno la implementa. Chi implementa potrebbe non essere la stessa persona che ha proposto la funzionalità! Quando l’implementazione è pronta, viene inserita nel branch principale dietro a una feature flag, come discusso nella sezione “Funzionalità Instabili”.
Dopo un po’ di tempo, quando gli sviluppatori Rust che usano i rilasci nightly hanno potuto provare la nuova funzionalità, i membri del team discutono la funzionalità, come è andata su nightly, e decidono se inserirla in Rust stabile o no. Se la decisione è di andare avanti, la feature flag viene rimossa, e la funzionalità è ora considerata stabile! Viaggia sul treno verso un nuovo rilascio stable di Rust.
Appendice H - Note di Traduzione
In questa appendice verranno raccolte note e indicazioni sulle scelte di traduzione usate nel corso di questo lavoro.
Come regola generale è stato scelto di tradurre in italiano termini tecnici che sono di uso comune nella programmazione o in altri linguaggi di programmazione (funzioni, moduli, ecc…) e mantenere in inglese termini che sono più specifici del linguaggio Rust e meno comuni.
Seguono alcuni elenchi raggruppati per tipologia, della terminologia usata in questo libro e della traduzione/non-traduzione con una spiegazione della scelta se necessario.
Tipi di dato / Strutture Dati
| Terminologia | Termini usati nel libro | Spiegazione |
|---|---|---|
| Type | Type | Tipo di dato. |
| Reference | Reference / Riferimento | Riferimento ad una variabile |
| Integer | Intero / Integer | Usato sia tradotto che originale quando necessario. |
| Float | Float | Numero in virgola mobile, usato il termine originale per brevità. |
| Boolean | Booleano | |
| Struct | Struct | |
| Enum | Enum | Usato termine originale per brevità rispetto a enumerazione. |
| Tuple | Tupla / Tuple | |
| Collection | Collezione | |
| Array | Array | specificatamente riferito al type Array |
| Vector | Vettore | specificatamente riferito al type Vec |
| Hash Map | Hash Map | Mappa hash |
| Slice | Slice | Riferimento ad una porzione di dati |
| String Slice | Slice di stringa | Riferimento ad una porzione di stringa |
| Trait | Trait | Tratto, Caratteristica |
| Trait Bound | Vincolo di Trait | |
| Handle | Handle | Puntatore ad un thread/processo |
| String literal | Letterale stringa | |
| Numeric literal | Letterale numerico |
Ownership e Varie
| Terminologia | Termini usati nel libro | Italiano |
|---|---|---|
| Ownership | Ownership | Possesso / Proprietà di una variabile sui dati che contiene. |
| Borrow Checker | Borrow Checker / Controllo dei prestiti | Funzionalità del compilatore Rust per verificare la consistenza dei riferimenti. |
| Borrowed Type | Type Preso in prestito | Tipo di dato di cui si è ricevuta la ownership. |
| Owned Type | Type posseduto / Type con ownership | |
| Borrowing Rules | Regole di prestito | |
| Lifetime | Lifetime / Longevità | Usato sia termine originale che tradotto per facilità di lettura. |
Concetti del Linguaggio
| Terminologia | Termini usati nel libro | Italiano |
|---|---|---|
| Crate | Crate | Contenitore. Mantenuto termine originale per semplicità |
| Package | Pacchetto | |
| Path | Path / Percorso | Percorso file o moduli |
| Root | Root / Radice / Cartella principale | |
| Workspace | Workspace / Spazio di lavoro | Spazio di lavoro gestito da Cargo |
| Namespace | ||
| Runtime | Esecuzione | Usato quando si intende l’esecuzione di un programma ecc. |
| Runtime | Runtime | Usato quando si intende il gestore dei blocchi asincroni (Capitolo 16-17 ecc.) |
| Closure | Chiusura | Termine che si trova anche in altri linguaggi. |
| Scope | Scope | Ambito di validità. |
| Environment | Ambiente | Riferito alle chiusure. |
| Refactoring | Refactoring / Riscrittura | Riscrivere, spostare parte del codice. |
| Panic | Panic | Mantenuto il termine originale perché in italiano faceva ridere ;-D |
| Return | Restituire / Ritornare | |
| Return Value | Valore di ritorno / Valore restituito | |
| Iterator | Iteratore | |
| Iterator Adapter | Adattatore | Sarebbe “Adattatore all’iteratore” |
| Consuming Adapter | Consumatore | Sarebbe “Adattatore all’iteratore che consuma l’adattatore” |
| Lazy | Lazy | Pigro / Pigrizia |
Rust Asincrono
| Terminologia | Termini usati nel libro | Italiano |
|---|---|---|
| Concurrency | Concorrenza | |
| Async | Async / Asincrono | Usato il termine originale quando specificamente richiesto, tradotto quando usato nella descrizione meno approfondita. |
| Thread | Thread | Mantenuto termine originale per semplicità. |
| Task | Task | Mantenuto termine originale per semplicità. |
| Spawned Thread/Task | Thread/Task Generato | |
| Future | Future | Mantenuto termine originale per semplicità. |
| Stream | Stream | Mantenuto termine originale per semplicità. |
Gerarchia Moduli
Per la gerarchia tra moduli sono utilizzati termini che si rifanno alla vita reale:
| Originale | Tradotto |
|---|---|
| Parent | Genitore |
| Child | Figlio |
| Ancestor | Antenato |